
ב-Looker, טבלאות נגזרות מתמידות (PDT) נכתבות לסכימת ה-scratch של מסד הנתונים. Looker שומרת ובונה מחדש PDT על סמך אסטרטגיית השמירה שלו. כשמפעילים PDT כדי לבנות מחדש, Looker בונה מחדש את כל הטבלה כברירת מחדל.
PDT מצטבר הוא PDT ש-Looker בונה על ידי הוספת נתונים חדשים לטבלה, במקום לבנות מחדש את הטבלה כולה:
אם הדיאלקט שלכם תומך ב-PDT מצטבר, אתם יכולים להפוך את סוגי ה-PDT הבאים ל-PDT מצטבר:
- טבלאות מצטברות
- טבלאות PDT מבוססות LookML (מקורי)
- PDT מבוסס SQL
בפעם הראשונה שמריצים שאילתה ב-PDT מצטבר, Looker בונה את ה-PDT כולו כדי לקבל את הנתונים הראשוניים. אם הטבלה גדולה, יכול להיות שהבנייה הראשונית תימשך זמן רב, כמו כל בנייה של טבלה גדולה. אחרי שהטבלה הראשונית נוצרת, אם ה-PDT המצטבר מוגדר בצורה אסטרטגית, הטבלאות הבאות ייווצרו בהדרגה וידרשו פחות זמן.
הערות לגבי כללי PDT מצטברים:
- התכונה 'PDT מצטבר' נתמכת רק ב-PDT שמשתמשים באסטרטגיית התמדה מבוססת-טריגר (
datagroup_trigger,sql_trigger_valueאוinterval_trigger). התכונה 'PDT מצטבר' לא נתמכת ב-PDT שמשתמשים באסטרטגיית ההתמדהpersist_for. - כדי להשתמש ב-PDT מצטבר שמבוסס על SQL, צריך להגדיר את שאילתת הטבלה באמצעות הפרמטר
sql. אי אפשר לבנות באופן מצטבר PDTs מבוססי-SQL שמוגדרים עם הפרמטרsql_createאו עם הפרמטרcreate_process. כפי שאפשר לראות בדוגמה 1 בדף הזה, Looker משתמש בפקודה INSERT או בפקודה MERGE כדי ליצור את הגידולים ב-PDT מצטבר. אי אפשר להגדיר את טבלת הנתונים הנגזרים באמצעות הצהרות שפה להגדרת נתונים (DDL) בהתאמה אישית, כי Looker לא יוכל לקבוע אילו הצהרות DDL נדרשות כדי ליצור תוספת מדויקת. - טבלת המקור של ה-PDT המצטבר חייבת להיות מותאמת לשאילתות מבוססות-זמן. באופן ספציפי, לעמודה מבוססת-הזמן שמשמשת כמפתח מצטבר צריכה להיות מוגדרת אסטרטגיית אופטימיזציה, כמו חלוקה למחיצות, מפתחות מיון, אינדקסים או כל אסטרטגיית אופטימיזציה אחרת שנתמכת בניב שלכם. מומלץ מאוד לבצע אופטימיזציה של טבלת המקור, כי בכל פעם שמעדכנים את הטבלה המצטברת, Looker שולח שאילתה לטבלת המקור כדי לקבוע את הערכים העדכניים ביותר של העמודה שמבוססת על זמן ומשמשת כמפתח מצטבר. אם טבלת המקור לא עברה אופטימיזציה לשאילתות האלה, יכול להיות שהשאילתה של Looker לגבי הערכים האחרונים תהיה איטית ויקרה.
הגדרת PDT מצטבר
אפשר להשתמש בפרמטרים הבאים כדי להפוך PDT ל-PDT מצטבר:
-
increment_key(נדרש כדי להפוך את ה-PDT ל-PDT מצטבר): מגדיר את פרק הזמן שבו צריך לבצע שאילתה לגבי רשומות חדשות. {% incrementcondition %}מסנן Liquid (נדרש כדי להפוך PDT מבוסס-SQL ל-PDT מצטבר; לא רלוונטי ל-PDT מבוסס-LookML): מקשר את מפתח ההצטברות לעמודת הזמן במסד הנתונים שעליה מבוסס מפתח ההצטברות. מידע נוסף מופיע בדף התיעוד שלincrement_key.-
increment_offset(אופציונלי): מספר שלם שמגדיר את מספר התקופות הקודמות (ברמת הגרנולריות של מפתח התוספת) שנבנות מחדש עבור כל build מצטבר. הפרמטרincrement_offsetשימושי במקרים של נתונים שמתקבלים באיחור, שבהם יכול להיות שבנתונים מתקופות קודמות ייכללו נתונים חדשים שלא נכללו כשנוצר התוסף התואם והתווסף ל-PDT.
בדף התיעוד של הפרמטר increment_key יש דוגמאות שמראות איך ליצור PDT מצטבר מטבלאות נגזרות מתמידות מקוריות, מטבלאות נגזרות מתמידות שמבוססות על SQL ומטבלאות מצטברות.
הנה דוגמה פשוטה לקובץ תצוגה שמגדיר PDT מצטבר מבוסס LookML:
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
הטבלה הזו תיבנה במלואה בפעם הראשונה שתופעל עליה שאילתה. לאחר מכן, ה-PDT ייבנה מחדש במרווחים של יום אחד (increment_key: departure_date), עד שלושה ימים אחורה (increment_offset: 3).
מפתח הגידול מבוסס על המאפיין departure_date, שהוא למעשה date מסגרת הזמן מקבוצת המאפיינים departure. (במאמר על הפרמטר dimension_group מוסבר איך פועלות קבוצות של מאפיינים). קבוצת המאפיינים וטווח הזמן מוגדרים בתצוגה flights, שהיא explore_source עבור ה-PDT הזה. כך מוגדרת קבוצת המאפיינים departure בקובץ התצוגה המפורטת flights:
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
האינטראקציה בין פרמטרים של הגדלה לבין אסטרטגיית שמירה
ההגדרות increment_key ו-increment_offset של PDT לא תלויות בשיטת ההתמדה של ה-PDT:
- שיטת ההתמדה של ה-PDT המצטבר קובעת רק מתי ה-PDT יגדל. הכלי ליצירת PDT לא משנה את ה-PDT המצטבר אלא אם מופעלת אסטרטגיית השמירה של הטבלה, או אם ה-PDT מופעל באופן ידני באמצעות האפשרות Rebuild Derived Tables & Run (בנייה מחדש של טבלאות נגזרות והרצה) ב-Explore.
- כש-PDT מתעדכן, כלי ה-PDT Builder קובע מתי הנתונים האחרונים נוספו לטבלה, לפי המרווח הנוכחי ביותר של הזמן (תקופת הזמן שמוגדרת על ידי הפרמטר
increment_key). על סמך זה, כלי ה-PDT יקצץ את הנתונים לתחילת מרווח הזמן האחרון בטבלה, ואז יבנה את מרווח הזמן האחרון משם. - אם ל-PDT יש פרמטר
increment_offset, כלי ה-PDT Builder יבנה מחדש גם את מספר התקופות הקודמות שצוינו בפרמטרincrement_offset. התקופות הקודמות מתחילות מההתחלה של מרווח הזמן הנוכחי ביותר (תקופת הזמן שמוגדרת על ידי הפרמטרincrement_key).
בדוגמאות הבאות אפשר לראות איך מתעדכנים PDT מצטברים, ואיך מתבצעת האינטראקציה בין increment_key, increment_offset ואסטרטגיית השמירה.
דוגמה 1
בדוגמה הזו נעשה שימוש ב-PDT עם המאפיינים הבאים:
- מפתח מצטבר: תאריך
- הגדלת ההיסט: 3
- שיטת התמדה: מופעלת פעם בחודש ביום הראשון של החודש
כך הטבלה הזו תעודכן:
- אסטרטגיית התמדה חודשית פירושה שהטבלה נוצרת אוטומטית פעם בחודש. לדוגמה, ב-1 ביוני, השורה האחרונה בטבלה תהיה השורה שנוספה ב-1 במאי.
- מכיוון של-PDT הזה יש מפתח מצטבר שמבוסס על תאריך, הכלי ליצירת PDT יקצץ את הנתונים של 1 במאי לתחילת היום ויבנה מחדש את הנתונים של 1 במאי ועד היום הנוכחי, 1 ביוני.
- בנוסף, ל-PDT הזה יש היסט של
3. לכן, כלי ה-PDT גם בונה מחדש את הנתונים משלושת פרקי הזמן הקודמים (ימים) לפני 1 במאי. התוצאה היא שהנתונים נבנים מחדש עבור התאריכים 28, 29 ו-30 באפריל, ועד היום הנוכחי, 1 ביוני.
במונחים של SQL, זו הפקודה שכלי ה-PDT Builder יריץ ב-1 ביוני כדי לקבוע אילו שורות מתוך ה-PDT הקיים צריך לבנות מחדש:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
זו פקודת ה-SQL שכלי ה-PDT יריץ ב-1 ביוני כדי ליצור את התוספת האחרונה:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
דוגמה 2
בדוגמה הזו נעשה שימוש ב-PDT עם המאפיינים הבאים:
- שיטת התמדה: מופעלת פעם ביום
- Increment key: month
- Increment offset: 0
כך הטבלה הזו תעודכן ב-1 ביוני:
- המשמעות של אסטרטגיית ההתמדה היומית היא שהטבלה נוצרת באופן אוטומטי פעם ביום. ב-1 ביוני, השורה האחרונה בטבלה תהיה השורה שנוספה ב-31 במאי.
- מכיוון שמפתח ההגדלה מבוסס על החודש, הכלי ליצירת PDT יקצץ את הנתונים מ-31 במאי עד תחילת החודש, ויבנה מחדש את הנתונים של כל חודש מאי ועד היום הנוכחי, כולל 1 ביוני.
- מכיוון שאין ל-PDT הזה היסט של תוספת, לא מתבצעת בנייה מחדש של תקופות זמן קודמות.
כך הטבלה הזו תעודכן ב-2 ביוני:
- ב-2 ביוני, השורה האחרונה בטבלה תהיה השורה שנוספה ב-1 ביוני.
- כלי ה-PDT יקצץ את הנתונים עד לתחילת חודש יוני, ואז יבנה מחדש את הנתונים החל מ-1 ביוני ועד היום הנוכחי. לכן, הנתונים ייבנו מחדש רק לגבי 1 ביוני ו-2 ביוני.
- מכיוון שאין היסט של תוספת ל-PDT הזה, לא מתבצעת בנייה מחדש של תקופות זמן קודמות.
דוגמה 3
בדוגמה הזו נעשה שימוש ב-PDT עם המאפיינים הבאים:
- Increment key: month
- הגדלת ההיסט: 3
- שיטת התמדה: מופעלת פעם ביום
התרחיש הזה ממחיש הגדרה לא טובה של PDT מצטבר, כי מדובר ב-PDT שמופעל מדי יום עם היסט של שלושה חודשים. המשמעות היא שנתונים של לפחות שלושה חודשים ייבנו מחדש מדי יום, וזה יהיה שימוש לא יעיל במיוחד ב-PDT מצטבר. עם זאת, זהו תרחיש מעניין לבדיקה כדי להבין איך פועלים ערכי PDT מצטברים.
כך הטבלה הזו תעודכן ב-1 ביוני:
- המשמעות של אסטרטגיית ההתמדה היומית היא שהטבלה נוצרת באופן אוטומטי פעם ביום. לדוגמה, ב-1 ביוני, השורה האחרונה בטבלה תהיה השורה שנוספה ב-31 במאי.
- מכיוון שמפתח ההגדלה מבוסס על החודש, הכלי ליצירת PDT יקצץ את הנתונים מ-31 במאי עד תחילת החודש, ויבנה מחדש את הנתונים של כל חודש מאי ועד היום הנוכחי, כולל 1 ביוני.
- בנוסף, ל-PDT הזה יש היסט של
3. כלומר, כלי ה-PDT גם בונה מחדש את הנתונים משלושת פרקי הזמן הקודמים (חודשים) לפני מאי. התוצאה היא שהנתונים נבנים מחדש מפברואר, מרץ, אפריל ועד היום הנוכחי, 1 ביוני.
כך הטבלה הזו תעודכן ב-2 ביוני:
- ב-2 ביוני, השורה האחרונה בטבלה תהיה השורה שנוספה ב-1 ביוני.
- כלי ה-PDT Builder יקצץ את החודש עד 1 ביוני ויבנה מחדש את הנתונים לחודש יוני, כולל 2 ביוני.
- בנוסף, בגלל ההיסט של הגידול, כלי ה-PDT יבנה מחדש את הנתונים מ-3 החודשים הקודמים לפני יוני. התוצאה היא שהנתונים נבנים מחדש החל מחודש מרץ, אפריל ומאי ועד היום הנוכחי, 2 ביוני.
בדיקת PDT מצטבר במצב פיתוח
לפני שפורסים PDT מצטבר חדש בסביבת הייצור, אפשר לבדוק את ה-PDT כדי לוודא שהוא נבנה ומוסיף נתונים. כדי לבדוק PDT מצטבר במצב פיתוח:
יוצרים ניתוח ל-PDT:
- בקובץ מודל משויך, משתמשים בפרמטר
includeכדי לכלול את קובץ התצוגה של ה-PDT בקובץ המודל. - באותו קובץ מודל, משתמשים בפרמטר
exploreכדי ליצור תצוגה של PDT מצטבר ב-Explore.
include: "/views/e_faa_pdt.view" explore: e_faa_pdt {}- בקובץ מודל משויך, משתמשים בפרמטר
פותחים את הכלי 'חיפוש ובדיקה' עבור ה-PDT. כדי לעשות את זה, לוחצים על הלחצן See file actions (הצגת פעולות בקובץ) ואז בוחרים שם של Explore.
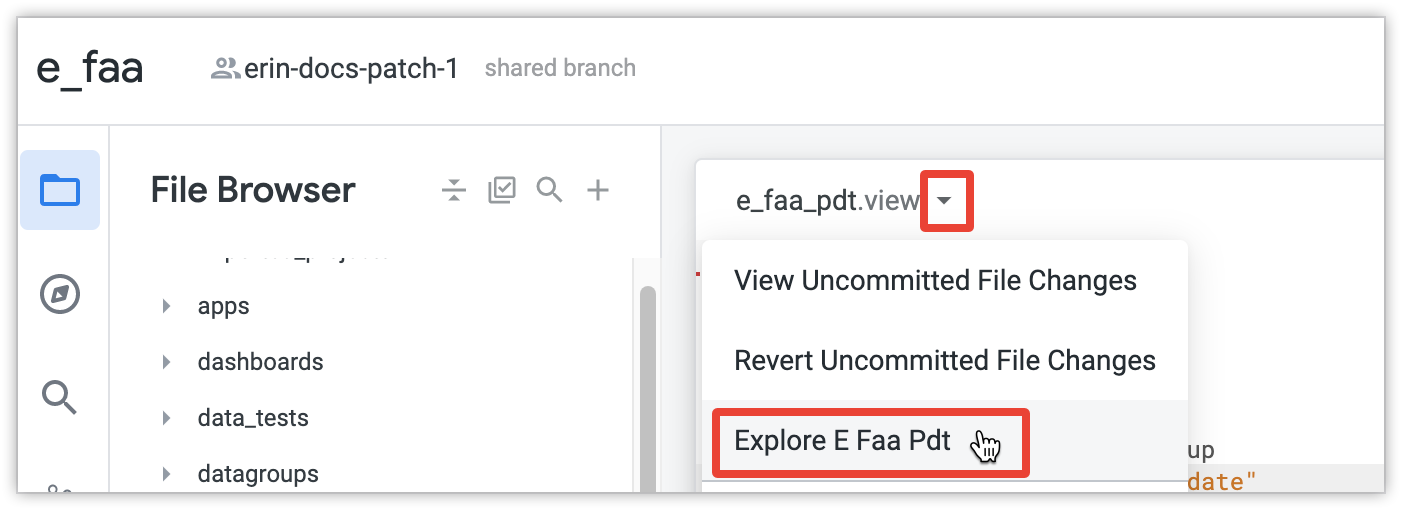
בכרטיסייה 'ניתוחים', בוחרים כמה מאפיינים או מדדים ולוחצים על הפעלה. לאחר מכן, מערכת Looker תבנה את כל ה-PDT. אם זו השאילתה הראשונה שהרצתם ב-PDT המצטבר, כלי ה-PDT Builder יבנה את כל ה-PDT כדי לקבל את הנתונים הראשוניים. אם הטבלה גדולה, יכול להיות שהבנייה הראשונית תימשך זמן רב, כמו כל בנייה של טבלה גדולה.
כדי לוודא ש-PDT הראשוני נוצר, אפשר לבצע את הפעולות הבאות:
- אם יש לכם הרשאה מסוג
see_logs, תוכלו לבדוק אם הטבלה נוצרה על ידי עיון ביומן האירועים של PDT. אם אתם לא רואים את האירועים של PDT ביומן האירועים של PDT, כדאי לבדוק את פרטי הסטטוס בחלק העליון של הכלי 'ניתוח נתונים' ביומן האירועים של PDT. אם מופיע הכיתוב 'מהמטמון', אפשר לבחור באפשרות ניקוי המטמון ורענון כדי לקבל מידע עדכני יותר. - אפשר גם לראות את ההערות בכרטיסייה SQL בסרגל נתונים של הכלי 'ניתוח נתונים'. בכרטיסייה SQL מוצגות השאילתה והפעולות שיבוצעו כשמריצים את השאילתה ב'ניתוח נתונים'. לדוגמה, אם התגובות בכרטיסייה SQL הן
-- generate derived table e_incremental_pdt
- אם יש לכם הרשאה מסוג
אחרי שיוצרים את הגרסה הראשונית של ה-PDT, מריצים בנייה מצטברת של ה-PDT באמצעות האפשרות Rebuild Derived Tables & Run (בנייה מחדש של טבלאות נגזרות והרצה) מתוך Explore.
אפשר להשתמש באותן שיטות כמו קודם כדי לוודא ש-PDT נוצר באופן מצטבר:
- אם יש לכם הרשאה ל-
see_logs, תוכלו להשתמש ביומן האירועים של PDT כדי לראות אירועים של PDT מצטבר.create increment completeאם האירוע הזה לא מופיע ביומן האירועים של PDT והסטטוס של השאילתה הוא 'ממטמון', בוחרים באפשרות ניקוי המטמון ורענון כדי לקבל מידע עדכני יותר. - בודקים את ההערות בכרטיסייה SQL בסרגל נתונים של הכלי 'ניתוח נתונים'. במקרה כזה, ההערות יציינו שה-PDT גדל. לדוגמה:
-- increment persistent derived table e_incremental_pdt to generation 2
- אם יש לכם הרשאה ל-
אחרי שמוודאים ש-PDT נוצר ושהערך שלו גדל בצורה תקינה, אפשר להסיר או להוסיף הערה לפרמטרים
exploreו-includeשל ה-PDT מקובץ המודל, אם לא רוצים לשמור את ה-Explore הייעודי ל-PDT.
אחרי שיוצרים את ה-PDT במצב פיתוח, אותו טבלה תשמש לייצור אחרי שפורסים את השינויים, אלא אם מבצעים שינויים נוספים בהגדרה של הטבלה. מידע נוסף זמין בקטע טבלאות שנשמרות במצב פיתוח בדף התיעוד טבלאות נגזרות ב-Looker.
פתרון בעיות ב-PDT מצטברות
בקטע הזה מתוארות כמה בעיות נפוצות שאתם עלולים להיתקל בהן במהלך השימוש בטבלאות PDT מצטברות, וגם מוסבר איך לפתור את הבעיות האלה.
בניית PDT מצטבר נכשלת אחרי שינוי בסכימה
אם ה-PDT המצטבר שלכם הוא טבלה נגזרת שמבוססת על SQL, והפרמטר sql כולל תו כללי לחיפוש כמו SELECT *, שינויים בסכימת מסד הנתונים הבסיסי (כמו הוספת עמודה, הסרת עמודה או שינוי סוג הנתונים של עמודה) עלולים לגרום ל-PDT להיכשל עם השגיאה הבאה:
SQL Error in incremental PDT: Query execution failed
כדי לפתור את הבעיה הזו, עורכים את ההצהרה SELECT בפרמטר sql כדי לבחור במקום זאת עמודות ספציפיות. לדוגמה, אם פסוקית ה-select היא SELECT *, צריך לשנות אותה ל-SELECT column1, column2, ....
אם הסכימה משתנה ואתם רוצים לבנות מחדש את ה-PDT המצטבר מאפס, צריך להשתמש בקריאה ל-API start_pdt_build ולכלול את הפרמטר full_force_incremental.
ניבים נתמכים של מסדי נתונים ל-PDT מצטבר
כדי ש-Looker יתמוך בטבלאות PDT מצטברות בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בפקודות Data Definition Language (DDL) שמאפשרות מחיקה והוספה של שורות.
בטבלה הבאה מפורטים הניבים שתומכים ב-PDT מצטבר בגרסה האחרונה של Looker (ב-Databricks, PDT מצטבר נתמך רק ב-Databricks מגרסה 12.1 ואילך):
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |