
מבוא ל-BigQuery Omni
בעזרת BigQuery Omni, אתם יכולים להריץ ניתוחים ב-BigQuery על נתונים שמאוחסנים ב-Amazon Simple Storage Service (Amazon S3) או ב-Azure Blob Storage באמצעות טבלאות BigLake.
הרבה ארגונים מאחסנים נתונים בכמה עננים ציבוריים. לרוב, הנתונים האלה מבודדים כי קשה להפיק תובנות מכל הנתונים. אתם רוצים לנתח את הנתונים באמצעות כלי נתונים מרובה עננים שהוא זול, מהיר ולא יוצר תקורה נוספת של משילות מידע מבוזרת. אנחנו משתמשים ב-BigQuery Omni כדי לצמצם את הבעיות האלה באמצעות ממשק מאוחד.
כדי להריץ ניתוח BigQuery על הנתונים החיצוניים, צריך קודם להתחבר ל-Amazon S3 או ל-Blob Storage. אם רוצים לשלוח שאילתות לנתונים חיצוניים, צריך ליצור טבלת BigLake שמפנה לנתונים ב-Amazon S3 או ב-Blob Storage.
כלים של BigQuery Omni
אתם יכולים להשתמש בכלים הבאים של BigQuery Omni כדי להריץ ניתוח BigQuery על הנתונים החיצוניים שלכם:
- צירופים ב-BigQuery Omni: הרצת שאילתה ישירות מאזור BigQuery שיכול לצרף נתונים מאזור BigQuery Omni.
- תצוגות חומריות של BigQuery Omni: אפשר להשתמש ברפליקות של תצוגות חומריות כדי לשכפל נתונים באופן רציף מאזורים של BigQuery Omni. תמיכה בסינון נתונים.
- העברה ב-BigQuery Omni באמצעות
SELECT: מריצים שאילתה באמצעות ההצהרהCREATE TABLE AS SELECTאוINSERT INTO SELECTבאזור BigQuery Omni ומעבירים את התוצאה לאזור BigQuery. - העברה של BigQuery Omni באמצעות
LOAD: שימוש בהצהרותLOAD DATAלטעינת נתונים ישירות מ-Amazon Simple Storage Service (Amazon S3) או מ-Azure Blob Storage ל-BigQuery
בטבלה הבאה מפורטות התכונות והיכולות העיקריות של כל כלי BigQuery Omni:
| צירופים ב-BigQuery Omni | תצוגה מהותית ב-BigQuery Omni | העברה באמצעות BigQuery Omni SELECT |
העברה באמצעות BigQuery Omni LOAD |
|
|---|---|---|---|---|
| שימוש מומלץ | הפעלת שאילתות על נתונים חיצוניים לשימוש חד-פעמי, שבהן אפשר לבצע הצטרפות לטבלאות מקומיות או הצטרפות לנתונים בין שני אזורים שונים של BigQuery Omni – לדוגמה, בין אזורים של AWS ו-Azure Blob Storage. אם הנתונים לא גדולים במיוחד, ואם אחסון במטמון הוא לא דרישה חשובה, כדאי להשתמש בצירופים של BigQuery Omni. | הגדרת שאילתות חוזרות או מתוזמנות להעברה רציפה של נתונים חיצוניים באופן מצטבר, כאשר אחסון במטמון הוא דרישה מרכזית. לדוגמה, כדי לתחזק לוח בקרה | שליחת שאילתות לנתונים חיצוניים לשימוש חד-פעמי, מאזור BigQuery Omni לאזור BigQuery, כשדרישה מרכזית היא אמצעי בקרה ידניים כמו שמירת נתונים במטמון ואופטימיזציה של שאילתות, ואם אתם משתמשים בשאילתות מורכבות שלא נתמכות על ידי הצטרפות של BigQuery Omni או תצוגות חומריות של BigQuery Omni | העברת מערכי נתונים גדולים כמו שהם בלי צורך בסינון, באמצעות שאילתות מתוזמנות להעברת נתונים גולמיים |
| תמיכה בסינון לפני העברת הנתונים | כן. יש מגבלות על אופרטורים מסוימים של שאילתות. מידע נוסף זמין במאמר מגבלות על הצטרפות ל-BigQuery Omni | כן. יש מגבלות על אופרטורים מסוימים של שאילתות, כמו פונקציות מצטברות והאופרטור UNION |
כן. אין מגבלות על אופרטורים של שאילתות | לא |
| מגבלות על גודל ההעברה | 60GB לכל העברה (כל שאילתת משנה לאזור מרוחק יוצרת העברה אחת) | אין מגבלה | 60GB לכל העברה (כל שאילתת משנה לאזור מרוחק יוצרת העברה אחת) | אין מגבלה |
| דחיסה של העברת נתונים | דחיסת חוטים | מבוסס-עמודות | דחיסת חוטים | דחיסת חוטים |
| שמירה במטמון | לא נתמך | נתמך בטבלאות עם הפעלת מטמון עם תצוגות חומריות | לא נתמך | לא נתמך |
| תמחור של תעבורת נתונים יוצאת (egress) | עלות תעבורת נתונים יוצאת (egress) ועלות העברת נתונים בין יבשות ב-AWS | עלות תעבורת נתונים יוצאת (egress) ועלות העברת נתונים בין יבשות ב-AWS | עלות תעבורת נתונים יוצאת (egress) ועלות העברת נתונים בין יבשות ב-AWS | עלות תעבורת נתונים יוצאת (egress) ועלות העברת נתונים בין יבשות ב-AWS |
| חישוב השימוש במשאבי מחשוב להעברת נתונים | משתמש במשבצות באזור המקור של AWS או Azure Blob Storage (הזמנה או לפי דרישה) | צולם בלי מבזק | משתמש במשבצות באזור המקור של AWS או Azure Blob Storage (הזמנה או לפי דרישה) | צולם בלי מבזק |
| שימוש במחשוב לסינון | משתמש במשבצות באזור המקור של AWS או Azure Blob Storage (הזמנה או לפי דרישה) | משתמש במשבצות זמן באזור המקור של AWS או Azure Blob Storage (הזמנה או לפי דרישה) כדי לחשב תצוגות חומריות מקומיות ומטא-נתונים | משתמש במשבצות באזור המקור של AWS או Azure Blob Storage (הזמנה או לפי דרישה) | צולם בלי מבזק |
| העברה מצטברת | לא נתמך | נתמך בתצוגות חומריות לא מצטברות | לא נתמך | לא נתמך |
אפשר גם להשתמש בחלופות הבאות כדי להעביר נתונים מ-Amazon Simple Storage Service (Amazon S3) או מ-Azure Blob Storage אל Google Cloud:
- Storage Transfer Service: העברת נתונים בין אחסון אובייקטים ואחסון קבצים ב- Google Cloud וב-Amazon Simple Storage Service (Amazon S3) או ב-Azure Blob Storage.
- שירות העברת הנתונים ל-BigQuery: הגדרה של העברת נתונים אוטומטית ל-BigQuery באופן מתוזמן ומנוהל. תומך במגוון מקורות ומתאים להעברת נתונים. שירות העברת הנתונים ל-BigQuery לא תומך בסינון.
ארכיטקטורה
הארכיטקטורה של BigQuery מפרידה בין מחשוב לאחסון, ומאפשרת ל-BigQuery להתרחב לפי הצורך כדי לטפל בעומסי עבודה גדולים מאוד. BigQuery Omni מרחיב את הארכיטקטורה הזו על ידי הפעלת מנוע השאילתות של BigQuery בעננים אחרים. כתוצאה מכך, לא צריך להעביר את הנתונים פיזית לאחסון ב-BigQuery. העיבוד מתבצע במקום שבו הנתונים כבר נמצאים.
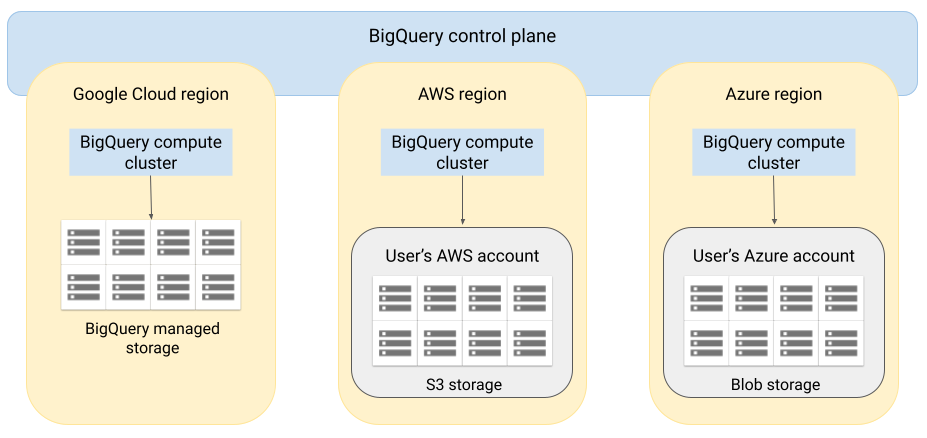
אפשר להחזיר את תוצאות השאילתה אל Google Cloud חיבור מאובטח – לדוגמה, כדי להציג אותן במסוף Google Cloud . לחלופין, אפשר לכתוב את התוצאות ישירות לקטגוריות של Amazon S3 או ל-Blob Storage. במקרה כזה, לא מתבצעת העברה של תוצאות השאילתה בין עננים.
BigQuery Omni משתמש בתפקידי IAM סטנדרטיים ב-AWS או ב-principals של Azure Active Directory כדי לגשת לנתונים במינוי שלכם. אתם מקצים הרשאת קריאה או כתיבה ל-BigQuery Omni, ויכולים לבטל את הגישה בכל שלב.
זרימת נתונים כשמריצים שאילתות על נתונים
בתמונה הבאה מתואר איך הנתונים עוברים בין Google Cloud לבין AWS או Azure בשאילתות הבאות:
SELECTדוחCREATE EXTERNAL TABLEדוח

- מישור הבקרה של BigQuery מקבל מכם משימות של שאילתות דרךGoogle Cloud המסוף, כלי שורת הפקודה של BigQuery, שיטת API או ספריית לקוח.
- מישור הבקרה של BigQuery שולח משימות של שאילתות לעיבוד למישור הנתונים של BigQuery ב-AWS או ב-Azure.
- מישור הנתונים של BigQuery מקבל את השאילתה ממישור הבקרה דרך חיבור VPN.
- מישור הנתונים של BigQuery קורא נתונים מטבלה מתוך קטגוריית Amazon S3 או Blob Storage.
- מישור הנתונים של BigQuery מריץ את משימת השאילתה על נתוני הטבלה. העיבוד של נתוני הטבלה מתבצע באזור AWS או Azure שצוין.
- תוצאת השאילתה מועברת ממישור הנתונים למישור הבקרה דרך חיבור ה-VPN.
- מישור הבקרה של BigQuery מקבל את תוצאות משימת השאילתה כדי להציג אותן בתגובה למשימת השאילתה. הנתונים האלה נשמרים למשך עד 24 שעות.
- תוצאת השאילתה מוחזרת אליכם.
מידע נוסף זמין במאמרים בנושא שאילתות על נתונים ב-Amazon S3 ונתונים ב-Blob Storage.
זרימת הנתונים במהלך ייצוא הנתונים
בתמונה הבאה מתואר איך הנתונים עוברים בין Google Cloud לבין AWS או Azure במהלך הצהרת EXPORT DATA.

- מישור הבקרה של BigQuery מקבל מכם משימות של שאילתות ייצוא דרך Google Cloud המסוף, כלי שורת הפקודה של BigQuery, שיטה של API או ספריית לקוח. השאילתה מכילה את נתיב היעד של תוצאת השאילתה בקטגוריה של Amazon S3 או ב-Blob Storage.
- מישור הבקרה של BigQuery שולח משימות של שאילתות ייצוא לעיבוד במישור הנתונים של BigQuery (ב-AWS או ב-Azure).
- מישור הנתונים של BigQuery מקבל את שאילתת הייצוא ממישור הבקרה דרך חיבור ה-VPN.
- מישור הנתונים של BigQuery קורא נתונים מטבלה מתוך קטגוריית Amazon S3 או Blob Storage.
- מישור הנתונים של BigQuery מריץ את משימת השאילתה על נתוני הטבלה. העיבוד של נתוני הטבלה מתבצע באזור AWS או Azure שצוין.
- BigQuery כותב את תוצאת השאילתה לנתיב היעד שצוין בדלי Amazon S3 או ב-Blob Storage.
מידע נוסף זמין במאמרים בנושא ייצוא תוצאות של שאילתות ל-Amazon S3 ול-Blob Storage.
יתרונות
ביצועים. אתם יכולים לקבל תובנות מהר יותר, כי הנתונים לא מועתקים בין עננים והשאילתות מופעלות באותו אזור שבו הנתונים נמצאים.
עלות אתם חוסכים בעלויות של העברת נתונים יוצאים כי הנתונים לא מועברים. אין חיובים נוספים בחשבון AWS או Azure שקשורים לניתוח נתונים ב-BigQuery Omni, כי השאילתות מופעלות באשכולות שמנוהלים על ידי Google. החיוב הוא רק על הרצת השאילתות, לפי מודל התמחור של BigQuery.
אבטחה ומשילות מידע. אתם מנהלים את הנתונים במינוי שלכם ל-AWS או ל-Azure. אין צורך להעביר או להעתיק את הנתונים הגולמיים מהענן הציבורי. כל החישובים מתבצעים בשירות BigQuery multi-tenant שפועל באותו אזור שבו הנתונים שלכם נמצאים.
ארכיטקטורה ללא שרתים (serverless). בדומה לשאר BigQuery, BigQuery Omni הוא שירות ללא שרת. Google פורסת ומנהלת את האשכולות שמריצים את BigQuery Omni. לא צריך להקצות משאבים או לנהל אשכולות.
ניהול קל. BigQuery Omni מספק ממשק ניהול מאוחד דרך Google Cloud. אפשר להשתמש ב-BigQuery Omni עם חשבון Google Cloud ופרויקטים קיימים ב-BigQuery. אפשר לכתוב שאילתת GoogleSQL ב Google Cloud מסוף כדי להריץ שאילתות על נתונים ב-AWS או ב-Azure, ולראות את התוצאות שמוצגות ב Google Cloud מסוף.
העברה של BigQuery Omni. אפשר לטעון נתונים לטבלאות רגילות ב-BigQuery ממאגרי S3 ומ-Blob Storage. מידע נוסף זמין במאמרים בנושא העברת נתונים מ-Amazon S3 והעברת נתונים מ-Blob Storage ל-BigQuery.
שמירת מטא-נתונים במטמון לשיפור הביצועים
אפשר להשתמש במטא-נתונים שמאוחסנים במטמון כדי לשפר את ביצועי השאילתות בטבלאות BigLake שמפנות לנתונים ב-Amazon S3. האפשרות הזו שימושית במיוחד כשעובדים עם מספר גדול של קבצים או אם הנתונים מחולקים למחיצות ב-Apache Hive.
BigQuery משתמש ב-CMETA כמערכת מבוזרת של מטא-נתונים כדי לטפל בטבלאות גדולות ביעילות. CMETA מספק מטא-נתונים פרטניים ברמת העמודה והבלוק, שאפשר לגשת אליהם דרך טבלאות מערכת. המערכת הזו עוזרת לשפר את הביצועים של השאילתות על ידי אופטימיזציה של הגישה לנתונים ושל העיבוד שלהם. כדי לשפר עוד יותר את ביצועי השאילתות בטבלאות גדולות, BigQuery שומר מטמון של מטא-נתונים. משימות רענון של CMETA דואגות שהמטמון הזה יהיה עדכני.המטא-נתונים כוללים שמות של קבצים, מידע על חלוקה למחיצות ומטא-נתונים פיזיים מקבצים, כמו מספר השורות. אתם יכולים לבחור אם להפעיל שמירת מטמון של מטא-נתונים בטבלה. התכונה 'שמירת מטא-נתונים במטמון' מועילה במיוחד לשאילתות עם מספר גדול של קבצים ולשאילתות עם מסנני חלוקה של Apache Hive.
אם לא מפעילים שמירת מטא-נתונים במטמון, כדי לקבל את המטא-נתונים של האובייקט, השאילתות בטבלה צריכות לקרוא את מקור הנתונים החיצוני. קריאת הנתונים האלה מגדילה את זמן האחזור של השאילתה. יכולות לעבור כמה דקות עד שמיליוני קבצים יופיעו ממקור הנתונים החיצוני. אם מפעילים שמירת מטא-נתונים במטמון, השאילתות יכולות להימנע מרישום קבצים ממקור הנתונים החיצוני, ולחלק ולצמצם קבצים מהר יותר.
שמירת מטא-נתונים במטמון משולבת גם עם ניהול גרסאות של אובייקטים ב-Cloud Storage. כשהמטמון מתמלא או מתעדכן, הוא מתעד את המטא-נתונים על סמך הגרסה הפעילה של האובייקטים ב-Cloud Storage באותו זמן. כתוצאה מכך, שאילתות שמופעל בהן מטמון של מטא-נתונים קוראות נתונים שתואמים לגרסה הספציפית של האובייקט שנשמרה במטמון, גם אם גרסאות חדשות יותר הופכות לפעילות ב-Cloud Storage. כדי לגשת לנתונים מגרסאות של אובייקטים שעודכנו ב-Cloud Storage, צריך לרענן את מטמון המטא-נתונים.
יש שני מאפיינים ששולטים בתכונה הזו:
- Maximum staleness מציין מתי שאילתות משתמשות במטא-נתונים שנשמרו במטמון.
- מצב מטמון של מטא-נתונים מציין את אופן איסוף המטא-נתונים.
כשמפעילים שמירת מטא-נתונים במטמון, מציינים את המרווח המקסימלי של מטא-נתונים לא עדכניים שמתקבל על הדעת לפעולות שמתבצעות בטבלה. לדוגמה, אם מציינים מרווח של שעה אחת, פעולות שמתבצעות בטבלה משתמשות במטא-נתונים שנשמרו במטמון אם הם רועננו בשעה האחרונה. אם המטא-נתונים שבמטמון ישנים יותר, הפעולה חוזרת לאחור ומנסה לאחזר מטא-נתונים מ-Amazon S3. אפשר לציין מרווח זמן בין 30 דקות ל-7 ימים.
כשמפעילים שמירת מטמון של מטא-נתונים בטבלאות BigLake או בטבלאות אובייקטים, BigQuery מפעיל משימות לרענון יצירת המטא-נתונים. אפשר לבחור לרענן את המטמון באופן אוטומטי או ידני:
- במקרה של רענון אוטומטי, המטמון מתרענן במרווח זמן שמוגדר על ידי המערכת, בדרך כלל בין 30 ל-60 דקות. רענון אוטומטי של המטמון הוא גישה טובה אם הקבצים ב-Amazon S3 מתווספים, נמחקים או משתנים במרווחי זמן אקראיים. אם אתם צריכים לשלוט בתזמון של הרענון, למשל כדי להפעיל את הרענון בסוף של עבודת חילוץ, שינוי וטעינה, אתם יכולים להשתמש ברענון ידני.
לרענונים ידניים, מריצים את הפרוצדורה
BQ.REFRESH_EXTERNAL_METADATA_CACHEשל המערכת כדי לרענן את מטמון המטא-נתונים לפי לוח זמנים שעונה על הדרישות שלכם. רענון ידני של המטמון הוא גישה טובה אם הקבצים ב-Amazon S3 מתווספים, נמחקים או משתנים במרווחי זמן ידועים, למשל כפלט של צינור.אם תבצעו כמה רענונים ידניים בו-זמנית, רק אחד מהם יצליח.
אם לא מרעננים את מטמון המטא-נתונים, התוקף שלו פג אחרי 7 ימים.
רענון ידני ואוטומטי של מטמון מתבצעים עם עדיפות לשאילתות INTERACTIVE.
שימוש בהזמנות ב-BACKGROUND
אם בוחרים להשתמש ברענון אוטומטי, מומלץ ליצור מקום שמור, ואז ליצור הקצאה עם סוג העבודה BACKGROUND לפרויקט שמריץ את משימות הרענון של מטמון המטא-נתונים. עם BACKGROUND הזמנות, עבודות הרענון משתמשות במאגר משאבים ייעודי, וכך הן לא מתחרות עם שאילתות של משתמשים, וגם לא עלולות להיכשל אם אין מספיק משאבים זמינים עבורן.
השימוש במאגר משבצות משותף לא כרוך בעלויות נוספות, אבל שימוש בBACKGROUNDהזמנות מספק ביצועים עקביים יותר כי הוא מקצה מאגר משאבים ייעודי, ומשפר את המהימנות של עבודות הרענון ואת היעילות הכוללת של השאילתות ב-BigQuery.
לפני שמגדירים את הערכים של מרווח הרענון ומצב שמירת המטא-נתונים במטמון, חשוב להבין איך הם ישפיעו זה על זה. מומלץ להביא בחשבון את הדוגמאות הבאות:
- אם אתם מרעננים ידנית את מטמון המטא-נתונים של טבלה, והגדרתם את מרווח הזמן של הנתונים המיושנים ליומיים, אתם צריכים להריץ את
BQ.REFRESH_EXTERNAL_METADATA_CACHEהפרוצדורה של המערכת כל יומיים או פחות, אם אתם רוצים שהפעולות בטבלה ישתמשו במטא-נתונים שנשמרו במטמון. - אם אתם מרעננים באופן אוטומטי את מטמון המטא-נתונים של טבלה, והגדרתם את מרווח הזמן של הנתונים המיושנים ל-30 דקות, יכול להיות שחלק מהפעולות שלכם בטבלה יקראו מ-Amazon S3 אם רענון מטמון המטא-נתונים יימשך יותר מהטווח הרגיל של 30 עד 60 דקות.
כדי למצוא מידע על עבודות רענון של מטא-נתונים, מריצים שאילתה על התצוגה INFORMATION_SCHEMA.JOBS, כמו בדוגמה הבאה:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
מידע נוסף זמין במאמר בנושא שמירה במטמון של מטא-נתונים.
טבלאות עם מטמון ותצוגות חומריות
אתם יכולים להשתמש בתצוגות חומריות על טבלאות עם מטמון מטא-נתונים של Amazon Simple Storage Service (Amazon S3) כדי לשפר את הביצועים והיעילות כשמבצעים שאילתות על נתונים מובנים שמאוחסנים ב-Amazon S3. התצוגות המגובות האלה פועלות כמו תצוגות מגובות בטבלאות אחסון שמנוהלות על ידי BigQuery, כולל היתרונות של רענון אוטומטי והתאמה חכמה.
כדי להפוך נתונים מ-Amazon S3 בתצוגה חומרית לזמינים באזור נתמך ב-BigQuery לצירופים, צריך ליצור העתק של התצוגה החומרית. אפשר ליצור עותקים של תצוגות מהותיות רק על בסיס תצוגות מהותיות מורשות.
מגבלות
בנוסף למגבלות על טבלאות BigLake, המגבלות הבאות חלות על BigQuery Omni, שכולל טבלאות BigLake שמבוססות על נתונים מ-Amazon S3 ומ-Blob Storage:
- מהדורות Standard ו-Enterprise Plus לא תומכות בעבודה עם נתונים באף אחד מהאזורים של BigQuery Omni. מידע נוסף על מהדורות זמין במאמר מבוא למהדורות BigQuery.
- התצוגות
OBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGEו-PARTITIONSINFORMATION_SCHEMAלא זמינות לטבלאות BigLake שמבוססות על נתונים מ-Amazon S3 ומ-Blob Storage. - אין תמיכה בתצוגות חומריות ב-Blob Storage.
- אין תמיכה בפונקציות מוגדרות על ידי המשתמש (UDF) ב-JavaScript.
אין תמיכה בהצהרות ה-SQL הבאות:
- הצהרות של BigQuery ML.
- הצהרות של שפת הגדרת נתונים (DDL)
שדורשות נתונים שמנוהלים ב-BigQuery. לדוגמה,
CREATE EXTERNAL TABLE,CREATE SCHEMAאוCREATE RESERVATIONנתמכים, אבלCREATE TABLEלא נתמך. - פקודות בשפת טיפול בנתונים (DML).
ההגבלות הבאות חלות על שאילתות וקריאה של טבלאות זמניות ביעד:
- אין תמיכה בשאילתות של טבלאות זמניות של יעד באמצעות ההצהרה
SELECT.
- אין תמיכה בשאילתות של טבלאות זמניות של יעד באמצעות ההצהרה
שאילתות מתוזמנות נתמכות רק באמצעות ה-API או שיטת ה-CLI. האפשרות טבלת היעד מושבתת בשאילתות. מותר להשתמש רק בשאילתות
EXPORT DATA.BigQuery Storage API לא זמין באזורים של BigQuery Omni.
אם השאילתה משתמשת בסעיף
ORDER BYוגודל התוצאה שלה גדול מ-256 MB, השאילתה תיכשל. כדי לפתור את הבעיה, צריך לצמצם את גודל התוצאה או להסיר את סעיףORDER BYמהשאילתה. מידע נוסף על מכסות ב-BigQuery Omni זמין במאמר מכסות ומגבלות.אין תמיכה בשימוש במפתחות הצפנה בניהול הלקוח (CMEK) עם מערכי נתונים וטבלאות חיצוניות.
תמחור
מידע על תמחור ומבצעים לזמן מוגבל ב-BigQuery Omni זמין במאמר תמחור ב-BigQuery Omni.
מכסות ומגבלות
מידע על מכסות ב-BigQuery Omni זמין במאמר מכסות ומגבלות.
אם תוצאת השאילתה גדולה מ-20 GiB, כדאי לייצא את התוצאות אל Amazon S3 או אל Blob Storage. מידע על מכסות של BigQuery Connection API זמין במאמר בנושא BigQuery Connection API.
מיקומים
מערכת BigQuery Omni מעבדת שאילתות באותו מיקום של מערך הנתונים שמכיל את הטבלאות שאתם שולחים לגביהן שאילתות. אחרי שיוצרים את מערך הנתונים, אי אפשר לשנות את המיקום. הנתונים שלכם נמצאים בחשבון AWS או Azure שלכם. אזורים ב-BigQuery Omni תומכים בהזמנות של מהדורת Enterprise ובתמחור של מחשוב על פי דרישה (ניתוח). מידע נוסף על מהדורות זמין במאמר מבוא למהדורות BigQuery.
| תיאור האזור | שם האזור | אזור BigQuery שמוקם באותו מיקום | |
|---|---|---|---|
| AWS | |||
| AWS – מזרח ארה"ב (צפון וירג'יניה) וירג'יניה) | aws-us-east-1 |
us-east4 |
|
| AWS - US West (Oregon) | aws-us-west-2 |
us-west1 |
|
| AWS - Asia Pacific (Seoul) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS - Asia Pacific (Sydney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - Europe (Ireland) | aws-eu-west-1 |
europe-west1 |
|
| AWS - Europe (Frankfurt) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure - East US 2 | azure-eastus2 |
us-east4 |
|
המאמרים הבאים
- איך מתחברים ל-Amazon S3 ול-Blob Storage
- איך יוצרים טבלאות BigLake ב-Amazon S3 וב-Blob Storage
- כך שולחים שאילתות לטבלאות BigLake ב-Amazon S3 וב-Blob Storage.
- איך מצטרפים לטבלאות של Amazon S3 ולטבלאות של Blob Storage BigLake באמצעות טבלאות של Google Cloud שימוש בצירופים של BigQuery Omni.
- איך מייצאים תוצאות של שאילתות ל-Amazon S3 ול-Blob Storage
- איך מעבירים נתונים מ-Amazon S3 ומ-Blob Storage ל-BigQuery
- מידע נוסף על הגדרת גבולות גזרה של VPC Service Controls
- איך מציינים את המיקום