
טבלה נגזרת היא שאילתה שהתוצאות שלה משמשות כאילו הטבלה הנגזרת היא טבלה פיזית במסד הנתונים. טבלה נגזרת מבוססת LookML (NDT) מבוססת על שאילתה שמוגדרת באמצעות מונחים של LookML. זה שונה מטבלה נגזרת שמבוססת על SQL, שמבוססת על שאילתה שאתם מגדירים באמצעות מונחי SQL. בהשוואה לטבלאות נגזרות שמבוססות על SQL, טבלאות נגזרות מקוריות קלות יותר לקריאה ולהבנה כשמבצעים מודלים של הנתונים. מידע נוסף זמין בקטע טבלאות נגזרות מקוריות וטבלאות נגזרות שמבוססות על SQL בדף התיעוד טבלאות נגזרות ב-Looker.
טבלאות נגזרות מובנות וטבלאות נגזרות שמבוססות על SQL מוגדרות ב-LookML באמצעות הפרמטר derived_table ברמת התצוגה. עם זאת, בטבלאות נגזרות מקוריות, לא צריך ליצור שאילתת SQL. במקום זאת, משתמשים בפרמטר explore_source כדי לציין את הניתוח שעל בסיסו תיבנה הטבלה הנגזרת, את העמודות הרצויות ומאפיינים רצויים אחרים.
אפשר גם להשתמש ב-Looker כדי ליצור את טבלת LookML הנגזרת משאילתה של SQL Runner, כמו שמתואר בדף התיעוד שימוש ב-SQL Runner ליצירת טבלאות נגזרות.
שימוש ב-Explore כדי להתחיל להגדיר טבלאות נגזרות מותאמות
החל מניתוח, Looker יכול ליצור LookML לכל הטבלה הנגזרת או לרוב החלקים שלה. פשוט יוצרים ניתוח ובודקים שכל השדות שרוצים לכלול בטבלה הנגזרת נבחרו. לאחר מכן, כדי ליצור את קוד ה-LookML של הטבלה הנגזרת מבוססת LookML (NDT), בצע את השלבים הבאים:
לוחצים על סמל גלגל השיניים Explore Actions ובוחרים באפשרות Get LookML.
לוחצים על הכרטיסייה Derived Table (טבלה נגזרת) כדי לראות את קוד ה-LookML ליצירת טבלה נגזרת מבוססת LookML (NDT) עבור ה-Explore.
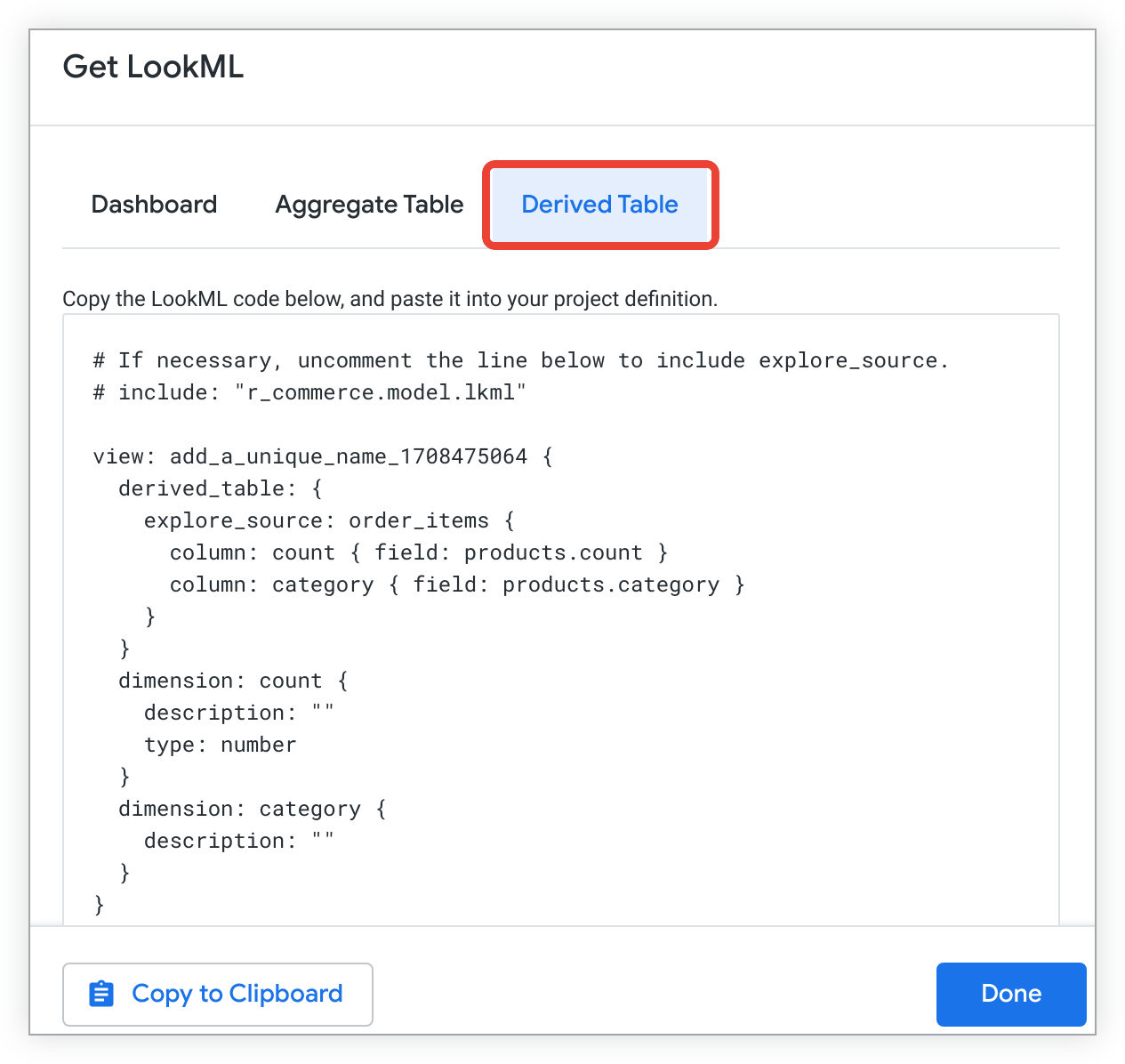
מעתיקים את קוד ה-LookML.
אחרי שהעתקתם את קוד ה-LookML שנוצר, מדביקים אותו בקובץ תצוגה:
במצב פיתוח, עוברים אל קבצי הפרויקט.
לוחצים על + בחלק העליון של רשימת קובצי הפרויקט ב-Looker IDE ובוחרים באפשרות Create View (יצירת תצוגה). לחלופין, אפשר ללחוץ על תפריט התיקייה ולבחור באפשרות יצירת תצוגה כדי ליצור את הקובץ בתוך התיקייה.
נותנים לתצוגה שם בעל משמעות.
אפשר גם לשנות את שמות העמודות, לציין עמודות נגזרות ולהוסיף מסננים.
כשמשתמשים במדד של
type: countב'ניתוח נתונים', התוויות של הערכים שמתקבלים בתרשים הן השם של התצוגה ולא המילה ספירה. כדי למנוע בלבול, כדאי להשתמש בשם ברבים לתצוגה. כדי לשנות את שם התצוגה, אפשר לבחור באפשרות הצגת שם השדה המלא בקטע סדרה בהגדרות הוויזואליזציה, או להשתמש בפרמטרview_labelעם גרסה ברבים של שם התצוגה.
הגדרה של טבלה נגזרת מבוססת LookML
בין אם משתמשים בטבלאות נגזרות שהוגדרו ב-SQL או ב-LookML מקורי, הפלט של שאילתת derived_table's הוא טבלה עם קבוצה של עמודות. כשהטבלה הנגזרת מבוטאת ב-SQL, שמות עמודות הפלט משתמעים משאילתת ה-SQL. לדוגמה, שאילתת ה-SQL הבאה תכלול את עמודות הפלט user_id, lifetime_number_of_orders ו-lifetime_customer_value:
SELECT
user_id
, COUNT(DISTINCT order_id) as lifetime_number_of_orders
, SUM(sale_price) as lifetime_customer_value
FROM order_items
GROUP BY 1
ב-Looker, שאילתה מבוססת על ניתוח, כוללת שדות של מדדים ומאפיינים, מוסיפה מסננים רלוונטיים, ויכולה גם לציין סדר מיון. טבלה נגזרת מקורית מכילה את כל הרכיבים האלה, בנוסף לשמות הפלט של העמודות.
בדוגמה הפשוטה הבאה נוצרת טבלה נגזרת עם שלוש עמודות: user_id, lifetime_customer_value ו-lifetime_number_of_orders. לא צריך לכתוב את השאילתה ב-SQL באופן ידני – במקום זאת, Looker יוצר את השאילתה בשבילכם באמצעות הניתוח שצוין ב'הצגה כניתוח' order_items וחלק מהשדות של הניתוח הזה (order_items.user_id, order_items.total_revenue ו-order_items.order_count).
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
}
שימוש בהצהרות include כדי לאפשר הפניה לשדות
בקובץ התצוגה של טבלת הנתונים הנגזרים המקוריים, משתמשים בפרמטר explore_source כדי להפנות אל כלי הניתוח, וכדי להגדיר את העמודות ומאפיינים אחרים של טבלת הנתונים הנגזרים המקוריים.
בקובץ התצוגה של טבלת הנתונים הנגזרת המקורית, לא צריך להשתמש בפרמטר include כדי להפנות לקובץ שמכיל את ההגדרה של הניתוח. אם לא מציינים את ההצהרה include, סביבת הפיתוח המשולבת של Looker לא autosuggest שמות של שדות ולא תאמת את ההפניות לשדות בזמן שיוצרים את טבלת הנתונים הנגזרת מבוססת LookML (NDT). במקום זאת, אפשר להשתמש בכלי לאימות LookML כדי לאמת את השדות שמופיעים בהפניה בטבלת הנתונים הנגזרים המקורית.
עם זאת, אם רוצים להפעיל את ההשלמה האוטומטית ואת האימות המיידי של השדה בסביבת הפיתוח המשולבת (IDE) של Looker, או אם יש פרויקט LookML מורכב עם כמה רכיבי Explore באותו שם או עם פוטנציאל להפניות מעגליות, אפשר להשתמש בפרמטר include כדי להפנות למיקום של הגדרת רכיב ה-Explore.
ניתוחים מוגדרים בדרך כלל בקובץ מודל, אבל במקרה של טבלאות נגזרות מקוריות, עדיף ליצור קובץ נפרד לניתוח. לקובצי LookML Explore יש את הסיומת .explore.lkml, כפי שמתואר במסמכי התיעוד בנושא יצירת קובצי Explore. כך תוכלו לכלול קובץ Explore אחד בקובץ התצוגה של הטבלה הנגזרת מבוססת LookML (NDT) המקורית, ולא את כל קובץ המודל.
אם אתם רוצים ליצור קובץ Explore נפרד ולהשתמש בפרמטר include כדי להפנות לקובץ Explore בקובץ התצוגה של טבלה נגזרת מבוססת LookML (NDT), אתם צריכים לוודא שקובצי ה-LookML שלכם עומדים בדרישות הבאות:
- קובץ התצוגה של טבלת הנתונים הנגזרת המקורית צריך לכלול את הקובץ של כלי הניתוח. לדוגמה:
include: "/explores/order_items.explore.lkml"
- קובץ ה-Explore צריך לכלול את קובצי התצוגה שהוא צריך. לדוגמה:
include: "/views/order_items.view.lkml"include: "/views/users.view.lkml"
- המודל צריך לכלול את קובץ הניתוח. לדוגמה:
include: "/explores/order_items.explore.lkml"
הגדרת עמודות של טבלה נגזרת מבוססת LookML (NDT)
כפי שמוצג בדוגמה הקודמת, משתמשים ב-column כדי לציין את עמודות הפלט של הטבלה הנגזרת.
ציון שמות העמודות
בעמודה user_id, שם העמודה זהה לשם השדה שצוין בניתוח המקורי.
לרוב, תרצו שם עמודה שונה בטבלת הפלט משם השדות בניתוח המקורי. בדוגמה הקודמת, חישוב ערך חיי המשתמש בוצע באמצעות הכלי order_items ניתוח. בטבלת הפלט, total_revenue הוא למעשה lifetime_customer_value של לקוח.
ההצהרה column תומכת בהצהרה על שם פלט ששונה משדה להזנת קלט. לדוגמה, הקוד הבא מורה ל-Looker "ליצור עמודת פלט בשם lifetime_value מהשדה order_items.total_revenue":
column: lifetime_value {
field: order_items.total_revenue
}
שמות עמודות משתמעים
אם לא מציינים את הפרמטר field בהצהרה על עמודה, המערכת מניחה שהערך שלו הוא <explore_name>.<field_name>. לדוגמה, אם ציינתם explore_source: order_items, אז
column: user_id {
field: order_items.user_id
}
שווה ערך ל-
column: user_id {}
יצירת עמודות נגזרות לערכים מחושבים
אפשר להוסיף פרמטרים של derived_column כדי לציין עמודות שלא קיימות בפרמטר explore_source של Explore. לכל פרמטר derived_column יש פרמטר sql שמציין איך ליצור את הערך.
בחישוב של sql אפשר להשתמש בכל העמודות שציינתם באמצעות פרמטרים של column. עמודות נגזרות לא יכולות לכלול פונקציות צבירה, אבל הן יכולות לכלול חישובים שאפשר לבצע בשורה אחת בטבלה.
הדוגמה הבאה יוצרת את אותה טבלה נגזרת כמו בדוגמה הקודמת, אבל היא מוסיפה עמודה מחושבת average_customer_order, שמחושבת מהעמודות lifetime_customer_value ו-lifetime_number_of_orders בטבלה נגזרת מבוססת LookML (NDT).
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
שימוש בפונקציות חלון ב-SQL
חלק מהניבים של מסדי נתונים תומכים בפונקציות חלון, במיוחד כדי ליצור מספרי רצף, מפתחות ראשיים, סכומים מצטברים וחישובים שימושיים אחרים של כמה שורות. אחרי שהשאילתה הראשית מופעלת, כל ההצהרות של derived_column מופעלות במעבר נפרד.
אם הדיאלקט של מסד הנתונים תומך בפונקציות אנליטיות (window function), אפשר להשתמש בהן בטבלה נגזרת מבוססת LookML (NDT). יוצרים פרמטר derived_column עם פרמטר sql שמכיל את פונקציית החלון הרצויה. כשמתייחסים לערכים, צריך להשתמש בשם העמודה כפי שהוא מוגדר בטבלה הנגזרת מבוססת LookML (NDT) המקורית.
בדוגמה הבאה נוצרת טבלה נגזרת מבוססת LookML שכוללת את העמודות user_id, order_id ו-created_time. לאחר מכן, באמצעות עמודה נגזרת עם פונקציה אנליטית (window function) SQL ROW_NUMBER(), המערכת מחשבת עמודה שמכילה את המספר הסידורי של הזמנת לקוח.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
הוספת מסננים לטבלה נגזרת מבוססת LookML (NDT)
נניח שאתם רוצים ליצור טבלת נתונים נגזרים של ערך הלקוח ב-90 הימים האחרונים. אתם רוצים לבצע את אותם חישובים כמו בדוגמה הקודמת, אבל אתם רוצים לכלול רק רכישות מ-90 הימים האחרונים.
פשוט מוסיפים מסנן לderived_table כדי לסנן עסקאות שבוצעו ב-90 הימים האחרונים. הפרמטר filters של טבלה נגזרת משתמש באותו תחביר שבו משתמשים כדי ליצור מדד מסונן.
view: user_90_day_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: number_of_orders_90_day {
field: order_items.order_count
}
column: customer_value_90_day {
field: order_items.total_revenue
}
filters: [order_items.created_date: "90 days"]
}
}
# Add define view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: number_of_orders_90_day {
type: number
}
dimension: customer_value_90_day {
type: number
}
}
המסננים יתווספו לסעיף WHERE כש-Looker יכתוב את ה-SQL עבור הטבלה הנגזרת.
בנוסף, אפשר להשתמש בתת-פרמטר dev_filters של explore_source עם טבלה נגזרת מבוססת LookML (NDT). הפרמטר dev_filters מאפשר לציין מסננים ש-Looker מחיל רק על גרסאות פיתוח של הטבלה הנגזרת. המשמעות היא שאפשר ליצור גרסאות קטנות ומסוננות של הטבלה כדי לבצע איטרציות ובדיקות בלי לחכות עד שהטבלה המלאה תיבנה אחרי כל שינוי.
הפרמטר dev_filters פועל בשילוב עם הפרמטר filters, כך שכל המסננים מוחלים על גרסת הפיתוח של הטבלה. אם גם dev_filters וגם filters מציינים מסננים לאותה עמודה, dev_filters מקבל עדיפות בגרסת הפיתוח של הטבלה.
מידע נוסף זמין במאמר בנושא עבודה מהירה יותר במצב פיתוח.
שימוש במסננים מבוססי-תבניות
אפשר להשתמש בbind_filters כדי לכלול מסננים מבוססי-תבניות:
bind_filters: {
to_field: users.created_date
from_field: filtered_lookml_dt.filter_date
}
הפעולה הזו זהה לשימוש בקוד הבא בבלוק sql:
{% condition filtered_lookml_dt.filter_date %} users.created_date {% endcondition %}
to_field הוא השדה שהמסנן חל עליו. הערך to_field חייב להיות שדה מתוך explore_source הבסיסי.
השדה from_field מציין את השדה שממנו יתקבל המסנן, אם יש מסנן בזמן הריצה.
בדוגמה bind_filters שלמעלה, Looker ייקח כל מסנן שהוחל על השדה filtered_lookml_dt.filter_date ויחיל את המסנן על השדה users.created_date.
אפשר גם להשתמש בתת-פרמטר bind_all_filters של explore_source כדי להעביר את כל המסננים של זמן הריצה מ-Explore לשאילתת משנה של טבלה נגזרת מבוססת LookML (NDT). מידע נוסף מופיע בדף התיעוד של הפרמטר explore_source.
מיון והגבלה של טבלאות נגזרות מבוססות LookML
אם רוצים, אפשר גם למיין ולהגביל את הטבלאות הנגזרות:
sorts: [order_items.count: desc]
limit: 10
חשוב לזכור: יכול להיות שהשורות ב-Explore יוצגו בסדר שונה מזה של המיון הבסיסי.
המרת טבלאות נגזרות מבוססות LookML לאזורי זמן שונים
אתם יכולים לציין את אזור הזמן של טבלה נגזרת מבוססת LookML (NDT) באמצעות תת-הפרמטר timezone:
timezone: "America/Los_Angeles"
כשמשתמשים בתת-פרמטר timezone, כל הנתונים שמבוססים על זמן בטבלה נגזרת מבוססת LookML (NDT) יומרו לאזור הזמן שצוין. רשימת אזורי הזמן הנתמכים מופיעה בדף התיעוד בנושא ערכי timezone.
אם לא מציינים אזור זמן בהגדרת טבלה נגזרת מבוססת LookML (NDT), לא מתבצעת המרה של אזור זמן בנתונים שמבוססים על זמן, ובמקום זאת, ברירת המחדל של נתונים שמבוססים על זמן היא אזור הזמן של מסד הנתונים.
אם טבלת ה-SQL הנגזרת המקורית לא קבועה, אפשר להגדיר את ערך אזור הזמן ל-"query_timezone" כדי להשתמש אוטומטית באזור הזמן של השאילתה שמופעלת כרגע.