
Einführung in kontinuierliche Abfragen
In diesem Dokument werden kontinuierliche Abfragen in BigQuery beschrieben.
Kontinuierliche Abfragen in BigQuery sind SQL-Anweisungen, die kontinuierlich ausgeführt werden. Mit kontinuierlichen Abfragen können Sie eingehende Daten in BigQuery in Echtzeit analysieren. Sie können die von einer kontinuierlichen Abfrage erzeugten Ausgaberow in eine BigQuery-Tabelle einfügen oder in Pub/Sub, Bigtable oder Spanner exportieren. Kontinuierliche Abfragen können Daten verarbeiten, die mit einer der folgenden Methoden in Standard-BigQuery-Tabellen geschrieben wurden:
- Die BigQuery Storage Write API
- Die
tabledata.insertAllMethode - Batch-Ladevorgang
- Die
INSERTDML-Anweisung - Mutieren von DML-Anweisungen (Datenbearbeitungssprache)
wie
DELETE,UPDATE, undMERGEbeim Exportieren von Daten nach Pub/Sub. - Schreibt aus den Ergebnissen einer Batch-Abfrage in eine permanente Tabelle
- Schreibt aus den Ergebnissen einer kontinuierlichen BigQuery-Abfrage in eine permanente Tabelle
- Ein Pub/Sub-BigQuery-Abo
- Schreibt aus Dataflow in BigQuery
- Schreibt aus Datastream in BigQuery im Modus „ Nur anhängen“
Mit kontinuierlichen Abfragen können Sie zeitkritische Aufgaben ausführen, z. B. Erkenntnisse erstellen und sofort darauf reagieren, Echtzeit-Inferenzen für maschinelles Lernen (ML) anwenden und Daten auf andere Plattformen replizieren. So können Sie BigQuery als ereignisgesteuerte Datenverarbeitungs-Engine für die Entscheidungslogik Ihrer Anwendung verwenden.
Das folgende Diagramm zeigt gängige Workflows für kontinuierliche Abfragen:
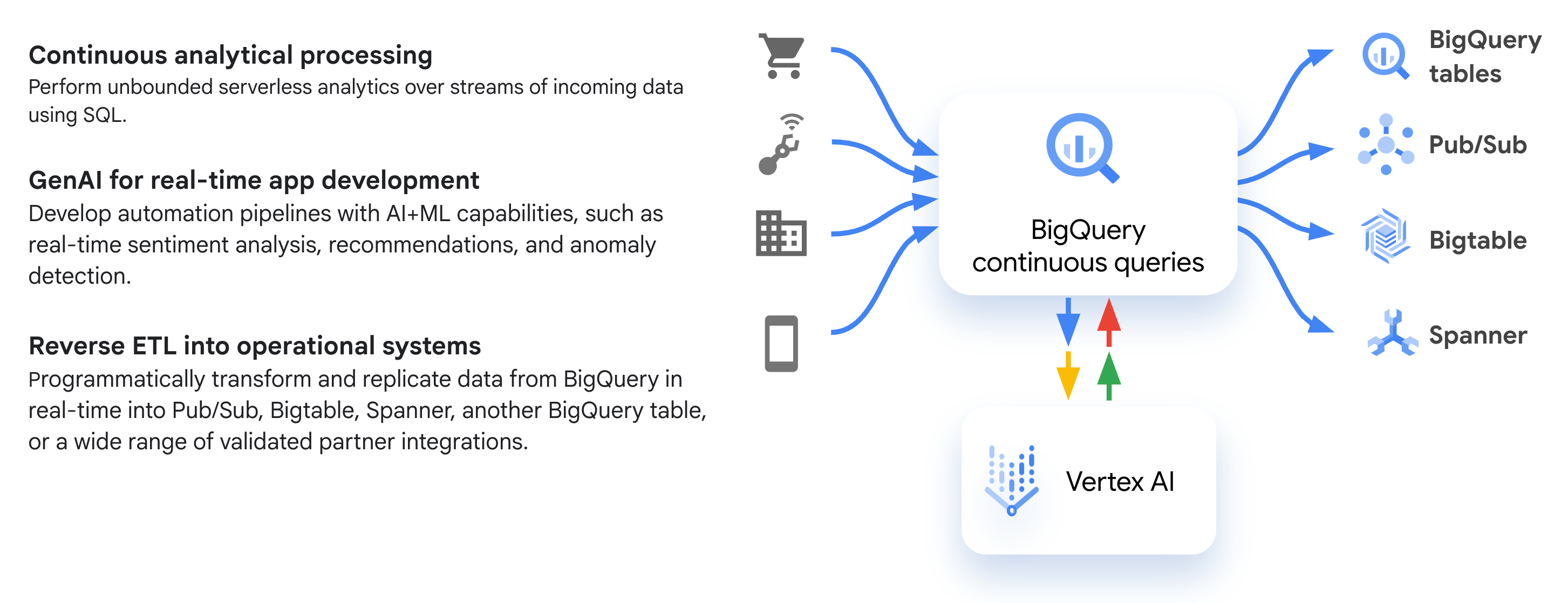
Anwendungsfälle
Häufige Anwendungsfälle, in denen Sie möglicherweise kontinuierliche Abfragen verwenden möchten:
- Personalisierte Kundenservice-Dienste: Mit generativer KI können Sie maßgeschneiderte Nachrichten erstellen, die für jede Kundeninteraktion angepasst sind.
- Anomalieerkennung: Erstellen Sie Lösungen, mit denen Sie Anomalien und Bedrohungen in komplexen Daten in Echtzeit erkennen können, damit Sie schneller auf Probleme reagieren können.
- Anpassbare ereignisgesteuerte Pipelines: Verwenden Sie die Integration kontinuierlicher Abfragen mit Pub/Sub, um nachgelagerte Anwendungen basierend auf eingehenden Daten auszulösen.
- Datenanreicherung und Entitätsextraktion: Verwenden Sie kontinuierliche Abfragen, um Daten in Echtzeit anzureichern und zu transformieren. Dazu können Sie SQL-Funktionen und ML-Modelle verwenden.
- Umgekehrte ETL (Extrahieren, Transformieren, Laden): Führen Sie umgekehrte ETL in Echtzeit in andere Speichersysteme durch, die besser für die Bereitstellung von Anwendungen mit niedriger Latenz geeignet sind. Beispiel: Analysieren oder verbessern Sie Ereignisdaten, die in BigQuery geschrieben werden, und streamen Sie sie dann zur Bereitstellung von Anwendungen in Bigtable oder Spanner.
- Autonomes Auslösen von Agenten: Lösen Sie agentische Datenpipelines in Echtzeit basierend auf komplexen Ereignissen aus, die in Live-Datenstreams erkannt werden. Ein Beispiel finden Sie im Codelab Ereignisgesteuerten Datenagenten mit BigQuery und Agent Development Kit (ADK) erstellen.
- Autonomes Agenten-Monitoring: Entwickeln Sie automatisiertes Monitoring und Benachrichtigungen in Echtzeit für agentische Interaktionen in Echtzeit mit dem BigQuery-Plug-in für die Agentenanalyse, das alle Agenten-Tracedaten, die Toolnutzung und die Betriebsprotokolle direkt in BigQuery streamt, um umfassende Beobachtbarkeit Ihrer KI-Mitarbeiter zu erhalten.
Unterstützte Funktionen
Die folgenden Vorgänge werden in kontinuierlichen Abfragen unterstützt:
- Ausführen von
INSERTAnweisungen um Daten aus einer kontinuierlichen Abfrage in eine BigQuery-Tabelle zu schreiben. Ausführen von
EXPORT DATAAnweisungen zum Veröffentlichen der Ausgabe von kontinuierlichen Abfragen in Pub/Sub-Themen. Weitere Informationen finden Sie unter Daten nach Pub/Sub exportieren.Aus einem Pub/Sub-Thema können Sie die Daten mit anderen Diensten verwenden, z. B. Streaminganalysen mit Dataflow durchführen oder die Daten in einem Workflow zur Anwendungsintegration verwenden.
Ausführen von
EXPORT DATA-Anweisungen, um Daten aus BigQuery in Bigtable-Tabellen zu exportieren. Weitere Informationen finden Sie unter Daten nach Bigtable exportieren.Ausführen von
EXPORT DATA-Anweisungen, um Daten aus BigQuery in Spanner-Tabellen zu exportieren. Weitere Informationen finden Sie unter Daten nach Spanner exportieren (umgekehrte ETL).Aufrufen der folgenden generativen KI-Funktionen:
AI.GENERATE-
- Für diese Funktion benötigen Sie ein BigQuery ML-Remote-Modell für ein Gemini Enterprise Agent Platform-Modell.
Aufrufen der folgenden KI-Funktionen:
Für diese Funktionen benötigen Sie ein BigQuery ML-Remote-Modell für eine Cloud AI API.
Normalisieren numerischer Daten mit der
ML.NORMALIZERFunktion.Analysieren und Verarbeiten von
JSONDaten, einschließlich Unterstützung für JSON-Funktionen und JSON-Entschachtelung.Verwenden zustandsloser GoogleSQL-Funktionen, z. B. Konvertierungsfunktionen. Bei zustandslosen Funktionen wird jede Zeile unabhängig von anderen Zeilen in der Tabelle verarbeitet.
Verwenden zustandsbehafteter Vorgänge, z. B.
JOINs, Aggregationen und Fenster aggregationen. Bei zustandsbehafteten Vorgängen wird der Zustand der aufgenommenen Daten über mehrere Zeilen oder Zeitintervalle hinweg beibehalten, um ein genaues Ergebnis zu berechnen.Verwenden der
APPENDSÄnderungsverlaufsfunktion, um angehängte Daten ab einem bestimmten Zeitpunkt zu verarbeiten.Verwenden der
CHANGESÄnderungsverlaufsfunktion, um geänderte Daten, einschließlich Anhänge und Mutationen, ab einem bestimmten Zeitpunkt zu verarbeiten, wenn Daten nach Pub/Sub exportiert werden.CHANGESwird jedoch nicht unterstützt, wenn ein zustandsbehafteter Vorgang verwendet wird.
Unterstützte zustandsbehaftete Vorgänge
Wenn Sie Support anfordern oder Feedback zu dieser Funktion geben möchten, senden Sie eine E-Mail an bq-continuous-queries-feedback@google.com.
Mit zustandsbehafteten Vorgängen können kontinuierliche Abfragen komplexe Analysen durchführen, bei denen Informationen über mehrere Zeilen oder Zeitintervalle hinweg beibehalten werden müssen. Während
zustandslose Funktionen jede Zeile unabhängig verarbeiten, behalten
zustandsbehaftete Vorgänge den Zustand der aufgenommenen Daten bei, um Funktionen wie JOINs, Aggregationen und
Fensteraggregationen zu unterstützen. Mit dieser Funktion können Sie Ereignisse aus verschiedenen Streams korrelieren oder Messwerte im Zeitverlauf berechnen, z. B. einen 30-Minuten-Durchschnitt, indem Sie die erforderlichen Daten während der Ausführung der Abfrage im Arbeitsspeicher speichern.
Kontinuierliche Abfragen unterstützen die folgenden zustandsbehafteten Vorgänge:
Autorisierung
Die Google Cloud Zugriffstokens , die beim Ausführen von Jobs für kontinuierliche Abfragen verwendet werden, haben eine Gültigkeitsdauer von zwei Tagen, wenn sie von einem Nutzerkonto generiert werden. Daher werden solche Jobs nach zwei Tagen beendet. Die von Dienstkonten generierten Zugriffstokens können länger ausgeführt werden, müssen aber dennoch die maximale Abfragelaufzeit einhalten. Weitere Informationen finden Sie unter Kontinuierliche Abfrage mit einem Dienstkonto ausführen.
Standorte
Eine Liste der unterstützten Regionen finden Sie unter Standorte für kontinuierliche BigQuery-Abfragen.
Beschränkungen
Kontinuierliche Abfragen unterliegen den folgenden Einschränkungen:
- Der Zustand der aufgenommenen Daten wird nur für die spezifischen
zustandsbehafteten Vorgänge in der Vorschau beibehalten.
Kontinuierliche Abfragen unterstützen jetzt zwar einige Arten von
JOIN-Vorgängen, Aggregationen und Fensteraggregationen, diese sind jedoch auf bestimmte zustandsbehaftete Vorgänge beschränkt. Nicht alle Arten von zustandsbehafteten Vorgängen werden unterstützt. Sie können die folgenden SQL-Funktionen nicht in einer kontinuierlichen Abfrage verwenden, es sei denn, sie sind als ein unterstützter zustandsbehafteter Vorgang aufgeführt:
Die folgenden Abfrage operatoren:
Andere BigQuery ML-Funktionen als die unter Unterstützte Funktionenaufgeführten
DDL-Anweisungen (Data Definition Language, Datendefinitionssprache)
DML-Anweisungen (Data Manipulation Language, Datenbearbeitungssprache) außer
INSERT.EXPORT DATA-Anweisungen, die nicht auf Bigtable, Pub/Sub oder Spanner ausgerichtet sind.
Kontinuierliche Abfragen unterstützen die folgenden Datenquellen nicht:
- Externe Tabellen.
- Ansichten des Informationsschemas.
- Verwaltete Apache Iceberg-Tabellen.
- Platzhaltertabellen.
- CDC-Upsert- Daten (Change Data Capture)
- Materialisierte Ansichten.
- Ansichten, die durch andere Einschränkungen für kontinuierliche Abfragen
definiert werden, z. B.
JOINVorgänge, Aggregatfunktionen, benutzerdefinierte Funktionen oder Tabellen, für die CDC aktiviert ist.
Kontinuierliche Abfragen unterstützen die column- Spalten- und Zeilenebene nicht.
Die Ausgabe einer kontinuierlichen Abfrage unterliegt den Quotas und Limits des Zieldienstes, in den die Ausgabe exportiert wird.
Wenn Sie Daten in Bigtable-, Spanner- oder Pub/Sub-Standortendpunkte exportieren, können Sie nur Bigtable-, Spanner- oder Pub/Sub-Ressourcen verwenden, die sich in derselben Google Cloud regionalen Grenze wie das BigQuery-Dataset befinden, das die Tabelle enthält, die Sie abfragen. Diese Einschränkung gilt nicht, wenn Sie Daten in globale Pub/Sub-Endpunkte exportieren. Weitere Informationen zum Exportieren in eine Bigtable-Anwendungsprofil Routingrichtlinie finden Sie unter Standortüberlegungen.
Sie können keine kontinuierliche Abfrage aus einem Data Canvas ausführen.
Sie können die in einer kontinuierlichen Abfrage verwendete SQL-Anweisung nicht ändern, während der Job für die kontinuierliche Abfrage ausgeführt wird. Weitere Informationen finden Sie unter SQL-Anweisung einer kontinuierlichen Abfrage ändern.
Wenn ein Job für eine kontinuierliche Abfrage bei der Verarbeitung eingehender Daten in Verzug gerät und eine Verzögerung des Ausgabewasserzeichens von mehr als 48 Stunden aufweist, schlägt er fehl. Sie können die Abfrage noch einmal ausführen und die
APPENDSoderCHANGESÄnderungsverlaufsfunktion verwenden, um die Verarbeitung ab dem Zeitpunkt fortzusetzen, an dem Sie den vorherigen Job für die kontinuierliche Abfrage beendet haben. Weitere Informationen finden Sie unter Kontinuierliche Abfrage ab einem bestimmten Zeitpunkt starten.Eine kontinuierliche Abfrage, die mit einem Nutzerkonto konfiguriert wurde, kann bis zu zwei Tage lang ausgeführt werden. Eine kontinuierliche Abfrage, die mit einem Dienstkonto konfiguriert wurde, kann bis zu 150 Tage lang ausgeführt werden. Wenn die maximale Abfragelaufzeit erreicht ist, schlägt die Abfrage fehl und die Verarbeitung eingehender Daten wird beendet.
Kontinuierliche Abfragen werden zwar mit den BigQuery Zuverlässigkeitsfunktionen erstellt, gelegentlich können jedoch vorübergehende Probleme auftreten. Probleme können zu einer automatischen Neuverarbeitung Ihrer kontinuierlichen Abfrage führen, was zu doppelten Daten in der Ausgabe der kontinuierlichen Abfrage führen kann. Entwerfen Sie Ihre nachgelagerten Systeme so, dass sie solche Szenarien verarbeiten können.
Reservierungseinschränkungen
- Sie müssen Reservierungen der Enterprise- oder Enterprise Plus Version erstellen, um kontinuierliche Abfragen auszuführen. Kontinuierliche Abfragen unterstützen das On-Demand-Abrechnungsmodell für die Compute-Nutzung nicht.
- Wenn Sie eine
CONTINUOUSReservierungszuweisung erstellen, ist die zugehörige Reservierung auf maximal 500 Slots beschränkt. Sie können eine Erhöhung dieses Limits unter bq-continuous-queries-feedback@google.com anfordern. - Sie können in derselben Reservierung keine Reservierungszuweisung erstellen, die einen anderen Jobtyp verwendet als eine Reservierungszuweisung für eine kontinuierliche Abfrage.
- Sie können die Nebenläufigkeit von kontinuierlichen Abfragen nicht konfigurieren. BigQuery bestimmt automatisch die Anzahl der kontinuierlichen Abfragen, die gleichzeitig ausgeführt werden können, basierend auf den verfügbaren Reservierungszuweisungen, die den Jobtyp
CONTINUOUSverwenden. - Wenn Sie mehrere kontinuierliche Abfragen mit derselben Reservierung ausführen, werden die verfügbaren Ressourcen möglicherweise nicht fair auf die einzelnen Jobs aufgeteilt, wie in der BigQuery-Fairness definiert.
Slot-Autoscaling
Kontinuierliche Abfragen können das Slot-Autoscaling verwenden, um die zugewiesene Kapazität dynamisch an die Arbeitslast anzupassen. Wenn die Arbeitslast Ihrer kontinuierlichen Abfragen steigt oder sinkt, passt BigQuery Ihre Slots dynamisch an.
Nachdem eine kontinuierliche Abfrage gestartet wurde, wartet sie aktiv auf eingehende Daten, wodurch Slot-Ressourcen verbraucht werden. Eine Reservierung mit einer ausgeführten kontinuierlichen Abfrage wird nicht auf null Slots herunterskaliert. Eine inaktive kontinuierliche Abfrage, die hauptsächlich auf eingehende Daten wartet, verbraucht jedoch nur eine minimale Anzahl von Slots, in der Regel etwa einen Slot.
Freigabe inaktiver Slots
Kontinuierliche Abfragen können die Freigabe inaktiver Slots verwenden, um nicht verwendete Slot-Ressourcen für andere Reservierungen und Jobtypen freizugeben.
- Für die Ausführung einer kontinuierlichen Abfrage ist weiterhin eine
CONTINUOUSReservierungszuweisung erforderlich. Sie kann nicht ausschließlich auf inaktive Slots aus anderen Reservierungen angewiesen sein. Daher erfordert eineCONTINUOUS-Reservierungszuweisung entweder eine Slot-Baseline ungleich null oder eine Slot-Autoscaling-Konfiguration ungleich null. - Nur inaktive Referenzslots oder zugesicherte Slots aus einer
CONTINUOUS-Reservierungszuweisung können freigegeben werden. Automatisch skalierte Slots können nicht als inaktive Slots für andere Reservierungen freigegeben werden.
Preise
Kontinuierliche Abfragen können die flexible Skalierung von BigQuery nutzen.
Für kontinuierliche Abfragen gelten die
BigQuery-Preise für die Compute-Kapazität,
die in Slotsgemessen wird.
Zum Ausführen kontinuierlicher Abfragen benötigen Sie eine
Reservierung mit dem
Enterprise oder Enterprise Plus,
und eine Reservierungszuweisung
mit dem CONTINUOUS Jobtyp.
Die Nutzung anderer BigQuery-Ressourcen wie Datenaufnahme und Speicherung wird zu den Preisen berechnet, die unter BigQuery-Preise aufgeführt sind.
Die Nutzung anderer Dienste, die Ergebnisse von kontinuierlichen Abfragen erhalten oder während der Verarbeitung von kontinuierlichen Abfragen aufgerufen werden, wird zu den für diese Dienste veröffentlichten Preisen berechnet. Informationen zu den Preisen für andere Google Cloud Dienste, die von kontinuierlichen Abfragen verwendet werden, finden Sie in den folgenden Themen:
Nächste Schritte
Versuchen Sie, eine kontinuierliche Abfrage zu erstellen.