
במאמר הזה מוצגת ארכיטקטורת הפניה שתעזור לכם לתכנן תשתית לאפליקציות של AI גנרטיבי מבוסס GraphRAG ב- Google Cloud. קהל היעד כולל אדריכלים, מפתחים ואדמינים שיוצרים ומנהלים מערכות חכמות לאחזור מידע. ההנחה במסמך הזה היא שיש לכם הבנה בסיסית במושגי AI, בניהול נתונים גרפיים ובתרשים ידע. במסמך הזה לא מפורטות הנחיות ספציפיות לעיצוב ולפיתוח של אפליקציות GraphRAG.
GraphRAG היא גישה מבוססת-גרף ל-Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG). טכנולוגיית RAG עוזרת לעגן תשובות שנוצרו על ידי AI על ידי הוספת נתונים רלוונטיים להקשר להנחיות, שמאוחזרים באמצעות חיפוש וקטורי. GraphRAG משלב חיפוש וקטורי עם שאילתה של תרשים ידע כדי לאחזר נתונים הקשריים שמשקפים טוב יותר את הקשרים בין נתונים ממקורות מגוונים. הנחיות שמשופרות באמצעות GraphRAG יכולות ליצור תשובות מפורטות ורלוונטיות יותר מ-AI.
ארכיטקטורה
התרשים הבא מציג ארכיטקטורה של אפליקציית AI גנרטיבי עם יכולות GraphRAG ב- Google Cloud:
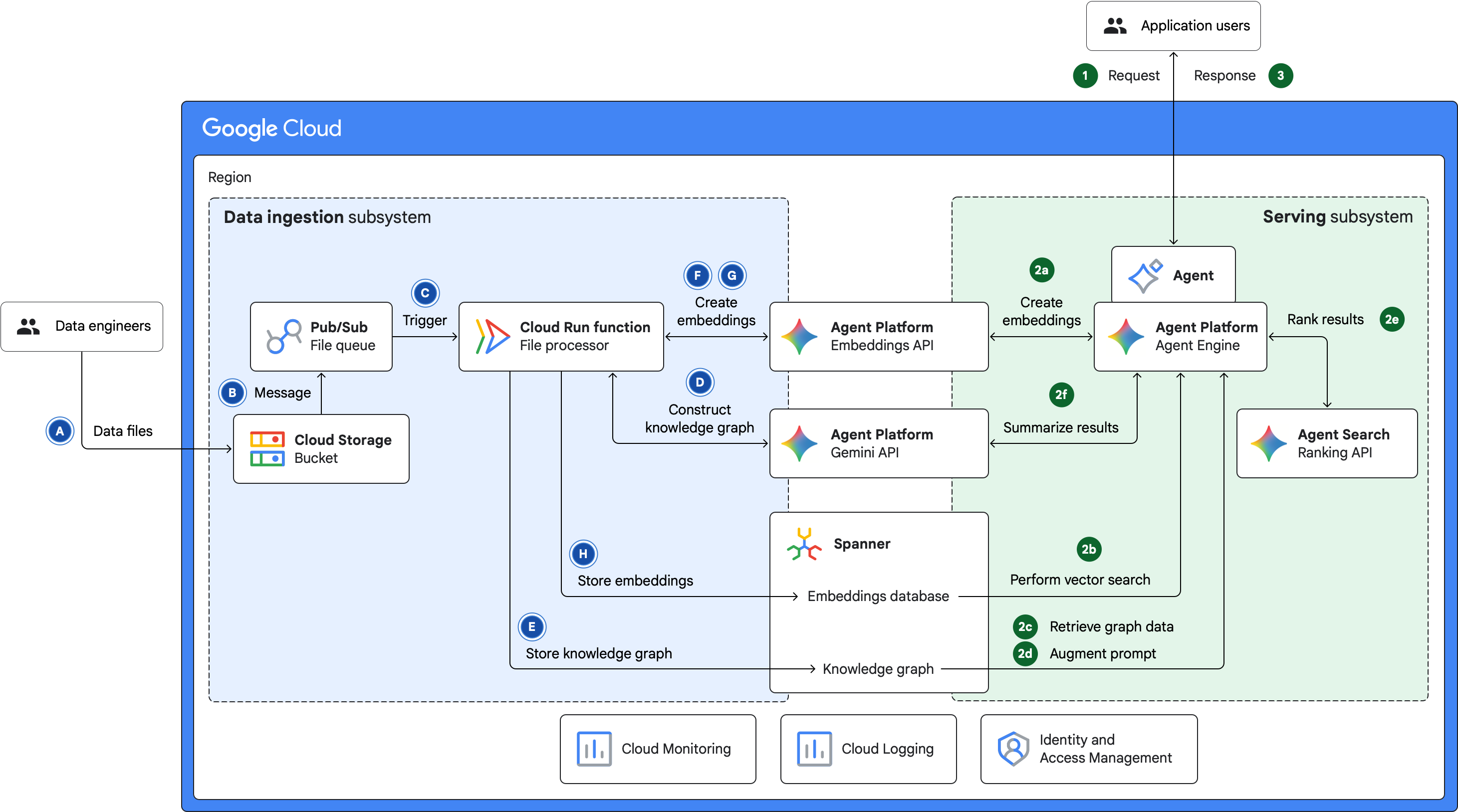
הארכיטקטורה בתרשים הקודם מורכבת משתי מערכות משנה: קליטת נתונים והצגת נתונים. בקטעים הבאים מתואר הייעוד של מערכות המשנה וזרימת הנתונים בתוך מערכות המשנה ובמעבר ביניהן.
מערכת משנה להטמעת נתונים
מערכת המשנה להטמעת נתונים מטמיעה נתונים ממקורות חיצוניים ואז מכינה את הנתונים ל-GraphRAG. תהליך הטמעת הנתונים וההכנה כולל את השלבים הבאים:
- הנתונים מוזנים לקטגוריה של Cloud Storage. אפשר להעלות את הנתונים האלה על ידי אנליסט נתונים, להטמיע אותם ממסד נתונים או להזרים אותם מכל מקור.
- כשנתונים מוזנים, הודעה נשלחת לנושא Pub/Sub.
- Pub/Sub מפעיל פונקציית Cloud Run כדי לעבד את הנתונים שהועלו.
- פונקציית Cloud Run יוצרת גרף ידע מקובצי הקלט באמצעות Gemini API וכלים כמו
LLMGraphTransformerשל LangChain. - הפונקציה מאחסנת את תרשים הידע במסד נתונים של Spanner Graph.
- הפונקציה מפצלת את התוכן הטקסטואלי של קובצי הנתונים ליחידות גרנולריות באמצעות כלים כמו
RecursiveCharacterTextSplitterשל LangChain או Layout Parser של Document AI. - הפונקציה יוצרת הטמעות וקטוריות של פלחי הטקסט באמצעות ממשקי ה-API של Gemini Enterprise Agent Platform Embeddings.
- הפונקציה מאחסנת את הטמעות הווקטורים ואת צמתי הגרף המשויכים ב-Spanner Graph.
הטמעות הווקטוריות משמשות כבסיס לאחזור סמנטי. הצמתים של גרף הידע מאפשרים מעבר בין קשרים מורכבים של נתונים ודפוסים וניתוח שלהם.
מערכת משנה להצגת מודעות
מערכת המשנה להצגת תוצאות מנהלת את מחזור החיים של השאילתה והתשובה בין אפליקציית ה-AI הגנרטיבי לבין המשתמשים שלה. תהליך הצגת המודעות כולל את השלבים הבאים:
- משתמש שולח שאילתה בשפה טבעית לסוכן AI שנפרס ב-Agent Runtime ב-Gemini Enterprise Agent Platform.
- הסוכן מעבד את השאילתה באופן הבא:
- המרת השאילתה להטמעות וקטוריות באמצעות ממשקי ה-API של Agent Platform Embeddings.
- שליפת צמתי תרשים שקשורים לשאילתה על ידי ביצוע חיפוש דמיון וקטורי במסד הנתונים של ההטמעות.
- אחזור נתונים שקשורים לשאילתה על ידי מעבר על גרף הידע.
- משפר את ההנחיה על ידי שילוב השאילתה המקורית עם נתוני הגרף שאוחזרו.
- הוא משתמש ב-Agent Search ranking API כדי לדרג את התוצאות, שמורכבות מצמתים וקשתות שנשלפים ממסד הנתונים הגרפי. הדירוג מבוסס על רלוונטיות סמנטית לשאילתה.
- מסכם את התוצאות באמצעות קריאה ל-Gemini API.
- הסוכן שולח למשתמש את התוצאה המסוכמת.
אתם יכולים לאחסן ולצפות ביומני פעילות של שאילתות ותשובות ב-Cloud Logging, ולהגדיר מעקב מבוסס-יומנים באמצעות Cloud Monitoring.
המוצרים שהשתמשו בהם
ארכיטקטורת ההפניה הזו משתמשת במוצרים ובכלים הבאים של Google:
- Spanner Graph: מסד נתונים של גרפים שמספק את התכונות של מדרגיות, זמינות ועקביות של Spanner.
- Gemini Enterprise Agent Platform: פלטפורמה מקיפה שמאפשרת לכם ליצור סוכני AI ברמה ארגונית, להרחיב את השימוש בהם, לנהל אותם ולבצע אופטימיזציה שלהם.
- פונקציות Cloud Run: פלטפורמת מחשוב ללא שרת שמאפשרת להריץ פונקציות חד-מטרה ישירות ב- Google Cloud.
- Cloud Storage: מאגר אובייקטים ללא הגבלה בעלות נמוכה, לשימוש עם סוגים שונים של נתונים. אפשר לגשת לנתונים מתוך Google Cloudומחוץ להם, והם משוכפלים במיקומים שונים כדי ליצור יתירות.
- Pub/Sub: שירות העברת הודעות אסינכרוני וניתן להרחבה, שמפריד בין שירותים שמפיקים הודעות לבין שירותים שמבצעים עיבוד של ההודעות האלה.
- Cloud Logging: מערכת לניהול יומנים בזמן אמת עם אחסון, חיפוש, ניתוח והתראות.
- Cloud Monitoring: שירות שמאפשר לראות את הביצועים, הזמינות והתקינות של האפליקציות והתשתית שלכם.
תרחישים לדוגמה
GraphRAG מאפשר שליפה חכמה של נתונים לתרחישי שימוש בתעשיות שונות. בקטע הזה מתוארים כמה תרחישי שימוש בתחומי הבריאות, הפיננסים, השירותים המשפטיים והייצור.
שירותי בריאות ותרופות: תמיכה בקבלת החלטות רפואיות
במערכות לתמיכה בקבלת החלטות קליניות לאבחון רפואי, GraphRAG משלב כמויות עצומות של נתונים ממאמרים רפואיים, מתיקים רפואיים אלקטרוניים של מטופלים, ממסדי נתונים של אינטראקציות בין תרופות ומתוצאות של ניסויים קליניים לתוך גרף ידע מאוחד. כשרופאים וחוקרים שולחים שאילתה לגבי תסמינים של מטופל ותרופות שהוא נוטל כרגע, מערכת GraphRAG סורקת את תרשים הידע כדי לזהות מצבים רלוונטיים ואינטראקציות פוטנציאליות בין תרופות. הוא יכול גם ליצור המלצות לטיפול בהתאמה אישית על סמך נתונים אחרים, כמו הפרופיל הגנטי של המטופל. סוג כזה של אחזור מידע מספק תשובות עשירות יותר בהקשר ומבוססות על ראיות, בהשוואה להתאמה למילות מפתח.
שירותים פיננסיים: איחוד נתונים פיננסיים
חברות שמספקות שירותים פיננסיים משתמשות בתרשימי ידע כדי לספק לאנליסטים שלהן תצוגה מאוחדת ומובנית של נתונים ממקורות שונים, כמו דוחות אנליסטים, שיחות בנושא רווחים והערכות סיכונים. גרפים של ידע מזהים ישויות נתונים מרכזיות כמו חברות ומנהלים, וממפים את הקשרים החשובים בין הישויות. הגישה הזו מספקת רשת עשירה ומקושרת של נתונים, שמאפשרת ניתוח פיננסי מעמיק ויעיל יותר. אנליסטים יכולים לגלות תובנות שהיו חבויות עד עכשיו, כמו תלות מורכבת בשרשרת האספקה, חברות בדירקטוריונים שחופפות בין מתחרים וחשיפה לסיכונים גיאופוליטיים מורכבים.
שירותים משפטיים: מחקר מקרים וניתוח תקדימים
במגזר המשפטי, אפשר להשתמש ב-GraphRAG כדי ליצור המלצות משפטיות מותאמות אישית על סמך תקדימים, חוקים, פסיקות, עדכונים רגולטוריים ומסמכים פנימיים. כשעורכי דין מתכוננים לתיקים, הם יכולים לשאול שאלות מורכבות על טיעונים משפטיים ספציפיים, על פסיקות קודמות בתיקים דומים או על ההשלכות של חקיקה חדשה. GraphRAG מנצל את הקשרים ההדדיים בין מקורות הידע המשפטיים הזמינים כדי לזהות תקדימים רלוונטיים ולהסביר את הרלוונטיות שלהם. הוא יכול גם להציע טיעוני נגד על ידי מעקב אחרי הקשרים בין מושגים משפטיים, חוקים ופרשנויות שיפוטיות. הגישה הזו מאפשרת לאנשי מקצוע בתחום המשפטים לקבל תובנות מקיפות ומדויקות יותר מאשר בשיטות רגילות לאחזור מידע.
ייצור ושרשרת אספקה: גישה לידע מוסדי
פעולות ייצור ושרשרת אספקה מצריכות רמה גבוהה של דיוק. הידע שנדרש כדי לשמור על רמת הדיוק הנדרשת לרוב קבור באלפי מסמכים צפופים וסטטיים של נוהלי הפעלה סטנדרטיים (SOP). כשפס ייצור או מכונה במפעל נכשלים, או אם מתרחשת בעיה לוגיסטית, מהנדסים וטכנאים מבזבזים הרבה זמן יקר בחיפוש במסמכי PDF לא מקושרים כדי לאבחן את הבעיה ולפתור אותה. אפשר לשלב בין Knowledge Graph ו-AI בממשק שיחה כדי להפוך ידע מוסדי מוצפן לשותף אינטראקטיבי לאבחון.
חלופות עיצוב
הארכיטקטורה שמתוארת במסמך הזה היא מודולרית. אתם יכולים להתאים רכיבים מסוימים בארכיטקטורה כדי להשתמש במוצרים, בכלים ובטכנולוגיות חלופיים בהתאם לדרישות שלכם.
יצירת תרשים הידע
אתם יכולים להשתמש בכלי LLMGraphTransformer של LangChain כדי ליצור תרשים ידע מאפס. אם מציינים את סכימת הגרף עם פרמטרים כמו LLMGraphTransformer, allowed_nodes, allowed_relationships ו-relationship_properties, אפשר לשפר את האיכות של גרף הידע שמתקבל.node_properties עם זאת, יכול להיות ש-LLMGraphTransformer יחלץ ישויות מדומיינים כלליים, ולכן הוא לא מתאים לדומיינים נישתיים כמו בריאות או תרופות. בנוסף, אם לארגון שלכם כבר יש תהליך חזק לבניית תרשימי ידע, אז מערכת המשנה להזנת נתונים שמוצגת בארכיטקטורת ההפניה הזו היא אופציונלית.
אחסון של Knowledge Graph והטמעות וקטוריות
הארכיטקטורה שמתוארת במסמך הזה משתמשת ב-Spanner כמאגר הנתונים של גרף הידע ושל הטמעות הווקטורים. אם הגרפים של הידע הארגוני שלכם כבר קיימים במקום אחר (למשל בפלטפורמה כמו Neo4j), כדאי לשקול שימוש במסד נתונים וקטורי להטמעות. עם זאת, הגישה הזו דורשת מאמץ ניהולי נוסף ועשויה להיות יקרה יותר. Spanner מספק מאגר נתונים מאוחד ועקבי ברמה הגלובלית, גם למבני גרפים וגם להטמעות וקטוריות. מאגר נתונים כזה מאפשר ניהול נתונים מאוחד, שעוזר לבצע אופטימיזציה של העלויות, הביצועים, האבטחה, השליטה והיעילות התפעולית.
זמן הריצה של הסוכן
באדריכלות ההפניה הזו, הסוכן נפרס ב-Agent Runtime, שמספק זמן ריצה מנוהל לסוכני AI. אפשרויות נוספות שכדאי לשקול כוללות את Cloud Run ואת Google Kubernetes Engine (GKE). הסבר על האפשרויות האלה לא נכלל במסמך הזה.
עיגון בנתונים באמצעות RAG
כפי שצוין בקטע תרחישים לדוגמה, GraphRAG מאפשר אחזור חכם של נתונים לצורך ביסוס במגוון תרחישים. עם זאת, אם לנתוני המקור שבהם אתם משתמשים כדי להוסיף מידע להנחיות אין קשרים מורכבים, יכול להיות ש-RAG היא בחירה מתאימה לאפליקציית ה-AI הגנרטיבי שלכם.
בארכיטקטורות ההפניה הבאות מוצגות דרכים לבניית התשתית שנדרשת ל-RAG ב- Google Cloud באמצעות מסדי נתונים מנוהלים עם תמיכה בווקטורים או מוצרים ייעודיים לחיפוש וקטורים:
- תשתית RAG ל-AI גנרטיבי באמצעות Agent Platform ו-Vector Search
- תשתית RAG ל-AI גנרטיבי באמצעות Agent Platform ו-AlloyDB ל-PostgreSQL
- תשתית RAG ל-AI גנרטיבי באמצעות GKE ו-Cloud SQL
- תשתית RAG ל-AI גנרטיבי באמצעות Gemini Enterprise ו-Agent Platform.
שיקולים בתכנון
בקטע הזה מפורטים גורמים שצריך לקחת בחשבון בתכנון, שיטות מומלצות והמלצות לשימוש בארכיטקטורת ההפניה הזו כדי לפתח טופולוגיה שעונה על הדרישות הספציפיות שלכם בנוגע לאבטחה, למהימנות, לעלות ולביצועים.
ההנחיות בקטע הזה הן חלקיות. בהתאם לדרישות של עומס העבודה ולמוצרים ולתכונות של צד שלישי שבהם אתם משתמשים, יכול להיות שיש עוד גורמים עיצוביים ושיקולים שצריך לקחת בחשבון. Google Cloud
אבטחה, פרטיות ותאימות
בקטע הזה מפורטים שיקולים והמלצות לתכנון טופולוגיה ב- Google Cloud שעומדת בדרישות האבטחה והתאימות של עומס העבודה.
| מוצר | שיקולים והמלצות לגבי עיצוב |
|---|---|
| Agent Platform | פלטפורמת Agent תומכת באמצעי בקרה לאבטחה Google Cloud שבהם אפשר להשתמש כדי לעמוד בדרישות שלכם בנוגע למיקום הנתונים, להצפנת הנתונים, לאבטחת הרשת ולשקיפות הגישה. מידע נוסף זמין במשאבי העזרה הבאים:
מודלים של AI גנרטיבי עשויים להפיק תשובות מזיקות, במיוחד אם הם מקבלים הנחיות מפורשות ליצור תשובות כאלה. כדי לשפר את הבטיחות ולצמצם את הסיכון לשימוש לרעה, אתם יכולים להגדיר מסנני תוכן שימנעו תשובות מזיקות. מידע נוסף זמין במאמר בנושא מסנני בטיחות ותוכן. |
| Spanner Graph | כברירת מחדל, הנתונים שמאוחסנים ב-Spanner Graph מוצפנים באמצעות Google-owned and Google-managed encryption keys. אם אתם צריכים להשתמש במפתחות הצפנה שאתם שולטים בהם ומנהלים אותם, אתם יכולים להשתמש במפתחות הצפנה בניהול הלקוח (CMEK). מידע נוסף זמין במאמר מידע על CMEK. |
| פונקציות Cloud Run | כברירת מחדל, Cloud Run מצפין נתונים באמצעות Google-owned and Google-managed encryption keys. כדי להגן על הקונטיינרים באמצעות מפתחות שאתם שולטים בהם, אתם יכולים להשתמש במפתחות הצפנה בניהול הלקוח (CMEK). מידע נוסף זמין במאמר בנושא שימוש במפתחות הצפנה בניהול הלקוח. כדי לוודא שרק קובצי אימג' מורשים של קונטיינרים נפרסים ב-Cloud Run, אפשר להשתמש ב-Binary Authorization. Cloud Run עוזר לכם לעמוד בדרישות של מיקום אחסון הנתונים. פונקציות Cloud Run פועלות באזור שבחרתם. |
| Cloud Storage |
כברירת מחדל, הנתונים שמאוחסנים ב-Cloud Storage מוצפנים באמצעות Google-owned and Google-managed encryption keys. אם נדרש, אפשר להשתמש במפתחות CMEK או במפתחות משלכם שאתם מנהלים באמצעות שיטת ניהול חיצונית, כמו מפתחות הצפנה באספקת הלקוח (CSEK). מידע נוסף זמין במאמר אפשרויות להצפנת נתונים. Cloud Storage תומך בשתי שיטות להענקת גישה למשתמשים לקטגוריות ולאובייקטים: ניהול זהויות והרשאות גישה (IAM) ורשימות של בקרת גישה (ACL). ברוב המקרים מומלץ להשתמש ב-IAM, שמאפשר לתת הרשאות ברמת הקטגוריה והפרויקט. מידע נוסף מופיע במאמר סקירה כללית על בקרת הגישה. הנתונים שאתם טוענים למערכת המשנה להטמעת נתונים דרך Cloud Storage עשויים לכלול מידע אישי רגיש. אפשר להשתמש ב-Sensitive Data Protection כדי לגלות, לסווג ולבטל את הזיהוי של מידע רגיש. מידע נוסף זמין במאמר בנושא שימוש ב-Sensitive Data Protection עם Cloud Storage. Cloud Storage עוזר לכם לעמוד בדרישות של מיקום אחסון הנתונים. הנתונים מאוחסנים או משוכפלים באזור שאתם מציינים. |
| Pub/Sub | כברירת מחדל, כל ההודעות ב-Pub/Sub מוצפנות גם כשהן נשמרות וגם כשהן נשלחות, באמצעות Google-owned and Google-managed encryption keys. Pub/Sub תומך בשימוש במפתחות CMEK להצפנת הודעות בשכבת האפליקציה. מידע נוסף זמין במאמר בנושא הגדרת הצפנת הודעות. אם יש לכם דרישות לגבי מיקום אחסון הנתונים, כדי לוודא שנתוני ההודעות מאוחסנים במיקומים ספציפיים, אתם יכולים להגדיר מדיניות לאחסון הודעות. |
| Cloud Logging | יומני הביקורת של פעילות האדמין מופעלים כברירת מחדל לכל השירותים של Google Cloud שנעשה בהם שימוש בארכיטקטורת ההפניה הזו. היומנים האלה מתעדים קריאות ל-API או פעולות אחרות שמשנות את ההגדרות או את המטא-נתונים שלGoogle Cloud משאבים. בשירותים Google Cloud שמשמשים בארכיטקטורה הזו, אפשר להפעיל יומני ביקורת לגבי גישה לנתונים. היומנים האלה מאפשרים לכם לעקוב אחרי קריאות ל-API שקוראות את ההגדרות או את המטא-נתונים של משאבים, או אחרי בקשות של משתמשים ליצור, לשנות או לקרוא נתוני משאבים שסופקו על ידי משתמשים. כדי לעמוד בדרישות של מיקום אחסון הנתונים, אתם יכולים להגדיר את Cloud Logging כך שנתוני היומנים יאוחסנו באזור שתציינו. מידע נוסף מופיע במאמר הגדרת אזור ליומנים. |
עקרונות והמלצות אבטחה שספציפיים לעומסי עבודה של AI ו-ML מפורטים במאמר AI and ML perspective: Security ב- Google Cloud Well-Architected Framework.
אמינות
בקטע הזה מפורטים שיקולים והמלצות לתכנון ולתפעול של תשתית אמינה לפריסה ב- Google Cloud.
| מוצר | שיקולים והמלצות לגבי עיצוב |
|---|---|
| Agent Platform | אם מספר הבקשות חורג מהקיבולת שהוקצתה, מוחזר קוד השגיאה 429. עבור עומסי עבודה שהם קריטיים לעסק ודורשים באופן עקבי תפוקה גבוהה, אפשר להזמין תפוקה באמצעות הקצאת משאבים לפי התפוקה שנקבעה. אם אפשר לשתף נתונים בין כמה אזורים או מדינות, אפשר להשתמש בנקודת קצה גלובלית. |
| Spanner Graph | Spanner מיועד לזמינות גבוהה של נתונים ולמדרגיות גלובלית. כדי להבטיח זמינות גם במהלך הפסקת חשמל באזור מסוים, ב-Spanner מוצעים הגדרות של כמה אזורים, שמשכפלות נתונים בכמה אזורים בכמה אזורים. בנוסף ליכולות המובנות של חוסן (resilience), Spanner מספק את התכונות הבאות לתמיכה באסטרטגיות מקיפות של תוכנית התאוששות מאסון (DR):
מידע נוסף זמין במאמר סקירה כללית על תוכנית התאוששות מאסון (DR). |
| פונקציות Cloud Run | Cloud Run הוא שירות אזורי. הנתונים מאוחסנים באופן סינכרוני בכמה אזורים בתוך אזור. תעבורת הנתונים מאוזנת אוטומטית בין האזורים. אם מתרחש הפסקת חשמל באזור, Cloud Run ממשיך לפעול והנתונים לא אובדים. אם מתרחש שיבוש באזור מסוים, השירות מפסיק לפעול עד ש-Google פותרת את השיבוש. |
| Cloud Storage | אפשר ליצור קטגוריות של Cloud Storage באחד משלושת סוגי המיקומים: אזורי, בשני אזורים או במספר אזורים. נתונים שמאוחסנים בקטגוריות אזוריות משוכפלים באופן סינכרוני בכמה אזורים בתוך אזור. כדי להשיג זמינות גבוהה יותר, אפשר להשתמש בקטגוריות בשני אזורים או במספר אזורים, שבהן הנתונים משוכפלים באופן אסינכרוני בין האזורים. |
| Pub/Sub | כדי למנוע שגיאות בתקופות של עליות זמניות בתנועת ההודעות, אפשר להגביל את קצב הבקשות לפרסום על ידי הגדרת בקרת זרימה בהגדרות של המוציא לאור. כדי לטפל בניסיונות פרסום שנכשלו, משנים את המשתנים של בקשת הניסיון החוזר לפי הצורך. מידע נוסף זמין במאמר בנושא ניסיון חוזר לשליחת בקשות. |
| כל המוצרים בארכיטקטורה | אחרי שפורסים את עומס העבודה ב- Google Cloud, אפשר להשתמש ב-Active Assist כדי לקבל המלצות לאופטימיזציה נוספת של המהימנות של משאבי הענן. בודקים את ההמלצות ומיישמים אותן בהתאם לסביבה שלכם. איך מוצאים המלצות ב-Active Assist |
עקרונות והמלצות בנושא מהימנות שספציפיים לעומסי עבודה של AI ו-ML מפורטים במאמר AI and ML perspective: Reliability (נקודת מבט על AI ו-ML: מהימנות) ב-Well-Architected Framework.
הוזלת עלויות
בקטע הזה מוסבר איך לבצע אופטימיזציה של העלות של הגדרת טופולוגיה של Google Cloud והפעלתה, שאתם בונים באמצעות ארכיטקטורת ההפניה הזו.
| מוצר | שיקולים והמלצות לגבי עיצוב |
|---|---|
| Agent Platform | כדי לנתח ולנהל את העלויות של Agent Platform, מומלץ ליצור בסיס של שאילתות לשנייה (QPS) וטוקנים לשנייה (TPS) ולעקוב אחרי המדדים האלה אחרי הפריסה. ערך הבסיס עוזר גם בתכנון הקיבולת. לדוגמה, ערך הבסיס עוזר לכם לקבוע מתי נדרש הקצאת משאבים לפי התפוקה שנקבעה. בחירת המודל המתאים לאפליקציית ה-AI הגנרטיבי היא החלטה קריטית שמשפיעה ישירות על העלויות ועל הביצועים. כדי לזהות את המודל שמספק את האיזון האופטימלי בין ביצועים לעלות בתרחיש השימוש הספציפי שלכם, מומלץ לבדוק מודלים באופן איטרטיבי. מומלץ להתחיל עם המודל הכי חסכוני ולעבור בהדרגה לאפשרויות מתקדמות יותר. האורך של ההנחיות (הקלט) והתשובות שנוצרות (הפלט) משפיע ישירות על הביצועים והעלות. לכתוב הנחיות קצרות וישירות שמספקות הקשר מספיק. כדאי לעצב את ההנחיות כדי לקבל מהמודל תשובות תמציתיות. לדוגמה, אפשר להוסיף ביטויים כמו "סכם ב-2 משפטים" או "ציין 3 נקודות עיקריות". מידע נוסף זמין במאמר בנושא שיטות מומלצות ליצירת הנחיות. כדי להפחית את העלות של בקשות שמכילות תוכן חוזר עם מספר גבוה של טוקנים של קלט, אפשר להשתמש בשמירת מטמון של ההקשר. אם רלוונטי, כדאי להשתמש בחיזויים רבים בבת אחת. בקשות באצווה מחויבות במחיר נמוך יותר מבקשות רגילות. |
| Spanner Graph | אפשר להשתמש בכלי לשינוי גודל אוטומטי מנוהל כדי לשנות באופן דינמי את קיבולת החישוב של מסדי נתונים של Spanner Graph על סמך השימוש במעבד וצרכי האחסון. לעתים קרובות נדרשת קיבולת מינימלית, גם לעומסי עבודה קטנים. כדי לקבל הנחות על קיבולת צפויה, יציבה או בסיסית של מחשוב, כדאי לרכוש הנחות תמורת התחייבות לשימוש (CUD). הנחות תמורת התחייבות לשימוש (CUD) מאפשרות לקבל הנחות משמעותיות בתמורה להתחייבות להוצאה של סכום מסוים לשעה על קיבולת מחשוב. כשמעתיקים גיבויים לאזורים שונים לצורך תוכנית התאוששות מאסון (DR) או לצורך תאימות, צריך לקחת בחשבון את עלויות תעבורת הנתונים היוצאת (egress). כדי לצמצם את העלויות, כדאי להעתיק רק את הגיבויים החיוניים. |
| פונקציות Cloud Run | כשיוצרים פונקציות Cloud Run, אפשר לציין את כמות הזיכרון והמעבד (CPU) שיוקצו. כדי לשלוט בעלויות, כדאי להתחיל עם הקצאות ברירת המחדל (המינימליות) של מעבד וזיכרון. כדי לשפר את הביצועים, אפשר להגדיל את ההקצאה על ידי הגדרת מגבלת המעבד ומגבלת הזיכרון. מידע נוסף זמין במאמרי העזרה הבאים: אם אתם יכולים לחזות את הדרישות של יחידת העיבוד המרכזית (CPU) והזיכרון, אתם יכולים לחסוך כסף באמצעות CUD. |
| Cloud Storage | לקטגוריית Cloud Storage במערכת המשנה של העברת הנתונים, בוחרים סוג אחסון (storage class) מתאים על סמך הדרישות של עומס העבודה לגבי שימור נתונים ותדירות הגישה. לדוגמה, כדי לשלוט בעלויות האחסון, אפשר לבחור את סוג האחסון Standard ולהשתמש ב ניהול מחזור החיים של אובייקטים. הגישה הזו מאפשרת להוריד באופן אוטומטי את הסיווג של אובייקטים לסיווג אחסון בעלות נמוכה יותר, או למחוק אובייקטים באופן אוטומטי על סמך תנאים שצוינו. |
| Cloud Logging | כדי לשלוט בעלות של אחסון יומנים, אפשר:
|
| כל המוצרים בארכיטקטורה | אחרי שפורסים את עומס העבודה ב- Google Cloud, אפשר להשתמש ב-Active Assist כדי לקבל המלצות לאופטימיזציה נוספת של עלויות המשאבים בענן. בודקים את ההמלצות ומיישמים אותן בהתאם לסביבה שלכם. איך מוצאים המלצות ב-Active Assist |
כדי להעריך את העלות של המשאבים ב- Google Cloud , אתם יכולים להשתמש בGoogle Cloud מחשבון עלויות.
עקרונות והמלצות לאופטימיזציה של עלויות שספציפיים לעומסי עבודה של AI ו-ML מפורטים במאמר AI and ML perspective: Cost optimization ב-Well-Architected Framework.
אופטימיזציה של הביצועים
בקטע הזה מפורטים שיקולים והמלצות לתכנון טופולוגיה ב- Google Cloud שעומדת בדרישות הביצועים של עומסי העבודה.
| מוצר | שיקולים והמלצות לגבי עיצוב |
|---|---|
| Agent Platform |
בחירת המודל המתאים לאפליקציית ה-AI הגנרטיבי היא החלטה קריטית שמשפיעה ישירות על העלויות ועל הביצועים. כדי לזהות את המודל שמספק את האיזון האופטימלי בין ביצועים לעלות בתרחיש השימוש הספציפי שלכם, מומלץ לבדוק מודלים באופן איטרטיבי. מומלץ להתחיל עם המודל הכי חסכוני ולעבור בהדרגה לאפשרויות מתקדמות יותר. האורך של ההנחיות (הקלט) והתשובות שנוצרות (הפלט) משפיע ישירות על הביצועים והעלות. לכתוב הנחיות קצרות וישירות שמספקות הקשר מספיק. כדאי לעצב את ההנחיות כדי לקבל מהמודל תשובות תמציתיות. לדוגמה, אפשר להוסיף ביטויים כמו "סכם ב-2 משפטים" או "ציין 3 נקודות עיקריות". מידע נוסף זמין במאמר בנושא שיטות מומלצות ליצירת הנחיות. הכלי לאופטימיזציה של פרומפטים ב-Agent Platform מאפשר לשפר ולייעל במהירות את הביצועים של הפרומפטים בהיקף נרחב, ומבטל את הצורך בשכתוב ידני. הכלי לאופטימיזציה עוזר לכם להתאים הנחיות ביעילות בין מודלים שונים. |
| Spanner Graph | המלצות לאופטימיזציה של הביצועים של Spanner Graph מופיעות במאמרי העזרה הבאים: |
| פונקציות Cloud Run | כברירת מחדל, לכל מופע של פונקציית Cloud Run מוקצה מעבד אחד וזיכרון בנפח 256 MiB. בהתאם לדרישות הביצועים, אפשר להגדיר מגבלות על המעבד (CPU) והזיכרון. מידע נוסף זמין במשאבי העזרה הבאים: הנחיות נוספות לאופטימיזציה של הביצועים זמינות במאמר טיפים כלליים לפיתוח ב-Cloud Run. |
| Cloud Storage | כדי להעלות קבצים גדולים, אפשר להשתמש בהעלאות מורכבות מקבילות. באסטרטגיה הזו, הקובץ הגדול מפולח לחלקים. המקטעים מועלים ל-Cloud Storage במקביל, ואז הנתונים מורכבים מחדש בענן. אם רוחב הפס של הרשת ומהירות הכתיבה לדיסק לא מהווים גורם מגביל, העלאות מורכבות מקבילות יכולות להיות מהירות יותר מהעלאות רגילות. עם זאת, לאסטרטגיה הזו יש כמה מגבלות והשלכות על העלויות. מידע נוסף זמין במאמר בנושא העלאות מורכבות במקביל. |
| כל המוצרים בארכיטקטורה | אחרי שפורסים את עומס העבודה ב- Google Cloud, אפשר להשתמש ב-Active Assist כדי לקבל המלצות לשיפור נוסף של הביצועים של משאבי הענן. בודקים את ההמלצות ומיישמים אותן בהתאם לסביבה שלכם. איך מוצאים המלצות ב-Active Assist |
עקרונות והמלצות לאופטימיזציה של ביצועים שספציפיים לעומסי עבודה של AI ו-ML מפורטים במאמר AI and ML perspective: Performance optimization ב-Well-Architected Framework.
פריסה
כדי להבין איך GraphRAG פועל ב- Google Cloud, אפשר להוריד ולהפעיל את מחברת Jupyter הבאה מ-GitHub: GraphRAG on Google Cloud With Spanner Graph and Agent Runtime on Gemini Enterprise Agent Platform.
המאמרים הבאים
- פיתוח אפליקציות GraphRAG באמצעות Spanner Graph ו-LangChain
- בחירת מודלים ותשתית לאפליקציות מבוססות-AI גנרטיבי
- תשתית RAG ל-AI גנרטיבי באמצעות Agent Platform ו-Vector Search
- תשתית RAG ל-AI גנרטיבי באמצעות Agent Platform ו-AlloyDB ל-PostgreSQL
- תשתית RAG ל-AI גנרטיבי באמצעות GKE ו-Cloud SQL
- תשתית RAG ל-AI גנרטיבי באמצעות Gemini Enterprise ו-Agent Platform
- כדי לקרוא על עקרונות ארכיטקטוניים והמלצות לגבי עומסי עבודה של AI ב- Google Cloud, אפשר לעיין בWell-Architected Framework: AI and ML perspective.
- לדוגמאות נוספות של ארכיטקטורות, תרשימים ושיטות מומלצות, עיינו במאמר Cloud Architecture Center.
שותפים ביצירת התוכן
מחברים:
- טריסטן לי | ארכיטקט ראשי, AI/ML
- קומאר דהנגופאל | מפתח פתרונות חוצי-מוצרים
תורמי תוכן אחרים:
- Ahsif Sheikh | AI Customer Engineer
- אשיש צ'והאן (Ashish Chauhan) | Customer Engineer של AI
- גרג ברוסמן | מנהל מוצר
- לוקאס ברודרר | מנהל מוצר, Cloud AI
- Nanditha Embar | AI Customer Engineer
- פיוש מאטור | מנהל מוצר, Spanner
- Smitha Venkat | AI Customer Engineer