
Schema und Daten aus Teradata migrieren
Durch die Kombination des BigQuery Data Transfer Service und eines speziellen Migrations-Agents können Sie Ihre Daten von einer lokalen Teradata Data Warehouse-Instanz nach BigQuery kopieren. In diesem Dokument wird der schrittweise Prozess der Datenmigration aus Teradata mithilfe des BigQuery Data Transfer Service beschrieben.
Hinweis
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator) and the Project IAM Admin role (roles/resourcemanager.projectIamAdmin). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the BigQuery, BigQuery Data Transfer Service, Cloud Storage, and Pub/Sub APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator) and the Project IAM Admin role (roles/resourcemanager.projectIamAdmin). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the following roles to the service account: roles/bigquery.user, roles/storage.objectAdmin, roles/iam.serviceAccountTokenCreator.
To grant a role, find the Select a role list, then select the role.
To grant additional roles, click Add another role and add each additional role.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
Erforderliche Berechtigungen festlegen
Achten Sie darauf, dass das Hauptkonto, das die Übertragung erstellt, die folgenden Rollen in dem Projekt hat, das den Übertragungsjob enthält:
- Loganzeige (
roles/logging.viewer) - Storage-Administrator (
roles/storage.admin) oder eine benutzerdefinierte Rolle mit folgenden Berechtigungen:storage.objects.createstorage.objects.getstorage.objects.list
- BigQuery-Administrator (
roles/bigquery.admin) oder eine benutzerdefinierte Rolle, die folgende Berechtigungen gewährt:bigquery.datasets.createbigquery.jobs.createbigquery.jobs.getbigquery.jobs.listAllbigquery.tables.getbigquery.transfers.getbigquery.transfers.update
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihrer Daten. Sie müssen keine Tabellen erstellen.
Cloud Storage-Bucket erstellen
Erstellen Sie einen Cloud Storage-Bucket für das Staging der Daten während des Übertragungsjobs.
Lokale Umgebung vorbereiten
Führen Sie die Aufgaben in diesem Abschnitt aus, um Ihre lokale Umgebung für den Übertragungsjob vorzubereiten.
Lokale Anforderungen an Maschinen
- Der Migrations-Agent verwendet eine JDBC-Verbindung mit der Teradata-Instanz und Google Cloud -APIs. Achten Sie darauf, dass der Netzwerkzugriff nicht von einer Firewall blockiert wird.
- Prüfen Sie, ob die Java-Laufzeitumgebung 8 oder höher installiert ist.
- Achten Sie darauf, dass Sie genügend Speicherplatz für die ausgewählte Extraktionsmethode haben, wie unter Extraktionsmethode beschrieben.
- Wenn Sie sich für die TPT-Extraktion (Teradata Parallel Transporter) entscheiden, muss das Dienstprogramm
tbuildinstalliert sein. Weitere Informationen zur Auswahl einer Extraktionsmethode finden Sie unter Extraktionsmethode.
Details zur Teradata-Verbindung
Sie benötigen den Nutzernamen und das Passwort eines Teradata-Nutzers mit Lesezugriff auf die Systemtabellen und die zu migrierenden Tabellen.
Sie müssen den Hostnamen und die Portnummer kennen, um eine Verbindung zur Teradata-Instanz herzustellen.
JDBC-Treiber herunterladen
Laden Sie die JDBC-Treiberdatei terajdbc4.jar von Teradata auf einen Computer herunter, der eine Verbindung zum Data Warehouse herstellen kann.
Legen Sie die Variable GOOGLE_APPLICATION_CREDENTIALS fest:
Legen Sie die Umgebungsvariable GOOGLE_APPLICATION_CREDENTIALS für den Dienstkontoschlüssel fest, den Sie im Abschnitt Vorbereitung heruntergeladen haben.
VPC Service Controls-Regel für ausgehenden Traffic aktualisieren
Fügen Sie der Regel für ausgehenden Traffic im VPC Service Controls-Perimeter das von BigQuery Data Transfer Service verwaltete Google Cloud Projekt für Ihre Region hinzu.
In der folgenden Tabelle sind die Projektnummern für die regionalen Standorte aufgeführt, die für Datenübertragungen verwendet werden. Fügen Sie die Projektnummern hinzu, die dem Standort Ihres Datasets entsprechen.
Multiregionale Standorte
| Beschreibung des multiregionalen Standorts | Name des multiregionalen Standorts | Projektnummern |
|---|---|---|
| Rechenzentren in Mitgliedsstaaten der Europäischen Union | eu |
17253722542 272853474138 420718595790 929473878322 990232121269 |
| Rechenzentren in den USA | us |
1005756709729 140222280645 247872939591 312976397333 521896999118 525821192359 892499355189 949134172629 990232121269 |
Regionale Standorte
| Beschreibung der Region | Name der Region | Projektnummern |
|---|---|---|
| Amerika | ||
| Montreal | northamerica-northeast1 |
603911341430 644379120249 665941355665 743643531530 990232121269 |
| Toronto | northamerica-northeast2 |
181203883014 569023246094 814935732186 833015518790 990232121269 |
| Mexiko | northamerica-south1 |
439376105624 737643102222 746316165749 863053761002 990232121269 |
| São Paolo | southamerica-east1 |
133435938206 376122552368 485381725001 796391836836 990232121269 |
| Santiago | southamerica-west1 |
1087357303029 348543783783 659924941015 862900136725 990232121269 |
| Iowa | us-central1 |
298453567688 788415223852 850878823175 986263347210 990232121269 |
| South Carolina | us-east1 |
1055108947046 1084124504460 335013112247 724101498857 990232121269 |
| Northern Virginia | us-east4 |
1029854080039 517474920593 970314007431 98298633330 990232121269 |
| Columbus, Ohio | us-east5 |
1018267783826 386306739011 420397636038 778968775575 990232121269 |
| Dallas | us-south1 |
1000457898916 1047122215716 241710172671 955278753983 990232121269 |
| Oregon | us-west1 |
232019391832 341405773774 376906440760 477215631937 990232121269 |
| Los Angeles | us-west2 |
1082081077124 593499865061 796558996990 812061960238 990232121269 |
| Salt Lake City | us-west3 |
34769458069 488393466740 870087576864 878441810105 990232121269 |
| Las Vegas | us-west4 |
219770299440 421529192039 516260452158 653925368482 990232121269 |
| Europa | ||
| Warschau | europe-central2 |
408105394529 556626738827 613447812609 875068591969 990232121269 |
| Finnland | europe-north1 |
1049140453480 148002628360 610856287987 657186468367 990232121269 |
| Stockholm | europe-north2 |
264708615094 275871864623 353052212156 915614473443 990232121269 |
| Madrid | europe-southwest1 |
1035291313153 1048466610864 16585749286 684773867031 990232121269 |
| Belgien | europe-west1 |
311010690362 337985836396 348525528820 874692481832 990232121269 |
| Berlin | europe-west10 |
1014021387408 1021109191575 1076988971454 965306537493 990232121269 |
| Turin | europe-west12 |
624998300135 664251133452 672417986210 702529954322 990232121269 |
| London | europe-west2 |
1013046052024 424062913611 625972158490 707263280432 990232121269 |
| Frankfurt | europe-west3 |
1087781646048 143240061766 312688138599 715827071311 990232121269 |
| Niederlande | europe-west4 |
110044889848 398757511504 557234723212 769143166592 990232121269 |
| Zürich | europe-west6 |
163551586425 378713015688 416925392034 669890417706 990232121269 |
| Mailand | europe-west8 |
103481800693 1082157965924 23655501621 555661886352 990232121269 |
| Paris | europe-west9 |
1085882338778 176207547936 221990904254 670920836007 990232121269 |
| Asiatisch-pazifischer Raum | ||
| Taiwan | asia-east1 |
21873972082 271898158674 389278959284 922460772707 990232121269 |
| Hongkong | asia-east2 |
263483805684 773980783174 865347783058 90665746791 990232121269 |
| Tokio | asia-northeast1 |
415417931028 53965067050 953665196151 983967577764 990232121269 |
| Osaka | asia-northeast2 |
205726704771 478186599828 57312416489 861476638029 990232121269 |
| Seoul | asia-northeast3 |
320159292295 548035635347 791473645597 935702892639 990232121269 |
| Mumbai | asia-south1 |
13592990997 229940966341 68960523189 901420668689 990232121269 |
| Delhi | asia-south2 |
496191507005 54806403576 741779061357 809478923584 990232121269 |
| Singapur | asia-southeast1 |
541653567103 60558171982 753901882843 944188302893 990232121269 |
| Jakarta | asia-southeast2 |
1074047252998 17464964742 271871433529 427023413305 990232121269 |
| Bangkok | asia-southeast3 |
1020436856624 355273974477 603543103680 777922772431 990232121269 |
| Sydney | australia-southeast1 |
163046745040 591848239128 623326425100 814418810594 990232121269 |
| Melbourne | australia-southeast2 |
1062391852597 441829466914 714897033691 748594785463 990232121269 |
| Naher Osten | ||
| Doha | me-central1 |
260539430499 380691191456 707684919235 799708208022 990232121269 |
| Dammam | me-central2 |
1067269861014 364585730608 702115426609 932431265647 990232121269 |
| Tel Aviv | me-west1 |
356023739839 748664533815 869899828196 940471234508 990232121269 |
| Afrika | ||
| Johannesburg | africa-south1 |
366497204741 900693348777 930834390708 990232121269 995904484959 |
| Sonstiges | ||
| AWS ap-northeast-2 | aws-ap-northeast-2 |
118757274428 227045504542 31525566793 415505940944 990232121269 |
| AWS ap-southeast-2 | aws-ap-southeast-2 |
179772227799 236687515237 779037664799 925378406445 990232121269 |
| AWS eu-central-1 | aws-eu-central-1 |
469423327197 5211207427 905007897524 989902812500 990232121269 |
| AWS eu-west-1 | aws-eu-west-1 |
477582827438 653238211450 795832028199 961178626984 990232121269 |
| AWS us-east-1 | aws-us-east-1 |
1005783963369 293187121246 622189180485 78860240845 990232121269 |
| AWS us-west-2 | aws-us-west-2 |
206681800614 264089603202 419256100048 79353630998 990232121269 |
| Azure – East US 2 | azure-eastus2 |
1021739993926 1054000274357 495696597482 590387575526 990232121269 |
| Azure westus2 | azure-westus2 |
118244543872 242088193076 278777007439 662989519829 990232121269 |
| Nur für interne Zwecke (europe-west15) | europe-west15 |
1075380375245 635354739083 663432613496 904125362271 990232121269 |
| Nur interner Standort (us-central2) | us-central2 |
1085843140251 269725830808 498892726043 68311303080 990232121269 |
| Nur für interne Zwecke (us-east7) | us-east7 |
173063949542 661852837608 704905947583 956740768291 990232121269 |
| Synthetischer Standort (us-synthetic1) | us-synthetic1 |
131957618958 250975404179 740244847288 787843086952 990232121269 |
| Nur für interne Zwecke (us-west8) | us-west8 |
13105749132 248649202605 477355088721 653053504449 990232121269 |
Für die Kommunikation zwischen dem lokal ausgeführten Agent und dem BigQuery Data Transfer Service wird Pub/Sub-Nachrichten in einem Übertragungsthema veröffentlicht. BigQuery Data Transfer Service muss Befehle an den Agent senden, um Daten zu extrahieren. Außerdem muss der Agent Nachrichten zurück in BigQuery Data Transfer Service veröffentlichen, um den Status zu aktualisieren und Antworten zur Datenextraktion zurückzugeben.
Benutzerdefinierte Schemadatei erstellen
Wenn Sie anstelle der automatischen Schemaerkennung eine benutzerdefinierte Schemadatei verwenden möchten, erstellen Sie sie manuell oder lassen Sie den Migrations-Agent bei der Initialisierung des Agent eine erstellen.
Wenn Sie eine Schemadatei manuell erstellen und die Google Cloud -Konsole zum Erstellen einer Übertragung verwenden möchten, laden Sie die Schemadatei in einen Cloud Storage-Bucket in dem Projekt hoch, das Sie für die Übertragung verwenden möchten.
Den Migrations-Agent herunterladen
Laden Sie den Migrations-Agent auf einen Computer herunter, der eine Verbindung zum Data Warehouse herstellen kann. Verschieben Sie die JAR-Datei des Migrations-Agent in dasselbe Verzeichnis wie die Teradata-JAR-Datei des JDBC-Treibers.
Datei mit Anmeldedaten für das Zugriffsmodul einrichten
Eine Anmeldedatei ist erforderlich, wenn Sie das Zugriffsmodul für Cloud Storage mit dem TPT-Dienstprogramm (Teradata Parallel Transporter) für die Extraktion verwenden.
Bevor Sie eine Anmeldedatendatei erstellen, müssen Sie einen Dienstkontoschlüssel erstellt haben. Rufen Sie aus der heruntergeladenen Dienstkontoschlüsseldatei die folgenden Informationen ab:
client_emailprivate_key: Kopiert alle Zeichen zwischen-----BEGIN PRIVATE KEY-----und-----END PRIVATE KEY-----, einschließlich aller/n-Zeichen und ohne die einschließenden doppelten Anführungszeichen.
Sobald Sie die erforderlichen Informationen haben, erstellen Sie eine Datei mit Anmeldedaten. Das folgende Beispiel zeigt eine Datei mit Anmeldedaten mit dem Standardspeicherort $HOME/.gcs/credentials:
[default] gcs_access_key_id = ACCESS_ID gcs_secret_access_key = ACCESS_KEY
Ersetzen Sie Folgendes:
ACCESS_ID: die ID des Zugriffsschlüssels oder derclient_email-Wert in der Schlüsseldatei Ihres Dienstkontos.ACCESS_KEY: Der geheime Zugriffsschlüssel oder derprivate_key-Wert in Ihrer Dienstkonto-Schlüsseldatei.
Übertragung einrichten
Erstellen Sie eine Übertragung mit dem BigQuery Data Transfer Service.
Wenn Sie eine benutzerdefinierte Schemadatei automatisch erstellen möchten, verwenden Sie den Migrations-Agent, um die Übertragung einzurichten.
Sie können On-Demand-Übertragungen nicht mit dem bq-Befehlszeilentool erstellen. Sie müssen stattdessen die Google Cloud Console oder die BigQuery Data Transfer Service API verwenden.
Wenn Sie eine wiederkehrende Übertragung erstellen, empfehlen wir dringend, eine Schemadatei anzugeben, damit Daten aus nachfolgenden Übertragungen beim Laden in BigQuery ordnungsgemäß partitioniert werden können. Ohne Schemadatei leitet BigQuery Data Transfer Service das Tabellenschema von den übertragenen Quelldaten ab und alle Informationen zu Partitionierung, Clustering, Primärschlüssel und Änderungsverfolgung gehen verloren. Außerdem überspringen nachfolgende Übertragungen zuvor migrierte Tabellen nach der ersten Übertragung. Weitere Informationen zum Erstellen einer Schemadatei finden Sie unter Benutzerdefinierte Schemadatei.
Console
Rufen Sie in der Google Cloud Console die Seite "BigQuery" auf.
Klicken Sie auf Datenübertragungen.
Klicken Sie auf Create Transfer (Übertragung erstellen).
Führen Sie im Abschnitt Quelltyp folgende Schritte aus:
- Wählen Sie Migration: Teradata.
- Geben Sie als Konfigurationsname für Übertragung den Namen für die Übertragung ein, der angezeigt werden soll, z. B.
My Migration. Der Anzeigename kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen. - Optional: Für Zeitplanoptionen können Sie den Standardwert Täglich (basierend auf der Zeit der Erstellung) belassen oder eine andere Zeit für eine wiederkehrende, inkrementelle Übertragung wählen. Andernfalls wählen Sie für eine einmalige Übertragung On-Demand.
Wählen Sie für Zieleinstellungen das entsprechende Dataset aus.
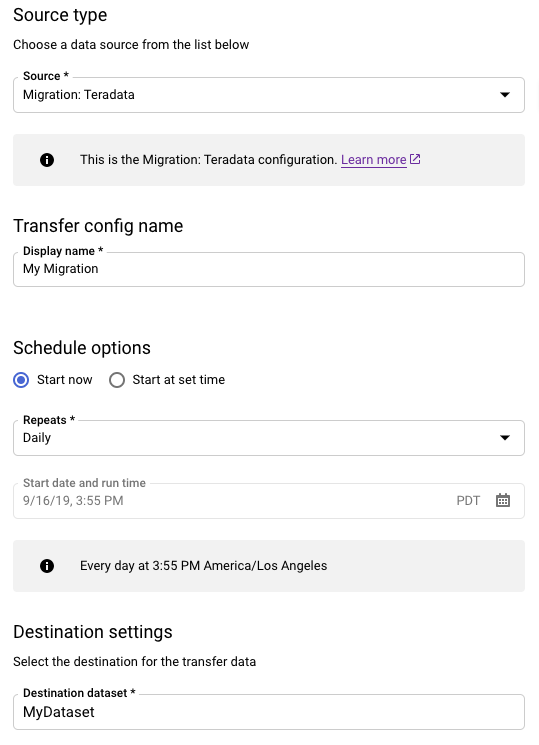
Fahren Sie im Abschnitt Details zur Datenquelle mit spezifischen Details für Ihre Teradata-Übertragung fort.
- Wählen Sie als Datenbanktyp Teradata aus.
- Suchen Sie unter Cloud Storage-Bucket nach dem Namen des Cloud Storage-Buckets für das Staging der Migrationsdaten. Geben Sie nicht das Präfix
gs://ein, sondern geben Sie nur den Bucket-Namen ein. - Geben Sie unter Datenbankname den Namen der Quellendatenbank in Teradata ein.
Geben Sie für Tabellennamensmuster ein Muster ein, das mit den Tabellennamen in der Quelldatenbank übereinstimmt. Sie können das Muster mit regulären Ausdrücken angeben. Beispiel:
sales|expensesführt zu Übereinstimmungen mit Tabellen, diesalesundexpensesheißen..*führt zu Übereinstimmung mit allen Tabellen.
Geben Sie unter E-Mail-Adresse des Dienstkontos die E-Mail-Adresse ein, die den Anmeldedaten eines Dienstkontos zugeordnet ist, die von einem Migrations-Agent verwendet werden.
Optional: Geben Sie als Schemadateipfad den Pfad und den Dateinamen einer benutzerdefinierten Schemadatei ein. Weitere Informationen zum Erstellen einer benutzerdefinierten Schemadatei finden Sie unter Benutzerdefinierte Schemadatei. Sie können dieses Feld leer lassen, damit BigQuery das Schema der Quelltabelle automatisch erkennt.
Optional: Geben Sie für Stammverzeichnis für Übersetzungsoutput den Pfad und den Dateinamen der von der BigQuery-Übersetzungs-Engine bereitgestellten Schemazuordnungsdatei ein. Weitere Informationen zum Generieren einer Schemazuordnungsdatei finden Sie unter Übersetzungs-Engine-Ausgabe für Schema verwenden (Vorabversion). Sie können dieses Feld leer lassen, damit BigQuery das Schema der Quelltabelle automatisch erkennt.
Optional: Klicken Sie für Direktes Entladen in GCS aktivieren das Kästchen an, um das Zugriffsmodul für Cloud Storage zu aktivieren.
Wählen Sie im Menü Dienstkonto ein Dienstkonto aus den Dienstkonten aus, die mit IhremGoogle Cloud -Projekt verknüpft sind. Sie können Ihre Übertragung mit einem Dienstkonto verknüpfen, anstatt Ihre Nutzeranmeldedaten zu verwenden. Weitere Informationen zur Verwendung von Dienstkonten mit Datenübertragungen finden Sie unter Dienstkonten verwenden.
- Wenn Sie sich mit einer föderierten Identität angemeldet haben, ist ein Dienstkonto zum Erstellen einer Übertragung erforderlich. Wenn Sie sich mit einem Google-Konto angemeldet haben, ist ein Dienstkonto für die Übertragung optional.
- Das Dienstkonto muss die erforderlichen Berechtigungen haben.
Optional: Gehen Sie im Abschnitt Benachrichtigungsoptionen so vor:
- Klicken Sie auf den Ein/Aus-Button E-Mail-Benachrichtigungen, wenn der Übertragungsadministrator eine E-Mail-Benachrichtigung erhalten soll, falls eine Übertragung fehlschlägt.
- Klicken Sie auf den Ein/Aus-Button Pub/Sub-Benachrichtigungen, um Pub/Sub-Ausführungsbenachrichtigungen für Ihre Übertragung zu konfigurieren. Wählen Sie unter Pub/Sub-Thema auswählen Ihr Thema aus oder klicken Sie auf Thema erstellen.
Klicken Sie auf Speichern.
Klicken Sie auf der Seite Übertragungsdetails auf den Tab Konfiguration.
Notieren Sie sich den Ressourcennamen für diese Übertragung, da Sie ihn für die Ausführung des Migrations-Agent benötigen.
bq
Wenn Sie eine Cloud Storage-Übertragung mit dem bq-Tool erstellen, wird die Übertragungskonfiguration alle 24 Stunden wiederholt. Verwenden Sie für On-Demand-Übertragungen die Google Cloud Console oder die BigQuery Data Transfer Service API.
Sie können Benachrichtigungen nicht mit dem bq-Tool konfigurieren.
Geben Sie den Befehl
bq mk ein und geben Sie das --transfer_config-Flag für die Übertragungserstellung an. Die folgenden Flags sind ebenfalls erforderlich:
--data_source--display_name--target_dataset--params
bq mk \ --transfer_config \ --project_id=project ID \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters' \ --data_source=data source
Dabei gilt:
- project ID ist die Projekt-ID. Wenn
--project_idnicht bereitgestellt wird, um ein bestimmtes Projekt anzugeben, wird das Standardprojekt verwendet. - dataset ist das Dataset, auf das Sie die Übertragungskonfiguration abzielen möchten (
--target_dataset). - name ist der Anzeigename (
--display_name) für die Übertragungskonfiguration. Der angezeigte Name der Übertragung kann ein beliebiger Wert sein, mit dem Sie die Übertragung identifizieren können, wenn Sie sie später ändern müssen. - service_account ist der Name des Dienstkontos, der zur Authentifizierung der Übertragung verwendet wird. Das Dienstkonto sollte zum selben
project_idgehören, das für die Erstellung der Übertragung verwendet wurde, und sollte alle aufgeführten erforderlichen Berechtigungen haben. - parameters enthält die Parameter (
--params) für die erstellte Übertragungskonfiguration im JSON-Format. Beispiel:--params='{"param":"param_value"}'.- Verwenden Sie für Teradata-Migrationen folgende Parameter:
bucketist der Cloud Storage-Bucket, der während der Migration als Staging-Bereich fungiert.database_typeist Teradata.agent_service_accountist die E-Mail-Adresse, die mit dem Dienstkonto, das Sie erstellt haben, verknüpft ist.database_nameist der Name der Quelldatenbank in Teradata.table_name_patternsist ein oder mehrere Muster zum Abgleich der Tabellennamen in der Quelldatenbank. Sie können das Muster mit regulären Ausdrücken angeben. Das Muster sollte der Java-Syntax für reguläre Ausdrücke folgen. Beispiel:sales|expensesführt zu Übereinstimmungen mit Tabellen, diesalesundexpensesheißen..*führt zu Übereinstimmung mit allen Tabellen.
is_direct_gcs_unload_enabledist ein boolescher Flag, mit dem das direkte Entladen in Cloud Storage aktiviert wird.
- Verwenden Sie für Teradata-Migrationen folgende Parameter:
- data_source ist die Datenquelle (
--data_source):on_premises.
Mit dem folgenden Befehl wird beispielsweise eine Teradata-Übertragung mit dem Namen My Transfer mit dem Cloud Storage-Bucket mybucket und dem Ziel-Dataset mydataset erstellt. Bei der Übertragung werden alle Tabellen aus dem Teradata Data Warehouse mydatabase migriert. Die optionale Schemadatei ist myschemafile.json.
bq mk \ --transfer_config \ --project_id=123456789876 \ --target_dataset=MyDataset \ --display_name='My Migration' \ --params='{"bucket": "mybucket", "database_type": "Teradata", "database_name":"mydatabase", "table_name_patterns": ".*", "agent_service_account":"myemail@mydomain.com", "schema_file_path": "gs://mybucket/myschemafile.json", "is_direct_gcs_unload_enabled": true}' \ --data_source=on_premises
Nachdem Sie den Befehl ausgeführt haben, erhalten Sie eine Meldung wie die Folgende:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Folgen Sie der Anleitung und fügen Sie den Authentifizierungscode in die Befehlszeile ein.
API
Verwenden Sie die Methode projects.locations.transferConfigs.create und geben Sie eine Instanz der Ressource TransferConfig an.
Java
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Java in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Java API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Migrations-Agent
Sie können die Übertragung optional direkt vom Migrations-Agent aus einrichten. Weitere Informationen finden Sie unter Migrations-Agent initialisieren.
Den Migrations-Agent initialisieren
Sie müssen den Migrations-Agent für eine neue Übertragung initialisieren. Die Initialisierung ist nur einmal für eine Übertragung erforderlich, unabhängig davon, ob diese wiederholt wird oder nicht. Bei der Initialisierung wird nur der Migrations-Agent konfiguriert und nicht die Übertragung gestartet.
Wenn Sie mithilfe des Migrations-Agents eine benutzerdefinierte Schemadatei erstellen, muss in Ihrem Arbeitsverzeichnis ein beschreibbares Verzeichnis mit dem Namen des Projekts vorhanden sein, das Sie für die Übertragung verwenden möchten. Hier erstellt der Migrations-Agent die Schemadatei.
Wenn Sie beispielsweise in /home arbeiten und die Übertragung im Projekt myProject einrichten, erstellen Sie das Verzeichnis /home/myProject und stellen Sie sicher, dass es für Nutzer beschreibbar ist.
Öffnen Sie eine neue Sitzung. Führen Sie in der Befehlszeile den Initialisierungsbefehl aus, der folgende Form hat:
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --initialize
Das folgende Beispiel zeigt den Initialisierungsbefehl, wobei sich die JAR-Dateien für den JDBC-Treiber und den Migrations-Agent in einem lokalen
migration-Verzeichnis befinden:Unix, Linux, Mac OS
java -cp \ /usr/local/migration/terajdbc4.jar:/usr/local/migration/mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --initialize
Windows
Kopieren Sie alle Dateien in den Ordner
C:\migration(oder passen Sie die Pfade im Befehl an) und führen Sie dann Folgendes aus:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --initialize
Konfigurieren Sie folgende Optionen, sobald Sie dazu aufgefordert werden:
- Wählen Sie aus, ob die TPT-Vorlage (Teradata Parallel Transporter) auf dem Laufwerk gespeichert werden soll. Wenn Sie die TPT-Extraktionsmethode verwenden möchten, können Sie die gespeicherte Vorlage mit Parametern ändern, die zu Ihrer Teradata-Instanz passen.
- Geben Sie den Pfad zu einem lokalen Verzeichnis ein, das der Übertragungsjob für die Dateiextraktion verwenden kann. Stellen Sie sicher, dass Sie über den empfohlenen Mindestspeicherplatz verfügen, wie unter Extraktionsmethode beschrieben.
- Geben Sie den Datenbankhostnamen ein.
- Geben Sie den Datenbankport ein.
- Wählen Sie aus, ob TPT (Teradata Parallel Transporter) als Extraktionsmethode verwendet werden soll.
- Optional: Geben Sie den Pfad zu einer Datei mit Datenbankanmeldedaten ein.
Wählen Sie aus, ob ein Namen für die BigQuery Data Transfer Service-Konfiguration angegeben werden soll.
Wenn Sie den Migrations-Agent für eine Übertragung initialisieren, die Sie bereits eingerichtet haben, gehen Sie so vor:
- Geben Sie den Ressourcennamen der Übertragung ein. Sie finden ihn auf der Seite Übertragungsdetails auf dem Tab Konfiguration.
- Geben Sie bei entsprechender Aufforderung Pfad und Dateinamen der zu erstellenden Konfigurationsdatei des Migrations-Agenten ein. Sie verweisen auf diese Datei, wenn Sie den Migrations-Agent ausführen, um die Übertragung zu starten.
- Überspringen Sie die restlichen Schritte.
Wenn Sie eine Übertragung mit dem Migrations-Agent einrichten, drücken Sie die Eingabetaste, um zur nächsten Eingabeaufforderung zu springen.
Geben Sie die Google Cloud Projekt-ID ein.
Geben Sie den Namen der Quelldatenbank in Teradata ein.
Geben Sie ein Muster ein, das mit den Tabellennamen in der Quelldatenbank übereinstimmt. Sie können das Muster mit regulären Ausdrücken angeben. Beispiel:
sales|expensesführt zu Übereinstimmungen mit Tabellen, diesalesundexpensesheißen..*führt zu Übereinstimmung mit allen Tabellen.
Optional: Geben Sie den Pfad zu einer lokalen JSON-Schemadatei ein. Dies wird für wiederkehrende Übertragungen dringend empfohlen.
Wenn Sie keine Schemadatei verwenden oder wenn Sie möchten, dass der Migrations-Agent eine für Sie erstellt, drücken Sie die Eingabetaste, um zur nächsten Eingabeaufforderung zu springen.
Wählen Sie aus, ob eine neue Schemadatei erstellt werden soll.
Wenn Sie eine Schemadatei erstellen möchten, gehen Sie so vor:
- Geben Sie
yesein. - Geben Sie den Nutzernamen eines Teradata-Nutzers ein, der Lesezugriff auf die Systemtabellen und die zu migrierenden Tabellen hat.
Geben Sie das Passwort für diesen Nutzer ein.
Der Migrations-Agent erstellt die Schemadatei und gibt ihren Speicherort aus.
Ändern Sie die Schemadatei, um Partitionierung, Clustering, Primärschlüssel und die Änderungsverfolgungsspalten zu ändern und prüfen Sie, ob Sie dieses Schema für die Übertragungskonfiguration verwenden möchten. Tipps finden Sie unter Benutzerdefinierte Schemadatei.
Drücken Sie
Enter, um zur nächsten Eingabeaufforderung zu springen.
Wenn Sie keine Schemadatei erstellen möchten, geben Sie
noein.- Geben Sie
Geben Sie den Namen des Cloud Storage-Ziel-Buckets für das Staging von Migrationsdaten ein, bevor Sie in BigQuery laden. Wenn der Migrations-Agent eine benutzerdefinierte Schemadatei erstellt hat, wird diese auch in diesen Bucket hochgeladen.
Geben Sie den Namen des Ziel-Datasets in BigQuery ein.
Geben Sie einen Anzeigenamen für die Übertragungskonfiguration ein.
Geben Sie Pfad und Dateinamen für die zu erstellende Konfigurationsdatei des Migrations-Agenten ein.
Nach der Eingabe aller angeforderten Parameter erstellt der Migrations-Agent eine Konfigurationsdatei und gibt sie in den von Ihnen angegebenen lokalen Pfad aus. Im nächsten Abschnitt erfahren Sie mehr über die Konfigurationsdatei.
Konfigurationsdatei für den Migrations-Agent
Die im Initialisierungsschritt erstellte Konfigurationsdatei sieht in etwa so aus:
{
"agent-id": "81f452cd-c931-426c-a0de-c62f726f6a6f",
"transfer-configuration": {
"project-id": "123456789876",
"location": "us",
"id": "61d7ab69-0000-2f6c-9b6c-14c14ef21038"
},
"source-type": "teradata",
"console-log": false,
"silent": false,
"teradata-config": {
"connection": {
"host": "localhost"
},
"local-processing-space": "extracted",
"database-credentials-file-path": "",
"max-local-storage": "50GB",
"gcs-upload-chunk-size": "32MB",
"use-tpt": true,
"transfer-views": false,
"max-sessions": 0,
"spool-mode": "NoSpool",
"max-parallel-upload": 4,
"max-parallel-extract-threads": 1,
"session-charset": "UTF8",
"max-unload-file-size": "2GB"
}
}
Optionen für Übertragungsjobs in der Konfigurationsdatei des Migrations-Agents
transfer-configuration: Informationen zu dieser Übertragungskonfiguration in BigQuery.teradata-config: Informationen speziell für diese Teradata-Extraktion:connection: Informationen zu Hostnamen und Portlocal-processing-space: Der Extraktionsordner, in den der Agent Tabellendaten extrahiert, bevor er sie in den Cloud-Speicher hochlädt.database-credentials-file-path: (Optional) Der Pfad zu einer Datei, die Anmeldedaten für die automatische Verbindung zur Teradata-Datenbank enthält. Die Datei sollte zwei Zeilen für die Anmeldedaten enthalten. Sie können einen Nutzernamen und ein Passwort verwenden, wie im folgenden Beispiel gezeigt:username=abc password=123
username=abc secret_resource_id=projects/my-project/secrets/my-secret-name/versions/1
max-local-storage: Die maximale Menge lokalen Speichers, die für die Extraktion im angegebenen Staging-Verzeichnis verwendet werden soll. Der Standardwert ist50GB. Das unterstützte Format ist:numberKB|MB|GB|TB.In allen Extraktionsmodi werden Dateien nach dem Hochladen in Cloud Storage aus dem lokalen Staging-Verzeichnis gelöscht.
use-tpt: Weist den Migrations-Agent an, Teradata Parallel Transporter (TPT) als Extraktionsmethode zu verwenden.Für jede Tabelle generiert der Migrations-Agent ein TPT-Skript, startet einen
tbuild-Prozess und wartet auf den Abschluss. Sobald dertbuild-Prozess abgeschlossen ist, listet der Agent die extrahierten Dateien auf und lädt sie in den Cloud-Speicher hoch. Anschließend wird das TPT-Skript gelöscht. Weitere Informationen finden Sie unter Extraktionsmethode.transfer-views: Weist den Migrations-Agent an, auch Daten aus Ansichten zu übertragen. Verwenden Sie diese Option nur, wenn Sie während der Migration die Datenanpassung vornehmen müssen. In anderen Fällen sollten Sie Ansichten zu BigQuery-Ansichten migrieren. Für diese Option gelten die folgenden Voraussetzungen:- Sie können diese Option nur mit Teradata Version 16.10 und höher verwenden.
- Eine Ansicht sollte eine Ganzzahlspalte „Partition“ definiert haben, die auf eine ID der Partition für die angegebene Zeile in der zugrunde liegenden Tabelle verweist.
max-sessions: Gibt die maximale Anzahl der vom Extraktionsjob (FastExport oder TPT) verwendeten Sitzungen an. Wenn Sie 0 festlegen, ermittelt die Teradata-Datenbank die maximale Anzahl von Sitzungen für jeden Extraktionsjob.gcs-upload-chunk-size: Eine große Datei wird in Blöcken in Cloud Storage hochgeladen. Dieser Parameter steuert zusammen mitmax-parallel-upload, wie viele Daten gleichzeitig in Cloud Storage hochgeladen werden. Beispiel: Wenngcs-upload-chunk-size64 MB beträgt undmax-parallel-upload10 MB ist, kann ein Migrations-Agent theoretisch 640 MB (64 MB * 10) an Daten gleichzeitig hochladen. Wenn der Block nicht hochgeladen werden kann, muss der gesamte Block wiederholt werden. Die Blockgröße muss klein sein.max-parallel-upload: Dieser Wert bestimmt die maximale Anzahl von Threads, die vom Migrations-Agent zum Hochladen von Dateien in Cloud Storage verwendet werden. Wenn nichts angegeben ist, wird standardmäßig die Anzahl der Prozessoren verwendet, die für die Java-VM verfügbar sind. Als Faustregel gilt: Wählen Sie den Wert anhand der Anzahl der Kerne auf der Maschine aus, auf der der Agent ausgeführt wird. Wenn Sie alsonKerne haben, sollte die optimale Anzahl von Threadsnsein. Wenn die Kerne hyper-threaded sind, sollte die optimale Zahl(2 * n)sein. Es gibt auch andere Einstellungen wie die Netzwerkbandbreite, die Sie beim Anpassen vonmax-parallel-uploadberücksichtigen müssen. Wenn Sie diesen Parameter anpassen, kann sich die Leistung beim Hochladen in Cloud Storage verbessern.spool-mode: In den meisten Fällen ist der NoSpool-Modus die beste Option.NoSpoolist die Standardeinstellung in der Agent-Konfiguration. Sie können diesen Parameter ändern, wenn einer der Nachteile von NoSpool auf Ihren Fall zutrifft.max-unload-file-size: Legt die maximale extrahierte Dateigröße fest. Dieser Parameter wird für TPT-Extraktionen nicht erzwungen.max-parallel-extract-threads: Diese Konfiguration wird nur im FastExport-Modus verwendet. Sie bestimmt die Anzahl der parallelen Threads, die zum Extrahieren der Daten aus Teradata verwendet werden. Wenn Sie diesen Parameter anpassen, kann sich die Leistung bei der Extraktion verbessern.tpt-template-path: Verwenden Sie diese Konfiguration, um ein benutzerdefiniertes TPT-Extraktionsskript als Eingabe bereitzustellen. Mit diesem Parameter können Sie Transformationen auf Ihre Migrationsdaten anwenden.tpt-export-count: Der Exportvorgang ist für das Extrahieren von Daten aus der Teradata-Datenbank verantwortlich. Mit diesem Parameter wird die Standardanzahl der Exporte im TPT-Script überschrieben. Er sollte kleiner oder gleich dem Wert des Parametersmax-sessionssein, damit für jede Instanz genügend Pipelines zur Datenbank vorhanden sind.tpt-file-writer-count: Der Operator für das Schreiben von Dateien ist dafür verantwortlich, die vom Exportoperator empfangenen Daten in eine physische Datei in Ihrem Speichersystem zu schreiben. Dieser Parameter überschreibt die Standardanzahl der Dateischreiber im TPT-Skript. Idealerweise sollte die Anzahl der Dateischreiber mit der Anzahl der Exporte übereinstimmen. Andernfalls wird die Übertragung entweder bei der Extraktion oder beim Schreiben zum Engpass.schema-mapping-rule-path: (Optional) Der Pfad zu einer Konfigurationsdatei, die eine Schemazuordnung zum Überschreiben der Standardzuordnungsregeln enthält. Einige Zuordnungstypen funktionieren nur mit dem Teradata Parallel Transporter-Modus (TPT).Beispiel: Zuordnung vom Teradata-Typ
TIMESTAMPzum BigQuery-TypDATETIME:{ "rules": [ { "database": { "name": "database.*", "tables": [ { "name": "table.*" } ] }, "match": { "type": "COLUMN_TYPE", "value": "TIMESTAMP" }, "action": { "type": "MAPPING", "value": "DATETIME" } } ] }
Attribute:
database: (Optional)nameist ein regulärer Ausdruck für die einzubeziehenden Datenbanken. Alle Datenbanken sind standardmäßig enthalten.tables: (Optional) enthält ein Array mit Tabellen.nameist ein regulärer Ausdruck für die einzuschließenden Tabellen. Alle Tabellen sind standardmäßig enthalten.match: (Erforderlich)typeunterstützte Werte:COLUMN_TYPE.valueunterstützte Werte:TIMESTAMP,DATETIME.
action: (Erforderlich)typeunterstützte Werte:MAPPING.valueunterstützte Werte:TIMESTAMP,DATETIME.
compress-output: (Optional) Legt fest, ob Daten vor dem Speichern in Cloud Storage komprimiert werden sollen. Dies wird nur im tpt-Modus angewendet. Standardmäßig ist dieser Wertfalse.gcs-module-config-dir: (Optional) Der Pfad zur Anmeldedatei für den Zugriff auf den Cloud Storage-Bucket. Das Standardverzeichnis ist$HOME/.gcs. Sie können es aber mit diesem Parameter ändern.gcs-module-connection-count: (Optional) Gibt die Anzahl der TCP-Verbindungen zum Cloud Storage-Dienst an. Der Standardwert ist 10.gcs-module-buffer-size: Optional. Gibt die Größe der Puffer an, die für die TCP-Verbindungen verwendet werden sollen. Der Standardwert ist 8 MB (8.388.608 Byte). Zur Vereinfachung können Sie die folgenden Multiplikatoren verwenden:k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-buffer-count: (Optional) Gibt die Anzahl der Puffer an, die für die TCP-Verbindungen verwendet werden sollen, die durchgcs-module-connection-countangegeben werden. Wir empfehlen, einen Wert zu verwenden, der dem Doppelten der Anzahl der TCP-Verbindungen zum Cloud Storage-Dienst entspricht. Der Standardwert ist 2 *gcs-module-connection-count.gcs-module-max-object-size: (Optional) Mit diesem Parameter wird die Größe von Cloud Storage-Objekten gesteuert. Der Wert dieses Parameters kann eine Ganzzahl oder eine Ganzzahl gefolgt von einem der folgenden Multiplikatoren sein (ohne Leerzeichen):k (1000)K (1024)m (1000 * 1000)M (1024*1024)
gcs-module-writer-instances: (Optional) Mit diesem Parameter wird die Anzahl der Cloud Storage-Schreibinstanzen angegeben. Der Standardwert ist 1. Sie können diesen Wert erhöhen, um den Durchsatz während der Schreibphase des TPT-Exports zu steigern.
Datenextraktion durch Agenten optimieren
Durch die Feinabstimmung der Agent-Parameter können Sie den Datenextraktionsprozess optimieren und den gesamten Übertragungsprozess effizienter gestalten.
In der folgenden Tabelle finden Sie Informationen zu Parametern, mit denen Sie die Migration optimieren können:
| Parameter | Empfohlener Wert | Beschreibung |
|---|---|---|
gcs-module-writer-instances |
4 | Erhöht die Parallelisierung für TPT-Extraktions- und Cloud Storage-Schreibvorgänge. Passen Sie diesen Wert an, um die Übertragungsoptimierung und die Teradata-Instanzlast auszugleichen. |
gcs-module-connection-count |
10 | Legt die Anzahl der TCP-Verbindungen zu Cloud Storage fest. Wenn Sie diesen Wert erhöhen, wird die Parallelisierung während der Cloud Storage-Uploadphase verbessert. |
gcs-module-buffer-size |
32 Min. | Definiert die Größe der Puffer für TCP-Verbindungen. Tests haben ergeben, dass 32m optimale Ergebnisse liefert. |
tpt-export-count |
Muss kleiner oder gleich dem Wert max-sessions sein. |
Überschreibt die Standardanzahl der Exportvorgänge im TPT-Script. Der Wert sollte kleiner oder gleich dem max-sessions-Wert sein, damit jede Instanz genügend Pipes zur Datenbank hat. |
tpt-file-writer-count |
Sollte dem Wert von export-count entsprechen. |
Überschreibt die Standardanzahl der File Writer-Operatoren im TPT-Skript. Im Idealfall sollte dieser Wert mit dem tpt-export-count-Wert übereinstimmen, um Engpässe zu vermeiden. |
Beachten Sie die folgenden Best Practices für die Konfiguration:
Arbeitsspeicherbeschränkung: Das Ergebnis der folgenden Berechnung muss kleiner sein als der Gesamtarbeitsspeicher der VM, auf der der Agent ausgeführt wird. Verwenden Sie für alle Werte in Ihrer Berechnung konsistente Einheiten.
$$ \text{gcs-module-writer-instances} \times \text{gcs-module-buffer-size} \times \text{gcs-module-buffer-count} < \text{Total VM memory} $$Reihenfolge der Feinabstimmung:
- Passen Sie zuerst den Parameterwert
gcs-module-writer-instancesan, um das beste Verhältnis zwischen Leistung und Last zu finden. - Wenn Sie die Leistung weiter steigern möchten, erhöhen Sie den Wert von
gcs-module-connection-count.
- Passen Sie zuerst den Parameterwert
Automatische Skalierung: Standardmäßig ist der Parameterwert
gcs-module-buffer-sizein der Regel auf das Doppelte der Anzahl der Verbindungen festgelegt. Wir empfehlen jedoch, den Wert für diese Arbeitslasten explizit auf32mfestzulegen.
Ausführen des Migrations-Agent
Führen Sie nach dem Initialisieren des Migrations-Agent und dem Erstellen der Konfigurationsdatei die folgenden Schritte aus, um den Agent auszuführen und die Migration zu starten:
Führen Sie den Agent aus. Dazu geben Sie die im vorhergehenden Initialisierungsschritt erstellten Pfade zum JDBC-Treiber, zum Migrations-Agent und zur Konfigurationsdatei an.
java -cp \ OS-specific-separated-paths-to-jars (JDBC and agent) \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=path to configuration file
Unix, Linux, Mac OS
java -cp \ /usr/local/migration/Teradata/JDBC/terajdbc4.jar:mirroring-agent.jar \ com.google.cloud.bigquery.dms.Agent \ --configuration-file=config.json
Windows
Kopieren Sie alle Dateien in den Ordner
C:\migration(oder passen Sie die Pfade im Befehl an) und führen Sie dann Folgendes aus:java -cp C:\migration\terajdbc4.jar;C:\migration\mirroring-agent.jar com.google.cloud.bigquery.dms.Agent --configuration-file=config.json
Wenn Sie mit der Migration fortfahren möchten, drücken Sie
Enter. Der Agent fährt fort, wenn der bei der Initialisierung angegebene Klassenpfad gültig ist.Wenn Sie dazu aufgefordert werden, geben Sie den Nutzernamen und das Kennwort für die Datenbankverbindung ein. Wenn der Nutzername und das Passwort gültig sind, beginnt die Datenmigration.
Optional Im Startbefehl für die Migration können Sie auch ein Flag verwenden, das eine Anmeldedatendatei an den Agent übergibt, anstatt jedes Mal den Nutzernamen und das Kennwort einzugeben. Weitere Informationen finden Sie im optionalen Parameter
database-credentials-file-pathin der Konfigurationsdatei des Agent. Führen Sie bei Verwendung einer Datei mit Anmeldedaten die entsprechenden Schritte aus, um den Zugriff auf den Ordner zu kontrollieren, in dem Sie die Datei im lokalen Dateisystem speichern, da diese nicht verschlüsselt wird.Lassen Sie diese Sitzung geöffnet, bis die Migration abgeschlossen ist. Wenn Sie eine wiederkehrende Migrationsübertragung erstellt haben, lassen Sie diese Sitzung unbegrenzt geöffnet. Wenn diese Sitzung unterbrochen wird, schlagen aktuelle und zukünftige Übertragungsausführungen fehl.
Prüfen Sie regelmäßig, ob der Agent ausgeführt wird. Wenn eine Übertragungsausführung läuft und kein Agent innerhalb von 24 Stunden antwortet, schlägt die Übertragung fehl.
Wenn der Migrations-Agent nicht mehr funktioniert, während die Übertragung ausgeführt wird oder geplant ist, zeigt die Google Cloud Console den Fehlerstatus an und fordert Sie auf, den Agent neu zu starten. Wenn Sie den Migrations-Agent neu starten möchten, kehren Sie zum Anfang dieses Abschnitts zurück. Sie müssen den Initialisierungsbefehl nicht wiederholen. Die Übertragung wird ab dem Punkt fortgesetzt, an dem die Tabellen nicht abgeschlossen wurden.
Migrationsfortschritt verfolgen
Sie können den Migrationsstatus in der Google Cloud -Konsole einsehen. Sie können auch Pub/Sub- oder E-Mail-Benachrichtigungen einrichten. Weitere Informationen finden Sie unter BigQuery Data Transfer Service-Benachrichtigungen.
Der BigQuery Data Transfer Service plant und initiiert eine Übertragung nach einem Zeitplan, der beim Erstellen der Übertragungskonfiguration festgelegt wurde. Es ist wichtig, dass der Migrations-Agent ausgeführt wird, wenn eine Übertragung aktiv ist. Wenn innerhalb von 24 Stunden keine Updates seitens des Agents vorliegen, schlägt eine Übertragungsausführung fehl.
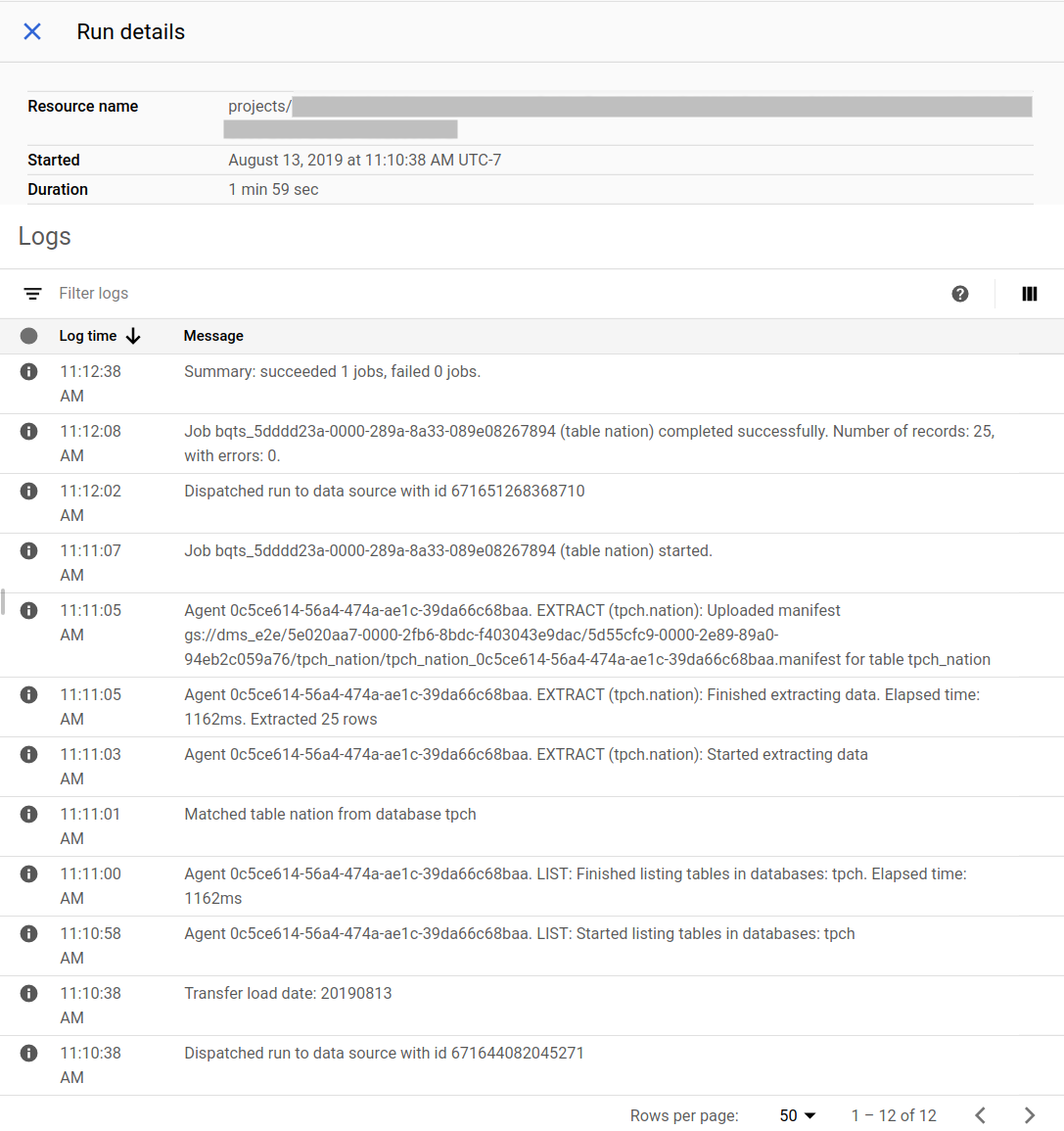
Beispiel für den Migrationsstatus in der Google Cloud Console:
Migrations-Agenten aktualisieren
Ist eine neue Version des Migrations-Agents verfügbar, so müssen Sie den Migrations-Agent manuell aktualisieren. Um Benachrichtigungen zum BigQuery Data Transfer Service zu erhalten, abonnieren Sie die Versionshinweise.
Nächste Schritte
- Testen Sie die Migration von Teradata zu BigQuery.
- Weitere Informationen zum BigQuery Data Transfer Service
- Migrieren Sie SQL-Code mit der Batch-SQL-Übersetzung.