

Gemini Enterprise Agent Platform 提供模型評估指標,協助您判斷模型效能,例如精確度和召回率指標。Agent Platform 會使用測試集計算評估指標。
如何使用模型評估指標
模型評估指標會透過量化方式,評估模型在測試集的效能。如何解讀及使用這些指標,取決於您的業務需求及模型接受訓練解決的問題。舉例來說,您對偽陽性的容忍度可能低於偽陰性,反之亦然。這類問題會影響您著重的指標。
如要進一步瞭解如何疊代模型以提升效能,請參閱「疊代模型」。
Agent Platform 回傳的評估指標
Agent Platform 會傳回多種評估指標,例如精確度、召回率和信賴度門檻。Agent Platform 傳回的指標取決於模型目標。舉例來說,與圖片物件偵測模型相比,Agent Platform 會為圖片分類模型提供不同的評估指標。
您可以從 Cloud Storage 位置下載結構定義檔案,該檔案會決定 Agent Platform 為每個目標提供的評估指標。以下分頁提供架構檔案的連結,並說明各模型目標的評估指標。
您可以從下列 Cloud Storage 位置查看及下載結構定義檔案:
gs://google-cloud-aiplatform/schema/modelevaluation/
- AuPRC:精確度和喚回度 (PR) 曲線下的面積,也稱為平均精確度。這個值介於 0 到 1 之間,值越大代表模型品質越高。
- 對數損失:模型推論與目標值之間的交叉熵。範圍從零到無限大,值越低代表模型品質越高。
- 可信度門檻:決定要傳回哪些推論的可信度分數。模型會傳回大於或等於這個值的推論結果。可信度門檻越高,精確度就會越高,但喚回度則會越低。Agent Platform 會傳回不同門檻值的信賴度指標,顯示門檻對精確度和召回率的影響。
- 喚回度:模型正確預測出含有此類別的推論比例,也稱為「真陽率」。
- 精確度:模型產生的正確分類推論比例。
- 混淆矩陣:混淆矩陣會顯示模型正確預測結果的頻率。如果是預測錯誤的結果,矩陣會顯示模型預測的結果。混淆矩陣可協助您瞭解模型「混淆」兩種結果的情況。
取得評估指標
您可以取得模型的匯總評估指標,以及特定類別或標籤的評估指標 (適用於部分目標)。特定類別或標籤的評估指標也稱為「評估切片」。以下內容說明如何使用 Google Cloud 控制台或 API 取得匯總評估指標和評估切片。
Google Cloud 控制台
前往 Google Cloud 控制台的「Agent Platform」部分,然後前往「Models」頁面。
在「Region」(區域) 下拉式選單中,選取模型所在的區域。
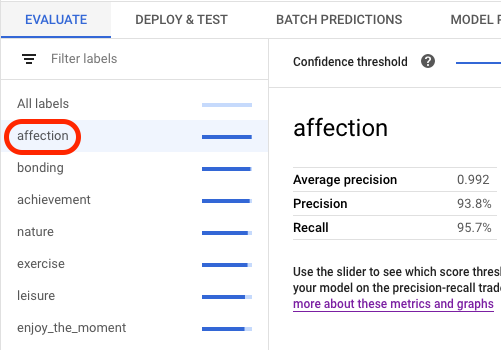
在模型清單中點選模型,開啟模型的「評估」分頁。
在「評估」分頁中,您可以查看模型的匯總評估指標,例如平均精確度和召回率。
如果模型目標有評估配量,控制台會顯示標籤清單。您可以按一下標籤,查看該標籤的評估指標,如下列範例所示:
(預覽) 您可以查看每個標籤的預測圖片,並依真陽性、偽陽性和偽陰性分組。每張圖片都有 L2 平方距離指標,可測量圖片與訓練圖片的相似程度。標示「離群值」徽章的圖片與所有訓練圖片的相似度相對較低。如要提升模型效能,建議您新增更多與離群值相似的訓練圖片。
API
取得評估指標的 API 要求適用於所有資料類型和目標,但輸出內容不同。下列範例顯示相同要求,但回應不同。
取得模型評估指標匯總
匯總模型評估指標會提供整體模型資訊。如要查看特定配量的資訊,請列出模型評估配量。
如要查看匯總模型評估指標,請使用 projects.locations.models.evaluations.get 方法。
Agent Platform 會傳回信賴度指標陣列。每個元素都會顯示不同 confidenceThreshold 值 (從 0 開始,最高為 1) 的評估指標。查看不同門檻值時,您可以瞭解門檻對精確度和召回率等其他指標的影響。
選取與語言或環境對應的分頁:
REST
使用任何要求資料之前,請先修改下列項目的值:
- LOCATION:模型儲存所在的區域。
- PROJECT: 您的 [專案 ID](/resource-manager/docs/creating-managing-projects#identifiers)。 。
- MODEL_ID:模型資源的 ID。
- PROJECT_NUMBER:系統自動為專案產生的專案編號。
- EVALUATION_ID:模型評估的 ID (會顯示在回應中)。
HTTP 方法和網址:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations
如要傳送要求,請選擇以下其中一個選項:
curl
執行下列指令:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations"
PowerShell
執行下列指令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations" | Select-Object -Expand Content
您應該會收到如下的 JSON 回覆:
Java
在試用這個範例之前,請先按照「使用用戶端程式庫的 Agent Platform 快速入門導覽課程」中的 Java 設定說明操作。
如要向 Agent Platform 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證機制」。
Node.js
在試用這個範例之前,請先按照「使用用戶端程式庫的 Agent Platform 快速入門導覽課程」中的 Node.js 設定說明操作。
如要向 Agent Platform 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證機制」。
Python
如要瞭解如何安裝或更新 Vertex AI SDK for Python,請參閱「安裝 Vertex AI SDK for Python」。 詳情請參閱 Python API 參考文件。
列出所有評估配量
projects.locations.models.evaluations.slices.list 方法會列出模型的所有評估配量。您必須擁有模型的評估 ID,才能查看匯總評估指標。
您可以透過模型評估配量,判斷模型在特定標籤上的成效。value 欄位會顯示指標所屬的標籤。
Agent Platform 會傳回信賴度指標陣列。每個元素都會顯示不同 confidenceThreshold 值 (從 0 開始,最高為 1) 的評估指標。查看不同門檻值時,您可以瞭解門檻對精確度和召回率等其他指標的影響。
REST
使用任何要求資料之前,請先修改下列項目的值:
- LOCATION:模型所在的區域。例如:
us-central1。 - PROJECT:。
- MODEL_ID:模型 ID。
- EVALUATION_ID:模型評估的 ID,其中包含要列出的評估配量。
HTTP 方法和網址:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices
如要傳送要求,請選擇以下其中一個選項:
curl
執行下列指令:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices"
PowerShell
執行下列指令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices" | Select-Object -Expand Content
您應該會收到如下的 JSON 回覆:
Java
在試用這個範例之前,請先按照「使用用戶端程式庫的 Agent Platform 快速入門導覽課程」中的 Java 設定說明操作。
如要向 Agent Platform 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證機制」。
Node.js
在試用這個範例之前,請先按照「使用用戶端程式庫的 Agent Platform 快速入門導覽課程」中的 Node.js 設定說明操作。
如要向 Agent Platform 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證機制」。
Python
如要瞭解如何安裝或更新 Vertex AI SDK for Python,請參閱「安裝 Vertex AI SDK for Python」。 詳情請參閱 Python API 參考文件。
取得單一區隔的指標
如要查看單一區隔的評估指標,請使用 projects.locations.models.evaluations.slices.get 方法。您必須擁有區隔 ID,這個 ID 會在您列出所有區隔時提供。下列範例適用於所有資料類型和目標。
REST
使用任何要求資料之前,請先修改下列項目的值:
- LOCATION:模型所在的區域,例如 us-central1。
- PROJECT:。
- MODEL_ID:模型 ID。
- EVALUATION_ID:模型評估的 ID,其中包含要擷取的評估切片。
- SLICE_ID:要取得的評估切片 ID。
- PROJECT_NUMBER:系統自動為專案產生的專案編號。
- EVALUATION_METRIC_SCHEMA_FILE_NAME:結構定義檔案的名稱,用於定義要傳回的評估指標,例如
classification_metrics_1.0.0。
HTTP 方法和網址:
GET https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID
如要傳送要求,請選擇以下其中一個選項:
curl
執行下列指令:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID"
PowerShell
執行下列指令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models/MODEL_ID/evaluations/EVALUATION_ID/slices/SLICE_ID" | Select-Object -Expand Content
您應該會收到如下的 JSON 回覆:
Java
在試用這個範例之前,請先按照「使用用戶端程式庫的 Agent Platform 快速入門導覽課程」中的 Java 設定說明操作。
如要向 Agent Platform 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證機制」。
Node.js
在試用這個範例之前,請先按照「使用用戶端程式庫的 Agent Platform 快速入門導覽課程」中的 Node.js 設定說明操作。
如要向 Agent Platform 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證機制」。
Python
如要瞭解如何安裝或更新 Vertex AI SDK for Python,請參閱「安裝 Vertex AI SDK for Python」。 詳情請參閱 Python API 參考文件。
反覆訓練模型
如果模型未達到預期效果,模型評估指標可做為模型除錯的起點。舉例來說,查準率和查全率低可能表示模型需要更多訓練資料,或者其中包含不一致的標籤。如果查準率和查全率都達到完美,可能表示測試資料太容易預測,因此模型可能無法妥善泛化。
您可以疊代訓練資料並建立新模型。建立新模型後,您可以比較現有模型和新模型的評估指標。
以下建議有助於改善標記項目的模型,例如分類或偵測模型:
- 請考慮在訓練資料中加入更多或更廣泛的範例。舉例來說,如果是圖像分類模型,您可以加入較寬角度的圖像、解析度較高或較低的圖像,或是不同視角的圖像。如需更多指引,請參閱「準備資料」。
- 如果類別或標籤的範例不多,請考慮移除。範例不足會導致模型無法持續且有把握地預測這些類別或標籤。
- 機器無法解讀類別或標籤的名稱,也無法瞭解兩者之間的細微差異,例如「door」和「door_with_knob」。您必須提供資料,協助機器辨識這類細微差異。
- 以更多真陽性和真陰性的範例來擴增資料,尤其是貼近決策邊界的範例,有助於減少模型混淆。
- 指定自己的資料分割方式 (訓練、驗證和測試)。Agent Platform 會隨機將項目指派給各個集合。因此,近乎重複的資料可能會分配到訓練和驗證集中,導致過度擬合,進而影響測試集的成效。如要進一步瞭解如何自行設定資料分割,請參閱「AutoML 模型資料分割作業簡介」。
- 如果模型的評估指標包含混淆矩陣,您可以查看模型是否混淆兩個標籤,也就是模型預測特定標籤的次數遠多於實際標籤。請檢查資料,確認範例標籤是否正確。
- 如果訓練時間短 (節點時數上限較低),您可以延長模型的訓練時間 (節點時數上限較高),以取得更高品質的模型。