
AI 함수 비용 최적화
이 문서에서는 BigQuery에서 관리형 AI 함수에 최적화된 모드를 사용하는 방법을 설명합니다. 이 모드를 사용하면 표준 행별 LLM 추론에 비해 대규모 언어 모델 (LLM) 토큰 소비와 쿼리 지연 시간이 크게 줄어든 수천 또는 수십억 개의 행이 포함된 대규모 데이터 세트를 처리할 수 있습니다.
다음 예에서는 최적화된 모드에서 AI.IF 함수
를 사용하여 text-embedding-005
를 임베딩 모델로 사용하여 자연재해에 관한 뉴스 기사를 식별하는 방법을 보여줍니다.
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
optimization_mode => 'MINIMIZE_COST' 인수를 사용하면 최적화된
모드가 사용 설정됩니다. 임베딩이 제공될 때 기본 설정이므로 이 인수를 생략할 수 있습니다.
이 예에서는 임베딩이 즉석에서 생성됩니다. 실제로 임베딩을 재사용할 수 있도록 구체화하는 것이 좋습니다.
최적화된 모드의 작동 방식
관리형 AI 함수인 AI.IF 및 AI.CLASSIFY는 일반적으로 데이터 세트의 모든 행에 대해 원격 LLM을 호출합니다. 최적화된 모드를 사용하면 BigQuery가 쿼리 실행 중에 경량의 증류 모델을 자동으로 학습시킵니다.
프로세스는 다음과 같습니다.
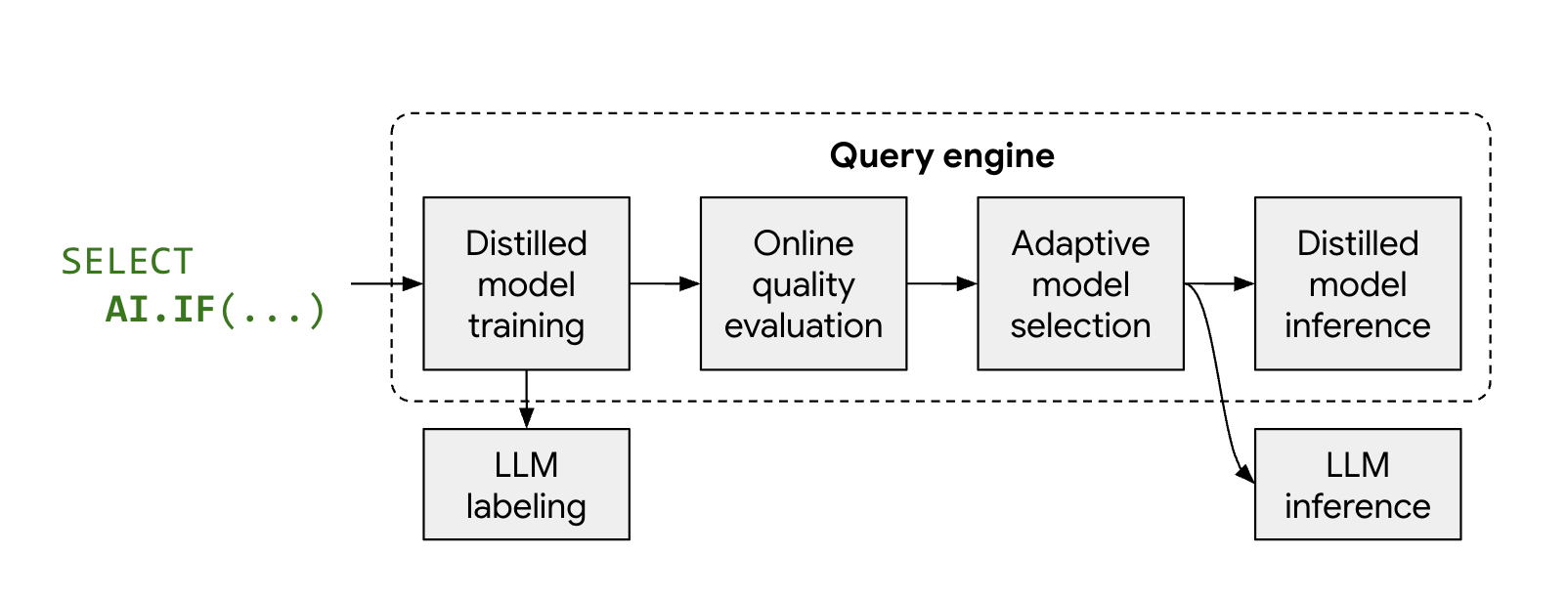
- 샘플링 및 라벨링: BigQuery는 데이터의 작은 대표 샘플을 선택하고 Gemini를 호출하여 라벨을 제공합니다.
- 증류 모델 학습: LLM 라벨과 데이터 임베딩을 특성으로 사용하여 적시에 로컬 증류 모델이 학습됩니다.
- 품질 검사: BigQuery는 증류 모델의 정확성을 LLM의 결과와 비교하여 평가합니다. 기본적으로 증류 모델이 필요한 품질 기준점을 충족하지 못하면 모델이 삭제된 이유를 설명하는 오류와 함께 쿼리가 실패합니다. 모델의 품질이 허용 가능한 경우 BigQuery는 일관된 품질을 유지하기 위해 또는 유효한 임베딩이 없는 행에 대해 특정 행의 원격 LLM으로 대체될 수 있습니다.
- 추론: 증류 모델은 대부분의 행을 처리하여 Gemini 호출 수를 크게 줄입니다.
제한사항
최적화된 모드에는 다음과 같은 제한사항이 있습니다.
- 최소 행 수: 모델 학습에 충분한 데이터를 확보하려면 AI 함수의 입력에 약 3,000개의 행이 포함되어야 합니다.
- 데이터 유형: 여러 열을 참조하는 프롬프트의 경우 최적화에 문자열 열만 지원됩니다.
- 멀티 라벨 분류:
AI.CLASSIFYoutput_mode => 'multi'최적화된 모드에서는 지원되지 않습니다. - 함수 지원:
AI.IF및AI.CLASSIFY함수만 최적화된 모드를 지원합니다. 하지만AI.CLASSIFY에서 최적화된 모드를 사용하는 경우 증류 모델 품질이 충분하지 않으면 쿼리가 실패할 수 있습니다. - 오류 비율:
max_error_ratio인수는 최적화된 모드에서는 지원되지 않습니다.
시작하기 전에
BigQuery에서 관리형 AI 함수를 실행하는 데 필요한 권한을 얻으려면 Gemini Enterprise Agent Platform LLM을 호출하는 생성형 AI 함수에 대한 권한 설정을 참고하세요.
임베딩 모델 선택
최적화된 모드를 사용하려면 데이터의 임베딩을 계산하고 AI 함수에 제공해야 합니다. 입력 열에 연결된 임베딩이 있으려면 모든 행에 일관된 임베딩 측정기준이 있어야 하며 동일한 임베딩 모델에서 생성되어야 합니다.
최적의 비용 품질과 확장성을 위해 임베딩 모델(예: text-embedding-005 또는 Gemini 임베딩)을 사용하여 데이터의 임베딩을 계산하는 것이 좋습니다. 멀티모달 데이터 (텍스트 및 이미지)의 경우
multimodalembedding@001과 같은 멀티모달 임베딩 모델을 사용합니다.
임베딩 생성
BigQuery에서 관리하는 자율 생성을 사용하거나 임베딩 열을 수동으로 만들어 데이터의 임베딩을 계산할 수 있습니다.
다음 섹션에서는 AI.CLASSIFY 및 AI.IF 함수에서 두 가지 접근 방식을 모두 사용하는 방법을 설명합니다.
자율 임베딩 생성
자율 임베딩 생성을 사용하는 경우 BigQuery는 AI.IF 또는
AI.CLASSIFY가 호출될 때 임베딩을 자동으로 사용합니다. 이 방법이 권장되지만 테이블당 하나의 임베딩 열로 제한됩니다.
다음 예에서는 text-embedding-005를 임베딩 모델로 사용하여 자율적으로 생성된 임베딩 열이 있는 테이블을 만든 다음 AI.CLASSIFY 함수를 사용하여 데이터를 분류합니다.
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
수동 열 사양
기존 임베딩 열이 있는 경우 AI.IF 또는 AI.CLASSIFY의 embeddings 인수에 지정합니다. 이를
AI.EMBED 함수를 사용하여 생성할 수 있습니다.
다음 예에서는 text-embedding-005를 임베딩 모델로 사용하여 임베딩 열이 있는 테이블을 만든 다음 AI.CLASSIFY 쿼리에서 해당 열을 사용하는 방법을 보여줍니다.
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
프롬프트가 여러 열을 참조하는 경우 embeddings 인수에 열 이름 목록과 해당 임베딩을 제공합니다. 예를 들면:
embeddings => [('body', body_embedding), ('title', title_embedding)]입니다.
쿼리 최적화 모니터링
쿼리 실행 중에 최적화된 행 수를 확인하려면 콘솔 또는 API를 통해 실행 통계를 확인하면 됩니다. Google Cloud
콘솔
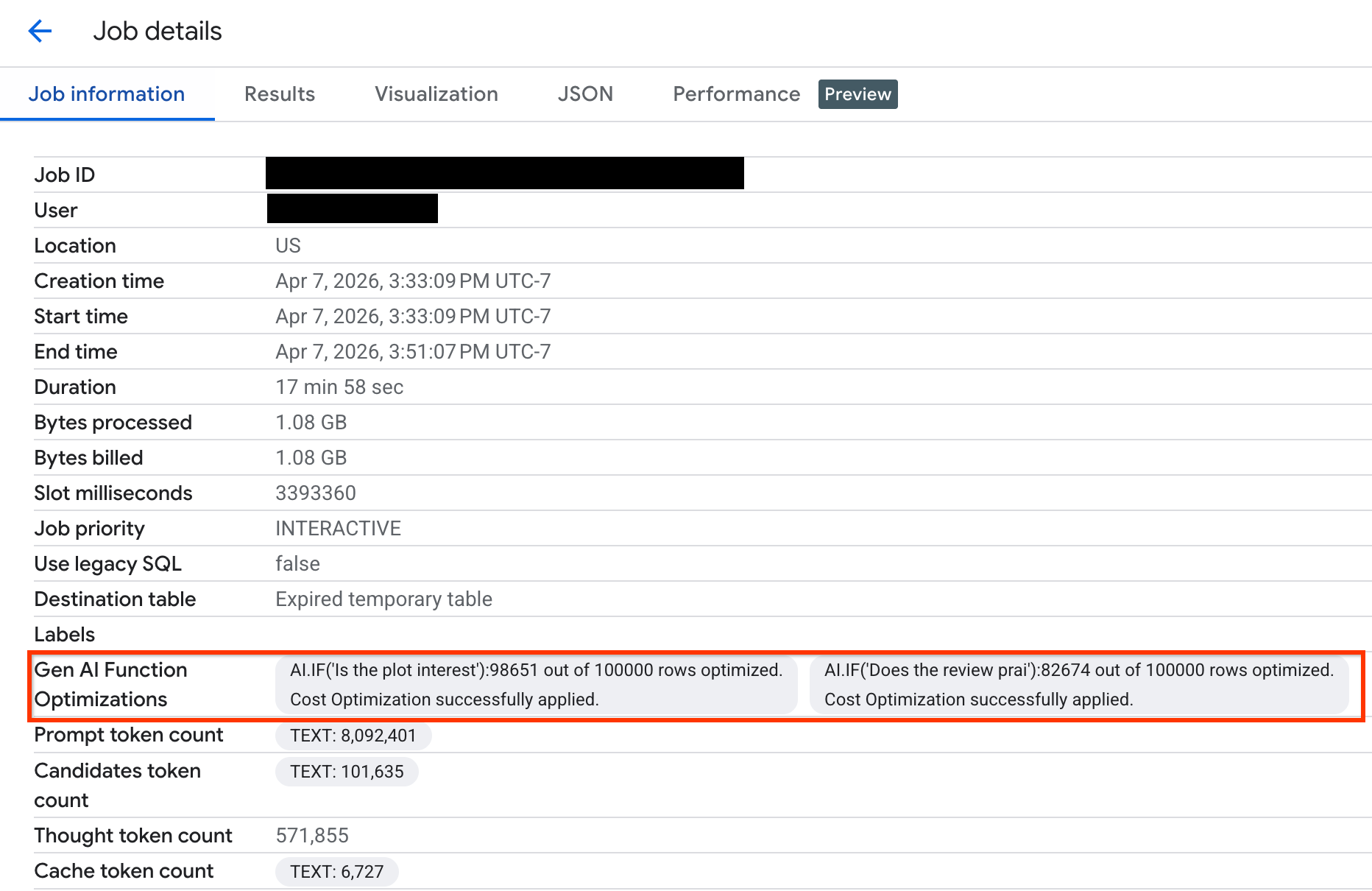
최적화된 행 수를 확인하고 최적화 상태에 관한 시스템 메시지를 보려면 다음 단계를 따르세요.
콘솔에서 Google Cloud BigQuery 페이지로 이동합니다.
탐색 메뉴에서 작업 탐색기 를 클릭합니다.
작업 ID를 클릭하여 작업 세부정보 창을 확인합니다.
작업 정보 탭을 클릭하고 생성형 AI 함수 최적화 필드에서 측정항목과 상태를 확인합니다.
API
작업 메타데이터의 GenAIFunctionStats 객체에서 FunctionGenAiCostOptimizationStats를 확인합니다. 이 객체에는 최적화된 워크플로를 통해 추론된 행 수와 최적화 상태에 관한 통계를 제공하는 시스템 생성 메시지가 포함되어 있습니다.
문제 해결
다음 섹션에서는 최적화된 모드 사용과 관련된 일반적인 문제를 진단하고 해결하는 방법을 설명합니다.
데이터 크기가 너무 작음
문제: 모델 학습에 데이터가 충분하지 않습니다. 다음과 같은
오류 메시지가 표시될 수 있습니다. Fail to apply cost optimization because the data size is too
small.
해결 방법: 입력 크기를 약 3,000개의 행으로 늘리고 모든 행에 유효한 임베딩이 올바르게 생성되었는지 확인합니다.
일부 클래스에 샘플이 거의 또는 전혀 없음
문제: 샘플링 단계에서 특정 카테고리의 샘플 수가 충분하지 않아 모델 학습이 불가능합니다. 다음과 같은
오류 메시지가 표시될 수 있습니다. Fail to apply cost optimization because some classes have
few or no samples.
해결 방법:
AI.CLASSIFY함수 호출에서 드문 카테고리 또는 빈 카테고리를 삭제합니다.- 드문 카테고리를 더 넓은 카테고리로 그룹화하여 샘플 크기를 늘립니다.
OTHER카테고리를 사용하여 더 구체적인 카테고리에서 다루지 않는 항목을 그룹화할 수 있습니다. 하지만 카테고리 목록이 이미 완료된 경우OTHER를 추가하지 마세요. 이 용어는 모호하며 혼동을 야기할 수 있습니다.
임베딩의 측정기준이 일관되지 않음
문제: 행 간의 임베딩 측정기준이 일관되지 않습니다. `Fail to apply cost optimization
because the embeddings have inconsistent dimensions.`이라는 오류 메시지가 표시될 수 있습니다.
해결 방법: 임베딩이 동일한 모델에서 생성되고 임베딩 벡터 길이가 동일한지 확인합니다. 다음과 유사한 SQL 쿼리를 사용하여 열의 임베딩 길이가 동일한지 확인할 수 있습니다.
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
프롬프트 복잡성이 너무 높음
문제: 증류 모델이 높은 정확성 기준점을 달성할 수 없습니다. `Fail to apply cost optimization
because the prompt complexity is too high.`이라는 오류 메시지가 표시될 수 있습니다.
해결 방법:
파티션을 구성하는 카테고리 집합을 사용합니다. 카테고리가 최소한으로 겹치고 가능한 모든 입력을 포함하는지 확인합니다.
- 입력이 여러 카테고리에 동시에 속할 수 있는 겹치는 카테고리는 피합니다. 예를 들어
['terrible', 'bad', 'okay', 'good', 'excellent']와 같은 카테고리는 피합니다. - 적용되는 카테고리가 없는 간격은 피합니다. 예를 들어
카테고리
['bad', 'average']목록은 칭찬을 표현하는 리뷰를 다루지 않습니다. 카테고리 간의 모호성을 해결하도록 LLM을 안내하는 카테고리 설명을 제공합니다. 예를 들면 다음과 같습니다.
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- 입력이 여러 카테고리에 동시에 속할 수 있는 겹치는 카테고리는 피합니다. 예를 들어
text-embedding-005또는multimodalembedding과 같은 고급 임베딩 모델을 사용해 보세요.추가 디버깅 지원을 받으려면 bqml-feedback@google.com 으로 문의하세요.
LLM에서 처리한 행 수가 예상과 다름
문제: 쿼리 실행 통계에 증류 모델 대신 원격 LLM에서 예상보다 많은 행이 처리된 것으로 표시됩니다. 이는 다음과 같은 이유 때문일 수 있습니다.
- 증류 모델이 학습되었지만 일부 행에 임베딩이 누락되었습니다. 이러한 행은 원격 LLM에서 처리됩니다.
- 증류 모델을 각 행에 적용할 수 없었으며 일관된 품질을 유지하기 위해 원격 LLM으로 대체해야 했습니다.
해결 방법: 데이터의 모든 행에 임베딩이 올바르게 생성되고 유효한지 확인합니다. 문제가 계속되면 디버깅을 위해 bqml-feedback@google.com으로 문의하세요.
자율 임베딩 열이 감지되지 않음
문제: BigQuery에서 자율 임베딩 열을 감지할 수 없습니다. 스크립트에서 임시 테이블을 사용하고 원본 테이블에 대한 참조가 손실된 경우 이 문제가 발생할 수 있습니다.
해결 방법: embeddings 매개변수를 사용하여 자율
임베딩 열(예: embeddings => content_embedding.result)을 명시적으로 전달합니다. 이렇게 하면 비용 최적화가 트리거됩니다.
다음 단계
- BigQuery의 생성형 AI에 대해 자세히 알아보기
AI.IF함수 문서를 참고하세요.AI.CLASSIFY함수 문서를 참고하세요.