

Gemini Enterprise Agent Platform מספקת שירות הדרכה מנוהל שעוזר לכם להפעיל הדרכה של מודלים בהיקף גדול. אתם יכולים להשתמש ב-Gemini Enterprise Agent Platform כדי להריץ אפליקציות הדרכה שמבוססות על כל מסגרת ללמידת מכונה (ML) בתשתיתGoogle Cloud . בנוסף, ל-Gemini Enterprise Agent Platform יש תמיכה משולבת במסגרות הפופולריות הבאות ללמידת מכונה, שמפשטת את תהליך ההכנה להדרכה ולהצגה של מודלים:
בדף הזה מוסבר מהם היתרונות של אימון בלי שרת (serverless) ב-Gemini Enterprise Agent Platform, מהו תהליך העבודה ומהן אפשרויות האימון השונות שזמינות.
Gemini Enterprise Agent Platform מאפשרת להפעיל הדרכה בקנה מידה גדול
יש כמה אתגרים בהפעלת אימון מודלים. האתגרים האלה כוללים את הזמן והעלות שנדרשים לאימון מודלים, את רמת המיומנויות שנדרשת לניהול תשתית המחשוב ואת הצורך לספק אבטחה ברמה של ארגון. Gemini Enterprise Agent Platform נותנת מענה לאתגרים האלה ומציעה מגוון יתרונות נוספים.
תשתית מחשוב מנוהלת
|
|
אימון מודלים ב-Gemini Enterprise Agent Platform הוא שירות מנוהל במלואו שלא דורש ניהול של תשתית פיזית. אפשר לאמן מודלים של למידת מכונה בלי להקצות או לנהל שרתים. התשלום הוא רק על משאבי המחשוב שבהם אתם משתמשים. Gemini Enterprise Agent Platform גם מטפל ברישום ביומן, בהוספה לתור ובמעקב של משימות. |
ביצועים גבוהים
|
|
משימות האימון של Gemini Enterprise Agent Platform מותאמות לאימון מודלים של ML, ולכן הן יכולות לספק ביצועים מהירים יותר מאשר הפעלה ישירה של אפליקציית האימון באשכול Google Kubernetes Engine (GKE). אפשר גם לזהות צווארי בקבוק בביצועים של משימת האימון ולנפות באגים באמצעות Cloud Profiler. |
אימון מבוזר
|
|
Reduction Server הוא אלגוריתם all-reduce בפלטפורמת הסוכנים של Gemini Enterprise, שיכול להגדיל את התפוקה ולהפחית את זמן האחזור של אימון מבוזר מרובה צמתים במעבדים גרפיים (GPU) של NVIDIA. האופטימיזציה הזו עוזרת לקצר את הזמן ולצמצם את העלות של השלמת משימות אימון גדולות. |
אופטימיזציה של היפר-פרמטרים
|
|
משימות כוונון של היפר-פרמטרים מריצות כמה ניסיונות של אפליקציית האימון באמצעות ערכים שונים של היפר-פרמטרים. מגדירים טווח של ערכים לבדיקה, ו-Gemini Enterprise Agent Platform מוצא את הערכים האופטימליים למודל בטווח הזה. |
אבטחה לארגונים
|
|
Gemini Enterprise Agent Platform מספקת את תכונות האבטחה הארגוניות הבאות:
|
שילובים של פעולות למידת מכונה (MLOps)
|
|
Gemini Enterprise Agent Platform מספקת חבילה של תכונות וכלים משולבים של MLOps שבהם אפשר להשתמש למטרות הבאות:
|
תהליך עבודה לאימון ללא שרת (serverless)
הדיאגרמה הבאה מציגה סקירה כללית של תהליך העבודה של אימון ללא שרתים ב-Gemini Enterprise Agent Platform. בחלקים הבאים מפורט כל שלב.
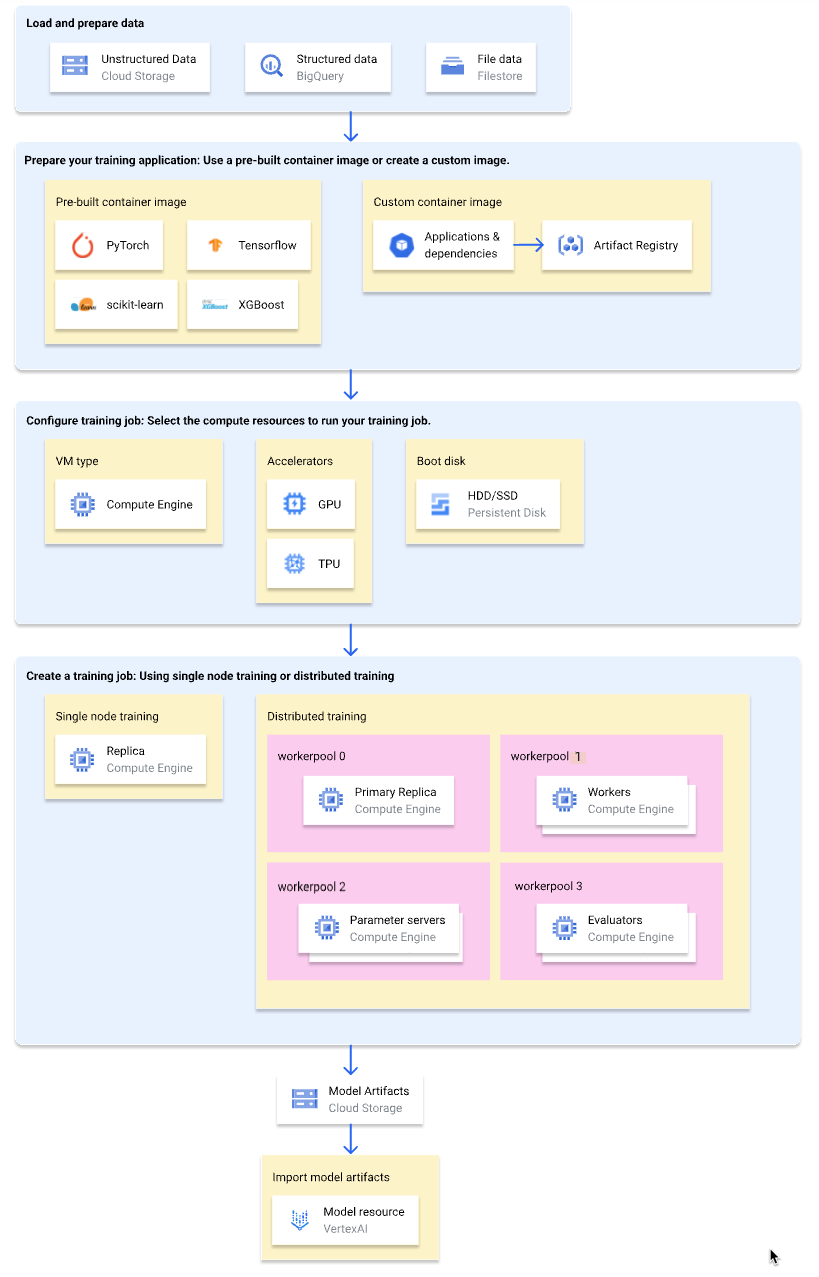
טעינה והכנה של נתוני אימון
כדי להשיג את הביצועים הטובים ביותר ולקבל תמיכה, מומלץ להשתמש באחד מהשירותים הבאים Google Cloud כמקור הנתונים:
- Cloud Storage
- BigQuery
- מערכות קבצים עם רמת ביצועים גבוהה, כמו שיתופי NFS ב-Google Cloud באמצעות שירותים כמו Google Cloud NetApp Volumes או Filestore.
כאן אפשר לראות השוואה בין השירותים האלה.
כשמשתמשים בצינור אימון כדי לאמן את המודל, אפשר גם לציין מערך נתונים מנוהל של פלטפורמת הסוכנים של Gemini Enterprise כמקור הנתונים. אימון של מודל בהתאמה אישית ומודל AutoML באמצעות אותו מערך נתונים מאפשר להשוות את הביצועים של שני המודלים.
הכנת בקשת ההדרכה
כדי להכין את אפליקציית האימון לשימוש ב-Gemini Enterprise Agent Platform, צריך לבצע את הפעולות הבאות:
- הטמעה של שיטות מומלצות לקוד אימון ב-Gemini Enterprise Agent Platform.
- קובעים באיזה סוג של קובץ אימג' של קונטיינר רוצים להשתמש.
- אורזים את אפליקציית האימון בפורמט נתמך בהתאם לסוג קובץ האימג' של הקונטיינר שנבחר.
שימוש בשיטות מומלצות בקוד ההדרכה
אפליקציית האימון צריכה להטמיע את השיטות המומלצות לקוד אימון ב-Gemini Enterprise Agent Platform. השיטות המומלצות האלה מתייחסות ליכולת של אפליקציית האימון לבצע את הפעולות הבאות:
- גישה אל Google Cloud שירותים
- טוענים את נתוני הקלט.
- הפעלת רישום אוטומטי ביומן למעקב אחר ניסויים.
- ייצוא ארטיפקטים של מודלים.
- משתמשים במשתני הסביבה של Gemini Enterprise Agent Platform.
- מוודאים שיש עמידות להפעלות מחדש של מכונות וירטואליות.
בחירת סוג מאגר
Gemini Enterprise Agent Platform מריצה את אפליקציית האימון בקובץ אימג' של קונטיינר של Docker. קובץ אימג' של קונטיינר Docker הוא חבילת תוכנה עצמאית שכוללת קוד וכל יחסי התלות, שאפשר להריץ כמעט בכל סביבת מחשוב. אפשר לציין את ה-URI של קובץ אימג' של קונטיינר שנבנה מראש לשימוש, או ליצור ולהעלות קובץ אימג' של קונטיינר בהתאמה אישית שבו אפליקציית האימון והתלות מותקנות מראש.
בטבלה הבאה מוצגים ההבדלים בין תמונות קונטיינר מוכנות מראש לבין תמונות קונטיינר בהתאמה אישית:
| מפרטים | קובצי אימג' מוכנים מראש של קונטיינרים | קובצי אימג' של קונטיינרים בהתאמה אישית |
|---|---|---|
| מסגרת ML | כל קובץ אימג' של קונטיינר ספציפי למסגרת ML. | אפשר להשתמש בכל מסגרת ML או לא להשתמש באף אחת. |
| גרסת מסגרת ML | כל קובץ אימג' של קונטיינר ספציפי לגרסה של מסגרת ML. | אפשר להשתמש בכל גרסה של framework ללמידת מכונה, כולל גרסאות משניות וגרסאות build יומיות. |
| תלות של האפליקציה | יחסי תלות נפוצים של מסגרת ה-ML מותקנים מראש. אתם יכולים לציין יחסי תלות נוספים להתקנה באפליקציית האימון. | מבצעים התקנה מראש של התלויות שאפליקציית האימון צריכה. |
| פורמט מסירת האפליקציה |
|
מתקינים מראש את אפליקציית האימון בקובץ האימג' המותאם אישית של הקונטיינר. |
| משך ההגדרה | נמוכה | גבוהה |
| מומלץ ל | אפליקציות אימון של Python שמבוססות על מסגרת למידת מכונה ועל גרסת מסגרת שיש לה קובץ אימג' מוכן מראש של קונטיינר. |
|
אריזת אפליקציית האימון
אחרי שקובעים את סוג קובץ האימג' של הקונטיינר שבו רוצים להשתמש, צריך לארוז את אפליקציית האימון באחד מהפורמטים הבאים, בהתאם לסוג קובץ האימג' של הקונטיינר:
קובץ Python יחיד לשימוש במאגר שנוצר מראש
כותבים את אפליקציית האימון כקובץ Python יחיד ומשתמשים ב-Agent Platform SDK for Python כדי ליצור מחלקה
CustomJobאוCustomTrainingJob. קובץ ה-Python נארז בהפצה של מקור Python ומוגדר להתקנה בקובץ אימג' של קונטיינר מוכן מראש. העברת אפליקציית האימון כקובץ Python יחיד מתאימה ליצירת אב טיפוס. באפליקציות אימון שמוכנות להפקה, סביר להניח שאפליקציית האימון תהיה מסודרת ביותר מקובץ אחד.הפצה של קוד מקור של Python לשימוש בקונטיינר מוכן מראש
אורזים את אפליקציית האימון למקורות הפצה אחד או יותר של Python ומעלים אותם לקטגוריה של Cloud Storage. Gemini Enterprise Agent Platform מתקינה את מקורות ההפצה בקובץ אימג' של קונטיינר מוכן מראש כשיוצרים משימת אימון.
קובץ אימג' של קונטיינר בהתאמה אישית
יוצרים קובץ אימג' של קונטיינר של Docker שכולל את אפליקציית האימון והתלויות שהותקנו מראש, ומעלים אותו ל-Artifact Registry. אם אפליקציית האימון כתובה ב-Python, אפשר לבצע את השלבים האלה באמצעות פקודה אחת של Google Cloud CLI.
הגדרת משימת אימון
משימת אימון של Gemini Enterprise Agent Platform מבצעת את הפעולות הבאות:
- הפונקציה מקצה מכונה וירטואלית אחת (אימון של צומת יחיד) או יותר (אימון מבוזר).
- מריצה את אפליקציית האימון בקונטיינרים במכונות הווירטואליות שהוקצו.
- מחיקת מכונות וירטואליות אחרי שפעולת האימון מסתיימת.
Gemini Enterprise Agent Platform מציעה שלושה סוגים של משימות אימון להרצת אפליקציית האימון:
-
עבודה בהתאמה אישית (
CustomJob) מריצה את אפליקציית האימון. אם משתמשים בקובץ אימג' של קונטיינר שנבנה מראש, פלט של ארטיפקטים של המודל מועבר לקטגוריה של Cloud Storage שצוינה. כשמשתמשים בקובצי אימג' של קונטיינר בהתאמה אישית, אפליקציית האימון יכולה גם להעביר פלט של ארטיפקטים של המודל למיקומים אחרים. -
תהליך אופטימיזציה של היפרפרמטרים (
HyperparameterTuningJob) מריץ כמה ניסיונות של אפליקציית האימון באמצעות ערכים שונים של היפרפרמטרים, עד שהוא מייצר ארטיפקטים של מודל עם ערכי ההיפרפרמטרים האופטימליים. אתם מציינים את טווח הערכים של ההיפרפרמטרים לבדיקה ואת המדדים לאופטימיזציה. -
צינור אימון (
CustomTrainingJob) מריץ משימה מותאמת אישית או משימת כוונון של היפר-פרמטרים, ובאופן אופציונלי מייצא את ארטיפקטים של המודל ל-Gemini Enterprise Agent Platform כדי ליצור משאב מודל. אתם יכולים לציין מערך נתונים מנוהל של Gemini Enterprise Agent Platform כמקור הנתונים.
כשיוצרים משימת אימון, מציינים את משאבי המחשוב שבהם רוצים להשתמש להרצת אפליקציית האימון ומגדירים את הגדרות הקונטיינר.
הגדרות מחשוב
מציינים את משאבי החישוב שבהם רוצים להשתמש למשימת ההדרכה. פלטפורמת הסוכנים של Gemini Enterprise תומכת בהדרכה של צומת יחיד, שבה משימת ההדרכה פועלת במכונה וירטואלית אחת, ובהדרכה מבוזרת, שבה משימת ההדרכה פועלת בכמה מכונות וירטואליות.
אלה משאבי המחשוב שאפשר לציין למשימת האימון:
VM machine type
סוגים שונים של מכונות מציעים מעבדים שונים, גודל זיכרון ורוחב פס שונים.
יחידות לעיבוד גרפי (GPU)
אפשר להוסיף יחידת GPU אחת או יותר למכונות וירטואליות מסוג A2 או N1. אם אפליקציית האימון שלכם מיועדת לשימוש ב-GPU, הוספת GPU יכולה לשפר משמעותית את הביצועים.
יחידות לעיבוד טנסורים (TPU)
מעבדי TPU מיועדים במיוחד להאצת עומסי עבודה של למידת מכונה. כשמשתמשים במכונת TPU וירטואלית לאימון, אפשר לציין רק מאגר עובדים אחד. במאגר העובדים הזה יכולה להיות רק העתק אחד.
דיסקים לאתחול
אפשר להשתמש בכונני SSD (ברירת מחדל) או בכונני HDD לדיסק האתחול. אם אפליקציית האימון קוראת וכותבת לדיסק, שימוש בכונני SSD יכול לשפר את הביצועים. אפשר גם לציין את הגודל של דיסק האתחול על סמך כמות הנתונים הזמניים שאפליקציית האימון כותבת לדיסק. גודל דיסקי האתחול יכול להיות בין 100GiB (ברירת מחדל) ל-64,000GiB. כל המכונות הווירטואליות במאגר העובדים צריכות להשתמש באותו סוג וגודל של דיסק אתחול.
הגדרות של קונטיינרים
הגדרות הקונטיינר שצריך לבצע תלויות בשאלה אם משתמשים בקובץ אימג' של קונטיינר שנבנה מראש או בקובץ אימג' מותאם אישית.
תצורות מוכנות מראש של קונטיינרים:
- מציינים את ה-URI של קובץ אימג' של קונטיינר המוכנה מראש שבה רוצים להשתמש.
- אם אפליקציית האימון שלכם ארוזה כהפצה של מקור Python, מציינים את ה-URI של Cloud Storage שבו נמצאת החבילה.
- מציינים את מודול נקודת הכניסה של אפליקציית ההדרכה.
- אופציונלי: מציינים רשימה של ארגומנטים בשורת הפקודה שיועברו למודול של נקודת הכניסה של אפליקציית האימון.
הגדרות מותאמות אישית של מאגר תגים:
- מציינים את ה-URI של קובץ האימג' של הקונטיינר בהתאמה אישית, שיכול להיות URI מ-Artifact Registry או מ-Docker Hub.
- אופציונלי: אפשר לבטל את ההוראות
ENTRYPOINTאוCMDבקובץ אימג' של קונטיינר.
יצירת משימת אימון
אחרי שמכינים את הנתונים ואת אפליקציית האימון, מריצים את אפליקציית האימון על ידי יצירת אחת ממשימות האימון הבאות:
כדי ליצור את משימת האימון, אפשר להשתמש במסוף Google Cloud , ב-Google Cloud CLI, ב-Agent Platform SDK for Python או ב-Agent Platform API.
(אופציונלי) ייבוא ארטיפקטים של מודלים ל-Gemini Enterprise Agent Platform
אפליקציית האימון שלכם כנראה יוצרת פלט של פריטי מידע של מודל אחד או יותר למיקום שצוין, בדרך כלל מאגר Cloud Storage. כדי לקבל מסקנות בפלטפורמת הסוכנים של Gemini Enterprise מפריטי המידע של המודל, קודם צריך לייבא את פריטי המידע של המודל למאגר המודלים של פלטפורמת הסוכנים של Gemini Enterprise.
בדומה לתמונות של קונטיינרים לאימון, Gemini Enterprise Agent Platform מאפשרת לבחור בין שימוש בתמונות של קונטיינרים שנוצרו מראש לבין שימוש בתמונות של קונטיינרים בהתאמה אישית להסקת מסקנות. אם יש קובץ אימג' של קונטיינר מוכן מראש להסקת מסקנות עבור framework ה-ML וגרסת ה-framework שלכם, מומלץ להשתמש בקובץ אימג' של קונטיינר מוכן מראש.
המאמרים הבאים
- קבלת מסקנות מהמודל.
- הערכת המודל.
- כדאי לנסות את המדריך Hello serverless training לקבלת הוראות מפורטות לאימון מודל לסיווג תמונות של TensorFlow Keras ב-Gemini Enterprise Agent Platform.