
Use nested and repeated fields
BigQuery can be used with many different data modeling methods, and generally provides high performance across many data model methodologies. To further tune a data model for performance, one method you might consider is data denormalization, which means adding columns of data to a single table to reduce or remove table joins.
Best practice: Use nested and repeated fields to denormalize data storage and increase query performance.
Denormalization is a common strategy for increasing read performance for relational datasets that were previously normalized. The recommended way to denormalize data in BigQuery is to use nested and repeated fields. It's best to use this strategy when the relationships are hierarchical and frequently queried together, such as in parent-child relationships.
The storage savings from using normalized data has less of an effect in modern systems. Increases in storage costs are worth the performance gains of using denormalized data. Joins require data coordination (communication bandwidth). Denormalization localizes the data to individual slots, so that execution can be done in parallel.
To maintain relationships while denormalizing your data, you can use nested and repeated fields instead of completely flattening your data. When relational data is completely flattened, network communication (shuffling) can negatively impact query performance.
For example, denormalizing an orders schema without using nested and repeated
fields might require you to group the data by a field like order_id
(when there is a one-to-many relationship). Because of the shuffling involved,
grouping the data is less effective than denormalizing the data by using
nested and repeated fields.
In some circumstances, denormalizing your data and using nested and repeated fields doesn't result in increased performance. For example, star schemas are typically optimized schemas for analytics, and as a result, performance might not be significantly different if you attempt to denormalize further.
Using nested and repeated fields
BigQuery doesn't require a completely flat denormalization. You can use nested and repeated fields to maintain relationships.
Nesting data (
STRUCT)- Nesting data lets you represent foreign entities inline.
- Querying nested data uses "dot" syntax to reference leaf fields, which is similar to the syntax using a join.
- Nested data is represented as a
STRUCTtype in GoogleSQL.
Repeated data (
ARRAY)- Creating a field of type
RECORDwith the mode set toREPEATEDlets you preserve a one-to-many relationship inline (so long as the relationship isn't high cardinality). - With repeated data, shuffling is not necessary.
- Repeated data is represented as an
ARRAY. You can use anARRAYfunction in GoogleSQL when you query the repeated data.
- Creating a field of type
Nested and repeated data (
ARRAYofSTRUCTs)- Nesting and repetition complement each other.
- For example, in a table of transaction records, you could include an array
of line item
STRUCTs.
For more information, see Specify nested and repeated columns in table schemas.
For more information about denormalizing data, see Denormalization.
Example
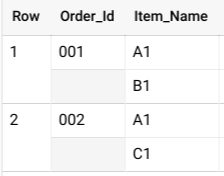
Consider an Orders table with a row for each line item sold:
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
If you wanted to analyze data from this table, you would need to use a
GROUP BY clause, similar to the following:
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
The GROUP BY clause involves additional computation overhead, but this can be
avoided by nesting repeated data. You can avoid using a GROUP BY clause
by creating a table with one order per row, where the order line items are in a
nested field:
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
In BigQuery, you typically specify a nested schema as an ARRAY
of STRUCT objects. You use the
UNNEST operator
to flatten the nested data,
as shown in the following query:
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
This query yields results similar to the following:
If this data wasn't nested, you could potentially have several rows for
each order, one for each item sold in that order, which would result in a
large table and an expensive GROUP BY operation.
Exercise
You can see the performance difference in queries that use nested fields as compared to those that don't by following the steps in this section.
Create a table based on the
bigquery-public-data.stackoverflow.commentspublic dataset:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
Using the
stackoverflowtable, run the following query to see the earliest comment for each user:SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
This query takes about 25 seconds to run and processes 1.88 GB of data.
Create a second table with identical data that creates a
commentsfield using aSTRUCTtype to store thepost_idandcreation_datedata, instead of two individual fields:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
Using the
stackoverflow_nestedtable, run the following query to see the earliest comment for each user:SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
This query takes about 10 seconds to run and processes 1.28 GB of data.
Delete the
stackoverflowandstackoverflow_nestedtables when you are finished with them.