

Mit dem Gemini-Modell und ‑Tool für die Computernutzung können Sie Ihre Anwendungen so konfigurieren, dass sie mit dem Browser interagieren und Aufgaben im Browser automatisieren. Mithilfe von Screenshots kann das Modell und Tool „Computer Use“ Informationen über einen Computerbildschirm ableiten und Aktionen ausführen, indem es bestimmte UI-Aktionen wie Mausklicks und Tastatureingaben generiert. Ähnlich wie beim Funktionsaufruf müssen Sie den clientseitigen Anwendungscode schreiben, um den Aufruf des Computer Use-Modells und der Tool-Funktion zu empfangen und die entsprechenden Aktionen auszuführen.
Mit dem Modell und Tool „Computer Use“ können Sie Agents erstellen, die Folgendes können:
- Wiederholte Dateneingaben oder das Ausfüllen von Formularen auf Websites automatisieren
- Websites aufrufen, um Informationen zu sammeln
- Nutzer unterstützen, indem Sie Abfolgen von Aktionen in Webanwendungen ausführen.
In diesem Leitfaden werden folgende Themen behandelt:
- Funktionsweise des Modells und Tools zur Computernutzung
- Modell und Tool zur Computernutzung aktivieren
- Anfragen senden, Antworten empfangen und Agent-Schleifen erstellen
- Unterstützte Computeraktionen
- Unterstützung bei Sicherheit und Datenschutz
- Preise in der Vorschau ansehen
In dieser Anleitung wird davon ausgegangen, dass Sie das Gen AI SDK for Python verwenden und mit der Playwright API vertraut sind.
Das Modell und Tool zur Computernutzung wird in den anderen SDK-Sprachen oder der Google Cloud -Konsole während dieser Vorschau nicht unterstützt.
Außerdem können Sie die Referenzimplementierung für das Modell und das Tool zur Computernutzung auf GitHub ansehen.
Unterstützte Modelle
Das Modell und Tool zur Computernutzung wird bei Verwendung der folgenden Modelle unterstützt:
Klicken Sie, um die unterstützten Modelle zu maximieren.
Funktionsweise des Modells und Tools zur Computernutzung
Anstatt Textantworten zu generieren, bestimmt das Modell und Tool für die Computernutzung, wann bestimmte UI-Aktionen wie Mausklicks ausgeführt werden sollen, und gibt die erforderlichen Parameter zum Ausführen dieser Aktionen zurück. Sie müssen den clientseitigen Anwendungscode schreiben, um das Modell und das Tool function_call für die Computernutzung zu empfangen und die entsprechenden Aktionen auszuführen.
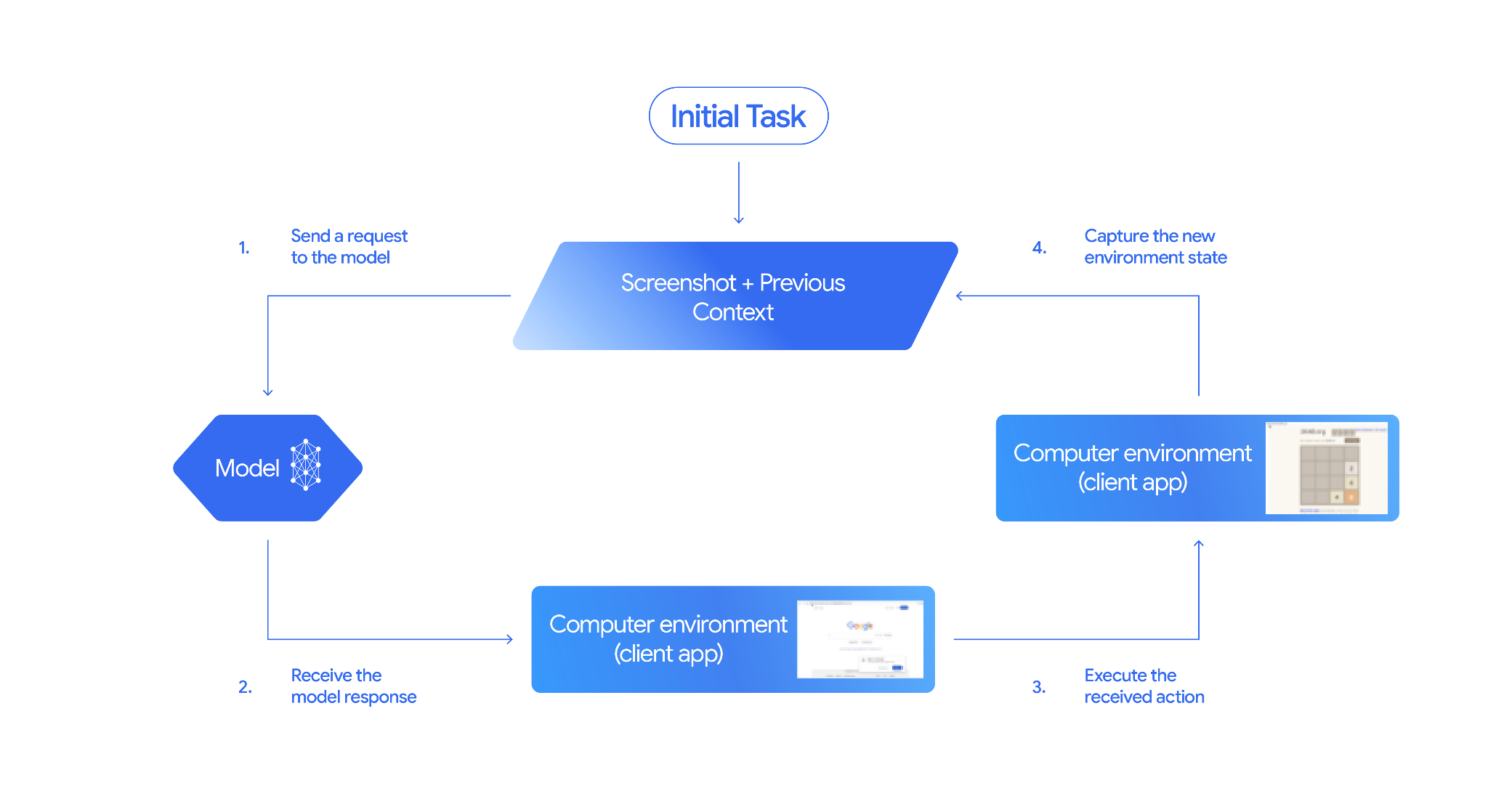
Das Modell für die Computernutzung und die Tool-Interaktionen folgen einem agentischen Schleifenprozess:
Anfrage an das Modell senden
- Fügen Sie Ihrer API-Anfrage das Modell und Tool für die Computernutzung und optional weitere Tools hinzu.
- Geben Sie die Nutzeranfrage und einen Screenshot, der den aktuellen Zustand der Benutzeroberfläche darstellt, als Prompt für das Modell und das Tool für die Computernutzung ein.
Modellantwort erhalten
- Das Modell analysiert die Nutzeranfrage und den Screenshot und generiert eine Antwort mit einer vorgeschlagenen
function_call, die eine UI-Aktion darstellt (z. B. „Klicken Sie auf die Koordinate (x,y)“ oder „Geben Sie ‚Text‘ ein“). Eine Liste aller Aktionen, die Sie mit dem Modell verwenden können, finden Sie unter Unterstützte Aktionen. - Die API-Antwort kann auch ein
safety_responsevon einem internen Sicherheitssystem enthalten, das die vorgeschlagene Aktion des Modells überprüft hat. Durchsafety_responsewird die Aktion so klassifiziert:- Regulär oder zulässig:Die Aktion gilt als sicher. Das kann auch dadurch dargestellt werden, dass kein
safety_responsevorhanden ist. - Bestätigung erforderlich:Das Modell ist dabei, eine möglicherweise riskante Aktion auszuführen, z. B. auf ein Banner zum Akzeptieren von Cookies zu klicken.
- Regulär oder zulässig:Die Aktion gilt als sicher. Das kann auch dadurch dargestellt werden, dass kein
- Das Modell analysiert die Nutzeranfrage und den Screenshot und generiert eine Antwort mit einer vorgeschlagenen
Erhaltene Aktion ausführen
- Ihr clientseitiger Code empfängt die
function_callund alle zugehörigensafety_response. - Wenn
safety_response„regular“ oder „allowed“ angibt (oder keinsafety_responsevorhanden ist), kann Ihr clientseitiger Code die angegebenefunction_callin Ihrer Zielumgebung (z. B. einem Webbrowser) ausführen. - Wenn das
safety_responseeine erforderliche Bestätigung angibt, muss Ihre Anwendung den Endnutzer zur Bestätigung auffordern, bevor diefunction_callausgeführt wird. Wenn der Nutzer bestätigt, fahre mit der Ausführung der Aktion fort. Wenn der Nutzer die Ausführung ablehnt, führe die Aktion nicht aus.
- Ihr clientseitiger Code empfängt die
Neuen Umgebungsstatus erfassen
- Wenn die Aktion ausgeführt wurde, erstellt Ihr Client einen neuen Screenshot der Benutzeroberfläche und der aktuellen URL, die als Teil eines
function_responsean das Modell und das Tool für die Computernutzung zurückgesendet werden. - Wenn eine Aktion vom Sicherheitssystem blockiert oder die Bestätigung durch den Nutzer verweigert wurde, kann Ihre Anwendung eine andere Art von Feedback an das Modell senden oder die Interaktion beenden.
- Wenn die Aktion ausgeführt wurde, erstellt Ihr Client einen neuen Screenshot der Benutzeroberfläche und der aktuellen URL, die als Teil eines
Eine neue Anfrage wird mit dem aktualisierten Status an das Modell gesendet. Der Vorgang wird ab Schritt 2 wiederholt. Das Modell und das Tool für die Computernutzung verwenden den neuen Screenshot (falls angegeben) und das laufende Ziel, um die nächste Aktion vorzuschlagen. Die Schleife wird fortgesetzt, bis die Aufgabe abgeschlossen ist, ein Fehler auftritt oder der Prozess beendet wird (z. B. wenn eine Antwort durch Sicherheitsfilter blockiert wird oder der Nutzer den Prozess beendet).
Das folgende Diagramm veranschaulicht die Funktionsweise des Modells und Tools zur Computernutzung:
Modell und Tool für die Computernutzung aktivieren
Wenn Sie das Modell und Tool für die Computernutzung aktivieren möchten, verwenden Sie gemini-3-flash-preview oder gemini-3.5-flash als Modell und fügen Sie das Modell und Tool für die Computernutzung Ihrer Liste der aktivierten Tools hinzu:
Python
from google import genai from google.genai import types from google.genai.types import Content, Part, FunctionResponse client = genai.Client() # Add Computer Use model and tool to the list of tools generate_content_config = genai.types.GenerateContentConfig( tools=[ types.Tool( computer_use=types.ComputerUse( environment=types.Environment.ENVIRONMENT_BROWSER, ) ), ] ) # Example request using the Computer Use model and tool contents = [ Content( role="user", parts=[ Part(text="Go to google.com and search for 'weather in New York'"), ], ) ] response = client.models.generate_content( model="gemini-3-flash-preview", contents=contents, config=generate_content_config, )
Anfrage senden
Nachdem Sie das Modell und das Tool für die Computernutzung konfiguriert haben, senden Sie einen Prompt an das Modell, der das Ziel des Nutzers und einen ersten Screenshot der Benutzeroberfläche enthält.
Optional können Sie auch Folgendes hinzufügen:
- Ausgeschlossene Aktionen:Wenn es Aktionen aus der Liste der unterstützten UI-Aktionen gibt, die das Modell nicht ausführen soll, geben Sie diese Aktionen in
excluded_predefined_functionsan. - Benutzerdefinierte Funktionen:Zusätzlich zum Modell und Tool zur Computernutzung können Sie benutzerdefinierte Funktionen einbeziehen.
Im folgenden Beispielcode werden das Modell und das Tool für die Computernutzung aktiviert und die Anfrage an das Modell gesendet:
Python
from google import genai from google.genai import types from google.genai.types import Content, Part client = genai.Client() # Specify predefined functions to exclude (optional) excluded_functions = ["drag_and_drop"] # Configuration for the Computer Use model and tool with browser environment generate_content_config = genai.types.GenerateContentConfig( tools=[ # 1. Computer Use tool with browser environment types.Tool( computer_use=types.ComputerUse( environment=types.Environment.ENVIRONMENT_BROWSER, # Optional: Exclude specific predefined functions excluded_predefined_functions=excluded_functions ) ), # 2. Optional: Custom user-defined functions (need to defined above) # types.Tool( # function_declarations=custom_functions # ) ], ) # Create the content with user message contents: list[Content] = [ Content( role="user", parts=[ Part(text="Search for highly rated smart fridges with touchscreen, 2 doors, around 25 cu ft, priced below 4000 dollars on Google Shopping. Create a bulleted list of the 3 cheapest options in the format of name, description, price in an easy-to-read layout."), # Optional: include a screenshot of the initial state # Part.from_bytes( # data=screenshot_image_bytes, # mime_type='image/png', # ), ], ) ] # Generate content with the configured settings response = client.models.generate_content( model='gemini-3-flash-preview', contents=contents, config=generate_content_config, ) # Print the response output print(response.text)
Sie können auch benutzerdefinierte Funktionen einfügen, um die Funktionalität des Modells zu erweitern. Weitere Informationen dazu, wie Sie die Computernutzung für mobile Anwendungsfälle konfigurieren können, indem Sie Aktionen wie open_app, long_press_at und go_home hinzufügen und gleichzeitig browserspezifische Aktionen ausschließen, finden Sie unter Computernutzungsmodell und ‑tool für mobile Anwendungsfälle verwenden.
Antworten erhalten
Das Modell antwortet mit einem oder mehreren FunctionCalls, wenn es feststellt, dass zur Erledigung der Aufgabe UI-Aktionen oder benutzerdefinierte Funktionen erforderlich sind. Ihr Anwendungscode muss diese Aktionen parsen, ausführen und die Ergebnisse erfassen. Das Modell und das Tool für die Computernutzung unterstützen parallele Funktionsaufrufe. Das bedeutet, dass das Modell in einem einzigen Zug mehrere unabhängige Aktionen zurückgeben kann.
{
"content": {
"parts": [
{
"text": "I will type the search query into the search bar. The search bar is in the center of the page."
},
{
"function_call": {
"name": "type_text_at",
"args": {
"x": 371,
"y": 470,
"text": "highly rated smart fridges with touchscreen, 2 doors, around 25 cu ft, priced below 4000 dollars on Google Shopping",
"press_enter": true
}
}
}
]
}
}
Je nach Aktion kann die API-Antwort auch ein safety_response zurückgeben:
{
"content": {
"parts": [
{
"text": "I have evaluated step 2. It seems Google detected unusual traffic and is asking me to verify I'm not a robot. I need to click the 'I'm not a robot' checkbox located near the top left (y=98, x=95)."
},
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "I have encountered a CAPTCHA challenge that requires interaction. I need you to complete the challenge by clicking the 'I'm not a robot' checkbox and any subsequent verification steps.",
"decision": "require_confirmation"
}
}
}
}
]
}
}
Empfangene Aktionen ausführen
Nachdem Sie eine Antwort erhalten haben, muss das Modell die empfangenen Aktionen ausführen.
Der folgende Code extrahiert Funktionsaufrufe aus einer Gemini-Antwort, konvertiert Koordinaten aus dem Bereich 0–1000 in tatsächliche Pixel, führt Browseraktionen mit Playwright aus und gibt den Erfolgs- oder Fehlerstatus für jede Aktion zurück:
import time
from typing import Any, List, Tuple
def normalize_x(x: int, screen_width: int) -> int:
"""Convert normalized x coordinate (0-1000) to actual pixel coordinate."""
return int(x / 1000 * screen_width)
def normalize_y(y: int, screen_height: int) -> int:
"""Convert normalized y coordinate (0-1000) to actual pixel coordinate."""
return int(y / 1000 * screen_height)
def execute_function_calls(response, page, screen_width: int, screen_height: int) -> List[Tuple[str, Any]]:
"""
Extract and execute function calls from Gemini response.
Args:
response: Gemini API response object
page: Playwright page object
screen_width: Screen width in pixels
screen_height: Screen height in pixels
Returns:
List of tuples: [(function_name, result), ...]
"""
# Extract function calls and thoughts from the model's response
candidate = response.candidates[0]
function_calls = []
thoughts = []
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_calls.append(part.function_call)
elif hasattr(part, 'text') and part.text:
thoughts.append(part.text)
if thoughts:
print(f"Model Reasoning: {' '.join(thoughts)}")
# Execute each function call
results = []
for function_call in function_calls:
result = None
try:
if function_call.name == "open_web_browser":
print("Executing open_web_browser")
# Browser is already open via Playwright, so this is a no-op
result = "success"
elif function_call.name == "click_at":
actual_x = normalize_x(function_call.args["x"], screen_width)
actual_y = normalize_y(function_call.args["y"], screen_height)
print(f"Executing click_at: ({actual_x}, {actual_y})")
page.mouse.click(actual_x, actual_y)
result = "success"
elif function_call.name == "type_text_at":
actual_x = normalize_x(function_call.args["x"], screen_width)
actual_y = normalize_y(function_call.args["y"], screen_height)
text = function_call.args["text"]
press_enter = function_call.args.get("press_enter", False)
clear_before_typing = function_call.args.get("clear_before_typing", True)
print(f"Executing type_text_at: ({actual_x}, {actual_y}) text='{text}'")
# Click at the specified location
page.mouse.click(actual_x, actual_y)
time.sleep(0.1)
# Clear existing text if requested
if clear_before_typing:
page.keyboard.press("Control+A")
page.keyboard.press("Backspace")
# Type the text
page.keyboard.type(text)
# Press enter if requested
if press_enter:
page.keyboard.press("Enter")
result = "success"
else:
# For any functions not parsed above
print(f"Unrecognized function: {function_call.name}")
result = "unknown_function"
except Exception as e:
print(f"Error executing {function_call.name}: {e}")
result = f"error: {str(e)}"
results.append((function_call.name, result))
return results
Wenn der zurückgegebene safety_decision require_confirmation ist, müssen Sie den Nutzer um Bestätigung bitten, bevor Sie mit der Ausführung der Aktion fortfahren. Gemäß den Nutzungsbedingungen dürfen Sie Anfragen zur Bestätigung durch einen Menschen nicht umgehen.
Im Folgenden wird dem vorherigen Code eine Sicherheitslogik hinzugefügt:
import termcolor
def get_safety_confirmation(safety_decision):
"""Prompt user for confirmation when safety check is triggered."""
termcolor.cprint("Safety service requires explicit confirmation!", color="red")
print(safety_decision["explanation"])
decision = ""
while decision.lower() not in ("y", "n", "ye", "yes", "no"):
decision = input("Do you wish to proceed? [Y]es/[N]o\n")
if decision.lower() in ("n", "no"):
return "TERMINATE"
return "CONTINUE"
def execute_function_calls(response, page, screen_width: int, screen_height: int):
# ... Extract function calls from response ...
for function_call in function_calls:
extra_fr_fields = {}
# Check for safety decision
if 'safety_decision' in function_call.args:
decision = get_safety_confirmation(function_call.args['safety_decision'])
if decision == "TERMINATE":
print("Terminating agent loop")
break
extra_fr_fields["safety_acknowledgement"] = "true"
# ... Execute function call and append to results ...
Neuen Zustand erfassen
Senden Sie nach der Ausführung der Aktionen das Ergebnis der Funktionsausführung zurück an das Modell, damit es diese Informationen zum Generieren der nächsten Aktion verwenden kann. Wenn mehrere Aktionen (parallele Aufrufe) ausgeführt wurden, müssen Sie im nächsten Nutzerzug für jede Aktion ein FunctionResponse senden. Bei benutzerdefinierten Funktionen sollte FunctionResponse den Rückgabewert der ausgeführten Funktion enthalten.
function_response_parts = []
for name, result in results:
# Take screenshot after each action
screenshot = page.screenshot()
current_url = page.url
function_response_parts.append(
FunctionResponse(
name=name,
response={"url": current_url}, # Include safety acknowledgement
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png", data=screenshot
)
)
]
)
)
# Create the user feedback content with all responses
user_feedback_content = Content(
role="user",
parts=function_response_parts
)
# Append this feedback to the 'contents' history list for the next API call
contents.append(user_feedback_content)
Agent-Schleife erstellen
Fassen Sie die vorherigen Schritte in einer Schleife zusammen, um mehrstufige Interaktionen zu ermöglichen. Die Schleife muss parallele Funktionsaufrufe verarbeiten. Denken Sie daran, den Unterhaltungsverlauf (Inhaltsarray) richtig zu verwalten, indem Sie sowohl Modellantworten als auch Ihre Funktionsantworten anhängen.
Python
from google import genai from google.genai.types import Content, Part from playwright.sync_api import sync_playwright def has_function_calls(response): """Check if response contains any function calls.""" candidate = response.candidates[0] return any(hasattr(part, 'function_call') and part.function_call for part in candidate.content.parts) def main(): client = genai.Client() # ... (config setup from "Send a request to model" section) ... with sync_playwright() as p: browser = p.chromium.launch(headless=False) page = browser.new_page() page.goto("https://www.google.com") screen_width, screen_height = 1920, 1080 # ... (initial contents setup from "Send a request to model" section) ... # Agent loop: iterate until model provides final answer for iteration in range(10): print(f"\nIteration {iteration + 1}\n") # 1. Send request to model (see "Send a request to model" section) response = client.models.generate_content( model='gemini-3-flash-preview', contents=contents, config=generate_content_config, ) contents.append(response.candidates[0].content) # 2. Check if done - no function calls means final answer if not has_function_calls(response): print(f"FINAL RESPONSE:\n{response.text}") break # 3. Execute actions (see "Execute the received actions" section) results = execute_function_calls(response, page, screen_width, screen_height) time.sleep(1) # 4. Capture state and create feedback (see "Capture the New State" section) contents.append(create_feedback(results, page)) input("\nPress Enter to close browser...") browser.close() if __name__ == "__main__": main()
Gemini 3.5 Flash oder höher und Anwendungsfälle für Mobilgeräte oder Computer
Das Modell und das Tool für die Computernutzung unterstützen die Festlegung von Umgebungen für Mobilgeräte (ENVIRONMENT_MOBILE), Computer (ENVIRONMENT_DESKTOP) oder Browser (ENVIRONMENT_BROWSER). Der Standardwert ist ENVIRONMENT_BROWSER.
Die folgenden Beispiele zeigen, wie Sie die Ausführungsumgebung für das Modell und das Tool zur Computernutzung mit Gemini 3.5 Flash oder höher konfigurieren.
REST API
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID: Ihre Projekt-ID.
HTTP-Methode und URL:
POST https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/global/publishers/google/models/gemini-3.5-flash:generateContent
JSON-Text anfordern:
{
"contents": [
{
"role": "user",
"parts": {
"text": "find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th. start by navigating directly to flights.google.com"
}
}
],
"generation_config": {
"candidateCount": 1
},
"tools": [
{
"computer_use": {
"environment": "ENVIRONMENT_BROWSER"
}
}
]
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten einen erfolgreichen Statuscode (2xx) und eine leere Antwort als Ausgabe erhalten.
Python
Für das folgende Beispiel ist python-genai Version 2.7.0 oder höher erforderlich.
from google import genai
from google.genai.types import (
Part,
GenerateContentConfig,
Content,
Tool,
ComputerUse,
Environment,
ThinkingConfig,
)
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=[
Content(
role="user",
parts=[
Part(text="find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th"),
],
)
],
config=GenerateContentConfig(
temperature=1,
top_p=0.95,
top_k=40,
max_output_tokens=8192,
tools=[
Tool(
computer_use=ComputerUse(
environment=Environment.ENVIRONMENT_MOBILE
),
),
],
thinking_config=ThinkingConfig(
include_thoughts=True
),
)
)
Gemini 3 Flash und mobile Nutzung
Im folgenden Beispiel für Gemini 3 Flash wird gezeigt, wie Sie benutzerdefinierte Funktionen (z. B. open_app, long_press_at und go_home) definieren, sie mit dem integrierten Tool zur Computernutzung von Gemini kombinieren und unnötige browserspezifische Funktionen ausschließen. Durch die Registrierung dieser benutzerdefinierten Funktionen kann das Modell sie zusammen mit Standard-UI-Aktionen intelligent aufrufen, um Aufgaben in Nicht-Browser-Umgebungen auszuführen.
from typing import Optional, Dict, Any
from google import genai
from google.genai import types
from google.genai.types import Content, Part
client = genai.Client()
def open_app(app_name: str, intent: Optional[str] = None) -> Dict[str, Any]:
"""Opens an app by name.
Args:
app_name: Name of the app to open (any string).
intent: Optional deep-link or action to pass when launching, if the app supports it.
Returns:
JSON payload acknowledging the request (app name and optional intent).
"""
return {"status": "requested_open", "app_name": app_name, "intent": intent}
def long_press_at(x: int, y: int, duration_ms: int = 500) -> Dict[str, int]:
"""Long-press at a specific screen coordinate.
Args:
x: X coordinate (absolute), scaled to the device screen width (pixels).
y: Y coordinate (absolute), scaled to the device screen height (pixels).
duration_ms: Press duration in milliseconds. Defaults to 500.
Returns:
Object with the coordinates pressed and the duration used.
"""
return {"x": x, "y": y, "duration_ms": duration_ms}
def go_home() -> Dict[str, str]:
"""Navigates to the device home screen.
Returns:
A small acknowledgment payload.
"""
return {"status": "home_requested"}
# Build function declarations
CUSTOM_FUNCTION_DECLARATIONS = [
types.FunctionDeclaration.from_callable(client=client, callable=open_app),
types.FunctionDeclaration.from_callable(client=client, callable=long_press_at),
types.FunctionDeclaration.from_callable(client=client, callable=go_home),
]
# Exclude browser functions
EXCLUDED_PREDEFINED_FUNCTIONS = [
"open_web_browser",
"search",
"navigate",
"hover_at",
"scroll_document",
"go_forward",
"key_combination",
"drag_and_drop",
]
# Utility function to construct a GenerateContentConfig
def make_generate_content_config() -> genai.types.GenerateContentConfig:
"""Return a fixed GenerateContentConfig with Computer Use + custom functions."""
return genai.types.GenerateContentConfig(
tools=[
types.Tool(
computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER,
excluded_predefined_functions=EXCLUDED_PREDEFINED_FUNCTIONS,
)
),
types.Tool(function_declarations=CUSTOM_FUNCTION_DECLARATIONS),
]
)
# Create the content with user message
contents: list[Content] = [
Content(
role="user",
parts=[
# text instruction
Part(text="Open Chrome, then long-press at 200,400."),
# optional screenshot attachment
Part.from_bytes(
data=screenshot_image_bytes,
mime_type="image/png",
),
],
)
]
# Build your fixed config (from helper)
config = make_generate_content_config()
# Generate content with the configured settings
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=contents,
config=generate_content_config,
)
print(response)
Unterstützte Aktionen
Mit dem Modell und Tool „Computer Use“ kann das Modell die folgenden Aktionen mit einer FunctionCall anfordern. In Ihrem clientseitigen Code muss die Ausführungslogik für diese Aktionen implementiert werden. Beispiele finden Sie in der Referenzimplementierung. In der folgenden Tabelle sind die unterstützten Aktionen für die Browserumgebung aufgeführt.
Gemini 3 Flash und Gemini 3.5 Flash haben unterschiedliche FunctionCall-Namenssätze.
Gemini 3.5 Flash
| Befehlsname | Beschreibung | Argumente (im Funktionsaufruf) |
|---|---|---|
| click | Linksklicks an der Koordinate. |
y: int (0–999)x: int
(0–999)intent: str
|
| double_click | Doppelklicks an der Koordinate. |
y: int (0–999)x: int
(0–999)intent: str
|
| triple_click | Dreifachklicks an der Koordinate. |
y: int (0–999)x: int
(0–999)intent: str
|
| middle_click | Mit der mittleren Maustaste auf die Koordinate klicken. |
y: int (0–999)x: int
(0–999)intent: str
|
| right_click | Rechtsklicks an der Koordinate. |
y: int (0–999)x: int
(0–999)intent: str
|
| mouse_down | Drückt die Maustaste an der Koordinate und hält sie gedrückt. |
y: int (0–999)x: int
(0–999)intent: str
|
| mouse_up | Lässt die Maustaste an der Koordinate los. |
y: int (0–999)x: int
(0–999)intent: str
|
| move | Bewegen Sie den Cursor an die angegebene Position. |
y: int (0–999)x: int
(0–999)intent: str
|
| type | Text eingeben |
text: strintent:
strpress_enter: bool (optional, Standardwert: „false“)
|
| drag_and_drop | Zieht das Element von „start_y“ und „start_x“ nach „end_y“ und „end_x“. |
start_y: int (0–999)start_x: int
(0–999)end_y: int (0–999)end_x:
int (0–999)intent: str
|
| wait | Warten Sie die angegebene Anzahl von Sekunden. |
intent: strseconds: int (optional, Standardwert: 1)
|
| press_key | Drückt die angegebene Taste und lässt sie wieder los. | key: strintent: str |
| key_down | Drückt und hält die angegebene Taste. | key: strintent: str |
| key_up | Gibt den angegebenen Schlüssel frei. | key: strintent: str |
| Tastenkürzel | Drückt die angegebene Tastenkombination. | keys: List[str]intent: str |
| take_screenshot | Gibt einen Screenshot des aktuellen Bildschirms zurück. | intent: str |
| scroll | Scrollt an einer Koordinate um eine bestimmte Anzahl von Pixeln nach oben, unten, links oder rechts. |
y: int (0–999)x: int
(0–999)direction: str („up“, „down“, „left“,
„right“)intent:
strmagnitude_in_pixels: int (0–999, optional,
Standardwert: 300)
|
| go_back | Navigiert zurück zur vorherigen Webseite im Browserverlauf. | intent: str |
| navigate | Navigiert direkt zu einer angegebenen URL. | url: strintent: str |
| go_forward | Navigiert vorwärts zur nächsten Webseite im Browserverlauf. | intent: str |
Gemini 3 Flash
| Befehlsname | Beschreibung | Argumente (im Funktionsaufruf) | Beispiel für Funktionsaufruf |
|---|---|---|---|
| open_web_browser | Öffnet den Webbrowser. | Kein | {"name": "open_web_browser", "args": {}} |
| wait_5_seconds | Pausiert die Ausführung für 5 Sekunden, damit dynamische Inhalte geladen oder Animationen abgeschlossen werden können. | Kein | {"name": "wait_5_seconds", "args": {}} |
| go_back | Navigiert zur vorherigen Seite im Browserverlauf. | Kein | {"name": "go_back", "args": {}} |
| go_forward | Navigiert zur nächsten Seite im Browserverlauf. | Kein | {"name": "go_forward", "args": {}} |
| search | Ruft die Startseite der Standardsuchmaschine auf (z. B. Google). Nützlich, um eine neue Suchaufgabe zu starten. | Kein | {"name": "search", "args": {}} |
| navigate | Leitet den Browser direkt zur angegebenen URL weiter. | url: str |
{"name": "navigate", "args": {"url": "https://www.wikipedia.org"}}
|
| click_at | Klicks an einer bestimmten Koordinate auf der Webseite. Die x- und y-Werte basieren auf einem 1.000 × 1.000-Raster und werden an die Bildschirmabmessungen angepasst. | y: int (0–999), x: int (0–999) |
{"name": "click_at", "args": {"y": 300, "x": 500}}
|
| hover_at | 521963309 Bewegt den Mauszeiger zu einer bestimmten Koordinate auf der Webseite. Nützlich zum Aufrufen von Untermenüs. x und y basieren auf einem 1.000 × 1.000-Raster. | y: int (0–999) x: int (0–999) |
{"name": "hover_at", "args": {"y": 150, "x": 250}}
|
| type_text_at | Gibt Text an einer bestimmten Koordinate ein. Standardmäßig wird das Feld zuerst gelöscht und nach der Eingabe die Eingabetaste gedrückt. Diese Einstellungen können jedoch deaktiviert werden. „x“ und „y“ basieren auf einem 1000 × 1000-Raster. |
y: int (0–999), x: int (0–999),
text: str, press_enter: bool (optional, Standardwert: True), clear_before_typing: bool (optional, Standardwert: True)
|
{"name": "type_text_at", "args": {"y": 250, "x": 400,
"text": "search query", "press_enter": false}}
|
| key_combination | Drückt Tastaturtasten oder ‑kombinationen wie „Strg+C“ oder „Eingabe“. Nützlich zum Auslösen von Aktionen (z. B. zum Senden eines Formulars mit der Eingabetaste) oder für Zwischenablagevorgänge. |
keys: str (z. B. „enter“, „control+c“). Eine vollständige Liste der zulässigen Schlüssel finden Sie in der API-Referenz.
|
{"name": "key_combination", "args": {"keys":
"Control+A"}}
|
| scroll_document | Scrollt die gesamte Webseite nach „oben“, „unten“, „links“ oder „rechts“. | direction: str („up“, „down“, „left“ oder „right“) |
{"name": "scroll_document", "args": {"direction": "down"}}
|
| scroll_at | Scrollt ein bestimmtes Element oder einen bestimmten Bereich an der Koordinate (x, y) in der angegebenen Richtung um einen bestimmten Betrag. Koordinaten und Magnitude (Standardwert: 800) basieren auf einem 1.000 × 1.000-Raster. |
y: int (0–999), x: int (0–999),
direction: str („up“, „down“, „left“, „right“),
magnitude: int (0–999, optional, Standardwert: 800)
|
{"name": "scroll_at", "args": {"y": 500, "x": 500,
"direction": "down", "magnitude": 400}}
|
| drag_and_drop | Zieht ein Element von einer Startkoordinate (x, y) und legt es an einer Zielkoordinate (destination_x, destination_y) ab. Alle Koordinaten basieren auf einem 1.000 × 1.000-Raster. |
y: int (0–999), x: int (0–999),
destination_y: int (0–999),
destination_x: int (0–999)
|
{"name": "drag_and_drop", "args": {"y": 100, "x": 100,
"destination_y": 500, "destination_x": 500}}
|
Gemini 3.5 Flash: Je nach ausgewählter Umgebung haben Sie Zugriff auf verschiedene Gruppen von Funktionsaufrufen:
Mobile Umgebung
| Befehlsname | Beschreibung | Argumente (im Funktionsaufruf) |
|---|---|---|
| open_app | Öffnet eine Anwendung anhand ihres Namens. | intent: str |
| Klick | Linksklicks an der Koordinate. |
y: int (0–999) x: int (0–999) intent: str |
| list_apps | Listet die auf dem Gerät verfügbaren Anwendungen auf und gibt ihre Namen und Paketnamen zurück. | intent: str |
| wait | Wartet die angegebene Anzahl von Sekunden. |
intent: str seconds: int(optional, Standardwert: 1) |
| go_back | Navigiert zurück zur vorherigen Webseite im Browserverlauf. | intent: str |
| Typ | Text eingeben |
text: str intent: str press_enter: bool(optional, Standardwert: false) |
| drag_and_drop | Zieht das Element von „start_y“ und „start_x“ nach „end_y“ und „end_x“. |
start_y: int (0–999) start_x: int (0–999) end_y: int (0–999) end_x: int (0–999) intent: str |
| long_press | Führt ein langes Drücken an einer bestimmten Y-Koordinate (0–999) und X-Koordinate (0–999) auf dem Bildschirm aus. |
y: int (0–999) x: int (0–999) intent: str seconds: int (optional, Standardwert: 2) |
| press_key | Drückt die angegebene Taste und lässt sie wieder los. |
key: str intent: str |
| take_screenshot | Gibt einen Screenshot des aktuellen Bildschirms zurück. | intent: str |
Desktopumgebung
| Befehlsname | Beschreibung | Argumente (im Funktionsaufruf) |
|---|---|---|
| Klick | Linksklicks an der Koordinate. |
y: int (0–999) x: int (0–999) intent: str |
| double_click | Doppelklicks an der Koordinate. |
y: int (0–999) x: int (0–999) intent: str |
| triple_click | Dreifachklicks an der Koordinate. |
y: int (0–999) x: int (0–999) intent: str |
| middle_click | Mit der mittleren Maustaste auf die Koordinate klicken. |
y: int (0–999) x: int (0–999) intent: str |
| right_click | Rechtsklicks an der Koordinate. |
y: int (0–999) x: int (0–999) intent: str |
| mouse_down | Drückt die Maustaste an der Koordinate und hält sie gedrückt. |
y: int (0–999) x: int (0–999) intent: str |
| mouse_up | Lässt die Maustaste an der Koordinate los. |
y: int (0–999) x: int (0–999) intent: str |
| move | Bewegen Sie den Cursor an die angegebene Position. |
y: int (0–999) x: int (0–999) intent: str |
| Typ | Text eingeben |
text: str intent: str press_enter: bool(optional, Standardwert: false) |
| drag_and_drop | Zieht das Element von „start_y“ und „start_x“ nach „end_y“ und „end_x“. |
start_y: int (0–999) start_x: int (0–999) end_y: int (0–999) end_x: int (0–999) intent: str |
| wait | Warten Sie die angegebene Anzahl von Sekunden. |
intent: str seconds: int(Optional, default 1) |
| press_key | Drückt die angegebene Taste und lässt sie wieder los. |
key: str intent: str |
| key_down | Drückt und hält die angegebene Taste. |
key: str intent: str |
| key_up | Gibt den angegebenen Schlüssel frei. |
key: str intent: str |
| Tastenkombination | Drückt die angegebene Tastenkombination. |
keys: List[str] intent: str |
| take_screenshot | Gibt einen Screenshot des aktuellen Bildschirms zurück. | intent: str |
| scroll | Scrollt an einer Koordinate um eine bestimmte Pixelanzahl nach oben, unten, links oder rechts. |
y: int (0–999) x: int (0–999) direction: str ("up", "down", "left", "right") intent: str magnitude_in_pixels: int (0–999, Optional, default 300) |
Sicherheit
In diesem Abschnitt werden die Sicherheitsmaßnahmen beschrieben, die das Modell und das Tool zur Computernutzung implementiert haben, um die Nutzerkontrolle und die Sicherheit zu verbessern. Außerdem werden Best Practices beschrieben, mit denen potenzielle neue Risiken, die durch das Tool entstehen könnten, minimiert werden können.
Sicherheitsentscheidung bestätigen
Je nach Aktion kann die Antwort des Modells und Tools zur Computernutzung eine safety_decision von einem internen Sicherheitssystem enthalten. Mit dieser Entscheidung wird die vom Tool vorgeschlagene Aktion zur Sicherheit bestätigt.
{
"content": {
"parts": [
{
"text": "I have evaluated step 2. It seems Google detected unusual traffic and is asking me to verify I'm not a robot. I need to click the 'I'm not a robot' checkbox located near the top left (y=98, x=95)."
},
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "I have encountered a CAPTCHA challenge that requires interaction. I need you to complete the challenge by clicking the 'I'm not a robot' checkbox and any subsequent verification steps.",
"decision": "require_confirmation"
}
}
}
}
]
}
}
Wenn safety_decision gleich require_confirmation ist, müssen Sie den Endnutzer um Bestätigung bitten, bevor Sie mit der Ausführung der Aktion fortfahren.
Im folgenden Codebeispiel wird der Nutzer vor der Ausführung der Aktion um Bestätigung gebeten. Wenn der Nutzer die Aktion nicht bestätigt, wird die Schleife beendet. Wenn der Nutzer die Aktion bestätigt, wird sie ausgeführt und das Feld safety_acknowledgement wird als True markiert.
import termcolor
def get_safety_confirmation(safety_decision):
"""Prompt user for confirmation when safety check is triggered."""
termcolor.cprint("Safety service requires explicit confirmation!", color="red")
print(safety_decision["explanation"])
decision = ""
while decision.lower() not in ("y", "n", "ye", "yes", "no"):
decision = input("Do you wish to proceed? [Y]es/[N]o\n")
if decision.lower() in ("n", "no"):
return "TERMINATE"
return "CONTINUE"
def execute_function_calls(response, page, screen_width: int, screen_height: int):
# ... Extract function calls from response ...
for function_call in function_calls:
extra_fr_fields = {}
# Check for safety decision
if 'safety_decision' in function_call.args:
decision = get_safety_confirmation(function_call.args['safety_decision'])
if decision == "TERMINATE":
print("Terminating agent loop")
break
extra_fr_fields["safety_acknowledgement"] = "true" # Safety acknowledgement
# ... Execute function call and append to results ...
Wenn der Nutzer die Bestätigung vornimmt, müssen Sie die Sicherheitsbestätigung in Ihre FunctionResponse aufnehmen.
function_response_parts.append(
FunctionResponse(
name=name,
response={"url": current_url,
**extra_fr_fields}, # Include safety acknowledgement
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png", data=screenshot
)
)
]
)
)
Erkennung von Prompt Injection
Das Modell „Computer Use“ und das Tool für Gemini 3.5 Flash oder höher unterstützen einen erweiterten Sicherheitsmechanismus zur Erkennung von Prompt-Injection-Angriffen. Wenn diese Funktion aktiviert ist, wird geprüft, ob ein enthaltener Screenshot das Potenzial für einen Prompt-Injection-Angriff birgt. Sie können diese Funktion in der Modell- und Toolkonfiguration für die Computernutzung festlegen. Der Standardwert ist false.
In den folgenden Beispielen wird gezeigt, wie Sie das Modell „Computer Use“ und die Toolkonfiguration aktivieren, um die Erkennung von Prompt-Injections zu ermöglichen:
REST API
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID: Ihre Projekt-ID.
HTTP-Methode und URL:
POST https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/global/publishers/google/models/gemini-3.5-flash:generateContent
JSON-Text anfordern:
{
"contents": [
{
"role": "user",
"parts": {
"text": "find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th. start by navigating directly to flights.google.com"
}
}
],
"generation_config": {
"candidateCount": 1
},
"tools": [
{
"computer_use": {
"environment": "ENVIRONMENT_BROWSER",
"enable_prompt_injection_detection": true
}
}
]
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten einen erfolgreichen Statuscode (2xx) und eine leere Antwort als Ausgabe erhalten.
Python
Für das folgende Beispiel ist python-genai Version 2.7.0 oder höher erforderlich.
from google import genai
from google.genai.types import (
Part,
GenerateContentConfig,
Content,
Tool,
ComputerUse,
Environment,
ThinkingConfig,
)
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.5-flash",
contents=[
Content(
role="user",
parts=[
Part(text="find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th"),
],
)
],
config=GenerateContentConfig(
temperature=1,
top_p=0.95,
top_k=40,
max_output_tokens=8192,
tools=[
Tool(
computer_use=ComputerUse(
environment=Environment.ENVIRONMENT_MOBILE,
enable_prompt_injection_detection=True
),
),
],
thinking_config=ThinkingConfig(
include_thoughts=True
),
)
)
Best Practices für die Sicherheit
Das Modell und Tool zur Computernutzung ist neu und birgt neue Risiken, die Entwickler beachten sollten:
- Nicht vertrauenswürdige Inhalte und Betrug: Da das Modell versucht, das Ziel des Nutzers zu erreichen, kann es auf nicht vertrauenswürdige Informationsquellen und Anweisungen auf dem Bildschirm zurückgreifen. Wenn das Ziel des Nutzers beispielsweise darin besteht, ein Pixel Smartphone zu kaufen, und das Modell auf einen Betrugsstil „Kostenloses Pixel, wenn Sie an einer Umfrage teilnehmen“ stößt, besteht eine gewisse Wahrscheinlichkeit, dass das Modell die Umfrage ausfüllt.
- Gelegentliche unbeabsichtigte Aktionen:Das Modell kann das Ziel eines Nutzers oder den Inhalt einer Webseite falsch interpretieren und dadurch falsche Aktionen ausführen, z. B. auf die falsche Schaltfläche klicken oder das falsche Formular ausfüllen. Dies kann zu fehlgeschlagenen Aufgaben oder zum Abziehen von Daten führen.
- Richtlinienverstöße:Die Funktionen der API könnten, absichtlich oder unabsichtlich, auf Aktivitäten ausgerichtet sein, die gegen die Nutzungsbedingungen und Richtlinien von Google verstoßen. Dazu gehören Aktionen, die die Integrität eines Systems beeinträchtigen, die Sicherheit gefährden, Sicherheitsmaßnahmen wie CAPTCHAs umgehen oder medizinische Geräte steuern könnten.
Um diese Risiken zu minimieren, sollten Sie die folgenden Sicherheitsmaßnahmen und Best Practices implementieren:
- Human-in-the-Loop (HITL):
- Nutzerbestätigung implementieren:Wenn die Sicherheitsantwort „require_confirmation“ angibt, müssen Sie vor der Ausführung eine Nutzerbestätigung implementieren.
- Benutzerdefinierte Sicherheitshinweise bereitstellen:Zusätzlich zu den integrierten Prüfungen zur Nutzerbestätigung können Entwickler optional eine benutzerdefinierte Systemanweisung hinzufügen, mit der sie ihre eigenen Sicherheitsrichtlinien durchsetzen. Damit können sie bestimmte Modellaktionen blockieren oder eine Nutzerbestätigung anfordern, bevor das Modell bestimmte irreversible Aktionen mit hohem Risiko ausführt. Hier ist ein Beispiel für eine benutzerdefinierte Systemanweisung für die Sicherheit, die Sie bei der Interaktion mit dem Modell einfügen können.
Klicken Sie hier, um ein Beispiel für das Erstellen einer Verbindung aufzurufen.
## **RULE 1: Seek User Confirmation (USER_CONFIRMATION)** This is your first and most important check. If the next required action falls into any of the following categories, you MUST stop immediately, and seek the user's explicit permission. **Procedure for Seeking Confirmation:** * **For Consequential Actions:** Perform all preparatory steps (e.g., navigating, filling out forms, typing a message). You will ask for confirmation **AFTER** all necessary information is entered on the screen, but **BEFORE** you perform the final, irreversible action (e.g., before clicking "Send", "Submit", "Confirm Purchase", "Share"). * **For Prohibited Actions:** If the action is strictly forbidden (e.g., accepting legal terms, solving a CAPTCHA), you must first inform the user about the required action and ask for their confirmation to proceed. **USER_CONFIRMATION Categories:** * **Consent and Agreements:** You are FORBIDDEN from accepting, selecting, or agreeing to any of the following on the user's behalf. You must ask th e user to confirm before performing these actions. * Terms of Service * Privacy Policies * Cookie consent banners * End User License Agreements (EULAs) * Any other legally significant contracts or agreements. * **Robot Detection:** You MUST NEVER attempt to solve or bypass the following. You must ask the user to confirm before performing these actions. * CAPTCHAs (of any kind) * Any other anti-robot or human-verification mechanisms, even if you are capable. * **Financial Transactions:** * Completing any purchase. * Managing or moving money (e.g., transfers, payments). * Purchasing regulated goods or participating in gambling. * **Sending Communications:** * Sending emails. * Sending messages on any platform (e.g., social media, chat apps). * Posting content on social media or forums. * **Accessing or Modifying Sensitive Information:** * Health, financial, or government records (e.g., medical history, tax forms, passport status). * Revealing or modifying sensitive personal identifiers (e.g., SSN, bank account number, credit card number). * **User Data Management:** * Accessing, downloading, or saving files from the web. * Sharing or sending files/data to any third party. * Transferring user data between systems. * **Browser Data Usage:** * Accessing or managing Chrome browsing history, bookmarks, autofill data, or saved passwords. * **Security and Identity:** * Logging into any user account. * Any action that involves misrepresentation or impersonation (e.g., creating a fan account, posting as someone else). * **Insurmountable Obstacles:** If you are technically unable to interact with a user interface element or are stuck in a loop you cannot resolve, ask the user to take over. --- ## **RULE 2: Default Behavior (ACTUATE)** If an action does **NOT** fall under the conditions for `USER_CONFIRMATION`, your default behavior is to **Actuate**. **Actuation Means:** You MUST proactively perform all necessary steps to move the user's request forward. Continue to actuate until you either complete the non-consequential task or encounter a condition defined in Rule 1. * **Example 1:** If asked to send money, you will navigate to the payment portal, enter the recipient's details, and enter the amount. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Send" button. * **Example 2:** If asked to post a message, you will navigate to the site, open the post composition window, and write the full message. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Post" button. After the user has confirmed, remember to get the user's latest screen before continuing to perform actions. # Final Response Guidelines: Write final response to the user in these cases: - User confirmation - When the task is complete or you have enough information to respond to the user
- Sichere Ausführungsumgebung:Führen Sie Ihren Agent in einer sicheren Sandbox-Umgebung aus, um seine potenziellen Auswirkungen zu begrenzen, z. B. in einer Sandbox-VM, einem Container (z. B. Docker) oder einem dedizierten Browserprofil mit eingeschränkten Berechtigungen.
- Eingabebereinigung:Bereinigen Sie alle von Nutzern generierten Texte in Prompts, um das Risiko unbeabsichtigter Anweisungen oder Prompt Injection zu minimieren. Dies ist eine hilfreiche Sicherheitsebene, aber kein Ersatz für eine sichere Ausführungsumgebung.
- Zulassungs- und Sperrlisten:Implementieren Sie Filtermechanismen, um zu steuern, wohin das Modell navigieren und was es tun kann. Eine Sperrliste mit verbotenen Websites ist ein guter Ausgangspunkt, eine restriktivere Zulassungsliste ist noch sicherer.
- Beobachtbarkeit und Protokollierung:Detaillierte Logs für das Debugging, die Prüfung und die Incident Response führen. Ihr Kunde sollte Prompts, Screenshots, vom Modell vorgeschlagene Aktionen (
function_call), Sicherheitsantworten und alle Aktionen protokollieren, die letztendlich vom Kunden ausgeführt werden.
Preise
Das Modell und Tool „Computer Use“ wird zu denselben Preisen wie Gemini abgerechnet und verwendet dieselben Artikelnummern. Wenn Sie die Kosten für das Modell und das Tool für die Computernutzung aufteilen möchten, verwenden Sie benutzerdefinierte Metadatenlabels. Weitere Informationen zur Verwendung benutzerdefinierter Metadatenlabels für das Kostenmonitoring finden Sie unter Benutzerdefinierte Metadatenlabels.