
Mit benutzerdefinierten Funktionen in Python arbeiten
Mit einer benutzerdefinierten Python-Funktion (User-defined Function, UDF) können Sie eine skalare Funktion in Python implementieren und in einer SQL-Abfrage verwenden. Python-UDFs ähneln SQL- und JavaScript-UDFs, bieten aber zusätzliche Funktionen. Mit Python-UDFs können Sie Drittanbieterbibliotheken aus dem Python Package Index (PyPI) installieren und über eine Cloud-Ressourcenverbindung auf externe Dienste zugreifen.
Python-UDFs werden auf von BigQuery verwalteten Ressourcen erstellt und ausgeführt.
Beschränkungen
python-3.11ist die einzige unterstützte Laufzeit.- Sie können keine temporäre Python-UDF erstellen.
- Sie können keine Python-UDF mit einer materialisierten Ansicht verwenden.
- Die Ergebnisse einer Abfrage, die eine Python-UDF aufruft, werden nicht im Cache gespeichert, da der Rückgabewert einer Python-UDF immer als nicht deterministisch angenommen wird.
- Assured Workloads werden nicht unterstützt.
- Die folgenden Datentypen werden nicht unterstützt:
JSON,RANGE,INTERVALundGEOGRAPHY. - Container, in denen Python-UDFs ausgeführt werden, können nur mit bis zu 4 vCPUs und 16 GiB konfiguriert werden.
- Das Verschlüsseln von Python-UDF-Code mit vom Kunden verwalteten Verschlüsselungsschlüsseln (Customer-Managed Encryption Keys, CMEK) wird nicht unterstützt.
- Python-UDFs unterstützen VPC Service Controls, aber VPC-Netzwerke werden nicht unterstützt.
Erforderliche Rollen
Die erforderlichen IAM-Rollen hängen davon ab, ob Sie Inhaber oder Nutzer einer benutzerdefinierten Python-Funktion (UDF) sind.
UDF-Inhaber
Ein Python-UDF-Inhaber erstellt oder aktualisiert in der Regel eine UDF. Zusätzliche Rollen sind auch erforderlich, wenn Sie eine Python-UDF erstellen, die auf eine Cloud-Ressourcenverbindung verweist.
Diese Verbindung ist nur erforderlich, wenn in Ihrer UDF die Klausel WITH CONNECTION verwendet wird, um auf einen externen Dienst zuzugreifen.
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Erstellen oder Aktualisieren einer Python-UDF benötigen:
- BigQuery-Datenbearbeiter (
roles/bigquery.dataEditor) für das Dataset - BigQuery-Jobnutzer (
roles/bigquery.jobUser) für das Projekt - BigQuery-Verbindungsadministrator (
roles/bigquery.connectionAdmin) für das Projekt
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierten Rollen enthalten die Berechtigungen, die zum Erstellen oder Aktualisieren einer Python-UDF erforderlich sind. Maximieren Sie den Abschnitt Erforderliche Berechtigungen, um die notwendigen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Zum Erstellen oder Aktualisieren einer Python-UDF sind die folgenden Berechtigungen erforderlich:
-
Erstellen Sie eine Python-UDF mit der
CREATE FUNCTION-Anweisung:bigquery.routines.createfür das Dataset -
Aktualisieren Sie eine Python-UDF mit der
CREATE FUNCTION-Anweisung:bigquery.routines.updatefür das Dataset -
So führen Sie einen Abfragejob mit einer
CREATE FUNCTION-Anweisung aus:bigquery.jobs.createfür das Projekt -
Neue Cloud-Ressourcenverbindung erstellen:
bigquery.connections.createfür das Projekt -
Verwenden Sie eine Verbindung in der
CREATE FUNCTION-Anweisung:bigquery.connections.delegatein der Verbindung
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Weitere Informationen zu Rollen in BigQuery finden Sie unter Vordefinierte IAM-Rollen.
UDF-Nutzer
Ein Python-UDF-Nutzer ruft eine UDF auf, die von einer anderen Person erstellt wurde. Zusätzliche Rollen sind auch erforderlich, wenn Sie eine Python-UDF aufrufen, die auf eine Cloud-Ressourcenverbindung verweist.
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Aufrufen einer von einer anderen Person erstellten Python-UDF benötigen:
- BigQuery-Nutzer (
roles/bigquery.user) für das Projekt - BigQuery Data Viewer (
roles/bigquery.dataViewer) für das Dataset - BigQuery-Verbindungsnutzer (
roles/bigquery.connectionUser) für die Verbindung
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierten Rollen enthalten die Berechtigungen, die zum Aufrufen einer von einer anderen Person erstellten Python-UDF erforderlich sind. Maximieren Sie den Abschnitt Erforderliche Berechtigungen, um die notwendigen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Die folgenden Berechtigungen sind erforderlich, um eine Python-UDF aufzurufen, die von einer anderen Person erstellt wurde:
-
So führen Sie einen Abfragejob aus, der auf eine Python-UDF verweist:
bigquery.jobs.createfür das Projekt -
So rufen Sie eine Python-UDF auf, die von einer anderen Person erstellt wurde:
bigquery.routines.getfür das Dataset -
So führen Sie eine Python-UDF aus, die auf eine Cloud-Ressourcenverbindung verweist:
bigquery.connections.useauf der Verbindung
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Weitere Informationen zu Rollen in BigQuery finden Sie unter Vordefinierte IAM-Rollen.
Nichtflüchtige Python-UDF erstellen
Beachten Sie beim Erstellen einer Python-UDF die folgenden Regeln:
Der Hauptteil der Python-UDF muss ein in Anführungszeichen gesetztes Stringliteral sein, das den Python-Code darstellt. Weitere Informationen zu Stringliteralen in Anführungszeichen finden Sie unter Formate für Literale in Anführungszeichen.
Der Hauptteil der Python-UDF muss eine Python-Funktion enthalten, die im
entry_point-Argument in der Optionsliste der Python-UDF verwendet wird.Eine Python-Laufzeitversion muss in der Option
runtime_versionangegeben werden. Die einzige unterstützte Python-Laufzeitversion istpython-3.11. Eine vollständige Liste der verfügbaren Optionen finden Sie in der Liste der Funktionsoptionen für dieCREATE FUNCTION-Anweisung.
Verwenden Sie zum Erstellen einer persistenten Python-UDF die CREATE FUNCTION-Anweisung ohne das Schlüsselwort TEMP oder TEMPORARY. Verwenden Sie die Anweisung DROP FUNCTION, um eine persistente Python-UDF zu löschen.
Beispiel
Wenn Sie ein Beispiel für das Erstellen einer persistenten Python-UDF sehen möchten, wählen Sie eine der folgenden Optionen aus:
Console
Im folgenden Beispiel wird eine persistente Python-UDF mit dem Namen multiplyInputs erstellt und die UDF aus einer SELECT-Anweisung aufgerufen:
Rufen Sie die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende
CREATE FUNCTION-Anweisung ein:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyInputs(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="multiply") AS r''' def multiply(x, y): return x * y '''; -- Call the Python UDF. WITH numbers AS (SELECT 1 AS x, 5 as y UNION ALL SELECT 2 AS x, 10 as y UNION ALL SELECT 3 as x, 15 as y) SELECT x, y, `PROJECT_ID.DATASET_ID`.multiplyInputs(x, y) AS product FROM numbers;
Ersetzen Sie PROJECT_ID.DATASET_ID durch Ihre Projekt-ID und Dataset-ID.
Klicken Sie auf Ausführen.
Dieses Beispiel liefert folgende Ausgabe:
+-----+-----+--------------+ | x | y | product | +-----+-----+--------------+ | 1 | 5 | 5.0 | | 2 | 10 | 20.0 | | 3 | 15 | 45.0 | +-----+-----+--------------+
BigQuery DataFrames
Im folgenden Beispiel wird BigQuery DataFrames verwendet, um eine benutzerdefinierte Funktion in eine Python-UDF umzuwandeln:
Container-Build-Status
Wenn Sie eine Python-UDF mit der CREATE FUNCTION-Anweisung erstellen, erstellt oder aktualisiert BigQuery ein Container-Image, das auf einem Basis-Image basiert. Der Container wird auf dem Basis-Image mit Ihrem Code und allen angegebenen Paketabhängigkeiten erstellt.
Das Erstellen des Containers ist ein langwieriger Vorgang. Bei der ersten Abfrage nach dem Ausführen der CREATE FUNCTION-Anweisung wird gewartet, bis der Image-Build abgeschlossen ist. Wenn keine externen Abhängigkeiten vorhanden sind, wird das Container-Image in der Regel in weniger als einer Minute erstellt.
Die Größe aller Python-UDF-Container pro Projekt und Region ist auf insgesamt 10 GiB beschränkt. Weitere Informationen finden Sie unter Limits für benutzerdefinierte Funktionen für persistente UDFs. Der Containerbuild schlägt fehl, wenn Ihr Projekt das Kontingent erreicht hat.
Wählen Sie eine der folgenden Optionen aus, um den Status Ihres Container-Builds aufzurufen:
Console
Rufen Sie die BigQuery-Seite Studio auf.
Maximieren Sie im linken Bereich Ihr Projekt und klicken Sie dann auf Datasets.
Klicken Sie auf den Link, um das Dataset zu öffnen, das Ihre Python-UDF enthält.
Klicken Sie auf der Dataset-Seite auf den Tab Routinen.
Klicken Sie in der Spalte Routine-ID auf Ihre Python-UDF.
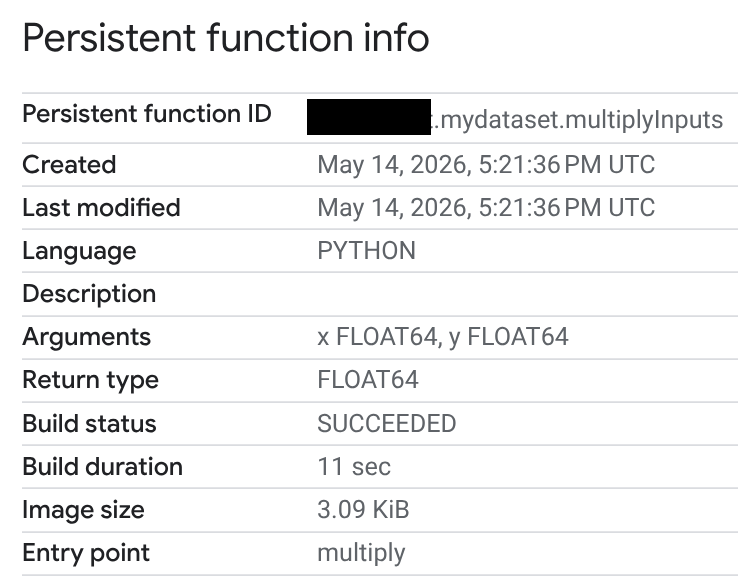
Auf der Seite Persistent function info (Informationen zur persistenten Funktion) können Sie den Build-Status, die Build-Dauer und die Bildgröße ansehen. Der Build-Status ist einer der folgenden:
- In Bearbeitung
- Erfolgreich
- Fehlgeschlagen
Wenn ein Build fehlschlägt, enthält die Funktionsinformationsseite detaillierte Fehlermeldungen, mit denen Sie Probleme wie Syntaxfehler oder Probleme bei der Installation externer Pakete beheben können.
SQL
So fragen Sie die Felder für den Build-Status in der Ansicht INFORMATION_SCHEMA.ROUTINES ab:
Rufen Sie die BigQuery-Seite Studio auf.
Wechseln Sie zum Abfrageeditor oder klicken Sie auf SQL-Abfrage.
Geben Sie die folgende Abfrage ein, um die Felder
BUILD_STATUSaus derINFORMATION_SCHEMA.ROUTINES-Ansicht abzurufen. Die SpalteBUILD_STATUSist in GoogleSQL vom TypSTRUCT:SELECT build_status.* FROM `PROJECT_ID.DATASET_ID`.INFORMATION_SCHEMA.ROUTINES;Ersetzen Sie PROJECT_ID.DATASET_ID durch Ihre Projekt-ID und Dataset-ID.
Die Ausgabe sollte so aussehen: Fehlerfelder werden ausgelassen:
+---------------+--------------------------------+------------------------+------------------+ | build_state | build_state_update_time | build_duration_seconds | image_size_bytes | +---------------+--------------------------------+------------------------+------------------+ | SUCCEEDED | 2026-05-14 17:21:49.736000 UTC | 11 | 3167 | +---------------+--------------------------------+------------------------+------------------+
API
Sie können den Status des Container-Builds mit RoutineBuildStatus in der API aufrufen.
Vektorisierte Python-UDF erstellen
Sie können Ihre Python-UDF so implementieren, dass sie einen Batch von Zeilen anstelle einer einzelnen Zeile verarbeitet. Dazu verwenden Sie die Vektorisierung. Die Vektorisierung kann die Abfrageleistung verbessern. Sie können eine vektorisierte UDF mit Pandas oder Apache Arrow erstellen.
Wenn Sie das Batching-Verhalten steuern möchten, geben Sie mit der Option max_batching_rows in der Optionsliste die maximale Anzahl von Zeilen in jedem Batch an.CREATE OR REPLACE FUNCTION Wenn Sie max_batching_rows angeben, bestimmt BigQuery die Anzahl der Zeilen in einem Batch bis zum Limit von max_batching_rows.
Wenn max_batching_rows nicht angegeben ist, wird die Anzahl der Zeilen für den Batch automatisch ermittelt.
Pandas verwenden
Eine vektorisierte Python-UDF hat ein einzelnes pandas.DataFrame-Argument, das annotiert werden muss. Das Argument pandas.DataFrame hat dieselbe Anzahl von Spalten wie die Python-UDF-Parameter, die in der CREATE FUNCTION-Anweisung definiert sind. Die Spaltennamen im pandas.DataFrame-Argument haben dieselben Namen wie die Parameter der UDF.
Ihre Funktion muss entweder ein pandas.Series oder ein einspaltiges pandas.DataFrame mit derselben Anzahl von Zeilen wie die Eingabe zurückgeben.
Im folgenden Beispiel wird eine vektorisierte Python-UDF mit dem Namen multiplyInputs mit zwei Parametern erstellt: x und y.
Rufen Sie die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende
CREATE FUNCTION-Anweisung ein:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorized(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="vectorized_multiply") AS r''' import pandas as pd def vectorized_multiply(df: pd.DataFrame): return df['x'] * df['y'] ''';
Ersetzen Sie PROJECT_ID.DATASET_ID durch Ihre Projekt-ID und Dataset-ID.
Der Aufruf der UDF ist derselbe wie im vorherigen Beispiel.
Klicken Sie auf Ausführen.
Apache Arrow verwenden
Im folgenden Beispiel wird die RecordBatch-Schnittstelle von Apache Arrow verwendet. Wenn Sie die RecordBatch-Schnittstelle verwenden, übergibt die Funktion einen Batch von Zeilen mit Spalten gleicher Länge an den Einstiegspunkt.
Im folgenden Beispiel wird Apache Arrow verwendet, um eine vektorisierte Python-UDF mit dem Namen multiplyVectorizedArrow zu erstellen.
Rufen Sie die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende
CREATE FUNCTION-Anweisung ein:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorizedArrow(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS( runtime_version="python-3.11", entry_point="vectorized_multiply_arrow" ) AS r''' import pyarrow as pa import pyarrow.compute as pc def vectorized_multiply_arrow(batch: pa.RecordBatch): # Access columns directly from the Arrow RecordBatch x = batch.column('x') y = batch.column('y') # Use pyarrow.compute for vectorized operations return pc.multiply(x, y) ''';
Ersetzen Sie PROJECT_ID.DATASET_ID durch Ihre Projekt-ID und Dataset-ID.
Das Aufrufen der UDF ist dasselbe wie in den vorherigen Beispielen.
Klicken Sie auf Ausführen.
Python-UDF aufrufen
Wenn Sie die Berechtigung zum Aufrufen einer Python-UDF haben, können Sie sie wie jede andere Funktion aufrufen. Wenn Sie eine Funktion verwenden möchten, die in einem anderen Projekt definiert ist, verwenden Sie den vollständig qualifizierten Namen der Funktion. Wenn Sie beispielsweise eine XML-Extraktionsfunktion namens cw_xml_extract in einem anderen Projekt aufrufen möchten, führen Sie die folgenden Schritte aus.
Console
Rufen Sie die Seite BigQuery auf.
Geben Sie im Abfrageeditor das folgende Beispiel ein:
SELECT `PROJECT_ID.DATASET_ID`.`cw_xml_extract`(xml, '//title/text()') AS `title` FROM UNNEST([ STRUCT('''<book id="1"> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> </book>''' AS xml), STRUCT('''<book id="2"> <title>1984</title> <author>George Orwell</author> </book>''' AS xml), STRUCT('''<book id="3"> <title>Brave New World</title> <author>Aldous Huxley</author> </book>''' AS xml) ])Klicken Sie auf Ausführen.
Dieses Beispiel liefert folgende Ausgabe:
+--------------------------+ | title | +--------------------------+ | The Great Gatsby | | 1984 | | Brave New World | +--------------------------+
BigQuery DataFrames
Im folgenden Beispiel wird eine Python-UDF mit den Methoden BigQuery DataFrames
sql_scalar, read_gbq_function und apply aufgerufen:
Von Python-UDFs unterstützte Datentypen
In der folgenden Tabelle wird die Zuordnung zwischen BigQuery-Datentypen, Python-Datentypen und Pandas-Datentypen definiert:
| BigQuery-Datentyp | Integrierter Python-Datentyp, der von Standard-UDFs verwendet wird | Von der vektorisierten UDF verwendeter Pandas-Datentyp | PyArrow-Datentyp für ARRAY und STRUCT in vektorisierten UDFs |
|---|---|---|---|
BOOL |
bool |
BooleanDtype |
DataType(bool) |
INT64 |
int |
Int64Dtype |
DataType(int64) |
FLOAT64 |
float |
FloatDtype |
DataType(double) |
STRING |
str |
StringDtype |
DataType(string) |
BYTES |
bytes |
binary[pyarrow] |
DataType(binary) |
TIMESTAMP |
Funktionsparameter: Rückgabewert der Funktion: |
Funktionsparameter: Rückgabewert der Funktion: |
TimestampType(timestamp[us]) mit Zeitzone |
DATE |
datetime.date |
date32[pyarrow] |
DataType(date32[day]) |
TIME |
datetime.time |
time64[pyarrow] |
Time64Type(time64[us]) |
DATETIME |
datetime.datetime (ohne Zeitzone) |
timestamp[us][pyarrow] |
TimestampType(timestamp[us]), ohne Zeitzone |
ARRAY |
list |
list<...>[pyarrow], wobei der Datentyp des Elements ein pandas.ArrowDtype ist. |
ListType |
STRUCT |
dict |
struct<...>[pyarrow], wobei der Datentyp des Felds pandas.ArrowDtype ist |
StructType |
Unterstützte Laufzeitversionen
BigQuery-Python-UDFs unterstützen die python-3.11-Laufzeit. Diese Python-Version enthält einige zusätzliche vorinstallierte Pakete. Prüfen Sie bei Systembibliotheken das Laufzeit-Basis-Image.
| Laufzeitversion | Python-Version | Enthält |
|---|---|---|
| python-3.11 | Python 3.11 | numpy 1.26.3 pyarrow 14.0.2 pandas 2.1.4 python-dateutil 2.8.2 absl-py 2.0.0 pytz 2023.3.post1 tzdata 2023.4 six 1.16.0 |
Drittanbieterpakete verwenden
Mit der Optionsliste CREATE FUNCTION können Sie andere Module als die von der Python-Standardbibliothek bereitgestellten und vorinstallierten Pakete verwenden.
Sie können Pakete aus dem Python-Paketindex (PyPI) installieren oder Python-Dateien aus Cloud Storage importieren.
Paket aus dem Python-Paketindex installieren
Wenn Sie ein Paket installieren, müssen Sie den Paketnamen angeben. Optional können Sie die Paketversion mit Python-Paketversionsspezifizierern angeben.
Wenn sich das Paket in der Laufzeit befindet, wird es verwendet, sofern in der Optionsliste CREATE FUNCTION keine bestimmte Version angegeben ist. Wenn keine Paketversion angegeben ist und das Paket nicht in der Laufzeit enthalten ist, wird die neueste verfügbare Version verwendet. Es werden nur Pakete mit dem binären Format „Wheels“ unterstützt.
Im folgenden Beispiel wird gezeigt, wie Sie eine Python-UDF erstellen, die das Paket scipy mit der Optionsliste CREATE OR REPLACE FUNCTION installiert:
Rufen Sie die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende
CREATE FUNCTION-Anweisung ein:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.area(radius FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='area_handler', runtime_version='python-3.11', packages=['scipy==1.15.3']) AS r""" import scipy def area_handler(radius): return scipy.constants.pi*radius*radius """; SELECT `PROJECT_ID.DATASET_ID`.area(4.5);
Ersetzen Sie PROJECT_ID.DATASET_ID durch Ihre Projekt-ID und Dataset-ID.
Klicken Sie auf Ausführen.
Zusätzliche Python-Dateien als Bibliotheken importieren
Sie können Ihre Python-UDFs mit der Funktionsoptionsliste erweitern, indem Sie Python-Dateien aus Cloud Storage importieren.
Im Python-Code Ihrer UDF können Sie die Python-Dateien aus Cloud Storage als Module importieren. Verwenden Sie dazu die Importanweisung, gefolgt vom Pfad zum Cloud Storage-Objekt. Wenn Sie beispielsweise gs://BUCKET_NAME/path/to/lib1.py importieren, lautet die Importanweisung import
path.to.lib1.
Der Python-Dateiname muss eine Python-Kennzeichnung sein. Jeder folder-Name im Objektnamen (nach dem /) muss eine gültige Python-Kennzeichnung sein. Im ASCII-Bereich (U+0001..U+007F) können die folgenden Zeichen in Bezeichnern verwendet werden:
- Groß- und Kleinbuchstaben A bis Z.
- Unterstriche.
- Die Ziffern 0 bis 9, aber eine Zahl darf nicht als erstes Zeichen in der Kennung stehen.
Im folgenden Beispiel wird gezeigt, wie Sie eine Python-UDF erstellen, die das Clientbibliotheks-Paket lib1.py aus einem Cloud Storage-Bucket mit dem Namen my_bucket importiert:
Rufen Sie die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende
CREATE FUNCTION-Anweisung ein:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.myFunc(a FLOAT64, b STRING) RETURNS STRING LANGUAGE python OPTIONS ( entry_point='compute', runtime_version='python-3.11', library=['gs://BUCKET_NAME/PATH/lib1.py']) AS r""" import path.to.lib1 as lib1 def compute(a, b): # doInterestingStuff is a function defined in # gs://BUCKET_NAME/PATH/lib1.py return lib1.doInterestingStuff(a, b); """;
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Projekt-ID.
- DATASET_ID: Ihre Dataset-ID.
- BUCKET_NAME: Der Name des Cloud Storage-Bucket, der
lib1.pyenthält. - PATH: der Pfad zum Cloud Storage-Bucket.
Klicken Sie auf Ausführen.
Containerlimits für Python-UDFs konfigurieren
Mit der Optionsliste für CREATE FUNCTION können Sie Grenzwerte für die Parallelität von CPU-, Arbeitsspeicher- und Containeranforderungen für Container angeben, in denen Python-UDFs ausgeführt werden.
Standardmäßig werden Containern die folgenden Ressourcen zugewiesen:
- Der zugewiesene Arbeitsspeicher beträgt
512Mi. - Die zugewiesene CPU beträgt
1.0vCPU. - Das Limit für die Nebenläufigkeit von Containeranfragen beträgt
80.
Im folgenden Beispiel wird eine Python-UDF erstellt, in der mit der Optionsliste CREATE FUNCTION Containerlimits angegeben werden:
Rufen Sie die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende
CREATE FUNCTION-Anweisung ein:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.square_area(length FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='square_area', runtime_version='python-3.11', container_memory='CONTAINER_MEMORY', container_cpu=CONTAINER_CPU, container_request_concurrency=CONTAINER_REQUEST_CONCURRENCY) AS r""" def square_area(length): return length*length """; SELECT `PROJECT_ID.DATASET_ID`.square_area(4.5);
Ersetzen Sie Folgendes:
- PROJECT_ID.DATASET_ID: Ihre Projekt-ID und Dataset-ID.
- CONTAINER_MEMORY: Der Arbeitsspeicherwert im folgenden Format:
<integer_number><unit>. Die Einheit muss einer der folgenden Werte sein:Mi(MiB),M(MB),Gi(GiB) oderG(GB). Beispiel:2Gi - CONTAINER_CPU: Der CPU-Wert. Python-UDFs unterstützen fraktionale CPU-Werte zwischen
0.33und1.0sowie nicht fraktionale CPU-Werte von1,2und4. - CONTAINER_REQUEST_CONCURRENCY: Die maximale Anzahl gleichzeitiger Anfragen pro Containerinstanz der benutzerdefinierten Python-Funktion. Der Wert muss eine Ganzzahl zwischen
1und1000sein.
Klicken Sie auf Ausführen.
Unterstützte CPU-Werte
Python-UDFs unterstützen CPU-Werte mit Nachkommastellen zwischen 0.33 und 1.0 sowie CPU-Werte ohne Nachkommastellen von 1, 2 und 4. Container, in denen Python-UDFs ausgeführt werden, können mit bis zu 4 vCPUs konfiguriert werden. Der Standardwert ist 1.0. Gleitkomma-Eingabewerte werden auf zwei Dezimalstellen gerundet, bevor sie auf den Container angewendet werden.
Unterstützte Arbeitsspeicherwerte
Python-UDF-Container unterstützen Speicherwerte im folgenden Format:
<integer_number><unit>. Die Einheit muss einer der folgenden Werte sein: Mi, M, Gi, G. Die Mindestspeichermenge, die Sie konfigurieren können, beträgt 256Mi. Die maximal konfigurierbare Arbeitsspeichermenge ist 16Gi.
Abhängig vom ausgewählten Speicherwert müssen Sie auch eine angemessene CPU-Menge angeben. Die folgende Tabelle zeigt die minimalen und maximalen CPU-Werte für jeden Arbeitsspeicherwert:
| Arbeitsspeicher | Mindestanforderung CPU | Maximale CPU-Auslastung |
|---|---|---|
256Mi bis 512Mi |
0.33 |
2 |
Größer als 512Mi und kleiner als oder gleich 1Gi |
0.5 |
2 |
Größer als 1Gi und kleiner als 2Gi |
1 |
2 |
2Gi bis 4Gi |
1 |
4 |
Größer als 4Gi und bis zu 8Gi |
2 |
4 |
Größer als 8Gi und bis zu 16Gi |
4 |
4 |
Wenn Sie die Menge an CPU, die Sie zuweisen, bereits ermittelt haben, können Sie die folgende Tabelle verwenden, um den entsprechenden Speicherbereich zu bestimmen:
| CPU | Mindestspeicher | Maximaler Arbeitsspeicher |
|---|---|---|
Weniger als 0.5 |
256Mi |
512Mi |
0.5 auf weniger als 1 |
256Mi |
1Gi |
1 |
256Mi |
4Gi |
2 |
256Mi |
8Gi |
4 |
2Gi |
16Gi |
Google Cloud oder Onlinedienste in Python-Code aufrufen
Eine Python-UDF greift über das Dienstkonto der Cloud-Ressourcenverbindung auf einen Google Cloud -Dienst oder einen externen Dienst zu. Dem Dienstkonto der Verbindung müssen Berechtigungen für den Zugriff auf den Dienst gewährt werden. Die erforderlichen Berechtigungen hängen vom Dienst ab, auf den zugegriffen wird, und von den APIs, die von Ihrem Python-Code aufgerufen werden.
Wenn Sie eine Python-UDF ohne Verwendung einer Cloud-Ressourcenverbindung erstellen, wird die Funktion in einer Umgebung ausgeführt, in der der Netzwerkzugriff blockiert wird. Wenn Ihre UDF auf Onlinedienste zugreift, müssen Sie sie mit einer Cloud-Ressourcenverbindung erstellen. Andernfalls wird der Zugriff der UDF auf das Netzwerk blockiert, bis ein internes Zeitlimit für die Verbindung erreicht ist. Wenn Sie eine Cloud-Ressourcenverbindung verwenden, müssen Sie Folgendes implementieren:
Zeitüberschreitungen Wenn Sie Netzwerkaufrufe in Ihrer Python-UDF ausführen, sollten Sie immer ein angemessenes Zeitlimit festlegen. So wird verhindert, dass die UDF unbegrenzt lange hängt, wenn der externe Dienst langsam reagiert oder nicht erreichbar ist.
Fehlerbehandlung verwenden Schließen Sie den Code für Netzwerkaufrufe in einen
try...except-Block ein, um potenzielle Fehler wie Verbindungsfehler, Zeitüberschreitungen oder HTTP-Fehlerstatuscodes ordnungsgemäß zu verarbeiten. So kann Ihre UDF einen aussagekräftigen Fehler oder einen Fallback-Wert zurückgeben, anstatt dass die Abfrage fehlschlägt oder nicht mehr reagiert.
Im folgenden Beispiel wird gezeigt, wie Sie über eine Python-UDF auf den Cloud Translation-Dienst zugreifen. In diesem Beispiel gibt es zwei Projekte: ein Projekt mit dem Namen my_query_project, in dem Sie die UDF und die Cloud-Ressourcenverbindung erstellen, und ein Projekt mit dem Namen my_translate_project, in dem Sie Cloud Translation ausführen.
Cloud-Ressourcenverbindung erstellen
Zuerst erstellen Sie eine Cloud-Ressourcenverbindung in my_query_project. So erstellen Sie die Cloud-Ressourcenverbindung:
Console
Rufen Sie die Seite BigQuery auf.
Klicken Sie im linken Bereich auf Explorer:

Wenn das linke Steuerfeld nicht angezeigt wird, klicken Sie auf Linkes Steuerfeld maximieren, um es zu öffnen.
Maximieren Sie im Bereich Explorer den Namen Ihres Projekts und klicken Sie dann auf Verbindungen.
Klicken Sie auf der Seite Verbindungen auf Verbindung erstellen.
Wählen Sie als Verbindungstyp die Option Vertex AI-Remote-Modelle, Remote-Funktionen, BigLake und Cloud Spanner (Cloud-Ressource) aus.
Geben Sie im Feld Verbindungs-ID einen Namen für die Verbindung ein.
Wählen Sie unter Standorttyp einen Standort für die Verbindung aus. Die Verbindung sollte sich am selben Ort wie Ihre anderen Ressourcen, z. B. Datasets, befinden.
Klicken Sie auf Verbindung erstellen.
Klicken Sie auf Zur Verbindung.
Kopieren Sie im Bereich Verbindungsinformationen die Dienstkonto-ID zur Verwendung in einem späteren Schritt.
SQL
Verwenden Sie die Anweisung CREATE CONNECTION:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
Ersetzen Sie Folgendes:
-
CONNECTION_NAME: Der Name der Verbindung im FormatPROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_IDoderCONNECTION_ID. Wenn das Projekt oder der Standort weggelassen werden, werden sie aus dem Projekt und dem Standort abgeleitet, in dem die Anweisung ausgeführt wird. -
FRIENDLY_NAME(optional): Ein beschreibender Name für die Verbindung. -
DESCRIPTION(optional): eine Beschreibung der Verbindung.
-
Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
bq
Erstellen Sie in einer Befehlszeilenumgebung eine Verbindung:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
Der Parameter
--project_idüberschreibt das Standardprojekt.Ersetzen Sie dabei Folgendes:
REGION: Ihre VerbindungsregionPROJECT_ID: Ihre Google Cloud Projekt-IDCONNECTION_ID: eine ID für Ihre Verbindung
Wenn Sie eine Verbindungsressource herstellen, erstellt BigQuery ein eindeutiges Systemdienstkonto und ordnet es der Verbindung zu.
Fehlerbehebung:Wird der folgende Verbindungsfehler angezeigt, aktualisieren Sie das Google Cloud SDK:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
Rufen Sie die Dienstkonto-ID ab und kopieren Sie sie zur Verwendung in einem späteren Schritt:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
Die Ausgabe sieht etwa so aus:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Python
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Python in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Python API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Node.js
Bevor Sie dieses Beispiel anwenden, folgen Sie den Schritten zur Einrichtung von Node.js in der BigQuery-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Angaben finden Sie in der Referenzdokumentation zur BigQuery Node.js API.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Terraform
Verwenden Sie die Ressource google_bigquery_connection:
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Im folgenden Beispiel wird eine Cloud-Ressourcenverbindung mit dem Namen my_cloud_resource_connection in der Region US erstellt:
Führen Sie die Schritte in den folgenden Abschnitten aus, um Ihre Terraform-Konfiguration auf ein Google Cloud -Projekt anzuwenden.
Cloud Shell vorbereiten
- Rufen Sie Cloud Shell auf.
-
Legen Sie das Standardprojekt Google Cloud fest, auf das Sie Ihre Terraform-Konfigurationen anwenden möchten.
Sie müssen diesen Befehl nur einmal pro Projekt und in jedem beliebigen Verzeichnis ausführen.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Umgebungsvariablen werden überschrieben, wenn Sie in der Terraform-Konfigurationsdatei explizite Werte festlegen.
Verzeichnis vorbereiten
Jede Terraform-Konfigurationsdatei muss ein eigenes Verzeichnis haben (auch als Stammmodul bezeichnet).
-
Erstellen Sie in Cloud Shell ein Verzeichnis und eine neue Datei in diesem Verzeichnis. Der Dateiname muss die Erweiterung
.tfhaben, z. B.main.tf. In dieser Anleitung wird die Datei alsmain.tfbezeichnet.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Wenn Sie einer Anleitung folgen, können Sie den Beispielcode in jedem Abschnitt oder Schritt kopieren.
Kopieren Sie den Beispielcode in das neu erstellte
main.tf.Kopieren Sie optional den Code aus GitHub. Dies wird empfohlen, wenn das Terraform-Snippet Teil einer End-to-End-Lösung ist.
- Prüfen und ändern Sie die Beispielparameter, die auf Ihre Umgebung angewendet werden sollen.
- Speichern Sie die Änderungen.
-
Initialisieren Sie Terraform. Dies ist nur einmal für jedes Verzeichnis erforderlich.
terraform init
Fügen Sie optional die Option
-upgradeein, um die neueste Google-Anbieterversion zu verwenden:terraform init -upgrade
Änderungen anwenden
-
Prüfen Sie die Konfiguration und prüfen Sie, ob die Ressourcen, die Terraform erstellen oder aktualisieren wird, Ihren Erwartungen entsprechen:
terraform plan
Korrigieren Sie die Konfiguration nach Bedarf.
-
Wenden Sie die Terraform-Konfiguration an. Führen Sie dazu den folgenden Befehl aus und geben Sie
yesan der Eingabeaufforderung ein:terraform apply
Warten Sie, bis Terraform die Meldung „Apply complete“ anzeigt.
- Öffnen Sie Ihr Google Cloud -Projekt, um die Ergebnisse aufzurufen. Rufen Sie in der Google Cloud Console Ihre Ressourcen in der Benutzeroberfläche auf, um sicherzustellen, dass Terraform sie erstellt oder aktualisiert hat.
Dem Dienstkonto der Verbindung Zugriff gewähren
Sie benötigen die Dienstkonto-ID, die Sie zuvor kopiert haben, wenn Sie Berechtigungen für die Verbindung konfigurieren. Wenn Sie eine Verbindungsressource erstellen, erstellt BigQuery ein eindeutiges Systemdienstkonto und ordnet es der Verbindung zu.
Damit das Dienstkonto für die Cloud-Ressourcenverbindung auf Ihre Projekte zugreifen kann, weisen Sie dem Dienstkonto in my_query_project die Rolle „Service Usage Consumer“ (roles/serviceusage.serviceUsageConsumer) und in my_translate_project die Rolle „Cloud Translation API-Nutzer“ (roles/cloudtranslate.user) zu.
Console
Rufen Sie die IAM-Seite auf.
Prüfen Sie, ob
my_query_projectausgewählt ist.Klicken Sie auf Zugriff gewähren.
Geben Sie im Feld Neue Hauptkonten die Dienstkonto-ID der Cloud-Ressourcenverbindung ein, die Sie zuvor kopiert haben.
Wählen Sie im Feld Rolle auswählen die Option Dienstnutzung und dann Nutzer der Dienstnutzung aus.
Klicken Sie auf Speichern.
Wählen Sie in der Projektauswahl
my_translate_projectaus.Rufen Sie die IAM-Seite auf.
Klicken Sie auf Zugriff gewähren.
Geben Sie im Feld Neue Hauptkonten die Dienstkonto-ID der Cloud-Ressourcenverbindung ein, die Sie zuvor kopiert haben.
Wählen Sie im Feld Rolle auswählen die Option Cloud Translation und dann Cloud Translation API-Nutzer aus.
Klicken Sie auf Speichern.
SQL
Verwenden Sie die GRANT-Anweisung, um dem Dienstkonto in my_query_project die Rolle „Service Usage Consumer“ (roles/serviceusage.serviceUsageConsumer) zuzuweisen:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
GRANT `roles/serviceusage.serviceUsageConsumer` ON PROJECT `my_query_project` TO "connection:SERVICE_ACCOUNT_ID";
Ersetzen Sie
SERVICE_ACCOUNT_IDdurch die zuvor kopierte Dienstkonto-ID.Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Verwenden Sie die GRANT-Anweisung, um die Rolle „Cloud Translation API-Nutzer“ (roles/cloudtranslate.user) in my_translate_project zuzuweisen:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie im Abfrageeditor die folgende Anweisung ein:
GRANT `roles/cloudtranslate.user` ON PROJECT `my_translate_project` TO "connection:SERVICE_ACCOUNT_ID";
Ersetzen Sie
SERVICE_ACCOUNT_IDdurch die zuvor kopierte Dienstkonto-ID.Klicken Sie auf Ausführen.
Informationen zum Ausführen von Abfragen finden Sie unter Interaktive Abfrage ausführen.
Python-UDF erstellen, die den Cloud Translation-Dienst aufruft
Erstellen Sie in my_query_project eine Python-UDF, die den Cloud Translation-Dienst über Ihre Cloud-Ressourcenverbindung aufruft.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Geben Sie die folgende
CREATE FUNCTION-Anweisung in den Abfrageeditor ein:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.translate_to_es(x STRING) RETURNS STRING LANGUAGE python WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID` OPTIONS (entry_point='do_translate', runtime_version='python-3.11', packages=['google-cloud-translate>=3.11', 'google-api-core']) AS r""" from google.api_core.retry import Retry from google.cloud import translate project = "my_translate_project" translate_client = translate.TranslationServiceClient() def do_translate(x : str) -> str: response = translate_client.translate_text( request={ "parent": f"projects/PROJECT_ID/locations/us-central1", "contents": [x], "target_language_code": "es", "mime_type": "text/plain", }, retry=Retry(), ) return response.translations[0].translated_text """; -- Call the UDF. WITH text_table AS (SELECT "Hello" AS text UNION ALL SELECT "Good morning" AS text UNION ALL SELECT "Goodbye" AS text) SELECT text, `PROJECT_ID.DATASET_ID`.translate_to_es(text) AS translated_text FROM text_table;
Ersetzen Sie Folgendes:
PROJECT_ID: Projekt-ID.DATASET_ID: Die Dataset-ID.REGION: Die Region Ihrer Verbindung.CONNECTION_ID: die Verbindungs-ID.
Klicken Sie auf Ausführen.
Die Ausgabe sollte so aussehen:
+--------------------------+-------------------------------+ | text | translated_text | +--------------------------+-------------------------------+ | Hello | Hola | | Good morning | Buen dia | | Goodbye | Adios | +--------------------------+-------------------------------+
VPC Service Controls verwenden
Python-UDFs übernehmen den VPC Service Controls-Perimeter des Projekts, in dem der Abfragejob ausgeführt wird. Dieser Perimeter schützt Ihre Jobs vor Daten-Exfiltration und sorgt für sichere Dienstinteraktionen.
Wenn Sie eine Python-UDF innerhalb des VPC Service Controls-Perimeters aufrufen, hat sie die folgende Netzwerkverbindung:
- Python-UDFs, die keine Cloud-Ressourcenverbindung verwenden, sind vollständig isoliert. Der gesamte ausgehende Traffic wird blockiert.
- Python-Nutzerdefinierte Funktionen, die eine Cloud-Ressourcenverbindung verwenden, sind für den öffentlichen Internetzugriff gesperrt. Python-UDFs können nur auf Google Cloud Dienste zugreifen, die VPC Service Controls unterstützen. Ausgehender Traffic zu anderen Zielen als
restricted.googleapis.comwird blockiert.
Python-Nutzerdefinierte Funktionen für den sicheren Zugriff auf Google Cloud -Dienste in VPC Service Controls konfigurieren
So greifen Sie über Python-UDFs auf Google Cloud Dienste zu und erzwingen gleichzeitig VPC Service Controls:
- Erstellen Sie die benutzerdefinierte Python-Funktion (UDF) mit der
WITH CONNECTION-Klausel der CREATE FUNCTION-Anweisung. - Fügen Sie das BigQuery-Projekt, in dem der Abfragejob ausgeführt wird, und das Ziel-Dienstprojekt in den Dienstperimeter ein. Alternativ können Sie eine Perimeter-Bridge konfigurieren.
- Fügen Sie die API des Zieldienstes der Perimeterkonfiguration hinzu.
translate.googleapis.com, wenn Sie beispielsweise eine Verbindung zur Cloud Translation API herstellen.
Weitere Informationen zum Konfigurieren eines VPC Service Controls-Perimeters finden Sie unter:
Best Practices
Beachten Sie beim Erstellen von Python-UDFs die folgenden Best Practices:
- Abfragelogik für Batching optimieren Komplexe Abfragestrukturen können das Batching deaktivieren. Dadurch wird eine langsame, zeilenweise Verarbeitung erzwungen, was die Latenz bei großen Datasets erheblich erhöht.
- Daten-Payload optimieren Die Größe einzelner Zeilen kann sich auf die Effizienz der Batching-Funktion auswirken. Halten Sie jede Zeile so kurz wie möglich, um die Anzahl der Zeilen zu maximieren, die in einem einzelnen Batch verarbeitet werden können.
- Konfigurieren Sie Containerlimits effizient. Die Skalierbarkeit hängt von CPU, Arbeitsspeicher und der Nebenläufigkeit von Anfragen ab. Überprüfen Sie die Monitoring-Messwerte, um die Containerkonfiguration zu optimieren.
Wenn die CPU-Auslastung hoch ist, erhöhen Sie die CPU-Zuweisung mit dem
container_cpu-Limit oder verringern Sie die Nebenläufigkeit von Containeranfragen mit demcontainer_request_concurrency-Limit. - Beginnen Sie bei der iterativen Optimierung mit den Standardwerten. Wenn die Leistung nicht optimal ist, analysieren Sie die Monitoring-Messwerte, um bestimmte Engpässe zu ermitteln.
- API-Timeouts implementieren Wenn Ihre Python-UDF auf das Internet zugreift, legen Sie für den API-Aufruf ein Zeitlimit fest, um unerwartetes Verhalten zu vermeiden. Ein Beispiel für den Internetzugriff ist das Lesen aus einem Cloud Storage-Bucket.
Python-UDF-Messwerte ansehen
Python-UDFs exportieren Messwerte nach Cloud Monitoring. Mithilfe dieser Messwerte können Sie verschiedene Aspekte des Betriebs und des Ressourcenverbrauchs Ihrer UDF überwachen und so Einblicke in die Leistung und das Verhalten Ihrer UDF-Instanzen erhalten.
Typ der überwachten Ressource
Die Messwerte für Python-UDFs werden unter dem folgenden Cloud Monitoring-Ressourcentyp gemeldet:
- Typ:
bigquery.googleapis.com/ManagedRoutineInvocation - Anzeigename: Von BigQuery verwalteter Aufruf von Abläufen
- Labels:
resource_container: die ID des Projekts, in dem der Abfragejob ausgeführt wurde.location: der Ort, an dem der Abfragejob ausgeführt wurde.query_job_id: die ID des Abfragejobs, mit dem die Python-UDF aufgerufen wurde.routine_project_id: die Projekt-ID, in der die aufgerufene Routine gespeichert ist.routine_dataset_id: die Dataset-ID, in der die aufgerufene Routine gespeichert ist.routine_id: Die ID der aufgerufenen Routine.
Messwerte
Die folgenden Messwerte sind für den Ressourcentyp bigquery.googleapis.com/ManagedRoutineInvocation verfügbar:
| Messwert | Beschreibung | Einheit | Werttyp |
|---|---|---|---|
bigquery.googleapis.com/managed_routine/python/cpu_utilizations |
Wenn eine Python-UDF aufgerufen wird, zeigt dieser Messwert die Verteilung der CPU-Auslastung auf alle Python-UDF-Instanzen für den Abfragejob an. | Prozentwert | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/memory_utilizations |
Wenn eine Python-UDF aufgerufen wird, zeigt dieser Messwert die Verteilung der Arbeitsspeicherauslastung auf alle Python-UDF-Instanzen für den Abfragejob. | Prozentwert | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/max_request_concurrencies |
Dieser Messwert zeigt die Verteilung der maximalen Anzahl gleichzeitiger Anfragen, die von jeder Python-UDF-Instanz verarbeitet werden. | Anzahl | DISTRIBUTION |
Messwerte aufrufen
Wenn Sie die Messwerte für Ihre Python-UDFs aufrufen möchten, wählen Sie eine der Optionen in den folgenden Abschnitten aus.
Jobdetails
So rufen Sie Python-UDF-Messwerte für einen bestimmten Abfragejob auf:
Rufen Sie die Seite BigQuery auf.
Klicken Sie auf Jobverlauf.
Klicken Sie in der Spalte Job-ID auf die Job-ID der Abfrage.
Klicken Sie auf der Seite Abfragejobdetails auf Cloud Monitoring-Dashboard. Über diesen Link wird ein Dashboard aufgerufen, das so gefiltert ist, dass die Messwerte für die Python-UDF für den Job angezeigt werden.
Metrics Explorer
So rufen Sie Python-UDF-Messwerte im Metrics Explorer auf:
Rufen Sie die Cloud Monitoring-Seite Metrics Explorer auf.
Klicken Sie auf Messwert auswählen und geben Sie im Feld Filter
BigQuery Managed Routine Invocationoderbigquery.googleapis.com/ManagedRoutineInvocationein.Wählen Sie Von BigQuery verwalteter Ablauf > Managed_routine aus.
Klicken Sie auf einen der verfügbaren Messwerte, z. B.:
- CPU-Auslastung der Instanz
- Arbeitsspeicherauslastung der Instanz
- Maximale Anzahl gleichzeitiger Anfragen
Klicken Sie auf Übernehmen.
Standardmäßig werden die Messwerte in einem Diagramm dargestellt.
Sie können die Messwerte mit den in den Monitoring-Ressourcentypen definierten Labels filtern und gruppieren. So filtern Sie die Messwerte:
Wählen Sie im Feld Filter einen Ressourcentyp aus, z. B.
query_job_idoderroutine_id.Geben Sie im Feld Wert die Job-ID oder die Routine-ID ein oder wählen Sie eine aus der Liste aus.
Cloud Monitoring-Dashboards
So rufen Sie Python-UDF-Messwerte über die Monitoring-Dashboards auf:
Rufen Sie die Cloud Monitoring-Seite Dashboards auf.
Klicken Sie auf das Dashboard BigQuery Managed Routine Query Monitoring (Monitoring von Abfragen für von BigQuery verwaltete Routinen).
Dieses Dashboard bietet einen Überblick über die wichtigsten Messwerte für Ihre UDFs.
So filtern Sie dieses Dashboard:
Klicken Sie auf Filter.
Wählen Sie in der Liste Nach Ressource filtern eine Option wie Projekt-ID, Standort, Routine-ID oder Job-ID aus.
Unterstützte Standorte
Python-UDFs werden in allen multiregionalen und regionalen Standorten von BigQuery unterstützt.
Preise
Gebühren für Python-UDFs werden über die BigQuery Services-SKU abgerechnet.
Die Kosten umfassen Folgendes:
Erstellen oder Neuerstellen des UDF-Container-Images. Diese Gebühr ist proportional zur Dauer, die zum Erstellen des entsprechenden Images mit Kundencode und Abhängigkeiten erforderlich ist.
- Wenn Sie die Routines API verwenden, finden Sie die Dauer des letzten Builds im Feld
BuildStatus. Sie können die Build-Dauer auch in der SpalteBuildStatusin derINFORMATION_SCHEMA.ROUTINES-Ansicht sehen. - Wenn Sie die Gesamtkosten für Builds pro Projekt aufrufen möchten, können Sie Ihren Abrechnungsbericht mit den folgenden Filtern filtern:
- Key:
goog-bq-feature-type - Wert:
MANAGED_ROUTINE_BUILD
- Key:
- Wenn Sie die Routines API verwenden, finden Sie die Dauer des letzten Builds im Feld
Kunden mit Python-UDFs werden auch die Kosten für den Aufruf einer Python-UDF in Rechnung gestellt. Diese Gebühr ist proportional zur Menge an Rechenleistung und Arbeitsspeicher, die beim Aufrufen der Python-UDF verbraucht werden.
- Wenn Sie die Kosten für Python-UDFs pro Abfrage aufrufen möchten, können Sie das Feld
ExternalServiceCostsmit der Job API abfragen. Sie können die Kosten pro Anfrage auch in derINFORMATION_SCHEMA.JOBS-Ansicht in der Spalteexternal_service_costssehen. Wenden Sie dazu den folgenden Filter an:'external_service_costs.external_service="MANAGED_ROUTINE_EXECUTION"'. - Wenn Sie die Gesamtkosten für die Ausführung von Python-UDFs pro Projekt aufrufen möchten, können Sie den Abrechnungsbericht mit den folgenden Filtern filtern:
- Key:
goog-bq-feature-type - Wert:
MANAGED_ROUTINE_EXECUTION
- Key:
- Wenn Sie die Kosten für Python-UDFs pro Abfrage aufrufen möchten, können Sie das Feld
Wenn Python-UDFs zu ausgehendem externen oder Internet-Netzwerktraffic führen, wird auch eine Gebühr für ausgehenden Internettraffic der Premium-Stufe basierend auf den BigQuery-SKUs für ausgehenden Traffic berechnet.
Kontingente
Weitere Informationen finden Sie unter UDF-Kontingente und ‑Limits.