
Python에서 사용자 정의 함수 사용
Python 사용자 정의 함수(UDF)를 사용하면 Python에서 스칼라 함수를 구현하고 SQL 쿼리에서 사용할 수 있습니다. Python UDF는 SQL 및 JavaScript UDF와 유사하지만 추가 기능이 있습니다. Python UDF를 사용하면 Python 패키지 색인 (PyPI)에서 서드 파티 라이브러리를 설치하고 Cloud 리소스 연결을 사용하여 외부 서비스에 액세스할 수 있습니다.
Python UDF는 BigQuery 관리 리소스에서 빌드되고 실행됩니다.
제한사항
python-3.11만 지원되는 런타임입니다.- 임시 Python UDF는 만들 수 없습니다.
- 구체화된 뷰에서는 Python UDF를 사용할 수 없습니다.
- Python UDF의 반환 값은 항상 확정되지 않은 것으로 간주되므로 Python UDF를 호출하는 쿼리의 결과는 캐시되지 않습니다.
- Assured Workloads는 지원되지 않습니다.
JSON,RANGE,INTERVAL,GEOGRAPHY데이터 유형은 지원되지 않습니다.- Python UDF를 실행하는 컨테이너는 최대 vCPU 4개 및 16GiB로만 구성할 수 있습니다.
- 고객 관리 암호화 키 (CMEK)를 사용하여 Python UDF 코드를 암호화하는 것은 지원되지 않습니다.
- Python UDF는 VPC 서비스 제어를 지원하지만 VPC 네트워크는 지원하지 않습니다.
필요한 역할
필요한 IAM 역할은 Python UDF 소유자인지 Python UDF 사용자인지에 따라 다릅니다.
UDF 소유자
Python UDF 소유자는 일반적으로 UDF를 만들거나 업데이트합니다. Cloud 리소스 연결을 참조하는 Python UDF를 만드는 경우 추가 역할도 필요합니다.
이 연결은 UDF가 WITH CONNECTION 절을 사용하여 외부 서비스에 액세스하는 경우에만 필요합니다.
Python UDF를 만들거나 업데이트하는 데 필요한 권한을 얻으려면 관리자에게 다음 IAM 역할을 부여해 달라고 요청하세요.
- 데이터 세트에 대한 BigQuery 데이터 편집자 (
roles/bigquery.dataEditor) - 프로젝트에 대한 BigQuery 작업 사용자(
roles/bigquery.jobUser) - 프로젝트에 대한 BigQuery 연결 관리자 (
roles/bigquery.connectionAdmin)
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
이러한 사전 정의된 역할에는 Python UDF를 만들거나 업데이트하는 데 필요한 권한이 포함되어 있습니다. 필요한 정확한 권한을 보려면 필수 권한 섹션을 펼치세요.
필수 권한
Python UDF를 만들거나 업데이트하려면 다음 권한이 필요합니다.
-
CREATE FUNCTION문을 사용하여 Python UDF를 만듭니다.bigquery.routines.createon the dataset -
CREATE FUNCTION문을 사용하여 Python UDF를 업데이트합니다.bigquery.routines.update데이터 세트에서 -
CREATE FUNCTION문 쿼리 작업을 실행합니다.bigquery.jobs.create프로젝트에 대한 권한 -
새 Cloud 리소스 연결 만들기:
bigquery.connections.createon the project -
CREATE FUNCTION문에서 연결을 사용합니다.bigquery.connections.delegateon the connection
커스텀 역할이나 다른 사전 정의된 역할을 사용하여 이 권한을 부여받을 수도 있습니다.
BigQuery의 역할에 대한 자세한 내용은 사전 정의된 IAM 역할을 참조하세요.
UDF 사용자
Python UDF 사용자는 다른 사용자가 만든 UDF를 호출합니다. Cloud 리소스 연결을 참조하는 Python UDF를 호출하는 경우에도 추가 역할이 필요합니다.
다른 사용자가 만든 Python UDF를 호출하는 데 필요한 권한을 얻으려면 관리자에게 다음 IAM 역할을 부여해 달라고 요청하세요.
- 프로젝트에 대한 BigQuery 사용자 (
roles/bigquery.user) - 데이터 세트에 대한 BigQuery 데이터 뷰어 (
roles/bigquery.dataViewer) - 연결에 대한 BigQuery 연결 사용자 (
roles/bigquery.connectionUser)
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
이러한 사전 정의된 역할에는 다른 사용자가 만든 Python UDF를 호출하는 데 필요한 권한이 포함되어 있습니다. 필요한 정확한 권한을 보려면 필수 권한 섹션을 펼치세요.
필수 권한
다른 사용자가 만든 Python UDF를 호출하려면 다음 권한이 필요합니다.
-
Python UDF를 참조하는 쿼리 작업을 실행하려면 프로젝트에 대한
bigquery.jobs.create권한이 필요합니다. -
다른 사용자가 만든 Python UDF를 호출하려면 데이터 세트에 대한
bigquery.routines.get권한이 있어야 합니다. -
Cloud 리소스 연결을 참조하는 Python UDF를 실행하려면 다음을 실행하세요.
bigquery.connections.use연결
커스텀 역할이나 다른 사전 정의된 역할을 사용하여 이 권한을 부여받을 수도 있습니다.
BigQuery의 역할에 대한 자세한 내용은 사전 정의된 IAM 역할을 참조하세요.
영구 Python UDF 만들기
Python UDF를 만들 때는 다음 규칙을 따르세요.
Python UDF 본문은 Python 코드를 나타내는 따옴표 붙은 문자열 리터럴이어야 합니다. 따옴표 붙은 문자열 리터럴에 대해 자세히 알아보려면 따옴표 붙은 리터럴의 형식을 참조하세요.
Python UDF의 본문에는 Python UDF 옵션 목록의
entry_point인수에서 사용되는 Python 함수가 포함되어야 합니다.runtime_version옵션에 Python 런타임 버전을 지정해야 합니다. 지원되는 유일한 Python 런타임 버전은python-3.11입니다. 사용 가능한 옵션의 전체 목록은CREATE FUNCTION문의 함수 옵션 목록을 참고하세요.
영구 Python UDF를 만들려면 TEMP 또는 TEMPORARY 키워드 없이 CREATE FUNCTION 문을 사용합니다. 영구 Python UDF를 삭제하려면 DROP FUNCTION 문을 사용합니다.
예
영구 Python UDF를 만드는 예시를 보려면 다음 옵션 중 하나를 선택하세요.
콘솔
다음 예시에서는 multiplyInputs라는 영구 Python UDF를 만들고 SELECT 문 내에서 UDF를 호출합니다.
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음
CREATE FUNCTION문을 입력합니다.CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyInputs(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="multiply") AS r''' def multiply(x, y): return x * y '''; -- Call the Python UDF. WITH numbers AS (SELECT 1 AS x, 5 as y UNION ALL SELECT 2 AS x, 10 as y UNION ALL SELECT 3 as x, 15 as y) SELECT x, y, `PROJECT_ID.DATASET_ID`.multiplyInputs(x, y) AS product FROM numbers;
PROJECT_ID을 바꿉니다.DATASET_ID 를 프로젝트 ID와 데이터 세트 ID로 바꿉니다.
실행을 클릭합니다.
이 예시는 다음 출력을 생성합니다.
+-----+-----+--------------+ | x | y | product | +-----+-----+--------------+ | 1 | 5 | 5.0 | | 2 | 10 | 20.0 | | 3 | 15 | 45.0 | +-----+-----+--------------+
BigQuery DataFrames
다음 예시에서는 BigQuery DataFrames를 사용하여 커스텀 함수를 Python UDF로 변환합니다.
컨테이너 빌드 상태
CREATE FUNCTION 문을 사용하여 Python UDF를 만들면 BigQuery는 기본 이미지를 기반으로 하는 컨테이너 이미지를 만들거나 업데이트합니다. 컨테이너는 코드와 지정된 패키지 종속 항목을 사용하여 기본 이미지에 빌드됩니다.
컨테이너를 만드는 것은 장기 실행 프로세스입니다. CREATE FUNCTION 문장을 실행한 후 첫 번째 쿼리는 이미지 빌드가 완료될 때까지 기다립니다. 외부 종속 항목이 없으면 일반적으로 1분 이내에 컨테이너 이미지가 생성됩니다.
프로젝트 및 리전별 모든 Python UDF 컨테이너의 크기는 합계 10GiB로 제한됩니다. 자세한 내용은 영구 UDF의 사용자 정의 함수 제한을 참고하세요. 프로젝트가 할당량에 도달하면 컨테이너 빌드가 실패합니다.
컨테이너 빌드 상태를 확인하려면 다음 중 하나를 선택합니다.
콘솔
BigQuery Studio 페이지로 이동합니다.
왼쪽 창에서 프로젝트를 펼친 다음 데이터 세트를 클릭합니다.
링크를 클릭하여 Python UDF가 포함된 데이터 세트를 엽니다.
데이터 세트 페이지에서 루틴 탭을 클릭합니다.
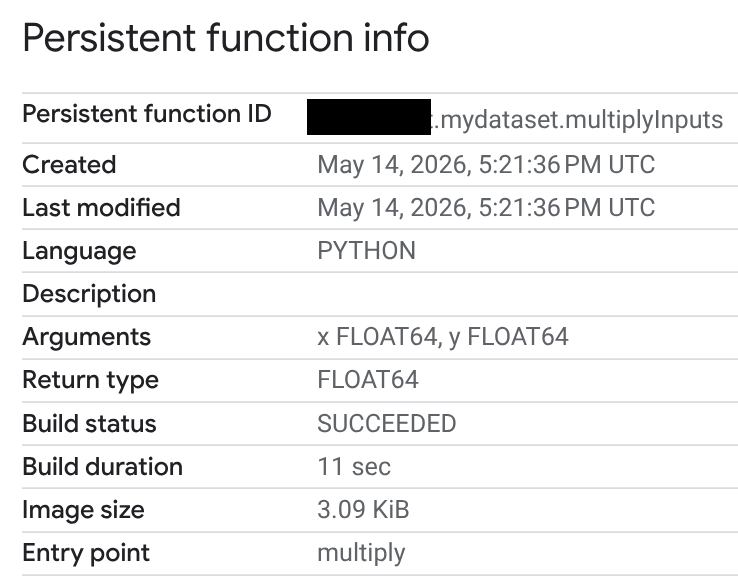
루틴 ID 열에서 Python UDF를 클릭합니다.
영구 함수 정보 페이지에서 빌드 상태, 빌드 기간, 이미지 크기를 확인할 수 있습니다. 빌드 상태는 다음 중 하나입니다.
- 진행 중
- 성공
- 실패
빌드가 실패하면 함수 정보 페이지에 자세한 오류 메시지가 표시되므로 구문 오류나 외부 패키지 설치 문제와 같은 문제를 해결할 수 있습니다.
SQL
INFORMATION_SCHEMA.ROUTINES 뷰에서 빌드 상태 필드를 쿼리하려면 다음 단계를 따르세요.
BigQuery Studio 페이지로 이동합니다.
쿼리 편집기로 전환하거나 SQL 쿼리를 클릭합니다.
다음 쿼리를 입력하여
INFORMATION_SCHEMA.ROUTINES뷰에서BUILD_STATUS필드를 가져옵니다.BUILD_STATUS열은 GoogleSQL에서STRUCT유형입니다.SELECT build_status.* FROM `PROJECT_ID.DATASET_ID`.INFORMATION_SCHEMA.ROUTINES;PROJECT_ID을 바꿉니다.DATASET_ID를 프로젝트 ID와 데이터 세트 ID로 바꿉니다.
다음과 유사하게 출력됩니다. 오류 필드가 생략됩니다.
+---------------+--------------------------------+------------------------+------------------+ | build_state | build_state_update_time | build_duration_seconds | image_size_bytes | +---------------+--------------------------------+------------------------+------------------+ | SUCCEEDED | 2026-05-14 17:21:49.736000 UTC | 11 | 3167 | +---------------+--------------------------------+------------------------+------------------+
API
API에서 RoutineBuildStatus를 사용하여 컨테이너 빌드 상태를 확인합니다.
벡터화된 Python UDF 만들기
벡터화를 사용하여 단일 행 대신 행 배치를 처리하도록 Python UDF를 구현할 수 있습니다. 벡터화는 쿼리 성능을 개선할 수 있습니다. Pandas 또는 Apache Arrow를 사용하여 벡터화된 UDF를 만들 수 있습니다.
일괄 처리 동작을 제어하려면 CREATE OR REPLACE FUNCTION 옵션 목록에서 max_batching_rows 옵션을 사용하여 각 배치에 있는 최대 행 수를 지정합니다. max_batching_rows를 지정하면 BigQuery에서 배치의 행 수를 max_batching_rows 한도까지 결정합니다.
max_batching_rows를 지정하지 않으면 일괄처리할 행 수가 자동으로 결정됩니다.
Pandas 사용
벡터화된 Python UDF에는 주석 처리해야 하는 단일 pandas.DataFrame 인수가 있습니다. pandas.DataFrame 인수에는 CREATE FUNCTION 문에 정의된 Python UDF 파라미터와 동일한 수의 열이 있습니다. pandas.DataFrame 인수에서 열 이름은 UDF의 파라미터와 이름이 같습니다.
함수는 pandas.Series 또는 입력과 행 수가 동일한 단일 열 pandas.DataFrame을 반환해야 합니다.
다음 예시에서는 x 및 y라는 두 파라미터가 있는 벡터화된 Python UDF multiplyInputs를 만듭니다.
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음
CREATE FUNCTION문을 입력합니다.CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorized(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="vectorized_multiply") AS r''' import pandas as pd def vectorized_multiply(df: pd.DataFrame): return df['x'] * df['y'] ''';
PROJECT_ID을 바꿉니다.DATASET_ID를 프로젝트 ID와 데이터 세트 ID로 바꿉니다.
UDF 호출은 이전 예시와 동일합니다.
실행을 클릭합니다.
Apache Arrow 사용
다음 예시에서는 Apache Arrow RecordBatch 인터페이스를 사용합니다. RecordBatch 인터페이스를 사용하면 함수가 길이가 동일한 열의 행 배치를 진입점에 전달합니다.
다음 예에서는 Apache Arrow를 사용하여 multiplyVectorizedArrow라는 벡터화된 Python UDF를 만듭니다.
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음
CREATE FUNCTION문을 입력합니다.CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorizedArrow(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS( runtime_version="python-3.11", entry_point="vectorized_multiply_arrow" ) AS r''' import pyarrow as pa import pyarrow.compute as pc def vectorized_multiply_arrow(batch: pa.RecordBatch): # Access columns directly from the Arrow RecordBatch x = batch.column('x') y = batch.column('y') # Use pyarrow.compute for vectorized operations return pc.multiply(x, y) ''';
PROJECT_ID을 바꿉니다.DATASET_ID를 프로젝트 ID와 데이터 세트 ID로 바꿉니다.
UDF 호출은 이전 예시와 동일합니다.
실행을 클릭합니다.
Python UDF 호출
Python UDF를 호출할 권한이 있으면 다른 함수처럼 호출할 수 있습니다. 다른 프로젝트에 정의된 함수를 사용하려면 함수의 완전한 이름을 사용하세요. 예를 들어 다른 프로젝트에서 cw_xml_extract라는 XML 추출 함수를 호출하려면 다음 단계를 완료하세요.
콘솔
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 예시를 입력합니다.
SELECT `PROJECT_ID.DATASET_ID`.`cw_xml_extract`(xml, '//title/text()') AS `title` FROM UNNEST([ STRUCT('''<book id="1"> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> </book>''' AS xml), STRUCT('''<book id="2"> <title>1984</title> <author>George Orwell</author> </book>''' AS xml), STRUCT('''<book id="3"> <title>Brave New World</title> <author>Aldous Huxley</author> </book>''' AS xml) ])실행을 클릭합니다.
이 예시는 다음 출력을 생성합니다.
+--------------------------+ | title | +--------------------------+ | The Great Gatsby | | 1984 | | Brave New World | +--------------------------+
BigQuery DataFrames
다음 예에서는 BigQuery DataFrames
sql_scalar, read_gbq_function, apply 메서드를 사용하여 Python UDF를 호출합니다.
지원되는 Python UDF 데이터 유형
다음 표에서는 BigQuery 데이터 유형, Python 데이터 유형, Pandas 데이터 유형 간의 매핑을 정의합니다.
| BigQuery 데이터 유형 | 표준 UDF에서 사용하는 Python 기본 제공 데이터 유형 | 벡터화된 UDF에서 사용되는 Pandas 데이터 유형 | 벡터화된 UDF에서 ARRAY 및 STRUCT에 사용되는 PyArrow 데이터 유형 |
|---|---|---|---|
BOOL |
bool |
BooleanDtype |
DataType(bool) |
INT64 |
int |
Int64Dtype |
DataType(int64) |
FLOAT64 |
float |
FloatDtype |
DataType(double) |
STRING |
str |
StringDtype |
DataType(string) |
BYTES |
bytes |
binary[pyarrow] |
DataType(binary) |
TIMESTAMP |
함수 파라미터: 함수 반환 값: |
함수 파라미터: 함수 반환 값: |
TimestampType(timestamp[us]), 시간대 포함 |
DATE |
datetime.date |
date32[pyarrow] |
DataType(date32[day]) |
TIME |
datetime.time |
time64[pyarrow] |
Time64Type(time64[us]) |
DATETIME |
datetime.datetime(시간대 없음) |
timestamp[us][pyarrow] |
TimestampType(timestamp[us]), 시간대 없음 |
ARRAY |
list |
list<...>[pyarrow](요소 데이터 유형이 pandas.ArrowDtype인 경우) |
ListType |
STRUCT |
dict |
struct<...>[pyarrow](필드 데이터 유형이 pandas.ArrowDtype인 경우) |
StructType |
지원되는 런타임 버전
BigQuery Python UDF는 python-3.11 런타임을 지원합니다. 이 Python 버전에는 몇 가지 추가 사전 설치 패키지가 포함되어 있습니다. 시스템 라이브러리의 경우 런타임 기본 이미지를 확인합니다.
| 런타임 버전 | Python 버전 | 포함 |
|---|---|---|
| python-3.11 | Python 3.11 | numpy 1.26.3 pyarrow 14.0.2 pandas 2.1.4 python-dateutil 2.8.2 absl-py 2.0.0 pytz 2023.3.post1 tzdata 2023.4 six 1.16.0 |
서드 파티 패키지 사용
CREATE FUNCTION 옵션 목록을 사용하여 Python 표준 라이브러리 및 사전 설치된 패키지에서 제공하는 모듈이 아닌 다른 모듈을 사용할 수 있습니다.
Python 패키지 색인 (PyPI)에서 패키지를 설치하거나 Cloud Storage에서 Python 파일을 가져올 수 있습니다.
Python 패키지 색인에서 패키지 설치
패키지를 설치할 때는 패키지 이름을 제공해야 하며, Python 패키지 버전 지정자를 사용하여 패키지 버전을 선택적으로 제공할 수 있습니다.
패키지가 런타임에 있는 경우 CREATE FUNCTION 옵션 목록에 특정 버전이 지정되지 않는 한 해당 패키지가 사용됩니다. 패키지 버전을 지정하지 않고 패키지가 런타임에 없으면 사용 가능한 최신 버전이 사용됩니다. 휠 바이너리 형식이 있는 패키지만 지원됩니다.
다음 예시에서는 CREATE OR REPLACE FUNCTION 옵션 목록을 사용하여 scipy 패키지를 설치하는 Python UDF를 만드는 방법을 보여줍니다.
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음
CREATE FUNCTION문을 입력합니다.CREATE FUNCTION `PROJECT_ID.DATASET_ID`.area(radius FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='area_handler', runtime_version='python-3.11', packages=['scipy==1.15.3']) AS r""" import scipy def area_handler(radius): return scipy.constants.pi*radius*radius """; SELECT `PROJECT_ID.DATASET_ID`.area(4.5);
PROJECT_ID을 바꿉니다.DATASET_ID를 프로젝트 ID와 데이터 세트 ID로 바꿉니다.
실행을 클릭합니다.
추가 Python 파일을 라이브러리로 가져오기
Cloud Storage에서 Python 파일을 가져와 함수 옵션 목록을 사용하여 Python UDF를 확장할 수 있습니다.
UDF의 Python 코드에서 import 문과 Cloud Storage 객체 경로를 사용하여 Cloud Storage의 Python 파일을 모듈로 가져올 수 있습니다. 예를 들어 gs://BUCKET_NAME/path/to/lib1.py를 가져오는 경우 가져오기 문은 import
path.to.lib1이 됩니다.
Python 파일 이름은 Python 식별자여야 합니다. 객체 이름 (/ 뒤)의 각 folder 이름은 유효한 Python 식별자여야 합니다. ASCII 범위(U+0001..U+007F) 내에서 다음 문자를 식별자에 사용할 수 있습니다.
- 대문자 및 소문자 A~Z
- 밑줄
- 0~9의 숫자. 단, 숫자는 식별자의 첫 번째 문자로 사용할 수 없습니다.
다음 예시에서는 my_bucket이라는 Cloud Storage 버킷에서 lib1.py 클라이언트 라이브러리 패키지를 가져오는 Python UDF를 만드는 방법을 보여줍니다.
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음
CREATE FUNCTION문을 입력합니다.CREATE FUNCTION `PROJECT_ID.DATASET_ID`.myFunc(a FLOAT64, b STRING) RETURNS STRING LANGUAGE python OPTIONS ( entry_point='compute', runtime_version='python-3.11', library=['gs://BUCKET_NAME/PATH/lib1.py']) AS r""" import path.to.lib1 as lib1 def compute(a, b): # doInterestingStuff is a function defined in # gs://BUCKET_NAME/PATH/lib1.py return lib1.doInterestingStuff(a, b); """;
다음을 바꿉니다.
- PROJECT_ID: 프로젝트 ID입니다.
- DATASET_ID: 데이터 세트 ID입니다.
- BUCKET_NAME:
lib1.py이 포함된 Cloud Storage 버킷의 이름입니다. - PATH: Cloud Storage 버킷 경로
실행을 클릭합니다.
Python UDF의 컨테이너 한도 구성
CREATE FUNCTION 옵션 목록을 사용하여 Python UDF를 실행하는 컨테이너의 CPU, 메모리, 컨테이너 요청 동시 실행 제한을 지정할 수 있습니다.
기본적으로 컨테이너에는 다음 리소스가 할당됩니다.
- 할당된 메모리는
512Mi입니다. - 할당된 CPU는
1.0vCPU입니다. - 컨테이너 요청 동시 실행 한도는
80입니다.
다음 예시에서는 CREATE FUNCTION 옵션 목록을 사용하여 컨테이너 한도를 지정하여 Python UDF를 만듭니다.
BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음
CREATE FUNCTION문을 입력합니다.CREATE FUNCTION `PROJECT_ID.DATASET_ID`.square_area(length FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='square_area', runtime_version='python-3.11', container_memory='CONTAINER_MEMORY', container_cpu=CONTAINER_CPU, container_request_concurrency=CONTAINER_REQUEST_CONCURRENCY) AS r""" def square_area(length): return length*length """; SELECT `PROJECT_ID.DATASET_ID`.square_area(4.5);
다음을 바꿉니다.
- PROJECT_ID.DATASET_ID: 프로젝트 ID 및 데이터 세트 ID입니다.
- CONTAINER_MEMORY: 다음 형식의 메모리 값입니다.
<integer_number><unit>단위는Mi(MiB),M(MB),Gi(GiB),G(GB) 중 하나여야 합니다. 예를 들면2Gi입니다. - CONTAINER_CPU: CPU 값입니다. Python UDF는
0.33과1.0사이의 분수 CPU 값과1,2,4의 정수 CPU 값을 지원합니다. - CONTAINER_REQUEST_CONCURRENCY: Python UDF 컨테이너 인스턴스당 최대 동시 요청 수입니다. 값은
1~1000범위의 정수여야 합니다.
실행을 클릭합니다.
지원되는 CPU 값
Python UDF는 0.33과 1.0 사이의 분수 CPU 값과 1, 2, 4의 정수 CPU 값을 지원합니다. Python UDF를 실행하는 컨테이너는 최대 4 vCPU로 구성할 수 있습니다. 기본값은 1.0입니다. 분수 입력 값은 컨테이너에 적용되기 전에 소수점 둘째 자리로 반올림됩니다.
지원되는 메모리 값
Python UDF 컨테이너는 <integer_number><unit> 형식의 메모리 값을 지원합니다. 단위는 Mi, M, Gi, G 중 하나여야 합니다. 구성할 수 있는 최소 메모리 양은 256Mi입니다. 구성할 수 있는 최대 메모리 양은 16Gi입니다.
선택한 메모리 값을 기반으로 적절한 CPU 양도 지정해야 합니다. 다음 표에서는 각 메모리 값의 최소 및 최대 CPU 값을 보여줍니다.
| 메모리 | 최소 CPU | 최대 CPU |
|---|---|---|
256Mi~512Mi |
0.33 |
2 |
512Mi보다 크고 1Gi 이하 |
0.5 |
2 |
1Gi보다 크고 2Gi보다 작음 |
1 |
2 |
2Gi~4Gi |
1 |
4 |
4Gi 초과 8Gi 이하 |
2 |
4 |
8Gi 초과 16Gi 이하 |
4 |
4 |
또는 할당할 CPU 양을 결정한 경우 다음 표를 사용하여 적절한 메모리 범위를 결정할 수 있습니다.
| CPU | 최소 메모리 | 최대 메모리 |
|---|---|---|
0.5 미만 |
256Mi |
512Mi |
0.5에서 1 미만으로 |
256Mi |
1Gi |
1 |
256Mi |
4Gi |
2 |
256Mi |
8Gi |
4 |
2Gi |
16Gi |
Python 코드에서 Google Cloud 또는 온라인 서비스 호출
Python UDF는 Cloud 리소스 연결 서비스 계정을 사용하여 Google Cloud 서비스 또는 외부 서비스에 액세스합니다. 연결의 서비스 계정에 서비스 액세스 권한이 부여되어야 합니다. 필요한 권한은 액세스하는 서비스와 Python 코드에서 호출하는 API에 따라 다릅니다.
Cloud 리소스 연결을 사용하지 않고 Python UDF를 만들면 네트워크 액세스를 차단하는 환경에서 함수가 실행됩니다. UDF가 온라인 서비스에 액세스하는 경우 Cloud 리소스 연결을 사용하여 UDF를 만들어야 합니다. 그렇지 않으면 내부 연결 제한 시간이 도달할 때까지 UDF가 네트워크에 액세스할 수 없습니다. Cloud 리소스 연결을 사용하는 경우 다음을 구현합니다.
제한 시간 Python UDF 내에서 네트워크 호출을 할 때는 항상 적절한 시간 제한을 포함하세요. 이렇게 하면 외부 서비스의 응답이 느리거나 연결할 수 없는 경우 UDF가 무기한 중단되지 않습니다.
오류 처리를 사용합니다. 네트워크 호출 코드를
try...except블록으로 래핑하여 연결 오류, 시간 초과, HTTP 실패 상태 코드와 같은 잠재적인 오류를 정상적으로 처리합니다. 이를 통해 UDF는 쿼리가 실패하거나 응답을 중지하는 대신 의미 있는 오류나 대체 값을 반환할 수 있습니다.
다음 예시에서는 Python UDF에서 Cloud Translation 서비스에 액세스하는 방법을 보여줍니다. 이 예시에는 두 개의 프로젝트가 있습니다. UDF와 Cloud 리소스 연결을 만드는 프로젝트(my_query_project)와 Cloud Translation을 실행하는 프로젝트(my_translate_project)입니다.
Cloud 리소스 연결 만들기
먼저 my_query_project에서 Cloud 리소스 연결을 만듭니다. Cloud 리소스 연결을 만들려면 다음 단계를 따르세요.
콘솔
BigQuery 페이지로 이동합니다.
왼쪽 창에서 탐색기를 클릭합니다.

왼쪽 창이 표시되지 않으면 왼쪽 창 펼치기를 클릭하여 창을 엽니다.
탐색기 창에서 프로젝트 이름을 펼친 후 연결을 클릭합니다.
연결 페이지에서 연결 만들기를 클릭합니다.
연결 유형으로 Vertex AI 원격 모델, 원격 함수, BigLake, Spanner(Cloud 리소스)를 선택합니다.
연결 ID 필드에 연결 이름을 입력합니다.
위치 유형에서 연결 위치를 선택합니다. 연결은 데이터 세트와 같이 다른 리소스와 함께 배치해야 합니다.
연결 만들기를 클릭합니다.
연결로 이동을 클릭합니다.
연결 정보 창에서 이후 단계에 사용할 서비스 계정 ID를 복사합니다.
SQL
CREATE CONNECTION 문을 사용합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
다음을 바꿉니다.
-
CONNECTION_NAME:PROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_ID또는CONNECTION_ID형식의 연결 이름입니다. 프로젝트 또는 위치를 생략하면 문이 실행되는 프로젝트 및 위치에서 추론됩니다. -
FRIENDLY_NAME(선택사항): 연결의 설명이 포함된 이름입니다. -
DESCRIPTION(선택사항): 연결에 대한 설명입니다.
-
실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
bq
명령줄 환경에서 연결을 만듭니다.
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
--project_id매개변수는 기본 프로젝트를 재정의합니다.다음을 바꿉니다.
REGION: 연결 리전PROJECT_ID: Google Cloud 프로젝트 IDCONNECTION_ID: 연결의 ID
연결 리소스를 만들면 BigQuery가 고유한 시스템 서비스 계정을 만들고 이를 연결에 연계합니다.
문제 해결: 다음 연결 오류가 발생하면 Google Cloud SDK를 업데이트하세요.
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
이후 단계에서 사용할 수 있도록 서비스 계정 ID를 가져와 복사합니다.
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
출력은 다음과 비슷합니다.
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Python
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Terraform
google_bigquery_connection 리소스를 사용합니다.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
다음 예시에서는 US 리전에 my_cloud_resource_connection이라는 Cloud 리소스 연결을 만듭니다.
Google Cloud 프로젝트에 Terraform 구성을 적용하려면 다음 섹션의 단계를 완료하세요.
Cloud Shell 준비
- Cloud Shell을 실행합니다.
-
Terraform 구성을 적용할 기본 Google Cloud 프로젝트를 설정합니다.
이 명령어는 프로젝트당 한 번만 실행하면 되며 어떤 디렉터리에서도 실행할 수 있습니다.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Terraform 구성 파일에서 명시적 값을 설정하면 환경 변수가 재정의됩니다.
디렉터리 준비
각 Terraform 구성 파일에는 자체 디렉터리(루트 모듈이라고도 함)가 있어야 합니다.
-
Cloud Shell에서 디렉터리를 만들고 해당 디렉터리 내에 새 파일을 만드세요. 파일 이름에는
.tf확장자가 있어야 합니다(예:main.tf). 이 튜토리얼에서는 파일을main.tf라고 합니다.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
튜토리얼을 따라 하는 경우 각 섹션이나 단계에서 샘플 코드를 복사할 수 있습니다.
샘플 코드를 새로 만든
main.tf에 복사합니다.필요한 경우 GitHub에서 코드를 복사합니다. 이는 Terraform 스니펫이 엔드 투 엔드 솔루션의 일부인 경우에 권장됩니다.
- 환경에 적용할 샘플 파라미터를 검토하고 수정합니다.
- 변경사항을 저장합니다.
-
Terraform을 초기화합니다. 이 작업은 디렉터리당 한 번만 수행하면 됩니다.
terraform init
원하는 경우 최신 Google 공급업체 버전을 사용하려면
-upgrade옵션을 포함합니다.terraform init -upgrade
변경사항 적용
-
구성을 검토하고 Terraform에서 만들거나 업데이트할 리소스가 예상과 일치하는지 확인합니다.
terraform plan
필요에 따라 구성을 수정합니다.
-
다음 명령어를 실행하고 프롬프트에
yes를 입력하여 Terraform 구성을 적용합니다.terraform apply
Terraform에 '적용 완료' 메시지가 표시될 때까지 기다립니다.
- 결과를 보려면 Google Cloud 프로젝트를 엽니다. Google Cloud 콘솔에서 UI의 리소스로 이동하여 Terraform이 리소스를 만들었거나 업데이트했는지 확인합니다.
연결의 서비스 계정에 대한 액세스 권한 부여하기
연결의 권한을 구성할 때 이전에 복사한 서비스 계정 ID가 필요합니다. 연결 리소스를 만들면 BigQuery가 고유한 시스템 서비스 계정을 만들고 이를 연결에 연계합니다.
Cloud 리소스 연결 서비스 계정에 프로젝트 액세스 권한을 부여하려면 my_query_project에서 서비스 계정에 서비스 사용량 소비자 역할(roles/serviceusage.serviceUsageConsumer)을 부여하고 my_translate_project에서 Cloud Translation API 사용자 역할 (roles/cloudtranslate.user)을 부여합니다.
콘솔
IAM 페이지로 이동합니다.
my_query_project가 선택되었는지 확인합니다.액세스 권한 부여를 클릭합니다.
새 주 구성원 필드에 이전에 복사한 클라우드 리소스 연결의 서비스 계정 ID를 입력합니다.
역할 선택 필드에서 서비스 사용량을 선택한 후 서비스 사용량 소비자를 선택합니다.
저장을 클릭합니다.
프로젝트 선택기에서
my_translate_project를 선택합니다.IAM 페이지로 이동합니다.
액세스 권한 부여를 클릭합니다.
새 주 구성원 필드에 이전에 복사한 클라우드 리소스 연결의 서비스 계정 ID를 입력합니다.
역할 선택 필드에서 Cloud Translation을 선택한 후 Cloud Translation API 사용자를 선택합니다.
저장을 클릭합니다.
SQL
GRANT 문을 사용하여 my_query_project의 서비스 계정에 서비스 사용량 소비자 역할 (roles/serviceusage.serviceUsageConsumer)을 부여합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
GRANT `roles/serviceusage.serviceUsageConsumer` ON PROJECT `my_query_project` TO "connection:SERVICE_ACCOUNT_ID";
SERVICE_ACCOUNT_ID을 이전에 복사한 서비스 계정 ID로 바꿉니다.실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
GRANT 문을 사용하여 my_translate_project에서 Cloud Translation API 사용자 역할 (roles/cloudtranslate.user)을 부여합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에서 다음 문을 입력합니다.
GRANT `roles/cloudtranslate.user` ON PROJECT `my_translate_project` TO "connection:SERVICE_ACCOUNT_ID";
SERVICE_ACCOUNT_ID을 이전에 복사한 서비스 계정 ID로 바꿉니다.실행을 클릭합니다.
쿼리를 실행하는 방법에 대한 자세한 내용은 대화형 쿼리 실행을 참조하세요.
Cloud Translation 서비스를 호출하는 Python UDF 만들기
my_query_project에서 Cloud 리소스 연결을 사용하여 Cloud Translation 서비스를 호출하는 Python UDF를 만듭니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
쿼리 편집기에 다음
CREATE FUNCTION문을 입력합니다.CREATE FUNCTION `PROJECT_ID.DATASET_ID`.translate_to_es(x STRING) RETURNS STRING LANGUAGE python WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID` OPTIONS (entry_point='do_translate', runtime_version='python-3.11', packages=['google-cloud-translate>=3.11', 'google-api-core']) AS r""" from google.api_core.retry import Retry from google.cloud import translate project = "my_translate_project" translate_client = translate.TranslationServiceClient() def do_translate(x : str) -> str: response = translate_client.translate_text( request={ "parent": f"projects/PROJECT_ID/locations/us-central1", "contents": [x], "target_language_code": "es", "mime_type": "text/plain", }, retry=Retry(), ) return response.translations[0].translated_text """; -- Call the UDF. WITH text_table AS (SELECT "Hello" AS text UNION ALL SELECT "Good morning" AS text UNION ALL SELECT "Goodbye" AS text) SELECT text, `PROJECT_ID.DATASET_ID`.translate_to_es(text) AS translated_text FROM text_table;
다음을 바꿉니다.
PROJECT_ID: 프로젝트 IDDATASET_ID: 데이터 세트 IDREGION: 연결의 리전CONNECTION_ID: 연결 ID입니다.
실행을 클릭합니다.
다음과 유사하게 출력됩니다.
+--------------------------+-------------------------------+ | text | translated_text | +--------------------------+-------------------------------+ | Hello | Hola | | Good morning | Buen dia | | Goodbye | Adios | +--------------------------+-------------------------------+
VPC 서비스 제어 사용
Python UDF는 쿼리 작업을 실행하는 프로젝트의 VPC 서비스 제어 경계를 상속합니다. 이 경계는 데이터 무단 반출로부터 작업을 보호하고 서비스 상호작용이 안전하도록 보장합니다.
VPC 서비스 제어 경계 내에서 Python UDF를 호출하면 다음과 같은 네트워크 연결이 있습니다.
- Cloud 리소스 연결을 사용하지 않는 Python UDF는 완전히 격리됩니다. 모든 아웃바운드 트래픽이 차단됩니다.
- Cloud 리소스 연결을 사용하는 Python UDF는 공개 인터넷 액세스가 차단됩니다. Python UDF는 VPC 서비스 제어를 지원하는 Google Cloud 서비스에만 액세스할 수 있습니다.
restricted.googleapis.com이외의 모든 대상으로의 아웃바운드 트래픽이 차단됩니다.
VPC 서비스 제어 내에서 Google Cloud 서비스에 안전하게 액세스하도록 Python UDF 구성
VPC 서비스 제어를 적용하는 동안 Python UDF에서 Google Cloud 서비스에 액세스하려면 다음 단계를 따르세요.
- CREATE FUNCTION 문's
WITH CONNECTION절을 사용하여 Python UDF를 만듭니다. - 쿼리 작업이 실행되는 BigQuery 프로젝트와 타겟 서비스 프로젝트를 서비스 경계에 포함합니다. 또는 경계 브리지를 구성합니다.
- 타겟 서비스 API를 경계 구성에 추가합니다. 예를 들어 Cloud Translation API에 연결하는 경우
translate.googleapis.com입니다.
VPC 서비스 제어 경계 구성에 관한 자세한 내용은 다음을 참고하세요.
권장사항
Python UDF를 만들 때는 다음 권장사항을 따르세요.
- 일괄 처리를 위해 쿼리 로직을 최적화합니다. 복잡한 쿼리 구조는 일괄 처리를 사용 중지할 수 있습니다. 이로 인해 행별로 느리게 처리되므로 대규모 데이터 세트의 지연 시간이 크게 늘어납니다.
- 데이터 페이로드를 최적화합니다. 개별 행의 크기는 일괄 처리 기능의 효율성에 영향을 줄 수 있습니다. 단일 배치에서 처리할 수 있는 행 수를 최대화하려면 각 행을 최대한 작게 유지하세요.
- 컨테이너 한도를 효율적으로 구성합니다. 확장성은 CPU, 메모리, 요청 동시성의 함수입니다. 모니터링 측정항목을 확인하여 컨테이너 구성을 조정합니다.
CPU 사용률이 높으면
container_cpu한도를 사용하여 CPU 할당을 늘리거나container_request_concurrency한도를 사용하여 컨테이너 요청 동시 실행을 줄입니다. - 반복 튜닝을 사용하는 경우 기본값으로 시작하세요. 성능이 최적이 아닌 경우 모니터링 측정항목을 분석하여 특정 병목 현상을 파악합니다.
- API 시간 제한 구현 Python UDF가 인터넷에 액세스할 때는 예기치 않은 동작을 방지하기 위해 API 호출에 제한 시간을 설정하세요. 인터넷 액세스의 예로는 Cloud Storage 버킷에서 읽는 것이 있습니다.
Python UDF 측정항목 보기
Python UDF는 Cloud Monitoring으로 측정항목을 내보냅니다. 이러한 측정항목은 UDF의 운영 상태와 리소스 소비의 다양한 측면을 모니터링하는 데 도움이 되며 UDF 인스턴스의 성능과 동작에 대한 통계를 제공합니다.
모니터링 리소스 유형
Python UDF의 측정항목은 다음 Cloud Monitoring 리소스 유형에 따라 보고됩니다.
- 유형:
bigquery.googleapis.com/ManagedRoutineInvocation - 표시 이름: BigQuery 관리형 루틴 호출
- 라벨:
resource_container: 쿼리 작업이 실행된 프로젝트의 ID입니다.location: 쿼리 작업이 실행된 위치입니다.query_job_id: Python UDF를 호출한 쿼리 작업의 ID입니다.routine_project_id: 호출된 루틴이 저장된 프로젝트 ID입니다.routine_dataset_id: 호출된 루틴이 저장된 데이터 세트 ID입니다.routine_id: 호출된 루틴의 ID입니다.
측정항목
bigquery.googleapis.com/ManagedRoutineInvocation 리소스 유형에 사용할 수 있는 측정항목은 다음과 같습니다.
| 측정항목 | 설명 | 단위 | 값 유형 |
|---|---|---|---|
bigquery.googleapis.com/managed_routine/python/cpu_utilizations |
Python UDF가 호출되면 이 측정항목은 쿼리 작업의 모든 Python UDF 인스턴스에 대한 CPU 사용률 분포를 보여줍니다. | 백분율 값 | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/memory_utilizations |
Python UDF가 호출되면 이 측정항목은 쿼리 작업의 모든 Python UDF 인스턴스에 걸친 메모리 사용률 분포를 보여줍니다. | 백분율 값 | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/max_request_concurrencies |
이 측정항목은 각 Python UDF 인스턴스에서 처리하는 최대 동시 요청 수의 분포를 보여줍니다. | 개수 | DISTRIBUTION |
측정항목 보기
Python UDF의 측정항목을 보려면 다음 섹션의 옵션 중 하나를 선택하세요.
작업 세부정보
특정 쿼리 작업의 Python UDF 측정항목을 보려면 다음 단계를 따르세요.
BigQuery 페이지로 이동합니다.
작업 기록을 클릭합니다.
작업 ID 열에서 쿼리 작업 ID를 클릭합니다.
쿼리 작업 세부정보 페이지에서 Cloud Monitoring 대시보드를 클릭합니다. 이 링크를 클릭하면 작업의 Python UDF 측정항목을 표시하도록 필터링된 대시보드가 표시됩니다.
측정항목 탐색기
측정항목 탐색기에서 Python UDF 측정항목을 보려면 다음 단계를 따르세요.
Cloud Monitoring 측정항목 탐색기 페이지로 이동합니다.
측정항목 선택을 클릭하고 필터 필드에
BigQuery Managed Routine Invocation또는bigquery.googleapis.com/ManagedRoutineInvocation를 입력합니다.Bigquery Managed Routine > Managed_routine을 선택합니다.
다음과 같은 사용 가능한 측정항목을 클릭합니다.
- 인스턴스 CPU 사용률
- 인스턴스 메모리 사용률
- 최대 동시 요청 수
적용을 클릭합니다.
기본적으로 측정항목은 차트에 표시됩니다.
모니터링 리소스 유형에 정의된 라벨을 사용하여 측정항목을 필터링하고 그룹화할 수 있습니다. 측정항목을 필터링하려면 다음 단계를 따르세요.
필터 필드에서
query_job_id또는routine_id과 같은 리소스 유형을 선택합니다.값 필드에 작업 ID 또는 루틴 ID를 입력하거나 목록에서 선택합니다.
Cloud Monitoring 대시보드
모니터링 대시보드를 사용하여 Python UDF 측정항목을 보려면 다음 단계를 따르세요.
Cloud Monitoring 대시보드 페이지로 이동합니다.
BigQuery 관리형 루틴 쿼리 모니터링 대시보드를 클릭합니다.
이 대시보드에서는 UDF 전반의 주요 측정항목을 개략적으로 확인할 수 있습니다.
이 대시보드를 필터링하려면 다음 단계를 따르세요.
필터를 클릭합니다.
리소스별 필터링 목록에서 프로젝트 ID, 위치, 루틴 ID, 작업 ID와 같은 옵션을 선택합니다.
지원되는 위치
Python UDF는 모든 BigQuery 멀티 리전 및 리전 위치에서 지원됩니다.
가격 책정
Python UDF 요금은 BigQuery 서비스 SKU를 사용하여 청구됩니다.
요금에는 다음이 포함됩니다.
UDF 컨테이너 이미지를 빌드하거나 다시 빌드합니다. 이 요금은 고객 코드와 종속 항목으로 해당 이미지를 빌드하는 데 필요한 시간에 비례합니다.
- 루틴 API를 사용하는 경우 최신 빌드 기간은
BuildStatus필드에 있습니다.INFORMATION_SCHEMA.ROUTINES뷰의BuildStatus열에서 빌드 기간을 확인할 수도 있습니다. - 프로젝트별 빌드 총비용을 확인하려면 다음을 사용하여 결제 보고서를 필터링하세요.
- 키:
goog-bq-feature-type - 값:
MANAGED_ROUTINE_BUILD
- 키:
- 루틴 API를 사용하는 경우 최신 빌드 기간은
Python UDF 고객에게는 Python UDF 호출 비용도 청구됩니다. 이 요금은 Python UDF가 호출될 때 소비되는 컴퓨팅 및 메모리 양에 비례합니다.
- 쿼리당 Python UDF 비용을 보려면 Job API를 사용하여
ExternalServiceCosts필드를 쿼리하면 됩니다.INFORMATION_SCHEMA.JOBS뷰에서external_service_costs열을 확인하고'external_service_costs.external_service="MANAGED_ROUTINE_EXECUTION"'필터를 적용하여 쿼리당 비용을 확인할 수도 있습니다. - 프로젝트별로 Python UDF를 실행하는 총비용을 확인하려면 다음을 사용하여 결제 보고서를 필터링하세요.
- 키:
goog-bq-feature-type - 값:
MANAGED_ROUTINE_EXECUTION
- 키:
- 쿼리당 Python UDF 비용을 보려면 Job API를 사용하여
Python UDF로 인해 외부 또는 인터넷 네트워크 이그레스가 발생하는 경우 BigQuery 이그레스 SKU에 따라 프리미엄 등급 인터넷 이그레스 요금도 표시됩니다.
할당량
UDF 할당량 및 한도를 참고하세요.