

I modelli di incorporamento di Gemini Enterprise Agent Platform possono generare incorporamenti ottimizzati per vari tipi di attività, come il recupero di documenti, la risposta a domande e la verifica dei fatti. I tipi di attività sono etichette che ottimizzano gli incorporamenti generati dal modello in base al tuo caso d'uso previsto. Questo documento descrive come scegliere il tipo di attività ottimale per i tuoi incorporamenti.
Modelli supportati
I tipi di attività sono supportati dai seguenti modelli:
text-embedding-005text-multilingual-embedding-002gemini-embedding-001
Vantaggi dei tipi di attività
I tipi di attività possono migliorare la qualità degli incorporamenti generati da un modello di incorporamento.
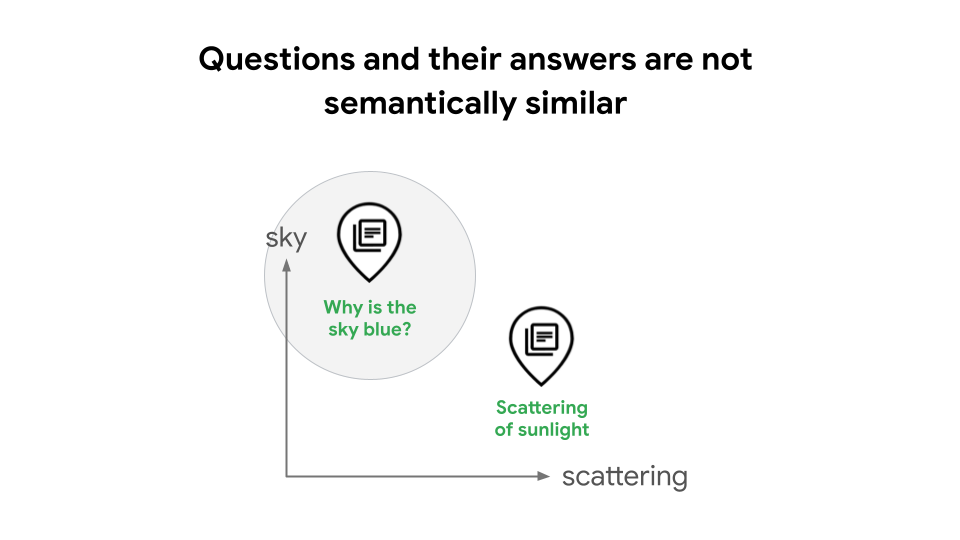
Ad esempio, quando si creano sistemi di generazione aumentata dal recupero (RAG), un progetto comune è quello di utilizzare gli incorporamenti di testo e la ricerca vettoriale per eseguire una ricerca di similarità. In alcuni casi, ciò può comportare un peggioramento della qualità della ricerca, perché le domande e le relative risposte non sono semanticamente simili. Ad esempio, una domanda come "Perché il cielo è blu?" e la sua risposta "La diffusione della luce solare causa il colore blu" hanno significati distinti come affermazioni, il che significa che un sistema RAG non riconoscerà automaticamente la loro relazione, come illustrato nella Figura 1. Senza i tipi di attività, uno sviluppatore RAG dovrebbe addestrare il modello per apprendere la relazione tra query e risposte, il che richiede competenze ed esperienza avanzate in data science, oppure utilizzare l'espansione delle query basata su LLM o HyDE, che possono introdurre latenza e costi elevati.
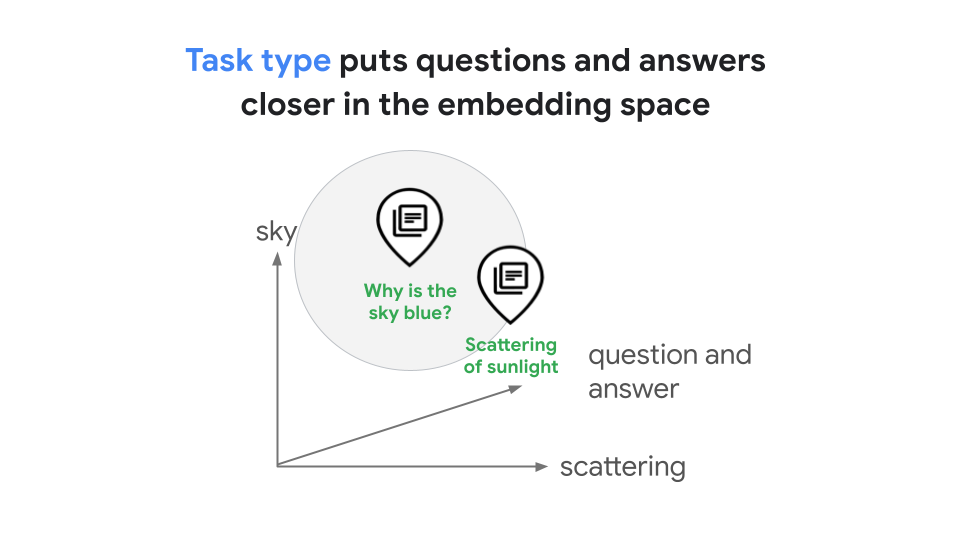
I tipi di attività ti consentono di generare incorporamenti ottimizzati per attività specifiche, il che ti fa risparmiare tempo e costi rispetto allo sviluppo di incorporamenti specifici per le attività. L'incorporamento generato per la query "Perché il cielo è blu?" e la relativa risposta "La diffusione della luce solare causa il colore blu" si troverebbe nello spazio di incorporamento condiviso che rappresenta la relazione tra loro, come mostrato nella Figura 2. In questo esempio RAG, gli incorporamenti ottimizzati migliorerebbero le ricerche di similarità.
Oltre al caso d'uso di query e risposte, i tipi di attività forniscono anche spazi di incorporamento ottimizzati per attività come classificazione, clustering e verifica dei fatti.
Tipi di attività supportati
I modelli di incorporamento che utilizzano tipi di attività supportano i seguenti tipi di attività:
| Tipo di attività | Descrizione |
|---|---|
CLASSIFICATION |
Utilizzato per generare embedding ottimizzati per classificare i testi in base a etichette preimpostate |
CLUSTERING |
Utilizzato per generare incorporamenti ottimizzati per raggruppare i testi in base alle loro somiglianze |
RETRIEVAL_DOCUMENT, RETRIEVAL_QUERY, QUESTION_ANSWERING e FACT_VERIFICATION |
Utilizzato per generare incorporamenti ottimizzati per la ricerca di documenti o il recupero di informazioni |
CODE_RETRIEVAL_QUERY |
Utilizzato per recuperare un blocco di codice in base a una query in linguaggio naturale, ad esempio ordina un array o inverti un elenco collegato. Gli incorporamenti dei blocchi di codice vengono calcolati utilizzando RETRIEVAL_DOCUMENT. |
SEMANTIC_SIMILARITY |
Utilizzato per generare incorporamenti ottimizzati per valutare la somiglianza del testo. Non è destinato a casi d'uso di recupero. |
Il tipo di attività migliore per il tuo job di incorporamento dipende dal caso d'uso per gli incorporamenti. Prima di selezionare un tipo di attività, determina il caso d'uso degli incorporamenti.
Determinare il caso d'uso degli incorporamenti
I casi d'uso degli incorporamenti rientrano in genere in una delle quattro categorie: valutazione
della somiglianza del testo, classificazione dei testi, raggruppamento dei testi o recupero di informazioni
dai testi. Se il tuo caso d'uso non rientra in una delle categorie precedenti,
utilizza per impostazione predefinita il tipo di attività RETRIEVAL_QUERY.
Esistono due tipi di formattazione delle istruzioni per le attività: asimmetrica e simmetrica. Dovrai utilizzare quella corretta in base al tuo caso d'uso.
| Casi d'uso del recupero (formato asimmetrico) |
Tipo di attività della query | Tipo di attività del documento |
|---|---|---|
| Query di ricerca | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| Question answering | QUESTION_ANSWERING | |
| Fact checking | FACT_VERIFICATION | |
| Recupero del codice | CODE_RETRIEVAL_QUERY |
| Casi d'uso con un solo input (formato simmetrico) |
Tipo di attività di input |
|---|---|
| Classificazione | CLASSIFICAZIONE |
| Clustering | CLUSTERING |
| Semantic Similarity (Non utilizzare per i casi d'uso di recupero; destinato a STS) |
SEMANTIC_SIMILARITY |
Classificare i testi
Se vuoi utilizzare gli incorporamenti per classificare i testi in base a etichette preimpostate, utilizza
il tipo di attività CLASSIFICATION. Questo tipo di attività genera incorporamenti in uno spazio di incorporamento ottimizzato per la classificazione.
Ad esempio, supponiamo di voler generare incorporamenti per i post sui social media che puoi poi utilizzare per classificare il loro sentiment come positivo, negativo o neutro. Quando gli incorporamenti per un post sui social media che recita "Non mi piace viaggiare in aereo" vengono classificati, il sentimento viene classificato come negativo.
Testi del cluster
Se vuoi utilizzare gli incorporamenti per raggruppare i testi in base alle loro somiglianze, utilizza
il tipo di attività CLUSTERING. Questo tipo di attività genera incorporamenti ottimizzati
per essere raggruppati in base alle loro somiglianze.
Ad esempio, supponiamo che tu voglia generare incorporamenti per articoli di notizie in modo da mostrare agli utenti articoli correlati per argomento a quelli che hanno letto in precedenza. Una volta generati e raggruppati gli incorporamenti, puoi suggerire agli utenti che leggono molti articoli sportivi altri articoli correlati.
Altri casi d'uso per il clustering includono:
- Segmentazione dei clienti:raggruppa i clienti con incorporamenti simili generati dai loro profili o attività per un marketing mirato ed esperienze personalizzate.
- Segmentazione dei prodotti: il clustering degli incorporamenti dei prodotti in base al titolo e alla descrizione del prodotto, alle immagini del prodotto o alle recensioni dei clienti può aiutare le attività a eseguire l'analisi dei segmenti sui propri prodotti.
- Ricerche di mercato:il clustering delle risposte ai sondaggi sui consumatori o degli incorporamenti dei dati dei social media può rivelare modelli e tendenze nascosti nelle opinioni, nelle preferenze e nei comportamenti dei consumatori, contribuendo agli sforzi di ricerca di mercato e informando le strategie di sviluppo dei prodotti.
- Sanità:il clustering degli incorporamenti dei pazienti derivati da dati medici può aiutare a identificare gruppi con condizioni o risposte al trattamento simili, portando a piani sanitari più personalizzati e terapie mirate.
- Tendenze del feedback dei clienti:il raggruppamento del feedback dei clienti di vari canali (sondaggi, social media, ticket di assistenza) può aiutare a identificare punti problematici comuni, richieste di funzionalità e aree di miglioramento del prodotto.
Recuperare informazioni dai messaggi
Quando crei un sistema di ricerca o recupero, lavori con due tipi di testo:
- Corpus: la raccolta di documenti in cui vuoi eseguire la ricerca.
- Query: il testo fornito da un utente per cercare informazioni all'interno del corpus.
Per ottenere il rendimento migliore, devi utilizzare diversi tipi di attività per generare incorporamenti per il corpus e le query.
Innanzitutto, genera gli incorporamenti per l'intera raccolta di documenti. Questi sono i contenuti che verranno recuperati dalle query degli utenti. Quando incorpori questi documenti,
utilizza il tipo di attività RETRIEVAL_DOCUMENT. In genere, esegui questo passaggio una volta per
indicizzare l'intero corpus e poi archiviare gli embedding risultanti in un database
di vettori.
Successivamente, quando un utente invia una ricerca, generi un embedding per il testo della query in tempo reale. Per questo, devi utilizzare un tipo di attività che corrisponda all'intento dell'utente. Il sistema utilizzerà questo embedding della query per trovare gli embedding dei documenti più simili nel database vettoriale.
Per le query vengono utilizzati i seguenti tipi di attività:
RETRIEVAL_QUERY: utilizza questa opzione per una query di ricerca standard in cui vuoi trovare documenti pertinenti. Il modello cerca incorporamenti di documenti semanticamente vicini all'incorporamento della query.QUESTION_ANSWERING: utilizza questo valore quando tutte le query dovrebbero essere domande vere e proprie, ad esempio "Perché il cielo è blu?" o "Come si allacciano le scarpe?".FACT_VERIFICATION: utilizza questo operatore quando vuoi recuperare un documento dal tuo corpus che dimostri o smentisca un'affermazione. Ad esempio, la query "le mele crescono sottoterra" potrebbe recuperare un articolo sulle mele che smentirebbe l'affermazione.
Considera il seguente scenario reale in cui le query di recupero sarebbero utili:
- Per una piattaforma di e-commerce, vuoi utilizzare gli incorporamenti per consentire agli utenti di cercare prodotti utilizzando sia query di testo sia immagini, offrendo un'esperienza di acquisto più intuitiva e coinvolgente.
- Per una piattaforma didattica, vuoi creare un sistema di domande e risposte che possa rispondere alle domande degli studenti in base ai contenuti dei libri di testo o alle risorse didattiche, fornendo esperienze di apprendimento personalizzate e aiutando gli studenti a comprendere concetti complessi.
Recupero del codice
text-embedding-005 supporta un nuovo tipo di attività CODE_RETRIEVAL_QUERY,
che può essere utilizzato per recuperare blocchi di codice pertinenti utilizzando query di testo normale. Per
utilizzare questa funzionalità, i blocchi di codice devono essere incorporati utilizzando il
tipo di attività RETRIEVAL_DOCUMENT, mentre le query di testo vengono incorporate utilizzando
CODE_RETRIEVAL_QUERY.
Per esplorare tutti i tipi di attività, consulta il riferimento del modello.
Ecco un esempio:
REST
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-005:predict -d \
$'{
"instances": [
{
"task_type": "CODE_RETRIEVAL_QUERY",
"content": "Function to add two numbers"
}
],
}'
Python
Per scoprire come installare o aggiornare l'SDK Vertex AI per Python, consulta Installare l'SDK Vertex AI per Python. Per saperne di più, consulta la documentazione di riferimento dell'API Python.
Valutare la somiglianza del testo
Se vuoi utilizzare gli incorporamenti per valutare la somiglianza del testo, utilizza il tipo di attività
SEMANTIC_SIMILARITY. Questo tipo di attività genera incorporamenti ottimizzati per la generazione di punteggi di similarità.
Ad esempio, supponiamo di voler generare embedding da utilizzare per confrontare la somiglianza dei seguenti testi:
- Il gatto sta dormendo
- Il felino sta facendo un pisolino
Quando gli incorporamenti vengono utilizzati per creare un punteggio di similarità, questo è elevato perché entrambi i testi hanno quasi lo stesso significato.
Considera i seguenti scenari reali in cui valutare la somiglianza dell'input sarebbe utile:
- Per un sistema di consigli, devi identificare gli elementi (ad es. prodotti, articoli, film) semanticamente simili a quelli preferiti da un utente, fornendo consigli personalizzati e migliorando la soddisfazione dell'utente.
Quando utilizzi questi modelli, si applicano le seguenti limitazioni:
- Non utilizzare questi modelli di anteprima su sistemi di produzione o mission critical.
- Questi modelli sono disponibili solo in
us-central1. - Le previsioni in batch non sono supportate.
- La personalizzazione non è supportata.
Passaggi successivi
- Scopri come ottenere incorporamenti di testo.