
Bekerja dengan fungsi yang ditentukan pengguna di Python
Fungsi yang ditentukan pengguna (UDF) Python memungkinkan Anda menerapkan fungsi skalar di Python dan menggunakannya dalam kueri SQL. UDF Python mirip dengan UDF SQL dan JavaScript, tetapi dengan kemampuan tambahan. UDF Python memungkinkan Anda menginstal library pihak ketiga dari Python Package Index (PyPI) dan memungkinkan Anda mengakses layanan eksternal menggunakan koneksi resource Cloud.
UDF Python dibuat dan dijalankan di resource yang dikelola BigQuery.
Batasan
python-3.11adalah satu-satunya runtime yang didukung.- Anda tidak dapat membuat UDF Python sementara.
- Anda tidak dapat menggunakan UDF Python dengan tampilan terwujud.
- Hasil kueri yang memanggil UDF Python tidak di-cache karena nilai yang ditampilkan UDF Python selalu dianggap non-deterministik.
- Assured Workloads tidak didukung.
- Jenis data ini tidak didukung:
JSON,RANGE,INTERVAL, danGEOGRAPHY. - Container yang menjalankan UDF Python hanya dapat dikonfigurasi hingga 4 vCPU dan 16 GiB.
- Mengenkripsi kode UDF Python dengan Kunci enkripsi yang dikelola pelanggan (CMEK) tidak didukung.
- UDF Python mendukung Kontrol Layanan VPC, tetapi jaringan VPC tidak didukung.
Peran yang diperlukan
Peran IAM yang diperlukan didasarkan pada apakah Anda adalah pemilik UDF Python atau pengguna UDF Python.
Pemilik UDF
Pemilik UDF Python biasanya membuat atau memperbarui UDF. Peran tambahan juga diperlukan jika Anda membuat UDF Python yang mereferensikan koneksi resource Cloud.
Koneksi ini hanya diperlukan jika UDF Anda menggunakan
klausa WITH CONNECTION untuk mengakses
layanan eksternal.
Untuk mendapatkan izin yang Anda perlukan untuk membuat atau memperbarui UDF Python, minta administrator untuk memberi Anda peran IAM berikut:
- BigQuery Data Editor (
roles/bigquery.dataEditor) di set data - BigQuery Job User (
roles/bigquery.jobUser) di project - BigQuery Connection Admin (
roles/bigquery.connectionAdmin) di project
Untuk mengetahui informasi selengkapnya tentang pemberian peran, lihat Mengelola akses ke project, folder, dan organisasi.
Peran bawaan ini berisi izin yang diperlukan untuk membuat atau memperbarui UDF Python. Untuk melihat izin yang benar-benar diperlukan, perluas bagian Izin yang diperlukan:
Izin yang diperlukan
Izin berikut diperlukan untuk membuat atau memperbarui UDF Python:
-
Buat UDF Python menggunakan pernyataan
CREATE FUNCTION:bigquery.routines.createpada set data -
Perbarui UDF Python menggunakan pernyataan
CREATE FUNCTION:bigquery.routines.updatepada set data -
Menjalankan tugas kueri pernyataan
CREATE FUNCTION:bigquery.jobs.createdi project -
Buat koneksi resource Cloud baru:
bigquery.connections.createdi project -
Gunakan koneksi dalam pernyataan
CREATE FUNCTION:bigquery.connections.delegatepada koneksi
Anda mungkin juga bisa mendapatkan izin ini dengan peran khusus atau peran bawaan lainnya.
Untuk mengetahui informasi selengkapnya tentang peran di BigQuery, lihat Peran IAM yang telah ditetapkan.
Pengguna UDF
Pengguna UDF Python memanggil UDF yang dibuat oleh orang lain. Peran tambahan juga diperlukan jika Anda memanggil UDF Python yang mereferensikan koneksi resource Cloud.
Untuk mendapatkan izin yang Anda perlukan untuk memanggil UDF Python yang dibuat oleh orang lain, minta administrator untuk memberi Anda peran IAM berikut:
- Pengguna BigQuery (
roles/bigquery.user) di project - BigQuery Data Viewer (
roles/bigquery.dataViewer) pada set data - BigQuery Connection User (
roles/bigquery.connectionUser) pada koneksi
Untuk mengetahui informasi selengkapnya tentang pemberian peran, lihat Mengelola akses ke project, folder, dan organisasi.
Peran bawaan ini berisi izin yang diperlukan untuk memanggil UDF Python yang dibuat oleh orang lain. Untuk melihat izin yang benar-benar diperlukan, perluas bagian Izin yang diperlukan:
Izin yang diperlukan
Izin berikut diperlukan untuk memanggil UDF Python yang dibuat oleh orang lain:
-
Untuk menjalankan tugas kueri yang mereferensikan UDF Python:
bigquery.jobs.createdi project -
Untuk memanggil UDF Python yang dibuat oleh orang lain:
bigquery.routines.getpada set data -
Untuk menjalankan UDF Python yang mereferensikan koneksi resource Cloud:
bigquery.connections.usepada koneksi
Anda mungkin juga bisa mendapatkan izin ini dengan peran khusus atau peran bawaan lainnya.
Untuk mengetahui informasi selengkapnya tentang peran di BigQuery, lihat Peran IAM yang telah ditetapkan.
Membuat UDF Python persisten
Ikuti aturan berikut saat Anda membuat UDF Python:
Isi UDF Python harus berupa literal string yang dikutip yang merepresentasikan kode Python. Untuk mempelajari lebih lanjut literal string yang dikutip, lihat Format untuk literal yang dikutip.
Isi UDF Python harus menyertakan fungsi Python yang digunakan dalam argumen
entry_pointdalam daftar opsi UDF Python.Versi runtime Python harus ditentukan dalam opsi
runtime_version. Satu-satunya versi runtime Python yang didukung adalahpython-3.11. Untuk daftar lengkap opsi yang tersedia, lihat Daftar opsi fungsi untuk pernyataanCREATE FUNCTION.
Untuk membuat UDF Python persisten, gunakan pernyataan CREATE FUNCTION
tanpa kata kunci TEMP atau TEMPORARY. Untuk menghapus UDF Python persisten,
gunakan pernyataan DROP FUNCTION.
Contoh
Untuk melihat contoh pembuatan UDF Python persisten, pilih salah satu opsi berikut:
Konsol
Contoh berikut membuat persistent Python UDF bernama multiplyInputs
dan memanggil UDF dari dalam pernyataan SELECT:
Buka halaman BigQuery.
Di editor kueri, masukkan pernyataan
CREATE FUNCTIONberikut:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyInputs(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="multiply") AS r''' def multiply(x, y): return x * y '''; -- Call the Python UDF. WITH numbers AS (SELECT 1 AS x, 5 as y UNION ALL SELECT 2 AS x, 10 as y UNION ALL SELECT 3 as x, 15 as y) SELECT x, y, `PROJECT_ID.DATASET_ID`.multiplyInputs(x, y) AS product FROM numbers;
Ganti PROJECT_ID.DATASET_ID dengan project ID dan ID set data Anda.
Klik Run.
Contoh ini menghasilkan output berikut:
+-----+-----+--------------+ | x | y | product | +-----+-----+--------------+ | 1 | 5 | 5.0 | | 2 | 10 | 20.0 | | 3 | 15 | 45.0 | +-----+-----+--------------+
BigQuery DataFrames
Contoh berikut menggunakan BigQuery DataFrames untuk mengubah fungsi kustom menjadi UDF Python:
Status build container
Saat Anda membuat UDF Python menggunakan pernyataan CREATE FUNCTION, BigQuery akan membuat atau mengupdate image container yang didasarkan pada image dasar. Container dibangun di image dasar menggunakan kode Anda dan dependensi paket yang ditentukan.
Pembuatan penampung adalah proses yang berjalan lama. Kueri pertama setelah Anda menjalankan
pernyataan CREATE FUNCTION menunggu hingga build gambar selesai. Jika tidak ada dependensi eksternal, image penampung biasanya dibuat dalam waktu kurang dari satu menit.
Ukuran semua penampung UDF Python per project dan per region dibatasi hingga total 10 GiB. Untuk mengetahui informasi selengkapnya, lihat Batas fungsi yang ditentukan pengguna untuk UDF persisten. Build penampung Anda akan gagal jika project Anda telah mencapai kuota.
Untuk melihat status build penampung, pilih salah satu opsi berikut:
Konsol
Buka halaman Studio BigQuery.
Di panel kiri, luaskan project Anda, lalu klik Datasets.
Klik link untuk membuka set data yang berisi UDF Python Anda.
Di halaman set data, klik tab Rutinitas.
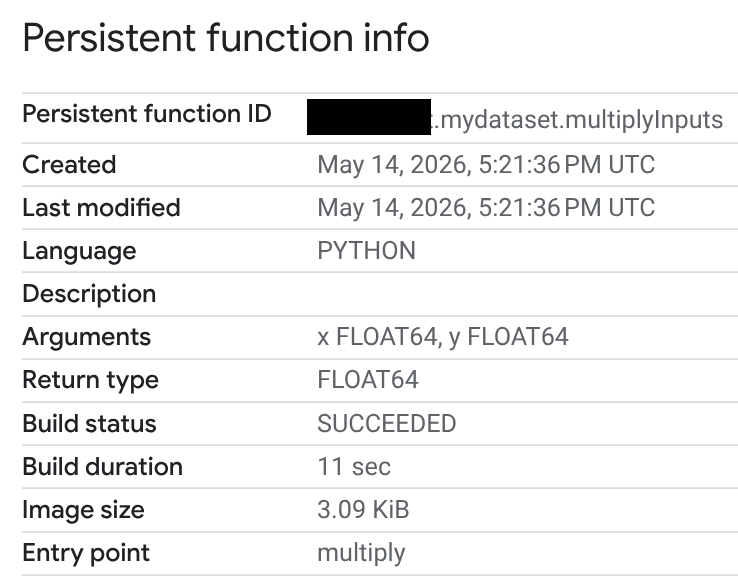
Di kolom Routine ID, klik UDF Python Anda.
Di halaman Persistent function info, Anda dapat melihat status build, durasi build, dan ukuran gambar. Status build adalah salah satu dari berikut:
- Dalam proses
- Berhasil
- Gagal
Jika build gagal, halaman informasi fungsi akan memberikan pesan error mendetail sehingga Anda dapat memecahkan masalah seperti error sintaksis atau masalah penginstalan paket eksternal.
SQL
Untuk membuat kueri kolom status build di tampilan INFORMATION_SCHEMA.ROUTINES,
ikuti langkah-langkah berikut:
Buka halaman Studio BigQuery.
Beralih ke editor kueri atau klik SQL query.
Masukkan kueri berikut untuk mengambil kolom
BUILD_STATUSdari tabel virtualINFORMATION_SCHEMA.ROUTINES. KolomBUILD_STATUSadalah jenisSTRUCTdi GoogleSQL:SELECT build_status.* FROM `PROJECT_ID.DATASET_ID`.INFORMATION_SCHEMA.ROUTINES;Ganti PROJECT_ID.DATASET_ID dengan project ID dan ID set data Anda.
Output-nya akan terlihat seperti berikut. Kolom error tidak ada:
+---------------+--------------------------------+------------------------+------------------+ | build_state | build_state_update_time | build_duration_seconds | image_size_bytes | +---------------+--------------------------------+------------------------+------------------+ | SUCCEEDED | 2026-05-14 17:21:49.736000 UTC | 11 | 3167 | +---------------+--------------------------------+------------------------+------------------+
API
Lihat status build penampung menggunakan RoutineBuildStatus di API.
Membuat UDF Python tervektorisasi
Anda dapat menerapkan UDF Python untuk memproses batch baris, bukan satu baris, dengan menggunakan vektorisasi. Vektorisasi dapat meningkatkan performa kueri. Anda dapat membuat UDF tervektor menggunakan Pandas atau Apache Arrow.
Untuk mengontrol perilaku batching, tentukan jumlah maksimum baris dalam setiap batch
menggunakan opsi max_batching_rows dalam daftar opsi CREATE OR REPLACE FUNCTION. Jika Anda menentukan max_batching_rows, BigQuery akan menentukan jumlah baris dalam batch, hingga batas max_batching_rows.
Jika max_batching_rows tidak ditentukan, jumlah baris yang akan di-batch akan ditentukan secara otomatis.
Menggunakan Pandas
UDF Python tervektorisasi memiliki satu argumen pandas.DataFrame yang harus
dianotasi. Argumen pandas.DataFrame memiliki jumlah kolom yang sama dengan
parameter UDF Python yang ditentukan dalam pernyataan CREATE FUNCTION. Nama kolom dalam argumen pandas.DataFrame memiliki nama yang sama dengan parameter UDF.
Fungsi Anda harus menampilkan pandas.Series atau pandas.DataFrame satu kolom
dengan jumlah baris yang sama dengan input.
Contoh berikut membuat UDF Python tervektorisasi bernama multiplyInputs
dengan dua parameter—x dan y:
Buka halaman BigQuery.
Di editor kueri, masukkan pernyataan
CREATE FUNCTIONberikut:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorized(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="vectorized_multiply") AS r''' import pandas as pd def vectorized_multiply(df: pd.DataFrame): return df['x'] * df['y'] ''';
Ganti PROJECT_ID.DATASET_ID dengan project ID dan ID set data Anda.
Memanggil UDF sama seperti pada contoh sebelumnya.
Klik Run.
Menggunakan Apache Arrow
Contoh berikut menggunakan antarmuka
RecordBatch Apache Arrow. Saat Anda menggunakan antarmuka RecordBatch, fungsi meneruskan batch baris kolom dengan panjang yang sama ke titik entri.
Contoh berikut menggunakan Apache Arrow untuk membuat UDF Python tervektorisasi bernama multiplyVectorizedArrow.
Buka halaman BigQuery.
Di editor kueri, masukkan pernyataan
CREATE FUNCTIONberikut:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorizedArrow(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS( runtime_version="python-3.11", entry_point="vectorized_multiply_arrow" ) AS r''' import pyarrow as pa import pyarrow.compute as pc def vectorized_multiply_arrow(batch: pa.RecordBatch): # Access columns directly from the Arrow RecordBatch x = batch.column('x') y = batch.column('y') # Use pyarrow.compute for vectorized operations return pc.multiply(x, y) ''';
Ganti PROJECT_ID.DATASET_ID dengan project ID dan ID set data Anda.
Memanggil UDF sama seperti pada contoh sebelumnya.
Klik Run.
Memanggil UDF Python
Jika memiliki izin untuk memanggil UDF Python, Anda dapat memanggilnya seperti
fungsi lainnya. Untuk menggunakan fungsi yang ditentukan dalam project lain, gunakan nama yang sepenuhnya memenuhi syarat untuk fungsi tersebut. Misalnya, untuk memanggil fungsi ekstraksi XML
bernama cw_xml_extract
di project lain, selesaikan langkah-langkah berikut.
Konsol
Buka halaman BigQuery.
Di editor kueri, masukkan contoh berikut:
SELECT `PROJECT_ID.DATASET_ID`.`cw_xml_extract`(xml, '//title/text()') AS `title` FROM UNNEST([ STRUCT('''<book id="1"> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> </book>''' AS xml), STRUCT('''<book id="2"> <title>1984</title> <author>George Orwell</author> </book>''' AS xml), STRUCT('''<book id="3"> <title>Brave New World</title> <author>Aldous Huxley</author> </book>''' AS xml) ])Klik Run.
Contoh ini menghasilkan output berikut:
+--------------------------+ | title | +--------------------------+ | The Great Gatsby | | 1984 | | Brave New World | +--------------------------+
BigQuery DataFrames
Contoh berikut menggunakan metode BigQuery
DataFrames
sql_scalar,
read_gbq_function,
dan
apply
untuk memanggil UDF Python:
Jenis data UDF Python yang didukung
Tabel berikut menentukan pemetaan antara jenis data BigQuery, jenis data Python, dan jenis data Pandas:
| Jenis data BigQuery | Jenis data bawaan Python yang digunakan oleh UDF standar | Jenis data pandas yang digunakan oleh UDF tervektorisasi | Jenis data PyArrow yang digunakan untuk ARRAY dan STRUCT di UDF tervektorisasi |
|---|---|---|---|
BOOL |
bool |
BooleanDtype |
DataType(bool) |
INT64 |
int |
Int64Dtype |
DataType(int64) |
FLOAT64 |
float |
FloatDtype |
DataType(double) |
STRING |
str |
StringDtype |
DataType(string) |
BYTES |
bytes |
binary[pyarrow] |
DataType(binary) |
TIMESTAMP |
Parameter fungsi: Nilai yang ditampilkan fungsi: |
Parameter fungsi: Nilai yang ditampilkan fungsi: |
TimestampType(timestamp[us]), dengan zona waktu |
DATE |
datetime.date |
date32[pyarrow] |
DataType(date32[day]) |
TIME |
datetime.time |
time64[pyarrow] |
Time64Type(time64[us]) |
DATETIME |
datetime.datetime (tanpa zona waktu) |
timestamp[us][pyarrow] |
TimestampType(timestamp[us]), tanpa zona waktu |
ARRAY |
list |
list<...>[pyarrow], dengan jenis data elemen adalah pandas.ArrowDtype |
ListType |
STRUCT |
dict |
struct<...>[pyarrow], dengan jenis data kolom adalah pandas.ArrowDtype |
StructType |
Versi runtime yang didukung
UDF Python BigQuery mendukung runtime python-3.11. Versi
Python ini menyertakan beberapa paket bawaan tambahan. Untuk library
sistem, periksa image dasar runtime.
| Versi runtime | Versi Python | Mencakup |
|---|---|---|
| python-3.11 | Python 3.11 | numpy 1.26.3 pyarrow 14.0.2 pandas 2.1.4 python-dateutil 2.8.2 absl-py 2.0.0 pytz 2023.3.post1 tzdata 2023.4 six 1.16.0 |
Menggunakan paket pihak ketiga
Anda dapat menggunakan daftar opsi CREATE FUNCTION untuk menggunakan modul selain
yang disediakan oleh library standar Python dan paket yang sudah diinstal.
Anda dapat menginstal paket dari Python Package Index (PyPI), atau Anda dapat mengimpor file Python dari Cloud Storage.
Menginstal paket dari indeks paket Python
Saat menginstal paket, Anda harus memberikan nama paket, dan Anda dapat secara opsional memberikan versi paket menggunakan penentu versi paket Python.
Jika paket ada di runtime, paket tersebut akan digunakan kecuali jika versi tertentu ditentukan dalam daftar opsi CREATE FUNCTION. Jika versi paket
tidak ditentukan, dan paket tidak ada di runtime, versi
terbaru yang tersedia akan digunakan. Hanya paket dengan format biner roda yang didukung.
Contoh berikut menunjukkan cara membuat UDF Python yang menginstal paket
scipy menggunakan daftar opsi CREATE OR REPLACE FUNCTION:
Buka halaman BigQuery.
Di editor kueri, masukkan pernyataan
CREATE FUNCTIONberikut:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.area(radius FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='area_handler', runtime_version='python-3.11', packages=['scipy==1.15.3']) AS r""" import scipy def area_handler(radius): return scipy.constants.pi*radius*radius """; SELECT `PROJECT_ID.DATASET_ID`.area(4.5);
Ganti PROJECT_ID.DATASET_ID dengan project ID dan ID set data Anda.
Klik Run.
Mengimpor file Python tambahan sebagai library
Anda dapat memperluas UDF Python menggunakan Daftar opsi fungsi dengan mengimpor file Python dari Cloud Storage.
Dalam kode Python UDF, Anda dapat mengimpor file Python dari
Cloud Storage sebagai modul menggunakan pernyataan impor yang diikuti dengan
jalur ke objek Cloud Storage. Misalnya, jika Anda mengimpor
gs://BUCKET_NAME/path/to/lib1.py, pernyataan impor Anda adalah import
path.to.lib1.
Nama file Python harus berupa ID Python. Setiap nama folder dalam
nama objek (setelah /) harus berupa ID Python yang valid. Dalam rentang ASCII (U+0001..U+007F), karakter berikut dapat digunakan dalam
ID:
- Huruf besar dan huruf kecil A hingga Z.
- Garis bawah.
- Angka nol hingga sembilan, tetapi angka tidak boleh muncul sebagai karakter pertama dalam ID.
Contoh berikut menunjukkan cara membuat UDF Python yang mengimpor paket library klien
lib1.py dari bucket Cloud Storage bernama
my_bucket:
Buka halaman BigQuery.
Di editor kueri, masukkan pernyataan
CREATE FUNCTIONberikut:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.myFunc(a FLOAT64, b STRING) RETURNS STRING LANGUAGE python OPTIONS ( entry_point='compute', runtime_version='python-3.11', library=['gs://BUCKET_NAME/PATH/lib1.py']) AS r""" import path.to.lib1 as lib1 def compute(a, b): # doInterestingStuff is a function defined in # gs://BUCKET_NAME/PATH/lib1.py return lib1.doInterestingStuff(a, b); """;
Ganti kode berikut:
- PROJECT_ID: project ID Anda.
- DATASET_ID: ID set data Anda.
- BUCKET_NAME: nama bucket Cloud Storage yang berisi
lib1.py. - PATH: jalur ke bucket Cloud Storage.
Klik Run.
Mengonfigurasi batas container untuk UDF Python
Anda dapat menggunakan daftar opsi CREATE FUNCTION untuk menentukan batas serentak permintaan CPU, memori, dan container untuk container yang menjalankan UDF Python.
Secara default, container dialokasikan resource berikut:
- Memori yang dialokasikan adalah
512Mi. - CPU yang dialokasikan adalah
1.0vCPU. - Batas serentak permintaan container adalah
80.
Contoh berikut membuat UDF Python menggunakan daftar opsi CREATE FUNCTION
untuk menentukan batas container:
Buka halaman BigQuery.
Di editor kueri, masukkan pernyataan
CREATE FUNCTIONberikut:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.square_area(length FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='square_area', runtime_version='python-3.11', container_memory='CONTAINER_MEMORY', container_cpu=CONTAINER_CPU, container_request_concurrency=CONTAINER_REQUEST_CONCURRENCY) AS r""" def square_area(length): return length*length """; SELECT `PROJECT_ID.DATASET_ID`.square_area(4.5);
Ganti kode berikut:
- PROJECT_ID.DATASET_ID: project ID dan ID set data Anda.
- CONTAINER_MEMORY: nilai memori dalam
format berikut:
<integer_number><unit>. Unit harus berupa salah satu nilai berikut:Mi(MiB),M(MB),Gi(GiB), atauG(GB). Misalnya,2Gi. - CONTAINER_CPU: nilai CPU. UDF Python mendukung nilai CPU fraksional antara
0.33dan1.0serta nilai CPU non-fraksional1,2, dan4. - CONTAINER_REQUEST_CONCURRENCY: jumlah maksimum
permintaan serentak per instance container UDF Python. Nilai harus
berupa bilangan bulat dari
1hingga1000.
Klik Run.
Nilai CPU yang didukung
UDF Python mendukung nilai CPU fraksional antara 0.33 dan 1.0 serta
nilai CPU non-fraksional 1, 2, dan 4. Container yang menjalankan UDF Python dapat dikonfigurasi hingga 4 vCPU. Nilai defaultnya adalah 1.0. Nilai input
pecahan dibulatkan menjadi dua tempat desimal sebelum diterapkan ke
penampung.
Nilai memori yang didukung
Penampung UDF Python mendukung nilai memori dalam format berikut:
<integer_number><unit>. Unit harus berupa salah satu nilai berikut: Mi, M, Gi,
G. Jumlah minimum memori yang dapat Anda konfigurasi adalah 256Mi. Jumlah memori maksimum yang dapat Anda konfigurasi adalah 16Gi.
Berdasarkan nilai memori yang Anda pilih, Anda juga harus menentukan jumlah CPU yang sesuai. Tabel berikut menunjukkan nilai CPU minimum dan maksimum untuk setiap nilai memori:
| Memori | CPU minimum | CPU Maksimum |
|---|---|---|
256Mi ke 512Mi |
0.33 |
2 |
Lebih besar dari 512Mi dan kurang dari atau sama dengan 1Gi |
0.5 |
2 |
Lebih besar dari 1Gi dan lebih kecil dari 2Gi |
1 |
2 |
2Gi ke 4Gi |
1 |
4 |
Lebih dari 4Gi dan hingga 8Gi |
2 |
4 |
Lebih dari 8Gi dan hingga 16Gi |
4 |
4 |
Atau, jika Anda telah menentukan jumlah CPU yang dialokasikan, Anda dapat menggunakan tabel berikut untuk menentukan rentang memori yang sesuai:
| CPU | Memori minimum | Memori maksimum |
|---|---|---|
Kurang dari 0.5 |
256Mi |
512Mi |
0.5 menjadi kurang dari 1 |
256Mi |
1Gi |
1 |
256Mi |
4Gi |
2 |
256Mi |
8Gi |
4 |
2Gi |
16Gi |
Memanggil Google Cloud atau layanan online dalam kode Python
UDF Python mengakses layanan atau layanan eksternal menggunakan akun layanan koneksi resource Cloud. Google Cloud Akun layanan koneksi harus diberi izin untuk mengakses layanan. Izin yang diperlukan bervariasi, bergantung pada layanan yang diakses dan API yang dipanggil dari kode Python Anda.
Jika Anda membuat UDF Python tanpa menggunakan koneksi resource Cloud, fungsi akan dieksekusi di lingkungan yang memblokir akses jaringan. Jika UDF Anda mengakses layanan online, Anda harus membuat UDF dengan koneksi resource Cloud. Jika tidak, UDF akan diblokir untuk mengakses jaringan hingga batas waktu koneksi internal tercapai. Saat Anda menggunakan koneksi resource Cloud, terapkan hal berikut:
Waktu tunggu. Saat Anda melakukan panggilan jaringan dalam UDF Python, selalu sertakan waktu tunggu yang wajar. Hal ini mencegah UDF berhenti berfungsi tanpa batas waktu jika layanan eksternal lambat merespons atau tidak dapat dijangkau.
Gunakan Penanganan Error. Bungkus kode panggilan jaringan Anda dalam blok
try...exceptuntuk menangani potensi error dengan baik, seperti error koneksi, waktu tunggu habis, atau kode status kegagalan HTTP. Hal ini memungkinkan UDF Anda menampilkan error yang bermakna atau nilai penggantian, bukan menyebabkan kueri gagal atau berhenti merespons.
Contoh berikut menunjukkan cara mengakses layanan Cloud Translation
dari UDF Python. Contoh ini memiliki dua project—project bernama my_query_project tempat Anda membuat UDF dan koneksi resource Cloud, serta project tempat Anda menjalankan Cloud Translation bernama my_translate_project.
Membuat koneksi resource Cloud
Pertama, Anda membuat koneksi resource Cloud di my_query_project. Untuk membuat koneksi resource cloud, ikuti langkah-langkah berikut.
Konsol
Buka halaman BigQuery.
Di panel kiri, klik Explorer:

Jika Anda tidak melihat panel kiri, klik Luaskan panel kiri untuk membuka panel.
Di panel Explorer, luaskan nama project Anda, lalu klik Connections.
Di halaman Koneksi, klik Buat koneksi.
Untuk Connection type, pilih Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource).
Di kolom Connection ID, masukkan nama untuk koneksi Anda.
Untuk Location type, pilih lokasi untuk koneksi Anda. Koneksi harus ditempatkan bersama resource Anda yang lain seperti set data.
Klik Create connection.
Klik Go to connection.
Di panel Connection info, salin ID akun layanan untuk digunakan pada langkah berikutnya.
SQL
Gunakan pernyataan CREATE CONNECTION:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, masukkan pernyataan berikut:
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
Ganti kode berikut:
-
CONNECTION_NAME: nama koneksi dalam formatPROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_ID, atauCONNECTION_ID. Jika project atau lokasi dihilangkan, maka project atau lokasi tersebut disimpulkan dari project dan lokasi tempat pernyataan dijalankan. -
FRIENDLY_NAME(opsional): nama deskriptif untuk koneksi. -
DESCRIPTION(opsional): deskripsi koneksi.
-
Klik Run.
Untuk mengetahui informasi selengkapnya tentang cara menjalankan kueri, lihat artikel Menjalankan kueri interaktif.
bq
Di lingkungan command line, buat koneksi:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
Parameter
--project_idakan mengganti project default.Ganti kode berikut:
REGION: region koneksi AndaPROJECT_ID: Project ID Google Cloud AndaCONNECTION_ID: ID untuk koneksi Anda
Saat Anda membuat resource koneksi, BigQuery akan membuat akun layanan sistem unik dan mengaitkannya dengan koneksi.
Pemecahan masalah: Jika Anda mendapatkan error koneksi berikut, update Google Cloud SDK:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
Ambil dan salin ID akun layanan untuk digunakan pada langkah berikutnya:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
Outputnya mirip dengan hal berikut ini:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Python
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Python di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Python API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Node.js
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan Node.js di Panduan memulai BigQuery menggunakan library klien. Untuk mengetahui informasi selengkapnya, lihat Dokumentasi referensi BigQuery Node.js API.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Terraform
Gunakan resource google_bigquery_connection.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk library klien.
Contoh berikut membuat koneksi resource Cloud bernama
my_cloud_resource_connection di region US:
Untuk menerapkan konfigurasi Terraform di project, selesaikan langkah-langkah di bagian berikut. Google Cloud
Menyiapkan Cloud Shell
- Luncurkan Cloud Shell.
-
Tetapkan project Google Cloud default tempat Anda ingin menerapkan konfigurasi Terraform.
Anda hanya perlu menjalankan perintah ini sekali per project, dan dapat dijalankan di direktori mana pun.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Variabel lingkungan akan diganti jika Anda menetapkan nilai eksplisit dalam file konfigurasi Terraform.
Menyiapkan direktori
Setiap file konfigurasi Terraform harus memiliki direktorinya sendiri (juga disebut modul root).
-
Di Cloud Shell, buat direktori dan file baru di dalam direktori tersebut. Nama file harus memiliki
ekstensi
.tf—misalnyamain.tf. Dalam tutorial ini, file ini disebut sebagaimain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Jika mengikuti tutorial, Anda dapat menyalin kode contoh di setiap bagian atau langkah.
Salin kode contoh ke dalam
main.tfyang baru dibuat.Atau, salin kode dari GitHub. Tindakan ini direkomendasikan jika cuplikan Terraform adalah bagian dari solusi menyeluruh.
- Tinjau dan ubah contoh parameter untuk diterapkan pada lingkungan Anda.
- Simpan perubahan Anda.
-
Lakukan inisialisasi Terraform. Anda hanya perlu melakukan ini sekali per direktori.
terraform init
Secara opsional, untuk menggunakan versi penyedia Google terbaru, sertakan opsi
-upgrade:terraform init -upgrade
Menerapkan perubahan
-
Tinjau konfigurasi dan pastikan resource yang akan dibuat atau
diupdate oleh Terraform sesuai yang Anda inginkan:
terraform plan
Koreksi konfigurasi jika diperlukan.
-
Terapkan konfigurasi Terraform dengan menjalankan perintah berikut dan memasukkan
yespada prompt:terraform apply
Tunggu hingga Terraform menampilkan pesan "Apply complete!".
- Buka Google Cloud project Anda untuk melihat hasilnya. Di konsol Google Cloud , buka resource Anda di UI untuk memastikan bahwa Terraform telah membuat atau mengupdatenya.
Memberikan akses ke akun layanan koneksi
Anda memerlukan ID akun layanan yang Anda salin sebelumnya saat mengonfigurasi izin untuk koneksi. Saat Anda membuat resource koneksi, BigQuery akan membuat akun layanan sistem unik dan mengaitkannya dengan koneksi.
Untuk memberikan akses akun layanan koneksi resource Cloud ke project Anda, berikan peran Service Usage Consumer
(roles/serviceusage.serviceUsageConsumer) kepada akun layanan di my_query_project dan peran Pengguna Cloud Translation API (roles/cloudtranslate.user) di
my_translate_project.
Konsol
Buka halaman IAM.
Pastikan
my_query_projectdipilih.Klik Berikan Akses.
Di kolom New principals, masukkan ID akun layanan koneksi resource Cloud yang Anda salin sebelumnya.
Di kolom Select a role, pilih Service usage, lalu pilih Service usage consumer.
Klik Simpan.
Di pemilih project, pilih
my_translate_project.Buka halaman IAM.
Klik Berikan Akses.
Di kolom New principals, masukkan ID akun layanan koneksi resource Cloud yang Anda salin sebelumnya.
Di kolom Pilih peran, pilih Cloud Translation, lalu pilih Pengguna Cloud Translation API.
Klik Simpan.
SQL
Gunakan pernyataan GRANT
untuk memberikan peran Service usage consumer (roles/serviceusage.serviceUsageConsumer)
ke akun layanan di my_query_project:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, masukkan pernyataan berikut:
GRANT `roles/serviceusage.serviceUsageConsumer` ON PROJECT `my_query_project` TO "connection:SERVICE_ACCOUNT_ID";
Ganti
SERVICE_ACCOUNT_IDdengan ID akun layanan yang Anda salin sebelumnya.Klik Run.
Untuk mengetahui informasi selengkapnya tentang cara menjalankan kueri, lihat artikel Menjalankan kueri interaktif.
Gunakan pernyataan GRANT
untuk memberikan peran pengguna Cloud Translation API (roles/cloudtranslate.user)
di my_translate_project:
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, masukkan pernyataan berikut:
GRANT `roles/cloudtranslate.user` ON PROJECT `my_translate_project` TO "connection:SERVICE_ACCOUNT_ID";
Ganti
SERVICE_ACCOUNT_IDdengan ID akun layanan yang Anda salin sebelumnya.Klik Run.
Untuk mengetahui informasi selengkapnya tentang cara menjalankan kueri, lihat artikel Menjalankan kueri interaktif.
Membuat UDF Python yang memanggil layanan Cloud Translation
Di my_query_project, buat UDF Python yang memanggil layanan Cloud Translation
menggunakan koneksi resource Cloud Anda.
Di konsol Google Cloud , buka halaman BigQuery.
Masukkan pernyataan
CREATE FUNCTIONberikut di editor kueri:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.translate_to_es(x STRING) RETURNS STRING LANGUAGE python WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID` OPTIONS (entry_point='do_translate', runtime_version='python-3.11', packages=['google-cloud-translate>=3.11', 'google-api-core']) AS r""" from google.api_core.retry import Retry from google.cloud import translate project = "my_translate_project" translate_client = translate.TranslationServiceClient() def do_translate(x : str) -> str: response = translate_client.translate_text( request={ "parent": f"projects/PROJECT_ID/locations/us-central1", "contents": [x], "target_language_code": "es", "mime_type": "text/plain", }, retry=Retry(), ) return response.translations[0].translated_text """; -- Call the UDF. WITH text_table AS (SELECT "Hello" AS text UNION ALL SELECT "Good morning" AS text UNION ALL SELECT "Goodbye" AS text) SELECT text, `PROJECT_ID.DATASET_ID`.translate_to_es(text) AS translated_text FROM text_table;
Ganti kode berikut:
PROJECT_ID: project ID.DATASET_ID: ID set data.REGION: region koneksi Anda.CONNECTION_ID: ID koneksi.
Klik Run.
Outputnya akan terlihat seperti berikut ini:
+--------------------------+-------------------------------+ | text | translated_text | +--------------------------+-------------------------------+ | Hello | Hola | | Good morning | Buen dia | | Goodbye | Adios | +--------------------------+-------------------------------+
Menggunakan Kontrol Layanan VPC
UDF Python mewarisi perimeter Kontrol Layanan VPC project yang menjalankan tugas kueri. Perimeter ini melindungi tugas Anda dari pemindahan data yang tidak sah, dan memastikan interaksi layanan aman.
Saat Anda memanggil UDF Python di dalam perimeter Kontrol Layanan VPC, UDF tersebut memiliki konektivitas jaringan berikut:
- UDF Python yang tidak menggunakan koneksi resource Cloud sepenuhnya terisolasi. Semua traffic keluar diblokir.
- UDF Python yang menggunakan koneksi resource Cloud diblokir dari akses internet publik. UDF Python hanya dapat mengakses Google Cloud layanan yang
mendukung Kontrol Layanan VPC. Traffic keluar ke tujuan selain
restricted.googleapis.comdiblokir.
Mengonfigurasi UDF Python untuk mengakses Google Cloud layanan secara aman dalam Kontrol Layanan VPC
Untuk mengakses layanan dari UDF Python sambil menerapkan Kontrol Layanan VPC, ikuti langkah-langkah berikut: Google Cloud
- Buat UDF Python menggunakan klausa
CREATE FUNCTION statement's
WITH CONNECTION. - Sertakan project BigQuery tempat tugas kueri berjalan dan project layanan target dalam perimeter layanan. Atau, konfigurasikan perantara perimeter.
- Tambahkan API layanan target ke konfigurasi perimeter. Misalnya,
translate.googleapis.comjika Anda terhubung ke Cloud Translation API.
Untuk mengetahui detail selengkapnya tentang cara mengonfigurasi perimeter Kontrol Layanan VPC, lihat:
Praktik terbaik
Saat membuat UDF Python, ikuti praktik terbaik berikut:
- Optimalkan logika kueri Anda untuk pengelompokan. Struktur kueri yang kompleks dapat menonaktifkan pengelompokan. Hal ini memaksa pemrosesan baris demi baris yang lambat, yang secara signifikan meningkatkan latensi pada set data besar.
- Mengoptimalkan payload data. Ukuran setiap baris dapat memengaruhi efisiensi fitur pengelompokan. Buat setiap baris sekecil mungkin untuk memaksimalkan jumlah baris yang dapat diproses dalam satu batch.
- Konfigurasi batas penampung
secara efisien. Skalabilitas adalah fungsi CPU, memori, dan konkurensi permintaan. Periksa metrik pemantauan untuk menyesuaikan konfigurasi penampung.
Jika pemakaian CPU tinggi, tingkatkan alokasi CPU menggunakan batas
container_cpu, atau kurangi serentak permintaan container menggunakan batascontainer_request_concurrency. - Saat menggunakan penyesuaian iteratif, mulailah dengan nilai default. Jika performa tidak optimal, analisis metrik pemantauan untuk mengidentifikasi bottleneck tertentu.
- Terapkan waktu tunggu API. Saat UDF Python Anda mengakses internet, tetapkan waktu tunggu pada panggilan API untuk menghindari perilaku yang tidak terduga. Contoh akses internet adalah membaca dari bucket Cloud Storage.
Melihat metrik UDF Python
UDF Python mengekspor metrik ke Cloud Monitoring. Metrik ini membantu Anda memantau berbagai aspek kesehatan operasional dan konsumsi resource UDF, sehingga memberikan insight tentang performa dan perilaku instance UDF Anda.
Jenis resource pemantauan
Metrik untuk UDF Python dilaporkan dalam jenis resource Cloud Monitoring berikut:
- Jenis:
bigquery.googleapis.com/ManagedRoutineInvocation - Nama Tampilan: Pemanggilan Rutin Terkelola BigQuery
- Label:
resource_container: ID project tempat tugas kueri dijalankan.location: lokasi tempat tugas kueri dijalankan.query_job_id: ID tugas kueri yang memanggil UDF Python.routine_project_id: project ID tempat rutin yang dipanggil disimpan.routine_dataset_id: ID set data tempat rutinitas yang dipanggil disimpan.routine_id: ID rutinitas yang dipanggil.
Metrik
Metrik berikut tersedia untuk jenis resource
bigquery.googleapis.com/ManagedRoutineInvocation:
| Metrik | Deskripsi | Unit | Jenis nilai |
|---|---|---|---|
bigquery.googleapis.com/managed_routine/python/cpu_utilizations |
Saat UDF Python dipanggil, metrik ini menunjukkan distribusi pemakaian CPU di semua instance UDF Python untuk tugas kueri. | Nilai persentase | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/memory_utilizations |
Saat UDF Python dipanggil, metrik ini menunjukkan distribusi penggunaan memori di semua instance UDF Python untuk tugas kueri. | Nilai persentase | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/max_request_concurrencies |
Metrik ini menunjukkan distribusi jumlah maksimum permintaan serentak yang ditayangkan oleh setiap instance UDF Python. | Jumlah | DISTRIBUTION |
Lihat metrik
Untuk melihat metrik UDF Python, pilih salah satu opsi di bagian berikut.
Detail tugas
Untuk melihat metrik UDF Python untuk tugas kueri tertentu, ikuti langkah-langkah berikut:
Buka halaman BigQuery.
Klik Histori tugas.
Di kolom Job ID, klik ID tugas kueri.
Di halaman Query job details, klik Cloud Monitoring dashboard. Link ini menampilkan dasbor yang difilter untuk menampilkan metrik UDF Python untuk tugas.
Metrics Explorer
Untuk melihat metrik UDF Python di Metrics Explorer, ikuti langkah-langkah berikut:
Buka halaman Metrics explorer Cloud Monitoring.
Klik Select a metric, lalu di kolom Filter, ketik
BigQuery Managed Routine Invocationataubigquery.googleapis.com/ManagedRoutineInvocation.Pilih Bigquery Managed Routine > Managed_routine.
Klik salah satu metrik yang tersedia seperti berikut:
- Penggunaan CPU instance
- Penggunaan memori instance
- Permintaan serentak maksimum
Klik Terapkan.
Secara default, metrik ditampilkan dalam diagram.
Anda dapat memfilter dan mengelompokkan metrik menggunakan label yang ditentukan dalam jenis resource Monitoring. Untuk memfilter metrik, ikuti langkah-langkah berikut:
Di kolom Filter, pilih jenis resource seperti
query_job_idatauroutine_id.Di kolom Nilai, masukkan ID tugas atau ID rutin, atau pilih salah satu dari daftar.
Dasbor Cloud Monitoring
Untuk melihat metrik UDF Python menggunakan dasbor pemantauan, ikuti langkah-langkah berikut:
Buka halaman Dasbor Cloud Monitoring.
Klik dasbor BigQuery Managed Routine Query Monitoring.
Dasbor ini memberikan ringkasan metrik utama di seluruh UDF Anda.
Untuk memfilter dasbor ini, ikuti langkah-langkah berikut:
Klik Filter.
Di daftar Filter menurut resource, pilih opsi seperti project ID, lokasi, ID rutinitas, atau ID tugas.
Lokasi yang didukung
UDF Python didukung di semua lokasi multi-region dan regional BigQuery.
Harga
Biaya UDF Python ditagih menggunakan SKU Layanan BigQuery.
Biaya mencakup hal berikut:
Membangun atau membangun ulang image container UDF. Biaya ini sebanding dengan durasi yang diperlukan untuk membuat image yang sesuai dengan kode dan dependensi pelanggan.
- Jika Anda menggunakan Routines API, durasi build terbaru ada di
kolom
BuildStatus. Anda juga dapat melihat durasi build di kolomBuildStatusdalam tampilanINFORMATION_SCHEMA.ROUTINES. - Untuk melihat total biaya build per project, Anda dapat memfilter
laporan penagihan menggunakan hal berikut:
- Kunci:
goog-bq-feature-type - Nilai:
MANAGED_ROUTINE_BUILD
- Kunci:
- Jika Anda menggunakan Routines API, durasi build terbaru ada di
kolom
Pelanggan UDF Python juga ditagih untuk biaya pemanggilan UDF Python. Biaya ini sebanding dengan jumlah komputasi dan memori yang digunakan saat UDF Python dipanggil.
- Untuk melihat biaya UDF Python per kueri, Anda dapat membuat kueri kolom
ExternalServiceCostsmenggunakan Job API. Anda juga dapat melihat biaya per kueri dengan melihat kolomexternal_service_costsdi tampilanINFORMATION_SCHEMA.JOBSdan menerapkan filter berikut:'external_service_costs.external_service="MANAGED_ROUTINE_EXECUTION"'. - Untuk melihat total biaya menjalankan UDF Python per project, Anda dapat memfilter laporan penagihan menggunakan:
- Kunci:
goog-bq-feature-type - Nilai:
MANAGED_ROUTINE_EXECUTION
- Kunci:
- Untuk melihat biaya UDF Python per kueri, Anda dapat membuat kueri kolom
Jika UDF Python menghasilkan traffic keluar jaringan eksternal atau internet, Anda juga akan melihat biaya traffic keluar internet Tingkat Premium berdasarkan SKU Egress BigQuery.
Kuota
Lihat Kuota dan batas UDF.