
從 Oracle 遷移至 BigQuery
本文提供從 Oracle 遷移至 BigQuery 的概略指引。本文說明基本架構差異,並建議從 Oracle RDBMS (包括 Exadata) 執行的資料倉儲和資料市集遷移至 BigQuery 的方法。本文提供的詳細資料也適用於 Exadata、ExaCC 和 Oracle Autonomous Data Warehouse,因為這些服務使用的 Oracle 軟體相容。
本文適用於企業架構師、資料庫管理員、應用程式開發人員和 IT 安全專業人員,協助他們從 Oracle 遷移至 BigQuery,並解決遷移過程中的技術難題。
您也可以使用批次 SQL 翻譯大量遷移 SQL 指令碼,或使用互動式 SQL 翻譯翻譯臨時查詢。這兩項工具的預先發布版都支援 Oracle SQL、PL/SQL 和 Exadata。
遷移前
為確保資料倉儲遷移作業順利完成,請在專案時間軸的早期開始規劃遷移策略。如要瞭解如何有系統地規劃遷移作業,請參閱「遷移的內容和方式:遷移作業架構」。
BigQuery 容量規劃
在幕後,BigQuery 中的分析輸送量是以「時段」為單位計算。BigQuery 運算單元是 Google 專有的運算能力單位,用來執行 SQL 查詢。
BigQuery 會在查詢執行時持續計算所需的運算單元數量,但會根據公平調度器將運算單元分配給查詢。
為 BigQuery 運算單元規劃容量時,您可以選擇下列計價模式:
以量計價:在以量計價模式中,BigQuery 會按照實際處理的位元組數 (資料大小) 收取費用,因此您只需為執行的查詢付費。如要進一步瞭解 BigQuery 如何判斷資料量,請參閱「資料量的計算方式」。由於運算單元決定了基礎運算容量,因此您可以根據所需的運算單元數量支付 BigQuery 使用費用 (而非根據處理的位元組數)。根據預設, Google Cloud 專案最多只能有 2,000 個時段。
以運算資源為基礎的計價方式: 採用以運算資源為基礎的計價方式時,您購買的是 BigQuery 運算單元保留項目 (最少 100 個),而不是根據查詢處理的位元組數付費。對於企業資料倉儲工作負載,我們建議採用以容量計價模式,這類工作負載通常會同時執行許多報表和擷取、載入、轉換 (ELT) 查詢,且耗用量可預測。
為協助估算配額,建議您使用 Cloud Monitoring 設定 BigQuery 監控,並使用 BigQuery 分析稽核記錄。許多客戶使用 Looker Studio (例如,請參閱 Looker Studio 資訊主頁的開放原始碼範例)、Looker 或 Tableau 做為前端,以視覺化方式呈現 BigQuery 稽核記錄資料,特別是查詢和專案的時段用量。您也可以運用 BigQuery 系統資料表資料,監控各項工作和預訂的時段用量。如需範例,請參閱開放原始碼範例,瞭解 Looker Studio 資訊主頁。
定期監控及分析時段使用情況,有助於預估貴機構在 Google Cloud成長時所需的總時段數。
舉例來說,假設您一開始保留 4,000 個 BigQuery 運算單元,同時執行 100 個中等複雜度的查詢。如果您發現查詢的執行計畫中等待時間偏長,且資訊主頁顯示運算單元使用率偏高,可能表示您需要額外的 BigQuery 運算單元,才能支援工作負載。如要透過一年或三年期承諾自行購買運算單元,請使用 Google Cloud 控制台或 bq 指令列工具,開始使用 BigQuery 預留。
如有任何關於目前方案和上述選項的問題,請與業務代表聯絡。
Google Cloud的安全防護
以下各節說明常見的 Oracle 安全性控制項,以及如何確保資料倉儲在 Google Cloud環境中受到保護。
身分與存取權管理 (IAM)
Oracle 提供使用者、權限、角色和設定檔,可管理資源存取權。
BigQuery 使用 IAM 管理資源存取權,並提供資源和動作的集中式存取權管理。BigQuery 提供的資源類型包括機構、專案、資料集、資料表和檢視區塊。在 IAM 政策階層中,資料集是專案的子項資源。資料表會繼承所屬資料集的權限。
如要授予資源的存取權,請將一或多個角色指派給使用者、群組或服務帳戶。機構和專案角色會影響執行工作或管理專案的能力,而資料集角色則會影響存取或修改專案內資料的能力。
IAM 提供下列類型的角色:
- 預先定義角色的用意在於支援常見的用途和存取權控管模式。預先定義的角色可針對特定服務提供精細的存取權,並由 Google Cloud管理。
基本角色包括「擁有者」、「編輯者」和「檢視者」角色。
自訂角色:根據使用者指定的權限清單,提供精細的存取權限。
當您同時把預先定義角色和基本角色指派給某個使用者時,您授予的權限就是這兩個角色權限的聯集。
資料列層級安全性
Oracle Label Security (OLS) 可限制資料存取權,以資料列為單位。行層級安全性的典型用途是限制銷售人員只能存取自己管理的帳戶。實作資料列層級安全防護機制後,您就能獲得精細的存取控管機制。
如要在 BigQuery 中實現資料列層級安全防護機制,可以使用授權檢視區塊和資料列層級存取權政策。如要進一步瞭解如何設計及導入這些政策,請參閱「BigQuery 資料列層級安全防護機制簡介」。
全磁碟加密
Oracle 提供資料庫透明加密 (TDE) 和網路加密,可加密靜態資料和傳輸中的資料。如要使用 TDE,必須另外購買授權,才能啟用進階安全性選項。
無論資料來源或任何其他條件為何,BigQuery 預設都會加密所有靜態和傳輸中的資料,且無法關閉這項功能。BigQuery 也支援客戶自行管理的加密金鑰 (CMEK),方便使用者在 Cloud Key Management Service 中控管及管理金鑰加密金鑰。如要進一步瞭解靜態加密,請參閱「預設靜態加密」和「傳輸中資料加密」。 Google Cloud
資料遮蓋和遮蓋
Oracle 會在 Real Application Testing 中使用資料遮蓋和資料遮蓋,讓您遮蓋 (遮蓋) 應用程式發出查詢時傳回的資料。
BigQuery 支援資料欄層級的動態資料遮蓋。您可以針對使用者群組,選擇性地掩蓋特定資料欄的資料,但這些使用者還是能正常使用該資料欄。
您可以使用 Sensitive Data Protection 識別及遮蓋 BigQuery 中的機密個人識別資訊 (PII)。
BigQuery 和 Oracle 比較
本節說明 BigQuery 和 Oracle 的主要差異。這些重點有助於找出遷移障礙,並規劃必要的變更。
系統架構
Oracle 和 BigQuery 的主要差異之一,在於 BigQuery 是無伺服器雲端 EDW,具有獨立的儲存空間和運算層,可根據查詢需求調度資源。由於 BigQuery 無伺服器服務的性質,您不會受到硬體決策的限制,而是可以透過預留項目,為查詢和使用者要求更多資源。BigQuery 也不需要設定底層軟體和基礎架構,例如作業系統 (OS)、網路系統和儲存系統,包括擴充和高可用性。BigQuery 會負責處理擴充性、管理和管理作業。下圖說明 BigQuery 儲存空間階層。

瞭解基礎儲存空間和查詢處理架構 (例如儲存空間 (Colossus) 和查詢執行 (Dremel) 之間的區隔,以及Google Cloud 如何分配資源 (Borg)),有助於瞭解行為差異,並盡可能提高查詢效能和成本效益。詳情請參閱 BigQuery、Oracle 和 Exadata 的參考系統架構。
資料和儲存空間架構
資料和儲存空間結構是任何資料分析系統的重要部分,因為這會影響查詢效能、成本、可擴充性和效率。
BigQuery 會將資料儲存和運算作業分離,並將資料儲存在 Colossus 中,資料會經過壓縮,並以名為 Capacitor 的資料欄格式儲存。
BigQuery 會使用 Capacitor 直接處理壓縮資料,不必解壓縮。如上圖所示,BigQuery 提供資料集做為最高層級的抽象概念,用於整理資料表的存取權。您可以使用結構定義和標籤進一步整理表格。BigQuery 提供分區功能,可提升查詢效能和降低成本,並管理資訊生命週期。儲存空間資源會在耗用時分配,並在移除資料或捨棄資料表時取消分配。
Oracle 會使用以區段形式整理的 Oracle 區塊格式,以資料列格式儲存資料。結構定義 (由使用者擁有) 用於整理資料表和其他資料庫物件。自 Oracle 12c 起,多租戶用於在一個資料庫執行個體中建立可插入式資料庫,以進一步隔離。分區可用於提升查詢效能和資訊生命週期作業。Oracle 為獨立和Real Application Clusters (RAC) 資料庫提供多種儲存空間選項,例如 ASM、OS 檔案系統和叢集檔案系統。
Exadata 會在儲存格伺服器中提供最佳化的儲存基礎架構,並允許 Oracle 伺服器透過 ASM 透明地存取這項資料。Exadata 提供混合分欄壓縮 (HCC) 選項,方便使用者壓縮資料表和分割區。
Oracle 需要預先佈建儲存空間容量,並仔細調整區隔、資料檔案和表空間的大小,以及設定自動遞增。
查詢執行和效能
BigQuery 會在查詢層級管理效能和調整規模,以盡可能提高效能,BigQuery 會進行許多最佳化,例如:
- 記憶體內查詢執行作業
- 以 Dremel 執行引擎為基礎的多層樹狀架構
- Capacitor 內建自動儲存空間最佳化功能
- 每秒總對分頻寬 1 PB,採用 Jupiter
- 自動調度資源管理,可快速查詢 PB 級資料
BigQuery 會在載入資料時收集資料欄統計資料,並提供診斷查詢計畫和時間點資訊。查詢資源會根據查詢類型及複雜度分配。每個查詢都會使用一些運算單元,這些運算單元是由一定數量的 CPU 與 RAM 組成。
Oracle 提供資料統計資料收集工作。資料庫最佳化工具會使用統計資料提供最佳執行計畫。如要快速查詢資料列和執行聯結作業,可能需要索引。Oracle 也提供記憶體內資料欄儲存空間,用於記憶體內分析。Exadata 提供多項效能改善功能,例如儲存格智慧掃描、儲存空間索引、快閃快取,以及儲存伺服器和資料庫伺服器之間的 InfiniBand 連線。Real Application Clusters (RAC) 可用於實現伺服器高可用性,並使用相同的基礎儲存空間,擴充資料庫 CPU 密集型應用程式。
如要使用 Oracle 最佳化查詢效能,必須仔細考量這些選項和資料庫參數。Oracle 提供多種工具,例如「作用中工作階段記錄 (ASH)」、「自動資料庫診斷監控 (ADDM)」、「自動工作負載存放區 (AWR)」報表、SQL 監控和調整顧問,以及「復原和記憶體調整顧問」,可供您調整效能。
敏捷分析
在 BigQuery 中,您可以允許不同專案、使用者和群組查詢不同專案中的資料集。查詢執行作業分離後,自主團隊就能在專案中工作,不會影響其他使用者和專案,因為系統會將配額和查詢帳單與其他專案和代管資料集的專案分開。
高可用性、備份和災難復原
Oracle 提供 Data Guard 做為災難復原和資料庫複製解決方案。Real Application Clusters (RAC) 可設定伺服器可用性。 復原管理員 (RMAN) 備份可設定為資料庫和封存記錄備份,也可用於還原和復原作業。資料庫回溯功能可用於資料庫回溯,將資料庫倒轉至特定時間點。復原資料表空間保留表格快照。視先前執行的 DML/DDL 作業和復原保留設定而定,您可以使用回溯查詢和「as of」查詢子句,查詢舊的快照。在 Oracle 中,資料庫的完整性應在依附於系統中繼資料、復原和相應表空間的表空間內管理,因為 Oracle 備份需要強烈一致性,且復原程序應包含完整的主要資料。如果不需要 Oracle 中的時間點復原功能,您可以在資料表結構定義層級排定匯出作業。
BigQuery 是全代管服務,與傳統資料庫系統不同,具備完整的備份功能。您不必擔心伺服器、儲存空間故障、系統錯誤和實體資料損毀。BigQuery 會根據資料集位置,在不同資料中心複製資料,盡可能提高可靠性和可用性。BigQuery 多區域功能會跨不同區域複製資料,並防範區域內單一可用區無法使用的情況。BigQuery 單一區域功能會在同一區域內的不同可用區複製資料。
BigQuery 支援時間回溯功能,可讓您查詢最多七天前的資料表快照,並在兩天內還原已刪除的資料表。您可以使用快照語法 (dataset.table@timestamp) 複製已刪除的資料表 (以便還原)。如需額外備份,例如從使用者誤操作中復原,可以從 BigQuery 資料表匯出資料。您可以使用現有資料倉儲 (DWH) 系統的備份策略和時間表。
批次作業和快照技術可為 BigQuery 提供不同的備份策略,因此您不需要經常匯出未變更的資料表和分區。載入或 ETL 作業完成後,匯出一個分割區或資料表的備份檔就足夠。如要降低備份成本,您可以將匯出檔案儲存在 Cloud Storage Nearline 儲存空間或 Coldline 儲存空間,並根據資料保留規定定義生命週期政策,在一段時間後刪除檔案。
快取
BigQuery 提供使用者專屬快取,如果資料沒有變更,查詢結果會快取約 24 小時。如果結果是從快取擷取,查詢費用為零。
Oracle 提供多種資料和查詢結果的快取,例如緩衝區快取、結果快取、Exadata Flash 快取和記憶體內資料欄儲存空間。
連線
BigQuery 會處理連線管理作業,您不需要進行任何伺服器端設定。BigQuery 提供 JDBC 和 ODBC 驅動程式。您可以使用 Google Cloud 控制台或 bq command-line tool 進行互動式查詢。您可以使用 REST API 和用戶端程式庫,以程式輔助方式與 BigQuery 互動。您可以直接將 Google 試算表連結至 BigQuery,並使用 ODBC 和 JDBC 驅動程式連結至 Excel。如要使用電腦用戶端,可以選擇 DBeaver 等免費工具。
Oracle 提供接聽程式、服務、服務處理常式、多個設定和調整參數,以及共用和專用伺服器,用來處理資料庫連線。Oracle 提供 JDBC、JDBC Thin、ODBC 驅動程式、Oracle Client 和 TNS 連線。RAC 設定需要掃描接聽程式、掃描 IP 位址和掃描名稱。
價格和授權
Oracle 會根據資料庫版本和資料庫選項 (例如 RAC、多租戶、Active Data Guard、分割、記憶體內建、Real Application Testing、GoldenGate,以及 Spatial 和 Graph) 的核心數量,收取授權和支援費用。
BigQuery 提供彈性的計價選項,費用取決於儲存空間、查詢和串流插入的用量。如果客戶需要特定區域的預估費用和運算單元容量,BigQuery 提供以容量為準的計價方式。用於串流插入和載入的運算單元不會計入專案運算單元容量。如要決定為資料倉儲購買多少運算單元,請參閱 BigQuery 容量規劃。
此外,如果資料超過 90 天未經修改,BigQuery 也會自動減半儲存空間費用。
標籤
BigQuery 資料集、資料表和檢視區塊可以加上標籤,並以鍵值組表示。標籤可用於區分儲存空間費用和內部退款。
監控和稽核記錄
Oracle 提供不同層級和類型的資料庫稽核選項,以及稽核保管庫和資料庫防火牆功能,這些功能需另外取得授權。Oracle 提供 Enterprise Manager,用於監控資料庫。
對於 BigQuery,Cloud 稽核記錄會同時用於資料存取記錄和稽核記錄,且預設為啟用。資料存取記錄會保留 30 天,其他系統事件和管理員活動記錄則會保留 400 天。如要保留更長時間,您可以按照「安全性記錄分析 Google Cloud」一文的說明,將記錄匯出至 BigQuery、Cloud Storage 或 Pub/Sub。如需與現有事件監控工具整合,可以使用 Pub/Sub 匯出資料,並在現有工具上進行自訂開發,從 Pub/Sub 讀取記錄。
稽核記錄包含所有 API 呼叫、查詢陳述式和工作狀態。您可以使用 Cloud Monitoring 監控運算單元分配情形、查詢和儲存的位元組數,以及其他 BigQuery 指標。BigQuery 查詢計畫和時間軸可用於分析查詢階段和效能。
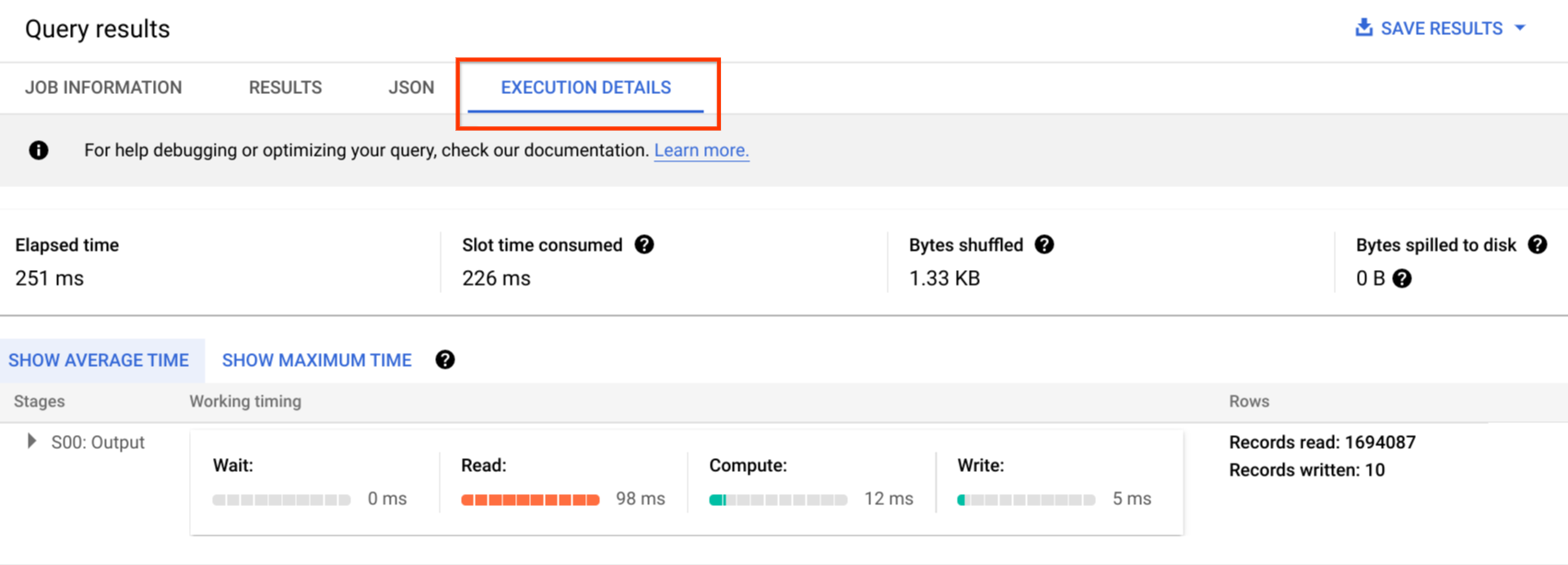
您可以參考錯誤訊息表,排解查詢工作和 API 錯誤。如要區分每個查詢或作業的時段分配情形,可以使用這個公用程式。如果客戶採用以容量為準的定價,且多個專案分散在不同團隊中,這項工具就相當實用。
維護、升級和版本
BigQuery 是全代管服務,您不需要進行任何維護或升級作業。BigQuery 不提供不同版本。升級作業會持續進行,不需要停機,也不會降低系統效能。詳情請參閱「版本資訊」。
Oracle 和 Exadata 要求您執行資料庫和基礎架構層級的修補、升級和維護作業。Oracle 有許多版本,且每年都會發布新的主要版本。雖然新版本具備回溯相容性,但查詢效能、內容和功能可能會有所變更。
有些應用程式可能需要特定版本,例如 10g、11g 或 12c。進行重大資料庫升級時,需要審慎規劃和測試。從不同版本遷移時,查詢子句和資料庫物件可能需要不同的技術轉換。
工作負載
Oracle Exadata 支援混合工作負載,包括 OLTP 工作負載。BigQuery 專為分析而設計,不適合處理 OLTP 工作負載。使用相同 Oracle 的 OLTP 工作負載應遷移至Google Cloud中的 Cloud SQL、Spanner 或 Firestore。Oracle 提供其他選項,例如進階分析、空間和圖形。這些工作負載可能需要重新編寫,才能遷移至 BigQuery。詳情請參閱「遷移 Oracle 選項」。
參數和設定
Oracle 提供許多參數,並要求在作業系統、資料庫、RAC、ASM 和接聽程式層級設定及調整這些參數,以因應不同的工作負載和應用程式。BigQuery 是全代管服務,您不需要設定任何初始化參數。
限制與配額
Oracle 會根據基礎架構、硬體容量、參數、軟體版本和授權,設定硬性與軟性限制。BigQuery 對特定動作和物件設有配額與限制。
BigQuery 佈建
BigQuery 是平台即服務 (PaaS),也是雲端大規模平行處理資料倉儲。Google 會管理後端,因此容量可隨時擴充或縮減,不需使用者介入。因此,不同於許多 RDBMS 系統的做法,您不需要在使用 BigQuery 之前佈建資源。BigQuery 會根據您的使用模式,以動態方式分配儲存空間及查詢資源。儲存空間資源會在耗用時分配,並在移除資料或捨棄資料表時取消分配。查詢資源會根據查詢類型及複雜度分配。每項查詢都會使用運算單元。系統會使用最終公平性排程器,因此某些查詢可能會在短時間內分配到較多的運算單元數量,但排程器最終仍會修正這個問題。
以傳統 VM 來說,BigQuery 相當於提供以下兩項服務:
- 以秒計費
- 以秒為單位的資源調度
為完成這項工作,BigQuery 會執行下列操作:
- 部署大量資源,避免需要快速擴充。
- 使用多租戶資源,一次分配大量區塊,時間以秒為單位。
- 透過規模經濟,有效分配使用者資源。
- 只會針對您執行的工作收費,不會針對部署的資源收費,因此您只要支付實際的使用量。
如要進一步瞭解定價,請參閱「瞭解 BigQuery 的快速擴充功能和簡單定價」。
結構定義遷移
如要將資料從 Oracle 遷移至 BigQuery,您必須瞭解 Oracle 資料類型和 BigQuery 對應關係。
Oracle 資料類型和 BigQuery 對應項目
Oracle 資料類型與 BigQuery 資料類型不同。如要進一步瞭解 BigQuery 資料類型,請參閱官方說明文件。
如要詳細比較 Oracle 和 BigQuery 資料類型,請參閱 Oracle SQL 翻譯指南。
索引
在許多分析工作負載中,會使用直欄資料表,而非資料列儲存區。這可大幅增加以資料欄為基礎的作業,並免除使用索引進行批次分析。BigQuery 也會以直欄格式儲存資料,因此不需要索引。如果分析工作負載只需要一小組以列為基礎的存取權,Bigtable 可能是更好的替代方案。如果工作負載需要處理交易,且具有嚴格的關聯一致性,Spanner 或 Cloud SQL 可能是更好的替代方案。
總而言之,BigQuery 不需要索引,也不會提供索引,您可以使用分區或分群。如要進一步瞭解如何在 BigQuery 中調整及提升查詢效能,請參閱最佳化查詢效能簡介。
瀏覽次數
與 Oracle 類似,BigQuery 允許建立自訂檢視區塊。不過,BigQuery 中的檢視表不支援 DML 陳述式。
具體化檢視表
Materialized view 通常用於改善「寫入一次,讀取多次」類型的報表和工作負載的報表顯示時間。
Oracle 提供 materialized view,只要建立及維護資料表來保存查詢結果資料集,即可提高檢視效能。在 Oracle 中,具體化檢視表有兩種重新整理方式:提交時和隨選。
BigQuery 也提供具體化檢視表功能。BigQuery 會運用具體化檢視表的預先運算結果,並盡可能只讀取基礎資料表的差異變更,以運算最新結果。
Looker Studio 或其他現代化商業智慧工具的快取功能也能提升效能,並免除重新執行相同查詢的需要,進而節省費用。
資料表分區
資料表分區廣泛用於 Oracle 資料倉儲。與 Oracle 不同,BigQuery 不支援階層式分區。
BigQuery 實作了三種資料表分區,可讓查詢根據分區欄指定述詞篩選條件,以減少掃描的資料量。
- 依擷取時間分區的資料表:根據資料的擷取時間分區的資料表。
- 依資料欄分區的資料表:根據
TIMESTAMP或DATE資料欄分區的資料表。 - 依整數範圍分區的資料表:根據整數資料欄分區的資料表。
如要進一步瞭解 BigQuery 中分區資料表的限制和配額,請參閱分區資料表簡介。
如果 BigQuery 限制會影響遷移資料庫的功能,請考慮使用分片,而非分割。
此外,BigQuery 不支援 EXCHANGE PARTITION、SPLIT PARTITION,也不支援將非分區資料表轉換為分區資料表。
分群
叢集有助於有效整理及擷取儲存在多個資料欄中的資料,這些資料通常會一起存取。不過,Oracle 和 BigQuery 的叢集功能最適合在不同情況下使用。在 BigQuery 中,如果資料表經常使用特定資料欄進行篩選和匯總,請使用叢集。從 Oracle 遷移清單分區或索引組織資料表時,可以考慮叢集處理。
臨時資料表
Oracle ETL 管道經常使用暫時資料表。臨時資料表會在使用者工作階段期間保留資料,工作階段結束時,系統會自動刪除這類資料。
BigQuery 會使用臨時資料表,快取未寫入永久資料表的查詢結果。查詢完成後,暫時性資料表最多會保留 24 小時。系統會在特殊資料集中建立資料表,並隨機命名。您也可以建立臨時表格供自己使用。詳情請參閱暫時性資料表。
外部資料表
與 Oracle 類似,BigQuery 可讓您查詢外部資料來源。BigQuery 支援直接從外部資料來源查詢資料,包括:
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob 儲存體
- Bigtable
- Spanner
- Cloud SQL
- Cloud Storage
- Google 雲端硬碟
建立資料模型
星狀或雪花資料模型可有效率地儲存分析資料,且通常用於 Oracle Exadata 上的資料倉儲。
反正規化資料表可避免耗費資源的聯結作業,而且在大多數情況下,BigQuery 的分析效能會更好。BigQuery 也支援星狀和雪花資料模型。如要進一步瞭解 BigQuery 資料倉儲設計,請參閱設計結構定義。
列格式與欄格式,以及伺服器限制與無伺服器
Oracle 使用資料列格式,將資料表資料列儲存在資料區塊中,因此系統會根據特定資料欄的篩選和匯總作業,在區塊中擷取分析查詢不需要的資料欄。
Oracle 採用「萬物共用」架構,並將記憶體和儲存空間等固定硬體資源指派給伺服器。這兩大力量是許多資料模型技術的基礎,這些技術不斷演進,以提升儲存效率和分析查詢效能。星狀和雪花結構定義,以及資料保險箱建模就是其中幾種。
BigQuery 採用資料欄格式儲存資料,且沒有固定的儲存空間和記憶體限制。這個架構可讓您根據讀取作業和業務需求,進一步取消正規化及設計結構定義,進而降低複雜度、提升彈性、擴充性和效能。
去標準化
關聯式資料庫正規化的主要目標之一是減少資料冗餘。雖然這個模型最適合使用列格式的關聯式資料庫,但資料去正規化更適合用於直欄式資料庫。如要進一步瞭解資料反正規化的優點,以及 BigQuery 中的其他查詢最佳化策略,請參閱「反正規化」一文。
簡化現有結構定義的技巧
BigQuery 技術結合了資料欄資料存取和處理、記憶體內儲存空間,以及分散式處理,可提供優質的查詢效能。
設計 BigQuery DWH 結構定義時,以扁平資料表結構建立事實資料表 (將所有維度資料表整合到事實資料表中的單一記錄),比使用多個 DWH 維度資料表更適合儲存空間利用率。除了減少儲存空間用量,在 BigQuery 中使用扁平資料表也能減少 JOIN 用量。下圖舉例說明如何將結構定義扁平化。
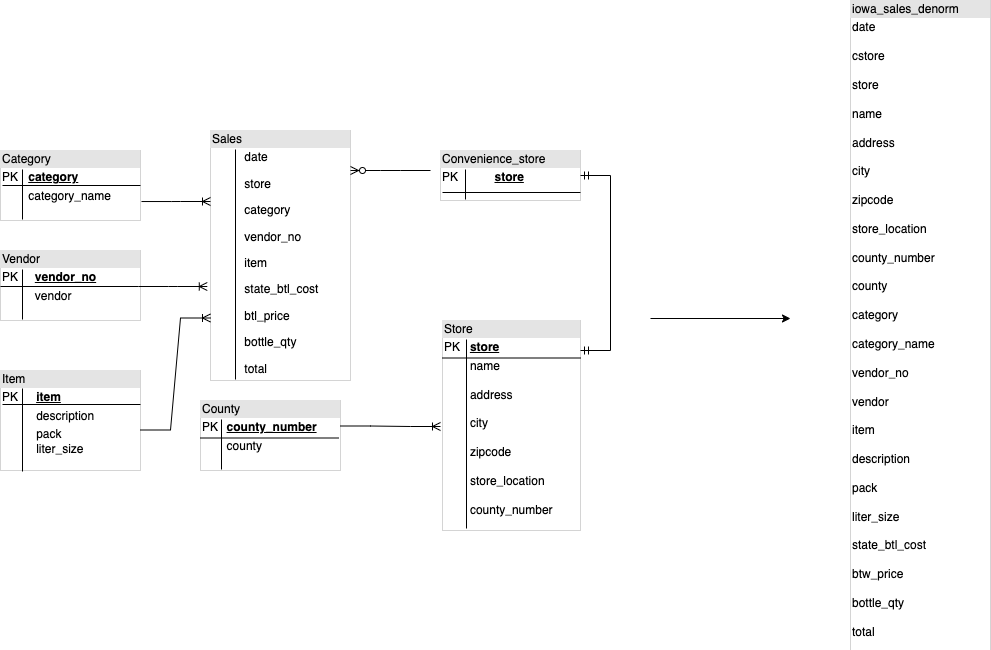
扁平化星狀結構定義的範例
圖 1 顯示虛構的銷售管理資料庫,內含四個資料表:
- 訂單/銷售表格 (事實表格)
- 員工表
- 門市表格
- 顧客表格
銷售資料表的主鍵是 OrderNum,其中也包含其他三個資料表的外鍵。
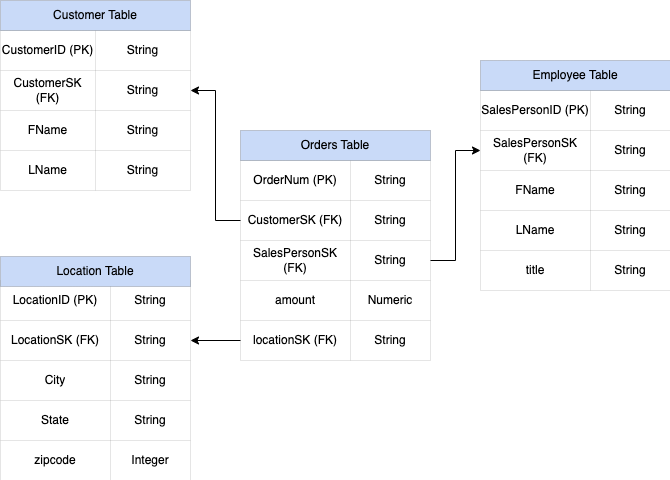
圖 1:星狀結構定義中的銷售資料範例
範例資料
訂單/事實資料表內容
| OrderNum | CustomerID | SalesPersonID | 金額 | 位置 |
|---|---|---|---|---|
| O-1 | 1234 | 12 | 234.22 | 18 |
| O-2 | 4567 | 1 | 192.10 | 27 |
| O-3 | 12 | 14.66 | 18 | |
| O-4 | 4567 | 4 | 182.00 | 26 |
員工表格內容
| SalesPersonID | FName | LName | title |
|---|---|---|---|
| 1 | Alex | Smith | 銷售助理 |
| 4 | Lisa | 陳 | 銷售助理 |
| 12 | John | 陳 | 銷售助理 |
客戶表格內容
| CustomerID | FName | LName |
|---|---|---|
| 1234 | Amanda | Lee |
| 4567 | Matt | Ryan |
位置表格內容
| 位置 | 城市 | state | 郵遞區號 |
|---|---|---|---|
| 18 | 布朗克斯 | NY | 10452 |
| 26 | 山景城 | CA | 90210 |
| 27 | 芝加哥 | IL | 60613 |
使用 LEFT OUTER JOIN 將資料扁平化的查詢
#standardSQL INSERT INTO flattened SELECT orders.ordernum, orders.customerID, customer.fname, customer.lname, orders.salespersonID, employee.fname, employee.lname, employee.title, orders.amount, orders.location, location.city, location.state, location.zipcode FROM orders LEFT OUTER JOIN customer ON customer.customerID = orders.customerID LEFT OUTER JOIN employee ON employee.salespersonID = orders.salespersonID LEFT OUTER JOIN location ON location.locationID = orders.locationID
扁平化資料的輸出內容
| OrderNum | CustomerID | FName | LName | SalesPersonID | FName | LName | 金額 | 位置 | 城市 | state | 郵遞區號 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| O-1 | 1234 | Amanda | Lee | 12 | John | Doe | 234.22 | 18 | 布朗克斯 | NY | 10452 |
| O-2 | 4567 | Matt | Ryan | 1 | Alex | Smith | 192.10 | 27 | 芝加哥 | IL | 60613 |
| O-3 | 12 | John | Doe | 14.66 | 18 | 布朗克斯 | NY | 10452 | |||
| O-4 | 4567 | Matt | Ryan | 4 | Lisa | Doe | 182.00 | 26 | 山岳
查看 |
CA | 90210 |
巢狀和重複欄位
如要從關聯式結構定義設計及建立 DWH 結構定義 (例如包含維度和事實資料表的星形和雪花狀結構定義),BigQuery 提供巢狀和重複欄位功能。因此,您可保留關聯式標準化 (或部分標準化) DWH 結構定義中的關係,且不會影響效能。詳情請參閱「效能最佳做法」。
如要進一步瞭解如何實作巢狀和重複欄位,請查看 CUSTOMERS 資料表和 ORDER/SALES 資料表的簡單關係結構定義。這兩個資料表各代表一個實體,關係則使用主鍵和外鍵等索引鍵定義,做為資料表之間的連結,同時使用 JOIN 查詢。BigQuery 巢狀和重複欄位可讓您在單一資料表中保留實體之間的相同關係。您可以實作這項功能,讓所有顧客資料都存在,同時為每位顧客巢狀顯示訂單資料。詳情請參閱指定巢狀和重複的欄位。
如要將扁平結構轉換為巢狀或重複結構定義,請依下列方式將欄位設為巢狀:
CustomerID、FName、LName巢狀結構,並放入名為Customer的新欄位。SalesPersonID、FName、LName巢狀結構,並放入名為Salesperson的新欄位。LocationID、city、state、zip code巢狀結構,並放入名為Location的新欄位。
OrderNum 和 amount 欄位不會巢狀化,因為它們代表不重複的元素。
您希望架構夠彈性,讓每個訂單都能有多位顧客 (主要和次要)。顧客欄位標示為重複。產生的結構定義如圖 2 所示,其中說明瞭巢狀和重複的欄位。
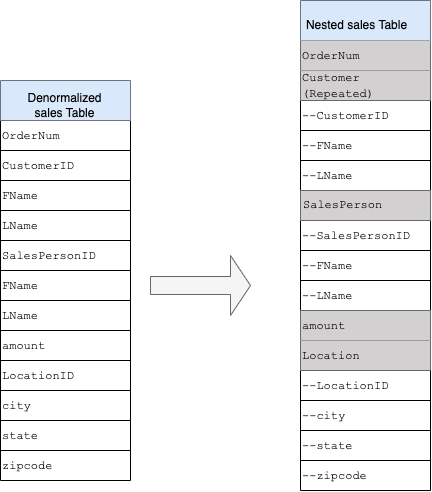
圖 2:巢狀結構的邏輯表示法
在某些情況下,使用巢狀和重複欄位進行去標準化並無法提升效能。如要進一步瞭解限制,請參閱在資料表結構定義中指定巢狀與重複的資料欄。
替代鍵
通常會使用資料表中的不重複索引鍵來識別資料列。Oracle 通常會使用序列來建立這些金鑰。在 BigQuery 中,您可以使用 row_number 和 partition by 函式建立替代鍵。詳情請參閱「BigQuery and surrogate keys: a practical approach」(BigQuery 和替代鍵:實用方法)。
追蹤變更和記錄
規劃 BigQuery DWH 遷移作業時,請考量緩慢變更的維度 (SCD) 概念。一般來說,SCD 一詞是指在維度資料表中進行變更 (DML 作業) 的程序。
傳統資料倉儲會基於多種原因,使用不同類型來處理資料變更,並在緩慢變動維度中保留歷來資料。如先前所述,由於硬體限制和效率需求,因此需要使用這些型別。由於儲存空間比運算便宜許多,而且可無限擴充,因此如果資料冗餘和重複可加快 BigQuery 的查詢速度,建議您採用這種做法。您可以使用資料快照技術,將所有資料載入新的每日分區。
角色專屬和使用者專屬檢視畫面
如果使用者屬於不同團隊,且只需要查看所需的記錄和結果,請使用角色專屬和使用者專屬的檢視畫面。
BigQuery 支援column-和資料列層級的安全防護機制。資料欄層級安全防護機制透過政策標記或依據類型的資料分類方式,對機密資料欄提供精細的存取權限。資料列層級安全防護機制:可根據符合資格的使用者條件篩選資料,並允許存取資料表中的特定資料列。
資料遷移
本節提供從 Oracle 遷移至 BigQuery 的資料相關資訊,包括初始載入、變更資料擷取 (CDC),以及 ETL/ELT 工具和方法。
遷移活動
建議您先找出適合遷移的用途,然後分階段執行遷移作業。您可以使用多種工具和服務,將資料從 Oracle 遷移至 Google Cloud。這份清單並未詳盡列出所有項目,但可讓您瞭解遷移作業的規模和範圍。
從 Oracle 匯出資料:詳情請參閱初始載入和從 Oracle 到 BigQuery 的 CDC 和串流擷取。ETL 工具可用於初始載入。
資料暫存 (在 Cloud Storage 中):建議您將從 Oracle 匯出的資料暫存於 Cloud Storage。Cloud Storage 的設計宗旨是快速且彈性地擷取結構化或非結構化資料。
ETL 程序:詳情請參閱「ETL/ELT 遷移」。
直接將資料載入 BigQuery:您可以透過 Dataflow 或即時串流,直接從 Cloud Storage 將資料載入 BigQuery。需要轉換資料時,請使用 Dataflow。
初始載入
視資料大小和網路頻寬而定,將初始資料從現有 Oracle 資料倉儲遷移至 BigQuery,可能與增量 ETL/ELT 管道不同。如果資料大小為幾 TB,可以使用相同的 ETL/ELT 管道。
如果資料量最多只有幾 TB,傾印資料並使用 gcloud storage 進行轉移,會比使用 JdbcIO 類似的程式輔助資料庫擷取方法更有效率,因為程式輔助方法可能需要更精細的效能調整。如果資料大小超過幾 TB,且儲存在雲端或線上儲存空間 (例如 Amazon Simple Storage Service (Amazon S3)),建議使用 BigQuery 資料移轉服務。對於大規模移轉 (尤其是網路頻寬受限的移轉作業),Transfer Appliance 是實用的選擇。
初始載入的限制
規劃資料遷移作業時,請注意下列事項:
- Oracle DWH 資料大小:結構定義的來源大小對所選資料轉移方式有重大影響,尤其是在資料量龐大 (TB 以上) 的情況下。如果資料量相對較小,資料轉移程序可以簡化。處理大規模資料會使整體程序更加複雜。
停機時間:決定是否要停機,是遷移至 BigQuery 的重要環節。為減少停機時間,您可以大量載入穩定的歷來資料,並使用 CDC 解決方案,趕上轉移程序期間發生的變更。
價格:在某些情況下,您可能需要第三方整合工具 (例如 ETL 或複製工具),這類工具需要額外授權。
初始資料移轉 (批次)
使用批次方法轉移資料表示資料會以單一程序匯出 (例如將 Oracle DWH 結構定義資料匯出至 CSV、Avro 或 Parquet 檔案,或匯入 Cloud Storage 以在 BigQuery 上建立資料集)。您可以使用 ETL/ELT 遷移作業中說明的所有 ETL 工具和概念,進行初始載入。
如果不想使用 ETL/ELT 工具進行初始載入,可以編寫自訂指令碼,將資料匯出至檔案 (CSV、Avro 或 Parquet),然後使用 gcloud storage、BigQuery 資料移轉服務或 Transfer Appliance,將資料上傳至 Cloud Storage。如要進一步瞭解如何調整大型資料移轉作業的效能,以及移轉選項,請參閱「轉移大型資料集」。然後將資料從 Cloud Storage 載入 BigQuery。
Cloud Storage 非常適合處理資料的初始登陸。 Cloud Storage 是高可用性且耐用的物件儲存服務,檔案數量沒有限制,而且只會收取您使用的儲存空間費用。這項服務經過最佳化,可與 BigQuery 和 Dataflow 等其他 Google Cloud 服務搭配使用。
透過 CDC 和串流擷取功能,將資料從 Oracle 遷移至 BigQuery
您可以透過多種方式擷取 Oracle 中的變更資料,每種選項都有取捨之處,主要在於對來源系統的效能影響、開發和設定需求,以及定價和授權。
以記錄為基礎的 CDC
建議您使用 Oracle GoldenGate 擷取重做記錄,並使用 GoldenGate for Big Data 將記錄串流到 BigQuery。GoldenGate 需要 CPU 授權。如要瞭解價格,請參閱 Oracle Technology Global Price List。如果可以使用 Oracle GoldenGate for Big Data (前提是已取得授權),建議使用 GoldenGate 建立資料管道來移轉資料 (初始載入),然後同步所有資料修改。
Oracle XStream
Oracle 會將每次提交的內容儲存在重做記錄檔中,這些重做記錄檔可用於 CDC。Oracle XStream Out 是以 LogMiner 為基礎建構,並由第三方工具提供,例如 Debezium (0.8 版起) 或 Striim 等商業工具。即使未安裝及使用 GoldenGate,使用 XStream API 仍須購買 Oracle GoldenGate 授權。XStream 可讓您在 Oracle 和其他軟體之間有效率地傳播 Streams 訊息。
Oracle LogMiner
LogMiner 不需要特殊授權。您可以使用 Debezium 社群連接器中的 LogMiner 選項。您也可以使用 Attunity、Striim 或 StreamSets 等工具,透過商業管道取得資料。如果來源資料庫非常活躍,LogMiner 可能會對效能造成影響。如果每小時的變更量 (重做大小) 超過 10 GB,請謹慎使用 LogMiner,具體情況取決於伺服器的 CPU、記憶體、I/O 容量和使用率。
以 SQL 為基礎的 CDC
這是遞增 ETL 方法,SQL 查詢會根據單調遞增鍵和包含上次修改或插入日期的時間戳記欄,持續輪詢來源資料表是否有任何變更。如果沒有單調遞增的鍵,使用精確度較低的 (以秒為單位) 時間戳記資料欄 (修改日期),可能會導致記錄重複或遺漏資料,視資料量和比較運算子 (例如 > 或 >=) 而定。
如要解決這類問題,您可以在時間戳記資料欄中使用更高的精確度,例如六個小數點位數 (微秒,這是 BigQuery 支援的最高精確度),或者根據業務鍵和資料特徵,在 ETL/ELT 管道中新增重複資料刪除工作。
索引應位於鍵或時間戳記欄,以提升擷取效能,並減少對來源資料庫的影響。刪除作業對這項方法來說是一大挑戰,因為這類作業應在來源應用程式中以虛刪除方式處理,例如放置已刪除的旗標並更新 last_modified_date。您也可以使用觸發程序,在另一個資料表中記錄這些作業。
觸發條件
您可以在來源資料表上建立資料庫觸發程序,將變更記錄到影子日誌資料表中。日誌資料表可以保留整個資料列,追蹤每個資料欄的變更,也可以只保留主鍵和作業類型 (插入、更新或刪除)。然後,您可以使用 SQL 型 CDC 中說明的 SQL 型方法擷取變更的資料。如果儲存完整資料列,使用觸發程序可能會影響交易效能,並使單一資料列 DML 作業延遲時間加倍。只儲存主鍵可以減少這項負擔,但這樣一來,SQL 型擷取作業就必須對原始資料表執行 JOIN 作業,而這會遺漏中繼變更。
遷移 ETL/ELT
在 Google Cloud上處理 ETL/ELT 的方式有很多種。本文件不提供特定 ETL 工作負載轉換的技術指引。您可以考慮採用直接移轉方法,或根據成本和時間等限制,重新設計資料整合平台。如要進一步瞭解如何將資料管道遷移至 Google Cloud ,以及許多其他遷移概念,請參閱「遷移資料管道」。
隨即轉移方法
如果現有平台支援 BigQuery,且您想繼續使用現有的資料整合工具:
- 您可以維持 ETL/ELT 平台現狀,並在 ETL/ELT 工作中,使用 BigQuery 變更必要的儲存階段。
- 如要將 ETL/ELT 平台也遷移至 Google Cloud ,請向供應商確認其工具是否已在 Google Cloud取得授權,如果是,即可在 Compute Engine 上安裝該工具,或前往 Google Cloud Marketplace 尋找。
如要瞭解資料整合解決方案供應商,請參閱「BigQuery 合作夥伴」。
重新設計 ETL/ELT 平台架構
如要重新設計資料管道,強烈建議您考慮使用 Google Cloud 服務。
Cloud Data Fusion
Cloud Data Fusion 是 CDAP 的代管版本,提供圖形介面和許多外掛程式,可執行拖曳和管道開發等工作。 Google Cloud Cloud Data Fusion 可用來從各種來源系統擷取資料,並提供批次和串流複製功能。您可以使用 Cloud Data Fusion 或 Oracle 外掛程式,從 Oracle 擷取資料。您可以使用 BigQuery 外掛程式將資料載入 BigQuery,並處理結構定義更新。
來源和接收器外掛程式都未定義輸出結構定義,且來源外掛程式也使用 select * from 複製新資料欄。
您可以使用 Cloud Data Fusion 的 Wrangle 功能清理及準備資料。
Dataflow
Dataflow 是無伺服器資料處理平台,可自動調整規模,並處理批次和串流資料。對於想編寫資料管道程式碼,並將同一段程式碼用於串流和批次工作負載的 Python 和 Java 開發人員來說,Dataflow 是個不錯的選擇。使用 JDBC 到 BigQuery 範本,從 Oracle 或其他關聯式資料庫擷取資料,並載入至 BigQuery。
Cloud Composer
Cloud Composer 是以 Apache Airflow 為基礎建構的全代管工作流程自動化調度管理服務。 Google Cloud 您可以使用這項服務,建立、排程及監控散布於不同雲端環境和內部部署資料中心的管道。Cloud Composer 提供運算子和貢獻內容,可執行多雲技術,適用於擷取和載入、ELT 轉換,以及 REST API 呼叫等用途。
Cloud Composer 會使用有向非循環圖 (DAG) 排定及自動化調度管理工作流程。如要瞭解一般 Airflow 概念,請參閱「Airflow Apache 概念」。如要進一步瞭解 DAG,請參閱「編寫 DAG (工作流程)」。如需使用 Apache Airflow 的 ETL 最佳做法範例,請參閱 Airflow 說明文件網站的 ETL 最佳做法。您可以在該範例中將 Hive 運算子替換為 BigQuery 運算子,概念相同。
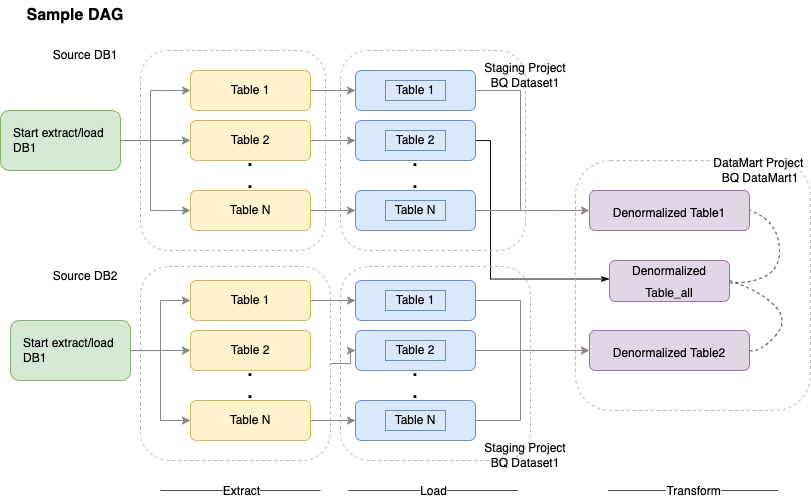
以下程式碼範例是上述圖表範例 DAG 的高階部分:
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=10),
}
schedule_interval = "00 01 * * *"
dag = DAG('load_db1_db2',catchup=False, default_args=default_args,
schedule_interval=schedule_interval)
tables = {
'DB1_TABLE1': {'database':'DB1', 'table_name':'TABLE1'},
'DB1_TABLE2': {'database':'DB1', 'table_name':'TABLE2'},
'DB1_TABLEN': {'database':'DB1', 'table_name':'TABLEN'},
'DB2_TABLE1': {'database':'DB2', 'table_name':'TABLE1'},
'DB2_TABLE2': {'database':'DB2', 'table_name':'TABLE2'},
'DB2_TABLEN': {'database':'DB2', 'table_name':'TABLEN'},
}
start_db1_daily_incremental_load = DummyOperator(
task_id='start_db1_daily_incremental_load', dag=dag)
start_db2_daily_incremental_load = DummyOperator(
task_id='start_db2_daily_incremental_load', dag=dag)
load_denormalized_table1 = BigQueryOperator(
task_id='load_denormalized_table1',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db1.TABLEN` as tN on t1.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt1', dag=dag)
load_denormalized_table2 = BigQueryOperator(
task_id='load_denormalized_table2',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),tN.* except (ID)
from `ingest-project.ingest_db1.TABLE1` as t1
left join `ingest-project.ingest_db2.TABLE2` as t2 on t1.ID = t2.ID
left join `ingest-project.ingest_db2.TABLEN` as tN on t2.ID = tN.ID
''', destination_dataset_table='datamart-project.dm1.dt2', dag=dag)
load_denormalized_table_all = BigQueryOperator(
task_id='load_denormalized_table_all',
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
trigger_rule='all_done',
bql='''
#standardSQL
select
t1.*,t2.* except (ID),t3.* except (ID)
from `datamart-project.dm1.dt1` as t1
left join `ingest-project.ingest_db1.TABLE2` as t2 on t1.ID = t2.ID
left join `datamart-project.dm1.dt2` as t3 on t2.ID = t3.ID
''', destination_dataset_table='datamart-project.dm1.dt_all', dag=dag)
def start_pipeline(database,table,...):
#start initial or incremental load job here
#you can write your custom operator to integrate ingestion tool
#or you can use operators available in composer instead
for table,table_attr in tables.items():
tbl=table_attr['table_name']
db=table_attr['database'])
load_start = PythonOperator(
task_id='start_load_{db}_{tbl}'.format(tbl=tbl,db=db),
python_callable=start_pipeline,
op_kwargs={'database': db,
'table':tbl},
dag=dag
)
load_monitor = HttpSensor(
task_id='load_monitor_{db}_{tbl}'.format(tbl=tbl,db=db),
http_conn_id='ingestion-tool',
endpoint='restapi-endpoint/',
request_params={},
response_check=lambda response: """{"status":"STOPPED"}""" in
response.text,
poke_interval=1,
dag=dag,
)
load_start.set_downstream(load_monitor)
if table_attr['database']=='db1':
load_start.set_upstream(start_db1_daily_incremental_load)
else:
load_start.set_upstream(start_db2_daily_incremental_load)
if table_attr['database']=='db1':
load_monitor.set_downstream(load_denormalized_table1)
else:
load_monitor.set_downstream(load_denormalized_table2)
load_denormalized_table1.set_downstream(load_denormalized_table_all)
load_denormalized_table2.set_downstream(load_denormalized_table_all)
上述程式碼僅供示範,無法直接使用。
Dataprep by Trifacta
Dataprep 是一項資料服務,可讓您透過圖表探索資料、清理及準備結構化與非結構化資料,以便用於數據分析、報表和機器學習作業。您將來源資料匯出為 JSON 或 CSV 檔案,使用 Dataprep 轉換資料,然後使用 Dataflow 載入資料。如需範例,請參閱「使用 Dataflow 和 Dataprep 將 Oracle 資料 (ETL) 匯入 BigQuery」。
Dataproc
Dataproc 是 Google 代管的 Hadoop 服務。您可以使用 Sqoop 將資料從 Oracle 和許多關聯式資料庫匯出至 Cloud Storage,並以 Avro 檔案格式儲存,然後使用 bq tool 將 Avro 檔案載入 BigQuery。在 Hadoop 上安裝 CDAP 等 ETL 工具非常常見,這些工具會使用 JDBC 擷取資料,並使用 Apache Spark 或 MapReduce 轉換資料。
合作夥伴適用的資料遷移工具
擷取、轉換及載入 (ETL) 領域有許多供應商。Informatica、Talend、Matillion、Infoworks、Stitch、Fivetran 和 Striim 等 ETL 市場領導者已與 BigQuery 和 Oracle 深度整合,可協助您擷取、轉換及載入資料,並管理處理工作流程。
ETL 工具已問世多年,部分機構可能會覺得運用現有的信任 ETL 指令碼投資很方便。BigQuery 合作夥伴網站上列出了一些重要的合作夥伴解決方案。瞭解何時該選擇合作夥伴工具而非Google Cloud 內建公用程式,取決於您目前的基礎架構,以及 IT 團隊是否熟悉以 Java 或 Python 程式碼開發資料管道。
商業智慧 (BI) 工具遷移
BigQuery 支援彈性十足的商業智慧 (BI) 解決方案工具套件,可供您用於報告和分析。如要進一步瞭解 BI 工具遷移和 BigQuery 整合,請參閱「BigQuery 數據分析總覽」。
查詢 (SQL) 翻譯
BigQuery 的 GoogleSQL 支援 SQL 2011 標準,並具備查詢巢狀和重複資料的擴充功能。所有符合 ANSI 標準的 SQL 函式和運算子,只需稍加修改即可使用。如要詳細比較 Oracle 和 BigQuery SQL 語法與函式,請參閱 Oracle 到 BigQuery SQL 翻譯參考資料。
使用批次 SQL 翻譯大量遷移 SQL 程式碼,或使用互動式 SQL 翻譯翻譯臨時查詢。
遷移 Oracle 選項
本節提供架構建議和參考資料,協助您轉換使用 Oracle Data Mining、R,以及空間和圖形功能的應用程式。
Oracle Advanced Analytics 選項
Oracle 提供進階分析選項,可用於資料探勘、基本機器學習 (ML) 演算法和 R 用途。進階分析選項需要授權。您可以從 Google AI/ML 產品的完整清單中選擇合適的項目,滿足從開發到大規模生產的各種需求。
Oracle R Enterprise
Oracle R Enterprise (ORE) 是 Oracle Advanced Analytics 選項的元件,可將開放原始碼 R 統計程式設計語言與 Oracle Database 整合。在標準 ORE 部署作業中,R 會安裝在 Oracle 伺服器上。
如果資料量非常龐大,或是您採用倉儲方法,將 R 與 BigQuery 整合是理想選擇。您可以使用開放原始碼 bigrquery R 程式庫,將 R 與 BigQuery 整合。
Google 與 RStudio 合作,為使用者提供這個領域最先進的工具。您可以使用 RStudio 存取 BigQuery 中 TB 級的資料、在 TensorFlow 中擬合模型,以及透過 AI 平台大規模執行機器學習模型。在 Google Cloud中,R 可大規模安裝在 Compute Engine 上。
Oracle Data Mining
Oracle Data Mining (ODM) 是 Oracle Advanced Analytics 選項的元件,可讓開發人員在 Oracle 上使用 Oracle PL/SQL Developer 建構機器學習模型。
開發人員可透過 BigQuery ML 執行多種模型,例如線性迴歸、二元邏輯迴歸、多元類別邏輯迴歸、k-means 分群,以及匯入 TensorFlow 模型。詳情請參閱 BigQuery ML 簡介。
轉換 ODM 工作時,可能需要重寫程式碼。您可以選擇各種 Google AI 產品,例如 BigQuery ML、AI API (Speech-to-Text、Text-to-Speech、Dialogflow、Cloud Translation、Cloud Natural Language API、Cloud Vision、Timeseries Insights API 等),或是 Vertex AI。
Vertex AI Workbench 可做為數據資料學家的開發環境,Vertex AI Training 則可用於大規模執行訓練和評分工作負載。
空間和圖表選項
Oracle 提供 Spatial 和 Graph 選項,用於查詢幾何和圖形,但必須取得授權才能使用。您可以在 BigQuery 中使用幾何函式,不必支付額外費用或取得授權,並在 Google Cloud中使用其他圖形資料庫。
立體
BigQuery 提供地理空間分析函式和資料類型。詳情請參閱「使用 地理空間分析資料」。Oracle Spatial 資料類型和函式可以轉換為 BigQuery 標準 SQL 中的地理函式。地理位置函式不會在標準 BigQuery 定價之外加收費用。
圖表
JanusGraph 是開放原始碼的圖形資料庫解決方案,可使用 Bigtable 做為儲存空間後端。詳情請參閱「在 GKE 上使用 Bigtable 執行 JanusGraph」。
Neo4j 是另一種圖形資料庫解決方案,以 Google Cloud 服務形式提供,可在 Google Kubernetes Engine (GKE) 上執行。
Oracle Application Express
Oracle Application Express (APEX) 應用程式是 Oracle 獨有的,因此需要重新編寫。您可以使用 Looker Studio 或 BI 引擎開發報表和資料視覺化功能,而應用程式層級功能 (例如建立及編輯資料列) 則可透過 AppSheet 搭配 Cloud SQL 開發,完全不需編寫程式碼。
後續步驟
- 瞭解如何最佳化工作負載,全面提升效能並降低成本。
- 瞭解如何在 BigQuery 中最佳化儲存空間。
- 如要瞭解 BigQuery 的最新消息,請參閱版本資訊。
- 請參閱 Oracle SQL 翻譯指南。