
טעינת נתונים מ-Amazon S3 ל-BigQuery
אפשר לטעון נתונים מ-Amazon S3 ל-BigQuery באמצעות מחבר BigQuery Data Transfer Service ל-Amazon S3. שירות העברת הנתונים ל-BigQuery מאפשר לתזמן משימות העברה חוזרות שמוסיפות את הנתונים העדכניים מ-Amazon S3 ל-BigQuery.
לפני שמתחילים
לפני שיוצרים העברת נתונים מ-Amazon S3:
- מוודאים שביצעתם את כל הפעולות שנדרשות כדי להפעיל את שירות העברת נתונים ל-BigQuery.
- יוצרים מערך נתונים ב-BigQuery לאחסון הנתונים.
- יוצרים את טבלת היעד להעברת הנתונים ומציינים את הגדרת הסכימה. טבלת היעד צריכה לעמוד בכללים למתן שמות לטבלאות. שמות של טבלאות יעד תומכים גם בפרמטרים. אפשר ליצור טבלה ב-BigQuery או ליצור טבלת Iceberg מנוהלת.
- מאחזרים את ה-URI של Amazon S3, את מזהה מפתח הגישה ואת מפתח הגישה הסודי. מידע על ניהול מפתחות הגישה זמין במסמכי AWS.
- אם אתם רוצים להגדיר התראות על הפעלת העברה ב-Pub/Sub, אתם צריכים הרשאות
pubsub.topics.setIamPolicy. אם מגדירים רק התראות באימייל, לא צריך הרשאות Pub/Sub. מידע נוסף זמין במאמר בנושא התראות על הפעלת שירות העברת נתונים ל-BigQuery.
מגבלות
העברות נתונים מ-Amazon S3 כפופות למגבלות הבאות:
- אי אפשר להגדיר פרמטרים לחלק של קטגוריית ה-URI של Amazon S3.
- העברות נתונים מ-Amazon S3 עם הפרמטר Write disposition שמוגדר לערך
WRITE_TRUNCATEיעבירו את כל הקבצים התואמים אל Google Cloud במהלך כל הפעלה. יכול להיות שבעקבות זאת יחולו עלויות נוספות על העברת נתונים יוצאים ב-Amazon S3. מידע נוסף על הקבצים שמועברים במהלך ההרצה זמין במאמר ההשפעה של התאמת קידומת לעומת התאמת תווים כלליים. - אין תמיכה בהעברות נתונים מאזורים של AWS GovCloud (
us-gov). - העברת נתונים למיקומים ב-BigQuery Omni לא אפשרית.
יכול להיות שיחולו מגבלות נוספות בהתאם לפורמט של נתוני המקור ב-Amazon S3. למידע נוסף:
מרווח הזמן המינימלי בין העברות נתונים חוזרות הוא שעה אחת. כברירת מחדל, ההעברה החוזרת של הנתונים מתבצעת כל 24 שעות.
העברות נתונים מ-Amazon S3 נתמכות על ידי אותן מגבלות אזוריות של Amazon S3 כמו ב-Storage Transfer Service. מידע נוסף זמין במאמר בנושא אזורים נתמכים.
ההרשאות הנדרשות
ודאו שהענקתם את ההרשאות הבאות.
התפקידים הנדרשים ב-BigQuery
כדי לקבל את ההרשאות שנדרשות ליצירת העברת נתונים באמצעות BigQuery Data Transfer Service, צריך לבקש מהאדמין להקצות לכם את תפקיד BigQuery Admin (roles/bigquery.admin) ב-IAM בפרויקט.
כדי לקרוא הסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
התפקיד המוגדר מראש הזה כולל את ההרשאות שנדרשות ליצירת העברת נתונים בשירות העברת נתונים ל-BigQuery. כדי לראות בדיוק אילו הרשאות נדרשות, אפשר להרחיב את הקטע ההרשאות הנדרשות:
ההרשאות הנדרשות
כדי ליצור העברת נתונים באמצעות שירות העברת הנתונים ל-BigQuery, נדרשות ההרשאות הבאות:
-
הרשאות של שירות העברת נתונים ל-BigQuery:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
הרשאות ב-BigQuery:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
יכול להיות שתקבלו את ההרשאות האלה באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
מידע נוסף מופיע במאמר בנושא מתן גישה ל-bigquery.admin.
התפקידים הנדרשים ב-Amazon S3
כדאי לעיין במסמכי התיעוד של Amazon S3 כדי לוודא שהגדרתם את כל ההרשאות שנדרשות להפעלת העברת הנתונים. לפחות, צריך להחיל על נתוני המקור ב-Amazon S3 את המדיניות המנוהלת של AWS AmazonS3ReadOnlyAccess.
הגדרת העברת נתונים מ-Amazon S3
כדי ליצור העברת נתונים מ-Amazon S3:
המסוף
עוברים לדף 'העברות נתונים' במסוף Google Cloud .
לוחצים על Create transfer (יצירת העברה).
בדף Create Transfer:
בקטע Source type, בוחרים באפשרות Amazon S3 בשדה Source.

בקטע Transfer config name, בשדה Display name, מזינים שם להעברה, כמו
My Transfer. שם ההעברה יכול להיות כל ערך שיאפשר לכם לזהות את ההעברה אם תצטרכו לשנות אותה בהמשך.
בקטע אפשרויות תזמון:
בוחרים תדירות חזרה. אם בוחרים באפשרות שעות, ימים, שבועות או חודשים, צריך לציין גם תדירות. אפשר גם לבחור באפשרות בהתאמה אישית כדי ליצור תדירות חזרה ספציפית יותר. אם בוחרים באפשרות על פי דרישה, העברת הנתונים הזו תפעל רק כשמפעילים את ההעברה באופן ידני.
אם רלוונטי, בוחרים באפשרות התחלה מיידית או התחלה בשעה שנקבעה, ומזינים תאריך התחלה ומשך הפעלה.
בקטע הגדרות היעד:
- בשדה Dataset, בוחרים את מערך הנתונים שיצרתם לאחסון הנתונים.
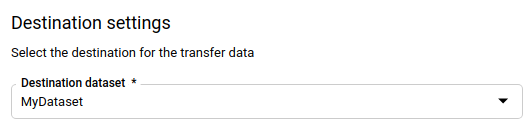
- בוחרים באפשרות Native table (טבלה מקורית) אם רוצים להעביר לטבלה ב-BigQuery.
- בוחרים באפשרות Iceberg Managed (טבלה בניהול Iceberg) אם רוצים להעביר לטבלה בניהול Iceberg.
- בשדה Dataset, בוחרים את מערך הנתונים שיצרתם לאחסון הנתונים.
בקטע פרטי מקור הנתונים:
- בשדה טבלת יעד, מזינים את שם הטבלה שיצרתם כדי לאחסן את הנתונים ב-BigQuery. שמות של טבלאות ביעד תומכים בפרמטרים.
- בשדה Amazon S3 URI, מזינים את ה-URI בפורמט
s3://mybucket/myfolder/.... מזהי URI תומכים גם בפרמטרים. - בשדה Access key ID (מזהה מפתח הגישה), מזינים את מזהה מפתח הגישה.
- בקטע מפתח גישה סודי, מזינים את מפתח הגישה הסודי.
- בקטע פורמט קובץ בוחרים את פורמט הנתונים (JSON עם תווי שורה, CSV, Avro, Parquet או ORC).
- בקטע Write Disposition (הגדרת כתיבה), בוחרים באחת מהאפשרויות הבאות:
-
WRITE_APPENDכדי להוסיף נתונים חדשים לטבלת היעד הקיימת. WRITE_APPENDהוא ערך ברירת המחדל של העדפת הכתיבה. -
WRITE_TRUNCATEכדי להחליף את הנתונים בטבלת היעד במהלך כל הרצה של העברת הנתונים.
-
מידע נוסף על האופן שבו שירות העברת הנתונים ל-BigQuery קולט נתונים באמצעות
WRITE_APPENDאוWRITE_TRUNCATEזמין במאמר קליטת נתונים להעברות מ-Amazon S3. מידע נוסף על השדהwriteDispositionזמין במאמרJobConfigurationLoad.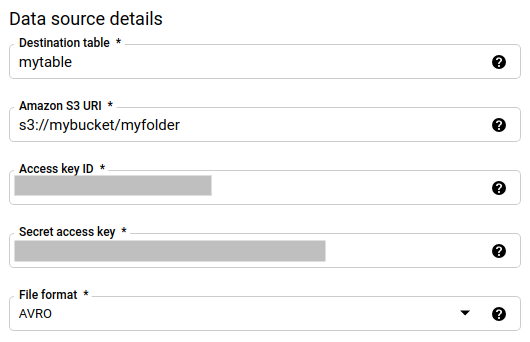
בקטע אפשרויות העברה – כל הפורמטים:
- בקטע מספר השגיאות המותר, מזינים ערך של מספר שלם עבור המספר המקסימלי של רשומות פגומות שאפשר להתעלם מהן.
- (אופציונלי) בשביל סוגי יעד עשרוניים, מזינים רשימה מופרדת בפסיקים של סוגי נתונים אפשריים ב-SQL שאפשר להמיר אליהם את הערכים העשרוניים של המקור. סוג הנתונים של SQL שנבחר להמרה תלוי בתנאים הבאים:
- סוג הנתונים שייבחר להמרה יהיה סוג הנתונים הראשון ברשימה הבאה שתומך בדיוק ובקנה המידה של נתוני המקור, לפי הסדר הזה: NUMERIC, BIGNUMERIC ו-STRING.
- אם אף אחד מסוגי הנתונים שמופיעים ברשימה לא תומך בדיוק ובקנה המידה, ייבחר סוג הנתונים שתומך בטווח הרחב ביותר ברשימה שצוינה. אם ערך חורג מהטווח הנתמך בזמן קריאת נתוני המקור, תוצג שגיאה.
- סוג הנתונים STRING תומך בכל ערכי הדיוק והקנה מידה.
- אם השדה הזה יישאר ריק, סוג הנתונים יהיה ברירת המחדל 'NUMERIC,STRING' עבור ORC, ו-'NUMERIC' עבור פורמטים אחרים של קבצים.
- השדה הזה לא יכול להכיל סוגי נתונים כפולים.
- הסדר של סוגי הנתונים שמציינים בשדה הזה לא משנה.

אם בחרתם בפורמט CSV או JSON, בקטע JSON,CSV, מסמנים את התיבה Ignore unknown values כדי לאשר שורות שמכילות ערכים שלא תואמים לסכימה. המערכת מתעלמת מערכים לא מוכרים. בקובצי CSV, האפשרות הזו מתעלמת מערכים מיותרים בסוף השורה.

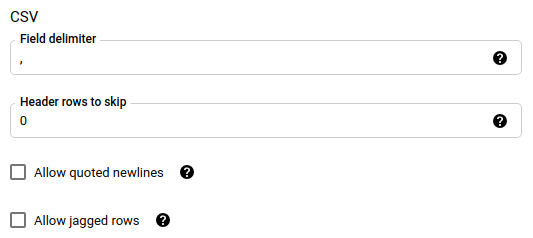
אם בחרתם ב-CSV כפורמט הקובץ, בקטע CSV מזינים אפשרויות נוספות של CSV לטעינת הנתונים.
בתפריט Service Account, בוחרים חשבון שירות מתוך חשבונות השירות שמשויכים לפרויקטGoogle Cloud . אתם יכולים לשייך חשבון שירות להעברת הנתונים במקום להשתמש בפרטי הכניסה של המשתמש. מידע נוסף על שימוש בחשבונות שירות עם העברות נתונים זמין במאמר שימוש בחשבונות שירות.
- אם נכנסתם באמצעות זהות מאוחדת, תצטרכו חשבון שירות כדי ליצור העברת נתונים. אם נכנסתם באמצעות חשבון Google, לא חייבים להשתמש בחשבון שירות להעברת הנתונים.
- לחשבון השירות צריכות להיות ההרשאות הנדרשות.
(אופציונלי) בקטע אפשרויות להתראות:
לוחצים על Save.
BQ
מזינים את הפקודה bq mk ומספקים את האפשרות ליצירת העברה –
--transfer_config.
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --display_name=name \ --target_dataset=dataset \ --service_account_name=service_account \ --params='parameters'
כאשר:
- project_id: אופציונלי. מזהה הפרויקט Google Cloud .
אם לא מציינים את
--project_idכדי לציין פרויקט מסוים, המערכת משתמשת בפרויקט שמוגדר כברירת מחדל. - data_source: שדה חובה. מקור הנתונים –
amazon_s3. - display_name: שדה חובה. השם המוצג של הגדרת העברת הנתונים. שם ההעברה יכול להיות כל ערך שיעזור לכם לזהות את ההעברה אם תצטרכו לשנות אותה בהמשך.
- dataset: שדה חובה. מערך נתוני היעד להגדרת העברת הנתונים.
- service_account: השם של חשבון השירות שמשמש לאימות של העברת הנתונים. חשבון השירות צריך להיות בבעלות אותו
project_idששימש ליצירת העברת הנתונים, וצריכות להיות לו כל ההרשאות הנדרשות. parameters: שדה חובה. הפרמטרים של הגדרת ההעברה שנוצרה בפורמט JSON. לדוגמה:
--params='{"param":"param_value"}'. אלה הפרמטרים להעברה מ-Amazon S3:- destination_table_name_template: שדה חובה. השם של טבלת היעד.
data_path: שדה חובה. כתובת ה-URI של Amazon S3, בפורמט הבא:
s3://mybucket/myfolder/...מזהי URI תומכים גם בפרמטרים.
access_key_id: שדה חובה. המזהה של מפתח הגישה.
secret_access_key: שדה חובה. מפתח הגישה הסודי.
file_format: אופציונלי. מציין את סוג הקבצים שרוצים להעביר:
CSV,JSON,AVRO,PARQUETאוORC. ערך ברירת המחדל הואCSV.write_disposition: אופציונלי.
WRITE_APPENDיעביר רק את הקבצים ששונו מאז ההפעלה הקודמת שהסתיימה בהצלחה. WRITE_TRUNCATEיעביר את כל הקבצים התואמים, כולל קבצים שהועברו בהרצה קודמת. ערך ברירת המחדל הואWRITE_APPEND.max_bad_records: אופציונלי. מספר הרשומות הפגומות המותר. ערך ברירת המחדל הוא
0.decimal_target_types: אופציונלי. רשימה מופרדת בפסיקים של סוגי נתונים אפשריים של SQL שאפשר להמיר אליהם את הערכים העשרוניים של המקור. אם לא מציינים את השדה הזה, סוג הנתונים יהיה ברירת המחדל NUMERIC,STRING עבור ORC, ו-NUMERIC עבור פורמטים אחרים של קבצים.
ignore_unknown_values: אופציונלי, ומתעלמים ממנו אם הערך של file_format הוא לא
JSONאוCSV. האם להתעלם מערכים לא ידועים בנתונים.field_delimiter (לא חובה): חל רק אם הערך של
file_formatהואCSV. התו שמפריד בין השדות. ערך ברירת המחדל הוא פסיק.skip_leading_rows (לא חובה): חל רק אם הערך של file_format הוא
CSV. מציין את מספר שורות הכותרת שלא רוצים לייבא. ערך ברירת המחדל הוא0.allow_quoted_newlines (לא חובה): חל רק אם הערך של file_format הוא
CSV. מציין אם מותר להשתמש בתווי newline בשדות שמוקפים במירכאות.allow_jagged_rows (לא חובה): חל רק אם הערך של file_format הוא
CSV. מציין אם לקבל שורות שחסרות בהן עמודות אופציונליות בסוף. הערכים החסרים ימולאו בערכי NULL.
לדוגמה, הפקודה הבאה יוצרת העברת נתונים ב-Amazon S3 בשם My Transfer באמצעות ערך data_path של s3://mybucket/myfile/*.csv, מערך נתונים של יעד mydataset ו-file_format
CSV. בדוגמה הזו מופיעים ערכים לא סטנדרטיים לפרמטרים האופציונליים שמשויכים ל-CSV file_format.
העברת הנתונים נוצרת בפרויקט ברירת המחדל:
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"data_path":"s3://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"write_disposition":"WRITE_APPEND",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false"}' \
--data_source=amazon_s3
אחרי הרצת הפקודה, תקבלו הודעה כמו זו:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
פועלים לפי ההוראות ומדביקים את קוד האימות בשורת הפקודה.
API
משתמשים בשיטה projects.locations.transferConfigs.create ומספקים מופע של המשאב TransferConfig.
Java
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Java API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
ההבדל בין התאמת תחילית לבין התאמת תווים כלליים לחיפוש
Amazon S3 API תומך בהתאמה של קידומות, אבל לא בהתאמה של תווים כלליים לחיפוש. כל הקבצים ב-Amazon S3 שתואמים לקידומת יועברו אל Google Cloud. עם זאת, רק קבצים שתואמים ל-URI של Amazon S3 בהגדרת ההעברה ייטענו בפועל ל-BigQuery. התוצאה יכולה להיות עלויות גבוהות מדי של העברת נתונים יוצאים מ-Amazon S3 עבור קבצים שמועברים אבל לא נטענים ל-BigQuery.
לדוגמה, נתיב הנתונים הזה:
s3://bucket/folder/*/subfolder/*.csv
בנוסף לקבצים האלה במיקום המקור:
s3://bucket/folder/any/subfolder/file1.csv
s3://bucket/folder/file2.csv
כתוצאה מכך, כל הקבצים ב-Amazon S3 עם הקידומת s3://bucket/folder/ יועברו אל Google Cloud. בדוגמה הזו, גם file1.csv וגם file2.csv יועברו.
עם זאת, רק קבצים שתואמים ל-s3://bucket/folder/*/subfolder/*.csv ייטענו בפועל ל-BigQuery. בדוגמה הזו, רק file1.csv ייטען ל-BigQuery.
פתרון בעיות בהגדרת ההעברה
אם נתקלתם בבעיות בהגדרת העברת הנתונים, כדאי לעיין במאמר בעיות בהעברה מ-Amazon S3.
המאמרים הבאים
- למידע נוסף על העברת נתונים מ-Amazon S3, אפשר לעיין במאמר סקירה כללית על העברות מ-Amazon S3.
- סקירה כללית של שירות העברת נתונים ל-BigQuery זמינה במאמר מבוא לשירות העברת נתונים ל-BigQuery.
- מידע על שימוש בהעברות נתונים, כולל קבלת מידע על הגדרות העברה, הצגת רשימה של הגדרות העברה והצגת היסטוריית ההרצה של העברה, זמין במאמר עבודה עם העברות.
- איך טוענים נתונים באמצעות פעולות BigQuery Omni