
ניהול המלצות למחיצות ולאשכולות
במאמר הזה מוסבר איך פועל שירות ההמלצות על מחיצות ועל אשכולות, איך צופים בהמלצות ובתובנות ואיך מיישמים את ההמלצות על מחיצות ועל אשכולות.
איך פועלת מערכת ההמלצות
הכלי להמלצות על חלוקה למחיצות וסידור באשכולות ב-BigQuery יוצר המלצות לחלוקה למחיצות או לסידור באשכולות כדי לייעל את הטבלאות ב-BigQuery. כלי ההמלצות מנתח את תהליכי העבודה בטבלאות BigQuery ומציע המלצות לאופטימיזציה טובה יותר של תהליכי העבודה ושל עלויות השאילתות באמצעות חלוקת טבלאות למחיצות או סידור טבלאות באשכולות.
בסקירה הכללית על שירות ההמלצות תוכלו לקרוא מידע נוסף על השירות.
הכלי להמלצות על חלוקה למחיצות ועל אשכולות משתמש בנתוני הביצוע של עומסי העבודה של הארגון מ-30 הימים האחרונים כדי לנתח כל טבלה ב-BigQuery ולזהות הגדרות לא אופטימליות של חלוקה למחיצות ושל אשכולות. בנוסף, הכלי להמלצות משתמש בלמידת מכונה כדי לחזות את מידת האופטימיזציה של ביצוע עומס העבודה באמצעות הגדרות שונות של חלוקה למחיצות או של אשכולות. אם הכלי להמלצות יזהה שחלוקה למחיצות או קיבוץ של טבלה יניבו חיסכון משמעותי, הוא ייצור המלצה. כלי ההמלצות לחלוקה למחיצות ולקיבוץ לאשכולות יוצר את סוגי ההמלצות הבאים:
| סוג טבלה קיים | סוג משנה של המלצה | דוגמה להמלצה |
|---|---|---|
| לא מחולקת למחיצות, לא מקובצת לאשכולות | מחיצה | "Save about 64 slot hours per month by partitioning on column_C by DAY" (חיסכון של כ-64 שעות משבצת בחודש על ידי חלוקה למחיצות בעמודה column_C לפי DAY) |
| לא מחולקת למחיצות, לא מקובצת לאשכולות | אשכול | "Save about 64 slot hours per month by clustering on column_C" (חיסכון של כ-64 שעות שימוש במשבצות זמן בחודש על ידי אשכול על column_C) |
| מחולקת למחיצות, לא מקובצת לאשכולות | אשכול | "Save about 64 slot hours per month by clustering on column_C" |
כל המלצה מורכבת משלושה חלקים:
- הנחיות לחלוקה למחיצות או לאשכולות של טבלה ספציפית
- העמודה הספציפית בטבלה שרוצים לחלק או לאגד
- החיסכון החודשי המשוער מיישום ההמלצה
כדי לחשב את החיסכון הפוטנציאלי בעומס העבודה, שירות המלצות מניח שנתוני עומס העבודה ההיסטוריים מהרצת 30 הימים האחרונים מייצגים את עומס העבודה העתידי.
בנוסף, ה-Recommender API מחזיר מידע על עומסי עבודה של טבלאות בצורה של תובנות. תובנות הן ממצאים שעוזרים לכם להבין את עומס העבודה בפרויקט, ומספקים הקשר נוסף לגבי האופן שבו המלצה על מחיצה או על אשכול יכולה לשפר את העלויות של עומס העבודה.
מגבלות
הכלי להמלצות על חלוקה למחיצות ועל אשכולות לא תומך בטבלאות BigQuery עם SQL מדור קודם. כשיוצרים המלצה, הכלי להמלצות לא כולל בניתוח שלו שאילתות SQL מדור קודם. בנוסף, החלת המלצות על חלוקה למחיצות בטבלאות BigQuery עם SQL מדור קודם תשבור כל תהליך עבודה של SQL מדור קודם בטבלה הזו.
לפני שמיישמים המלצות לגבי חלוקה למחיצות, צריך להעביר את תהליכי העבודה שלכם ב-SQL מדור קודם אל GoogleSQL.
ב-BigQuery אי אפשר לשנות את סכימת החלוקה למחיצות של טבלה במקום. אפשר לשנות את החלוקה למחיצות של טבלה רק בעותק של הטבלה. מידע נוסף זמין במאמר בנושא יישום המלצות לחלוקה למחיצות.
כלי ההמלצות לחלוקה למחיצות וקיבוץ לאשכולות פועל מדי יום. עם זאת, אם ייקח יותר מ-24 שעות עד שההפעלה תושלם, ההפעלה של היום הבא תדלג.
מיקומים
שירות ההמלצות לחלוקה למחיצות וסידור באשכולות זמין במיקומי העיבוד הבאים:
| תיאור האזור | שם האזור | פרטים | |
|---|---|---|---|
| אסיה ואזור האוקיינוס השקט | |||
| דלהי | asia-south2 |
||
| הונג קונג | asia-east2 |
||
| ג'קארטה | asia-southeast2 |
||
| מומבאי | asia-south1 |
||
| אוסקה | asia-northeast2 |
||
| סיאול | asia-northeast3 |
||
| סינגפור | asia-southeast1 |
||
| סידני | australia-southeast1 |
||
| טייוואן | asia-east1 |
||
| טוקיו | asia-northeast1 |
||
| אירופה | |||
| בלגיה | europe-west1 |
|
|
| ברלין | europe-west10 |
||
| אירופה, במספר אזורים | eu |
||
| פרנקפורט | europe-west3 |
||
| לונדון | europe-west2 |
|
|
| הולנד | europe-west4 |
|
|
| ציריך | europe-west6 |
|
|
| אמריקה | |||
| איווה | us-central1 |
|
|
| לאס וגאס | us-west4 |
||
| לוס אנג'לס | us-west2 |
||
| מונטריאול | northamerica-northeast1 |
|
|
| צפון וירג'יניה | us-east4 |
||
| אורגון | us-west1 |
|
|
| סולט לייק סיטי | us-west3 |
||
| סאו פאולו | southamerica-east1 |
|
|
| טורונטו | northamerica-northeast2 |
|
|
| ארה"ב, במספר אזורים | us |
||
לפני שמתחילים
ההרשאות הנדרשות
כדי לקבל את ההרשאות שדרושות לגישה להמלצות לגבי חלוקה למחיצות ואשכולות, צריך לבקש מהאדמין להקצות לכם את תפקיד ה-IAM BigQuery Partitioning Clustering Recommender Viewer (roles/recommender.bigqueryPartitionClusterViewer).
כדי לקרוא הסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
זהו תפקיד שמוגדר מראש וכולל את ההרשאות שנדרשות לגישה להמלצות לגבי מחיצות ואשכולות. כדי לראות בדיוק אילו הרשאות נדרשות, אפשר להרחיב את הקטע ההרשאות הנדרשות:
ההרשאות הנדרשות
כדי לגשת להמלצות לגבי מחיצות ואשכולות, נדרשות ההרשאות הבאות:
-
recommender.bigqueryPartitionClusterRecommendations.get -
recommender.bigqueryPartitionClusterRecommendations.list
יכול להיות שתקבלו את ההרשאות האלה באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש אחרים.
במאמר מבוא ל-IAM יש מידע נוסף על תפקידים והרשאות ב-IAM ב-BigQuery.
לצפייה בהמלצות
בקטע הזה מוסבר איך לראות המלצות ותובנות לגבי מחיצות ואשכולות באמצעות מסוף Google Cloud , Google Cloud CLI או Recommender API.
בוחרים באחת מהאפשרויות הבאות:
המסוף
במסוף Google Cloud , עוברים לדף BigQuery.
בתפריט הניווט, לוחצים על המלצות.
בכרטיסייה 'המלצות' מופיעות כל ההמלצות שזמינות לפרויקט.
בחלונית Optimize BigQuery workload cost (אופטימיזציה של עלות עומס העבודה ב-BigQuery), לוחצים על View all (הצגת הכול).
בטבלת ההמלצות לגבי עלויות מפורטות כל ההמלצות שנוצרו עבור הפרויקט הנוכחי. לדוגמה, בצילום המסך הבא אפשר לראות שהכלי להמלצות ניתח את הטבלה
example_table, ואז המליץ על אשכול של העמודהexample_columnכדי לחסוך כמות משוערת של בייטים ומשבצות.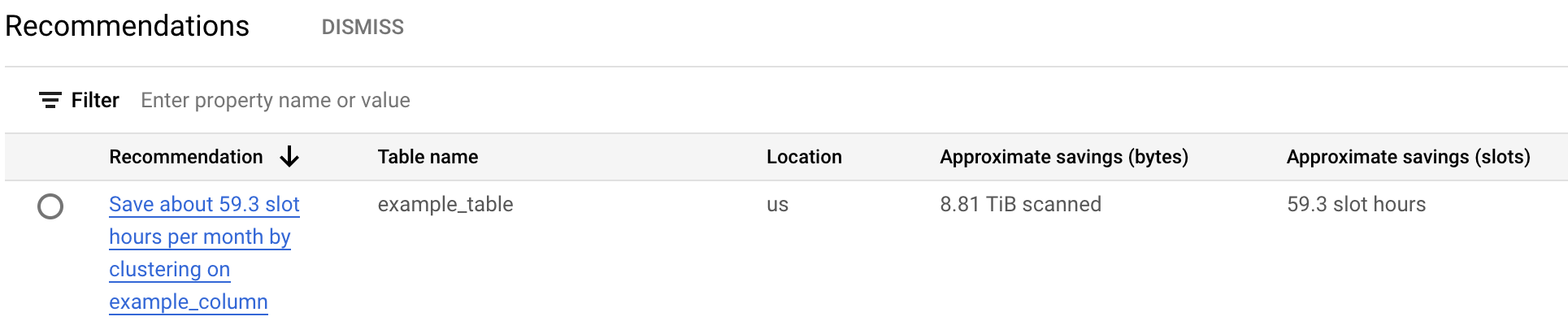
כדי לראות מידע נוסף על התובנה וההמלצה שמופיעות בטבלה, לוחצים על ההמלצה.
gcloud
כדי לראות המלצות לגבי מחיצות או אשכולות בפרויקט ספציפי, משתמשים בפקודה gcloud recommender recommendations list:
gcloud recommender recommendations list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--recommender=google.bigquery.table.PartitionClusterRecommender \
--format=FORMAT_TYPE \
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_NAME: שם הפרויקט שמכיל את הטבלה ב-BigQuery -
REGION_NAME: האזור שבו נמצא הפרויקט -
FORMAT_TYPE: פורמט פלט נתמך של ה-CLI של gcloud – לדוגמה, JSON
| מאפיין (property) | רלוונטי לסוג משנה | תיאור |
|---|---|---|
recommenderSubtype |
מחיצה או אשכול | מציין את סוג ההמלצה. |
content.overview.partitionColumn |
מחיצה | שם העמודה המומלצת לחלוקה למחיצות. |
content.overview.partitionTimeUnit |
מחיצה | יחידת זמן מומלצת לחלוקה למחיצות. לדוגמה, DAY אומר שההמלצה היא להשתמש במחיצות יומיות בעמודה המומלצת. |
content.overview.clusterColumns |
אשכול | שמות מומלצים של עמודות לאשכולות. |
- מידע נוסף על שדות אחרים בתגובה של שירות ההמלצות מופיע במאמר בנושא משאבי REST:
projects.locations.recommendersrecommendation. - מידע נוסף על השימוש ב-Recommender API זמין במאמר שימוש ב-API – המלצות.
כדי להציג תובנות לגבי טבלה באמצעות ה-CLI של gcloud, משתמשים בפקודה gcloud recommender insights list:
gcloud recommender insights list \
--project=PROJECT_NAME \
--location=REGION_NAME \
--insight-type=google.bigquery.table.StatsInsight \
--format=FORMAT_TYPE \
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_NAME: שם הפרויקט שמכיל את הטבלה ב-BigQuery -
REGION_NAME: האזור שבו נמצא הפרויקט -
FORMAT_TYPE: פורמט פלט נתמך של ה-CLI של gcloud – לדוגמה, JSON
| מאפיין (property) | רלוונטי לסוג משנה | תיאור |
|---|---|---|
content.existingPartitionColumn |
אשכול | עמודת חלוקה קיימת, אם יש כזו |
content.tableSizeTb |
הכול | גודל הטבלה בטרה-בייט |
content.bytesReadMonthly |
הכול | מספר הבייטים שנקראו מהטבלה מדי חודש |
content.slotMsConsumedMonthly |
הכול | מספר אלפיות השנייה של משבצות זמן שנצרכו מדי חודש על ידי עומס העבודה שפועל בטבלה |
content.queryJobsCountMonthly |
הכול | מספר העבודות שמופעלות בטבלה מדי חודש |
- מידע נוסף על שדות אחרים בתגובה של התובנות זמין במאמר בנושא משאבי REST:
projects.locations.insightTypes.insights. - מידע נוסף על השימוש בתובנות זמין במאמר שימוש ב-API – תובנות.
API בארכיטקטורת REST
כדי לראות המלצות לגבי מחיצות או אשכולות בפרויקט ספציפי, צריך להשתמש ב-API בארכיטקטורת REST. לכל פקודה צריך לספק אסימון אימות, שאפשר לקבל באמצעות ה-CLI של gcloud. מידע נוסף על קבלת אסימון אימות זמין במאמר שיטות לקבלת אסימון מזהה.
אפשר להשתמש בבקשת curl list כדי לראות את כל ההמלצות לפרויקט ספציפי:
curl
-H "Authorization: Bearer $GCLOUD_AUTH_TOKEN"
-H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/recommenders/google.bigquery.table.PartitionClusterRecommender/recommendations
מחליפים את מה שכתוב בשדות הבאים:
-
GCLOUD_AUTH_TOKEN: השם של אסימון גישה תקין ל-CLI של gcloud -
PROJECT_NAME: שם הפרויקט שמכיל את הטבלה ב-BigQuery
| מאפיין (property) | רלוונטי לסוג משנה | תיאור |
|---|---|---|
recommenderSubtype |
מחיצה או אשכול | מציין את סוג ההמלצה. |
content.overview.partitionColumn |
מחיצה | שם העמודה המומלצת לחלוקה למחיצות. |
content.overview.partitionTimeUnit |
מחיצה | יחידת זמן מומלצת לחלוקה למחיצות. לדוגמה, DAY אומר שההמלצה היא להשתמש במחיצות יומיות בעמודה המומלצת. |
content.overview.clusterColumns |
אשכול | שמות מומלצים של עמודות לאשכולות. |
- מידע נוסף על שדות אחרים בתגובה של שירות ההמלצות מופיע במאמר בנושא משאבי REST:
projects.locations.recommendersrecommendation. - מידע נוסף על השימוש ב-Recommender API זמין במאמר שימוש ב-API – המלצות.
כדי להציג תובנות לגבי טבלה באמצעות API בארכיטקטורת REST, מריצים את הפקודה הבאה:
curl -H "Authorization: Bearer $GCLOUD_AUTH_TOKEN" -H "x-goog-user-project: PROJECT_NAME" https://recommender.googleapis.com/v1/projects/my-project/locations/us/insightTypes/google.bigquery.table.StatsInsight/insights
מחליפים את מה שכתוב בשדות הבאים:
-
GCLOUD_AUTH_TOKEN: השם של אסימון גישה תקין ל-CLI של gcloud -
PROJECT_NAME: שם הפרויקט שמכיל את הטבלה ב-BigQuery
| מאפיין (property) | רלוונטי לסוג משנה | תיאור |
|---|---|---|
content.existingPartitionColumn |
אשכול | עמודת חלוקה קיימת, אם יש כזו |
content.tableSizeTb |
הכול | גודל הטבלה בטרה-בייט |
content.bytesReadMonthly |
הכול | מספר הבייטים שנקראו מהטבלה מדי חודש |
content.slotMsConsumedMonthly |
הכול | מספר אלפיות השנייה של משבצות זמן שנצרכו מדי חודש על ידי עומס העבודה שפועל בטבלה |
content.queryJobsCountMonthly |
הכול | מספר העבודות שמופעלות בטבלה מדי חודש |
- מידע נוסף על שדות אחרים בתגובה של התובנות זמין במאמר בנושא משאבי REST:
projects.locations.insightTypes.insights. - מידע נוסף על השימוש בתובנות זמין במאמר שימוש ב-API – תובנות.
צפייה בהמלצות עם INFORMATION_SCHEMA
אפשר גם לראות את ההמלצות והתובנות באמצעות INFORMATION_SCHEMAתצוגות. לדוגמה, אפשר להשתמש בתצוגה INFORMATION_SCHEMA.RECOMMENDATIONS כדי לראות את שלוש ההמלצות המובילות על סמך החיסכון בחריצים, כמו בדוגמה הבאה:
SELECT
recommender,
target_resources,
LAX_INT64(additional_details.overview.bytesSavedMonthly) / POW(1024, 3) as est_gb_saved_monthly,
LAX_INT64(additional_details.overview.slotMsSavedMonthly) / (1000 * 3600) as slot_hours_saved_monthly,
last_updated_time
FROM
`region-us`.INFORMATION_SCHEMA.RECOMMENDATIONS
WHERE
primary_impact.category = 'COST'
AND
state = 'ACTIVE'
ORDER by
slot_hours_saved_monthly DESC
LIMIT 3;
INFORMATION_SCHEMA
התוצאה אמורה להיראות כך:
+---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | recommender | target_resources | est_gb_saved_monthly | slot_hours_saved_monthly | last_updated_time +---------------------------------------------------+--------------------------------------------------------------------------------------------------+ | google.bigquery.materializedview.Recommender | ["project_resource"] | 140805.38289248943 | 9613.139166666666 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_1"] | 4393.7416711859405 | 56.61476777777777 | 2024-07-01 13:00:00 | google.bigquery.table.PartitionClusterRecommender | ["table_resource_2"] | 3934.07264107652 | 10.499466666666667 | 2024-07-01 13:00:00 +---------------------------------------------------+--------------------------------------------------------------------------------------------------+
מידע נוסף זמין במקורות המידע הבאים:
INFORMATION_SCHEMA.RECOMMENDATIONSצפייהINFORMATION_SCHEMA.RECOMMENDATIONS_BY_ORGANIZATIONצפייהINFORMATION_SCHEMA.INSIGHTSצפייה
החלת המלצות לגבי אשכולות
כדי ליישם המלצות לגבי אשכולות, מבצעים אחת מהפעולות הבאות:
החלת אשכולות ישירות על הטבלה המקורית
אפשר להחיל המלצות לגבי אשכולות ישירות על טבלה קיימת ב-BigQuery. השיטה הזו מהירה יותר מהחלת המלצות על טבלה שהועתקה, אבל היא לא שומרת טבלת גיבוי.
כדי להחיל הגדרת אשכול חדשה על טבלאות לא מחולקות או מחולקות למחיצות, פועלים לפי השלבים הבאים.
בכלי bq, מעדכנים את הגדרת האשכולות של הטבלה כך שתתאים לאשכולות החדשים:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
מחליפים את מה שכתוב בשדות הבאים:
-
CLUSTER_COLUMN: העמודה שלפיה מתבצעת ההצבה באשכולות – לדוגמה,mycolumn -
DATASET: השם של מערך הנתונים שמכיל את הטבלה, למשלmydataset -
ORIGINAL_TABLE: השם של הטבלה המקורית, למשלmytable
אפשר גם לקרוא לשיטת ה-API
tables.updateאוtables.patchכדי לשנות את מפרט האשכולות.-
כדי לאגד את כל השורות לפי הגדרת האשכול החדשה, מריצים את ההצהרה הבאה
UPDATE:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
החלת אשכולות על טבלה שהועתקה
כשמחילים המלצות לגבי אשכול על טבלה ב-BigQuery, אפשר קודם להעתיק את הטבלה המקורית ואז להחיל את ההמלצה על הטבלה שהועתקה. השיטה הזו מבטיחה שהנתונים המקוריים יישמרו אם תצטרכו לבטל את השינוי בהגדרת האשכול.
אפשר להשתמש בשיטה הזו כדי להחיל המלצות לגבי אשכולות על טבלאות עם מחיצות ועל טבלאות ללא מחיצות.
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, יוצרים טבלה ריקה עם אותם מטא-נתונים (כולל מפרטי האשכולות) של הטבלה המקורית באמצעות האופרטור
LIKE:CREATE TABLE DATASET.COPIED_TABLE LIKE DATASET.ORIGINAL_TABLE
מחליפים את מה שכתוב בשדות הבאים:
-
DATASET: השם של מערך הנתונים שמכיל את הטבלה, למשלmydataset -
COPIED_TABLE: שם לטבלה שהועתקה, למשלcopy_mytable -
ORIGINAL_TABLE: השם של הטבלה המקורית, למשלmytable
-
במסוף Google Cloud , פותחים את Cloud Shell Editor.
ב-Cloud Shell Editor, מעדכנים את הגדרת האשכולות של הטבלה שהועתקה כך שתתאים להגדרת האשכולות המומלצת באמצעות הפקודה
bq update:bq update --clustering_fields=CLUSTER_COLUMN DATASET.COPIED_TABLE
מחליפים את
CLUSTER_COLUMNבעמודה שעליה רוצים ליצור אשכולות – לדוגמה,mycolumn.אפשר גם לקרוא לשיטת ה-API
tables.updateאוtables.patchכדי לשנות את מפרט האשכולות.בעורך השאילתות, מאחזרים את סכימת הטבלה עם הגדרות החלוקה למחיצות והאשכולות של הטבלה המקורית, אם קיימות חלוקה למחיצות או אשכולות. אפשר לאחזר את הסכימה על ידי הצגת התצוגה
INFORMATION_SCHEMA.TABLESשל הטבלה המקורית:SELECT ddl FROM DATASET.INFORMATION_SCHEMA.TABLES WHERE table_name = 'ORIGINAL_TABLE'
הפלט הוא הצהרת שפת הגדרת הנתונים (DDL) המלאה של ORIGINAL_TABLE, כולל סעיף
PARTITION BY. מידע נוסף על הארגומנטים בפלט של DDL זמין במאמר בנושא הצהרתCREATE TABLE.פלט ה-DDL מציין את סוג החלוקה למחיצות בטבלה המקורית:
סוג החלוקה למחיצות פלט לדוגמה לא חולקו למחיצות הסעיף PARTITION BYחסר.חלוקה למחיצות לפי עמודה בטבלה PARTITION BY c0PARTITION BY DATE(c0)PARTITION BY DATETIME_TRUNC(c0, MONTH)חלוקה למחיצות לפי זמני כתיבת הנתונים PARTITION BY _PARTITIONDATEPARTITION BY DATETIME_TRUNC(_PARTITIONTIME, MONTH)מבצעים המרה של נתונים לפורמט שמתאים לטבלה שהועתקה. התהליך שבו משתמשים מבוסס על סוג המחיצה.
- אם הטבלה המקורית לא מחולקת למחיצות או שהיא מחולקת למחיצות לפי עמודה בטבלה, צריך להטמיע את הנתונים מהטבלה המקורית בטבלה המועתקת:
INSERT INTO DATASET.COPIED_TABLE SELECT * FROM DATASET.ORIGINAL_TABLE
אם הטבלה המקורית מחולקת למחיצות לפי זמני כתיבת הנתונים, פועלים לפי השלבים הבאים:
כדי לאחזר את רשימת העמודות ליצירת הביטוי להעברת הנתונים, משתמשים בתצוגה
INFORMATION_SCHEMA.COLUMNS:SELECT ARRAY_TO_STRING(( SELECT ARRAY( SELECT column_name FROM DATASET.INFORMATION_SCHEMA.COLUMNS WHERE table_name = 'ORIGINAL_TABLE')), ", ")
הפלט הוא רשימה של שמות עמודות, שמופרדים באמצעות פסיקים.
מייבאים את הנתונים מהטבלה המקורית לטבלה שהועתקה:
INSERT DATASET.COPIED_TABLE (COLUMN_NAMES, _PARTITIONTIME) SELECT *, _PARTITIONTIME FROM DATASET.ORIGINAL_TABLE
מחליפים את
COLUMN_NAMESברשימת העמודות שהתקבלה כפלט בשלב הקודם, מופרדות בפסיקים – לדוגמה,col1, col2, col3.
עכשיו יש לכם טבלה משוכפלת עם נתונים זהים לטבלה המקורית. בשלבים הבאים, מחליפים את הטבלה המקורית בטבלה מסודרת באשכולות חדשה.
- אם הטבלה המקורית לא מחולקת למחיצות או שהיא מחולקת למחיצות לפי עמודה בטבלה, צריך להטמיע את הנתונים מהטבלה המקורית בטבלה המועתקת:
משנים את השם של הטבלה המקורית לטבלת גיבוי:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO BACKUP_TABLE
מחליפים את
BACKUP_TABLEבשם של טבלת הגיבוי – לדוגמה,backup_mytable.משנים את השם של הטבלה שהועתקה לשם של הטבלה המקורית:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO ORIGINAL_TABLE
הטבלה המקורית מקובצת עכשיו בהתאם להמלצה לקבוצת מיקוד.
- גישה והרשאות, כמו הרשאות IAM, גישה ברמת השורה או גישה ברמת העמודה.
- ארטיפקטים של טבלה, כמו שיבוטים של טבלה, תמונות מצב של טבלה או אינדקסים של חיפוש.
- הסטטוס של כל התהליכים שמתבצעים בטבלה, כמו תצוגות חומריות או עבודות שהופעלו כשביצעתם את ההעתקה של הטבלה.
- היכולת לגשת לנתונים היסטוריים בטבלה באמצעות time travel.
- כל מטא-נתונים שמשויכים לטבלה המקורית – לדוגמה,
table_option_listאוcolumn_option_list. מידע נוסף זמין במאמר הצהרות בשפת הגדרת נתונים.
אם מתעוררות בעיות, צריך להעביר ידנית את הארטיפקטים המושפעים לטבלה החדשה.
אחרי שבודקים את הטבלה המקובצת, אפשר למחוק את טבלת הגיבוי באמצעות הפקודה הבאה:DROP TABLE DATASET.BACKUP_TABLE
שימוש באשכולות בתצוגה מהותית
אפשר ליצור תצוגה חומרית של הטבלה כדי לאחסן נתונים מהטבלה המקורית עם ההמלצה שהוחלה. שימוש בתצוגות חומריות ליישום המלצות מבטיח שהנתונים המקובצים יישארו עדכניים באמצעות רענונים אוטומטיים. יש שיקולים שקשורים לתמחור כשמריצים שאילתות על תצוגות חומריות, מתחזקים אותן ומאחסנים אותן. במאמר תצוגות מהותיות מקובצות מוסבר איך ליצור תצוגה מהותית מקובצת.יישום המלצות לגבי מחיצות
כדי ליישם המלצות לחלוקה למחיצות, צריך ליישם אותן על עותק של הטבלה המקורית. ב-BigQuery אי אפשר לשנות את סכימת החלוקה של טבלה במקום, למשל לשנות טבלה לא מחולקת לטבלה מחולקת, לשנות את סכימת החלוקה של טבלה או ליצור תצוגה חומרית עם סכימת חלוקה שונה מזו של טבלת הבסיס. אפשר לשנות את החלוקה למחיצות של טבלה רק בעותק של הטבלה.
החלת המלצות לגבי חלוקה למחיצות על טבלה שהועתקה
כשמחילים המלצות על חלוקה למחיצות בטבלה ב-BigQuery, צריך קודם להעתיק את הטבלה המקורית ואז להחיל את ההמלצה על הטבלה שהועתקה. הגישה הזו תאפשר לכם לשמור את הנתונים המקוריים אם תצטרכו לבטל את השינויים במחיצה.
בפרוצדורה הבאה נעשה שימוש בהמלצה לדוגמה כדי לחלק טבלה לפי יחידת הזמן של החלוקה DAY.
כדי ליצור טבלה שהיא העתק של הטבלה המקורית באמצעות ההמלצות לחלוקה למחיצות:
CREATE TABLE DATASET.COPIED_TABLE PARTITION BY DATE_TRUNC(PARTITION_COLUMN, DAY) AS SELECT * FROM DATASET.ORIGINAL_TABLE
מחליפים את מה שכתוב בשדות הבאים:
-
DATASET: השם של מערך הנתונים שמכיל את הטבלה, למשלmydataset -
COPIED_TABLE: שם לטבלה שהועתקה, למשלcopy_mytable -
PARTITION_COLUMN: העמודה שלפיה מבצעים את החלוקה למחיצות. לדוגמה,mycolumn
מידע נוסף על יצירת טבלאות עם חלוקה למחיצות זמין במאמר יצירת טבלאות עם חלוקה למחיצות.
-
משנים את השם של הטבלה המקורית לטבלת גיבוי:
ALTER TABLE DATASET.ORIGINAL_TABLE RENAME TO BACKUP_TABLE
מחליפים את
BACKUP_TABLEבשם של טבלת הגיבוי – לדוגמה,backup_mytable.משנים את השם של הטבלה שהועתקה לשם של הטבלה המקורית:
ALTER TABLE DATASET.COPIED_TABLE RENAME TO ORIGINAL_TABLE
הטבלה המקורית מחולקת עכשיו למחיצות בהתאם להמלצה לגבי המחיצות.
- גישה והרשאות, כמו הרשאות IAM, גישה ברמת השורה או גישה ברמת העמודה.
- ארטיפקטים של טבלה, כמו שיבוטים של טבלה, תמונות מצב של טבלה או אינדקסים של חיפוש.
- הסטטוס של כל התהליכים שמתבצעים בטבלה, כמו תצוגות חומריות או עבודות שהופעלו כשביצעתם את ההעתקה של הטבלה.
- היכולת לגשת לנתונים היסטוריים בטבלה באמצעות time travel.
- כל מטא-נתונים שמשויכים לטבלה המקורית – לדוגמה,
table_option_listאוcolumn_option_list. מידע נוסף זמין במאמר הצהרות בשפת הגדרת נתונים. - אפשר להשתמש ב-SQL מדור קודם כדי לכתוב תוצאות של שאילתות בטבלאות עם חלוקה למחיצות. אין תמיכה מלאה בשימוש ב-SQL מדור קודם בטבלאות עם חלוקה למחיצות. אחד הפתרונות הוא להעביר את תהליכי העבודה שלכם ב-SQL מדור קודם אל GoogleSQL לפני שמחילים המלצה על חלוקה למחיצות.
אם מתעוררות בעיות, צריך להעביר ידנית את הארטיפקטים המושפעים לטבלה החדשה.
אחרי שבודקים את הטבלה המפוצלת, אפשר למחוק את טבלת הגיבוי באמצעות הפקודה הבאה:DROP TABLE DATASET.BACKUP_TABLE
הערכת יתר של החיסכון
במקרים מסוימים, יכול להיות שההמלצות של הכלי ליצירת אשכולות ב-BigQuery יציגו חיסכון משוער שנראה גדול באופן לא פרופורציונלי – למשל, גדול יותר מהמספר הכולל של בייטים שחויבו בחודש עבור הטבלה הספציפית הזו. הבעיה הזו בדרך כלל נגרמת בגלל תבנית שנקראת סיכום של שאילתת משנה.
מה גורם להערכת יתר כזו
הערכת היתר נפוצה בעיקר בעומסי עבודה שכוללים שאילתות מורכבות של GoogleSQL שמפנות לאותה טבלה כמה פעמים. דוגמאות:
- שאילתות עם הרבה הצטרפויות עצמיות בטבלה גדולה אחת.
- שאילתות עם כמה ביטויי טבלה נפוצים או שאילתות משנה שכולן סורקות את אותה טבלת בסיס.
למה הערכת יתר מתרחשת
תוכניות ההפעלה של BigQuery מחלקות לעיתים קרובות שאילתות מורכבות לשלבים נפרדים. כלי ההמלצות לאשכולות מחשב ומסכם את החיסכון הפוטנציאלי לכל שלב בנפרד.
אם עבודה אחת מורכבת משלבים רבים שכל אחד מהם קורא מאותה טבלה, יכול להיות שהמערכת להמלצות תספור את החיסכון הפוטנציאלי בכל שלב בעבודה הזו, במקום לבטל את הכפילויות של החיסכון ברמת העבודה. הדבר עלול להוביל להמלצות מוגזמות לגבי טבלאות עם דפוסי שאילתות מורכבים.
איך בודקים אם עומס העבודה מושפע
אם יש לכם המלצה ספציפית לגבי אשכול שאתם רוצים לאמת, אתם יכולים להריץ את השאילתה הבאה במסוף Google Cloud כדי לזהות משימות שאולי גורמות להערכת יתר כזו.
השאילתה הזו מחפשת בהיסטוריית העבודות מקרים שבהם עבודה יחידה סורקת את אותה טבלה ביותר מ-10 שלבי ביצוע שונים.
SELECT job_id, project_id, user_email, table_name, scan_count, total_billed_gb, creation_time FROM ( SELECT job_id, project_id, user_email, creation_time, total_bytes_billed / (1024*1024*1024) as total_billed_gb, -- Extract the table name from the 'READ' substeps REGEXP_EXTRACT(substep, r'FROM ([^ ]+)') as table_name, COUNT(DISTINCT stage.id) as scan_count FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(job_stages) as stage, UNNEST(stage.steps) as step, UNNEST(step.substeps) as substep WHERE creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 14 DAY) AND step.kind = 'READ' AND substep LIKE 'FROM %' -- Exclude internal intermediate stages AND NOT REGEXP_CONTAINS(substep, r'FROM __stage') GROUP BY 1, 2, 3, 4, 5, 6 ) WHERE scan_count > 10 -- Adjust this threshold to find more complex query patterns ORDER BY scan_count DESC LIMIT 100;
מחליפים את REGION_NAME באזור שבו נמצא הפרויקט.
אם אתם רואים בטבלה המלצות עם ציון גבוה scan_count (למשל, מעל 20), סביר להניח שהחיסכון המשוער עבור הטבלה הזו מוגזם. יכול להיות שעדיין תהיה תועלת בביצועים מהקיבוץ, אבל החיסכון בפועל לא יגיע לרמה שמוצגת בהמלצה.
תמחור
כשמחילים המלצה על טבלה, יכולות להיות עלויות מהסוגים הבאים:
- עלויות עיבוד. כשמחילים המלצה, מריצים שאילתת שפת הגדרת נתונים (DDL) או שפת טיפול בנתונים (DML) בפרויקט BigQuery.
- עלויות אחסון. אם משתמשים בשיטה של העתקת טבלה, נדרש נפח אחסון נוסף לטבלה המועתקת (או לגיבוי).
החיובים הרגילים על עיבוד ואחסון חלים בהתאם לחשבון לחיוב שמקושר לפרויקט. מידע נוסף זמין במאמר תמחור ב-BigQuery.
פתרון בעיות
בעיה: לא מופיעות המלצות לטבלה מסוימת.
יכול להיות שהמלצות על חלוקה למחיצות לא יופיעו לגבי טבלאות שעומדות בקריטריונים הבאים:
- הטבלה קטנה מ-100GB.
- הטבלה כבר מחולקת למחיצות או מקובצת לאשכולות.
יכול להיות שהמלצות לגבי אשכולות לא יופיעו לגבי טבלאות שעומדות בקריטריונים הבאים:
- הטבלה קטנה מ-10GB.
- הטבלה כבר מסודרת באשכולות.
יכול להיות שההמלצות לגבי מחיצות וקלאסטרים לא יוצגו במקרים הבאים:
- הטבלה כוללת עלות כתיבה גבוהה מפעולות של שפת טיפול בנתונים (DML).
- הטבלה לא נקראה ב-30 הימים האחרונים.
- החיסכון החודשי המשוער נמוך מדי (פחות משעת שימוש אחת בחריץ).
בעיה: החיסכון המשוער גדול באופן לא פרופורציונלי.
יכול להיות שהחיסכון החודשי המשוער יהיה גבוה מדי אם עומס העבודה כולל שאילתות מורכבות שמפנות לאותה טבלה כמה פעמים בשלבים שונים של ביצוע. מידע נוסף מופיע בקטע הערכת יתר של החיסכון.