
Optimiza los costos de las funciones IA con la destilación de modelos
En este documento, se describe cómo usar el modo optimizado para las funciones de IA administradas en BigQuery. Puedes usar el modo optimizado para procesar conjuntos de datos a gran escala que contengan miles o incluso miles de millones de filas con un consumo de tokens del modelo de lenguaje grande (LLM) y una latencia de consulta significativamente reducidos en comparación con la inferencia de LLM estándar por fila. Esta optimización solo se aplica a las funciones AI.IF y AI.CLASSIFY.
Para comprender mejor tu consumo de tokens, puedes ver la cantidad de tokens
que usa una consulta en la
Google Cloud consola. Para estimar este uso antes de ejecutar una consulta, usa la
AI.COUNT_TOKENS función.
En el siguiente ejemplo, se muestra cómo usar la función AI.IF
con el modo optimizado para identificar artículos de noticias sobre desastres naturales, usando text-embedding-005
como el modelo de incorporación:
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
El argumento optimization_mode => 'MINIMIZE_COST' habilita el modo optimizado. Esta es la configuración predeterminada cuando se proporcionan incorporaciones, por lo que puedes omitir este argumento.
En este ejemplo, las incorporaciones se generan de forma dinámica. En la práctica, te recomendamos que materialices las incorporaciones para que se puedan volver a usar.
Cómo funciona el modo optimizado
Las funciones de IA administradas, AI.IF y AI.CLASSIFY, suelen llamar a un
LLM remoto para cada fila de tu conjunto de datos. Cuando usas el modo optimizado, BigQuery entrena automáticamente un modelo destilado y ligero durante la ejecución de la consulta.
El proceso funciona de la siguiente manera:
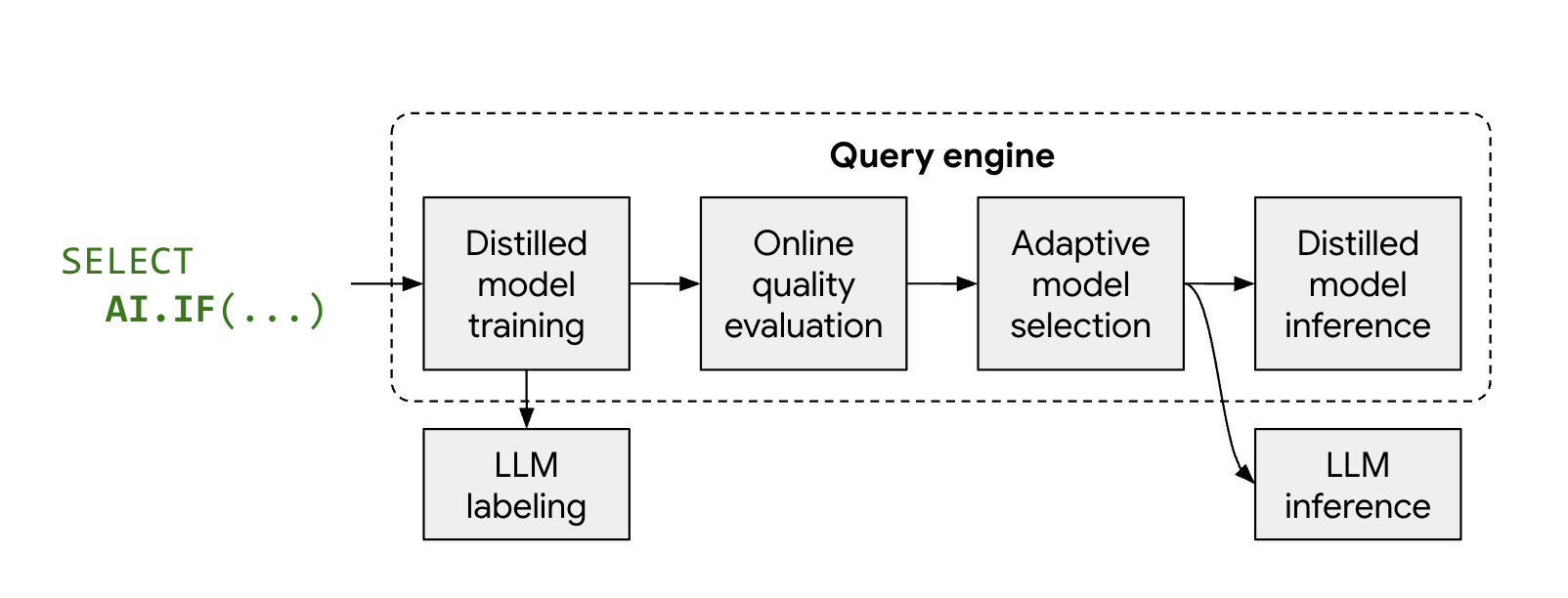
- Muestreo y etiquetado: BigQuery selecciona una pequeña muestra representativa de tus datos y llama a Gemini para que proporcione etiquetas.
- Entrenamiento del modelo destilado: Se entrena un modelo destilado local justo a tiempo con las etiquetas de LLM y las incorporaciones de datos como atributos.
- Verificación de calidad: BigQuery evalúa la exactitud del modelo destilado en comparación con los resultados del LLM. De forma predeterminada, si el modelo destilado no cumple con el umbral de calidad requerido, la consulta falla con un error que explica por qué se descartó el modelo. Si el modelo tiene una calidad aceptable, es posible que BigQuery aún recurra al LLM remoto para filas específicas para mantener una calidad coherente o para filas que no tengan incorporaciones válidas.
- Inferencia: El modelo destilado procesa la mayoría de las filas, lo que reduce significativamente la cantidad de llamadas a Gemini.
Limitaciones
El modo optimizado tiene las siguientes limitaciones:
- Cantidad mínima de filas: La entrada a la función de IA debe contener aproximadamente 3,000 filas para garantizar suficientes datos para el entrenamiento de modelos.
- Tipos de datos: Para las instrucciones que hacen referencia a varias columnas, solo se admiten columnas de cadena para la optimización.
- Clasificación de varias etiquetas:
AI.CLASSIFYconoutput_mode => 'multi'no se admite en el modo optimizado. - Compatibilidad con funciones: Solo las funciones
AI.IFyAI.CLASSIFYadmiten el modo optimizado. Sin embargo, cuando se usa el modo optimizado conAI.CLASSIFY, las consultas pueden fallar si la calidad del modelo destilado es insuficiente. - Proporción de errores: El argumento
max_error_rationo se admite en el modo optimizado.
Antes de comenzar
Para obtener los permisos que necesitas para ejecutar funciones de IA administradas en BigQuery, consulta Establece permisos para las funciones de IA generativa que llaman a LLM de la plataforma de agentes de Gemini Enterprise.
Elige un modelo de incorporación
Para usar el modo optimizado, debes calcular embeddings de tus datos y proporcionarlos a la función IA. Para que las columnas de entrada tengan incorporaciones asociadas, todas las filas deben tener dimensiones de incorporación coherentes y generarse con el mismo modelo de incorporación.
Para obtener la mejor calidad y escalabilidad en relación con el costo, te recomendamos que calcules las incorporaciones de
tus datos con un modelo de incorporación, como
text-embedding-005 o las incorporaciones de Gemini
para tareas en inglés o multilingües. Para datos multimodales (texto e imágenes), usa un
modelo de incorporación multimodal, como
multimodalembedding@001.
Genera embeddings
Puedes calcular las incorporaciones de tus datos con la generación autónoma administrada por BigQuery o creando manualmente las columnas de incorporación.
En las siguientes secciones, se describe cómo usar ambos enfoques con las funciones AI.CLASSIFY y AI.IF.
Generación autónoma de incorporaciones
Si usas la generación autónoma de incorporaciones,
BigQuery usa automáticamente las incorporaciones cuando se llama a AI.IF o
AI.CLASSIFY. Este es el enfoque recomendado, pero se limita a una columna de incorporación por tabla.
En el siguiente ejemplo, se crea una tabla con una columna de incorporación generada de forma autónoma, usando text-embedding-005 como el modelo de incorporación y, luego, se usa la función AI.CLASSIFY para categorizar los datos:
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
Especificación manual de columnas
Si tienes una columna de incorporación existente, especifícala en el argumento embeddings de AI.IF o AI.CLASSIFY. Puedes generarla con la
AI.EMBED función.
En el siguiente ejemplo, se muestra cómo crear una tabla con una columna de incorporación, usando text-embedding-005 como el modelo de incorporación y, luego, usar esa columna en una consulta AI.CLASSIFY:
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
Si tu instrucción hace referencia a varias columnas, proporciona una lista de nombres de columnas y sus incorporaciones correspondientes en el argumento embeddings. Por ejemplo:
embeddings => [('body', body_embedding), ('title', title_embedding)].
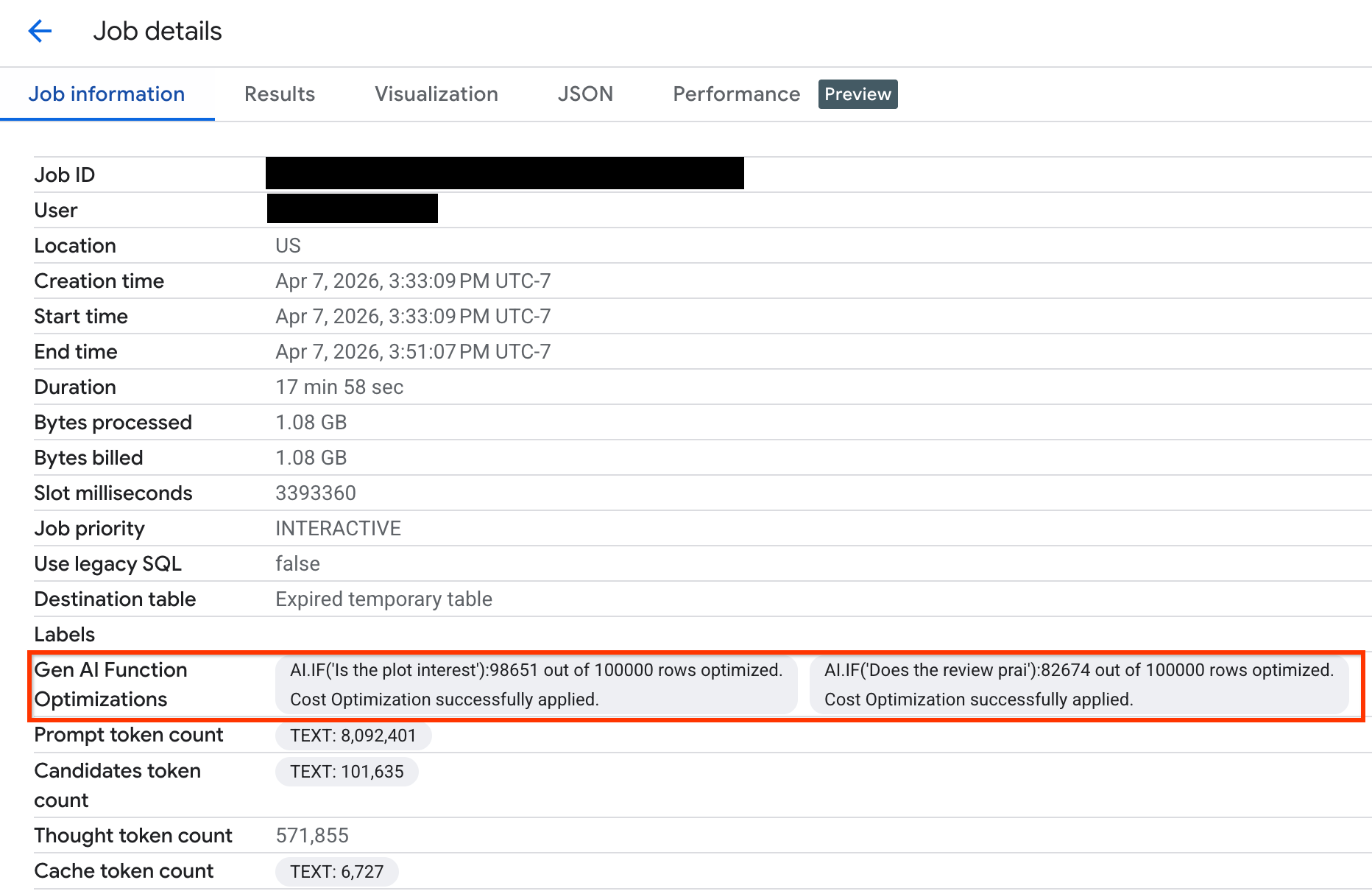
Supervisa la optimización de consultas
Para verificar cuántas filas se optimizaron durante la ejecución de la consulta, puedes ver las estadísticas de ejecución en la Google Cloud consola o a través de la API:
Console
Para ver cuántas filas se optimizaron y ver los mensajes del sistema sobre el estado de optimización, haz lo siguiente:
En la Google Cloud consola de, ve a la página BigQuery.
En el menú de navegación, haz clic en Explorador de trabajos.
Haz clic en el ID del trabajo para ver el panel Detalles del trabajo.
Haz clic en la pestaña Información del trabajo y consulta las métricas y el estado en el campo Optimizaciones de funciones IA.
API
Verifica FunctionGenAiCostOptimizationStats en el objeto GenAIFunctionStats de los metadatos del trabajo. Este objeto incluye la cantidad de filas inferidas a través del flujo de trabajo optimizado y los mensajes generados por el sistema que proporcionan estadísticas sobre el estado de optimización.
Solucionar problemas
En las siguientes secciones, se explica cómo diagnosticar y resolver problemas comunes con el uso del modo optimizado.
El tamaño de los datos es demasiado pequeño
Problema: Datos insuficientes para el entrenamiento de modelos. Es posible que veas el siguiente
mensaje de error: Fail to apply cost optimization because the data size is too
small.
Solución: Aumenta el tamaño de tu entrada a aproximadamente 3,000 filas y verifica que se hayan generado correctamente incorporaciones válidas para todas las filas.
Pocas o ninguna muestra en algunas clases
Problema: Cantidad insuficiente de muestras para ciertas categorías durante la
fase de muestreo, lo que impide el entrenamiento de modelos. Es posible que veas el siguiente
mensaje de error: Fail to apply cost optimization because some classes have
few or no samples.
Solución:
- Quita las categorías raras o vacías de la llamada a la función
AI.CLASSIFY. - Agrupa las categorías raras en una más amplia para aumentar el tamaño de la muestra. Puedes usar una categoría
OTHERpara agrupar elementos que no estén cubiertos por categorías más específicas. Sin embargo, no agreguesOTHERsi tu lista de categorías ya está completa, ya que este término es ambiguo y puede causar confusión.
Las incorporaciones tienen dimensiones incoherentes
Problema: Incoherencias entre las dimensiones de incorporación en las filas. Es posible que veas el siguiente mensaje de error: Fail to apply cost optimization
because the embeddings have inconsistent dimensions.
Solución: Verifica que las incorporaciones se generen con el mismo modelo y tengan la misma longitud del vector de incorporación. Puedes usar una consulta en SQL similar a la siguiente para verificar que los embeddings de una columna tengan la misma longitud:
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
La complejidad de la instrucción es demasiado alta
Problema: El modelo destilado no puede alcanzar un umbral de exactitud alto. Es posible que veas el siguiente mensaje de error: Fail to apply cost optimization
because the prompt complexity is too high.
Solución:
Usa un conjunto de categorías que formen una partición. Asegúrate de que las categorías tengan una superposición mínima y cubran todas las entradas posibles.
- Evita las categorías superpuestas en las que una entrada pueda pertenecer a varias categorías de forma simultánea. Por ejemplo, evita categorías como
['terrible', 'bad', 'okay', 'good', 'excellent']. - Evita las brechas en las que no se apliquen categorías. Por ejemplo, la lista de
categorías
['bad', 'average']no cubre una reseña que exprese elogios. Proporciona descripciones de categorías para guiar al LLM a resolver la ambigüedad entre categorías. Por ejemplo:
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- Evita las categorías superpuestas en las que una entrada pueda pertenecer a varias categorías de forma simultánea. Por ejemplo, evita categorías como
Prueba modelos de incorporación más avanzados, como
text-embedding-005omultimodalembedding.Comunícate con bqml-feedback@google.com para obtener asistencia adicional para la depuración.
Cantidad inesperada de filas procesadas por el LLM
Problema: Las estadísticas de ejecución de la consulta muestran que el LLM remoto procesó una cantidad inesperadamente alta de filas en lugar del modelo destilado. Esto puede deberse a los siguientes motivos:
- El modelo destilado se entrenó correctamente, pero algunas filas no tenían incorporaciones. El LLM remoto procesa estas filas.
- No se pudo aplicar el modelo destilado para cada fila y se tuvo que recurrir al LLM remoto para mantener una calidad coherente.
Solución: Verifica que las incorporaciones se generen correctamente y sean válidas para todas las filas de tus datos. Si el problema persiste, comunícate con bqml-feedback@google.com para la depuración.
No se detectó la columna de incorporación autónoma
Problema: BigQuery no puede detectar una columna de incorporación autónoma. Esto puede ocurrir si tu secuencia de comandos usa una tabla temporal y se pierde la referencia a la tabla original.
Solución: Usa el parámetro embeddings para pasar de forma explícita una columna de incorporación autónoma, por ejemplo, embeddings => content_embedding.result, que activa la optimización de costos.
¿Qué sigue?
- Obtén más información sobre la IA generativa en BigQuery.
- Consulta la documentación de la función
AI.IF. - Consulta la documentación de la función
AI.CLASSIFY.