
במדריך הזה תלמדו איך להשתמש במודל k-means ב-BigQuery ML כדי לזהות אשכולות במערך נתונים.
אלגוריתם k-means שמקבץ את הנתונים לאשכולות הוא סוג של למידת מכונה לא מפוקחת. בניגוד ללמידת מכונה מפוקחת, שמתמקדת בניתוח נתונים לחיזוי, למידת מכונה לא מפוקחת מתמקדת בניתוח נתונים תיאורי. למידת מכונה לא מפוקחת יכולה לעזור לכם להבין את הנתונים כדי שתוכלו לקבל החלטות מבוססות-נתונים.
השאילתות במדריך הזה משתמשות בפונקציות גיאוגרפיות שזמינות בניתוח נתונים גיאו-מרחביים. מידע נוסף זמין במאמר מבוא לניתוח נתונים גיאו-מרחביים.
במדריך הזה נשתמש במערך הנתונים הציבורי London Bicycle Hires. הנתונים כוללים חותמות זמן של התחלה וסיום, שמות תחנות ומשך הנסיעה.
מטרות
במדריך הזה מוסבר איך לבצע את הפעולות הבאות:- בודקים את הנתונים ששימשו לאימון המודל.
- יצירת מודל k-means clustering.
- לפרש את אשכולות הנתונים שנוצרו באמצעות ההדמיה של האשכולות ב-BigQuery ML.
- מריצים את הפונקציה
ML.PREDICTבמודל k-means כדי לחזות את האשכול הסביר עבור קבוצה של תחנות להשכרת אופניים.
עלויות
במדריך הזה נעשה שימוש ברכיבים של Google Cloudשחלים עליהם חיובים, כולל הרכיבים הבאים:
- BigQuery
- BigQuery ML
מידע על העלויות ב-BigQuery זמין בדף תמחור ב-BigQuery.
מידע על העלויות של BigQuery ML זמין במאמר תמחור BigQuery ML.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery מופעל באופן אוטומטי בפרויקטים חדשים.
כדי להפעיל את BigQuery בפרויקט קיים, עוברים אל
מפעילים את BigQuery API.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים
ההרשאות הנדרשות
כדי ליצור את מערך הנתונים, אתם צריכים את ההרשאה
bigquery.datasets.createב-IAM.כדי ליצור את המודל, צריך את ההרשאות הבאות:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
כדי להריץ הסקה, אתם צריכים את ההרשאות הבאות:
bigquery.models.getDatabigquery.jobs.create
במאמר מבוא ל-IAM יש מידע נוסף על תפקידים והרשאות ב-IAM ב-BigQuery.
יצירת מערך נתונים
יוצרים מערך נתונים ב-BigQuery לאחסון מודל k-means:
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer, לוחצים על שם הפרויקט.
לוחצים על הצגת פעולות > יצירת מערך נתונים.
בדף Create dataset, מבצעים את הפעולות הבאות:
בשדה Dataset ID (מזהה מערך הנתונים), מזינים
bqml_tutorial.בקטע Location type (סוג המיקום), בוחרים באפשרות Multi-region (מספר אזורים) ואז באפשרות EU (multiple regions in European Union) (האיחוד האירופי, מספר אזורים).
מערך הנתונים הציבורי של השכרת אופניים בלונדון מאוחסן ב
EUמספר אזורים. מערך הנתונים צריך להיות באותו מיקום.משאירים את הגדרות ברירת המחדל שנותרו כמו שהן ולוחצים על Create dataset (יצירת מערך נתונים).

בדיקת נתוני האימון
בודקים את הנתונים שישמשו לאימון מודל k-means. במדריך הזה, תבצעו אשכולות של תחנות השכרת אופניים על סמך המאפיינים הבאים:
- משך ההשכרה
- מספר הנסיעות ביום
- מרחק ממרכז העיר
SQL
השאילתה הזו מחלצת נתונים על השכרת אופניים, כולל העמודות start_station_name ו-duration, ומצרפת את הנתונים האלה למידע על התחנות. זה כולל יצירת עמודה מחושבת שמכילה את המרחק של התחנה ממרכז העיר. לאחר מכן, הפונקציה מחשבת את המאפיינים של התחנה בעמודה stationstats, כולל משך הנסיעות הממוצע ומספר הנסיעות, ובעמודה distance_from_city_center.
כדי לבדוק את נתוני האימון:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
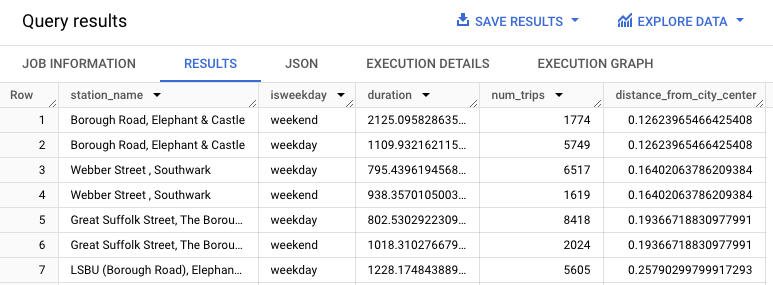
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
התוצאות אמורות להיראות כך:
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
יצירת מודל k-means
יוצרים מודל k-means באמצעות נתוני אימון של השכרת אופניים בלונדון.
SQL
בשאילתה הבאה, המשפט CREATE MODEL מציין את מספר האשכולות לשימוש – ארבעה. במשפט SELECT, פסוקית EXCEPT
לא כוללת את העמודה station_name כי העמודה הזו לא מכילה תכונה. השאילתה יוצרת שורה ייחודית לכל station_name, ורק התכונות מוזכרות בהצהרה SELECT.
כדי ליצור מודל k-means:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
הסבר על אשכולות הנתונים
המידע בכרטיסייה Evaluation של המודל יכול לעזור לכם להבין את האשכולות שהמודל יצר.
כדי לראות את פרטי ההערכה של המודל:
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית הימנית, לוחצים על כלי הניתוחים:
בחלונית Explorer, מרחיבים את הפרויקט ולוחצים על Datasets (מערכי נתונים).
לוחצים על מערך הנתונים
bqml_tutorialואז עוברים לכרטיסייה מודלים.בוחרים את המודל
london_station_clusters.לוחצים על הכרטיסייה הערכה. בכרטיסייה הזו מוצגות תצוגות חזותיות של האשכולות שזוהו על ידי מודל k-means. בקטע Numeric features (מאפיינים מספריים), תרשימי עמודות מציגים את ערכי המאפיינים המספריים החשובים ביותר לכל מרכז מסה. כל מרכז מסה מייצג אשכול נתונים מסוים. אפשר לבחור אילו תכונות להציג בתרשים מהתפריט הנפתח.
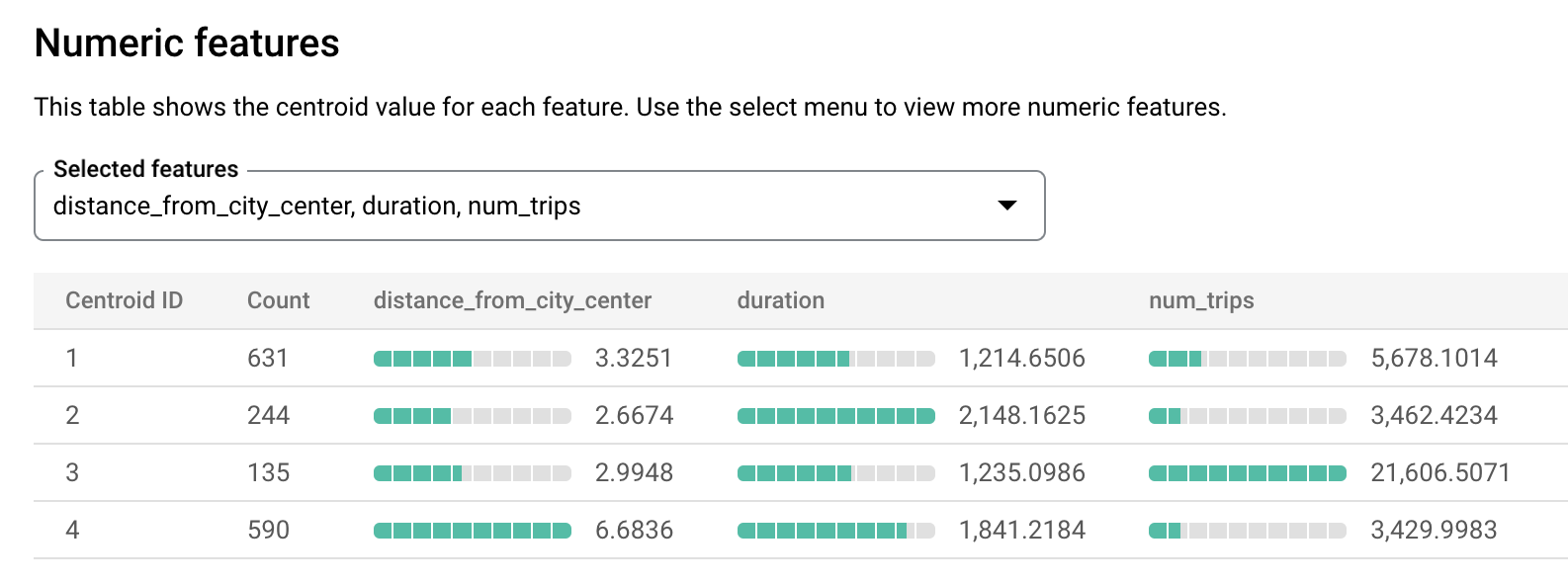
המודל הזה יוצר את מרכזי הכובד הבאים:
- במרכז המסה 1 מוצגת תחנה עירונית פחות עמוסה, עם השכרות לפרקי זמן קצרים יותר.
- במרכז המסה 2 מוצגת התחנה השנייה בעיר, שפחות עמוסה ומשמשת להשכרות לפרקי זמן ארוכים יותר.
- נקודת המרכז 3 מראה תחנה עירונית הומה שקרובה למרכז העיר.
- מרכז המסה 4 מציג תחנה בפרברים עם נסיעות ארוכות יותר.
אם הייתם מנהלים עסק להשכרת אופניים, הייתם יכולים להשתמש במידע הזה כדי לקבל החלטות עסקיות. לדוגמה:
נניח שאתם רוצים להתנסות בסוג חדש של נעילה. איזו קבוצת תחנות כדאי לבחור כנושא לניסוי הזה? התחנות בנקודת המרכז 1, בנקודת המרכז 2 או בנקודת המרכז 4 נראות כמו בחירות הגיוניות כי הן לא התחנות העמוסות ביותר.
נניח שאתם רוצים להציב אופני מירוץ בכמה תחנות. באילו תחנות כדאי לבחור? מרכז הכובד 4 הוא קבוצת התחנות שנמצאות רחוק ממרכז העיר, והנסיעות בהן הן הארוכות ביותר. אלה מועמדים מתאימים לאופני מרוץ.
שימוש בפונקציה ML.PREDICT כדי לחזות את האשכול של תחנה
כדי לזהות לאיזה אשכול שייכת תחנה מסוימת, משתמשים בפונקציית ה-SQL ML.PREDICT או בפונקציית predict BigQuery DataFrames.
SQL
השאילתה הבאה משתמשת בפונקציה REGEXP_CONTAINS כדי למצוא את כל הערכים בעמודה station_name שמכילים את המחרוזת Kennington. הפונקציה ML.PREDICT משתמשת בערכים האלה כדי לחזות אילו אשכולות עשויים להכיל את התחנות האלה.
כדי לחזות את האשכול של כל תחנה שכוללת את המחרוזת Kennington בשם שלה, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בעורך השאילתות, מדביקים את השאילתה הבאה ולוחצים על Run (הרצה):
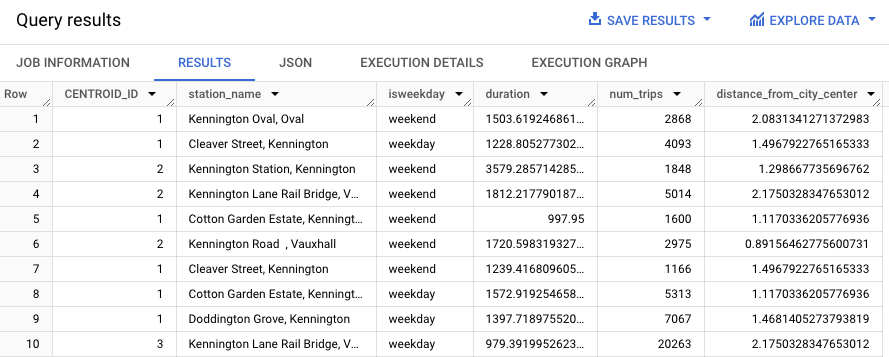
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
התוצאות אמורות להיראות כך:
BigQuery DataFrames
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי הוראות ההגדרה של BigQuery DataFrames במדריך לתחילת העבודה עם BigQuery באמצעות BigQuery DataFrames. מידע נוסף מופיע במאמרי העזרה בנושא BigQuery DataFrames.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת ADC לסביבת פיתוח מקומית.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
- אתם יכולים למחוק את הפרויקט שיצרתם.
- אפשר גם להשאיר את הפרויקט ולמחוק את קבוצת הנתונים.
מחיקת מערך נתונים
אם מוחקים פרויקט, כל מערכי הנתונים וכל הטבלאות בפרויקט נמחקים. אם אתם מעדיפים להשתמש מחדש בפרויקט, אתם יכולים למחוק את מערך הנתונים שיצרתם במדריך הזה:
אם צריך, פותחים את הדף BigQuery במסוףGoogle Cloud .
בחלונית הניווט, לוחצים על מערך הנתונים bqml_tutorial שיצרתם.
בצד שמאל של החלון, לוחצים על מחיקת מערך נתונים. הפעולה הזו מוחקת את מערך הנתונים ואת המודל.
בתיבת הדו-שיח מחיקת מערך נתונים, מקלידים את שם מערך הנתונים (
bqml_tutorial) כדי לאשר את פקודת המחיקה, ואז לוחצים על מחיקה.
מחיקת פרויקט
כדי למחוק את הפרויקט:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
- סקירה כללית על BigQuery ML זמינה במאמר מבוא ל-BigQuery ML.
- מידע על יצירת מודלים זמין בדף התחביר של
CREATE MODEL.