
העברת קוד באמצעות כלי התרגום של SQL באצווה
במאמר הזה מוסבר איך להשתמש בכלי לתרגום SQL באצווה ב-BigQuery כדי לתרגם סקריפטים שנכתבו בניבים אחרים של SQL לשאילתות GoogleSQL. המסמך הזה מיועד למשתמשים שמכירים את מסוףGoogle Cloud .
לפני שמתחילים
לפני ששולחים עבודת תרגום, צריך לבצע את השלבים הבאים:
- מוודאים שיש לכם את כל ההרשאות הנדרשות.
- מפעילים את BigQuery Migration API.
- אוספים את קובצי המקור שמכילים את הסקריפטים והשאילתות של SQL שרוצים לתרגם.
- זה שינוי אופציונלי. יוצרים קובץ מטא-נתונים כדי לשפר את דיוק התרגום.
- זה שינוי אופציונלי. מחליטים אם צריך למפות שמות של אובייקטים ב-SQL בקובצי המקור לשמות חדשים ב-BigQuery. במידת הצורך, קובעים אילו כללי מיפוי שמות להחיל.
- קובעים באיזו שיטה להשתמש כדי לשלוח את עבודת התרגום.
- מעלים את קובצי המקור ל-Cloud Storage.
ההרשאות הנדרשות
כדי להפעיל את שירות ההעברה של BigQuery, צריכות להיות לכם ההרשאות הבאות בפרויקט:
resourcemanager.projects.getserviceusage.services.enableserviceusage.services.get
כדי לגשת אל BigQuery Migration Service ולהשתמש בו, אתם צריכים את ההרשאות הבאות בפרויקט:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.listלחלופין, אפשר להשתמש בתפקידים הבאים כדי לקבל את אותן הרשאות:
bigquerymigration.viewer- הרשאת קריאה בלבד.-
bigquerymigration.editor- גישת קריאה/כתיבה.
כדי לגשת לקטגוריות של Cloud Storage לקובצי קלט ופלט:
-
storage.objects.getבקטגוריית המקור של Cloud Storage. -
storage.objects.listבקטגוריית המקור של Cloud Storage. -
storage.objects.createבקטגוריית היעד של Cloud Storage.
התפקידים הבאים כוללים את כל ההרשאות הנדרשות ל-Cloud Storage שצוינו למעלה:
roles/storage.objectAdminroles/storage.admin
הפעלת BigQuery Migration API
אם הפרויקט שלכם ב-Google Cloud CLI נוצר לפני 15 בפברואר 2022, צריך להפעיל את BigQuery Migration API באופן הבא:
במסוף Google Cloud , עוברים לדף BigQuery Migration API.
לוחצים על Enable.
איסוף קובצי מקור
קובצי המקור צריכים להיות קובצי טקסט שמכילים SQL תקין לדיאלקט המקור. קובצי המקור יכולים לכלול גם הערות. חשוב לוודא שה-SQL תקין, באמצעות כל השיטות שזמינות לכם.
יצירת קובצי מטא-נתונים
כדי שהשירות יפיק תוצאות תרגום מדויקות יותר, מומלץ לספק קובצי מטא-נתונים. עם זאת, לא חובה לעשות זאת.
אתם יכולים להשתמש בכלי השורת הפקודה dwh-migration-dumper לחילוץ כדי ליצור את פרטי המטא-נתונים, או לספק קובצי מטא-נתונים משלכם. אחרי שמכינים את קובצי המטא-נתונים, אפשר לכלול אותם יחד עם קובצי המקור בתיקיית המקור של התרגום. הכלי לתרגום מזהה אותם באופן אוטומטי ומשתמש בהם כדי לתרגם את קובצי המקור, בלי שתצטרכו להגדיר הגדרות נוספות כדי להפעיל את התכונה הזו.
כדי ליצור מידע על מטא-נתונים באמצעות הכלי dwh-migration-dumper, ראו יצירת מטא-נתונים לתרגום.
כדי לספק מטא נתונים משלכם, צריך לאסוף את הצהרות שפת הגדרת הנתונים (DDL) של אובייקטי ה-SQL במערכת המקור בקובצי טקסט נפרדים.
החלטה איך לשלוח את עבודת התרגום
יש שלוש אפשרויות לשליחת משימת תרגום של קבוצת קבצים:
לקוח תרגום באצווה: מגדירים משימה על ידי שינוי ההגדרות בקובץ הגדרות, ושולחים את המשימה באמצעות שורת הפקודה. בגישה הזו לא צריך להעלות ידנית קובצי מקור ל-Cloud Storage. הלקוח עדיין משתמש ב-Cloud Storage כדי לאחסן קבצים במהלך העיבוד של משימת התרגום.
לקוח התרגום של קבצים בכמות גדולה מדור קודם הוא לקוח Python בקוד פתוח שמאפשר לכם לתרגם קובצי מקור שנמצאים במחשב המקומי, ולשמור את קובצי התרגום בספרייה מקומית. כדי להגדיר את הלקוח לשימוש בסיסי, משנים כמה הגדרות בקובץ ההגדרות שלו. אם רוצים, אפשר גם להגדיר את הלקוח כך שיטפל במשימות מורכבות יותר, כמו החלפת מאקרו ועיבוד מקדים ועיבוד שלאחר מכן של קלט ופלט של תרגום. מידע נוסף זמין בreadme של לקוח התרגום באצווה.
Google Cloud מסוף: הגדרה ושליחה של משימה באמצעות ממשק משתמש. בגישה הזו צריך להעלות קובצי מקור ל-Cloud Storage.
יצירת קובצי YAML של תצורה
אפשר גם ליצור ולהשתמש בקובצי YAML של הגדרות כדי להתאים אישית את התרגומים של קבוצות קבצים. אפשר להשתמש בקבצים האלה כדי לשנות את פלט התרגום בדרכים שונות. לדוגמה, אפשר ליצור קובץ YAML של הגדרות כדי לשנות את האותיות של אובייקט SQL במהלך התרגום.
אם רוצים להשתמש במסוף Google Cloud או ב-BigQuery Migration API כדי להריץ תרגום באצווה, אפשר להעלות את קובץ ה-YAML של ההגדרות לקטגוריה של Cloud Storage שמכילה את קובצי המקור.
אם רוצים להשתמש בלקוח של תרגום באצווה, אפשר למקם את קובץ ה-YAML של ההגדרה בתיקיית הקלט המקומית של התרגום.
העלאת קובצי קלט ל-Cloud Storage
אם רוצים להשתמש במסוף Google Cloud או ב-BigQuery Migration API כדי לבצע עבודת תרגום, צריך להעלות ל-Cloud Storage את קובצי המקור שמכילים את השאילתות והסקריפטים שרוצים לתרגם. אפשר גם להעלות קבצים של מטא-נתונים או קבצי YAML של הגדרות לאותה קטגוריה של Cloud Storage ולאותה תיקייה שמכילות את קובצי המקור. מידע נוסף על יצירת קטגוריות והעלאת קבצים ל-Cloud Storage זמין במאמרים בנושא יצירת קטגוריות והעלאת אובייקטים ממערכת קבצים.
דיאלקטים נתמכים של SQL
כלי התרגום של SQL בקבוצות הוא חלק משירות ההעברה ל-BigQuery. הכלי לתרגום SQL באצווה יכול לתרגם את הדיאלקטים הבאים של SQL ל-GoogleSQL:
- Amazon Redshift SQL
- Apache HiveQL ו-Beeline CLI
- IBM Netezza SQL ו-NZPLSQL
- Teradata ו-Teradata Vantage:
- SQL
- שאילתת Teradata בסיסית (BTEQ)
- Teradata Parallel Transport (TPT)
בנוסף, יש תמיכה בתרגום של הדיאלקטים הבאים של SQL בגרסת טרום-השקה:
- Apache Impala SQL
- Apache Spark SQL
- Azure Synapse T-SQL
- GoogleSQL (BigQuery)
- Greenplum SQL
- IBM DB2 SQL
- MySQL SQL
- Oracle SQL, PL/SQL, Exadata
- PostgreSQL SQL
- Trino או PrestoSQL
- Snowflake SQL
- SQL Server T-SQL
- SQLite
- Vertica SQL
טיפול בפונקציות SQL שלא נתמכות באמצעות פונקציות UDF מסייעות
כשמתרגמים SQL מניבוב מקור ל-BigQuery, יכול להיות שלחלק מהפונקציות אין מקבילה ישירה. כדי לפתור את הבעיה הזו, שירות ההעברה ל-BigQuery (וגם קהילת BigQuery הרחבה) מספק פונקציות עזר מוגדרות על ידי המשתמש (UDF) שמשכפלות את ההתנהגות של הפונקציות האלה בניבוב המקור שלא נתמך.
פונקציות UDF כאלה נמצאות לרוב במערך הנתונים הציבורי bqutil, כך ששאילתות מתורגמות יכולות להפנות אליהן בהתחלה באמצעות הפורמט bqutil.<dataset>.<function>(). לדוגמה, bqutil.fn.cw_count().
שיקולים חשובים לגבי סביבות ייצור:
bqutil אמנם מספק גישה נוחה לפונקציות העזר האלה של UDF לצורך תרגום ובדיקה ראשוניים, אבל לא מומלץ להסתמך ישירות על bqutil לעומסי עבודה של ייצור, מכמה סיבות:
- ניהול גרסאות: פרויקט
bqutilמארח את הגרסה העדכנית של הפונקציות האלה, כלומר ההגדרות שלהן יכולות להשתנות עם הזמן. הסתמכות ישירה עלbqutilעלולה להוביל להתנהגות לא צפויה או לשינויים שוברים בשאילתות הייצור שלכם אם הלוגיקה של UDF תעודכן. - בידוד תלות: פריסת פונקציות UDF בפרויקט שלכם מבודדת את סביבת הייצור משינויים חיצוניים.
- התאמה אישית: יכול להיות שתצטרכו לשנות או לבצע אופטימיזציה של הפונקציות המוגדרות על ידי המשתמש כדי שיתאימו יותר ללוגיקה העסקית הספציפית או לדרישות הביצועים שלכם. אפשר לעשות את זה רק אם הם נמצאים בפרויקט שלכם.
- אבטחה וניהול: יכול להיות שמדיניות האבטחה של הארגון שלכם מגבילה גישה ישירה למערכי נתונים ציבוריים כמו
bqutilלעיבוד נתוני ייצור. העתקת פונקציות מוגדרות על ידי המשתמש לסביבה המבוקרת תואמת למדיניות כזו.
פריסת פונקציות UDF מסוג helper בפרויקט:
כדי להשתמש בפונקציות העזר האלה בייצור בצורה מהימנה ויציבה, צריך לפרוס אותן בפרויקט ובמערך הנתונים שלכם. כך יש לכם שליטה מלאה בגרסה, בהתאמה האישית ובגישה שלהם. הוראות מפורטות להטמעה של פונקציות UDF זמינות במדריך להטמעה של פונקציות UDF ב-GitHub. במדריך הזה מפורטים הסקריפטים והשלבים שנדרשים כדי להעתיק את הפונקציות המוגדרות על ידי המשתמש לסביבה שלכם.
מיקומים
הכלי לתרגום SQL של קבוצות זמין במיקומי העיבוד הבאים:
| תיאור האזור | שם האזור | פרטים | |
|---|---|---|---|
| אסיה ואזור האוקיינוס השקט | |||
| בנגקוק | asia-southeast3 |
||
| דלהי | asia-south2 |
||
| הונג קונג | asia-east2 |
||
| ג'קארטה | asia-southeast2 |
||
| מלבורן | australia-southeast2 |
||
| מומבאי | asia-south1 |
||
| אוסקה | asia-northeast2 |
||
| סיאול | asia-northeast3 |
||
| סינגפור | asia-southeast1 |
||
| סידני | australia-southeast1 |
||
| טייוואן | asia-east1 |
||
| טוקיו | asia-northeast1 |
||
| אירופה | |||
| בלגיה | europe-west1 |
|
|
| ברלין | europe-west10 |
||
| אירופה, במספר אזורים | eu |
||
| פינלנד | europe-north1 |
|
|
| פרנקפורט | europe-west3 |
||
| לונדון | europe-west2 |
|
|
| מדריד | europe-southwest1 |
|
|
| מילאנו | europe-west8 |
||
| הולנד | europe-west4 |
|
|
| פריז | europe-west9 |
|
|
| שטוקהולם | europe-north2 |
|
|
| טורינו | europe-west12 |
||
| ורשה | europe-central2 |
||
| ציריך | europe-west6 |
|
|
| אמריקה | |||
| קולומבוס, אוהיו | us-east5 |
||
| דאלאס | us-south1 |
|
|
| אייווה | us-central1 |
|
|
| לאס וגאס | us-west4 |
||
| לוס אנג'לס | us-west2 |
||
| מקסיקו | northamerica-south1 |
||
| צפון וירג'יניה | us-east4 |
||
| אורגון | us-west1 |
|
|
| קוויבק | northamerica-northeast1 |
|
|
| סאו פאולו | southamerica-east1 |
|
|
| סולט לייק סיטי | us-west3 |
||
| סנטיאגו | southamerica-west1 |
|
|
| דרום קרוליינה | us-east1 |
||
| טורונטו | northamerica-northeast2 |
|
|
| ארה"ב, במספר אזורים | us |
||
| אפריקה | |||
| יוהנסבורג | africa-south1 |
||
| MiddleEast | |||
| דמאם | me-central2 |
||
| דוחה | me-central1 |
||
| ישראל | me-west1 |
||
שליחת עבודת תרגום
כדי להתחיל עבודת תרגום, לראות את ההתקדמות ולצפות בתוצאות, פועלים לפי השלבים הבאים.
המסוף
אנחנו יוצאים מנקודת הנחה שכבר העליתם קובצי מקור לקטגוריה של Cloud Storage.
נכנסים לדף SQL Translation במסוף Google Cloud .
בחלונית SQL translation (תרגום SQL), לוחצים על Start translation (התחלת התרגום).
בקטע הגדרת תרגום, מזינים את הפרטים הבאים:
- בשדה שם מוצג, מקלידים שם למשימת התרגום. השם יכול להכיל אותיות, מספרים או קווים תחתונים.
- בשדה מיקום העיבוד, בוחרים את המיקום שבו רוצים שהעבודה של התרגום תתבצע. לדוגמה, אם אתם נמצאים באירופה ולא רוצים שהנתונים שלכם יעברו את הגבולות של מיקום כלשהו, בוחרים באזור
eu. התרגום מתבצע בצורה הכי טובה כשבוחרים את אותו מיקום כמו של קטגוריית קובץ המקור. - בשדה Source dialect (ניב המקור), בוחרים את ניב ה-SQL שרוצים לתרגם.
- בקטע ניב היעד, בוחרים באפשרות GoogleSQL.
לוחצים על הבא.
בקטע פרטים על מיקום הקובץ, מציינים את הנתיבים ב-Cloud Storage שבהם רוצים להשתמש לקלט ולפלט של התרגום. אפשר להקליד את הנתיבים בפורמט
bucket_name/folder_name/או להשתמש באפשרות עיון כדי לעבור לתיקייה.- בקטע מיקום ספריית הפלט, מציינים נתיב לתיקיית היעד ב-Cloud Storage של הקבצים המתורגמים. התיקייה הזו משמשת כספריית שורש לכל פלט התרגום.
- בוחרים מיקום אחד או יותר של תיקיות קלט שמכילות את הנתיב לקובצי ה-SQL שרוצים לתרגם.
- אם צריך, אפשר לתת לכל ספריית קלט שם של ספריית פלט משנית מתחת לספריית הפלט הראשית.
לוחצים על הבא.
בוחרים את ההגדרות האופציונליות שרוצים להתאים אישית את המטא-נתונים ואת פלט התרגום הנוסף.
אפשר להתאים אישית את התנהגות התרגום על ידי יצירת קובצי YAML של הגדרות והצבת הקבצים האלה בקטגוריית הקלט של Cloud Storage. אפשר להשתמש בקבצים האלה כדי להגדיר שינוי שם של אובייקטים, להפעיל אופטימיזציות, לשפר תרגומים באמצעות Gemini ועוד. מידע נוסף על קובצי YAML של הגדרות זמין במאמר יצירת קובץ YAML של הגדרות.
לוחצים על יצירה כדי להתחיל את עבודת התרגום.
אחרי שיוצרים את עבודת התרגום, אפשר לראות את הסטטוס שלה ברשימת עבודות התרגום.
לקוח תרגום באצווה
בתיקיית ההתקנה של לקוח התרגום באצווה, משתמשים בעורך הטקסט שבחרתם כדי לפתוח את הקובץ
config.yamlולשנות את ההגדרות הבאות:-
project_number: מקלידים את מספר הפרויקט שרוצים להשתמש בו לעבודת התרגום באצווה. אפשר למצוא את המספר הזה בחלונית Project info בGoogle Cloud דף הפתיחה של המסוף של הפרויקט. -
gcs_bucket: מקלידים את השם של קטגוריית Cloud Storage שבה לקוח התרגום באצווה משתמש כדי לאחסן קבצים במהלך העיבוד של עבודת התרגום. -
input_directory: מקלידים את הנתיב המוחלט או היחסי לספרייה שמכילה את קובצי המקור וקובצי המטא-נתונים. -
output_directory: מקלידים את הנתיב המוחלט או היחסי לספריית היעד של הקבצים המתורגמים.
-
שומרים את השינויים וסוגרים את הקובץ
config.yaml.ממקמים את קובצי המקור והמטא-נתונים בספריית הקלט.
מריצים את לקוח התרגום באצווה באמצעות הפקודה הבאה:
bin/dwh-migration-clientיוצרים משימת תרגום.
בדוגמה הבאה מוצגת פקודה ליצירת משימת תרגום. הפקודה תפעיל את תהליך העבודה ותציג פלט אם תהליך העבודה יצליח.
gcloud bq migration-workflows create --location=us --config-file=CONFIG_FILE_NAME.json
בדוגמה הבאה מוצגת פקודה ליצירה ולהרצה של תהליך העבודה עם הדגל
--async. הפקודה תיצור את תהליך העבודה ותפעיל אותו, ותחזיר מיד קישור לתהליך העבודה.gcloud bq migration-workflows create --location=LOCATION --config-file=CONFIG_FILE_NAME.json --async
בדוגמה הבאה מוצגת פקודה להצגת רשימה של משימות התרגום:
gcloud bq migration-workflows list --location=LOCATION
מחליפים את מה שכתוב בשדות הבאים:
-
LOCATION: המיקום של Google Cloud הפרויקט שבו מופעלת משימת התרגום הזו. -
CONFIG_FILE_NAME: השם של קובץconfig.yaml. אחרי שיוצרים את משימת התרגום, אפשר לראות את הסטטוס שלה ברשימת משימות התרגום במסוף Google Cloud .
זה שינוי אופציונלי. אחרי שמשימת התרגום מסתיימת, מוחקים את הקבצים שהמשימה יצרה בקטגוריה של Cloud Storage שציינתם, כדי להימנע מעלויות אחסון.
BigQuery CLI
כדי להריץ את הכלי לתרגום SQL של קבוצות באמצעות כלי שורת הפקודה של BigQuery, מבצעים את השלבים הבאים:
יוצרים קובץ הגדרות תרגום בפורמט YAML או JSON. בקובץ הזה, צריך להגדיר את הנתיב לקובץ המקור, את יעד הפלט ואת הניבים של שפת המקור ושפת היעד של התרגום.
הדוגמה הבאה מציגה קובץ YAML של הגדרות תרגום מ-Teradata ל-BigQuery:
tasks: translation_task: type: Teradata2BigQuery_Translation translationDetails: sourceTargetMapping: - sourceSpec: baseUri: gs://bq-translations/input targetSpec: relativePath: output targetBaseUri: gs://bq-translations targetTypes: - sql sourceEnvironment: defaultDatabase: default_db schemaSearchPath: - foo
בדוגמה הבאה מוצג קובץ JSON של הגדרות תרגום מ-Teradata ל-BigQuery:
{ "tasks": { "translation_task": { "type": "Teradata2BigQuery_Translation", "translationDetails": { "sourceTargetMapping": [ { "sourceSpec": { "literal": { "literalString": "sel 1", "relativePath": "my_input_1" }, "encoding": "UTF-8" } }, { "sourceSpec": { "literal": { "literalString": "sel 2", "relativePath": "my_input_2" }, "encoding": "UTF-8" } } ], "targetReturnLiterals": [ "sql/my_input_1", "sql/my_input_2" ] } } } }
אחרי שיוצרים את הגדרות התרגום, מריצים את הפקודה הבאה כדי להפעיל את משימת התרגום.
bq mk --migration_workflow --location=LOCATION --config_file=CONFIG_FILE_NAME.json
מחליפים את מה שכתוב בשדות הבאים:
-
LOCATION: המיקום של Google Cloud הפרויקט שבו מופעלת משימת התרגום הזו. -
CONFIG_FILE_NAME: השם של קובץconfig.yaml.
-
כדי לראות פרטים על משימת תרגום ספציפית, מריצים את הפקודה הבאה:
bq show --migration_workflow projects/PROJECT_ID/ locations/us/workflows/WORKFLOW_ID
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: המזהה של Google Cloud הפרויקט שבו מופעלת משימת התרגום הזו. -
WORKFLOW_ID: המזהה של עבודת התרגום.
-
כדי לראות את התוצאות של עבודת תרגום ספציפית, מריצים את הפקודה הבאה:
gcloud bq migration-workflows describe projects/PROJECT_ID /locations/us/workflows/WORKFLOW_ID
כדי להסיר משימת תרגום מהרשימה, מריצים את הפקודה הבאה:
bq rm --migration_workflow projects/PROJECT_ID/locations/us/workflows/WORKFLOW_ID
כדי להציג רשימה של כל עבודות התרגום, מריצים את הפקודה הבאה:
bq ls --migration_workflow --location=LOCATION
בדיקת פלט התרגום
אחרי שמריצים את עבודת התרגום, אפשר לראות מידע על העבודה במסוף Google Cloud . אם השתמשתם במסוף Google Cloud כדי להריץ את העבודה, תוכלו לראות את תוצאות העבודה בקטגוריית Cloud Storage שציינתם כיעד. אם השתמשתם בלקוח של תרגום באצווה כדי להריץ את העבודה, תוכלו לראות את תוצאות העבודה בספריית הפלט שציינתם. מתרגם ה-SQL של אצווה מוציא את הקבצים הבאים ליעד שצוין:
- הקבצים המתורגמים.
- דוח סיכום התרגום בפורמט CSV.
- מיפוי שמות הפלט שנצרך בפורמט JSON.
- הקבצים עם ההצעות מ-AI.
פלט של מסוףGoogle Cloud
כדי לראות את פרטי עבודת התרגום, פועלים לפי השלבים הבאים:
נכנסים לדף SQL Translation במסוף Google Cloud .
ברשימת עבודות התרגום, מאתרים את העבודה שרוצים לראות את פרטי התרגום שלה. לאחר מכן לוחצים על שם עבודת התרגום. תוכלו לראות תרשים סנקיי שממחיש את האיכות הכוללת של העבודה, את מספר שורות הקוד של הקלט (לא כולל שורות ריקות ותגובות) ואת רשימת הבעיות שהתרחשו במהלך תהליך התרגום. חשוב לתת עדיפות לתיקונים משמאל לימין. בעיות בשלב מוקדם עלולות לגרום לבעיות נוספות בשלבים הבאים.
מעבירים את מצביע העכבר מעל פסי השגיאה או האזהרה, וקוראים את ההצעות כדי להחליט מה השלבים הבאים לניפוי הבאגים של עבודת התרגום.
בכרטיסייה סיכום יומן מוצג סיכום של בעיות התרגום, כולל קטגוריות של בעיות, פעולות מומלצות ותדירות ההתרחשות של כל בעיה. אפשר ללחוץ על העמודות בתרשים סנקיי כדי לסנן את הבעיות. אפשר גם לבחור קטגוריה של בעיות כדי לראות את הודעות היומן שמשויכות לקטגוריה הזו.
כדי לראות פרטים נוספים על כל בעיה בתרגום, כולל קטגוריית הבעיה, הודעת הבעיה הספציפית וקישור לקובץ שבו הבעיה התרחשה, בוחרים בכרטיסייה הודעות יומן. אפשר ללחוץ על העמודות בתרשים סנקיי כדי לסנן בעיות. אפשר לבחור בעיה בכרטיסייה הודעת יומן כדי לפתוח את הכרטיסייה 'קוד' שבה מוצגים קובץ הקלט וקובץ הפלט, אם רלוונטי.
לוחצים על הכרטיסייה Job details כדי לראות את פרטי ההגדרה של עבודת התרגום.
דוח סיכום
דוח הסיכום הוא קובץ CSV שכולל טבלה של כל הודעות האזהרה והשגיאה שנתקלו בהן במהלך עבודת התרגום.
כדי לראות את קובץ הסיכום ב Google Cloud מסוף, פועלים לפי השלבים הבאים:
נכנסים לדף SQL Translation במסוף Google Cloud .
ברשימת עבודות התרגום, מאתרים את העבודה שמעניינת אתכם, לוחצים על שם העבודה או על אפשרויות נוספות > הצגת פרטים.
בכרטיסייה פרטי המשימה, בקטע דוח תרגום, לוחצים על translation_report.csv.
בדף פרטי האובייקט, לוחצים על הערך בשורה כתובת URL מאומתת כדי לראות את הקובץ בדפדפן.
בטבלה הבאה מתוארות העמודות בקובץ הסיכום:
| עמודה | תיאור |
|---|---|
| חותמת הזמן | חותמת הזמן שבה התרחשה הבעיה. |
| FilePath | הנתיב לקובץ המקור שהבעיה משויכת אליו. |
| FileName | השם של קובץ המקור שאליו משויכת הבעיה. |
| ScriptLine | מספר השורה שבה התרחשה הבעיה. |
| ScriptColumn | מספר העמודה שבה התרחשה הבעיה. |
| TranspilerComponent | הרכיב הפנימי של מנוע התרגום שבו התרחשה האזהרה או השגיאה. יכול להיות שהעמודה הזו תהיה ריקה. |
| סביבה | סביבת הדיאלקט של התרגום שמשויכת לאזהרה או לשגיאה. יכול להיות שהעמודה הזו תהיה ריקה. |
| ObjectName | אובייקט ה-SQL בקובץ המקור שמשויך לאזהרה או לשגיאה. יכול להיות שהעמודה הזו תהיה ריקה. |
| חוּמרה | חומרת הבעיה, אזהרה או שגיאה. |
| קטגוריה | קטגוריית הבעיה בתרגום. |
| SourceType | המקור של הבעיה הזו. הערך בעמודה הזו יכול להיות SQL, שמציין שיש בעיה בקובצי ה-SQL של הקלט, או METADATA, שמציין שיש בעיה בחבילת המטא-נתונים. |
| הודעה | האזהרה או הודעת השגיאה שקשורות לבעיה בתרגום. |
| ScriptContext | קטע ה-SQL בקובץ המקור שמשויך לבעיה. |
| פעולה | הפעולה המומלצת לפתרון הבעיה. |
הכרטיסייה 'קוד'
בכרטיסייה 'קוד' אפשר לעיין במידע נוסף על קובצי הקלט והפלט של עבודת תרגום מסוימת. בכרטיסייה 'קוד' אפשר לבדוק את הקבצים שנעשה בהם שימוש במשימת תרגום, לעיין בהשוואה בטבלה בין קובץ קלט לתרגום שלו כדי לזהות אי דיוקים, ולראות סיכומי יומנים והודעות לגבי קובץ ספציפי במשימה.
כדי לגשת לכרטיסייה 'קוד':
נכנסים לדף SQL Translation במסוף Google Cloud .
ברשימת עבודות התרגום, מאתרים את העבודה שמעניינת אתכם, לוחצים על שם העבודה או על אפשרויות נוספות > הצגת פרטים.
לוחצים על כרטיסיית קוד. כרטיסיית הקוד כוללת את החלוניות הבאות:
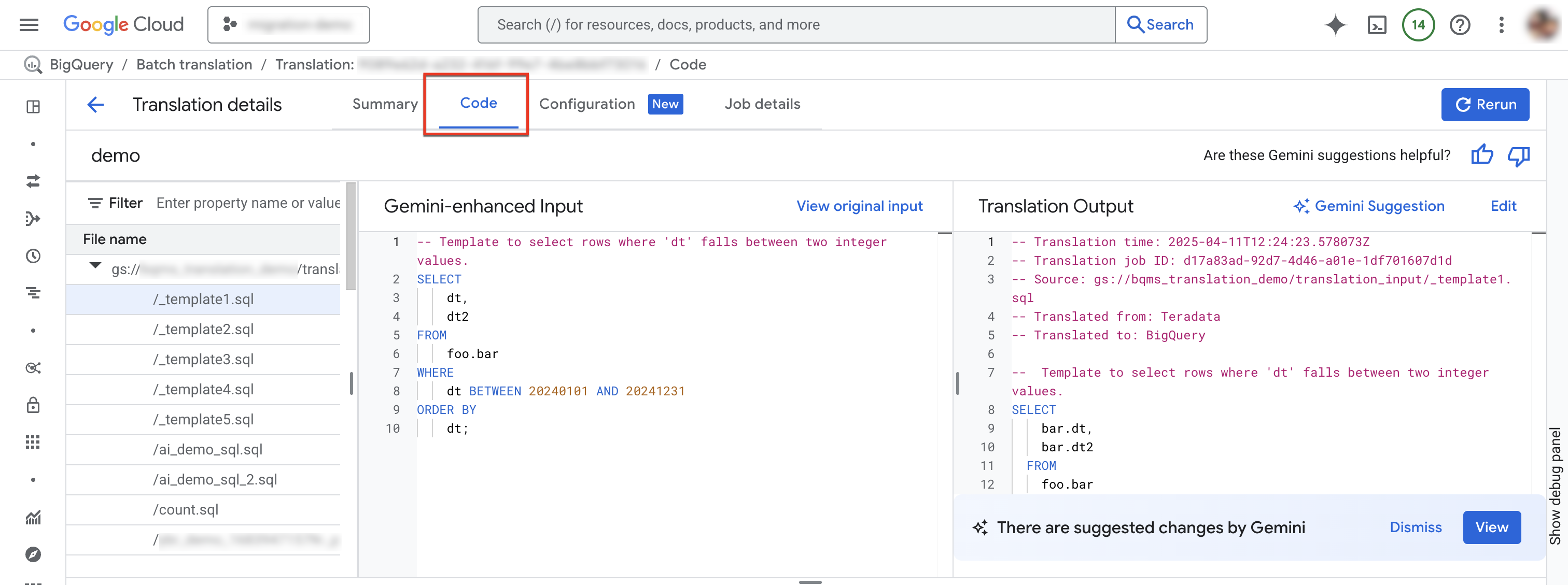
- סייר הקבצים: מכיל את כל קובצי ה-SQL שמשמשים לתרגום. לוחצים על קובץ כדי לראות את קלט התרגום והפלט שלו, ובעיות תרגום כלשהן מהתרגום שלו.
- קלט משופר על ידי Gemini: קלט ה-SQL שתורגם על ידי מנוע התרגום. אם הגדרתם כללי התאמה אישית של Gemini ל-SQL של המקור בהגדרות של Gemini, הכלי לתרגום ישנה קודם את הקלט המקורי ואז יתרגם את הקלט המשופר על ידי Gemini. כדי לראות את הקלט המקורי, לוחצים על הצגת הקלט המקורי.
- פלט התרגום: תוצאת התרגום. אם הגדרתם כללי התאמה אישית של Gemini עבור ה-SQL של היעד בהגדרות של Gemini, הטרנספורמציה תוחל על התוצאה המתורגמת כפלט משופר של Gemini. אם יש פלט משופר על ידי Gemini, אפשר ללחוץ על הלחצן הצעה מ-Gemini כדי לבדוק את הפלט המשופר.
אופציונלי: כדי לראות קובץ קלט וקובץ פלט בכלי האינטראקטיבי לתרגום SQL ב-BigQuery, לוחצים על עריכה. אפשר לערוך את הקבצים ולשמור את קובץ הפלט בחזרה ב-Cloud Storage.
הכרטיסייה 'הגדרות'
אתם יכולים להוסיף, לשנות את השם, להציג או לערוך את קובצי ה-YAML של ההגדרות בכרטיסייה Configuration.ב-Schema Explorer מוצגת תיעוד של סוגי ההגדרות הנתמכים, כדי לעזור לכם לכתוב את קובצי ה-YAML של ההגדרות. אחרי שאתם עורכים את קובצי ה-YAML של ההגדרות, אתם יכולים להריץ מחדש את המשימה כדי להשתמש בהגדרה החדשה.
כדי לגשת לכרטיסיית ההגדרות:
נכנסים לדף SQL Translation במסוף Google Cloud .
ברשימת עבודות התרגום, מאתרים את העבודה שמעניינת אתכם, לוחצים על שם העבודה או על אפשרויות נוספות > הצגת פרטים.
בחלון פרטי התרגום, לוחצים על הכרטיסייה הגדרה.
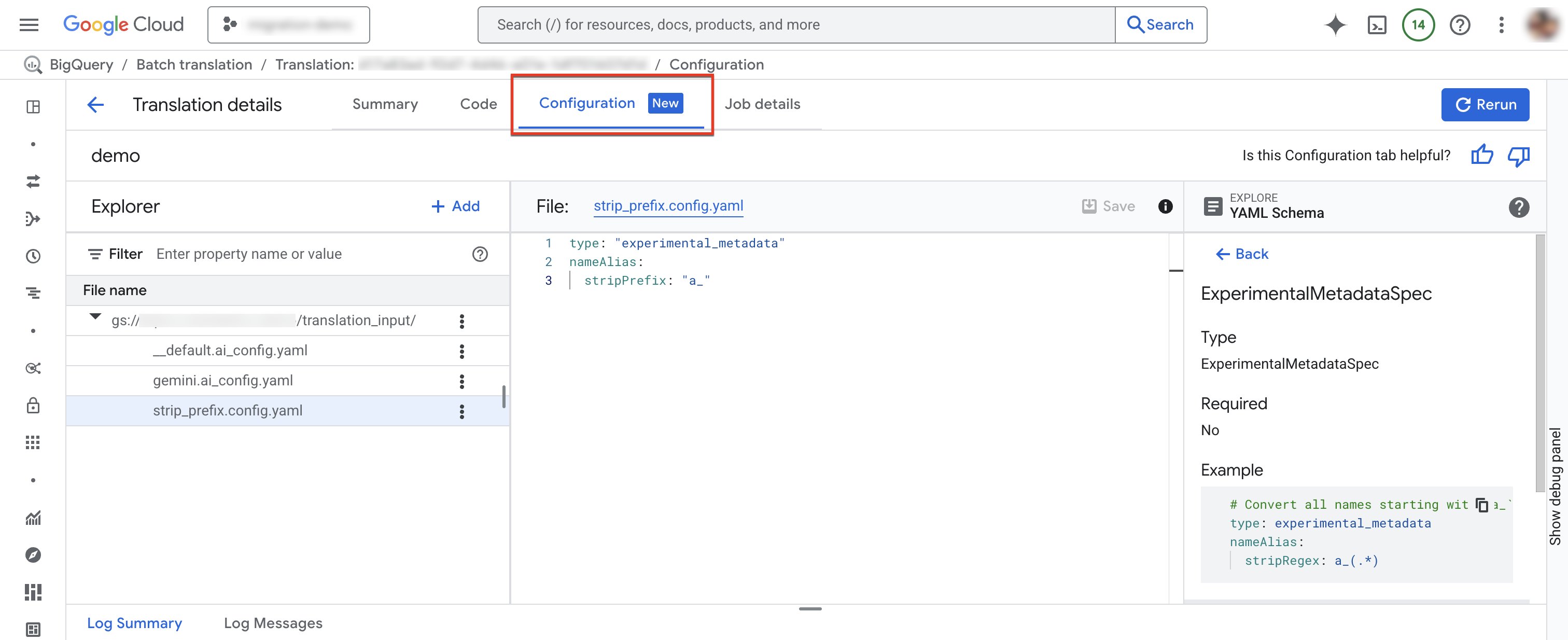
כדי להוסיף קובץ הגדרה חדש:
- לוחצים על more_vert אפשרויות נוספות > יצירת קובץ YAML להגדרת התצורה.
- מופיעה חלונית שבה אפשר לבחור את הסוג, המיקום והשם של קובץ ה-YAML החדש של התצורה.
- לוחצים על יצירה.
כדי לערוך קובץ תצורה קיים:
- לוחצים על קובץ ה-YAML של ההגדרות.
- עורכים את הקובץ ולוחצים על שמירה.
- לוחצים על הרצה מחדש כדי להריץ משימת תרגום חדשה שמשתמשת בקובצי ה-YAML של ההגדרות הערוכות.
כדי לשנות את השם של קובץ הגדרה קיים, לוחצים על more_vert אפשרויות נוספות > שינוי שם.
קובץ מיפוי של שמות פלט שנצרכו
קובץ ה-JSON הזה מכיל את כללי המיפוי של שמות הפלט ששימשו את משימת התרגום. יכול להיות שהכללים בקובץ הזה יהיו שונים מהכללים של מיפוי שמות הפלט שהגדרתם למשימת התרגום, בגלל התנגשויות בכללי מיפוי השמות או בגלל היעדר כללי מיפוי שמות לאובייקטים של SQL שזוהו במהלך התרגום. צריך לבדוק את הקובץ הזה כדי לדעת אם צריך לתקן את כללי מיפוי השמות. אם כן, צריך ליצור כללי מיפוי חדשים של שמות פלט שפותרים את הבעיות שזיהיתם, ולהריץ משימת תרגום חדשה.
קבצים מתורגמים
לכל קובץ מקור נוצר קובץ פלט תואם בנתיב היעד. קובץ הפלט מכיל את השאילתה המתורגמת.
ניפוי באגים בשאילתות SQL שתורגמו באצווה באמצעות כלי התרגום האינטראקטיבי של SQL
אתם יכולים להשתמש בכלי האינטראקטיבי לתרגום SQL ב-BigQuery כדי לבדוק או לנפות באגים בשאילתת SQL באמצעות אותם מטא-נתונים או מיפוי אובייקטים כמו במסד הנתונים של המקור. אחרי שמסיימים משימת תרגום באצווה, BigQuery יוצר מזהה של הגדרת תרגום שמכיל מידע על המטא-נתונים של המשימה, על מיפוי האובייקטים או על נתיב החיפוש של הסכימה, בהתאם לשאילתה. משתמשים במזהה ההגדרה של התרגום באצווה עם כלי התרגום האינטראקטיבי של SQL כדי להריץ שאילתות SQL עם ההגדרה שצוינה.
כדי להתחיל תרגום אינטראקטיבי של SQL באמצעות מזהה של הגדרת תרגום באצווה, פועלים לפי השלבים הבאים:
נכנסים לדף SQL Translation במסוף Google Cloud .
ברשימת עבודות התרגום, מאתרים את העבודה שרוצים, ואז לוחצים על אפשרויות נוספות > פתיחת תרגום אינטראקטיבי.
כלי התרגום האינטראקטיבי של SQL ב-BigQuery ייפתח עכשיו עם מזהה ההגדרה של תרגום באצווה. כדי לראות את מזהה ההגדרה של התרגום האינטראקטיבי, לוחצים על Tools (כלים) > Query translation (תרגום שאילתות) > Translation settings (הגדרות תרגום) בכלי התרגום האינטראקטיבי של SQL.
כדי לנפות באגים בקובץ תרגום באצווה בכלי האינטראקטיבי לתרגום SQL, פועלים לפי השלבים הבאים:
נכנסים לדף SQL Translation במסוף Google Cloud .
ברשימת עבודות התרגום, מאתרים את העבודה שמעניינת אתכם, ואז לוחצים על שם העבודה או על אפשרויות נוספות > הצגת פרטים.
בחלון פרטי התרגום, לוחצים על הכרטיסייה קוד.
בסייר הקבצים, לוחצים על שם הקובץ כדי לפתוח אותו.
לצד שם קובץ הפלט, לוחצים על עריכה כדי לפתוח את הקבצים בכלי האינטראקטיבי לתרגום SQL (תצוגה מקדימה).
קבצי הקלט והפלט יאוכלסו בכלי האינטראקטיבי לתרגום SQL, שמשתמש עכשיו במזהה ההגדרה המתאים של תרגום באצווה.
כדי לשמור את קובץ הפלט הערוך בחזרה ב-Cloud Storage, לוחצים על שמירה > שמירה ב-GCS בכלי האינטראקטיבי לתרגום SQL.
מגבלות
המתרגם לא יכול לתרגם פונקציות בהגדרת המשתמש (UDF) משפות שאינן SQL, כי הוא לא יכול לנתח אותן כדי לקבוע את סוגי נתוני הקלט והפלט שלהן. כתוצאה מכך, התרגום של הצהרות SQL שמפנות אל הפונקציות האלה יהיה לא מדויק. כדי לוודא שהפניות לפונקציות UDF שאינן SQL מתבצעות בצורה תקינה במהלך התרגום, צריך להשתמש ב-SQL תקין כדי ליצור פונקציות UDF של placeholder עם אותן חתימות.
לדוגמה, נניח שיש לכם UDF שנכתב ב-C ומחשב את הסכום של שני מספרים שלמים. כדי לוודא שהוראות SQL שמפנות אל פונקציית ה-UDF הזו מתורגמות בצורה נכונה, צריך ליצור פונקציית UDF של SQL כ-placeholder שכוללת את אותה חתימה כמו פונקציית ה-UDF של C, כמו בדוגמה הבאה:
CREATE FUNCTION Test.MySum (a INT, b INT)
RETURNS INT
LANGUAGE SQL
RETURN a + b;
שומרים את פונקציית ה-UDF של ה-placeholder בקובץ טקסט, וכוללים את הקובץ הזה כאחד מקובצי המקור של עבודת התרגום. כך המתרגם יכול ללמוד את ההגדרה של פונקציית ה-UDF ולזהות את סוגי נתוני הקלט והפלט הצפויים.
מכסות ומגבלות
- חלות מכסות של BigQuery Migration API.
- בכל פרויקט יכולות להיות עד 10 משימות תרגום פעילות.
- אין הגבלה על המספר הכולל של קובצי המקור והמטא-נתונים, אבל כדי לשפר את הביצועים מומלץ להגביל את מספר הקבצים ל-1,000.
פתרון בעיות שקשורות לתרגום
RelationNotFound או בעיות בתרגוםAttributeNotFound
אחרי תרגום של שאילתה באמצעות כלי התרגום של SQL באצווה, יכול להיות שתיתקלו בתרגום שנכשל עם השגיאה RelationNotFound או AttributeNotFound.
כדי למצוא תרגומים שנכשלו, עוברים לדף פרטי התרגום ופותחים את הכרטיסייה הודעות יומן.
התרגום פועל הכי טוב עם DDL של מטא-נתונים. אם לא ניתן למצוא הגדרות של אובייקטים ב-SQL, מנוע התרגום מעלה בעיות מסוג RelationNotFound או AttributeNotFound. מומלץ להשתמש בכלי לחילוץ מטא-נתונים כדי ליצור חבילות מטא-נתונים ולוודא שכל הגדרות האובייקטים קיימות. הוספת מטא-נתונים היא השלב הראשון המומלץ לפתרון רוב שגיאות התרגום, כי לעיתים קרובות היא יכולה לתקן שגיאות רבות אחרות שנגרמות באופן עקיף מחוסר במטא-נתונים.
מידע נוסף זמין במאמר יצירת מטא-נתונים לתרגום ולבדיקה.
פתרון בעיות בתרגום באמצעות Gemini
כדי לתקן עבודות תרגום שנכשלו עם השגיאות RelationNotFound או AttributeNotFound, אפשר גם להשתמש ב-Gemini כדי לנסות לפתור את הבעיות האלה באמצעות השלבים הבאים.
עוברים לדף פרטי התרגום ופותחים את הכרטיסייה הודעות יומן.
לוחצים על השאילתה שבה מופיעה ההודעה
RelationNotFoundאוAttributeNotFoundבעמודה Category (קטגוריה).לוחצים על הודעת השגיאה כדי לעבור לקובץ ולשורה שמכילים את השגיאה בכרטיסייה 'קוד'.
בעמודה פעולה, לוחצים על הצעה לתיקון.
בוחרים באחת מהאפשרויות הבאות: החלה או החלה והפעלה מחדש:
- לוחצים על החלה כדי להעתיק את קובץ הסכימה שנוצר מספריית הפלט לספריית הקלט.
- לוחצים על החלה והרצה מחדש כדי להעתיק את קובץ הסכימה שנוצר מספריית הפלט לספריית הקלט, ונפתח חלון של הרצה מחדש.
תמחור
אין תשלום על השימוש בכלי לתרגום SQL בכמות גדולה. עם זאת, האחסון שמשמש לאחסון קבצי קלט ופלט כרוך בעמלות רגילות. מידע נוסף מופיע במאמר בנושא תמחור אחסון.
המאמרים הבאים
מידע נוסף על השלבים הבאים בהעברת מחסן נתונים:
- סקירה כללית על מיגרציה
- הערכת תהליך ההעברה
- סקירה כללית של סכימה והעברת נתונים
- צינורות עיבוד נתונים
- תרגום אינטראקטיבי של SQL
- אבטחה ומשילות מידע
- כלי לאימות נתונים