
透過模型蒸餾技術,盡可能降低 AI 函式成本
本文說明如何在 BigQuery 中使用受管理 AI 函式的「最佳化模式」。與標準的逐列 LLM 推論相比,最佳化模式可大幅減少大型語言模型 (LLM) 權杖用量和查詢延遲時間,處理包含數千甚至數十億列的大規模資料集。這項最佳化功能僅適用於 AI.IF 和 AI.CLASSIFY 函式。
如要進一步瞭解詞元用量,您可以在Google Cloud 控制台中查看查詢使用的詞元數。如要在執行查詢前估算用量,請使用 AI.COUNT_TOKENS 函式。
以下範例說明如何搭配最佳化模式使用 AI.IF 函式,並以 text-embedding-005 做為嵌入模型,找出有關天災的新聞報導:
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
optimization_mode => 'MINIMIZE_COST' 引數會啟用最佳化模式。提供嵌入內容時,這是預設設定,因此您可以省略這個引數。
在本範例中,系統會即時生成嵌入。在實務上,我們建議您具體化嵌入項目,以便重複使用。
最佳化模式的運作方式
受管理 AI 函式 AI.IF 和 AI.CLASSIFY 通常會為資料集中的每個資料列呼叫遠端 LLM。使用最佳化模式時,BigQuery 會在查詢執行期間自動訓練輕量型精簡模型。
程序如下:
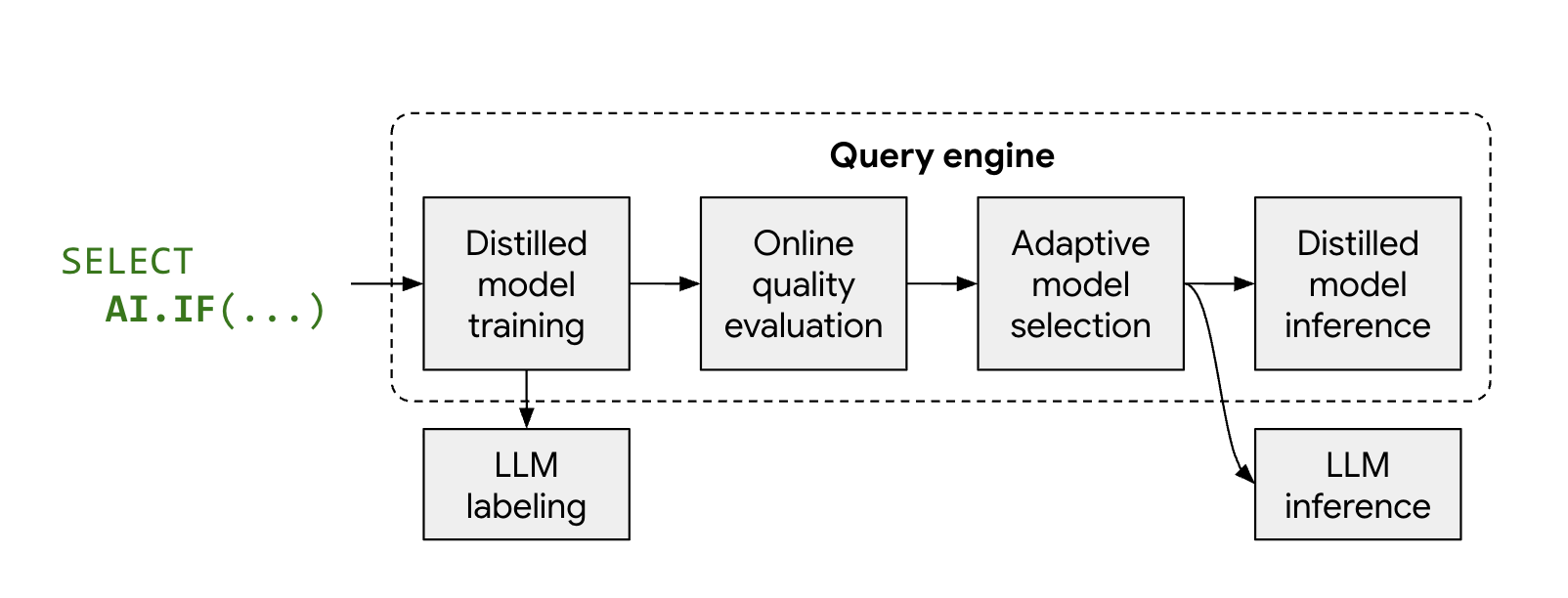
- 取樣和標記:BigQuery 會選取一小部分代表性樣本的資料,並呼叫 Gemini 提供標籤。
- 模型蒸餾訓練:使用 LLM 標籤和資料嵌入做為特徵,即時訓練本機蒸餾模型。
- 品質檢查:BigQuery 會根據 LLM 的結果評估精簡模型的準確度。根據預設,如果精簡模型未達到必要的品質門檻,查詢就會失敗,並顯示錯誤訊息說明模型遭到捨棄的原因。如果模型品質可接受,BigQuery 仍可能會針對特定資料列改用遠端 LLM,以維持一致的品質,或處理缺少有效嵌入的資料列。
- 推論:蒸餾模型會處理大部分資料列,大幅減少 Gemini 呼叫次數。
限制
最佳化模式有下列限制:
- 最少資料列數:AI 函式的輸入內容必須包含約 3,000 列,確保模型訓練有足夠的資料。
- 資料類型:如果提示參照多個資料欄,最佳化功能只支援字串資料欄。
- 多標籤分類:最佳化模式不支援
AI.CLASSIFY與output_mode => 'multi'。 - 函式支援:只有
AI.IF和AI.CLASSIFY函式支援最佳化模式;不過,如果使用AI.CLASSIFY搭配最佳化模式,且精簡模型品質不足,查詢可能會失敗。 - 錯誤比率:最佳化模式不支援
max_error_ratio引數。
事前準備
如要取得在 BigQuery 中執行代管 AI 函式所需的權限,請參閱為呼叫 Gemini Enterprise Agent Platform LLM 的生成式 AI 函式設定權限。
選擇嵌入模型
如要使用最佳化模式,您必須計算資料的嵌入,並提供給 AI 函式。如要讓輸入資料欄有相關聯的嵌入,所有資料列都必須有相同的嵌入維度,且由相同的嵌入模型生成。
為獲得最佳成本效益和擴充性,建議您使用嵌入模型 (例如 text-embedding-005 或 Gemini 嵌入模型) 計算資料的嵌入內容,以處理英文或多語言工作。如果是多模態資料 (文字和圖片),請使用多模態嵌入模型,例如 multimodalembedding@001。
生成嵌入項目
您可以透過 BigQuery 管理的自主生成功能,計算資料的嵌入內容,也可以手動建立嵌入內容資料欄。以下各節說明如何搭配使用 AI.CLASSIFY 和 AI.IF 函式,採用這兩種方法。
自主生成嵌入
如果您使用自主生成嵌入,BigQuery 會在呼叫 AI.IF 或 AI.CLASSIFY 時自動使用嵌入。這是建議做法,但每個資料表只能有一個嵌入資料欄。
下列範例會使用 text-embedding-005 做為嵌入模型,建立具有自主產生嵌入資料欄的資料表,然後使用 AI.CLASSIFY 函式將資料分類:
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
手動指定資料欄
如果您有現有的嵌入資料欄,請在 AI.IF 或 AI.CLASSIFY 的 embeddings 引數中指定該資料欄。您可以使用 AI.EMBED 函式產生這個項目。
以下範例說明如何使用 text-embedding-005 做為嵌入模型,建立含有嵌入資料欄的資料表,然後在 AI.CLASSIFY 查詢中使用該資料欄:
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
如果提示參照多個資料欄,請在 embeddings 引數中提供資料欄名稱清單和對應的嵌入。例如:embeddings => [('body', body_embedding), ('title', title_embedding)]。
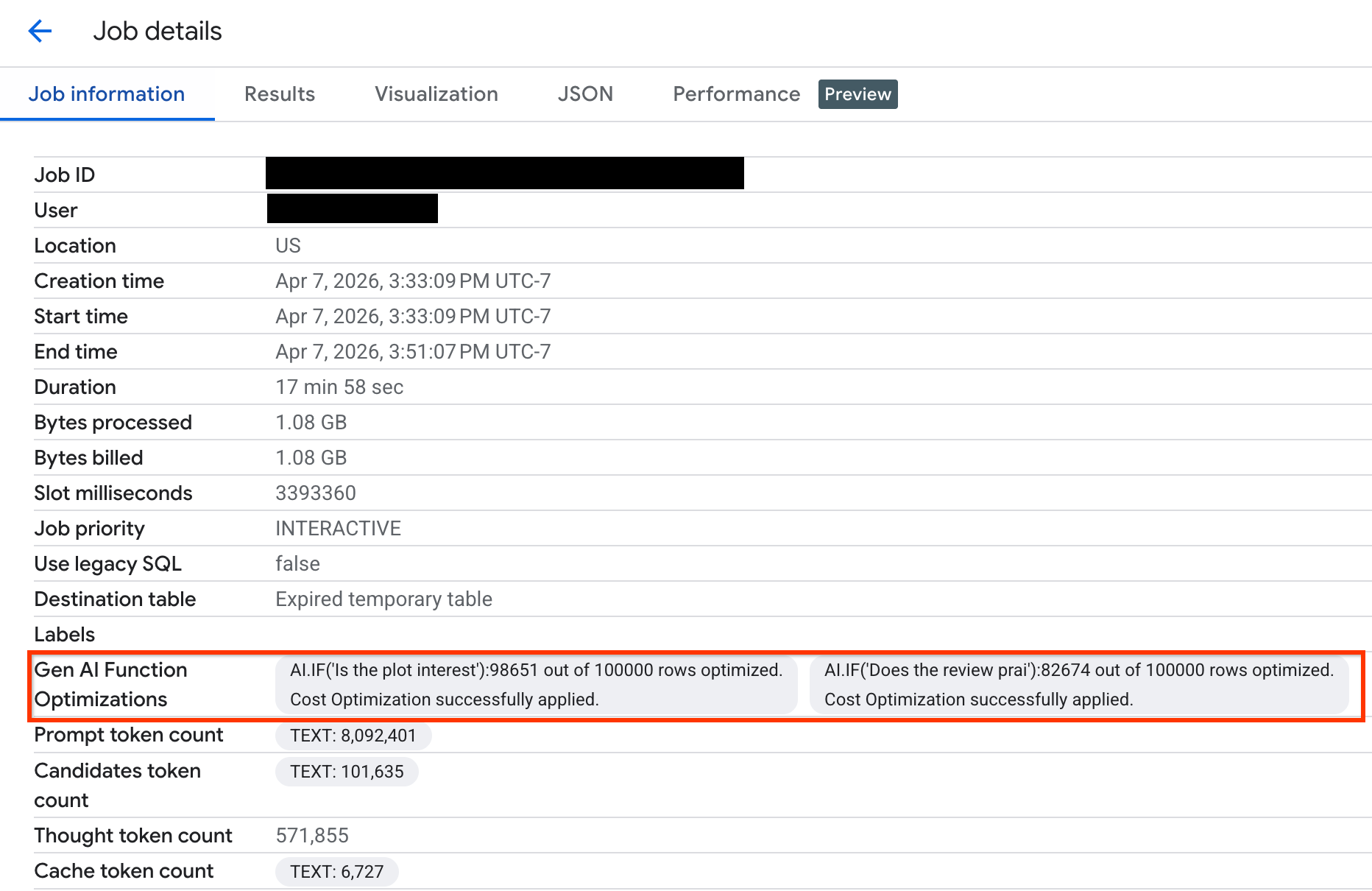
監控查詢最佳化
如要確認查詢執行期間最佳化的資料列數量,請在 Google Cloud 控制台或透過 API 查看執行統計資料:
控制台
如要查看最佳化處理的資料列數量,以及系統傳送的最佳化狀態訊息,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
在導覽選單中,按一下「Jobs explorer」(工作探索工具)。
按一下工作 ID,即可查看「工作詳細資料」窗格。
按一下「工作資訊」分頁,然後在「生成式 AI 函式最佳化調整」欄位中查看指標和狀態。
API
檢查工作的中繼資料物件中的 FunctionGenAiCostOptimizationStats。GenAIFunctionStats這個物件包含透過最佳化工作流程推斷的列數,以及提供最佳化狀態深入分析資訊的系統產生訊息。
疑難排解
下列各節說明如何診斷及解決使用最佳化模式時的常見問題。
資料大小過小
問題:模型訓練資料不足。您可能會看到下列錯誤訊息:Fail to apply cost optimization because the data size is too
small.
解決方案:將輸入內容的大小增加至約 3,000 個資料列,並確認所有資料列都已正確產生有效的嵌入。
部分類別的樣本很少或沒有
問題:在取樣階段,特定類別的樣本數量不足,導致無法訓練模型。您可能會看到以下錯誤訊息:Fail to apply cost optimization because some classes have
few or no samples.
解決方法:
- 從
AI.CLASSIFY函式呼叫中移除罕見或空白的類別。 - 將罕見類別歸入較廣泛的類別,以增加樣本大小。你可以使用「
OTHER」類別,將不屬於更具體類別的項目歸類。不過,如果類別清單已完整,請勿新增OTHER,因為這個字詞意義含糊不清,可能會造成混淆。
嵌入項目的維度不一致
問題:各資料列的嵌入維度不一致。您可能會看到下列錯誤訊息:Fail to apply cost optimization
because the embeddings have inconsistent dimensions.
解決方法:確認嵌入是由相同模型產生,且嵌入向量長度相同。您可以執行類似下列的 SQL 查詢,確認資料欄中的嵌入內容長度相同:
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
提示過於複雜
問題:精簡模型無法達到高準確度門檻。您可能會看到下列錯誤訊息:Fail to apply cost optimization
because the prompt complexity is too high.
解決方法:
使用一組構成分區的類別。請確保類別重疊程度最低,並涵蓋所有可能的輸入內容。
- 避免類別重疊,導致輸入內容可能同時屬於多個類別。舉例來說,請避免使用
['terrible', 'bad', 'okay', 'good', 'excellent']等類別。 - 避免出現沒有適用類別的情況。舉例來說,類別清單
['bad', 'average']未涵蓋表示讚美的評論。 提供類別說明,引導 LLM 解決類別之間的模糊不清問題。例如:
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- 避免類別重疊,導致輸入內容可能同時屬於多個類別。舉例來說,請避免使用
嘗試使用更進階的嵌入模型,例如
text-embedding-005或multimodalembedding。如需其他偵錯協助,請傳送電子郵件至 bqml-feedback@google.com。
LLM 處理的資料列數量超出預期
問題:查詢執行統計資料顯示,遠端 LLM 處理的資料列數量異常高,而非精簡模型。可能原因如下:
- 精簡模型已順利完成訓練,但部分資料列缺少嵌入內容。這些資料列會由遠端 LLM 處理。
- 無法為每個資料列套用精簡模型,因此必須改用遠端 LLM,才能維持一致的品質。
解決方法:確認所有資料列的嵌入內容都已正確產生且有效。如果問題仍未解決,請傳送電子郵件至 bqml-feedback@google.com 進行偵錯。
未偵測到自主嵌入資料欄
問題:BigQuery 無法偵測自主嵌入資料欄。如果指令碼使用臨時資料表,且原始資料表的參照遺失,就可能發生這種情況。
解決方案:使用 embeddings 參數明確傳遞自主嵌入資料欄,例如 embeddings => content_embedding.result,這會觸發成本最佳化。
後續步驟
- 進一步瞭解 BigQuery 中的生成式 AI。
- 請參閱
AI.IF函式說明文件。 - 請參閱
AI.CLASSIFY函式說明文件。