
העברה מ-Oracle ל-BigQuery
במאמר הזה מוסבר איך להעביר נתונים מ-Oracle ל-BigQuery. המאמר מתאר את ההבדלים המהותיים בארכיטקטורה ומציע דרכים למיגרציה ממחסני נתונים (data warehouse) וממאגרי נתונים (data mart) שפועלים ב-Oracle RDBMS (כולל Exadata) ל-BigQuery. הפרטים במסמך הזה רלוונטיים גם ל-Exadata, ל-ExaCC ול-Oracle Autonomous Data Warehouse, כי הם משתמשים בתוכנת Oracle תואמת.
המסמך הזה מיועד לאדריכלים ארגוניים, לאדמיניסטרטורים של מסדי נתונים, למפתחי אפליקציות ולמומחי אבטחת IT שרוצים לעבור מ-Oracle ל-BigQuery ולפתור אתגרים טכניים בתהליך ההעברה.
אפשר גם להשתמש בתרגום SQL באצווה כדי להעביר את סקריפטים של SQL בכמות גדולה, או בתרגום SQL אינטראקטיבי כדי לתרגם שאילתות אד-הוק. שני הכלים תומכים ב-Oracle SQL, ב-PL/SQL וב-Exadata בגרסת Preview.
לפני ההעברה
כדי להבטיח שהעברת מחסן הנתונים תהיה מוצלחת, מומלץ להתחיל לתכנן את אסטרטגיית ההעברה בשלב מוקדם בציר הזמן של הפרויקט. מידע על תכנון שיטתי של עבודת ההעברה זמין במאמר מה מעבירים ואיך מעבירים: מסגרת ההעברה.
תכנון הקיבולת ב-BigQuery
מתחת לפני השטח, נפח העבודה של ניתוח הנתונים ב-BigQuery נמדד בחריצים. יחידת קיבולת של BigQuery היא יחידה קניינית של Google לקיבולת חישובית שנדרשת להרצת שאילתות SQL.
מערכת BigQuery מחשבת באופן רציף כמה יחידות קיבולת נדרשות לשאילתות בזמן שהן מופעלות, אבל היא מקצה יחידות קיבולת לשאילתות על סמך מתזמן הוגן.
כשמתכננים את הקיבולת של משבצות BigQuery, אפשר לבחור בין מודלים התמחור הבאים:
תמחור על פי דרישה: בתמחור על פי דרישה, BigQuery מחייב על מספר הבייטים שעובדו (גודל הנתונים), כך שאתם משלמים רק על השאילתות שאתם מריצים. מידע נוסף על האופן שבו BigQuery קובע את גודל הנתונים זמין במאמר בנושא חישוב גודל הנתונים. יחידות הקיבולת (Slot) קובעות את קיבולת המחשוב הבסיסית, ולכן אפשר לשלם על השימוש ב-BigQuery בהתאם למספר יחידות הקיבולת שאתם צריכים (במקום לפי מספר הבייטים שעברו עיבוד). כברירת מחדל, Google Cloud פרויקטים מוגבלים ל-2,000 משבצות לכל היותר.
תמחור לפי קיבולת: בתמחור לפי קיבולת, אתם רוכשים מקומות שמורים של יחידות קיבולת של BigQuery (מינימום 100) במקום לשלם על בייטים שעוברים עיבוד בשאילתות שאתם מריצים. אנחנו ממליצים על תמחור לפי קיבולת לעומסי עבודה של מחסני נתונים ארגוניים, שבדרך כלל כוללים הרבה שאילתות מקבילות של דיווח ושל extract-load-transform (ELT) עם צריכה צפויה.
כדי להעריך את מספר הסלוטים, מומלץ להגדיר מעקב אחרי BigQuery באמצעות Cloud Monitoring ולנתח את יומני הביקורת באמצעות BigQuery. לקוחות רבים משתמשים ב-Data Studio (לדוגמה, אפשר לראות דוגמה של קוד פתוח של לוח בקרה ב-Data Studio), ב-Looker או ב-Tableau כממשקי קצה להמחשה של נתוני יומן ביקורת של BigQuery, במיוחד לשימוש במשבצות בשאילתות ובפרויקטים. אתם יכולים גם להשתמש בנתונים של טבלאות המערכת של BigQuery כדי לעקוב אחרי ניצול משבצות בכל המשימות וההזמנות. לדוגמה, אפשר לעיין בדוגמה של קוד פתוח של לוח בקרה ב-Data Studio.
מעקב וניתוח קבועים של השימוש במקומות עוזרים להעריך כמה מקומות סך הכול הארגון צריך ככל שהוא גדל ב- Google Cloud.
לדוגמה, נניח שבהתחלה הזמנתם 4,000 משבצות BigQuery כדי להריץ 100 שאילתות ברמת מורכבות בינונית בו-זמנית. אם אתם מבחינים בזמני המתנה ארוכים בתוכניות הביצוע של השאילתות, ובמרכזי הבקרה מוצג ניצול גבוה של משבצות, יכול להיות שאתם צריכים משבצות נוספות ב-BigQuery כדי לתמוך בעומסי העבודה. אם אתם רוצים לרכוש יחידות קיבולת (Slot) בעצמכם באמצעות התחייבויות לשימוש שנתיות או תלת-שנתיות, אתם יכולים להתחיל להשתמש בהזמנות של BigQuery באמצעות המסוף Google Cloud או כלי שורת הפקודה של BigQuery.
לשאלות בנוגע לתוכנית הנוכחית ולאפשרויות שצוינו למעלה, אפשר לפנות לנציג המכירות.
אבטחה ב Google Cloud
בקטעים הבאים מתוארים אמצעי אבטחה נפוצים של Oracle, ומוסבר איך אפשר לוודא שמחסן הנתונים שלכם יישאר מוגן בסביבת Google Cloud.
ניהול זהויות והרשאות גישה (IAM)
Oracle מספקת משתמשים, הרשאות, תפקידים ופרופילים לניהול הגישה למשאבים.
BigQuery משתמש ב-IAM כדי לנהל את הגישה למשאבים, ומספק ניהול גישה מרכזי למשאבים ולפעולות. סוגי המשאבים שזמינים ב-BigQuery כוללים ארגונים, פרויקטים, מערכי נתונים, טבלאות ותצוגות. בהיררכיית מדיניות IAM, מערכי נתונים הם משאבי צאצא של פרויקטים. טבלה מקבלת הרשאות בירושה ממערך הנתונים שמכיל אותה.
כדי להעניק גישה למשאב, מקצים תפקיד אחד או יותר למשתמש, לקבוצה או לחשבון שירות. תפקידים בארגון ובפרויקט משפיעים על היכולת להריץ משימות או לנהל את הפרויקט, בעוד שתפקידים במערך נתונים משפיעים על היכולת לגשת לנתונים בתוך פרויקט או לשנות אותם.
ב-IAM יש את סוגי התפקידים הבאים:
- תפקידים מוגדרים מראש נועדו לתמוך בתרחישים נפוצים לדוגמה ובדפוסי בקרת גישה. תפקידים מוגדרים מראש מאפשרים גישה פרטנית לשירותים ספציפיים ומנוהלים על ידי Google Cloud.
תפקידים בסיסיים כוללים את התפקידים 'בעלים', 'עריכה' ו'צפייה'.
תפקידים בהתאמה אישית מאפשרים גישה פרטנית בהתאם לרשימת ההרשאות שנבחרו.
כשמקצים למשתמש תפקידים מוגדרים מראש ותפקידים בסיסיים, ההרשאות שניתנות לו הן איחוד של ההרשאות של כל תפקיד בנפרד.
אבטחה ברמת השורה
Oracle Label Security (OLS) מאפשרת להגביל את הגישה לנתונים על בסיס שורה-אחרי-שורה. תרחיש אופייני לשימוש באבטחה ברמת השורה הוא הגבלת הגישה של אנשי מכירות לחשבונות שהם מנהלים. הטמעה של אבטחה ברמת השורה מאפשרת לכם לקבל בקרת גישה מדויקת.
כדי להשיג אבטחה ברמת השורה ב-BigQuery, אפשר להשתמש בתצוגות מורשות ובמדיניות גישה ברמת השורה. מידע נוסף על תכנון והטמעה של המדיניות הזו זמין במאמר מבוא לאבטחה ברמת השורה ב-BigQuery.
הצפנה מלאה של הדיסק
Oracle מציעה הצפנת נתונים שקופה (TDE) והצפנה של נתונים במעבר. כדי להשתמש ב-TDE צריך להפעיל את האפשרות 'אבטחה מתקדמת', שנדרש עבורה רישיון נפרד.
כל הנתונים ב-BigQuery מוצפנים כברירת מחדל במצב מנוחה ובזמן העברה, ללא קשר למקור או לכל תנאי אחר, ואי אפשר להשבית את ההצפנה. בנוסף, BigQuery תומך במפתחות הצפנה בניהול הלקוח (CMEK) למשתמשים שרוצים לשלוט במפתחות הצפנה ולנהל אותם ב-Cloud Key Management Service. מידע נוסף על הצפנה ב- Google Cloudזמין במאמרים ברירת המחדל של הצפנה במנוחה והצפנה בזמן ההעברה.
הסתרת נתונים והשמטת נתונים
Oracle משתמשת בהסתרת נתונים בבדיקות של אפליקציות בזמן אמת ובהשמטת נתונים, שמאפשרת להסתיר (להשמיט) נתונים שמוחזרים משאילתות שהונפקו על ידי אפליקציות.
BigQuery תומך בהסתרת נתונים דינמית ברמת העמודה. אתם יכולים להשתמש בהסתרת נתונים כדי להסתיר באופן סלקטיבי נתונים בעמודות עבור קבוצות של משתמשים, ועדיין לאפשר גישה לעמודה.
אתם יכולים להשתמש ב-Sensitive Data Protection כדי לזהות ולצנזר פרטים אישיים מזהים (PII) רגישים ב-BigQuery.
השוואה בין BigQuery לבין Oracle
בקטע הזה מתוארים ההבדלים העיקריים בין BigQuery לבין Oracle. ההדגשות האלה עוזרות לכם לזהות את הקשיים בהעברה ולתכנן את השינויים הנדרשים.
ארכיטקטורת המערכת
אחד ההבדלים העיקריים בין Oracle לבין BigQuery הוא ש-BigQuery הוא מחסן נתונים (EDW) בענן בלי שרת (serverless), עם שכבות נפרדות של אחסון ומחשוב שאפשר להרחיב אותן בהתאם לצרכים של השאילתה. בהתחשב באופי של שירות BigQuery ללא שרת, אתם לא מוגבלים על ידי החלטות לגבי חומרה. במקום זאת, אתם יכולים לבקש יותר משאבים לשאילתות ולמשתמשים באמצעות הזמנות. בנוסף, ב-BigQuery לא צריך להגדיר את התוכנה והתשתית הבסיסיות, כמו מערכת הפעלה (OS), מערכות רשת ומערכות אחסון, כולל הרחבה וזמינות גבוהה. BigQuery מטפל בפעולות שקשורות למדרגיות, לניהול ולניהול אדמיניסטרטיבי. בתרשים הבא מוצגת היררכיית האחסון ב-BigQuery.
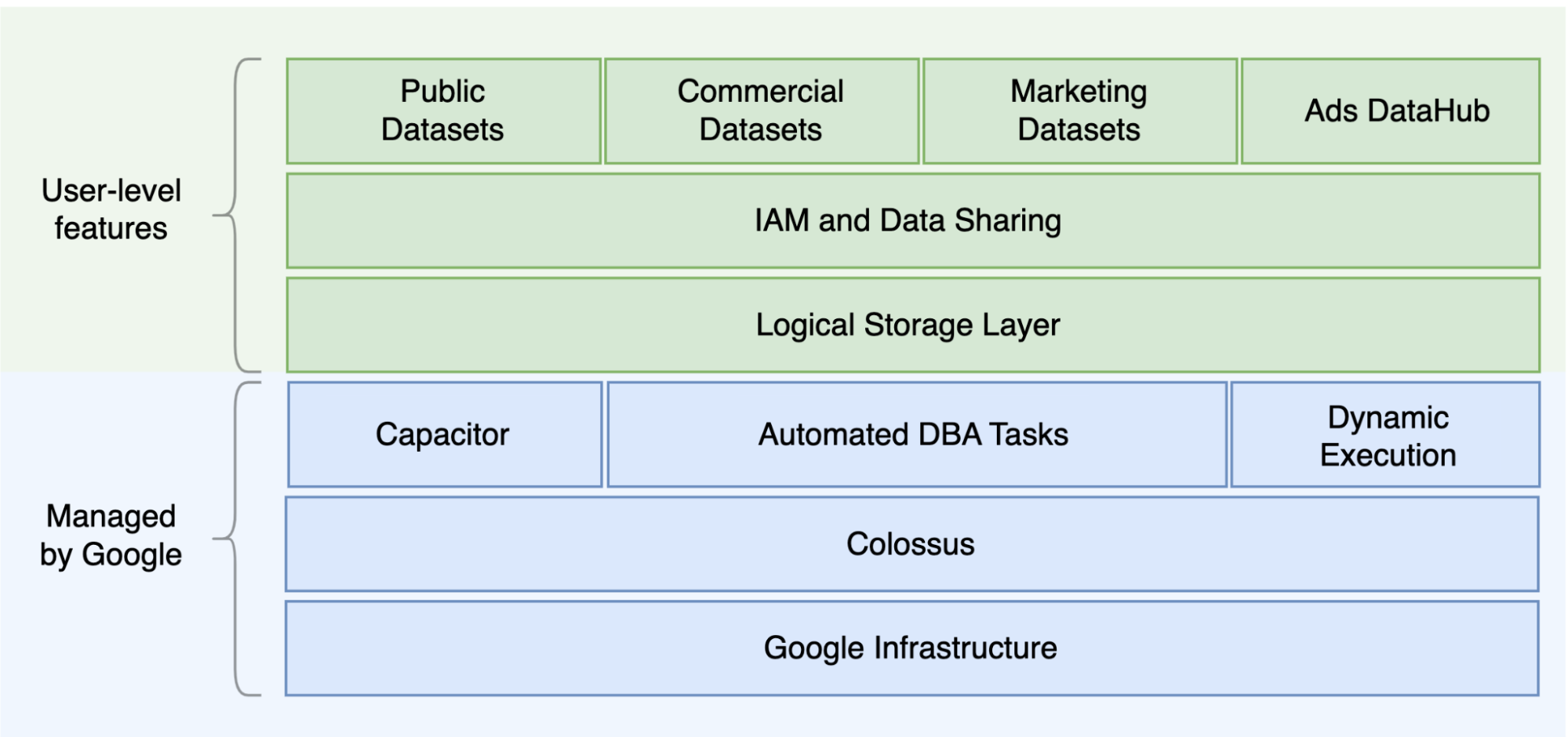
היכרות עם ארכיטקטורת האחסון ועיבוד השאילתות הבסיסית, כמו ההפרדה בין האחסון (Colossus) לבין ביצוע השאילתות (Dremel), ועם האופן שבוGoogle Cloud מוקצים משאבים (Borg), יכולה לעזור להבין את ההבדלים בהתנהגות ולשפר את ביצועי השאילתות ואת היעילות הכלכלית. פרטים נוספים זמינים במאמרים בנושא ארכיטקטורות מערכת לדוגמה ל-BigQuery, ל-Oracle ול-Exadata.
ארכיטקטורה של נתונים ואחסון
מבנה הנתונים והאחסון הוא חלק חשוב בכל מערכת לניתוח נתונים, כי הוא משפיע על ביצועי השאילתות, על העלות, על יכולת ההתאמה ועל היעילות.
BigQuery מפריד בין אחסון נתונים לבין מחשוב ומאחסן נתונים ב-Colossus, שבו הנתונים דחוסים ומאוחסנים בפורמט עמודות שנקרא Capacitor.
BigQuery פועל ישירות על נתונים דחוסים בלי לבצע דחיסה, באמצעות Capacitor. BigQuery מספק מערכי נתונים כהפשטה ברמה הגבוהה ביותר כדי לארגן את הגישה לטבלאות, כמו שמוצג בתרשים הקודם. אפשר להשתמש בסכימות ובתוויות כדי לארגן את הטבלאות. BigQuery מציע חלוקה למחיצות כדי לשפר את הביצועים והעלויות של השאילתות ולנהל את מחזור החיים של המידע. משאבי האחסון מוקצים לכם לפי הצריכה, ומבוטלים כשאתם מסירים נתונים או מוחקים טבלאות.
Oracle מאחסן נתונים בפורמט שורות באמצעות פורמט בלוקים של Oracle, שמסודר בפלחים. סכימות (בבעלות המשתמשים) משמשות לארגון טבלאות ואובייקטים אחרים במסד הנתונים. החל מ-Oracle 12c, נעשה שימוש ב-multitenant כדי ליצור מסדי נתונים ניתנים להרכבה בתוך מופע מסד נתונים אחד, לבידוד נוסף. אפשר להשתמש בחלוקה למחיצות כדי לשפר את ביצועי השאילתות ואת הפעולות של מחזור החיים של המידע. Oracle מציעה כמה אפשרויות אחסון למסדי נתונים עצמאיים ולמסדי נתונים של Real Application Clusters (RAC), כמו ASM, מערכת קבצים של מערכת הפעלה ומערכת קבצים של אשכול.
Exadata מספקת תשתית אחסון אופטימלית בשרתי תאי אחסון, ומאפשרת לשרתי Oracle לגשת לנתונים האלה באופן שקוף באמצעות ASM. ב-Exadata יש אפשרויות של דחיסה היברידית של עמודות (HCC), כך שהמשתמשים יכולים לדחוס טבלאות ומחיצות.
ב-Oracle נדרשת הקצאה מראש של קיבולת אחסון, הקפדה על גודל מתאים והגדרות של הגדלה אוטומטית בקטעים, בקבצי נתונים ובאזורי אחסון.
ביצוע שאילתות וביצועים
מערכת BigQuery מנהלת את הביצועים ומתאימה את קנה המידה ברמת השאילתה כדי למקסם את הביצועים ביחס לעלות. BigQuery משתמש בהרבה אופטימיזציות, למשל:
- ביצוע שאילתות בזיכרון
- ארכיטקטורת עץ רב-רמתית שמבוססת על מנוע ההפעלה Dremel
- אופטימיזציה אוטומטית של האחסון ב-Capacitor
- רוחב פס כולל של 1 פטה-ביט לשנייה עם Jupiter
- ניהול משאבים בהתאמה אוטומטית לעומס כדי לספק שאילתות מהירות בהיקף של פטה-בייט
במהלך טעינת הנתונים, BigQuery אוסף נתונים סטטיסטיים על העמודות וכולל מידע על תוכנית השאילתות והתזמון של האבחון. משאבי השאילתה מוקצים בהתאם לסוג השאילתה ולמורכבות שלה. כל שאילתה משתמשת במספר מסוים של משבצות, שהן יחידות חישוב שכוללות כמות מסוימת של מעבד וזיכרון RAM.
Oracle מספקת משימות לאיסוף נתונים סטטיסטיים. כלי האופטימיזציה של מסד הנתונים משתמש בסטטיסטיקות כדי לספק תוכניות ביצוע אופטימליות. יכול להיות שיהיה צורך באינדקסים כדי לבצע במהירות חיפושים של שורות ופעולות איחוד. Oracle מספקת גם מאגר עמודות בזיכרון לניתוח נתונים בזיכרון. Exadata מספקת כמה שיפורים בביצועים, כמו סריקה חכמה של תאים, אינדקסים של אחסון, מטמון פלאש וחיבורי InfiniBand בין שרתי אחסון לשרתי מסד נתונים. אפשר להשתמש ב-Real Application Clusters (RAC) כדי להשיג זמינות גבוהה של השרתים ולהרחיב את מסד הנתונים של אפליקציות שדורשות הרבה משאבי CPU, באמצעות אותו אחסון בסיסי.
כדי לבצע אופטימיזציה של ביצועי השאילתות ב-Oracle, צריך לשקול בקפידה את האפשרויות האלה ואת פרמטרים של מסד הנתונים. Oracle מספקת כמה כלים כמו Active Session History (היסטוריית הפעלות פעילות, ASH), Automatic Database Diagnostic Monitor (כלי אוטומטי לאבחון מסדי נתונים, ADDM), Automatic Workload Repository (מאגר אוטומטי של עומסי עבודה, AWR), SQL monitoring (מעקב אחרי SQL) ו-Tuning Advisor (יועץ לכוונון), וגם יועצים לביטול פעולות ולכוונון זיכרון, כדי לשפר את הביצועים.
ניתוח נתונים גמיש
ב-BigQuery אפשר להפעיל פרויקטים, משתמשים וקבוצות שונים כדי להריץ שאילתות במערכי נתונים בפרויקטים שונים. הפרדה של ביצוע השאילתות מאפשרת לצוותים אוטונומיים לעבוד בפרויקטים שלהם בלי להשפיע על משתמשים ופרויקטים אחרים. ההפרדה מתבצעת על ידי הקצאת מכסות של משבצות זמן וחיוב על שאילתות בנפרד מפרויקטים אחרים ומהפרויקטים שמארחים את מערכי הנתונים.
זמינות גבוהה, גיבויים ותוכנית התאוששות מאסון (DR)
חברת Oracle מספקת את Data Guard כפתרון לתוכנית התאוששות מאסון (DR) ולשכפול מסד נתונים. אפשר להגדיר Real Application Clusters (RAC) כדי להבטיח את זמינות השרת. אפשר להגדיר גיבויים של Recovery Manager (RMAN) למסדי נתונים ולגיבויים של יומני ארכיון, וגם להשתמש בהם לפעולות שחזור. אפשר להשתמש בתכונה Flashback database כדי להחזיר את מסד הנתונים לנקודה ספציפית בזמן. ב-Undo tablespace נשמרות תמונות מצב של הטבלה. אפשר להריץ שאילתות על תמונות מצב ישנות באמצעות שאילתת ה-flashback וסעיפי השאילתה as of, בהתאם לפעולות ה-DML/DDL שבוצעו קודם ולהגדרות undo retention. ב-Oracle, צריך לנהל את תקינות מסד הנתונים בתוך טבלאות שטח שמוגדרות בהתאם למטא-נתונים של המערכת, לביטול ולטבלאות השטח התואמות, כי מודל עקביות חזק חשוב לגיבוי של Oracle, וההליכים לשחזור צריכים לכלול את כל הנתונים הראשיים. אפשר לתזמן ייצוא ברמת סכימת הטבלה אם לא נדרש שחזור מערכת מנקודה מסוימת בזמן (PITR) ב-Oracle.
BigQuery הוא מחסן נתונים מנוהל, והוא שונה ממערכות מסורתיות של מסדי נתונים בגלל פונקציונליות הגיבוי המלאה שלו. אתם לא צריכים להתייחס לבעיות בשרת, לכשלים באחסון, לבאגים במערכת ולשיבושים בנתונים הפיזיים. מערכת BigQuery משכפלת נתונים במרכזי נתונים שונים בהתאם למיקום מערך הנתונים, כדי למקסם את המהימנות והזמינות. הפונקציונליות של BigQuery multi-region יוצרת רפליקה של נתונים באזורים שונים ומגנה מפני חוסר זמינות של אזור יחיד בתוך האזור. הפונקציונליות של BigQuery באזור יחיד יוצרת רפליקה של נתונים בין אזורים שונים באותו אזור.
BigQuery מאפשר להריץ שאילתות על תמונות היסטוריות של טבלאות עד שבעה ימים אחורה, ולשחזר טבלאות שנמחקו תוך יומיים באמצעות time travel.
אפשר להעתיק טבלה שנמחקה (כדי לשחזר אותה) באמצעות תחביר של תמונת מצב (dataset.table@timestamp). אפשר לייצא נתונים מטבלאות BigQuery לצרכי גיבוי נוספים, למשל כדי לשחזר נתונים מפעולות משתמש שבוצעו בטעות. אפשר להשתמש בגיבויים בשיטת גיבוי מוכחת ובתוכניות גיבוי שמשמשות למערכות קיימות של מחסני נתונים (DWH).
פעולות אצווה וטכניקת הצילום מאפשרות להשתמש באסטרטגיות שונות לגיבוי ב-BigQuery, כך שלא צריך לייצא לעיתים קרובות טבלאות ומחיצות שלא השתנו. גיבוי אחד של המחיצה או הטבלה מספיק אחרי שהטעינה או פעולת ה-ETL מסתיימות. כדי לצמצם את עלויות הגיבוי, אפשר לאחסן קובצי ייצוא ב-Cloud Storage Nearline Storage או Coldline Storage ולהגדיר מדיניות מחזור חיים למחיקת קבצים אחרי פרק זמן מסוים, בהתאם לדרישות שמירת הנתונים.
שמירה במטמון
ב-BigQuery יש מטמון לכל משתמש, ואם הנתונים לא משתנים, התוצאות של השאילתות נשמרות במטמון למשך כ-24 שעות. אם התוצאות מאוחזרות מהמטמון, השאילתה לא עולה כסף.
Oracle מציעה כמה מטמונים לנתונים ולתוצאות של שאילתות, כמו buffer cache, result cache, Exadata Flash Cache ומאגר עמודות בזיכרון.
חיבורים
מערכת BigQuery מטפלת בניהול החיבורים, ולא נדרש לבצע הגדרות בצד השרת. BigQuery מספק מנהלי התקנים של JDBC ו-ODBC. אפשר להשתמש בGoogle Cloud מסוף או ב-bq command-line tool כדי לבצע שאילתות אינטראקטיביות. אפשר להשתמש בממשקי REST API ובספריות לקוח כדי לקיים אינטראקציה עם BigQuery באופן פרוגרמטי. אפשר לקשר את Google Sheets ישירות ל-BigQuery ולהשתמש במנהלי התקנים של ODBC ו-JDBC כדי להתחבר ל-Excel. אם אתם מחפשים לקוח למחשב, יש כלים חינמיים כמו DBeaver.
Oracle מספקת listeners, services, service handlers, כמה פרמטרים להגדרה ולכוונון ושרתים משותפים וייעודיים לטיפול בחיבורים למסד הנתונים. Oracle מספקת מנהלי התקנים של JDBC, JDBC Thin, ODBC, Oracle Client וחיבורים של TNS. הפרמטרים scan listeners, scan IP addresses ו-scan-name נדרשים עבור הגדרות RAC.
תמחור ורישוי
Oracle מחייבת תשלום על רישיון ועל תמיכה על סמך מספר ליבות המעבד במהדורות Database ובאפשרויות Database כמו RAC, multitenant, Active Data Guard, partitioning, in-memory, Real Application Testing, GoldenGate, Spatial ו-Graph.
ב-BigQuery יש אפשרויות תמחור גמישות שמבוססות על השימוש באחסון, בשאילתות ובהזנת זרם נתונים. ב-BigQuery יש תמחור לפי קיבולת ללקוחות שצריכים עלות צפויה וקיבולת של משבצות בזמנים ספציפיים באזורים מסוימים. משבצות זמן שמשמשות להוספה ולטעינה של סטרימינג לא נספרות בקיבולת משבצות הזמן של הפרויקט. כדי להחליט כמה משבצות רוצים לרכוש למחסן הנתונים, אפשר לעיין במאמר בנושא תכנון הקיבולת ב-BigQuery.
בנוסף, BigQuery מפחית אוטומטית את עלויות האחסון בחצי עבור נתונים שלא בוצעו בהם שינויים ואוחסנו במשך יותר מ-90 ימים.
תוויות
אפשר לתייג מערכי נתונים, טבלאות ותצוגות של BigQuery באמצעות זוגות של מפתח וערך. אפשר להשתמש בתוויות כדי להבדיל בין עלויות אחסון לבין החזרים כספיים פנימיים.
מעקב ורישום ביומן ביקורת
Oracle מספקת רמות וסוגים שונים של אפשרויות ביקורת על מסדי נתונים, וגם כספת לביקורת ותכונות של חומת אש למסדי נתונים, שנדרש רישיון נפרד כדי להשתמש בהן. אורקל מספקת את Enterprise Manager למעקב אחרי מסדי נתונים.
ב-BigQuery, נעשה שימוש ביומני ביקורת ב-Cloud גם ליומני גישה לנתונים וגם ליומני ביקורת, שמופעלים כברירת מחדל. יומני הגישה לנתונים זמינים למשך 30 ימים, ויומני האירועים האחרים במערכת ופעילות האדמין זמינים למשך 400 ימים. אם אתם צריכים לשמור את היומנים לפרק זמן ארוך יותר, אתם יכולים לייצא אותם ל-BigQuery, ל-Cloud Storage או ל-Pub/Sub, כמו שמתואר במאמר ניתוח יומני אבטחה ב- Google Cloud. אם צריך לשלב עם כלי קיים למעקב אחרי אירועים, אפשר להשתמש ב-Pub/Sub לייצוא, ולבצע פיתוח בהתאמה אישית בכלי הקיים כדי לקרוא יומנים מ-Pub/Sub.
יומני הביקורת כוללים את כל הקריאות ל-API, את הצהרות השאילתות ואת סטטוסי המשימות. אתם יכולים להשתמש ב-Cloud Monitoring כדי לעקוב אחרי הקצאת משבצות, בייטים שנסרקו בשאילתות ובנתונים מאוחסנים, ומדדים אחרים של BigQuery. אפשר להשתמש בתוכנית השאילתות וציר הזמן של BigQuery כדי לנתח את השלבים והביצועים של השאילתות.
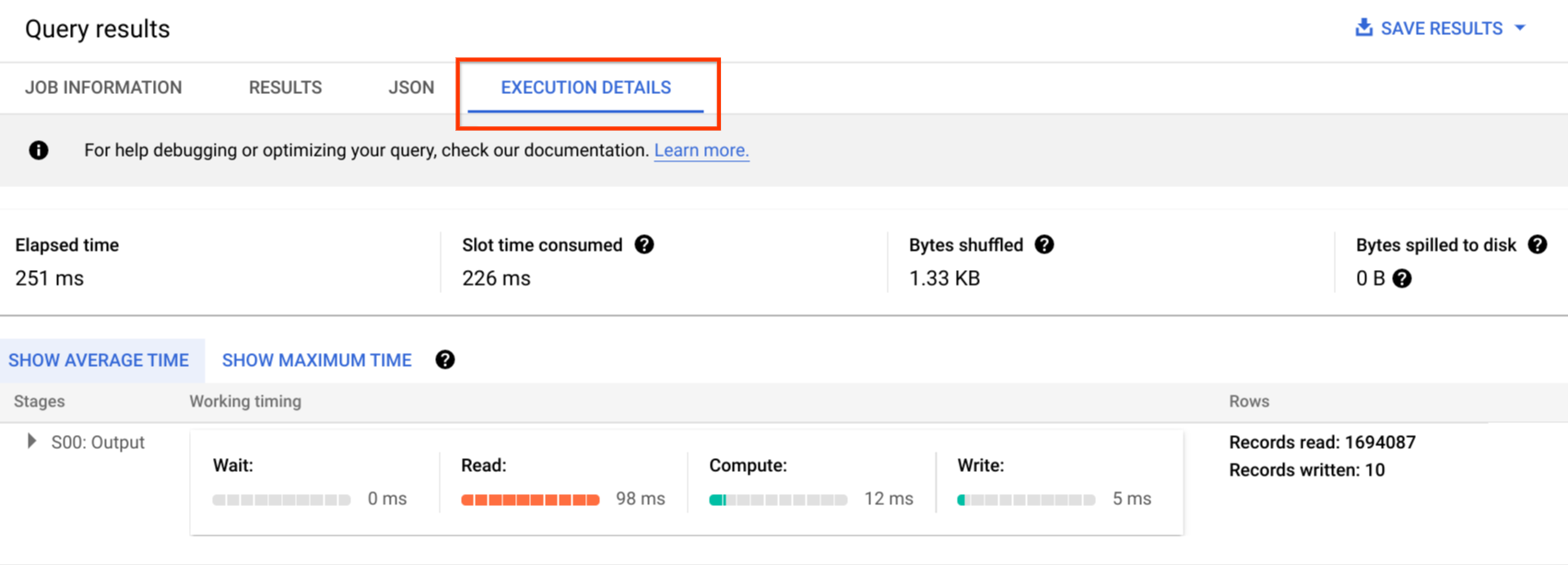
אפשר להשתמש בטבלת הודעות השגיאה כדי לפתור בעיות בשאילתות ובשגיאות ב-API. כדי להבחין בהקצאות של משבצות זמן לכל שאילתה או עבודה, אפשר להשתמש בכלי הזה. הכלי הזה שימושי ללקוחות שמשלמים לפי קיבולת ויש להם הרבה פרויקטים שמפוזרים בין כמה צוותים.
תחזוקה, שדרוגים וגרסאות
BigQuery הוא שירות מנוהל מלא, ולא נדרש לבצע בו תחזוקה או שדרוגים. אין גרסאות שונות של BigQuery. השדרוגים מתבצעים באופן רציף ולא דורשים השבתה או פוגעים בביצועי המערכת. מידע נוסף זמין בהערות לגבי הגרסה.
ב-Oracle וב-Exadata צריך לבצע תיקוני אבטחה, שדרוגים ותחזוקה ברמת מסד הנתונים וברמת התשתית הבסיסית. יש הרבה גרסאות של Oracle, ומתוכננת השקה של גרסה ראשית חדשה בכל שנה. למרות שהגרסאות החדשות תואמות לאחור, יכולים להיות שינויים בביצועי השאילתות, בהקשר ובתכונות.
יכול להיות שיהיו אפליקציות שדורשות גרסאות ספציפיות כמו 10g, 11g, או 12c. שדרוגים גדולים של מסדי נתונים מחייבים תכנון ובדיקה קפדניים. יכול להיות שבמיגרציה מגרסאות שונות יהיו צרכים שונים של המרות טכניות בסעיפי שאילתות ובאובייקטים של מסדי נתונים.
עומסי עבודה
Oracle Exadata תומך בעומסי עבודה מעורבים, כולל עומסי עבודה של OLTP. BigQuery מיועד לניתוח נתונים ולא לטיפול בעומסי עבודה של OLTP. עומסי עבודה של OLTP שמשתמשים באותו Oracle צריכים לעבור מיגרציה ל-Cloud SQL, ל-Spanner או ל-Firestore ב-Google Cloud. Oracle מציעה אפשרויות נוספות כמו Advanced Analytics ו-Spatial and Graph. יכול להיות שיהיה צורך לשכתב את עומסי העבודה האלה כדי להעביר אותם ל-BigQuery. מידע נוסף מופיע במאמר בנושא העברת אפשרויות של Oracle.
פרמטרים והגדרות
Oracle מציעה ומחייבת להגדיר ולכוונן הרבה פרמטרים ברמות OS, Database, RAC, ASM ו-Listener עבור עומסי עבודה ואפליקציות שונים. BigQuery הוא שירות מנוהל מלא, ולא צריך להגדיר בו פרמטרים של אתחול.
מגבלות ומכסות
ל-Oracle יש מגבלות קשיחות ורכות שמבוססות על התשתית, קיבולת החומרה, הפרמטרים, גרסאות התוכנה והרישוי. ב-BigQuery יש מכסות ומגבלות על פעולות ואובייקטים ספציפיים.
הקצאת משאבים ב-BigQuery
BigQuery היא פלטפורמה כשירות (PaaS) ומחסן נתונים בענן לעיבוד מקבילי מאסיבי. הקיבולת שלו גדלה וקטנה בלי התערבות של המשתמש, כי Google מנהלת את הקצה העורפי. לכן, בניגוד למערכות רבות של RDBMS, ב-BigQuery לא צריך להקצות משאבים לפני השימוש. מערכת BigQuery מקצה באופן דינמי משאבי אחסון ושאילתות על סמך דפוסי השימוש שלכם. משאבי האחסון מוקצים לכם כשאתם משתמשים בהם, ומבוטלים כשאתם מסירים נתונים או מוחקים טבלאות. משאבי השאילתות מוקצים בהתאם לסוג ולמורכבות של השאילתה. כל שאילתה משתמשת במשבצות. נעשה שימוש במתזמן הוגנות סופית, כך שיכול להיות שבמהלך תקופות קצרות חלק מהשאילתות יקבלו חלק גדול יותר מהמשבצות, אבל המתזמן יתקן את זה בסופו של דבר.
במונחים של מכונות וירטואליות מסורתיות, BigQuery מספק לכם את המקבילה של שני הדברים הבאים:
- חיוב לפי תשלום לשנייה
- שינוי גודל לפי שנייה
כדי לבצע את המשימה הזו, BigQuery עושה את הפעולות הבאות:
- היא מאפשרת לפרוס משאבים רבים כדי להימנע מהצורך בהרחבה מהירה.
- הוא משתמש במשאבים של ריבוי דיירים כדי להקצות באופן מיידי נתחים גדולים למשך שניות בכל פעם.
- הקצאת משאבים יעילה בין משתמשים עם יתרונות לגודל.
- החיוב מתבצע רק על המשימות שאתם מריצים, ולא על המשאבים שנפרסו, כך שאתם משלמים על המשאבים שבהם אתם משתמשים.
מידע נוסף על התמחור של BigQuery
העברת סכימות
כדי להעביר נתונים מ-Oracle ל-BigQuery, צריך לדעת את סוגי הנתונים של Oracle ואת המיפויים של BigQuery.
סוגי נתונים ב-Oracle ומיפויים ב-BigQuery
סוגי הנתונים ב-Oracle שונים מסוגי הנתונים ב-BigQuery. מידע נוסף על סוגי נתונים ב-BigQuery זמין במאמרי העזרה הרשמיים.
השוואה מפורטת בין סוגי הנתונים ב-Oracle וב-BigQuery זמינה במדריך לתרגום Oracle SQL.
מדדים
בהרבה עומסי עבודה אנליטיים, משתמשים בטבלאות עמודות במקום בחנויות שורות. כך אפשר להגדיל מאוד את הפעולות שמבוססות על עמודות ולבטל את השימוש באינדקסים לצורך ניתוח נתונים באצווה. ב-BigQuery הנתונים מאוחסנים בפורמט עמודתי, ולכן לא צריך אינדקסים. אם עומס העבודה של הניתוח דורש קבוצה קטנה ויחידה של גישה מבוססת-שורה, Bigtable יכול להיות חלופה טובה יותר. אם עומס העבודה דורש עיבוד עסקאות עם עקביות רלציונית חזקה, Spanner או Cloud SQL יכולים להיות חלופות טובות יותר.
לסיכום, לא צריך אינדקסים ב-BigQuery לניתוח נתונים באצווה. אפשר להשתמש בחלוקה למחיצות או באשכולות. מידע נוסף על כוונון ושיפור של ביצועי שאילתות ב-BigQuery זמין במאמר מבוא לאופטימיזציה של ביצועי שאילתות.
תצוגות
בדומה ל-Oracle, BigQuery מאפשר ליצור תצוגות בהתאמה אישית. עם זאת, תצוגות ב-BigQuery לא תומכות בהצהרות DML.
תצוגות מהותיות
תצוגות חומריות משמשות בדרך כלל לשיפור זמן העיבוד של דוחות בסוגים של דוחות ועומסי עבודה שבהם הכתיבה מתבצעת פעם אחת והקריאה מתבצעת פעמים רבות.
תצוגות חומריות מוצעות ב-Oracle כדי לשפר את הביצועים של התצוגות. לשם כך, פשוט יוצרים טבלה ומנהלים אותה כדי להכיל את מערך הנתונים של תוצאת השאילתה. יש שתי דרכים לרענן תצוגות חומריות ב-Oracle: on-commit ו-on-demand.
אפשר להשתמש ב-BigQuery גם בפונקציונליות של תצוגות חומריות. מערכת BigQuery משתמשת בתוצאות שחושבו מראש מתצוגות חומריות, ובכל הזדמנות אפשרית קוראת רק שינויים מצטברים מטבלת הבסיס כדי לחשב תוצאות עדכניות.
פונקציות של שמירת נתונים במטמון ב-Data Studio או בכלי BI מודרניים אחרים יכולות גם לשפר את הביצועים ולבטל את הצורך להריץ מחדש את אותה שאילתה, וכך לחסוך בעלויות.
חלוקת טבלה למחיצות
חלוקה למחיצות של טבלאות נמצאת בשימוש נרחב במחסני נתונים של Oracle. בניגוד ל-Oracle, BigQuery לא תומך בחלוקה היררכית.
BigQuery מטמיע שלושה סוגים של חלוקת טבלאות למחיצות שמאפשרים לשאילתות לציין מסנני פרדיקטים על סמך עמודת החלוקה למחיצות, כדי לצמצם את כמות הנתונים שנסרקים.
- טבלאות שמחולקות למחיצות לפי זמני כתיבת הנתונים: הטבלאות מחולקות למחיצות על סמך זמני כתיבת הנתונים.
- טבלאות עם חלוקה למחיצות לפי עמודה:
הטבלאות מחולקות למחיצות על סמך עמודה מסוג
TIMESTAMPאוDATE. - טבלאות שמחולקות למחיצות לפי טווח מספרים שלמים: הטבלאות מחולקות למחיצות על סמך עמודה של מספרים שלמים.
מידע נוסף על מגבלות ומכסות שחלות על טבלאות עם חלוקה למחיצות ב-BigQuery זמין במאמר מבוא לטבלאות עם חלוקה למחיצות.
אם ההגבלות של BigQuery משפיעות על הפונקציונליות של מסד הנתונים שהועבר, כדאי להשתמש בחלוקה לאופקים במקום בחלוקה למחיצות.
בנוסף, BigQuery לא תומך ב-EXCHANGE PARTITION,
SPLIT PARTITION או בהמרה של טבלה לא מחולקת למחיצות לטבלה מחולקת למחיצות.
סידור באשכולות
האשכולות עוזרים לארגן ולאחזר ביעילות נתונים שמאוחסנים בכמה עמודות, שלרוב ניגשים אליהם יחד. עם זאת, ב-Oracle וב-BigQuery יש נסיבות שונות שבהן האשכולות פועלים בצורה הכי טובה. ב-BigQuery, אם בדרך כלל מסננים ומצברים טבלה עם עמודות ספציפיות, כדאי להשתמש בסידור באשכולות. אפשר להשתמש באשכולות כדי להעביר טבלאות מחולקות לרשימות או מאורגנות לפי אינדקס מ-Oracle.
טבלאות זמניות
בצינורות עיבוד נתונים ETL של Oracle נעשה שימוש בטבלאות זמניות. טבלה זמנית מכילה נתונים במהלך סשן של משתמש. הנתונים האלה נמחקים באופן אוטומטי בסוף הסשן.
BigQuery משתמש בטבלאות זמניות כדי לשמור במטמון תוצאות של שאילתות שלא נכתבות לטבלה קבועה. אחרי ששאילתה מסתיימת, הטבלאות הזמניות קיימות למשך עד 24 שעות. הטבלאות נוצרות במערך נתונים מיוחד, והשמות שלהן נקבעים באופן אקראי. אפשר גם ליצור טבלאות זמניות לשימוש עצמי. מידע נוסף זמין במאמר בנושא טבלאות זמניות.
טבלאות חיצוניות
בדומה ל-Oracle, BigQuery מאפשרת לכם לשלוח שאילתות למקורות נתונים חיצוניים. BigQuery תומך בשליחת שאילתות לנתונים ישירות ממקורות נתונים חיצוניים, כולל:
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob Storage
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google Drive
מידול נתונים
מודלים של נתוני כוכב או פתית שלג יכולים להיות יעילים לאחסון נתונים לצורכי ניתוח, והם נפוצים בשימוש במחסני נתונים ב-Oracle Exadata.
טבלאות לא מנורמלות מבטלות פעולות יקרות של צירוף, וברוב המקרים מספקות ביצועים טובים יותר לניתוח ב-BigQuery. BigQuery תומך גם במודלים של נתוני כוכב ופתית שלג. לפרטים נוספים על עיצוב מחסן נתונים ב-BigQuery, אפשר לעיין במאמר עיצוב סכימה.
פורמט שורות לעומת פורמט עמודות ומגבלות שרת לעומת serverless
Oracle משתמשת בפורמט שורות שבו שורת הטבלה מאוחסנת בבלוקים של נתונים, ולכן עמודות לא נחוצות מאוחזרות בבלוק עבור שאילתות ניתוח, על סמך סינון וצבירה של עמודות ספציפיות.
ל-Oracle יש ארכיטקטורה של 'הכול משותף', עם תלות קבועה במשאבי חומרה, כמו זיכרון ואחסון, שמוקצים לשרת. אלה שני הכוחות העיקריים שמשפיעים על הרבה טכניקות של מידול נתונים שהתפתחו כדי לשפר את יעילות האחסון ואת הביצועים של שאילתות אנליטיות. חלק מהן הן סכימות של כוכבים ופתיתי שלג, ומידול של כספת נתונים.
ב-BigQuery נעשה שימוש בפורמט עמודות לאחסון נתונים, ואין מגבלות קבועות על נפח האחסון והזיכרון. הארכיטקטורה הזו מאפשרת לכם לבצע דה-נורמליזציה נוספת ולעצב סכימות על סמך קריאות וצרכים עסקיים, וכך להפחית את המורכבות ולשפר את הגמישות, את יכולת ההתאמה ואת הביצועים.
דה-נורמליזציה
אחת מהמטרות העיקריות של נירמול מסד נתונים רלציוני היא צמצום יתירות הנתונים. המודל הזה מתאים במיוחד למסד נתונים רלציוני שמשתמש בפורמט שורות, אבל ביטול הנרמול של הנתונים עדיף למסדי נתונים עמודתיים. מידע נוסף על היתרונות של דה-נורמליזציה של נתונים ועל אסטרטגיות אחרות לאופטימיזציה של שאילתות ב-BigQuery זמין במאמר בנושא דה-נורמליזציה.
טכניקות לשיטוח הסכימה הקיימת
הטכנולוגיה של BigQuery משלבת גישה לנתונים ועיבוד שלהם בפורמט עמודות, אחסון בזיכרון ועיבוד מבוזר כדי לספק ביצועים איכותיים של שאילתות.
כשמתכננים סכימה של מחסן נתונים ב-BigQuery, עדיף ליצור טבלת עובדות במבנה של טבלה שטוחה (איחוד כל טבלאות המימדים לרשומה אחת בטבלת העובדות) מאשר להשתמש בכמה טבלאות מימדים של מחסן נתונים. בנוסף לשימוש מופחת בנפח אחסון, טבלה שטוחה ב-BigQuery מובילה לשימוש מופחת ב-JOIN. התרשים הבא ממחיש דוגמה להשטחת הסכימה.
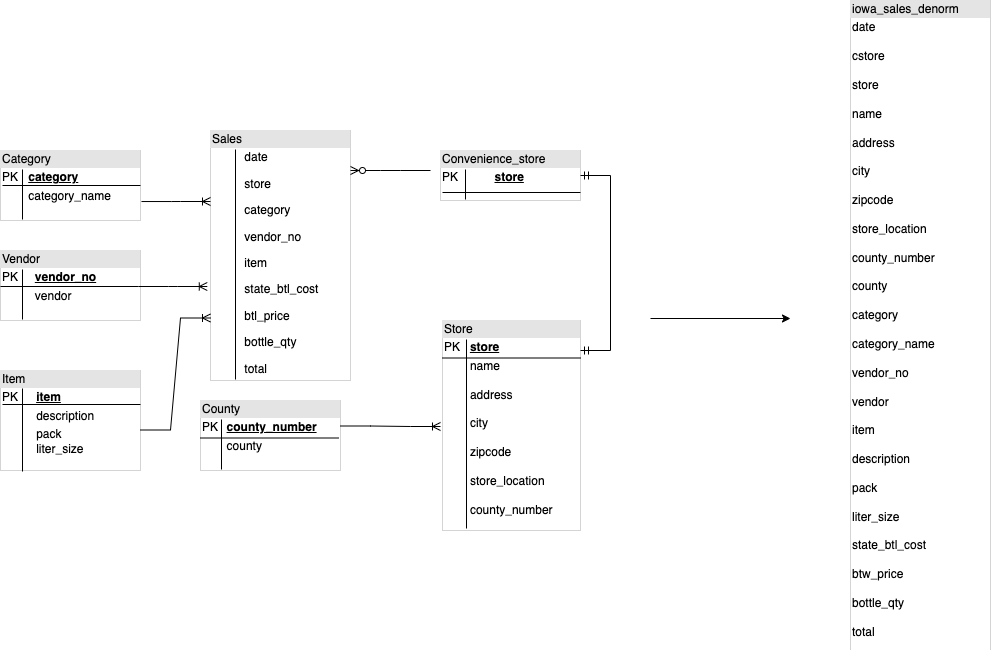
דוגמה להשטחה של סכמת כוכב
באיור 1 מוצג מסד נתונים פיקטיבי לניהול מכירות שכולל ארבע טבלאות:
- טבלת הזמנות/מכירות (טבלת עובדות)
- טבלת עובדים
- טבלת המיקומים
- טבלת לקוחות
המפתח הראשי של טבלת המכירות הוא OrderNum, שמכיל גם מפתחות זרים לשלוש הטבלאות האחרות.
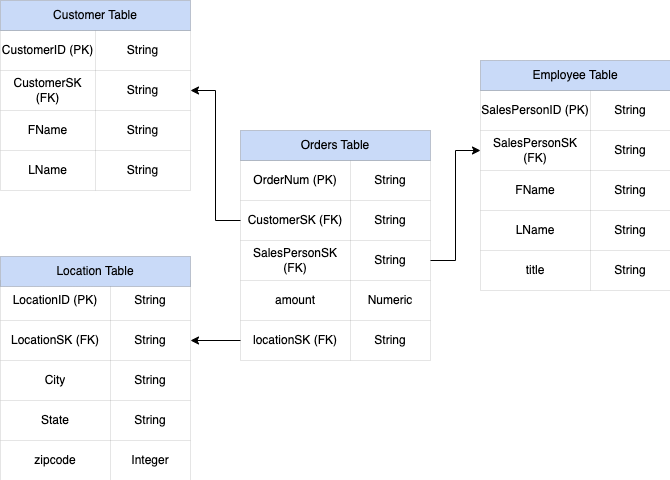
איור 1: נתוני מכירות לדוגמה בסכימת כוכב
נתונים לדוגמה
תוכן של הזמנות/טבלת עובדות
| OrderNum | CustomerID | SalesPersonID | amount | מיקום |
|---|---|---|---|---|
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14.66 | 18 | |
| O-4 | 4567 | 4 | 182.00 | 26 |
תוכן טבלת העובדים
| SalesPersonID | FName | LName | כותרת |
|---|---|---|---|
| 1 | Alex | סמית' | שותף מכירות |
| 4 | ליסה | כהן | שותף מכירות |
| 12 | יונתן | כהן | שותף מכירות |
תוכן בטבלת הלקוחות
| CustomerID | FName | LName |
|---|---|---|
| 1234 | אמנדה | Lee |
| 4567 | מאט | Ryan |
תוכן טבלת המיקומים
| מיקום | עיר | הסמוי הסופי | מיקוד |
|---|---|---|---|
| 18 | ברונקס | NY | 10452 |
| 26 | מאונטיין ויו | CA | 90210 |
| 27 | אמריקה/שיקגו | IL | 60613 |
שאילתה להשטחת הנתונים באמצעות LEFT OUTER JOIN
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
פלט הנתונים השטוחים
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | amount | מיקום | עיר | הסמוי הסופי | מיקוד |
|---|---|---|---|---|---|---|---|---|---|---|---|
| O-1 | 1234 | אמנדה | Lee | 12 | יונתן | כהן | 234.22 | 18 | ברונקס | NY | 10452 |
| O-2 | 4567 | מאט | Ryan | 1 | Alex | סמית' | 192.10 | 27 | אמריקה/שיקגו | IL | 60613 |
| O-3 | 12 | יונתן | כהן | 14.66 | 18 | ברונקס | NY | 10452 | |||
| O-4 | 4567 | מאט | Ryan | 4 | ליסה | כהן | 182.00 | 26 | הר
הצגה |
CA | 90210 |
שדות בתוך שדות ושדות חוזרים
כדי לעצב וליצור סכימת DWH מסכימה רלציונית (לדוגמה, סכימות של כוכב ופתית שלג שמכילות טבלאות של מידות ועובדות), BigQuery מציג את הפונקציונליות של שדות מקוננים וחוזרים. לכן, אפשר לשמור על מערכות היחסים באופן דומה לסקמת DWH רלציונית שעברה נרמול (או נרמול חלקי), בלי להשפיע על הביצועים. מידע נוסף זמין במאמר בנושא שיטות מומלצות לשיפור הביצועים.
כדי להבין טוב יותר את ההטמעה של שדות בתוך שדות ושדות חוזרים, אפשר לעיין בסכימה פשוטה של יחסים בין טבלה CUSTOMERS לבין טבלה ORDER או טבלה SALES. הן שתי טבלאות שונות, אחת לכל ישות, והקשרים מוגדרים באמצעות מפתח כמו מפתח ראשי ומפתח זר כקישור בין הטבלאות בזמן ביצוע שאילתה באמצעות JOINs. שדות מקוננים וחוזרים ב-BigQuery מאפשרים לשמור על אותו קשר בין הישויות בטבלה אחת. אפשר ליישם את זה על ידי שמירת כל נתוני הלקוחות, כשנתוני ההזמנות מוטמעים בכל אחד מהלקוחות. מידע נוסף זמין במאמר בנושא ציון עמודות מקוננות ועמודות חוזרות.
כדי להמיר את המבנה השטוח לסכימה עם שדות בתוך שדות או שדות חוזרים, צריך להוסיף את השדות בתוך שדות באופן הבא:
-
CustomerID,FName,LNameמוטמעים בשדה חדש שנקראCustomer. -
SalesPersonID,FName,LNameמוטמעים בשדה חדש שנקראSalesperson. -
LocationID,city,state,zip codeמוטמעים בשדה חדש שנקראLocation.
השדות OrderNum ו-amount לא מוצגים כרכיבים מוטמעים, כי הם מייצגים רכיבים ייחודיים.
אתם רוצים שהסכימה תהיה גמישה מספיק כדי לאפשר לכל הזמנה לכלול יותר מלקוח אחד: לקוח ראשי ולקוח משני. השדה customer מסומן כשדה חוזר. הסכימה שמתקבלת מוצגת באיור 2, שממחיש שדות מקוננים ושדות שחוזרים על עצמם.
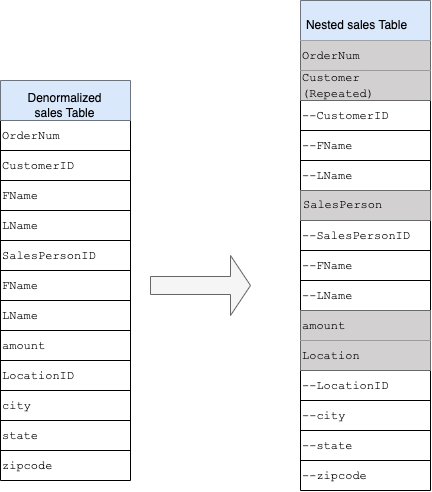
איור 2: ייצוג לוגי של מבנה מוטמע
במקרים מסוימים, דה-נורמליזציה באמצעות שדות בתוך שדות ושדות חוזרים לא מובילה לשיפורים בביצועים. מידע נוסף על מגבלות והגבלות זמין במאמר ציון עמודות מקוננות ועמודות חוזרות בסכימות של טבלאות.
מפתחות ממלאי מקום (Surrogate keys)
מקובל לזהות שורות עם מפתחות ייחודיים בטבלאות. ב-Oracle, רצפים משמשים בדרך כלל ליצירת המפתחות האלה. ב-BigQuery אפשר ליצור מפתחות סרוגייט באמצעות הפונקציות row_number ו-partition by. מידע נוסף זמין במאמר BigQuery and surrogate keys: a practical approach.
מעקב אחרי שינויים והיסטוריה
כשמתכננים העברה של מחסן נתונים (DWH) ל-BigQuery, כדאי להכיר את המושג 'מאפיינים שמשתנים לאט' (SCD). באופן כללי, המונח SCD מתאר את התהליך של ביצוע שינויים (פעולות DML) בטבלאות המאפיינים.
מכמה סיבות, במחסני נתונים מסורתיים נעשה שימוש בסוגים שונים כדי לטפל בשינויים בנתונים ולשמור נתונים היסטוריים בממדים שמשתנים לאט. השימושים האלה בסוגים נדרשים בגלל מגבלות החומרה ודרישות היעילות שצוינו קודם. מכיוון שהאחסון זול בהרבה מהמחשוב, ויש לו יכולת התאמה אינסופית, מומלץ להשתמש בשכפול נתונים ובנתונים עודפים אם זה מוביל לשאילתות מהירות יותר ב-BigQuery. אפשר להשתמש בטכניקות של צילום תמונת מצב של הנתונים, שבהן כל הנתונים נטענים למחיצות יומיות חדשות.
תצוגות ספציפיות לתפקיד ולמשתמש
כדאי להשתמש בתצוגות ספציפיות לתפקיד ולמשתמש אם המשתמשים שייכים לצוותים שונים וצריכים לראות רק את הרשומות והתוצאות שהם צריכים.
BigQuery תומך בcolumn- ובאבטחה ברמת השורה. אבטחה ברמת העמודה מספקת גישה מדויקת לעמודות עם נתונים רגישים באמצעות תגי מדיניות, או סיווג מבוסס-נתונים. אבטחה ברמת השורה שמאפשרת לכם לסנן נתונים ולתת גישה לשורות ספציפיות בטבלה על סמך תנאים שמשתמשים עומדים בהם.
העברת נתונים
בקטע הזה מפורט מידע על העברת נתונים מ-Oracle ל-BigQuery, כולל טעינה ראשונית, לכידת נתונים לשינוי (CDC) וכלים וגישות של ETL/ELT.
פעילויות שקשורות להעברה
מומלץ לבצע את ההעברה בשלבים, על ידי זיהוי תרחישי שימוש מתאימים להעברה. יש כמה כלים ושירותים שזמינים להעברת נתונים מ-Oracle אל Google Cloud. הרשימה הזו לא מקיפה, אבל היא נותנת מושג לגבי הגודל וההיקף של מאמצי ההעברה.
ייצוא נתונים מ-Oracle: מידע נוסף זמין במאמרים בנושא טעינה ראשונית וCDC והטמעת עדכונים בזמן אמת מ-Oracle ל-BigQuery. אפשר להשתמש בכלי ETL לטעינה הראשונית.
הכנת הנתונים (ב-Cloud Storage): Cloud Storage הוא המקום המומלץ להעברת נתונים (אזור הכנה) שמיוצאים מ-Oracle. Cloud Storage מיועד להטמעה מהירה וגמישה של נתונים מובְנים או לא מובְנים.
תהליך ETL: מידע נוסף זמין במאמר בנושא העברת ETL/ELT.
טעינת נתונים ישירות ל-BigQuery: אפשר לטעון נתונים ל-BigQuery ישירות מ-Cloud Storage, דרך Dataflow או דרך סטרימינג בזמן אמת. משתמשים ב-Dataflow כשנדרש סידור נתונים.
טעינה ראשונית
ההעברה של הנתונים הראשוניים ממחסן הנתונים הקיים של Oracle אל BigQuery עשויה להיות שונה מצינורות ה-ETL/ELT המצטברים, בהתאם לגודל הנתונים ולרוחב הפס של הרשת. אפשר להשתמש באותם צינורות ETL/ELT אם גודל הנתונים הוא כמה טרה-בייט.
אם הנתונים מגיעים לכמה טרה-בייט, יכול להיות שיהיה יעיל יותר להשתמש ב-gcloud storage כדי לייצא את הנתונים ולהעביר אותם, מאשר להשתמש בשיטה של JdbcIO לחילוץ נתונים ממסד נתונים באופן פרוגרמטי. הסיבה לכך היא שגישות פרוגרמטיות עשויות לדרוש כוונון ביצועים הרבה יותר מדויק. אם גודל הנתונים גדול מכמה טרה-בייט והנתונים מאוחסנים בענן או באחסון אונליין (כמו Amazon Simple Storage Service (Amazon S3)), כדאי להשתמש בשירות העברת הנתונים ל-BigQuery. להעברות בקנה מידה גדול (במיוחד העברות עם רוחב פס מוגבל ברשת), Transfer Appliance הוא אפשרות שימושית.
מגבלות לטעינה ראשונית
כשמתכננים העברת נתונים, כדאי להתייחס לנקודות הבאות:
- גודל הנתונים ב-Oracle DWH: גודל הסכימה של המקור משפיע באופן משמעותי על שיטת העברת הנתונים שנבחרה, במיוחד אם גודל הנתונים גדול (טרה-בייט ומעלה). אם גודל הנתונים קטן יחסית, תהליך העברת הנתונים יכול להסתיים בפחות שלבים. הטיפול בנתונים גדולים הופך את התהליך הכולל למורכב יותר.
זמן השבתה: חשוב להחליט אם זמן השבתה הוא אפשרות להעברה ל-BigQuery. כדי לצמצם את זמן ההשבתה, אפשר לטעון בכמות גדולה את הנתונים ההיסטוריים הקבועים ולהשתמש בפתרון CDC כדי להתעדכן בשינויים שמתרחשים במהלך תהליך ההעברה.
תמחור: בתרחישים מסוימים, יכול להיות שתצטרכו כלי שילוב של צד שלישי (לדוגמה, כלי ETL או כלי שכפול) שדורשים רישיונות נוספים.
העברת נתונים ראשונית (באצווה)
העברת נתונים באמצעות שיטת אצווה מציינת שהנתונים ייוצאו באופן עקבי בתהליך יחיד (לדוגמה, ייצוא נתוני סכימת Oracle DWH לקובצי CSV, Avro או Parquet, או ייבוא ל-Cloud Storage כדי ליצור מערכי נתונים ב-BigQuery). אפשר להשתמש בכל הכלים והמושגים של ETL שמוסברים במאמר בנושא העברת ETL/ELT לטעינה הראשונית.
אם אתם לא רוצים להשתמש בכלי ETL/ELT לטעינה הראשונית, אתם יכולים לכתוב סקריפטים בהתאמה אישית כדי לייצא נתונים לקבצים (CSV, Avro או Parquet) ולהעלות את הנתונים האלה ל-Cloud Storage באמצעות gcloud storage, שירות העברת הנתונים ל-BigQuery או Transfer Appliance. מידע נוסף על שיפור הביצועים של העברות נתונים גדולות ועל אפשרויות העברה אפשר למצוא במאמר העברת מערכי נתונים גדולים. לאחר מכן טוענים נתונים מ-Cloud Storage ל-BigQuery.
Cloud Storage הוא פתרון אידיאלי לטיפול בנחיתה הראשונית של נתונים. Cloud Storage הוא שירות אחסון אובייקטים עם זמינות גבוהה ועמידות גבוהה, ללא הגבלות על מספר הקבצים, ואתם משלמים רק על נפח האחסון שבו אתם משתמשים. השירות מותאם לעבודה עם שירותים אחרים של Google Cloud Google, כמו BigQuery ו-Dataflow.
CDC והטמעת עדכונים בזמן אמת מ-Oracle ל-BigQuery
יש כמה דרכים לתעד את הנתונים ששונו מ-Oracle. לכל אפשרות יש חסרונות, בעיקר בהשפעה על הביצועים במערכת המקורית, בדרישות הפיתוח וההגדרה, בתמחור ובהרשאות הרישיון.
CDC מבוסס-יומנים
Oracle GoldenGate הוא הכלי המומלץ של Oracle לחילוץ יומני שינויים, ואפשר להשתמש ב-GoldenGate for Big Data כדי להזרים יומנים ל-BigQuery. GoldenGate דורש רישוי לכל יחידת עיבוד מרכזית (CPU). למידע על המחיר, אפשר לעיין במחירון העולמי של Oracle Technology. אם Oracle GoldenGate for Big Data זמין (במקרה שכבר נרכשו רישיונות), שימוש ב-GoldenGate יכול להיות בחירה טובה ליצירת צינורות נתונים להעברת נתונים (טעינה ראשונית) ולאחר מכן לסנכרון כל שינוי הנתונים.
Oracle XStream
Oracle מאחסנת כל פעולת commit בקובצי יומן redo, ואפשר להשתמש בקובצי ה-redo האלה ל-CDC. Oracle XStream Out מבוסס על LogMiner ומסופק על ידי כלים של צד שלישי כמו Debezium (מגרסה 0.8) או באופן מסחרי באמצעות כלים כמו Striim. כדי להשתמש ב-XStream APIs צריך לרכוש רישיון ל-Oracle GoldenGate, גם אם GoldenGate לא מותקן ולא נעשה בו שימוש. XStream מאפשרת לכם להפיץ הודעות Streams בין Oracle לבין תוכנות אחרות ביעילות.
Oracle LogMiner
לא נדרש רישיון מיוחד ל-LogMiner. אפשר להשתמש באפשרות LogMiner במחבר הקהילה של Debezium. הוא זמין גם באופן מסחרי באמצעות כלים כמו Attunity, Striim או StreamSets. יכול להיות של-LogMiner תהיה השפעה מסוימת על הביצועים של מסד נתונים פעיל מאוד כמקור, ולכן צריך להשתמש בו בזהירות במקרים שבהם נפח השינויים (גודל ה-redo) הוא יותר מ-10GB לשעה, בהתאם למעבד, לזיכרון ולקיבולת הקלט/פלט של השרת ולניצול שלהם.
CDC שמבוסס על SQL
זהו תהליך ETL מצטבר שבו שאילתות SQL בודקות באופן רציף את טבלאות המקור כדי לזהות שינויים, בהתאם למפתח שגדל באופן מונוטוני ולעמודת חותמת הזמן שמכילה את התאריך של השינוי או ההוספה האחרונים. אם אין מפתח עם עלייה מונוטונית, שימוש בעמודת חותמת הזמן (תאריך השינוי) עם דיוק קטן (שניות) עלול לגרום לרשומות כפולות או לנתונים חסרים, בהתאם לנפח ולאופרטור ההשוואה, כמו > או >=.
כדי לפתור בעיות כאלה, אפשר להשתמש ברמת דיוק גבוהה יותר בעמודות של חותמות זמן, כמו שש ספרות אחרי הנקודה העשרונית (מיקרו-שניות, שהיא רמת הדיוק המקסימלית שנתמכת ב-BigQuery), או להוסיף משימות לביטול כפילויות בצינור ה-ETL/ELT, בהתאם למפתחות העסקיים ולמאפייני הנתונים.
כדי לשפר את הביצועים של החילוץ ולצמצם את ההשפעה על מסד הנתונים של המקור, צריך ליצור אינדקס בעמודה של המפתח או חותמת הזמן. פעולות מחיקה הן אתגר בשיטה הזו, כי צריך לטפל בהן באפליקציית המקור בשיטת מחיקה רכה, כמו הוספת דגל מחיקה ועדכון של last_modified_date. פתרון חלופי הוא רישום הפעולות האלה בטבלה אחרת באמצעות טריגר.
טריגרים
אפשר ליצור טריגרים במסד נתונים בטבלאות מקור כדי לרשום שינויים בטבלאות של יומן צללים. בטבלאות של יומן השינויים אפשר לשמור שורות שלמות כדי לעקוב אחרי כל שינוי בעמודה, או לשמור רק את המפתח הראשי עם סוג הפעולה (הוספה, עדכון או מחיקה). אחרי זה אפשר לתעד את הנתונים ששונו באמצעות גישה מבוססת-SQL שמתוארת במאמר בנושא CDC מבוסס-SQL. שימוש בטריגרים יכול להשפיע על ביצועי העסקאות ולהכפיל את זמן האחזור של פעולת DML בשורה אחת אם מאוחסנת שורה מלאה. אפשר לצמצם את התקורה הזו על ידי אחסון רק של המפתח הראשי, אבל במקרה כזה, נדרשת פעולת JOIN עם הטבלה המקורית בחילוץ מבוסס-SQL, ולכן השינוי הביניים לא נכלל.
העברה של ETL/ELT
יש הרבה אפשרויות לטיפול ב-ETL/ELT ב- Google Cloud. המסמך הזה לא כולל הנחיות טכניות לגבי המרות ספציפיות של עומסי עבודה של ETL. בהתאם למגבלות כמו עלות וזמן, אפשר לשקול גישה של העברה והפעלה או לשנות את הארכיטקטורה של פלטפורמת שילוב הנתונים. מידע נוסף על העברת צינורות נתונים אל Google Cloud ועל מושגים רבים אחרים שקשורים להעברת נתונים זמין במאמר העברת צינורות נתונים.
גישת חיתוך והעברה
אם הפלטפורמה הקיימת שלכם תומכת ב-BigQuery ואתם רוצים להמשיך להשתמש בכלי הקיים לשילוב נתונים:
- אתם יכולים להשאיר את פלטפורמת ה-ETL/ELT כמו שהיא ולשנות את שלבי האחסון הנדרשים באמצעות BigQuery במשימות ה-ETL/ELT.
- אם אתם רוצים להעביר גם את פלטפורמת ה-ETL/ELT אל Google Cloud , אתם יכולים לשאול את הספק אם הכלי שלו מורשה ב- Google Cloud. אם כן, תוכלו להתקין אותו ב-Compute Engine או לבדוק ב-Google Cloud Marketplace.
במאמר שותפים של BigQuery יש מידע על ספקי פתרונות לשילוב נתונים.
שינוי הארכיטקטורה של פלטפורמת ETL/ELT
אם אתם רוצים לשנות את הארכיטקטורה של צינורות הנתונים, מומלץ מאוד להשתמש בשירותים של Google Cloud .
Cloud Data Fusion
Cloud Data Fusion הוא שירות מנוהל של CDAP ב- Google Cloud שמציע ממשק חזותי עם הרבה תוספים למשימות כמו גרירה ושחרור ופיתוח צינורות עיבוד נתונים. אפשר להשתמש ב-Cloud Data Fusion כדי ללכוד נתונים ממגוון רחב של מערכות מקור, והוא מציע יכולות של שכפול באצוות ושל שכפול בסטרימינג. אפשר להשתמש בתוספים של Cloud Data Fusion או של Oracle כדי ללכוד נתונים מ-Oracle. אפשר להשתמש בתוסף BigQuery כדי לטעון את הנתונים ל-BigQuery ולטפל בעדכוני סכימה.
לא מוגדרת סכימת פלט גם בתוספי המקור וגם בתוספי היעד, ונעשה שימוש ב-select * from בתוסף המקור כדי לשכפל גם עמודות חדשות.
אפשר להשתמש בתכונה Wrangle של Cloud Data Fusion לטיוב נתונים ולהכנה.
Dataflow
Dataflow היא פלטפורמה לעיבוד נתונים ללא שרתים (serverless), שיכולה להתאים את עצמה לעומס (autoscaling) וגם לעבד נתונים באצווה ובסטרימינג. Dataflow יכול להיות בחירה טובה למפתחי Python ו-Java שרוצים לקודד את צינורות הנתונים שלהם ולהשתמש באותו קוד גם לסטרימינג וגם לעומסי עבודה של אצווה. אפשר להשתמש בתבנית JDBC ל-BigQuery כדי לחלץ נתונים ממסדי נתונים של Oracle או ממסדי נתונים רלציוניים אחרים, ולטעון אותם ל-BigQuery.
Managed Service for Apache Airflow
Managed Airflow הוא שירות מנוהל לתזמור תהליכי עבודה שמבוסס על Apache Airflow. Google Cloud הוא מאפשר ליצור, לתזמן ולנטר צינורות עיבוד נתונים בין סביבות ענן ומרכזי נתונים מקומיים. Managed Airflow מספק אופרטורים ותרומות שיכולים להפעיל טכנולוגיות מרובות עננים לתרחישי שימוש שכוללים חילוץ וטעינה, שינויים ב-ELT וקריאות ל-API בארכיטקטורת REST.
Managed Airflow משתמש בגרפים אציקליים מכוונים (DAG) לתזמון ולתזמור של תהליכי עבודה. כדי להבין את המושגים הכלליים של Airflow, אפשר לעיין במאמר מושגים של Airflow Apache. מידע נוסף על DAG זמין במאמר בנושא כתיבת DAG (תהליכי עבודה). דוגמאות לשיטות מומלצות ל-ETL באמצעות Apache Airflow זמינות במאמר ETL best practices with Airflow documentation site¶. אפשר להחליף את האופרטור של Hive בדוגמה הזו באופרטור של BigQuery, והמושגים יהיו רלוונטיים.
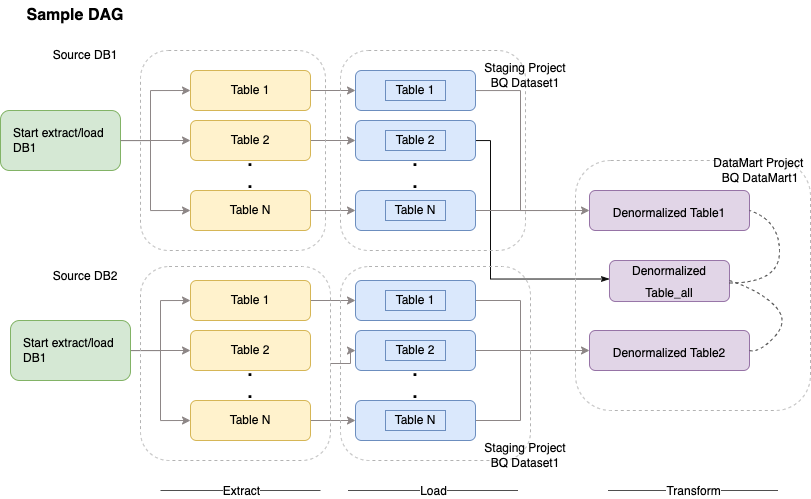
קטע קוד לדוגמה הבא הוא חלק כללי של DAG לדוגמה שמתאים לתרשים שלמעלה:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
הקוד שלמעלה ניתן להמחשה בלבד ואי אפשר להשתמש בו כמו שהוא.
Dataprep by Trifacta
Dataprep הוא שירות נתונים שמאפשר לבדוק בצורה חזותית, לנקות ולהכין נתונים מובְנים ולא מובְנים לניתוח, לדיווח וללמידת מכונה. מייצאים את נתוני המקור לקובצי JSON או CSV, מבצעים טרנספורמציה של הנתונים באמצעות Dataprep וטוענים את הנתונים באמצעות Dataflow. לדוגמה, אפשר לעיין במאמר העברת נתוני Oracle (ETL) ל-BigQuery באמצעות Dataflow ו-Dataprep.
Managed Service for Apache Spark
Managed Service for Apache Spark הוא שירות Hadoop מנוהל של Google. אפשר להשתמש ב-Sqoop כדי לייצא נתונים מ-Oracle וממסדי נתונים רלציוניים רבים ל-Cloud Storage כקובצי Avro, ואז לטעון קובצי Avro ל-BigQuery באמצעות bq tool. בדרך כלל מתקינים כלי ETL כמו CDAP ב-Hadoop, שמשתמשים ב-JDBC כדי לחלץ נתונים וב-Apache Spark או ב-MapReduce כדי לבצע טרנספורמציות של הנתונים.
כלים של שותפים להעברת נתונים
יש כמה ספקים בתחום החילוץ, הטרנספורמציה והטעינה (ETL). חברות מובילות בשוק ה-ETL כמו Informatica, Talend, Matillion, Infoworks, Stitch, Fivetran ו-Striim ביצעו שילוב עמוק עם BigQuery ועם Oracle, ויכולות לעזור בחילוץ, בשינוי ובטעינה של נתונים, ובניהול של תהליכי עבודה לעיבוד.
כלים ל-ETL קיימים כבר הרבה שנים. חלק מהארגונים עשויים להעדיף להשתמש בהשקעה קיימת בסקריפטים מהימנים של ETL. חלק מפתרונות השותפים העיקריים שלנו מופיעים באתר השותפים של BigQuery. ההחלטה מתי להשתמש בכלים של שותפים במקום בכלי השירות המובנים שלGoogle Cloud תלויה בתשתית הנוכחית ובמידת הנוחות של צוות ה-IT שלכם בפיתוח צינורות נתונים בקוד Java או Python.
העברה של כלי בינה עסקית (BI)
BigQuery תומך בחבילה גמישה של פתרונות בינה עסקית (BI) לדיווח ולניתוח שתוכלו להשתמש בהם. מידע נוסף על העברת כלי BI ושילוב עם BigQuery זמין במאמר סקירה כללית על ניתוח הנתונים ב-BigQuery.
תרגום שאילתות (SQL)
GoogleSQL של BigQuery תומך בתאימות לתקן SQL 2011 ויש לו הרחבות שתומכות בשאילתות של נתונים מקוננים וחוזרים. אפשר להשתמש בכל הפונקציות והאופרטורים של SQL שתואמים לתקן ANSI, עם שינויים מינימליים. השוואה מפורטת בין התחביר והפונקציות של Oracle ו-BigQuery SQL זמינה במאמר הפניות לתרגום מ-Oracle ל-BigQuery SQL.
אפשר להשתמש בתרגום SQL באצווה כדי להעביר את קוד ה-SQL בכמות גדולה, או בתרגום SQL אינטראקטיבי כדי לתרגם שאילתות אד-הוק.
אפשרויות להעברת Oracle
בקטע הזה מוצגות המלצות והפניות לארכיטקטורה להמרת אפליקציות שמשתמשות בפונקציות של Oracle Data Mining, R ו-Spatial and Graph.
האפשרות Oracle Advanced Analytics
אורקל מציעה אפשרויות מתקדמות לניתוח נתונים לצורך כריית נתונים, אלגוריתמים בסיסיים של למידת מכונה (ML) ושימוש ב-R. האפשרות 'ניתוח מתקדם' דורשת רישיון. אתם יכולים לבחור מתוך רשימה מקיפה של מוצרי AI/ML של Google, בהתאם לצרכים שלכם, החל משלב הפיתוח ועד לשלב הייצור בקנה מידה גדול.
Oracle R Enterprise
Oracle R Enterprise (ORE), רכיב באפשרות Oracle Advanced Analytics, מאפשר לשלב את שפת התכנות הסטטיסטית R בקוד פתוח עם Oracle Database. בפריסות רגילות של ORE, R מותקן בשרת Oracle.
אם יש לכם נתונים בהיקף גדול מאוד או שאתם משתמשים בגישות של Data Warehousing, שילוב של R עם BigQuery הוא בחירה אידיאלית. אפשר להשתמש בספריית R bigrquery בקוד פתוח כדי לשלב את R עם BigQuery.
Google משתפת פעולה עם RStudio כדי להנגיש למשתמשים את הכלים המתקדמים ביותר בתחום. אפשר להשתמש ב-RStudio כדי לגשת לנתונים בנפח טרה-בייט ב-BigQuery, להתאים מודלים ב-TensorFlow ולהריץ מודלים של למידת מכונה בהיקף גדול באמצעות AI Platform. ב- Google Cloud, אפשר להתקין את R ב- Compute Engine בהיקף גדול.
Oracle Data Mining
Oracle Data Mining (ODM), רכיב באפשרות Oracle Advanced Analytics, מאפשר למפתחים לבנות מודלים של למידת מכונה באמצעות Oracle PL/SQL Developer ב-Oracle.
בעזרת BigQuery ML, מפתחים יכולים להריץ סוגים רבים ושונים של מודלים, כמו רגרסיה לינארית, רגרסיה לוגיסטית בינארית, רגרסיה לוגיסטית מרובת מחלקות, אשכולות k-means וייבוא מודלים של TensorFlow. מידע נוסף זמין במאמר מבוא ל-BigQuery ML.
יכול להיות שתצטרכו לשכתב את הקוד כדי להמיר משימות ODM. אתם יכולים לבחור מתוך מגוון מוצרי Google AI, כמו BigQuery ML, ממשקי AI API (Speech-to-Text, Text-to-Speech, Dialogflow, Cloud Translation, Cloud Natural Language API, Cloud Vision ועוד) או פלטפורמת הסוכנים של Gemini Enterprise.
אפשר להשתמש ב-Vertex AI Workbench כסביבת פיתוח למדעני נתונים, וב-Vertex AI Training כדי להריץ עומסי עבודה של אימון ודירוג בהיקף נרחב.
אפשרות של תרשים מרחבי
Oracle מציעה את האפשרות Spatial and Graph לשאילתות של גיאומטריה וגרפים, ונדרש רישיון לאפשרות הזו. אתם יכולים להשתמש בפונקציות הגיאומטריה ב-BigQuery ללא עלויות או רישיונות נוספים, ולהשתמש במסדי נתונים אחרים של גרפים ב- Google Cloud.
מרחבי
BigQuery מציע פונקציות וסוגי נתונים של ניתוח נתונים גיאו-מרחביים. מידע נוסף זמין במאמר עבודה עם נתוני ניתוח גיאוגרפיים. אפשר להמיר סוגי נתונים ופונקציות של Oracle Spatial לפונקציות של מיקום גיאוגרפי ב-SQL רגיל ב-BigQuery. השימוש בפונקציות גיאוגרפיות לא מייקר את העלות מעבר לתמחור הרגיל של BigQuery.
תרשים
JanusGraph הוא פתרון מסד נתונים של גרפים בקוד פתוח, שיכול להשתמש ב-Bigtable כקצה עורפי לאחסון. מידע נוסף זמין במאמר הפעלת JanusGraph ב-GKE עם Bigtable.
Neo4j הוא פתרון נוסף של מסד נתונים גרפי שמוצע כשירות Google Cloud שפועל ב-Google Kubernetes Engine (GKE).
Oracle Application Express
אפליקציות Oracle Application Express (APEX) הן ייחודיות ל-Oracle וצריך לשכתב אותן. אפשר לפתח פונקציות של דיווח והצגת נתונים באמצעות Data Studio או BI Engine, ואילו פונקציות ברמת האפליקציה, כמו יצירה ועריכה של שורות, אפשר לפתח בלי לכתוב קוד ב-AppSheet באמצעות Cloud SQL.
המאמרים הבאים
- איך מבצעים אופטימיזציה של עומסי עבודה כדי לשפר את הביצועים הכוללים ולהפחית את העלויות.
- איך מייעלים את האחסון ב-BigQuery
- לעדכונים ב-BigQuery, אפשר לעיין בהערות המוצר.
- אפשר לעיין במדריך לתרגום Oracle SQL.