
המסמך הזה הוא החלק השני בסדרה שעוסקת בשחזור לאחר אסון (DR) ב- Google Cloud. בקטע הזה נדון בשירותים ובמוצרים שבהם אפשר להשתמש כאבני בניין לתוכנית ההתאוששות מאסון – גם מוצרים של Google Cloud וגם מוצרים שפועלים בפלטפורמות שונות.
הסדרה מורכבת מהחלקים הבאים:
- מדריך להכנת תוכנית התאוששות מאסון (DR)
- אבני בניין של תוכנית התאוששות מאסון (DR) (המאמר הזה)
- תרחישי התאוששות מאסון (DR) לנתונים
- תרחישים של התאוששות מאסון (DR) לאפליקציות
- תכנון תוכנית התאוששות מאסון (DR) לעומסי עבודה שמוגבלים למיקום
- תרחישי שימוש בתוכנית התאוששות מאסון (DR): אפליקציות לניתוח נתונים עם הגבלות על מיקום
- תכנון תוכנית התאוששות מאסון (DR) להפסקות זמניות בתשתית הענן
Google Cloud מציעה מגוון רחב של מוצרים שבהם אפשר להשתמש כחלק מארכיטקטורת ההתאוששות מאסון. בקטע הזה נסביר על התכונות שקשורות ל-DR במוצרים הנפוצים ביותר שמשמשים כאבני בניין ל- Google Cloud DR.
רבים מהשירותים האלה כוללים תכונות של זמינות גבוהה (HA). זמינות גבוהה (HA) לא חופפת לחלוטין להתאוששות מאסון (DR), אבל הרבה מהיעדים של זמינות גבוהה רלוונטיים גם לעיצוב תוכנית התאוששות מאסון. לדוגמה, באמצעות תכונות של זמינות גבוהה, אתם יכולים לתכנן ארכיטקטורות שמבצעות אופטימיזציה של זמן הפעולה, ויכולות לצמצם את ההשפעות של כשלים בקנה מידה קטן, כמו כשל במכונה וירטואלית אחת. מידע נוסף על הקשר בין DR ל-HA זמין במדריך לתכנון התאוששות מאסון.
בקטעים הבאים מתוארים אבני הבניין של Google Cloud DR ומוסבר איך הן עוזרות לכם להשיג את יעדי ה-DR.
מחשוב ואחסון
בטבלה הבאה מופיע סיכום של התכונות בשירותי מחשוב ואחסון שמשמשים כאבני בניין ל-DR: Google Cloud
| מוצר | תכונה |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
למידע נוסף על האופן שבו התכונות והעיצוב של המוצרים האלה ושל מוצרים אחרים שלGoogle Cloud עשויים להשפיע על אסטרטגיית תוכנית ההתאוששות מאסון (DR) שלכם, ראו Architecting disaster recovery for cloud infrastructure outages: product reference.
Compute Engine
Compute Engine מספק מכונות וירטואליות (VM). הוא המנוע העיקרי של Google Cloud. בנוסף להגדרת מכונות Compute Engine, להפעלתן ולמעקב אחריהן, בדרך כלל משתמשים במגוון תכונות קשורות כדי ליישם תוכנית DR.
בתרחישי DR, אפשר למנוע מחיקה בטעות של מכונות וירטואליות על ידי הגדרת דגל ההגנה מפני מחיקה. האפשרות הזו שימושית במיוחד כשמארחים שירותים עם שמירת מצב, כמו מסדי נתונים.
במאמר תכנון מערכות עמידות מוסבר איך להשיג ערכי RTO ו-RPO נמוכים.
תבניות של הגדרות מכונה
אתם יכולים להשתמש בתבניות של מכונות וירטואליות ב-Compute Engine כדי לשמור את פרטי ההגדרה של מכונת ה-VM, ואז ליצור מכונות ב-Compute Engine מתבניות קיימות של מכונות. אתם יכולים להשתמש בתבנית כדי להפעיל כמה מופעים שאתם צריכים, שמוגדרים בדיוק כמו שאתם רוצים, כשאתם צריכים להקים את סביבת היעד של DR. תבניות מכונה משוכפלות באופן גלובלי, כך שאפשר ליצור מחדש את המכונה בכל מקום ב- Google Cloud עם אותה הגדרה.
מידע נוסף זמין במקורות המידע הבאים:
פרטים על השימוש בתמונות של Compute Engine מופיעים בהמשך המאמר בקטע איזון בין הגדרת תמונות לבין מהירות הפריסה.
קבוצות של מופעי מכונה מנוהלים
קבוצות של מופעים מנוהלים פועלות עם Cloud Load Balancing (שמוסבר בהמשך המסמך הזה) כדי להפיץ תנועה לקבוצות של מופעים עם הגדרות זהות שמועתקים בין אזורים. קבוצות מופעי מכונה מנוהלים מאפשרות שימוש בתכונות כמו התאמה אוטומטית לעומס (automatic scaling) ותיקון תוכנה אוטומטי (autohealing), שבהן קבוצת מופעי מכונה מנוהלים יכולה למחוק מופעים וליצור אותם מחדש באופן אוטומטי.
הזמנות
ב-Compute Engine אפשר להזמין מכונות וירטואליות באזור ספציפי, באמצעות סוגי מכונות בהתאמה אישית או מוגדרים מראש, עם או בלי יחידות GPU נוספות או SSD מקומיות. כדי להבטיח קיבולת לעומסי עבודה קריטיים למשימה לצורך DR, מומלץ ליצור הזמנות באזורי היעד של ה-DR. בלי הזמנות, יכול להיות שלא תקבלו את הקיבולת על פי דרישה שאתם צריכים כדי לעמוד ביעד למשך ההתאוששות. הזמנות יכולות להיות שימושיות בתרחישי DR קרים, חמים או חמים מאוד. הם מאפשרים לכם לשמור משאבי שחזור זמינים ליתירות כשל כדי לעמוד בדרישות RTO נמוכות יותר, בלי שתצטרכו להגדיר ולפרוס אותם מראש באופן מלא.
דיסקים לאחסון מתמיד ותמונות מצב
דיסקים לאחסון מתמיד (persistent disk) הם מכשירים עמידים לאחסון ברשת שלמכונות שלכם יש אפשרות גישה אליהם. הם לא תלויים במופעים שלכם, כך שאתם יכולים לנתק ולהעביר דיסקים קשיחים כדי לשמור את הנתונים גם אחרי שאתם מוחקים את המופעים.
אתם יכולים ליצור גיבויים מצטברים או תמונות מצב של מכונות וירטואליות ב-Compute Engine, שאפשר להעתיק בין אזורים ולהשתמש בהם כדי ליצור מחדש דיסקים מתמידים במקרה של אסון. בנוסף, אפשר ליצור תמונות מצב של דיסקים קבועים כדי להגן על נתונים מפני אובדן נתונים בגלל טעות משתמש. קובצי ה-Snapshot הם מצטברים, והיצירה שלהם אורכת רק כמה דקות, גם אם דיסקי ה-Snapshot מצורפים למופעים פעילים.
לדיסקים קבועים יש יתירות מובנית כדי להגן על הנתונים מפני כשל בציוד, וכדי להבטיח את זמינות הנתונים במהלך אירועי תחזוקה של מרכזי נתונים. דיסקים לאחסון מתמיד הם אזוריים או של תחום מוגדר. דיסקים לאחסון מתמיד אזוריים משכפלים פעולות כתיבה בשני אזורים באזור. במקרה של הפסקה זמנית בשירות אזורית, מופע VM לגיבוי יכול לכפות חיבור של Persistent Disk אזורי באזור המשני. מידע נוסף זמין במאמר אפשרויות לזמינות גבוהה באמצעות דיסקים קשיחים אזוריים.
תחזוקה שקופה
Google מתחזקת את התשתית שלה באופן קבוע על ידי תיקון מערכות באמצעות התוכנה העדכנית ביותר, ביצוע בדיקות שגרתיות ותחזוקה מונעת, ופועלת כדי לוודא שהתשתית של Google מהירה ויעילה ככל האפשר.
כברירת מחדל, כל המכונות ב-Compute Engine מוגדרות כך שאירועי התחזוקה האלה שקופים לאפליקציות ולעומסי העבודה שלכם. מידע נוסף זמין במאמר בנושא תחזוקה שקופה.
כשמתרחש אירוע תחזוקה, Compute Engine משתמש בהעברה פעילה כדי להעביר אוטומטית את המופעים הפועלים למארח אחר באותו אזור. מיגרציה פעילה מאפשרת ל-Google לבצע תחזוקה שחיונית לשמירה על אבטחת התשתית ועל האמינות שלה, בלי להפריע למכונות הווירטואליות שלכם.
כלי לייבוא דיסקים וירטואליים
הכלי ייבוא דיסק וירטואלי מאפשר לייבא פורמטים של קבצים, כולל VMDK, VHD ו-RAW, כדי ליצור מכונות וירטואליות חדשות ב-Compute Engine. באמצעות הכלי הזה, אפשר ליצור מכונות וירטואליות ב-Compute Engine עם אותה הגדרה כמו המכונות הווירטואליות המקומיות. הגישה הזו מתאימה למקרים שבהם אי אפשר להגדיר תמונות של Compute Engine מקובצי ההפעלה של תוכנה שכבר מותקנת בתמונות.
גיבויים אוטומטיים
אתם יכולים להשתמש בתגים כדי להפוך את הגיבויים של מכונות Compute Engine לאוטומטיים. לדוגמה, אתם יכולים ליצור תבנית של תוכנית גיבוי באמצעות שירות Backup and DR, ולהחיל את התבנית באופן אוטומטי על המכונות של Compute Engine.
מידע נוסף זמין במאמר בנושא אוטומציה של ההגנה על מופעים חדשים של Compute Engine.
Cloud Storage
Cloud Storage הוא מאגר אובייקטים שמתאים במיוחד לאחסון קובצי גיבוי. הוא מספק סוגי אחסון שונים שמתאימים לתרחישי שימוש ספציפיים, כמו שמוצג בתרשים הבא.

במקרים של DR, כדאי להתעניין במיוחד ב-Nearline, ב-Coldline וב-Archive Storage. סוגי האחסון האלה מפחיתים את עלות האחסון בהשוואה ל-Standard Storage. עם זאת, יש עלויות נוספות שקשורות לאחזור נתונים או מטא-נתונים שמאוחסנים בסוגי האחסון האלה, וגם משך אחסון מינימלי שאתם מחויבים עליו. Nearline מיועד לתרחישי גיבוי שבהם הגישה היא לכל היותר פעם בחודש, ולכן הוא אידיאלי לביצוע בדיקות מאמץ קבועות של DR תוך שמירה על עלויות נמוכות.
האחסון ב-Nearline, ב-Coldline ובארכיון מותאם לגישה לא תדירה, ומודל התמחור מתוכנן בהתאם. לכן תחויבו על משך אחסון מינימלי, ויהיו עלויות נוספות על אחזור נתונים או מטא-נתונים בסוגי האחסון האלה לפני משך האחסון המינימלי שנקבע לסוג האחסון.
כדי להגן על הנתונים בקטגוריה של Cloud Storage מפני מחיקה מקרית או זדונית, אפשר להשתמש בתכונה מחיקה זמנית כדי לשמור אובייקטים שנמחקו או שנכתבו מחדש למשך תקופה מוגדרת, ובתכונה השהיות של אובייקטים כדי למנוע מחיקה או עדכון של אובייקטים.
Storage Transfer Service מאפשר לייבא נתונים מ-Amazon S3, מ-Azure Blob Storage או ממקורות נתונים מקומיים אל Cloud Storage. בתרחישי DR, אפשר להשתמש ב-Storage Transfer Service כדי:
- גיבוי נתונים מספקי אחסון אחרים לקטגוריה של Cloud Storage.
- העברת נתונים מקטגוריה בשני אזורים או במספר אזורים לקטגוריה באזור מסוים כדי להקטין את העלויות של אחסון גיבויים.
Filestore
מופעי Filestore הם שרתי קבצים מנוהלים מסוג NFS לשימוש עם אפליקציות שפועלות במופעים של Compute Engine או באשכולות GKE.
רמות השירות Filestore Basic ו-Zonal הן משאבים של תחום מוגדר ולא תומכות בשכפול בין תחומים, בעוד שמופעים של רמת השירות Filestore Enterprise הם משאבים אזוריים. כדי לשפר את העמידות של סביבת Filestore, מומלץ להשתמש במופעים ברמת Enterprise.
Google Kubernetes Engine
GKE היא סביבה מנוהלת שמוכנה לייצור, לפריסה של אפליקציות בקונטיינרים. GKE מאפשר לכם לתזמן מערכות HA, וכולל את התכונות הבאות:
- תיקון אוטומטי של צמתים. אם צומת נכשל בבדיקות תקינות רצופות במשך תקופה ממושכת (כ-10 דקות), GKE מתחיל תהליך תיקון של הצומת הזה.
- בדיקות מצב פעילות ובקשות לבדיקת תקינות מוכנות. אפשר לציין בדיקת מצב פעילות (liveness probe), שמודיעה ל-GKE באופן תקופתי שה-Pod פועל. אם בדיקת התקינות של ה-pod נכשלת, אפשר להפעיל אותו מחדש.
- אשכולות אזוריים ואשכולות בכמה אזורים. אפשר לפרוס משאבי Kubernetes בכמה אזורים בתוך אזור מסוים.
- Multi-cluster Gateway מאפשר להגדיר משאבי איזון עומסים משותפים בכמה אשכולות GKE באזורים שונים.
- גיבוי ל-GKE מאפשר לכם לגבות ולשחזר עומסי עבודה באשכולות GKE.
נטוורקינג והעברת נתונים
בטבלה הבאה מופיע סיכום של התכונות בשירותי הרשת והעברת הנתונים של Google Cloud , שמשמשים כאבני בניין להתאוששות מאסון:
| מוצר | תכונה |
|---|---|
| Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
Cloud Load Balancing מספק זמינות גבוהה למוצרי מחשוב על ידי חלוקת תנועת המשתמשים בין כמה מופעים של האפליקציות שלכם. Google Cloud אפשר להגדיר את Cloud Load Balancing עם בדיקות תקינות שקובעות אם מופעים זמינים לביצוע עבודה, כדי שלא תהיה הפניית תנועה למופעים שנכשלו.
Cloud Load Balancing מספק כתובת IP אחת מסוג anycast כדי להציג את האפליקציות שלכם. יכול להיות שלאפליקציות שלכם יש מופעים שפועלים באזורים שונים (לדוגמה, באירופה ובארה"ב), ומשתמשי הקצה מופנים לקבוצת המופעים הקרובה ביותר. בנוסף לאיזון עומסים בשירותים שחשופים לאינטרנט, אפשר להגדיר איזון עומסים פנימי בשירותים שמוגדרים מאחורי כתובת IP פרטית של איזון עומסים. אפשר לגשת לכתובת ה-IP הזו רק ממכונות וירטואליות (VM) שהן פנימיות לענן וירטואלי פרטי (VPC).
מידע נוסף זמין במאמר סקירה כללית על Cloud Load Balancing.
Cloud Service Mesh
Cloud Service Mesh היא רשת Service mesh בניהול Google שזמינה ב- Google Cloud. Cloud Service Mesh מספק טלמטריה מעמיקה שתעזור לכם לאסוף תובנות מפורטות לגבי האפליקציות שלכם. הוא תומך בשירותים שפועלים במגוון תשתיות מחשוב.
Cloud Service Mesh תומך גם בתכונות מתקדמות של ניהול תעבורה וניתוב, כמו ניתוק מעגל והזרקת תקלות. באמצעות ניתוק מעגל, אפשר לאכוף מגבלות על בקשות לשירות מסוים. כשמגיעים למגבלות של ניתוק המעגל, הבקשות לא מגיעות לשירות, וכך נמנעת פגיעה נוספת בשירות. באמצעות הזרקת תקלות, Cloud Service Mesh יכול להוסיף עיכובים או לבטל חלק מהבקשות לשירות. הזרקת תקלות מאפשרת לכם לבדוק את היכולת של השירות להתמודד עם עיכובים בבקשות או עם בקשות שבוטלו.
מידע נוסף זמין בסקירה הכללית על Cloud Service Mesh.
Cloud DNS
Cloud DNS מספק דרך לתכנת את ניהול רשומות ה-DNS כחלק מתהליך שחזור אוטומטי. שירות Cloud DNS משתמש ברשת הגלובלית של Google של שרתי שמות Anycast כדי להציג את אזורי ה-DNS שלכם ממיקומים עודפים ברחבי העולם, וכך מספק זמינות גבוהה וזמן אחזור נמוך יותר למשתמשים.
אם בחרתם לנהל רשומות DNS מקומיות, אתם יכולים להפעיל מכונות וירטואליות ב-Google Cloud כדי לפתור את הכתובות האלה באמצעות העברה של Cloud DNS.
Cloud DNS תומך במדיניות להגדרת אופן התגובה לבקשות DNS. לדוגמה, אפשר להגדיר מדיניות ניתוב של DNS כדי לנתב תנועה על סמך קריטריונים ספציפיים, כמו הפעלת מעבר לגיבוי במקרה של כשל כדי לספק זמינות גבוהה, או ניתוב של בקשות DNS על סמך המיקום הגאוגרפי שלהן.
Cloud Interconnect
Cloud Interconnect מספק דרכים להעברת מידע ממקורות אחרים אל Google Cloud. בהמשך המאמר נסביר על המוצר הזה בקטע העברת נתונים אל Google Cloud.
ניהול ומעקב
בטבלה הבאה מופיע סיכום של התכונות בשירותי הניהול והמעקב שמשמשים כאבני בניין ל-DR: Google Cloud
| מוצר | תכונה |
|---|---|
| לוח הבקרה של סטטוס שירותי הענן |
|
| Google Cloud Observability |
|
| השירות המנוהל של Google Cloud ל-Prometheus |
|
לוח הבקרה של סטטוס שירותי הענן
בלוח הבקרה של סטטוס שירותי הענן מוצגת הזמינות הנוכחית של שירותים. Google Cloud אפשר לראות את הסטטוס בדף, ולהירשם לפיד RSS שמתעדכן בכל פעם שיש חדשות לגבי שירות.
Cloud Monitoring
Cloud Monitoring אוסף מדדים, אירועים ומטא-נתונים מ- Google Cloud, מ-AWS, מבקשות לבדיקת תקינות של זמן פעילות במארחים, מאינסטרומנטציה של אפליקציות וממגוון של רכיבים אחרים באפליקציות. אתם יכולים להגדיר התראות כדי לשלוח עדכונים לאדמינים בזמן אמת באמצעות כלים של צד שלישי כמו Slack או Pagerduty.
בעזרת Cloud Monitoring אפשר ליצור בדיקות זמני פעילות עבור נקודות קצה שזמינות לציבור ועבור נקודות קצה ברשתות ה-VPC. לדוגמה, אתם יכולים לעקוב אחרי כתובות URL, מכונות של Compute Engine, גרסאות של Cloud Run ומשאבים של צד שלישי, כמו מכונות של Amazon Elastic Compute Cloud (EC2).
השירות המנוהל של Google Cloud ל-Prometheus
השירות המנוהל של Google Cloud ל-Prometheus הוא פתרון מרובה-עננים, חוצה-פרויקטים ומנוהל על ידי Google למדדי Prometheus. השירות מאפשר לכם לעקוב אחרי עומסי העבודה שלכם ולשלוח התראות לגביהם באופן גלובלי באמצעות Prometheus, בלי שתצטרכו לנהל ולהפעיל את Prometheus באופן ידני בהיקף גדול.
מידע נוסף זמין במאמר בנושא השירות המנוהל של Google Cloud ל-Prometheus.
אבני בניין של DR בפלטפורמות שונות
כשמריצים עומסי עבודה ביותר מפלטפורמה אחת, כדי לצמצם את התקורה התפעולית כדאי לבחור כלי שמתאים לכל הפלטפורמות שבהן משתמשים. בקטע הזה נדון בכמה כלים ושירותים שהם בלתי תלויים בפלטפורמה, ולכן תומכים בתרחישי DR בפלטפורמות שונות.
תשתית כקוד
הגדרת התשתית באמצעות קוד, במקום באמצעות ממשקים גרפיים או סקריפטים, מאפשרת להשתמש בכלי תבניות הצהרותיות ולבצע אוטומציה של הקצאת משאבים והגדרת תשתית בפלטפורמות שונות. לדוגמה, אתם יכולים להשתמש ב-Terraform וב-Infrastructure Manager כדי להפעיל את הגדרת התשתית הדקלרטיבית.
כלי ניהול הגדרות
למערכות DR גדולות או מורכבות, מומלץ להשתמש בכלים לניהול תוכנה שאינם תלויים בפלטפורמה, כמו Chef ו-Ansible. הכלים האלה מבטיחים שאפשר להחיל תצורות שניתנות לשחזור, לא משנה איפה עומס העבודה של המחשוב נמצא.
כלים לניהול תזמורת
אפשר גם לראות בקונטיינרים אבני בניין של DR. קונטיינרים הם דרך לארוז שירותים ולהבטיח עקביות בין פלטפורמות.
אם אתם עובדים עם קונטיינרים, בדרך כלל אתם משתמשים בכלי תזמור. Kubernetes לא רק מנהל קונטיינרים בתוך Google Cloud (באמצעות GKE), אלא גם מספק דרך לתזמר עומסי עבודה מבוססי-קונטיינרים במספר פלטפורמות. Google Cloud, AWS ו-Microsoft Azure מספקות גרסאות מנוהלות של Kubernetes.
כדי להפיץ תעבורה לאשכולות Kubernetes שפועלים בפלטפורמות שונות של Cloud, אפשר להשתמש בשירות DNS שתומך ברשומות משוקללות וכולל בדיקות תקינות.
צריך גם לוודא שאפשר למשוך את התמונה לסביבת היעד. כלומר, אתם צריכים להיות מסוגלים לגשת למאגר התמונות שלכם במקרה של אסון. אפשרות טובה נוספת שלא תלויה בפלטפורמה היא Artifact Registry.
העברת נתונים
העברת נתונים היא רכיב קריטי בתרחישי DR בפלטפורמות שונות. חשוב לתכנן, להטמיע ולבדוק את תרחישי ה-DR בין פלטפורמות שונות באמצעות מודלים מציאותיים של מה שנדרש בתרחיש העברת נתוני ה-DR. בקטע הבא נדון בתרחישים של העברת נתונים.
שירות Backup and DR
שירות Backup and DR הוא פתרון לגיבוי ול-DR של עומסי עבודה בענן. הוא עוזר לכם לשחזר נתונים ולחדש פעולות עסקיות קריטיות, ותומך בכמהGoogle Cloud מוצרים ומאגרי נתונים של צד שלישי ומערכות לאחסון נתונים.
מידע נוסף זמין במאמר סקירה כללית על שירות Backup and DR.
תבניות ל-DR
בקטע הזה נדון בכמה מהדפוסים הנפוצים ביותר לארכיטקטורות של DR, שמבוססים על אבני הבניין שצוינו קודם.
העברת נתונים אל Google Cloudוממנו
היבט חשוב בתוכנית ההתאוששות מאסון הוא המהירות שבה אפשר להעביר נתונים אל Google Cloudוממנו. זה חשוב במיוחד אם תוכנית ה-DR שלכם מבוססת על העברת נתונים משרתים מקומיים אל Google Cloud או מספק שירותי ענן אחר אל Google Cloud. בקטע הזה נדון בשירותי רשת ובשירותיGoogle Cloud שיכולים להבטיח תפוקה טובה.
כשמשתמשים ב- Google Cloud כאתר לשחזור עומסי עבודה שנמצאים במערכת מקומית בארגון או בסביבת ענן אחרת, כדאי להתייחס לפריטים העיקריים הבאים:
- איך מתחברים אל Google Cloud?
- מה רוחב הפס בין הלקוח לבין ספק הקישוריות?
- מה רוחב הפס שהספק מספק ישירות ל Google Cloud?
- אילו נתונים נוספים יועברו באמצעות הקישור הזה?
מידע נוסף על העברת נתונים אל Google Cloudזמין במאמר מעבר אל Google Cloud: העברת מערכי נתונים גדולים.
איזון בין הגדרת תמונות לבין מהירות הפריסה
כשמגדירים תמונת מכונה לפריסת מופעים חדשים, כדאי לקחת בחשבון את ההשפעה של ההגדרה על מהירות הפריסה. יש פשרה בין כמות ההגדרות המוקדמות של התמונה, העלויות של תחזוקת התמונה ומהירות הפריסה. לדוגמה, אם תמונת מכונה מוגדרת באופן מינימלי, יידרש יותר זמן להפעלת המופעים שמשתמשים בה, כי הם צריכים להוריד ולהתקין תלות. לעומת זאת, אם תמונת המכונה מוגדרת באופן מפורט, המופעים שמשתמשים בה יופעלו מהר יותר, אבל תצטרכו לעדכן את התמונה בתדירות גבוהה יותר. הזמן שיידרש להפעלת מופע שפועל באופן מלא יהיה קשור ישירות ל-RTO שלכם.
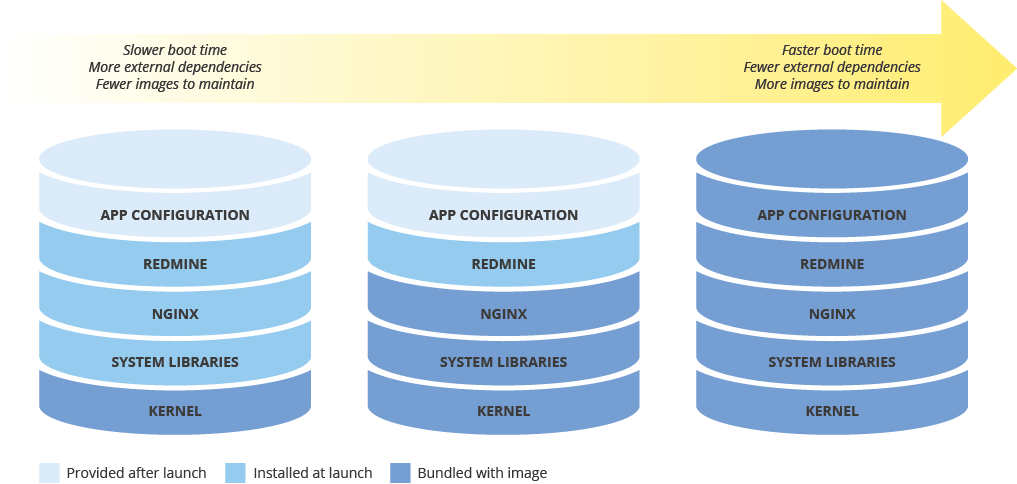
שמירה על עקביות של תמונות מכונה בסביבות היברידיות
אם מטמיעים פתרון היברידי (ממערכות מקומיות לענן או מענן לענן), צריך למצוא דרך לשמור על עקביות התמונות בסביבות הייצור.
אם נדרש קובץ אימג' עם הגדרות מלאות, כדאי להשתמש בכלי כמו Packer, שיכול ליצור קובצי אימג' זהים למכונות בכמה פלטפורמות. אפשר להשתמש באותם סקריפטים עם קובצי תצורה ספציפיים לפלטפורמה. במקרה של Packer, אפשר להוסיף את קובץ התצורה לניהול גרסאות כדי לעקוב אחרי הגרסה שמוטמעת בסביבת הייצור.
אפשרות נוספת היא להשתמש בכלים לניהול תצורה כמו Chef, Puppet, Ansible או Saltstack כדי להגדיר מכונות עם רמת פירוט גבוהה יותר, ליצור תמונות בסיסיות, תמונות עם הגדרה מינימלית או תמונות עם הגדרה מלאה לפי הצורך.
אפשר גם להמיר ולייבא באופן ידני תמונות קיימות, כמו Amazon AMI, תמונות Virtualbox ותמונות דיסק RAW, אל Compute Engine.
הטמעה של אחסון מדורג
הדפוס של אחסון בשכבות משמש בדרך כלל לגיבויים, כשגיבויים מהזמן האחרון מאוחסנים באחסון מהיר יותר, ומעבירים לאט את הגיבויים הישנים יותר לאחסון זול יותר (אבל איטי). באמצעות התבנית הזו, אפשר להעביר גיבויים בין קטגוריות של סוגי אחסון (storage classes) שונים, בדרך כלל מ-Standard לסוגי אחסון זולים יותר, כמו Nearline ו-Coldline.
כדי להטמיע את התבנית הזו, אפשר להשתמש בניהול מחזור החיים של אובייקטים. לדוגמה, אפשר לשנות באופן אוטומטי את סוג האחסון של אובייקטים שהגיל שלהם גדול מפרק זמן מסוים ל-Coldline.
המאמרים הבאים
- Google Cloud מידע נוסף על מיקום גיאוגרפי ואזורים
כדאי לקרוא מאמרים נוספים בסדרה הזו בנושא DR:
- מדריך להכנת תוכנית התאוששות מאסון (DR)
- תרחישי התאוששות מאסון (DR) לנתונים
- תרחישים של התאוששות מאסון (DR) לאפליקציות
- תכנון תוכנית התאוששות מאסון (DR) לעומסי עבודה שמוגבלים למיקום
- תרחישי שימוש בתוכנית התאוששות מאסון (DR): אפליקציות לניתוח נתונים עם הגבלות על מיקום
- תכנון תוכנית התאוששות מאסון (DR) להפסקות זמניות בתשתית הענן
לדוגמאות נוספות של ארכיטקטורות, תרשימים ושיטות מומלצות, עיינו במאמר Cloud Architecture Center.
שותפים ביצירת התוכן
מחברים:
- גרייס מוליסון | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect