

Tabular Workflow adalah serangkaian pipeline yang terintegrasi, terkelola sepenuhnya, dan skalabel untuk ML end-to-end dengan data berbentuk tabel. Solusi ini memanfaatkan teknologi Google untuk pengembangan model dan menyediakan opsi penyesuaian sesuai kebutuhan Anda.
Manfaat
- Terkelola sepenuhnya: Anda tidak perlu khawatir tentang update, dependensi, dan konflik.
- Mudah diskalakan: Anda tidak perlu merekayasa ulang infrastruktur seiring meningkatnya workload atau set data.
- Dioptimalkan untuk performa: hardware yang tepat akan otomatis dikonfigurasi sesuai kebutuhan alur kerja.
- Terintegrasi secara mendalam: kompatibilitas dengan produk di suite MLOps Gemini Enterprise Agent Platform, seperti Gemini Enterprise Agent Platform Pipelines dan Vertex AI Experiments, memungkinkan Anda menjalankan banyak eksperimen dalam waktu singkat.
Ringkasan Teknis
Setiap alur kerja adalah instance Gemini Enterprise Agent Platform Pipelines yang terkelola.
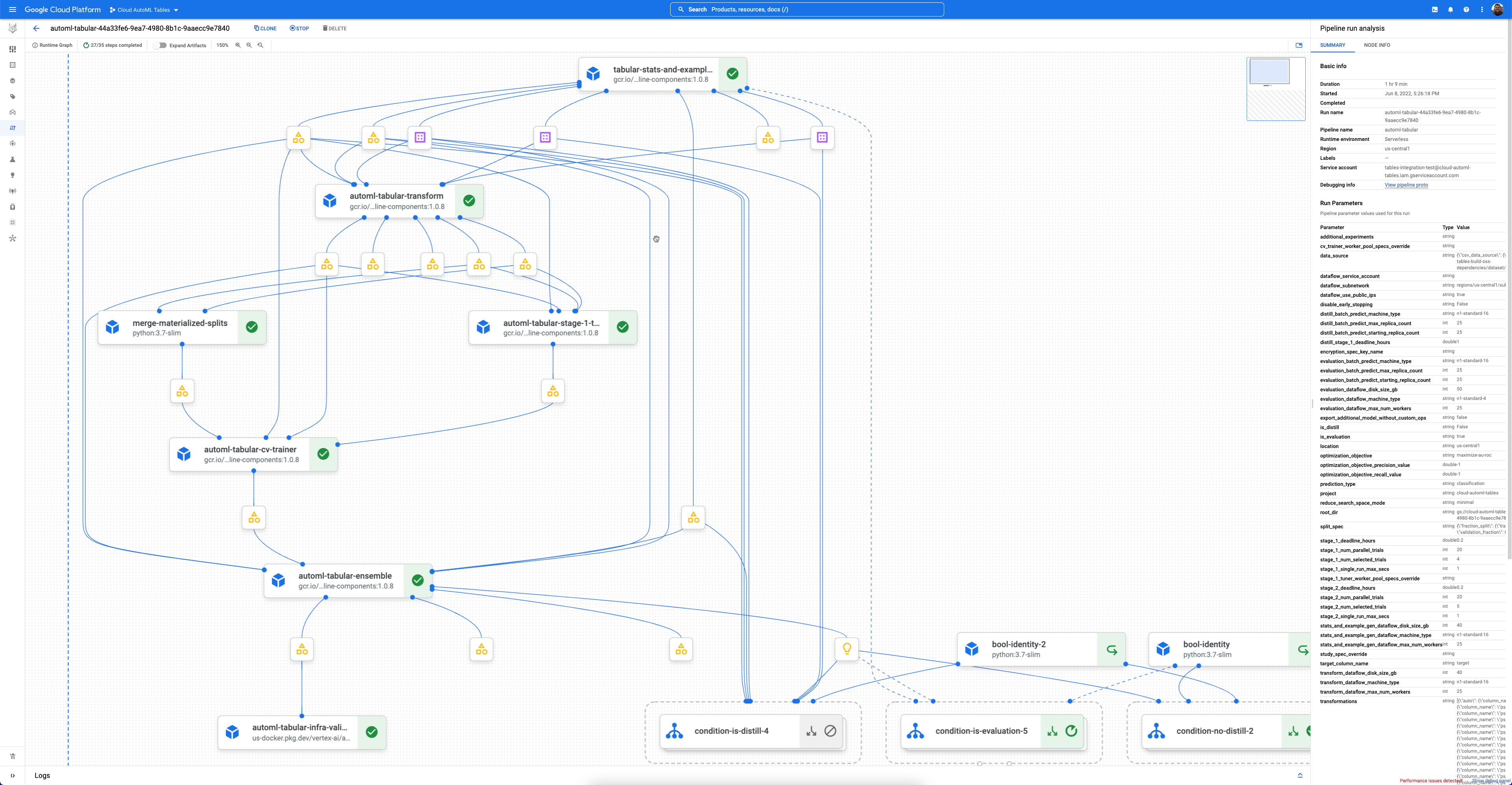
Gemini Enterprise Agent Platform Pipelines adalah layanan serverless yang menjalankan pipeline Kubeflow. Anda dapat menggunakan pipeline untuk mengotomatisasi dan memantau machine learning serta tugas penyiapan data Anda. Setiap langkah di pipeline menjalankan bagian dari alur kerja pipeline. Misalnya, pipeline dapat mencakup langkah-langkah untuk memisahkan data, mengubah jenis data, dan melatih model. Karena langkah tersebut adalah instance komponen pipeline, langkah memiliki input, output, dan image container. Input langkah dapat ditetapkan dari input pipeline atau dapat bergantung pada output langkah lain dalam pipeline ini. Dependensi ini menentukan alur kerja pipeline sebagai directed acyclic graph.
Mulai
Dalam sebagian besar kasus, tentukan dan jalankan pipeline menggunakan Google Cloud Pipeline Components SDK. Kode contoh berikut mengilustrasikan proses ini. Perhatikan bahwa penerapan kode yang sebenarnya mungkin berbeda.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
Untuk contoh colab dan notebook, hubungi sales representative Anda atau isi formulir permintaan.
Pembuatan versi dan pemeliharaan
Tabular Workflow memiliki sistem pembuatan versi yang efektif yang memungkinkan update dan peningkatan berkelanjutan tanpa menyebabkan perubahan yang dapat menyebabkan gangguan pada aplikasi Anda.
Setiap alur kerja dirilis dan diperbarui sebagai bagian dari Google Cloud Pipeline Components SDK. Update dan modifikasi pada alur kerja apa pun dirilis sebagai versi baru dari alur kerja tersebut. Versi sebelumnya dari setiap alur kerja selalu tersedia melalui SDK versi lama. Jika versi SDK disematkan, versi alur kerja juga disematkan.
Alur kerja yang tersedia
Agent Platform menyediakan Tabular Workflow berikut:
| Nama | Jenis | Ketersediaan |
|---|---|---|
| Mesin Transformasi Fitur | Rekayasa Fitur | Pratinjau Publik |
| AutoML End-to-End | Klasifikasi & Regresi | Tersedia Secara Umum |
| Prakiraan | Prakiraan | Pratinjau Publik |
Untuk informasi tambahan dan contoh notebook, hubungi Sales Rep Anda atau isi formulir permintaan.
Mesin Transformasi Fitur
Mesin Transformasi Fitur melakukan pemilihan fitur dan transformasi fitur. Jika pemilihan fitur diaktifkan, Feature Transform Engine akan membuat serangkaian fitur penting yang diberi peringkat. Jika transformasi fitur diaktifkan, Feature Transform Engine akan memproses fitur untuk memastikan bahwa input untuk pelatihan model dan penyajian model konsisten. Feature Transform Engine dapat digunakan sendiri atau bersama dengan salah satu alur kerja pelatihan tabel. Platform ini mendukung framework TensorFlow dan non-TensorFlow.
Untuk informasi selengkapnya, lihat Rekayasa fitur.
Tabular Workflow untuk klasifikasi dan regresi
Tabular Workflow untuk AutoML End-to-End
Tabular Workflow untuk AutoML End-to-End adalah pipeline AutoML lengkap untuk tugas klasifikasi dan regresi. Hal ini mirip dengan AutoML API, tetapi memungkinkan Anda memilih apa yang akan dikontrol dan diotomatisasi. Alih-alih memiliki kontrol untuk seluruh pipeline, Anda memiliki kontrol untuk setiap langkah di pipeline. Kontrol pipeline ini mencakup:
- Pemisahan data
- Rekayasa fitur
- Penelusuran arsitektur
- Pelatihan model
- Ansambel model
- Distilasi model
Manfaat
- Mendukung set data besar berukuran beberapa TB dan memiliki hingga 1.000 kolom.
- Memungkinkan Anda meningkatkan stabilitas dan menurunkan waktu pelatihan dengan membatasi ruang penelusuran jenis arsitektur atau melewati penelusuran arsitektur.
- Memungkinkan Anda meningkatkan kecepatan pelatihan dengan memilih secara manual hardware yang digunakan untuk penelusuran arsitektur dan pelatihan.
- Memungkinkan Anda mengurangi ukuran model dan meningkatkan latensi dengan distilasi atau dengan mengubah ukuran ansambel.
- Setiap komponen AutoML dapat diperiksa dengan antarmuka grafik pipeline andal yang memungkinkan Anda melihat tabel data yang ditransformasi, arsitektur model yang dievaluasi, dan banyak detail lainnya.
- Setiap komponen AutoML mendapatkan fleksibilitas dan transparansi yang lebih luas, seperti kemampuan untuk menyesuaikan parameter, hardware, status proses tampilan, log, dan lain-lain.
Input-Output
- Mengambil tabel BigQuery atau file CSV dari Cloud Storage sebagai input.
- Menghasilkan model Agent Platform sebagai output.
- Output perantara mencakup statistik set data dan pemisahan set data.
Untuk mengetahui informasi selengkapnya, lihat Tabular Workflow untuk AutoML End-to-End.
Tabular Workflow untuk perkiraan
Tabular Workflow untuk Perkiraan
Tabular Workflow untuk Perkiraan adalah pipeline lengkap untuk tugas perkiraan. Hal ini mirip dengan AutoML API, tetapi memungkinkan Anda memilih apa yang akan dikontrol dan diotomatisasi. Alih-alih memiliki kontrol untuk seluruh pipeline, Anda memiliki kontrol untuk setiap langkah di pipeline. Kontrol pipeline ini mencakup:
- Pemisahan data
- Rekayasa fitur
- Penelusuran arsitektur
- Pelatihan model
- Ansambel model
Manfaat
- Mendukung set data besar yang berukuran hingga 1 TB dan memiliki maksimal 200 kolom.
- Memungkinkan Anda meningkatkan stabilitas dan menurunkan waktu pelatihan dengan membatasi ruang penelusuran jenis arsitektur atau melewati penelusuran arsitektur.
- Memungkinkan Anda meningkatkan kecepatan pelatihan dengan memilih secara manual hardware yang digunakan untuk penelusuran arsitektur dan pelatihan.
- Memungkinkan Anda mengurangi ukuran model dan meningkatkan latensi dengan mengubah ukuran ansambel.
- Setiap komponen AutoML dapat diperiksa dengan antarmuka grafik pipeline andal yang memungkinkan Anda melihat tabel data yang ditransformasi, arsitektur model yang dievaluasi, dan banyak detail lainnya.
- Setiap komponen AutoML mendapatkan fleksibilitas dan transparansi yang lebih luas, seperti kemampuan untuk menyesuaikan parameter, hardware, status proses tampilan, log, dan lain-lain.
Input-Output
- Mengambil tabel BigQuery atau file CSV dari Cloud Storage sebagai input.
- Menghasilkan model Agent Platform sebagai output.
- Output perantara mencakup statistik set data dan pemisahan set data.
Untuk informasi selengkapnya, lihat Tabular Workflow untuk Perkiraan.
Langkah berikutnya
- Pelajari Tabular Workflow untuk AutoML End-to-End.
- Pelajari tentang Tabular Workflow untuk Perkiraan.
- Pelajari tentang Harga untuk Tabular Workflow.