

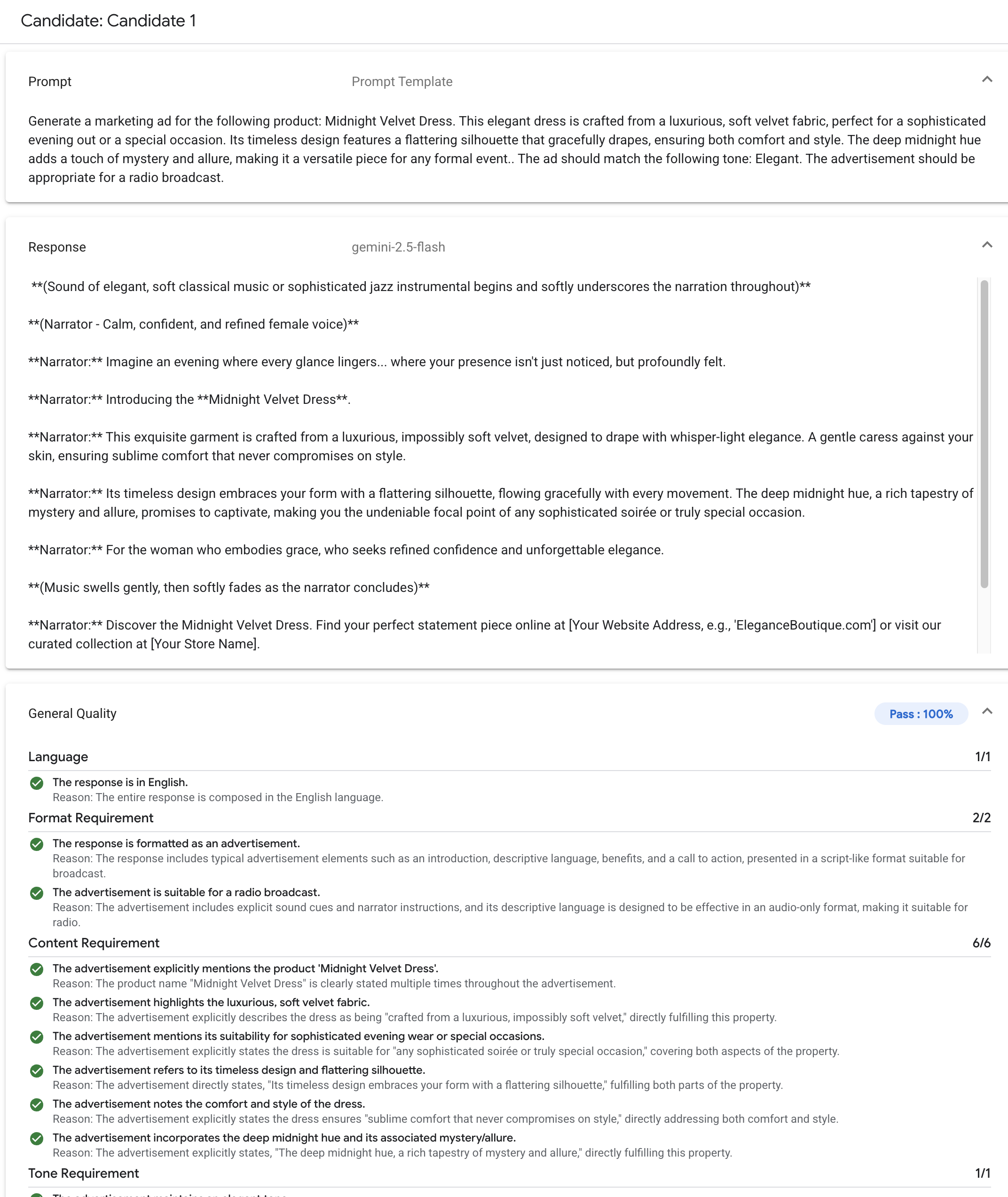
El Gen AI Evaluation Service proporciona herramientas de nivel empresarial para la evaluación objetiva y basada en datos de modelos de IA generativa. Brinda asistencia e información para varias tareas de desarrollo, como migraciones de modelos, edición de instrucciones y ajuste.
Funciones de Gen AI Evaluation Service
La característica distintiva del Gen AI Evaluation Service es la capacidad de usar rúbricas adaptables, un conjunto de pruebas personalizadas de aprobación o rechazo para cada instrucción individual. Las rúbricas de evaluación son similares a las pruebas de unidades en el desarrollo de software y tienen como objetivo mejorar el rendimiento del modelo en una variedad de tareas.
El servicio de evaluación de IA generativa admite los siguientes métodos de evaluación comunes:
Rúbricas adaptativas (recomendado): Genera un conjunto único de rúbricas de aprobación o rechazo para cada instrucción individual de tu conjunto de datos.
Rúbricas estáticas: Aplican un conjunto fijo de criterios de puntuación en todas las instrucciones.
Métricas basadas en cálculos: Usa algoritmos determinísticos, como
ROUGEoBLEU, cuando haya una verdad fundamental disponible.Funciones personalizadas: Define tu propia lógica de evaluación en Python para requisitos especializados.
Generación del conjunto de datos de evaluación
Puedes crear un conjunto de datos de evaluación con los siguientes métodos:
Sube un archivo que contenga instancias de instrucciones completas o proporciona una plantilla de instrucciones junto con un archivo correspondiente de valores de variables para completar las instrucciones.
Toma muestras directamente de los registros de producción para evaluar el uso real de tu modelo.
Usa la generación de datos sintéticos para generar una gran cantidad de ejemplos coherentes para cualquier plantilla de instrucciones.
Interfaces compatibles
Puedes definir y ejecutar tus evaluaciones con las siguientes interfaces:
Google Cloud consola: Una interfaz de usuario web que proporciona un flujo de trabajo guiado de extremo a extremo. Administra tus conjuntos de datos, ejecuta evaluaciones y profundiza en informes y visualizaciones interactivas. Consulta Cómo realizar la evaluación con la consola.
SDK de Python: Ejecuta evaluaciones de forma programática y renderiza comparaciones de modelos en paralelo directamente en tu entorno de Colab o Jupyter. Consulta Cómo realizar la evaluación con el cliente de IA generativa en el SDK de Agent Platform
Casos de uso
Gen AI Evaluation Service te permite ver el rendimiento de un modelo en tus tareas específicas y en función de tus criterios únicos, lo que proporciona estadísticas valiosas que no se pueden obtener de los rankings públicos ni de las comparativas generales. Esto admite tareas de desarrollo críticas, como las siguientes:
Migraciones de modelos: Compara versiones de modelos para comprender las diferencias de comportamiento y ajustar tus instrucciones y parámetros de configuración según corresponda.
Encuentra el mejor modelo: Ejecuta comparaciones directas de los modelos de Google y de terceros en tus datos para establecer un valor de referencia del rendimiento y determinar el que mejor se adapte a tu caso de uso.
Mejora de instrucciones: Usa los resultados de la evaluación para guiar tus esfuerzos de personalización. Volver a ejecutar una evaluación crea un ciclo de retroalimentación ajustado que proporciona comentarios inmediatos y cuantificables sobre tus cambios.
Ajuste del modelo: Evalúa la calidad de un modelo ajustado aplicando criterios de evaluación coherentes a cada ejecución.
Evaluación del agente: Evalúa el rendimiento de un agente con métricas específicas del agente, como los registros del agente y la calidad de la respuesta.
Flujo de trabajo de evaluación
Por lo general, para completar una evaluación, debes seguir estos pasos:
Crea un conjunto de datos de evaluación: Reúne un conjunto de datos de instancias de instrucciones que reflejen tu caso de uso específico. Puedes incluir respuestas de referencia (verdad fundamental) si planeas usar métricas basadas en cálculos.
Define métricas de evaluación: Elige las métricas que deseas usar para medir el rendimiento del modelo.
Generar respuestas del modelo: Selecciona uno o más modelos para generar respuestas para tu conjunto de datos. El SDK de Agent Platform admite cualquier modelo al que se pueda llamar a través de
LiteLLM, mientras que la consola admite los modelos de Google Gemini.Ejecuta la evaluación: Ejecuta el trabajo de evaluación, que evalúa las respuestas de cada modelo en función de las métricas seleccionadas.
Interpreta los resultados: Revisa las puntuaciones agregadas y las respuestas individuales para analizar el rendimiento del modelo.
Métricas de evaluación
A continuación, se incluyen los conceptos básicos relacionados con las métricas de evaluación:
Rúbricas: Son los criterios para calificar la respuesta de un modelo o una aplicación de LLM.
Métricas: Puntuación que mide el resultado del modelo en función de las rúbricas de calificación.
El servicio de evaluación de IA generativa ofrece las siguientes categorías de métricas:
Métricas basadas en rúbricas: Incorporan LLMs en los flujos de trabajo de evaluación para determinar la calidad de las respuestas del modelo. Las evaluaciones basadas en rúbricas son adecuadas para una variedad de tareas, en especial la calidad de la escritura, la seguridad y el cumplimiento de instrucciones, que a menudo son difíciles de evaluar con algoritmos determinísticos.
Rúbricas adaptables (recomendado): Las rúbricas se generan de forma dinámica para cada instrucción, como las pruebas de unidades. Las respuestas se evalúan con un conjunto único de pruebas de aprobación o rechazo para cada instrucción individual de tu conjunto de datos. Las rúbricas mantienen la evaluación pertinente para la tarea solicitada y tienen como objetivo proporcionar resultados objetivos, explicables y coherentes.
Por lo general, las rúbricas adaptativas son la forma más rápida de comenzar con las evaluaciones, ya que garantizan que cada evaluación sea pertinente para la tarea específica que se evalúa.
Rúbricas estáticas: Las rúbricas se definen de forma explícita y se aplica la misma rúbrica a todas las instrucciones. Las respuestas se evalúan con el mismo conjunto de evaluadores numéricos basados en la puntuación. Una sola puntuación numérica (por ejemplo, de 1 a 5) por instrucción. Usa rúbricas estáticas cuando se requiera una evaluación en una dimensión muy específica o cuando se requiera la misma rúbrica exacta en todas las instrucciones.
Métricas basadas en procesamiento: Evalúan las respuestas con algoritmos determinísticos, por lo general, con la verdad fundamental. Es una puntuación numérica (por ejemplo, de 0.0 a 1.0) por instrucción. Cuando la verdad fundamental está disponible y se puede correlacionar con un método determinístico.
Métricas de funciones personalizadas (solo SDK de Agent Platform): Define tu propia métrica a través de una función de Python.
Ejemplo de rúbrica adaptable
El proceso de evaluación de cada instrucción utiliza un sistema de dos pasos:
Generación de rúbricas: Primero, el servicio analiza tu instrucción y genera una lista de pruebas específicas y verificables (las rúbricas) que una buena respuesta debería cumplir.
Validación de la rúbrica: Después de que el modelo genera una respuesta, el servicio la evalúa en función de cada rúbrica, y ofrece un veredicto claro de
PassoFaily una justificación.
El resultado final es un porcentaje de aprobación agregado y un desglose detallado de las rúbricas que aprobó el modelo, lo que te brinda estadísticas prácticas para diagnosticar problemas y medir mejoras.
Si pasas de calificaciones subjetivas y de alto nivel a resultados de pruebas objetivos y detallados, puedes adoptar un ciclo de desarrollo basado en la evaluación y aplicar las prácticas recomendadas de ingeniería de software al proceso de creación de aplicaciones de IA generativa.
En el siguiente ejemplo, se muestran muestras de rúbricas adaptativas que se generaron para un conjunto de instrucciones:
Instrucción del usuario: Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.
Para esta instrucción, el paso de generación de rúbricas podría producir las siguientes rúbricas:
Rúbrica 1: La respuesta es un resumen del artículo proporcionado.
Rúbrica 2: La respuesta contiene exactamente cuatro oraciones.
Rúbrica 3: La respuesta mantiene un tono optimista.
Tu modelo puede producir la siguiente respuesta: The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.
Durante la validación de la rúbrica, el Gen AI Evaluation Service evalúa la respuesta según cada rúbrica:
Rúbrica 1: La respuesta es un resumen del artículo proporcionado.
Veredicto:
PassMotivo: La respuesta resume con precisión los puntos principales.
Rúbrica 2: La respuesta contiene exactamente cuatro oraciones.
Veredicto:
PassMotivo: La respuesta se compone de cuatro oraciones distintas.
Rúbrica 3: La respuesta mantiene un tono optimista.
Veredicto:
FailMotivo: La oración final introduce un punto negativo, lo que resta valor al tono optimista.
El porcentaje de aprobación final para esta respuesta es del 66.7%. Para comparar dos modelos, puedes evaluar sus respuestas con este mismo conjunto de pruebas generadas y comparar sus tasas de aprobación generales.
Comienza a usar las evaluaciones
Puedes comenzar a realizar evaluaciones con la consola.
Como alternativa, el siguiente código muestra cómo completar una evaluación con el cliente de IA generativa en el SDK de Agent Platform:
from vertexai import Client
from vertexai import types
import pandas as pd
client = Client(project=PROJECT_ID, location=LOCATION)
# Create an evaluation dataset
prompts_df = pd.DataFrame({
"prompt": [
"Write a simple story about a dinosaur",
"Generate a poem about Agent Platform",
],
})
# Get responses from one or multiple models
eval_dataset = client.evals.run_inference(model="gemini-2.5-flash", src=prompts_df)
# Define the evaluation metrics and run the evaluation job
eval_result = client.evals.evaluate(
dataset=eval_dataset,
metrics=[types.RubricMetric.GENERAL_QUALITY]
)
# View the evaluation results
eval_result.show()
El servicio de evaluación de IA generativa ofrece dos interfaces del SDK de Agent Platform:
Cliente de IA generativa en el SDK de Agent Platform (recomendado) (versión preliminar)
from vertexai import clientEl cliente de IA generativa es la interfaz más reciente y recomendada para la evaluación, a la que se accede a través de la clase Client unificada. Admite todos los métodos de evaluación y está diseñado para flujos de trabajo que incluyen la comparación de modelos, la visualización en el notebook y estadísticas para la personalización de modelos.
Módulo de evaluación en el SDK de Agent Platform (DG)
from vertexai.evaluation import EvalTaskEl módulo de evaluación es la interfaz anterior, que se mantiene para garantizar la retrocompatibilidad con los flujos de trabajo existentes, pero ya no está en desarrollo activo. Se accede a ella a través de la clase
EvalTask. Este método admite métricas estándar basadas en LLM como juez y métricas basadas en cálculos, pero no admite métodos de evaluación más nuevos, como las rúbricas adaptativas.
Regiones admitidas
Las siguientes regiones son compatibles con el servicio de evaluación de IA generativa:
Iowa (
us-central1)Virginia del Norte (
us-east4)Oregón (
us-west1)Las Vegas, Nevada - (
us-west4)Bélgica (
europe-west1)Países Bajos (
europe-west4)París, Francia (
europe-west9)
Notebooks disponibles
| Vínculos a notebooks | Descripción |
|---|---|
| Comienza a usar la evaluación rápida de IA generativa | Proporciona una introducción al servicio de evaluación de IA generativa. |
| Cómo evaluar modelos de terceros con el Gen AI Evaluation Service | Se muestra cómo usar el **SDK de Agent Platform** para evaluar varios tipos de modelos de terceros, incluidos los modelos a los que se accede con la API (como OpenAI y Anthropic), el modelo como servicio (MaaS) de Vertex Model Garden y los extremos de Bring Your Own Model (BYOM). |
| Migración de modelos con el servicio de evaluación de Gen AI | Muestra cómo usar el **SDK de Agent Platform** para el servicio de evaluación de IA generativa y comparar dos modelos propios (como Gemini 2.0 Flash y Gemini 2.5 Flash). Se destaca el uso de métricas predefinidas basadas en rúbricas adaptables y cómo los resultados de la evaluación pueden guiar la optimización de instrucciones. También se abordan funciones clave, como la evaluación de varios candidatos, la visualización en el notebook y la evaluación asíncrona por lotes. |
| Cómo evaluar la calidad de texto a imagen con el Gen AI Evaluation Service | Muestra cómo usar el SDK de Vertex AI para el servicio de evaluación de IA generativa para evaluar la calidad de las imágenes generadas en función de instrucciones de texto. Se muestra el uso de la métrica Gecko predefinida y adaptable basada en rúbricas. |
| Cómo evaluar la calidad de la conversión de texto a video con el servicio de evaluación de Gen AI | Muestra cómo usar el **SDK de Agent Platform** para el servicio de evaluación de IA generativa y evaluar la calidad de los videos generados en función de instrucciones de texto. Se muestra el uso de la métrica Gecko predefinida y adaptable basada en rúbricas. |