
Utilizzare le funzioni definite dall'utente in Python
Una funzione definita dall'utente (UDF) Python consente di implementare una funzione scalare in Python e utilizzarla in una query SQL. Le funzioni definite dall'utente Python sono simili alle funzioni definite dall'utente SQL e JavaScript, ma con funzionalità aggiuntive. Le UDF Python ti consentono di installare librerie di terze parti da Python Package Index (PyPI) e di accedere a servizi esterni utilizzando una connessione alle risorse Cloud.
Le UDF Python vengono create ed eseguite su risorse gestite da BigQuery.
Limitazioni
python-3.11è l'unico runtime supportato.- Non puoi creare una UDF Python temporanea.
- Non puoi utilizzare una UDF Python con una vista materializzata.
- I risultati di una query che chiama una funzione definita dall'utente Python non vengono memorizzati nella cache perché si presume sempre che il valore restituito di una funzione definita dall'utente Python non sia deterministico.
- Assured Workloads non è supportato.
- Questi tipi di dati non sono supportati:
JSON,RANGE,INTERVALeGEOGRAPHY. - I container che eseguono UDF Python possono essere configurati solo fino a 4 vCPU e 16 GiB.
- La crittografia del codice UDF Python con chiavi di crittografia gestite dal cliente (CMEK) non è supportata.
- Le UDF Python supportano i Controlli di servizio VPC, ma le reti VPC non sono supportate.
Ruoli obbligatori
I ruoli IAM richiesti dipendono dal fatto che tu sia il proprietario o l'utente di una UDF Python.
Proprietari UDF
In genere, il proprietario di una funzione definita dall'utente Python crea o aggiorna una funzione definita dall'utente. Sono necessari anche ruoli aggiuntivi
se crei una UDF Python che fa riferimento a una connessione alle risorse Cloud.
Questa connessione è necessaria solo se la tua UDF utilizza la clausola
WITH CONNECTION per accedere a un servizio esterno.
Per ottenere le autorizzazioni necessarie per creare o aggiornare una UDF Python, chiedi all'amministratore di concederti i seguenti ruoli IAM:
- Editor dati BigQuery (
roles/bigquery.dataEditor) sul set di dati - Utente job BigQuery (
roles/bigquery.jobUser) sul progetto - BigQuery Connection Admin (
roles/bigquery.connectionAdmin) sul progetto
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questi ruoli predefiniti contengono le autorizzazioni necessarie per creare o aggiornare una UDF Python. Per vedere quali sono esattamente le autorizzazioni richieste, espandi la sezione Autorizzazioni obbligatorie:
Autorizzazioni obbligatorie
Per creare o aggiornare una UDF Python sono necessarie le seguenti autorizzazioni:
-
Crea una UDF Python utilizzando l'istruzione
CREATE FUNCTION:bigquery.routines.createsul set di dati -
Aggiorna una funzione definita dall'utente Python utilizzando l'istruzione
CREATE FUNCTION:bigquery.routines.updatesul set di dati -
Esegui un job di query dell'istruzione
CREATE FUNCTION:bigquery.jobs.createsul progetto -
Crea una nuova connessione risorsa Cloud:
bigquery.connections.createsul progetto -
Utilizza una connessione nell'istruzione
CREATE FUNCTION:bigquery.connections.delegatesulla connessione
Potresti anche ottenere queste autorizzazioni con ruoli personalizzati o altri ruoli predefiniti.
Per saperne di più sui ruoli in BigQuery, vedi Ruoli IAM predefiniti.
utenti UDF
Un utente UDF Python richiama una UDF creata da un altro utente. Sono necessari anche ruoli aggiuntivi se richiami una UDF Python che fa riferimento a una connessione a una risorsa cloud.
Per ottenere le autorizzazioni necessarie per richiamare una UDF Python creata da un altro utente, chiedi all'amministratore di concederti i seguenti ruoli IAM:
- Utente BigQuery (
roles/bigquery.user) sul progetto - Visualizzatore dati BigQuery (
roles/bigquery.dataViewer) sul set di dati - BigQuery Connection User (
roles/bigquery.connectionUser) sulla connessione
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Questi ruoli predefiniti contengono le autorizzazioni necessarie per richiamare una UDF Python creata da un altro utente. Per vedere quali sono esattamente le autorizzazioni richieste, espandi la sezione Autorizzazioni obbligatorie:
Autorizzazioni obbligatorie
Per richiamare una UDF Python creata da un altro utente sono necessarie le seguenti autorizzazioni:
-
Per eseguire un job di query che fa riferimento a una UDF Python:
bigquery.jobs.createsul progetto -
Per richiamare una UDF Python creata da un altro utente:
bigquery.routines.getsul set di dati -
Per eseguire una funzione definita dall'utente Python che fa riferimento a una connessione alle risorse Cloud:
bigquery.connections.usesulla connessione
Potresti anche ottenere queste autorizzazioni con ruoli personalizzati o altri ruoli predefiniti.
Per saperne di più sui ruoli in BigQuery, vedi Ruoli IAM predefiniti.
Crea una funzione definita dall'utente Python permanente
Segui queste regole quando crei una funzione definita dall'utente Python:
Il corpo della UDF Python deve essere un valore letterale stringa tra virgolette che rappresenta il codice Python. Per scoprire di più sui valori letterali stringa tra virgolette, consulta Formati per i valori letterali tra virgolette.
Il corpo della UDF Python deve includere una funzione Python utilizzata nell'argomento
entry_pointnell'elenco delle opzioni della UDF Python.È necessario specificare una versione del runtime Python nell'opzione
runtime_version. L'unica versione del runtime Python supportata èpython-3.11. Per un elenco completo delle opzioni disponibili, consulta l'elenco delle opzioni di funzione per l'istruzioneCREATE FUNCTION.
Per creare una UDF Python persistente, utilizza l'istruzione CREATE FUNCTION
senza la parola chiave TEMP o TEMPORARY. Per eliminare una UDF Python permanente,
utilizza l'istruzione DROP FUNCTION.
Esempio
Per visualizzare un esempio di creazione di una UDF Python persistente, scegli una delle seguenti opzioni:
Console
L'esempio seguente crea una funzione definita dall'utente Python permanente denominata multiplyInputs
e la chiama da un'istruzione SELECT:
Vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyInputs(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="multiply") AS r''' def multiply(x, y): return x * y '''; -- Call the Python UDF. WITH numbers AS (SELECT 1 AS x, 5 as y UNION ALL SELECT 2 AS x, 10 as y UNION ALL SELECT 3 as x, 15 as y) SELECT x, y, `PROJECT_ID.DATASET_ID`.multiplyInputs(x, y) AS product FROM numbers;
Sostituisci PROJECT_ID.DATASET_ID con l'ID progetto e l'ID set di dati.
Fai clic su Esegui.
Questo esempio produce il seguente output:
+-----+-----+--------------+ | x | y | product | +-----+-----+--------------+ | 1 | 5 | 5.0 | | 2 | 10 | 20.0 | | 3 | 15 | 45.0 | +-----+-----+--------------+
BigQuery DataFrames
L'esempio seguente utilizza BigQuery DataFrames per trasformare una funzione personalizzata in una UDF Python:
Stato di Container Build
Quando crei una funzione definita dall'utente Python utilizzando l'istruzione CREATE FUNCTION,
BigQuery crea o aggiorna un'immagine container basata su un'immagine di base. Il container viene creato sull'immagine di base utilizzando il tuo codice e le dipendenze
dei pacchetti specificate.
La creazione del contenitore è un processo di lunga durata. La prima query dopo l'esecuzione
dell'istruzione CREATE FUNCTION attende il completamento della build dell'immagine. Se non
ci sono dipendenze esterne, l'immagine container viene in genere creata in
meno di un minuto.
La dimensione di tutti i container UDF Python per progetto e per regione è limitata a un totale di 10 GiB. Per saperne di più, consulta Limiti delle funzioni definite dall'utente per le funzioni definite dall'utente permanenti. La build del container non riesce se il progetto ha raggiunto la quota.
Per visualizzare lo stato della build del contenitore, scegli una delle seguenti opzioni:
Console
Vai alla pagina BigQuery Studio.
Nel riquadro a sinistra, espandi il progetto e fai clic su Set di dati.
Fai clic sul link per aprire il set di dati che contiene la tua UDF Python.
Nella pagina del set di dati, fai clic sulla scheda Routine.
Nella colonna ID routine, fai clic sulla UDF Python.
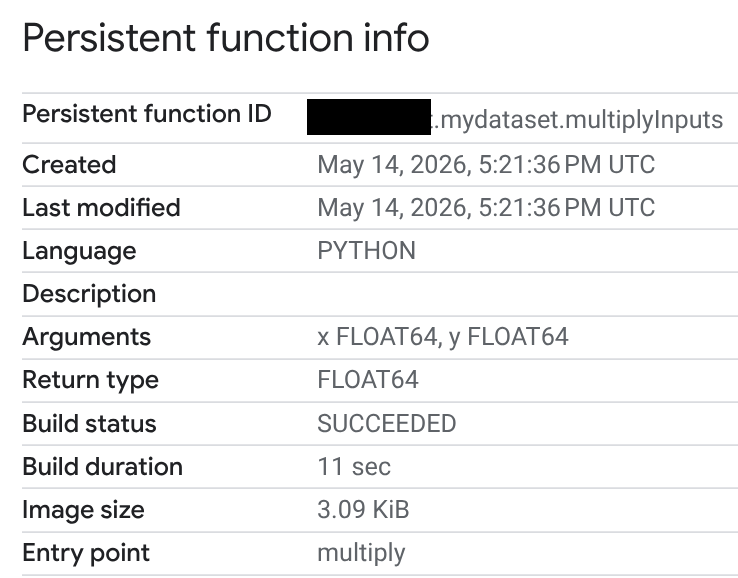
Nella pagina Informazioni funzione permanente puoi visualizzare lo stato della build, la durata della build e le dimensioni dell'immagine. Lo stato della build è uno dei seguenti:
- In corso
- Riuscito
- Non riuscito
Se una build non va a buon fine, la pagina delle informazioni sulla funzione fornisce messaggi di errore dettagliati in modo da poter risolvere problemi come errori di sintassi o problemi di installazione di pacchetti esterni.
SQL
Per eseguire query sui campi dello stato della build nella visualizzazione INFORMATION_SCHEMA.ROUTINES:
Vai alla pagina BigQuery Studio.
Passa all'editor di query o fai clic su Query SQL.
Inserisci la seguente query per recuperare i campi
BUILD_STATUSdalla visualizzazioneINFORMATION_SCHEMA.ROUTINES. La colonnaBUILD_STATUSè un tipoSTRUCTin GoogleSQL:SELECT build_status.* FROM `PROJECT_ID.DATASET_ID`.INFORMATION_SCHEMA.ROUTINES;Sostituisci PROJECT_ID.DATASET_ID con l'ID progetto e l'ID set di dati.
L'output dovrebbe essere simile al seguente. I campi di errore vengono omessi:
+---------------+--------------------------------+------------------------+------------------+ | build_state | build_state_update_time | build_duration_seconds | image_size_bytes | +---------------+--------------------------------+------------------------+------------------+ | SUCCEEDED | 2026-05-14 17:21:49.736000 UTC | 11 | 3167 | +---------------+--------------------------------+------------------------+------------------+
API
Visualizza lo stato della build del container utilizzando RoutineBuildStatus nell'API.
Crea una funzione definita dall'utente Python vettorizzata
Puoi implementare la tua funzione definita dall'utente Python per elaborare un batch di righe anziché una singola riga utilizzando la vettorizzazione. La vettorizzazione può migliorare le prestazioni delle query. Puoi creare una funzione definita dall'utente vettorizzata utilizzando Pandas o Apache Arrow.
Per controllare il comportamento del batch, specifica il numero massimo di righe in ogni batch
utilizzando l'opzione max_batching_rows nell'elenco di opzioni CREATE OR REPLACE FUNCTION. Se specifichi max_batching_rows, BigQuery
determina il numero di righe in un batch, fino al limite di max_batching_rows.
Se max_batching_rows non è specificato, il numero di righe da raggruppare viene determinato automaticamente.
Utilizzare Pandas
Una UDF Python vettorizzata ha un singolo argomento pandas.DataFrame che deve
essere annotato. L'argomento pandas.DataFrame ha lo stesso numero di colonne dei parametri UDF Python definiti nell'istruzione CREATE FUNCTION. I nomi delle colonne nell'argomento pandas.DataFrame hanno gli stessi nomi dei parametri della funzione definita dall'utente.
La funzione deve restituire un pandas.Series o un pandas.DataFrame a una sola colonna con lo stesso numero di righe dell'input.
Il seguente esempio crea una funzione definita dall'utente Python vettorizzata denominata multiplyInputs
con due parametri: x e y:
Vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorized(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="vectorized_multiply") AS r''' import pandas as pd def vectorized_multiply(df: pd.DataFrame): return df['x'] * df['y'] ''';
Sostituisci PROJECT_ID.DATASET_ID con l'ID progetto e l'ID set di dati.
La chiamata alla UDF è la stessa dell'esempio precedente.
Fai clic su Esegui.
Utilizzare Apache Arrow
L'esempio seguente utilizza l'interfaccia
RecordBatch di Apache Arrow. Quando utilizzi l'interfaccia RecordBatch, la funzione passa un batch di righe di colonne di uguale lunghezza al punto di ingresso.
L'esempio seguente utilizza Apache Arrow per creare una UDF Python vettorizzata
denominata multiplyVectorizedArrow.
Vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorizedArrow(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS( runtime_version="python-3.11", entry_point="vectorized_multiply_arrow" ) AS r''' import pyarrow as pa import pyarrow.compute as pc def vectorized_multiply_arrow(batch: pa.RecordBatch): # Access columns directly from the Arrow RecordBatch x = batch.column('x') y = batch.column('y') # Use pyarrow.compute for vectorized operations return pc.multiply(x, y) ''';
Sostituisci PROJECT_ID.DATASET_ID con l'ID progetto e l'ID set di dati.
La chiamata alla UDF è la stessa degli esempi precedenti.
Fai clic su Esegui.
Richiamare una funzione definita dall'utente Python
Se hai l'autorizzazione per richiamare una funzione definita dall'utente Python, puoi chiamarla come qualsiasi
altra funzione. Per utilizzare una funzione definita in un progetto diverso, utilizza il nome completo della funzione. Ad esempio, per chiamare una funzione di estrazione XML
denominata cw_xml_extract
in un altro progetto, completa i seguenti passaggi.
Console
Vai alla pagina BigQuery.
Nell'editor di query, inserisci il seguente esempio:
SELECT `PROJECT_ID.DATASET_ID`.`cw_xml_extract`(xml, '//title/text()') AS `title` FROM UNNEST([ STRUCT('''<book id="1"> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> </book>''' AS xml), STRUCT('''<book id="2"> <title>1984</title> <author>George Orwell</author> </book>''' AS xml), STRUCT('''<book id="3"> <title>Brave New World</title> <author>Aldous Huxley</author> </book>''' AS xml) ])Fai clic su Esegui.
Questo esempio produce il seguente output:
+--------------------------+ | title | +--------------------------+ | The Great Gatsby | | 1984 | | Brave New World | +--------------------------+
BigQuery DataFrames
L'esempio seguente utilizza i metodi BigQuery
DataFrames
sql_scalar,
read_gbq_function
e
apply
per chiamare una UDF Python:
Tipi di dati UDF Python supportati
La seguente tabella definisce il mapping tra i tipi di dati BigQuery, i tipi di dati Python e i tipi di dati Pandas:
| Tipo di dati BigQuery | Tipo di dati integrato di Python utilizzato dalla funzione definita dall'utente standard | Tipo di dati Pandas utilizzato dalla funzione definita dall'utente vettorizzata | Tipo di dati PyArrow utilizzato per ARRAY e STRUCT nella UDF vettorizzata |
|---|---|---|---|
BOOL |
bool |
BooleanDtype |
DataType(bool) |
INT64 |
int |
Int64Dtype |
DataType(int64) |
FLOAT64 |
float |
FloatDtype |
DataType(double) |
STRING |
str |
StringDtype |
DataType(string) |
BYTES |
bytes |
binary[pyarrow] |
DataType(binary) |
TIMESTAMP |
Parametro della funzione: Valore restituito dalla funzione: |
Parametro della funzione: Valore restituito dalla funzione: |
TimestampType(timestamp[us]), con fuso orario |
DATE |
datetime.date |
date32[pyarrow] |
DataType(date32[day]) |
TIME |
datetime.time |
time64[pyarrow] |
Time64Type(time64[us]) |
DATETIME |
datetime.datetime (senza fuso orario) |
timestamp[us][pyarrow] |
TimestampType(timestamp[us]), senza fuso orario |
ARRAY |
list |
list<...>[pyarrow], dove il tipo di dati dell'elemento è pandas.ArrowDtype |
ListType |
STRUCT |
dict |
struct<...>[pyarrow], dove il tipo di dati del campo è pandas.ArrowDtype |
StructType |
Versioni di runtime supportate
Le UDF Python di BigQuery supportano il runtime python-3.11. Questa
versione di Python include alcuni pacchetti preinstallati aggiuntivi. Per le librerie
di sistema, controlla l'immagine di base del runtime.
| Versione runtime | Versione Python | Include |
|---|---|---|
| python-3.11 | Python 3.11 | numpy 1.26.3 pyarrow 14.0.2 pandas 2.1.4 python-dateutil 2.8.2 absl-py 2.0.0 pytz 2023.3.post1 tzdata 2023.4 six 1.16.0 |
Utilizzare pacchetti di terze parti
Puoi utilizzare l'elenco di opzioni CREATE FUNCTION per utilizzare moduli diversi da quelli forniti dalla libreria standard Python e dai pacchetti preinstallati.
Puoi installare pacchetti da Python Package Index (PyPI) oppure importare file Python da Cloud Storage.
Installare un pacchetto dal Python Package Index
Quando installi un pacchetto, devi fornire il nome del pacchetto e, facoltativamente, puoi fornire la versione del pacchetto utilizzando gli specificatori di versione del pacchetto Python.
Se il pacchetto è nel runtime, viene utilizzato a meno che non venga specificata una versione particolare nell'elenco delle opzioni CREATE FUNCTION. Se non viene specificata una versione del pacchetto e il pacchetto non è nel runtime, viene utilizzata l'ultima versione disponibile. Sono supportati solo i pacchetti con il formato binario delle ruote.
L'esempio seguente mostra come creare una UDF Python che installa il pacchetto scipy utilizzando l'elenco di opzioni CREATE OR REPLACE FUNCTION:
Vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.area(radius FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='area_handler', runtime_version='python-3.11', packages=['scipy==1.15.3']) AS r""" import scipy def area_handler(radius): return scipy.constants.pi*radius*radius """; SELECT `PROJECT_ID.DATASET_ID`.area(4.5);
Sostituisci PROJECT_ID.DATASET_ID con l'ID progetto e l'ID set di dati.
Fai clic su Esegui.
Importa file Python aggiuntivi come librerie
Puoi estendere le tue UDF Python utilizzando l'elenco delle opzioni di funzione importando file Python da Cloud Storage.
Nel codice Python della UDF, puoi importare i file Python da Cloud Storage come moduli utilizzando l'istruzione import seguita dal percorso dell'oggetto Cloud Storage. Ad esempio, se importi
gs://BUCKET_NAME/path/to/lib1.py, l'istruzione di importazione sarà import
path.to.lib1.
Il nome file Python deve essere un identificatore Python. Ogni nome folder nel
nome dell'oggetto (dopo /) deve essere un identificatore Python valido. All'interno dell'intervallo ASCII (U+0001..U+007F), è possibile utilizzare i seguenti caratteri negli identificatori:
- Lettere maiuscole e minuscole dalla A alla Z.
- Trattini bassi.
- Le cifre da zero a nove, ma un numero non può essere il primo carattere dell'identificatore.
L'esempio seguente mostra come creare una UDF Python che importa il pacchetto della libreria client lib1.py da un bucket Cloud Storage denominato my_bucket:
Vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.myFunc(a FLOAT64, b STRING) RETURNS STRING LANGUAGE python OPTIONS ( entry_point='compute', runtime_version='python-3.11', library=['gs://BUCKET_NAME/PATH/lib1.py']) AS r""" import path.to.lib1 as lib1 def compute(a, b): # doInterestingStuff is a function defined in # gs://BUCKET_NAME/PATH/lib1.py return lib1.doInterestingStuff(a, b); """;
Sostituisci quanto segue:
- PROJECT_ID: il tuo ID progetto.
- DATASET_ID: il tuo ID set di dati.
- BUCKET_NAME: il nome del bucket Cloud Storage che contiene
lib1.py. - PATH: il percorso del bucket Cloud Storage.
Fai clic su Esegui.
Configura i limiti dei container per le UDF Python
Puoi utilizzare l'elenco delle opzioni CREATE FUNCTION per specificare i limiti di concorrenza delle richieste di CPU, memoria e container per i container che eseguono UDF Python.
Per impostazione predefinita, ai container vengono allocate le seguenti risorse:
- La memoria allocata è
512Mi. - La CPU allocata è
1.0vCPU. - Il limite di concorrenza delle richieste del container è
80.
L'esempio seguente crea una UDF Python utilizzando l'elenco di opzioni CREATE FUNCTION per specificare i limiti del container:
Vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.square_area(length FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='square_area', runtime_version='python-3.11', container_memory='CONTAINER_MEMORY', container_cpu=CONTAINER_CPU, container_request_concurrency=CONTAINER_REQUEST_CONCURRENCY) AS r""" def square_area(length): return length*length """; SELECT `PROJECT_ID.DATASET_ID`.square_area(4.5);
Sostituisci quanto segue:
- PROJECT_ID.DATASET_ID: il tuo ID progetto e il tuo ID set di dati.
- CONTAINER_MEMORY: il valore della memoria nel
seguente formato:
<integer_number><unit>. L'unità deve essere uno di questi valori:Mi(MiB),M(MB),Gi(GiB) oG(GB). Ad esempio,2Gi. - CONTAINER_CPU: il valore della CPU. Le UDF Python supportano
valori di CPU frazionari compresi tra
0.33e1.0e valori di CPU non frazionari pari a1,2e4. - CONTAINER_REQUEST_CONCURRENCY: il numero massimo di richieste simultanee per istanza container UDF Python. Il valore deve
essere un numero intero compreso tra
1e1000.
Fai clic su Esegui.
Valori della CPU supportati
Le UDF Python supportano valori frazionari della CPU compresi tra 0.33 e 1.0 e
valori non frazionari della CPU pari a 1, 2 e 4. I container che eseguono UDF Python
possono essere configurati fino a 4 vCPU. Il valore predefinito è 1.0. I valori di input frazionari vengono arrotondati a due cifre decimali prima di essere applicati al contenitore.
Valori di memoria supportati
I contenitori UDF Python supportano i valori di memoria nel seguente formato:
<integer_number><unit>. L'unità deve essere uno di questi valori: Mi, M, Gi,
G. La quantità minima di memoria che puoi configurare è 256Mi. La quantità massima di memoria che puoi configurare è 16Gi.
In base al valore di memoria che scegli, devi specificare anche una quantità di CPU appropriata. La tabella seguente mostra i valori minimi e massimi della CPU per ogni valore di memoria:
| Memoria | CPU minima | CPU massima |
|---|---|---|
Da 256Mi a 512Mi |
0.33 |
2 |
Maggiore di 512Mi e minore o uguale a 1Gi |
0.5 |
2 |
Maggiore di 1Gi e inferiore a 2Gi |
1 |
2 |
Da 2Gi a 4Gi |
1 |
4 |
Maggiore di 4Gi e fino a 8Gi |
2 |
4 |
Maggiore di 8Gi e fino a 16Gi |
4 |
4 |
In alternativa, se hai determinato la quantità di CPU da allocare, puoi utilizzare la tabella seguente per determinare l'intervallo di memoria appropriato:
| CPU | Memoria minima | Memoria massima |
|---|---|---|
Meno di 0.5 |
256Mi |
512Mi |
0.5 a meno di 1 |
256Mi |
1Gi |
1 |
256Mi |
4Gi |
2 |
256Mi |
8Gi |
4 |
2Gi |
16Gi |
Chiamata Google Cloud o servizi online nel codice Python
Una UDF Python accede a un servizio o a un servizio esterno utilizzando il account di servizio connessione alle risorse Cloud. Google Cloud All'account di servizio della connessione devono essere concesse le autorizzazioni per accedere al servizio. Le autorizzazioni richieste variano a seconda del servizio a cui si accede e delle API chiamate dal codice Python.
Se crei una funzione definita dall'utente Python senza utilizzare una connessione alle risorse Cloud, la funzione viene eseguita in un ambiente che blocca l'accesso alla rete. Se la tua UDF accede a servizi online, devi creare la UDF con una connessione a una risorsa cloud. In caso contrario, l'UDF non potrà accedere alla rete finché non viene raggiunto un timeout della connessione interna. Quando utilizzi una connessione a una risorsa Cloud, implementa quanto segue:
Timeout. Quando effettui chiamate di rete all'interno della tua UDF Python, includi sempre un timeout ragionevole. In questo modo, la UDF non si blocca indefinitamente se il servizio esterno risponde lentamente o non è raggiungibile.
Utilizza la gestione degli errori. Inserisci il codice di chiamata di rete in un blocco
try...exceptper gestire correttamente i potenziali errori, come errori di connessione, timeout o codici di stato di errore HTTP. In questo modo, la UDF può restituire un errore significativo o un valore di riserva anziché causare l'interruzione o il mancato funzionamento della query.
L'esempio seguente mostra come accedere al servizio Cloud Translation da una UDF Python. Questo esempio ha due progetti: un progetto denominato
my_query_project in cui crei la funzione definita dall'utente e la connessione alla risorsa cloud e un progetto in cui esegui Cloud Translation denominato
my_translate_project.
Crea una connessione alle risorse Cloud
Innanzitutto, crea una connessione alle risorse Cloud in my_query_project. Per creare
la connessione alla risorsa cloud, segui questi passaggi.
Console
Vai alla pagina BigQuery.
Nel riquadro a sinistra, fai clic su Explorer:

Se non vedi il riquadro a sinistra, fai clic su Espandi riquadro a sinistra per aprirlo.
Nel riquadro Explorer, espandi il nome del progetto e fai clic su Connessioni.
Nella pagina Connessioni, fai clic su Crea connessione.
Per Tipo di connessione, scegli Modelli remoti di Vertex AI, funzioni remote, BigLake e Spanner (risorsa Cloud).
Nel campo ID connessione, inserisci un nome per la connessione.
Per Tipo di località, seleziona una località per la connessione. La connessione deve essere collocata insieme alle altre risorse, ad esempio i set di dati.
Fai clic su Crea connessione.
Fai clic su Vai alla connessione.
Nel riquadro Informazioni sulla connessione, copia l'ID dell'account di servizio da utilizzare in un passaggio successivo.
SQL
Utilizza l'istruzione CREATE CONNECTION:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
Sostituisci quanto segue:
-
CONNECTION_NAME: il nome della connessione nel formatoPROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_IDoCONNECTION_ID. Se il progetto o la località vengono omessi, vengono dedotti dal progetto e dalla località in cui viene eseguita l'istruzione. -
FRIENDLY_NAME(facoltativo): un nome descrittivo per la connessione. -
DESCRIPTION(facoltativo): una descrizione della connessione.
-
Fai clic su Esegui.
Per saperne di più su come eseguire le query, consulta Eseguire una query interattiva.
bq
In un ambiente a riga di comando, crea una connessione:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
Il parametro
--project_idsostituisce il progetto predefinito.Sostituisci quanto segue:
REGION: la tua regione di connessionePROJECT_ID: il tuo Google Cloud ID progettoCONNECTION_ID: un ID per la connessione
Quando crei una risorsa di connessione, BigQuery crea un account di servizio di sistema univoco e lo associa alla connessione.
Risoluzione dei problemi: se viene visualizzato il seguente errore di connessione, aggiorna Google Cloud SDK:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
Recupera e copia l'ID account di servizio da utilizzare in un passaggio successivo:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
L'output è simile al seguente:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Python.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configura l'autenticazione per le librerie client.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di BigQuery per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API BigQuery Node.js.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configura l'autenticazione per le librerie client.
Terraform
Utilizza la risorsa
google_bigquery_connection.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, vedi Configura l'autenticazione per le librerie client.
L'esempio seguente crea una connessione alle risorse Cloud denominata
my_cloud_resource_connection nella regione US:
Per applicare la configurazione Terraform in un progetto Google Cloud , completa i passaggi nelle sezioni seguenti.
Prepara Cloud Shell
- Avvia Cloud Shell.
-
Imposta il progetto Google Cloud predefinito in cui vuoi applicare le configurazioni Terraform.
Devi eseguire questo comando una sola volta per progetto e puoi eseguirlo in qualsiasi directory.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Le variabili di ambiente vengono sostituite se imposti valori espliciti nel file di configurazione Terraform.
Prepara la directory
Ogni file di configurazione Terraform deve avere la propria directory (chiamata anche modulo radice).
-
In Cloud Shell, crea una directory e un nuovo file al suo interno. Il nome file deve avere l'estensione
.tf, ad esempiomain.tf. In questo tutorial, il file è denominatomain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Se stai seguendo un tutorial, puoi copiare il codice campione in ogni sezione o passaggio.
Copia il codice campione nel
main.tfappena creato.(Facoltativo) Copia il codice da GitHub. Questa operazione è consigliata quando lo snippet Terraform fa parte di una soluzione end-to-end.
- Rivedi e modifica i parametri di esempio da applicare al tuo ambiente.
- Salva le modifiche.
-
Inizializza Terraform. Devi eseguire questa operazione una sola volta per directory.
terraform init
(Facoltativo) Per utilizzare l'ultima versione del provider Google, includi l'opzione
-upgrade:terraform init -upgrade
Applica le modifiche
-
Rivedi la configurazione e verifica che le risorse che Terraform creerà o aggiornerà corrispondano alle tue aspettative:
terraform plan
Apporta le correzioni necessarie alla configurazione.
-
Applica la configurazione Terraform eseguendo questo comando e inserendo
yesal prompt:terraform apply
Attendi che Terraform visualizzi il messaggio "Apply complete!".
- Apri il tuo Google Cloud progetto per visualizzare i risultati. Nella console Google Cloud , vai alle risorse nell'interfaccia utente per assicurarti che Terraform le abbia create o aggiornate.
Concedi l'accesso al account di servizio della connessione
Quando configuri le autorizzazioni per la connessione, ti serve l'ID account di servizio che hai copiato in precedenza. Quando crei una risorsa di connessione, BigQuery crea un account di servizio di sistema univoco e lo associa alla connessione.
Per concedere al account di servizio di connessione delle risorse cloud l'accesso ai tuoi progetti, concedi al account di servizio il ruolo Consumer servizi (roles/serviceusage.serviceUsageConsumer) in my_query_project e il ruolo Utente API Cloud Translation (roles/cloudtranslate.user) in my_translate_project.
Console
Vai alla pagina IAM.
Verifica che
my_query_projectsia selezionato.Fai clic su Concedi l'accesso.
Nel campo Nuove entità, inserisci l'ID account di servizio della connessione alla risorsa cloud che hai copiato in precedenza.
Nel campo Seleziona un ruolo, scegli Utilizzo del servizio, quindi seleziona Consumer utilizzo del servizio.
Fai clic su Salva.
Nel selettore dei progetti, scegli
my_translate_project.Vai alla pagina IAM.
Fai clic su Concedi l'accesso.
Nel campo Nuove entità, inserisci l'ID account di servizio della connessione alla risorsa cloud che hai copiato in precedenza.
Nel campo Seleziona un ruolo, scegli Cloud Translation e poi seleziona Utente API Cloud Translation.
Fai clic su Salva.
SQL
Utilizza l'istruzione GRANT statement
per concedere il ruolo Consumer utilizzo servizi (roles/serviceusage.serviceUsageConsumer)
al account di servizio in my_query_project:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
GRANT `roles/serviceusage.serviceUsageConsumer` ON PROJECT `my_query_project` TO "connection:SERVICE_ACCOUNT_ID";
Sostituisci
SERVICE_ACCOUNT_IDcon l'ID service account che hai copiato in precedenza.Fai clic su Esegui.
Per saperne di più su come eseguire le query, consulta Eseguire una query interattiva.
Utilizza l'istruzione GRANT
per concedere il ruolo utente Cloud Translation API (roles/cloudtranslate.user)
in my_translate_project:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, inserisci la seguente istruzione:
GRANT `roles/cloudtranslate.user` ON PROJECT `my_translate_project` TO "connection:SERVICE_ACCOUNT_ID";
Sostituisci
SERVICE_ACCOUNT_IDcon l'ID service account che hai copiato in precedenza.Fai clic su Esegui.
Per saperne di più su come eseguire le query, consulta Eseguire una query interattiva.
Crea una UDF Python che chiama il servizio Cloud Translation
In my_query_project, crea una UDF Python che chiami il servizio Cloud Translation utilizzando la connessione alla risorsa cloud.
Nella console Google Cloud , vai alla pagina BigQuery.
Inserisci la seguente istruzione
CREATE FUNCTIONnell'editor di query:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.translate_to_es(x STRING) RETURNS STRING LANGUAGE python WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID` OPTIONS (entry_point='do_translate', runtime_version='python-3.11', packages=['google-cloud-translate>=3.11', 'google-api-core']) AS r""" from google.api_core.retry import Retry from google.cloud import translate project = "my_translate_project" translate_client = translate.TranslationServiceClient() def do_translate(x : str) -> str: response = translate_client.translate_text( request={ "parent": f"projects/PROJECT_ID/locations/us-central1", "contents": [x], "target_language_code": "es", "mime_type": "text/plain", }, retry=Retry(), ) return response.translations[0].translated_text """; -- Call the UDF. WITH text_table AS (SELECT "Hello" AS text UNION ALL SELECT "Good morning" AS text UNION ALL SELECT "Goodbye" AS text) SELECT text, `PROJECT_ID.DATASET_ID`.translate_to_es(text) AS translated_text FROM text_table;
Sostituisci quanto segue:
PROJECT_ID: l'ID progettoDATASET_ID: l'ID del set di dati.REGION: la regione della connessione.CONNECTION_ID: l'ID connessione.
Fai clic su Esegui.
L'output dovrebbe essere simile al seguente:
+--------------------------+-------------------------------+ | text | translated_text | +--------------------------+-------------------------------+ | Hello | Hola | | Good morning | Buen dia | | Goodbye | Adios | +--------------------------+-------------------------------+
Utilizzare i Controlli di servizio VPC
Le UDF Python ereditano il perimetro di Controlli di servizio VPC del progetto che esegue il job di query. Questo perimetro protegge i tuoi job dall'esfiltrazione di dati e garantisce che le interazioni con i servizi siano sicure.
Quando richiami una UDF Python all'interno del perimetro dei Controlli di servizio VPC, ha la seguente connettività di rete:
- Le UDF Python che non utilizzano una connessione alle risorse Cloud sono completamente isolate. Tutto il traffico in uscita è bloccato.
- Le UDF Python che utilizzano una connessione alle risorse Cloud non possono accedere a internet pubblico. Le UDF Python possono accedere solo ai servizi Google Cloud che supportano i Controlli di servizio VPC. Il traffico in uscita verso qualsiasi destinazione diversa da
restricted.googleapis.comviene bloccato.
Configura le UDF Python per accedere in modo sicuro ai servizi Google Cloud all'interno dei Controlli di servizio VPC
Per accedere ai Google Cloud servizi dalle UDF Python durante l'applicazione dei controlli di servizio VPC, segui questi passaggi:
- Crea la funzione definita dall'utente Python utilizzando la clausola
WITH CONNECTIONdell'istruzione CREATE FUNCTION. - Includi nel perimetro di servizio il progetto BigQuery in cui viene eseguito il job di query e il progetto di servizio di destinazione. In alternativa, configura un bridge del perimetro.
- Aggiungi l'API del servizio di destinazione alla configurazione del perimetro. Ad esempio,
translate.googleapis.comse ti connetti all'API Cloud Translation.
Per ulteriori dettagli sulla configurazione di un perimetro dei Controlli di servizio VPC, consulta:
Best practice
Quando crei UDF Python, segui queste best practice:
- Ottimizza la logica delle query per il batching. Le strutture di query complesse possono disattivare il batch. Ciò forza l'elaborazione lenta riga per riga, il che aumenta significativamente la latenza su set di dati di grandi dimensioni.
- Ottimizza il payload di dati. Le dimensioni delle singole righe possono influire sull'efficienza della funzionalità di batch. Mantieni ogni riga il più piccola possibile per massimizzare il numero di righe che possono essere elaborate in un singolo batch.
- Configura in modo efficiente i limiti dei container. La scalabilità è una funzione di CPU, memoria e concorrenza
delle richieste. Controlla le metriche di monitoraggio per ottimizzare la configurazione del container.
Se l'utilizzo della CPU è elevato, aumenta l'allocazione della CPU utilizzando il limite
container_cpuo riduci la concorrenza delle richieste dei container utilizzando il limitecontainer_request_concurrency. - Quando utilizzi l'ottimizzazione iterativa, inizia con i valori predefiniti. Se le prestazioni non sono ottimali, analizza le metriche di monitoraggio per identificare colli di bottiglia specifici.
- Implementa i timeout delle API. Quando la tua UDF Python accede a internet, imposta un timeout per la chiamata API per evitare comportamenti imprevisti. Un esempio di accesso a internet è la lettura da un bucket Cloud Storage.
Visualizza le metriche UDF Python
Le UDF Python esportano le metriche in Cloud Monitoring. Queste metriche ti aiutano a monitorare vari aspetti dell'integrità operativa e del consumo di risorse della tua UDF, fornendo informazioni sul rendimento e sul comportamento delle istanze UDF.
Tipo di risorsa di monitoraggio
Le metriche per le UDF Python vengono riportate nel seguente tipo di risorsa Cloud Monitoring:
- Tipo:
bigquery.googleapis.com/ManagedRoutineInvocation - Nome visualizzato: Chiamata della routine gestita BigQuery
- Etichette:
resource_container: l'ID del progetto in cui è stato eseguito il job di query.location: la località in cui è stato eseguito il job di query.query_job_id: l'ID del job di query che ha richiamato la UDF Python.routine_project_id: l'ID progetto in cui è archiviata la routine richiamata.routine_dataset_id: l'ID del set di dati in cui è archiviata la routine richiamata.routine_id: l'ID della routine richiamata.
Metriche
Per il tipo di risorsa
bigquery.googleapis.com/ManagedRoutineInvocation sono disponibili le seguenti metriche:
| Metrica | Descrizione | Unità | Tipo di valore |
|---|---|---|---|
bigquery.googleapis.com/managed_routine/python/cpu_utilizations |
Quando viene richiamata una UDF Python, questa metrica mostra la distribuzione dell'utilizzo della CPU in tutte le istanze UDF Python per il job di query. | Un valore percentuale | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/memory_utilizations |
Quando viene richiamata una UDF Python, questa metrica mostra la distribuzione dell'utilizzo della memoria in tutte le istanze UDF Python per il job di query. | Un valore percentuale | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/max_request_concurrencies |
Questa metrica mostra la distribuzione del numero massimo di richieste in parallelo pubblicate da ogni istanza di funzione definita dall'utente Python. | Conteggio | DISTRIBUTION |
Visualizza metriche
Per visualizzare le metriche per le UDF Python, scegli una delle opzioni nelle sezioni seguenti.
Dettagli job
Per visualizzare le metriche delle UDF Python per un job di query specifico:
Vai alla pagina BigQuery.
Fai clic su Cronologia dei job.
Nella colonna ID job, fai clic sull'ID job della query.
Nella pagina Dettagli job di query, fai clic su Dashboard Cloud Monitoring. Questo link mostra una dashboard filtrata per visualizzare le metriche UDF Python per il job.
Esplora metriche
Per visualizzare le metriche delle UDF Python in Metrics Explorer, segui questi passaggi:
Vai alla pagina Esplora metriche di Cloud Monitoring.
Vai a Esplora metriche
Fai clic su Seleziona una metrica e, nel campo Filtro, digita
BigQuery Managed Routine Invocationobigquery.googleapis.com/ManagedRoutineInvocation.Scegli Bigquery Managed Routine > Managed_routine.
Fai clic su una delle metriche disponibili, ad esempio:
- Utilizzo CPU istanza
- Utilizzo della memoria dell'istanza
- Numero max richieste in parallelo
Fai clic su Applica.
Per impostazione predefinita, le metriche vengono visualizzate in un grafico.
Puoi filtrare e raggruppare le metriche utilizzando le etichette definite in Tipi di risorse di monitoraggio. Per filtrare le metriche:
Nel campo Filtro, scegli un tipo di risorsa come
query_job_idoroutine_id.Nel campo Valore, inserisci l'ID job o l'ID routine oppure scegli un valore dall'elenco.
Dashboard di Cloud Monitoring
Per visualizzare le metriche delle UDF Python utilizzando le dashboard di monitoraggio, segui questi passaggi:
Vai alla pagina Dashboard di Cloud Monitoring.
Fai clic sulla dashboard Monitoraggio query della routine gestita BigQuery.
Questa dashboard fornisce una panoramica delle metriche chiave delle tue funzioni definite dall'utente.
Per filtrare questa dashboard:
Fai clic su Filtra.
Nell'elenco Filtra per risorsa, scegli un'opzione come ID progetto, posizione, ID routine o ID job.
Località supportate
Le UDF Python sono supportate in tutte le località multiregionali e regionali BigQuery.
Prezzi
I costi delle UDF Python vengono fatturati utilizzando lo SKU dei servizi BigQuery.
Gli addebiti includono:
Creazione o ricreazione dell'immagine container della funzione definita dall'utente. Questo addebito è proporzionale alla durata necessaria per creare l'immagine corrispondente con il codice cliente e le dipendenze.
- Se utilizzi l'API Routines, la durata dell'ultima build è nel campo
BuildStatus. Puoi anche visualizzare la durata della build nella colonnaBuildStatusdellaINFORMATION_SCHEMA.ROUTINESvista. - Per visualizzare il costo totale delle build per progetto, puoi filtrare il report sulla fatturazione utilizzando quanto segue:
- Chiave:
goog-bq-feature-type - Valore:
MANAGED_ROUTINE_BUILD
- Chiave:
- Se utilizzi l'API Routines, la durata dell'ultima build è nel campo
Ai clienti che utilizzano UDF Python viene addebitato anche il costo di chiamata di una UDF Python. Questo addebito è proporzionale alla quantità di calcolo e memoria consumati quando viene richiamata la UDF Python.
- Per visualizzare i costi delle UDF Python per query, puoi eseguire query sul campo
ExternalServiceCostsutilizzando l'API Job. Puoi anche visualizzare i costi per query visualizzando la colonnaexternal_service_costsnella vistaINFORMATION_SCHEMA.JOBSe applicando il seguente filtro:'external_service_costs.external_service="MANAGED_ROUTINE_EXECUTION"'. - Per visualizzare il costo totale di esecuzione delle UDF Python per progetto, puoi
filtrare il report sulla fatturazione utilizzando quanto segue:
- Chiave:
goog-bq-feature-type - Valore:
MANAGED_ROUTINE_EXECUTION
- Chiave:
- Per visualizzare i costi delle UDF Python per query, puoi eseguire query sul campo
Se le UDF Python generano traffico in uscita dalla rete esterna o da internet, viene visualizzato anche un addebito per il traffico in uscita da internet del livello Premium in base agli SKU per il traffico in uscita di BigQuery.
Quote
Consulta Quote e limiti delle UDF.