

In diesem Dokument wird erläutert, wie Sie das Verhalten, den Status und die Leistung Ihrer vollständig verwalteten Modelle in der Gemini Enterprise Agent Platform überwachen. Außerdem wird beschrieben, wie Sie das vordefinierte Dashboard zur Modellbeobachtung verwenden, um Einblicke in die Modellnutzung zu erhalten, Latenzprobleme zu identifizieren und Fehler zu beheben.
In diesem Dokument erfahren Sie, wie Sie Folgendes tun:
- Auf das Dashboard zur Modellbeobachtung zugreifen und es interpretieren
- Verfügbare Monitoring-Messwerte ansehen
- Traffic von Modellendpunkten mit dem Metrics Explorer überwachen
Auf das Dashboard zur Modellbeobachtung zugreifen und es interpretieren
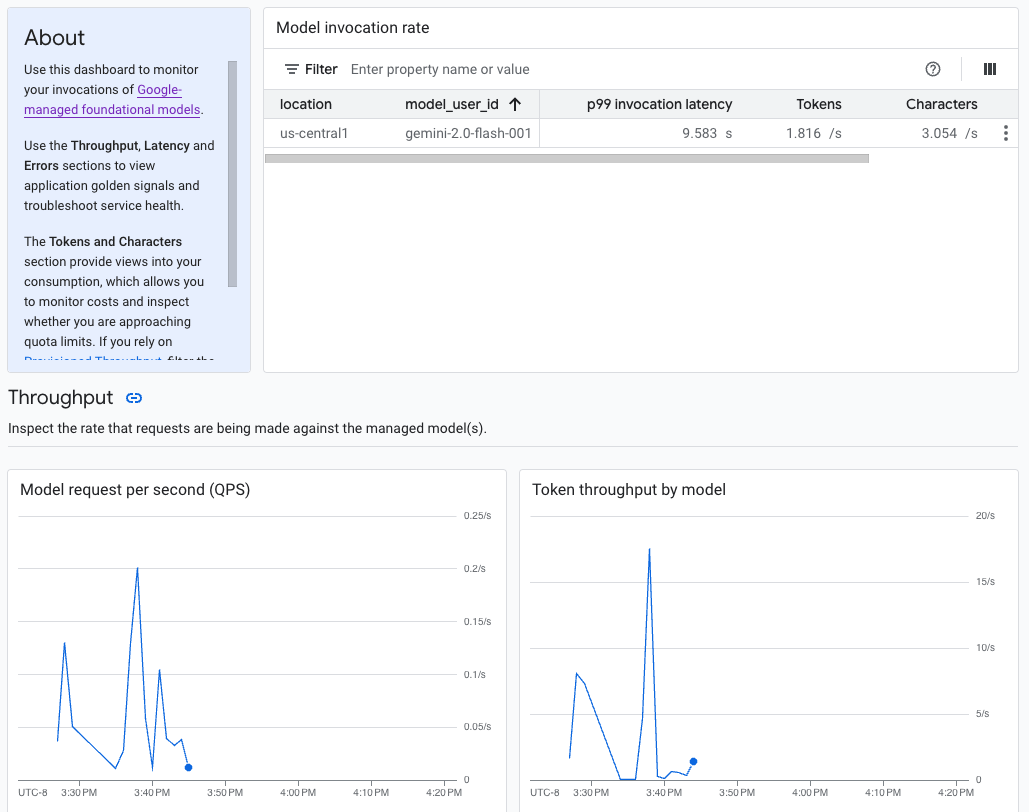
Generative AI in der Gemini Enterprise Agent Platform bietet ein vordefiniertes Dashboard zur Modellbeobachtung, mit dem Sie das Verhalten, den Status und die Leistung vollständig verwalteter Modelle ansehen können. Vollständig verwaltete Modelle, auch bekannt als Model as a Service (MaaS), werden von Google bereitgestellt und umfassen die Gemini-Modelle von Google und Partnermodelle mit verwalteten Endpunkten. Messwerte von selbst gehosteten Modellen sind nicht im Dashboard enthalten.
Generative AI in der Gemini Enterprise Agent Platform erfasst und meldet automatisch Aktivitäten von MaaS-Modellen, damit Sie Latenzprobleme schnell beheben und die Kapazität überwachen können.
Anwendungsfall
Als Anwendungsentwickler können Sie sehen, wie Ihre Nutzer mit den Modellen interagieren, die Sie bereitgestellt haben. Sie können beispielsweise sehen, wie sich die Modellnutzung (Modellanfragen pro Sekunde) und die Rechenintensität von Nutzerprompts (Latenzen bei der Modellaufrufung) im Zeitverlauf entwickeln. Da diese Messwerte mit der Modellnutzung zusammenhängen, können Sie auch die Kosten für die Ausführung der einzelnen Modelle schätzen.
Wenn ein Problem auftritt, können Sie es schnell über das Dashboard beheben. Sie können prüfen, ob Modelle zuverlässig und zeitnah reagieren, indem Sie die API-Fehlerraten, die Latenzen des ersten Tokens und den Token-Durchsatz ansehen.
Verfügbare Monitoring-Messwerte
Das Dashboard zur Modellbeobachtung zeigt eine Teilmenge der von Cloud Monitoring erfassten Messwerte an, z. B. Modellanfragen pro Sekunde (QPS), Token-Durchsatz und Latenzen des ersten Tokens. Im Dashboard finden Sie alle verfügbaren Messwerte.
Beschränkungen
Die Agent Platform erfasst Dashboard-Messwerte nur für API-Aufrufe an den Endpunkt eines Modells. Google Cloud Die Console-Nutzung, z. B. Messwerte aus Vertex AI Studio, wird nicht dem Dashboard hinzugefügt.
Dashboard aufrufen
- Wechseln Sie im Bereich „Agent Platform“ der Google Cloud Console zur Seite Dashboard.
Zur Agent Platform 1. Klicken Sie im Dashboard unter „Modellbeobachtung“ auf Alle Messwerte anzeigen, um das Dashboard zur Modellbeobachtung in der Google Cloud Observability Console aufzurufen.
Wenn Sie Messwerte für ein bestimmtes Modell oder an einem bestimmten Standort aufrufen möchten, legen Sie oben auf der Dashboard-Seite einen oder mehrere Filter fest.
Beschreibungen der einzelnen Messwerte finden Sie im Abschnitt „
aiplatform“ auf der Google Cloud Seite mit den Messwerten.
Traffic von Modellendpunkten überwachen
Folgen Sie dieser Anleitung, um den Traffic zu Ihrem Endpunkt im Metrics Explorer zu überwachen.
Wechseln Sie in der Google Cloud Console zur Seite Metrics Explorer.
Wählen Sie das Projekt aus, für das Sie Messwerte aufrufen möchten.
Klicken Sie im Drop-down-Menü Messwert auf Messwert auswählen.
Geben Sie in der Suchleiste Nach Ressourcen- oder Messwertname filtern den Wert
Gemini Enterprise Agent Platform Endpointein.Wählen Sie die Messwertkategorie Agent Platform-Endpunkt > Vorhersage aus. Wählen Sie unter Aktive Messwerte einen der folgenden Messwerte aus:
prediction/online/error_countprediction/online/prediction_countprediction/online/prediction_latenciesprediction/online/response_count
Klicken Sie auf Übernehmen. Wenn Sie mehr als einen Messwert hinzufügen möchten, klicken Sie auf Abfrage hinzufügen.
Sie können Ihre Messwerte mit den folgenden Drop-down-Menüs filtern oder aggregieren:
Mit dem Drop-down-Menü Filter können Sie eine Teilmenge Ihrer Daten anhand bestimmter Kriterien auswählen und ansehen. Wenn Sie beispielsweise nach dem Modell
gemini-2.0-flash-001filtern möchten, verwenden Sieendpoint_id = gemini-2p0-flash-001. Beachten Sie, dass das.in der Modellversion durch einpersetzt wird.Mit dem Drop-down-Menü Aggregation können Sie mehrere Datenpunkte zu einem einzelnen Wert kombinieren und eine zusammengefasste Ansicht Ihrer Messwerte aufrufen. Sie können beispielsweise die Summe von
response_codeaggregieren.
Optional können Sie Benachrichtigungen für Ihren Endpunkt einrichten. Weitere Informationen finden Sie unter Benachrichtigungsrichtlinien verwalten.
Informationen zum Aufrufen der Messwerte, die Sie Ihrem Projekt über ein Dashboard hinzufügen, finden Sie unter Dashboards – Übersicht.
Nächste Schritte
- Informationen zum Erstellen von Benachrichtigungen für Ihr Dashboard finden Sie unter Benachrichtigungen – Übersicht.
- Informationen zur Aufbewahrung von Messwertdaten finden Sie unter den Monitoring-Kontingenten und ‑Limits.
- Informationen zu ruhenden Daten finden Sie unter Ruhende Daten schützen.
- Eine Liste aller von Cloud Monitoring erfassten Messwerte finden Sie im
"
aiplatform" Abschnitt auf der Google Cloud Messwerte Seite.