
將 Apache Hive Metastore 資料表遷移至 Google Cloud
本文說明如何使用 BigQuery 資料移轉服務,將 Apache Hive Metastore 管理的 Iceberg 和 Hive 資料表遷移至Google Cloud 。
BigQuery 資料移轉服務中的 Apache Hive Metastore 遷移連接器,可讓您 Google Cloud 大規模地將 Hive Metastore 資料表順暢遷移至 BigQuery。這個連結器支援地端安裝和雲端環境 (包括 Cloudera 設定) 的 Hive 和 Iceberg 資料表。Hive Metastore 遷移連接器支援儲存在下列資料來源中的檔案:
- Apache Hadoop 分散式檔案系統 (HDFS)
- Amazon Simple Storage Service (Amazon S3)
- Azure Blob 儲存體或 Azure Data Lake Storage Gen2
透過 Hive Metastore 遷移連接器,您可以使用 Cloud Storage 做為檔案儲存空間,並向下列任一 metastore 註冊 Hive Metastore 資料表:
Lakehouse 執行階段目錄 Iceberg REST 目錄
建議您使用 Lakehouse 執行階段目錄 Iceberg REST 目錄,處理所有 Iceberg 資料。
Lakehouse 執行階段目錄 Iceberg REST 目錄會為所有 Iceberg 資料提供單一事實來源,在查詢引擎之間建立互通性。除了 Apache Spark 和其他 OSS 引擎,您也可以使用 BigQuery 查詢資料。Lakehouse 執行階段目錄 Iceberg REST 目錄僅支援 Iceberg 資料表格式。
Lakehouse 執行階段目錄 Hive 目錄 (預先發布版)
建議您為所有 Hive 資料表使用 Lakehouse 執行階段目錄 Hive 目錄。
您可以使用 Hive 目錄,透過 Lakehouse 執行階段目錄 Hive 目錄,將遷移的 Hive 資料表註冊至 Lakehouse 執行階段目錄。這項服務提供 Apache Hive 資料表的無伺服器 Metastore。除了 Apache Spark 和其他 OSS 引擎,您也可以使用 BigQuery 查詢資料 (須遵守格式限制)。
-
Dataproc Metastore 支援 Hive 和 Iceberg 資料表格式。您只能使用 Apache Spark 和其他 OSS 引擎,從 Dataproc Metastore 讀取及寫入資料。
這個連接器支援完整轉移和僅轉移中繼資料。完整轉移會將來源資料表中的資料和中繼資料,一併轉移至目標中繼資料存放區。如果資料已儲存在 Cloud Storage 中,且您只想將資料登錄至目的地中繼存放區,則可以建立僅含中繼資料的轉移作業。
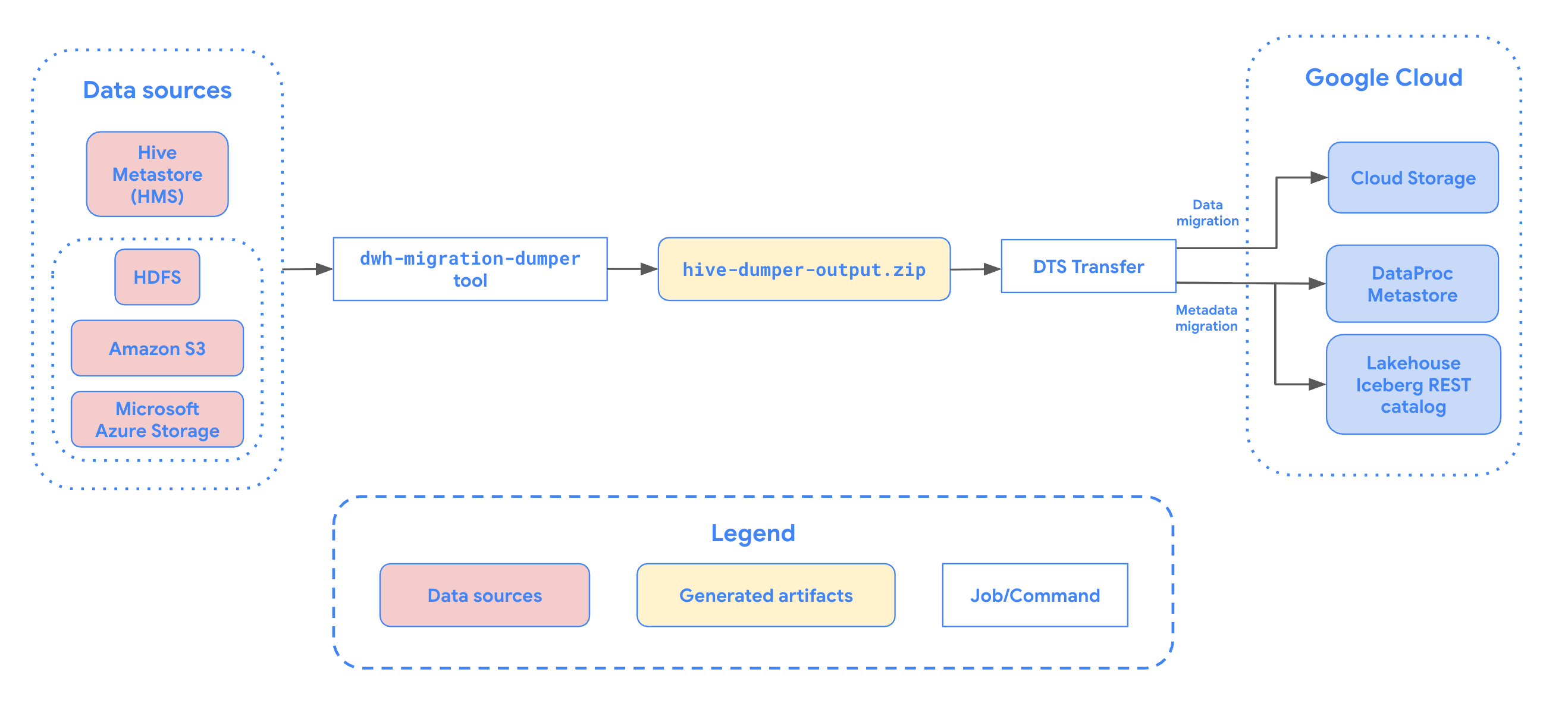
下圖概述遷移程序。
限制
Hive Metastore 資料表轉移作業有下列限制:
- 排定的兩次 Hive Metastore 轉移作業之間,至少須間隔 30 分鐘。您仍可隨時觸發隨選執行作業。
- 檔案名稱必須符合 Cloud Storage 物件命名規定。
- Cloud Storage 的單一物件大小上限為 5 TiB。如果 Hive Metastore 表格中的檔案大於 5 TiB,系統就無法轉移。
- 如果資料在移轉作業進行期間於來源端變更,Storage 移轉服務會有特定行為。我們不建議在資料表主動遷移期間寫入資料表。如需其他 Storage 移轉服務限制的清單,請參閱「已知限制」。
Lakehouse 執行階段目錄 Hive 目錄限制
使用 Lakehouse 執行階段目錄 Hive 目錄 (BIGLAKE_HIVE_CATALOG) 做為目的地 Metastore 時,請注意下列限制和事項:
- Lakehouse 執行階段目錄 Hive 目錄 ID 只能包含小寫英文字母、數字和底線 (
_),不得包含破折號 (-) 或大寫英文字母。 - 您無法在 Google Cloud 控制台中查看或管理 Lakehouse 執行階段目錄 Hive 目錄。不過,您可以在目標 BigQuery 資料集下查看及查詢已遷移的資料表。
- 所有 Lakehouse 執行階段目錄 Hive 目錄限制都適用於開放原始碼中繼資料格式和資料類型。
資料擷取選項
以下各節將詳細說明如何設定 Hive Metastore 轉移作業。
增量移轉
如果移轉設定設有週期性時間表,每次後續移轉都會更新 Google Cloud 中的資料表,並納入來源資料表的最新更新。舉例來說,所有資料更新,以及所有插入、刪除或更新作業 (含結構定義變更) 都會反映在 Google Cloud 中,每次轉移都會更新。
篩選分區
您可以提供儲存在 Cloud Storage 中的自訂篩選器 JSON 檔案,從 Hive 資料表移轉部分分割區。排定轉移作業時,請使用 partition_filter_gcs_path 參數,提供這個 JSON 檔案的完整 Cloud Storage 路徑。
以下是篩選器 JSON 檔案結構範例:
{
"filters": [
{
"table": "db1.table1", "condition": "IN", "partitions":
["partition1=value1/partition2=value2"]
},
{
"table": "db1.table2", "condition": "LESS_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table3", "condition": "GREATER_THAN", "partitions":
["partition1;value1"]
},
{
"table": "db1.table4", "condition": "RANGE", "partitions":
["partition1;value1;value2"]
}
]
}
篩選條件
JSON 檔案中的 condition 欄位支援下列值,每個值都有 partitions 陣列的特定格式:
IN:指定要納入的確切分割區路徑。partitions陣列包含代表分割區確切目錄結構的字串,這些結構與資料表基本路徑相關 (例如["partition_key1=value1/partition_key2=value2"])。您可以在陣列中指定多個路徑。LESS_THAN:包含主要分割區鍵值小於或等於指定值的分割區。partitions陣列必須包含格式為["<partition_key>;<value>"]的單一字串。GREATER_THAN:包含主要分區鍵值大於或等於指定值的分區。partitions陣列必須包含格式為["<partition_key>;<value>"]的單一字串。RANGE:包含主要分區鍵值落在指定範圍內 (含) 的分區。partitions陣列必須包含格式為["<partition_key>;<start_value>;<end_value>"]的單一字串。
篩選條件須遵守下列規則和限制:
- 包含的值:
GREATER_THAN、LESS_THAN和RANGE的篩選條件包含提供的值。舉例來說,值為2023的LESS_THAN篩選器會納入2023(含) 之前的分割區。 - 刪除分區:如果現有的目的地分區符合分區篩選器,但來源中已不再存在,系統就會從目的地中繼存放區捨棄該分區。不過,該分割區的基礎資料檔案不會從 Cloud Storage 目的地 bucket 刪除。
- 單一表格限制:
- 同一個表格中不得包含多個篩選器。
- 您無法在同一張表格中混用不同類型的條件 (例如:
GREATER_THAN和IN)。
- 目標分區資料欄:
GREATER_THAN、LESS_THAN和RANGE等篩選條件必須以主要分區資料欄為目標。 - 前置字串限制:指定的篩選條件組合不得為每個資料表解析出超過 1000 個前置字串。舉例來說,如果資料表是依
year/month/day分割,則year>2020等篩選條件產生的不重複year=前置字元必須少於 1000 個。
事前準備
排定 Hive Metastore 轉移作業前,請先執行本節中的步驟。
啟用 API
在Google Cloud 專案中啟用下列 API:
- Data Transfer API
- Storage Transfer API
- BigLake API
啟用 Data Transfer API 時,系統會建立服務代理程式。
設定權限
如要設定 Hive Metastore 轉移作業的權限,請按照下列各節的步驟操作。
- 建立轉移作業的使用者或服務帳戶應具備 BigQuery 管理員角色 (
roles/bigquery.admin)。如果您使用服務帳戶,該帳戶只會用於建立轉移作業。 啟用 Data Transfer API 時,系統會建立服務代理程式 (P4SA)。
為確保服務代理具備執行 Hive Metastore 轉移作業的必要權限,請要求管理員在專案中授予服務代理下列 IAM 角色:
- Storage Transfer 管理員 (
roles/storagetransfer.admin) - 服務使用情形消費者 (
roles/serviceusage.serviceUsageConsumer) - 儲存空間管理員 (
roles/storage.admin) -
如要將中繼資料遷移至 Lakehouse 執行階段目錄 (Iceberg REST 目錄或 Hive 目錄):
BigLake 管理員 (
roles/biglake.admin) -
如要將中繼資料遷移至 Dataproc Metastore,請執行下列步驟:
Dataproc Metastore 資料擁有者 (
roles/metastore.metadataOwner)
如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和組織的存取權」。
- Storage Transfer 管理員 (
如果您使用服務帳戶,請執行下列指令,將
roles/iam.serviceAccountTokenCreator角色授予服務代理程式:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
在專案中,將下列角色授予 Storage 移轉服務代理程式 (
project-PROJECT_NUMBER@storage-transfer-service.iam.gserviceaccount.com):roles/storage.admin- 如果您是從地端/HDFS 遷移,也必須授予
roles/storagetransfer.serviceAgent角色。
您也可以設定更精細的權限。詳情請參閱下列指南:
產生 Apache Hive 的中繼資料檔案
執行 dwh-migration-dumper 工具,擷取 Apache Hive 的中繼資料。這項工具會產生名為 hive-dumper-output.zip 的檔案,可上傳至 Cloud Storage bucket。本文將這個 Cloud Storage bucket 稱為 DUMPER_BUCKET。
您也可以使用指令碼,排定定期上傳時間。詳情請參閱「使用 cron 工作自動執行傾印工具」。
設定 Storage 移轉服務
選取下列選項之一:
HDFS
如要轉移地端部署或 HDFS 資料,必須使用儲存空間轉移代理程式。
如要設定代理程式,請執行下列操作:
- 在內部部署代理程式機器上安裝 Docker。
- 在 Google Cloud 專案中建立 Storage 移轉服務代理集區。
- 在您的地端部署代理程式電腦上安裝代理程式。
Amazon S3
從 Amazon S3 移轉資料時,不需要使用代理程式。
如要設定 Storage 移轉服務以進行 Amazon S3 移轉作業,請按照下列步驟操作:
- 設定 AWS Amazon S3 的存取憑證。
- 設定存取憑證後,請記下存取金鑰 ID 和私密存取金鑰。
- 如果 AWS 專案使用 IP 限制,請將 Storage 移轉服務 工作人員使用的 IP 範圍新增至許可 IP 清單。
Microsoft Azure
從 Microsoft Azure 儲存體轉移資料時,不需要代理程式。
如要設定 Storage 移轉服務,以便移轉 Microsoft Azure 儲存空間,請按照下列步驟操作:
- 為 Microsoft Azure 儲存體帳戶產生共用存取簽章 (SAS) 權杖。
- 產生 SAS 權杖後,請記下該權杖。
- 如果 Microsoft Azure 儲存空間帳戶使用 IP 限制,請將 Storage 移轉服務工作站使用的 IP 範圍新增至允許的 IP 清單。
排定 Hive Metastore 轉移作業
選取下列選項之一:
控制台
前往 Google Cloud 控制台的「資料移轉」頁面。
按一下 「建立轉移作業」。
在「來源類型」部分,從「來源」清單中選取「Hive Metastore」。
在「位置」下方選取位置類型,然後選取區域。
在「Transfer config name」(轉移設定名稱) 部分,「Display name」(顯示名稱) 請輸入資料移轉作業名稱。
在「Schedule options」(排程選項) 部分執行下列操作:
- 在「Repeat frequency」(重複頻率) 清單選取選項,指定這項資料移轉作業的執行頻率。如要指定自訂重複頻率,請選取「Custom」(自訂)。如果選取「On-demand」(隨選),這項移轉作業會在您手動觸發後執行。
- 視情況選取「Start now」(立即開始) 或「Start at set time」(在所設時間開始執行),並提供開始日期和執行時間。
在「Data source details」(資料來源詳細資料) 部分執行下列操作:
- 在「轉移策略」中,選取下列任一選項:
FULL_TRANSFER:轉移所有資料,並向目標中繼存放區註冊中繼資料。這是預設選項。METADATA_ONLY:僅註冊中繼資料。您必須在元資料參照的正確 Cloud Storage 位置中,預先存有資料。
- 在「Table name patterns」(資料表名稱格式) 部分,提供符合 HDFS 資料庫中資料表的資料表名稱或格式,指定要轉移的 HDFS 資料湖泊資料表。您必須使用 Java 規則運算式語法指定表格模式。例如:
db1..*會比對 db1 中的所有資料表。db1.table1;db2.table2會比對 db1 中的 table1 和 db2 中的 table2。
- 在「BQMS discovery dump gcs path」(BQMS 探索傾印 GCS 路徑) 中,輸入您在為 Apache Hive 建立中繼資料檔案時產生的
hive-dumper-output.zip檔案路徑。如果您使用 dumper 輸出自動化功能搭配cron,請提供--gcs-base-path中設定的 Cloud Storage 資料夾路徑,其中包含 dumper 輸出 ZIP 檔案。- 在「儲存空間類型」中,選取下列任一選項。只有在「轉移策略」設為
FULL_TRANSFER時,才能使用這個欄位: HDFS:如果檔案儲存空間是HDFS,請選取這個選項。在「STS agent pool name」(STS 代理程式集區名稱) 欄位中,您必須提供設定 Storage Transfer Agent 時建立的代理程式集區名稱。S3:如果檔案儲存空間是Amazon S3,請選取這個選項。在「Access key ID」(存取金鑰 ID) 和「Secret access key」(存取密鑰) 欄位中,您必須提供設定存取憑證時建立的存取金鑰 ID 和存取密鑰。AZURE:如果檔案儲存空間是Azure Blob Storage,請選取這個選項。在「SAS token」(SAS 權杖) 欄位中,您必須提供設定存取憑證時建立的 SAS 權杖。
- 在「儲存空間類型」中,選取下列任一選項。只有在「轉移策略」設為
- 選用:在「Partition Filter gcs path」(分區篩選器 GCS 路徑) 欄位中,輸入自訂篩選器 JSON 檔案的完整 Cloud Storage 路徑,以篩選來源資料表中的分區。
- 在「Destination gcs path」(目的地 GCS 路徑) 中,輸入 Cloud Storage bucket 的路徑,以儲存遷移的資料。
- 從下拉式清單中選擇目的地 Metastore 類型:
DATAPROC_METASTORE:選取這個選項,將中繼資料儲存在 Dataproc Metastore 中。您必須在「Dataproc metastore url」(Dataproc Metastore 網址) 中提供 Dataproc Metastore 的網址。BIGLAKE_REST_CATALOG:選取這個選項,將中繼資料儲存在 Lakehouse 執行階段目錄 Iceberg REST 目錄中。系統會根據目標 Cloud Storage 值區建立目錄。BIGLAKE_HIVE_CATALOG(預覽版):選取這個選項,將中繼資料儲存在 Lakehouse 執行階段目錄 Hive 目錄中。您必須在 BigLake Metastore Hive Catalog ID 中提供目錄名稱。如果目錄不存在,系統會自動建立。
- 選用:針對「服務帳戶」,輸入要用於這項資料移轉作業的服務帳戶。服務帳戶應屬於移轉設定和目的地資料集建立所在的Google Cloud 專案。
- 在「轉移策略」中,選取下列任一選項:
bq
如要排定 Hive Metastore 移轉作業,請輸入 bq mk 指令並加上移轉建立作業旗標 --transfer_config:
bq mk --transfer_config --data_source=hadoop display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' location='REGION' --params='{ "transfer_strategy":"TRANSFER_STRATEGY", "table_name_patterns":"LIST_OF_TABLES", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "metastore":"METASTORE", "destination_dataproc_metastore":"DATAPROC_METASTORE_URL", "destination_bigquery_dataset":"BIGLAKE_METASTORE_DATASET", "blms_hive_catalog_id":"HIVE_CATALOG_ID", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/", "storage_type":"STORAGE_TYPE", "agent_pool_name":"AGENT_POOL_NAME", "aws_access_key_id":"AWS_ACCESS_KEY_ID", "aws_secret_access_key":"AWS_SECRET_ACCESS_KEY", "azure_sas_token":"AZURE_SAS_TOKEN", "partition_filter_gcs_path":"FILTER_GCS_PATH" }'
更改下列內容:
TRANSFER_NAME:移轉設定的顯示名稱。移轉作業名稱可以是任意值,日後需要修改移轉作業時,能夠據此識別即可。SERVICE_ACCOUNT:用於建立轉移作業的服務帳戶名稱。服務帳戶應屬於同一個Google Cloud 專案,該專案中已建立轉移設定和目的地資料集。PROJECT_ID:您的 Google Cloud 專案 ID。如未提供--project_id指定特定專案,系統會使用預設專案。REGION:這項移轉設定的位置。TRANSFER_STRATEGY:(選用) 指定下列其中一個值:FULL_TRANSFER:轉移所有資料,並向目標 Metastore 註冊中繼資料。這是預設值。METADATA_ONLY:僅註冊中繼資料。您必須先在元資料中參照的正確 Cloud Storage 位置中,提供資料。
LIST_OF_TABLES:要轉移的實體清單。使用階層式命名規格 -database.table。這個欄位支援 RE2 規則運算式,可指定資料表。例如:db1..*:指定資料庫中的所有資料表db1.table1;db2.table2:資料表清單
DUMPER_BUCKET:包含hive-dumper-output.zip檔案的 Cloud Storage bucket。如果您使用 dumper 輸出自動化功能搭配cron,請將table_metadata_path變更為使用--gcs-base-path在 cron 設定中設定的 Cloud Storage 資料夾路徑,例如:"table_metadata_path":"<var>GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT</var>"。MIGRATION_BUCKET:所有基礎檔案的載入目的地 GCS 路徑。只有在transfer_strategy為FULL_TRANSFER時,才能使用這項功能。METASTORE:要遷移的 Metastore 類型。將此值設為下列其中一個值:DATAPROC_METASTORE:將中繼資料轉移至 Dataproc Metastore。BIGLAKE_REST_CATALOG:將中繼資料轉移至 Lakehouse 執行階段目錄 Iceberg REST 目錄 (建議用於 Iceberg 資料表)。BIGLAKE_HIVE_CATALOG:將中繼資料轉移至 Lakehouse 執行階段目錄 Hive 目錄 (建議用於 Apache Hive 表格) (預先發布版)。
DATAPROC_METASTORE_URL:Dataproc Metastore 的網址。如果metastore為DATAPROC_METASTORE,則為必要欄位。HIVE_CATALOG_ID:Lakehouse 執行階段目錄 Hive 目錄的 ID。如果metastore為BIGLAKE_HIVE_CATALOG,則為必要欄位。如果目錄不存在,系統會自動建立。STORAGE_TYPE:指定資料表的基礎檔案儲存空間。支援的類型為HDFS、S3和AZURE。如果transfer_strategy為FULL_TRANSFER,則為必填。AGENT_POOL_NAME:用於建立代理程式的代理程式集區名稱。如果storage_type為HDFS,則為必要欄位。AWS_ACCESS_KEY_ID:存取憑證中的存取金鑰 ID。如果storage_type為S3,則為必要欄位。AWS_SECRET_ACCESS_KEY:來自存取憑證的私密存取金鑰。如果storage_type為S3,則為必要欄位。AZURE_SAS_TOKEN:來自存取憑證的 SAS 權杖。如果storage_type為AZURE,則為必要欄位。FILTER_GCS_PATH:(選用) 自訂篩選器 JSON 檔案的完整 Cloud Storage 路徑,用於篩選分割區。
執行這項指令,建立移轉設定並開始移轉 Hive 受管理資料表。根據預設,系統每隔 24 小時就會執行移轉作業,但您可以使用移轉排程選項進行設定。
轉移完成後,Hadoop 叢集中的資料表就會遷移至 MIGRATION_BUCKET。
使用 cron 工作自動執行傾印工具
您可以透過cron工作執行 dwh-migration-dumper 工具,自動執行增量轉移作業。自動擷取中繼資料,確保資料來源的最新傾印檔可用於後續的增量轉移作業。
事前準備
使用這項自動化指令碼前,請務必完成下列步驟:
完成傾印工具的所有必要條件。
安裝 Google Cloud CLI。這個指令碼會使用
gsutil指令列工具,將傾印器輸出內容上傳至 Cloud Storage。如要透過 Google Cloud 驗證,允許
gsutil將檔案上傳至 Cloud Storage,請執行下列指令:gcloud auth application-default login
排定自動化動作的執行時間
將下列指令碼儲存至本機檔案。這個指令碼的設計宗旨,是透過
cronDaemon 設定及執行,自動擷取及上傳傾印器輸出內容。#!/bin/bash # Exit immediately if a command exits with a non-zero status. set -e # Treat unset variables as an error when substituting. set -u # Pipelines return the exit status of the last command to exit with a non-zero status. set -o pipefail # These values are used if not overridden by command-line options. DUMPER_EXECUTABLE="DUMPER_PATH/dwh-migration-dumper" GCS_BASE_PATH="gs://PATH_TO_DUMPER_OUTPUT" LOCAL_BASE_DIR="LOCAL_BASE_DIRECTORY_PATH" # Optional arguments for cloud environments DUMPER_HOST="" DUMPER_PORT="" HIVE_KERBEROS_URL="" HIVEQL_RPC_PROTECTION="" KERBEROS_AUTHENTICATION="false" # Function to display usage information usage() { echo "Usage: $0 [options]" echo "" echo "Runs the dwh-migration-dumper tool and uploads its output to provided Cloud Storage path." echo "" echo "Required Options:" echo " --dumper-executable
The full path to the dumper executable." echo " --gcs-base-pathThe base Cloud Storage folder to upload dumper output files to. The script generates timestamped ZIP files in this folder." echo " --local-base-dirThe local base directory for logs and temp files." echo "" echo "Optional Hive connection options:" echo " --hostThe hostname for the dumper connection." echo " --portThe port number for the dumper connection." echo "" echo "To use Kerberos authentication, include the following options." echo "If --kerberos-authentication is specified, then --host, --port," echo "--hive-kerberos-url and --hiveql-rpc-protection are all required:" echo "" echo " --kerberos-authentication Enable Kerberos authentication." echo " --hive-kerberos-urlThe Hive Kerberos URL." echo " --hiveql-rpc-protection" echo " The hiveql-rpc-protection level, equal to the value of" echo " 'hadoop.rpc.protection' in '/etc/hadoop/conf/core-site.xml'," echo " with one of the following values:" echo " - authentication" echo " - integrity" echo " - privacy" echo "" echo "Other Options:" echo " -h, --help Display this help message and exit." exit 1 } # This loop processes command-line options and overrides the default configuration. while [[ "$#" -gt 0 ]]; do case $1 in --dumper-executable) DUMPER_EXECUTABLE="$2" shift # past argument shift # past value ;; --gcs-base-path) GCS_BASE_PATH="$2" shift shift ;; --local-base-dir) LOCAL_BASE_DIR="$2" shift shift ;; --host) DUMPER_HOST="$2" shift shift ;; --port) DUMPER_PORT="$2" shift shift ;; --hive-kerberos-url) HIVE_KERBEROS_URL="$2" shift shift ;; --hiveql-rpc-protection) HIVEQL_RPC_PROTECTION="$2" shift shift ;; --kerberos-authentication) KERBEROS_AUTHENTICATION="true" shift ;; -h|--help) usage ;; *) echo "Unknown option: $1" usage ;; esac done # This runs AFTER parsing arguments to ensure no placeholder values are left. if [[ "$DUMPER_EXECUTABLE" == "DUMPER_PATH"* || "$GCS_BASE_PATH" == "gs://PATH_TO_DUMPER_OUTPUT" || "$LOCAL_BASE_DIR" == "LOCAL_BASE_DIRECTORY_PATH" ]]; then echo "ERROR: One or more configuration variables have not been set. Please provide them as command-line arguments or edit the script." >&2 echo "Run with --help for more information." >&2 exit 1 fi # If Kerberos authentication is enabled, check for required fields. if [[ "$KERBEROS_AUTHENTICATION" == "true" ]]; then if [[ -z "$DUMPER_HOST" || -z "$DUMPER_PORT" || -z "$HIVE_KERBEROS_URL" || -z "$HIVEQL_RPC_PROTECTION" ]]; then echo "ERROR: If --kerberos-authentication is enabled, --host, --port, --hive-kerberos-url and --hiveql-rpc-protection must be provided." >&2 echo "Run with --help for more information." >&2 exit 1 fi fi # Remove trailing slashes from GCS_BASE_PATH, if any. GCS_BASE_PATH=$(echo "${GCS_BASE_PATH}" | sed 's:/*$::') # Create unique timestamp and directories for this run EPOCH=$(date +%s) LOCAL_LOG_DIR="${LOCAL_BASE_DIR}/logs" mkdir -p "${LOCAL_LOG_DIR}" # Ensures the base and logs directories exist # Define the unique log and zip file path for this run LOG_FILE="${LOCAL_LOG_DIR}/dumper_execution_${EPOCH}.log" ZIP_FILE_NAME="dts-cron-dumper-output_${EPOCH}.zip" LOCAL_ZIP_PATH="${LOCAL_BASE_DIR}/${ZIP_FILE_NAME}" echo "Script execution started. All subsequent output will be logged to: ${LOG_FILE}" # --- Helper Functions --- log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $@" >> "${LOG_FILE}"; } cleanup() { local path_to_remove="$1" log "Cleaning up local file/directory: ${path_to_remove}..." rm -rf "${path_to_remove}" } # This function is called when the script exits to ensure cleanup and logging happen reliably. handle_exit() { local exit_code=$? # Only run the failure logic if the script is exiting with an error if [[ ${exit_code} -ne 0 ]]; then log "ERROR: Script is exiting with a failure code (${exit_code})." local gcs_log_path_on_failure="${GCS_BASE_PATH}/logs/$(basename "${LOG_FILE}")" log "Uploading log file to ${gcs_log_path_on_failure} for debugging..." # Attempt to upload the log file on failure, but don't let this command cause the script to exit. gsutil cp "${LOG_FILE}" "${gcs_log_path_on_failure}" > /dev/null 2>&1 || log "WARNING: Failed to upload log file to Cloud Storage." else # SUCCESS PATH log "Script finished successfully. Now cleaning up local zip file...." # Clean up the local zip file ONLY on success cleanup "${LOCAL_ZIP_PATH}" fi log "*****Script End*****" exit ${exit_code} } # Trap the EXIT signal to run the handle_exit function, ensuring cleanup always happens. trap handle_exit EXIT # Validates the dumper log file based on a strict set of rules. validate_dumper_output() { local log_file_to_check="$1" # Check for the specific success message from the dumper tool. if grep -q "Dumper execution: SUCCEEDED" "${log_file_to_check}"; then log "Validation Successful: Found 'Dumper execution: SUCCEEDED' message." return 0 # Success else log "ERROR: Validation failed. The 'Dumper execution: SUCCEEDED' message was not found." return 1 # Failure fi } # --- Main Script Logic --- log "*****Script Start*****" log "Dumper Executable: ${DUMPER_EXECUTABLE}" log "Cloud Storage Base Path: ${GCS_BASE_PATH}" log "Local Base Directory: ${LOCAL_BASE_DIR}" # Use an array to build the command safely dumper_command_args=( "--connector" "hiveql" "--output" "${LOCAL_ZIP_PATH}" ) # Add optional arguments if they are provided if [[ -n "${DUMPER_HOST}" ]]; then dumper_command_args+=("--host" "${DUMPER_HOST}") log "Using Host: ${DUMPER_HOST}" fi if [[ -n "${DUMPER_PORT}" ]]; then dumper_command_args+=("--port" "${DUMPER_PORT}") log "Using Port: ${DUMPER_PORT}" fi if [[ -n "${HIVE_KERBEROS_URL}" ]]; then dumper_command_args+=("--hive-kerberos-url" "${HIVE_KERBEROS_URL}") log "Using Hive Kerberos URL: ${HIVE_KERBEROS_URL}" fi if [[ -n "${HIVEQL_RPC_PROTECTION}" ]]; then dumper_command_args+=("-Dhiveql.rpc.protection=${HIVEQL_RPC_PROTECTION}") log "Using HiveQL RPC Protection: ${HIVEQL_RPC_PROTECTION}" fi log "Starting dumper tool execution..." log "COMMAND: JAVA_OPTS=\"-Djavax.security.auth.useSubjectCredsOnly=false\" ${DUMPER_EXECUTABLE} ${dumper_command_args[*]}" JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" "${DUMPER_EXECUTABLE}" "${dumper_command_args[@]}" >> "${LOG_FILE}" 2>&1 log "Dumper process finished." # Validate the output from the dumper execution for success or failure. validate_dumper_output "${LOG_FILE}" # Upload the ZIP file to Cloud Storage gcs_zip_path="${GCS_BASE_PATH}/${ZIP_FILE_NAME}" log "Uploading ${LOCAL_ZIP_PATH} to ${gcs_zip_path}..." if [ ! -f "${LOCAL_ZIP_PATH}" ]; then log "ERROR: Expected ZIP file ${LOCAL_ZIP_PATH} not found after dumper execution." # The script will exit here with an error code, and the trap will run. exit 1 fi gsutil cp "${LOCAL_ZIP_PATH}" "${gcs_zip_path}" >> "${LOG_FILE}" 2>&1 log "Upload to Cloud Storage successful." # The script will now exit with code 0. The trap will call cleanup and log the script end.執行以下指令,將指令碼設為可執行狀態:
chmod +x PATH_TO_SCRIPT
使用
crontab排定指令碼的執行時間,並將變數替換為適合您工作的值。新增項目來排定工作時間。下列範例會在每天凌晨 2:30 執行指令碼:如果您在可直接存取 Hive Metastore 的主機上執行,且不需要 Kerberos 驗證,請執行下列指令:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES
如果 Hive Metastore 執行個體需要 Kerberos 驗證,請執行下列指令:
# Run the Hive dumper daily at 2:30 AM for incremental BigQuery transfer with Kerberos authentication. 30 2 * * * PATH_TO_SCRIPT \ --dumper-executable PATH_TO_DUMPER_EXECUTABLE \ --gcs-base-path GCS_PATH_TO_UPLOAD_DUMPER_OUTPUT \ --local-base-dir LOCAL_PATH_TO_SAVE_INTERMEDIARY_FILES \ --kerberos-authentication \ --host HIVE_HOST \ --port HIVE_PORT \ --hive-kerberos-url HIVE_KERBEROS_URL \ --hiveql-rpc-protection HIVEQL_RPC_PROTECTION
排程考量事項
為避免資料過時,請在排定的資料轉移時間前執行傾印工具。
建議您手動執行幾次指令碼,判斷傾印工具產生輸出內容的平均時間。請利用這個時間點設定 cron 工作排程,確保在執行移轉作業前資料更新間隔為最新狀態。
監控及查看轉移狀態
您可以監控個別資料表的資源層級轉移作業,追蹤進度、查看詳細的錯誤資訊,以及查詢正在遷移的特定資源狀態。
如要查看資源的進度和狀態,請選取下列其中一個選項:
控制台
前往 Google Cloud 控制台的「資料移轉」頁面。
從清單中點選移轉設定。
在「Transfer details」(移轉作業詳細資料) 頁面中,按一下「Tables transferred」(已移轉的資料表) 分頁標籤。
查看要移轉的資源清單。你可以查看下列詳細資料:
- 上次移轉狀態:資源的目前狀態,以最新資源移轉作業為準,包括完成進度。
- 資料表名稱:待移轉資源的名稱。按一下資源名稱,即可查看資源的詳細資料。
- 最近一次執行:上次更新資源的轉移作業。
- 狀態摘要:精細的進度指標,或轉移失敗時的錯誤訊息。
- 上次成功執行:上次成功移轉資源的執行作業。
使用篩選列依名稱搜尋特定資源,或依目前狀態篩選,例如「傳輸失敗」。「資料表名稱」篩選器支援萬用字元比對 (例如使用 *),但其他篩選器欄位不支援萬用字元比對。
API
您可以使用 BigQuery 資料移轉服務 API 查詢移轉資源的狀態。
列出所有資源及其狀態
如要列出所有資源及其狀態,請使用 projects.locations.transferConfigs.transferResources.list 方法。
使用下列資訊執行 API 要求:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources Example Response (abridged) (JSON): { "transferResources": [ { "name": "projects/.../transferResources/table1", "latestStatusDetail": { "state": "RESOURCE_TRANSFER_SUCCEEDED", "completedPercentage": 100.0 }, "updateTime": "2026-02-03T22:42:06Z" } ] }
curl 指令:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
您可以依資源名稱或狀態篩選結果。舉例來說,如要找出所有失敗的轉移作業,請在要求網址中加入 ?filter=latest_status_detail.state="RESOURCE_TRANSFER_FAILED"。
更改下列內容:
CONFIG_ID:轉移設定的 ID。LOCATION:建立轉移設定的位置。PROJECT_ID:執行轉移作業的 Google Cloud 專案 ID。
取得特定資源
如要取得特定資料表或分區的狀態,請使用 projects.locations.transferConfigs.transferResources.get 方法。
使用下列資訊執行 API 要求:
GET https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID
curl 指令:
curl -X GET
"https://bigquerydatatransfer.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/transferConfigs/CONFIG_ID/transferResources/RESOURCE_ID"
-H "Authorization: Bearer $(gcloud auth print-access-token)"
-H "Accept: application/json"
更改下列內容:
CONFIG_ID:轉移設定的 ID。LOCATION:建立轉移設定的位置。PROJECT_ID:執行轉移作業的 Google Cloud 專案 ID。RESOURCE_ID:資源的 ID,例如資料表名稱。
配額和並行限制
每次執行 BigQuery 資料移轉服務時,Hive Metastore 連接器都會為每個資料表執行一項 Storage 移轉服務工作。
配額用完後,轉移作業會等待,直到有更多配額可用為止。 Storage 移轉服務工作是在客戶專案中建立,並受儲存空間移轉服務配額和限制規範。
定價
使用 Apache Hive Metastore 連接器移轉資料不會產生費用。資料移轉完成後,系統會因您在目的地儲存資料而向您收取費用。如要瞭解詳情,請參考下列資源: