
Ottimizzare i costi delle funzioni AI
Questo documento descrive come utilizzare la modalità ottimizzata per le funzioni AI gestite in BigQuery. Questa modalità consente di elaborare set di dati su larga scala contenenti migliaia o addirittura miliardi di righe con un consumo di token del modello linguistico di grandi dimensioni (LLM) e una latenza delle query notevolmente ridotti rispetto all'inferenza LLM standard per riga.
L'esempio seguente mostra come utilizzare la funzione AI.IF
con la modalità ottimizzata per identificare gli articoli di notizie sui disastri naturali, utilizzando text-embedding-005
come modello di embedding:
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
L'argomento optimization_mode => 'MINIMIZE_COST' abilita la modalità ottimizzata. Questa è l'impostazione predefinita quando vengono forniti gli embedding, quindi puoi omettere questo argomento.
In questo esempio, gli embedding vengono generati al volo. In pratica, ti consigliamo di materializzare gli embedding in modo che possano essere riutilizzati.
Come funziona la modalità ottimizzata
Le funzioni AI gestite, AI.IF e AI.CLASSIFY, in genere chiamano un
LLM remoto per ogni riga del set di dati. Quando utilizzi la modalità ottimizzata, BigQuery addestra automaticamente un modello leggero e distillato durante l'esecuzione della query.
La procedura funziona nel seguente modo:
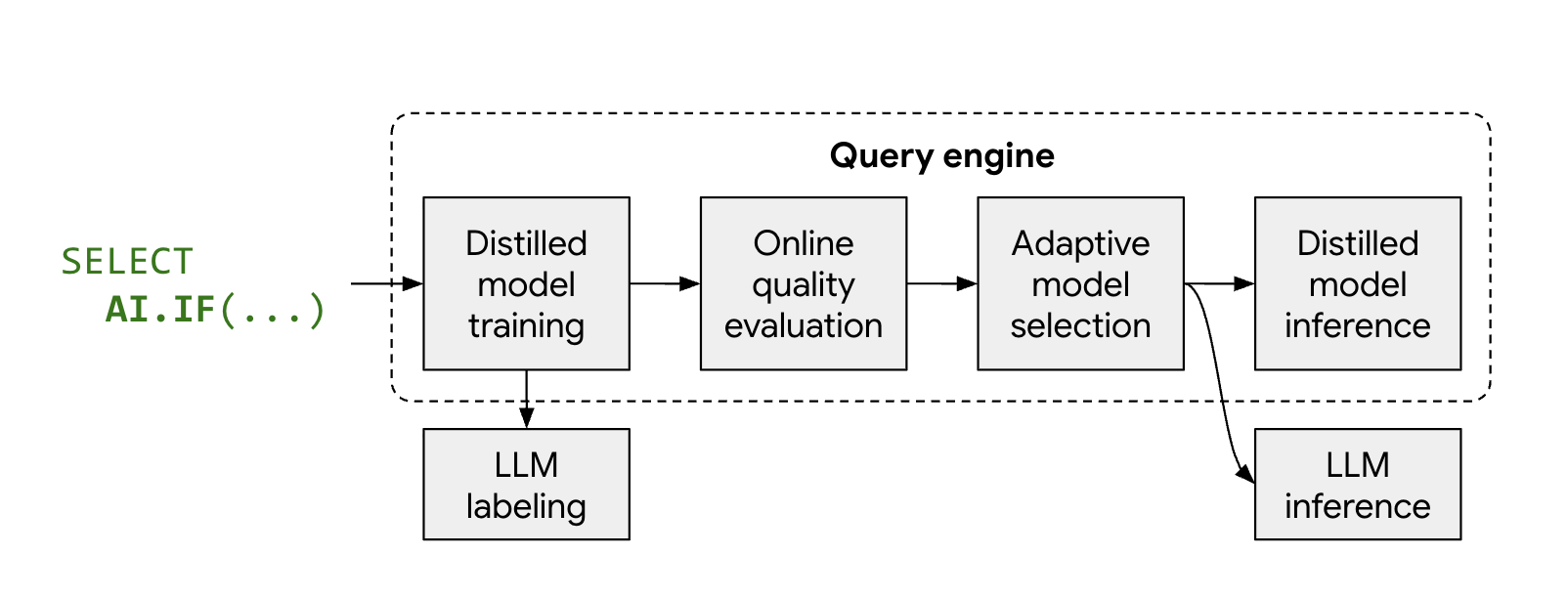
- Campionamento ed etichettatura: BigQuery seleziona un piccolo campione rappresentativo dei tuoi dati e chiama Gemini per fornire le etichette.
- Addestramento del modello distillato: un modello distillato locale viene addestrato just-in-time utilizzando le etichette LLM e gli embedding dei dati come funzionalità.
- Controllo qualità: BigQuery valuta la precisione del modello distillato rispetto ai risultati dell'LLM. Per impostazione predefinita, se il modello distillato non soddisfa la soglia di qualità richiesta, la query non riesce e viene visualizzato un errore che spiega perché il modello è stato scartato. Se il modello è di qualità accettabile, BigQuery potrebbe comunque eseguire il fallback all'LLM remoto per righe specifiche per mantenere una qualità coerente o per le righe prive di embedding validi.
- Inferenza: il modello distillato elabora la maggior parte delle righe, riducendo significativamente il numero di chiamate Gemini.
Limitazioni
La modalità ottimizzata presenta le seguenti limitazioni:
- Numero minimo di righe: l'input della funzione AI deve contenere circa 3000 righe per garantire dati sufficienti per l'addestramento del modello.
- Tipi di dati: per i prompt che fanno riferimento a più colonne, per l'ottimizzazione sono supportate solo le colonne di stringhe.
- Classificazione multi-etichetta:
AI.CLASSIFYconoutput_mode => 'multi'non è supportato in modalità ottimizzata. - Supporto delle funzioni: solo le funzioni
AI.IFeAI.CLASSIFYsupportano la modalità ottimizzata; tuttavia, quando utilizzi la modalità ottimizzata conAI.CLASSIFY, le query possono non riuscire se la qualità del modello distillato è insufficiente. - Rapporto di errore: l'argomento
max_error_rationon è supportato in modalità ottimizzata.
Prima di iniziare
Per ottenere le autorizzazioni necessarie per eseguire le funzioni AI gestite in BigQuery, consulta Impostare le autorizzazioni per le funzioni AI generative che chiamano gli LLM della piattaforma Gemini Enterprise Agent.
Scegliere un modello di embedding
Per utilizzare la modalità ottimizzata, devi calcolare gli embedding per i tuoi dati e fornirli alla funzione AI. Affinché le colonne di input abbiano embedding associati, tutte le righe devono avere dimensioni di embedding coerenti ed essere generate dallo stesso modello di embedding.
Per ottenere la migliore qualità-costo e scalabilità, ti consigliamo di calcolare gli embedding per
i tuoi dati utilizzando un modello di embedding, ad esempio
text-embedding-005 o gli embedding Gemini
per attività in inglese o multilingue. Per i dati multimodali (testo e immagini), utilizza un
modello di embedding multimodale come
multimodalembedding@001.
Genera embedding
Puoi calcolare gli embedding per i tuoi dati utilizzando la generazione autonoma gestita da BigQuery o creando manualmente le colonne di embedding.
Le sezioni seguenti descrivono come utilizzare entrambi gli approcci con le funzioni AI.CLASSIFY e AI.IF.
Generazione autonoma di embedding
Se utilizzi la generazione autonoma di embedding,
BigQuery utilizza automaticamente gli embedding quando vengono chiamate AI.IF o
AI.CLASSIFY. Questo è l'approccio consigliato, ma è limitato a una colonna di embedding per tabella.
L'esempio seguente crea una tabella con una colonna di embedding generata autonomamente, utilizzando text-embedding-005 come modello di embedding, quindi utilizza la funzione AI.CLASSIFY per classificare i dati:
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
Specifica manuale della colonna
Se hai una colonna di embedding esistente, specificala nell'argomento embeddings di AI.IF o AI.CLASSIFY. Puoi generarla utilizzando la
AI.EMBED funzione.
L'esempio seguente mostra come creare una tabella con una colonna di embedding, utilizzando text-embedding-005 come modello di embedding, e quindi utilizzare questa colonna in una query AI.CLASSIFY:
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
Se il prompt fa riferimento a più colonne, fornisci un elenco di nomi di colonne e i relativi embedding nell'argomento embeddings. Ad esempio:
embeddings => [('body', body_embedding), ('title', title_embedding)].
Monitorare l'ottimizzazione delle query
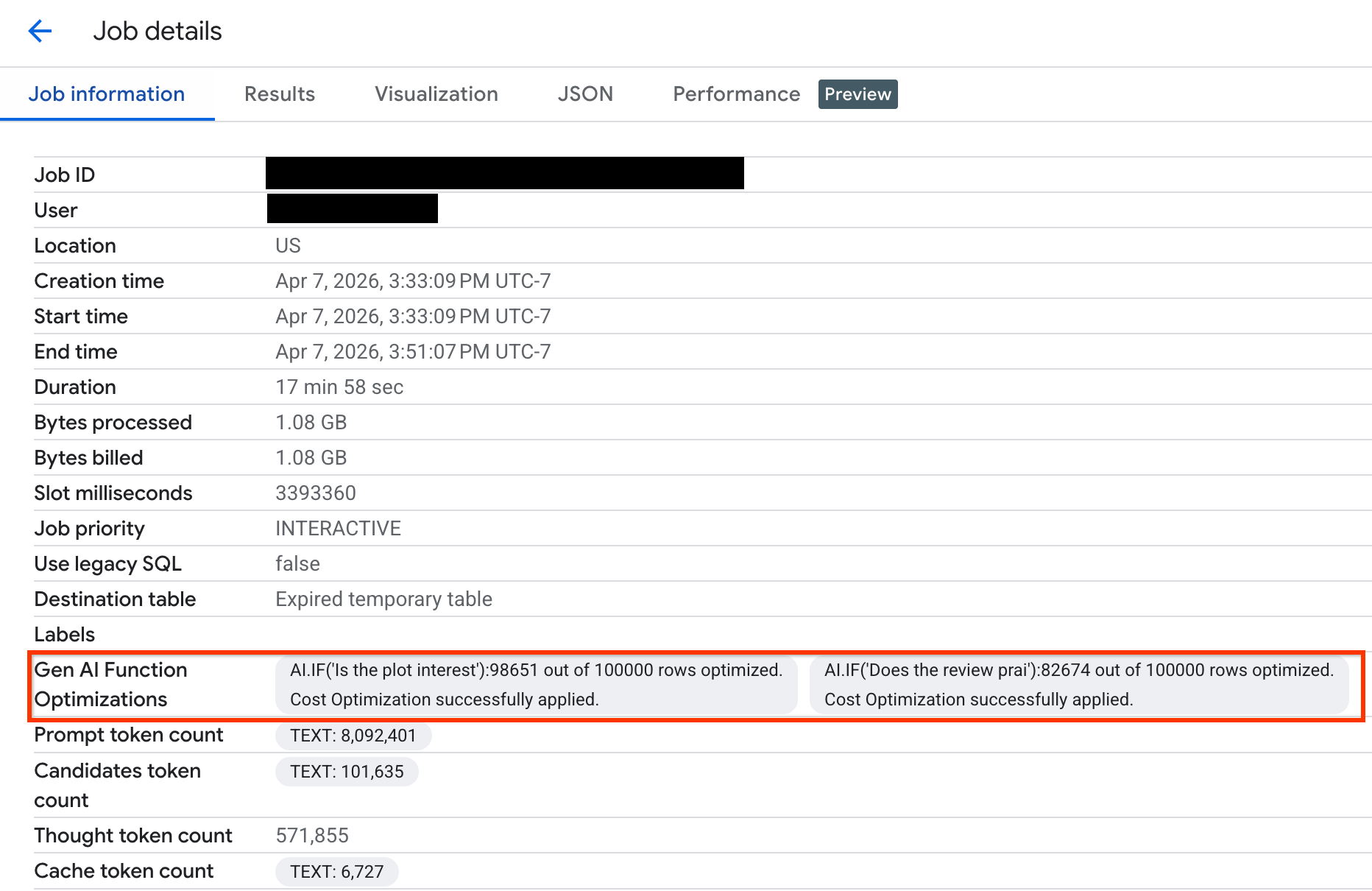
Per verificare quante righe sono state ottimizzate durante l'esecuzione della query, puoi visualizzare le statistiche di esecuzione nella Google Cloud consolao tramite l'API:
Console
Per visualizzare il numero di righe ottimizzate e i messaggi di sistema sullo stato dell'ottimizzazione:
Nella Google Cloud console, vai alla pagina BigQuery.
Nel menu di navigazione, fai clic su Esplora job.
Fai clic sull'ID job per visualizzare il riquadro Dettagli job.
Fai clic sulla scheda Informazioni job e visualizza le metriche e lo stato nel campo Ottimizzazioni delle funzioni AI generative.
API
Controlla FunctionGenAiCostOptimizationStats nell'oggetto GenAIFunctionStats dei metadati del job. Questo oggetto include il numero di righe dedotte tramite il flusso di lavoro ottimizzato e i messaggi generati dal sistema che forniscono informazioni sullo stato di ottimizzazione.
Risoluzione dei problemi
Le sezioni seguenti spiegano come diagnosticare e risolvere i problemi comuni relativi all'utilizzo della modalità ottimizzata.
Le dimensioni dei dati sono troppo piccole
Problema: dati insufficienti per l'addestramento del modello. Potresti visualizzare il seguente
messaggio di errore: Fail to apply cost optimization because the data size is too
small.
Soluzione: aumenta le dimensioni dell'input a circa 3000 righe e verifica che gli embedding validi siano stati generati correttamente per tutte le righe.
Pochi o nessun campione in alcune classi
Problema: numero insufficiente di campioni per determinate categorie durante la
fase di campionamento, che impedisce l'addestramento del modello. Potresti visualizzare il seguente
messaggio di errore: Fail to apply cost optimization because some classes have
few or no samples.
Soluzione:
- Rimuovi le categorie rare o vuote dalla chiamata di funzione
AI.CLASSIFY. - Raggruppa le categorie rare in una più ampia per aumentare le dimensioni del campione. Puoi utilizzare una categoria
OTHERper raggruppare gli elementi non coperti da categorie più specifiche. Tuttavia, non aggiungereOTHERse l'elenco delle categorie è già completo, in quanto questo termine è ambiguo e potrebbe causare confusione.
Le dimensioni degli embedding non sono coerenti
Problema: incoerenze tra le dimensioni degli embedding tra le righe. Potresti visualizzare il seguente messaggio di errore: Fail to apply cost optimization
because the embeddings have inconsistent dimensions.
Soluzione: verifica che gli embedding siano generati dallo stesso modello e abbiano la stessa lunghezza del vettore di embedding. Puoi utilizzare una query SQL simile alla seguente per verificare che gli embedding in una colonna abbiano la stessa lunghezza:
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
La complessità del prompt è troppo elevata
Problema: il modello distillato non può raggiungere una soglia di precisione elevata. Potresti visualizzare il seguente messaggio di errore: Fail to apply cost optimization
because the prompt complexity is too high.
Soluzione:
Utilizza un insieme di categorie che formano una partizione. Assicurati che le categorie abbiano una sovrapposizione minima e coprano tutti gli input possibili.
- Evita le categorie sovrapposte in cui un input potrebbe appartenere a più categorie contemporaneamente. Ad esempio, evita categorie come
['terrible', 'bad', 'okay', 'good', 'excellent']. - Evita i gap in cui non si applicano categorie. Ad esempio, l'elenco di
categorie
['bad', 'average']non copre una recensione che esprime elogi. Fornisci descrizioni delle categorie per guidare l'LLM a risolvere l'ambiguità tra le categorie. Ad esempio:
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- Evita le categorie sovrapposte in cui un input potrebbe appartenere a più categorie contemporaneamente. Ad esempio, evita categorie come
Prova modelli di embedding più avanzati come
text-embedding-005omultimodalembedding.Contatta bqml-feedback@google.com per ulteriore assistenza per il debug.
Numero imprevisto di righe elaborate dall'LLM
Problema: le statistiche di esecuzione delle query mostrano che un numero di righe inaspettatamente elevato è stato elaborato dall'LLM remoto anziché dal modello distillato. Questo potrebbe essere dovuto ai seguenti motivi:
- Il modello distillato è stato addestrato correttamente, ma alcune righe non avevano embedding. Queste righe vengono elaborate dall'LLM remoto.
- Non è stato possibile applicare il modello distillato a ogni riga ed è stato necessario eseguire il fallback all'LLM remoto per mantenere una qualità coerente.
Soluzione: verifica che gli embedding siano generati correttamente e siano validi per tutte le righe dei dati. Se il problema persiste, contatta bqml-feedback@google.com per il debug.
Colonna di embedding autonoma non rilevata
Problema: BigQuery non riesce a rilevare una colonna di embedding autonoma. Questo potrebbe verificarsi se lo script utilizza una tabella temporanea e il riferimento alla tabella originale viene perso.
Soluzione: utilizza il parametro embeddings per passare esplicitamente una colonna di embedding autonoma, ad esempio embeddings => content_embedding.result, che attiva l'ottimizzazione dei costi.
Passaggi successivi
- Scopri di più sull'AI generativa in BigQuery.
- Consulta la
AI.IFfunzione documentazione. - Consulta la documentazione della funzione
AI.CLASSIFY.