
Panoramica della preparazione dei dati di BigQuery
Puoi ridurre significativamente il tempo e lo sforzo necessari per le attività manuali sui dati utilizzando la preparazione dei dati basata sull'AI in BigQuery. La preparazione dei dati utilizza Gemini in BigQuery per analizzare i tuoi dati e fornire suggerimenti intelligenti per pulirli, trasformarli e arricchirli. Dataform pianifica queste preparazioni dei dati.
Vantaggi
- Puoi ridurre il tempo dedicato allo sviluppo della pipeline di dati con suggerimenti di trasformazione sensibili al contesto e generati da Gemini.
- Puoi convalidare i risultati generati in un'anteprima e ricevere suggerimenti per la pulizia e l'arricchimento della qualità dei dati con la mappatura automatica dello schema.
- Dataform ti consente di utilizzare un processo di integrazione continua e sviluppo continuo (CI/CD), supportando la collaborazione tra team per le revisioni del codice e il controllo del codice sorgente.
Punti di accesso alla preparazione dei dati
Puoi creare e gestire le preparazioni dei dati nella BigQuery Studio pagina (vedi Avviare una sessione di preparazione dei dati).
Quando apri una tabella nella preparazione dei dati di BigQuery, viene eseguito un job BigQuery utilizzando le tue credenziali. L'esecuzione crea righe di esempio dalla tabella scelta e scrive i risultati in una tabella temporanea nello stesso progetto. Gemini utilizza i dati e lo schema di esempio per generare suggerimenti di preparazione dei dati visualizzati nell'editor di preparazione dei dati.
Visualizzazioni nell'editor di preparazione dei dati
Le preparazioni dei dati vengono visualizzate come schede nella pagina BigQuery. Ogni scheda ha una serie di schede secondarie, o visualizzazioni di preparazione dei dati, in cui sviluppi e gestisci le preparazioni dei dati.
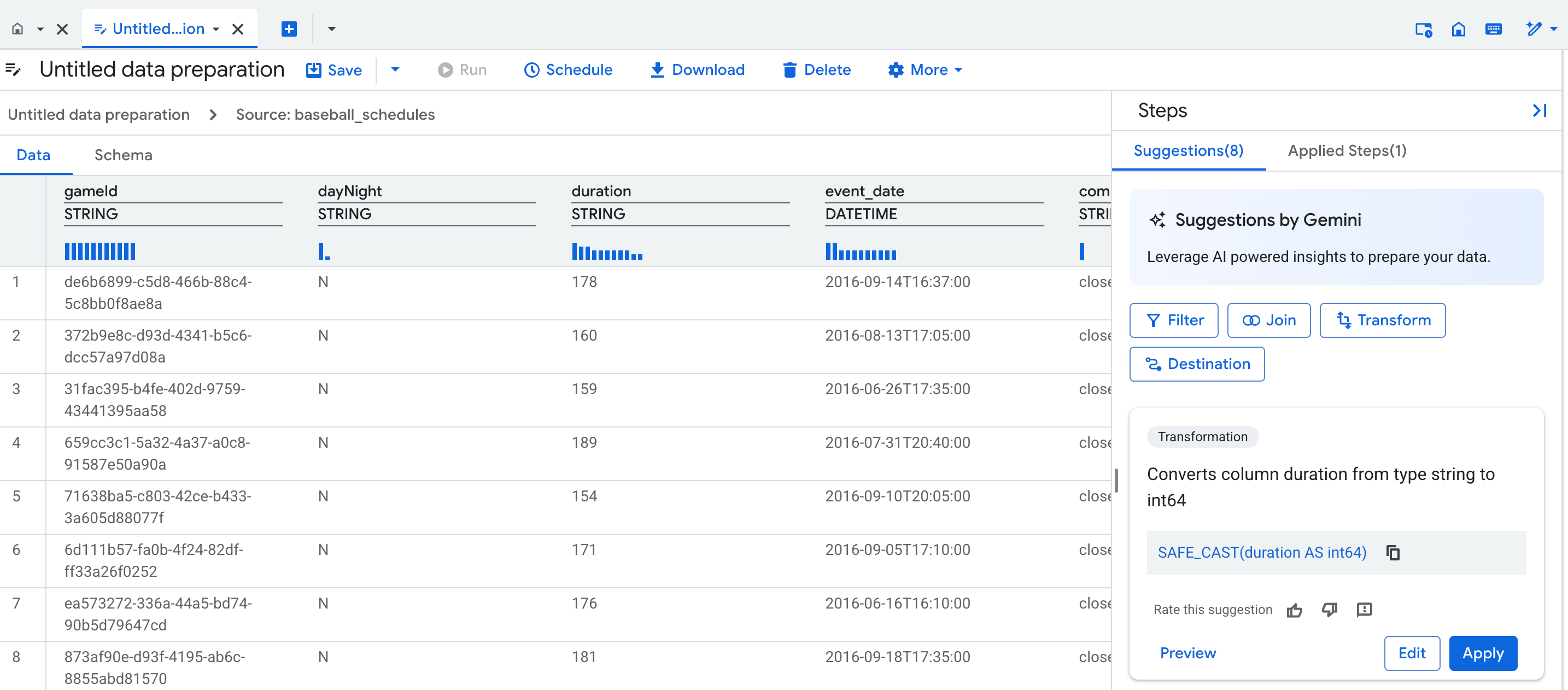
Visualizzazione dati
Quando crei una nuova preparazione dei dati, si apre una scheda dell'editor di preparazione dei dati che mostra la visualizzazione dei dati, contenente un campione rappresentativo della tabella. Per le preparazioni dei dati esistenti, puoi passare alla visualizzazione dei dati facendo clic su un nodo nella visualizzazione del grafico della pipeline di preparazione dei dati.
La visualizzazione dei dati ti consente di:
- Interagire con i dati per formare i passaggi di preparazione dei dati.
- Applicare i suggerimenti di Gemini.
- Migliorare la qualità dei suggerimenti di Gemini inserendo valori di esempio nelle celle.
Sopra ogni colonna della tabella, un profilo statistico (un istogramma) mostra il conteggio dei valori principali di ogni colonna nelle righe di anteprima.
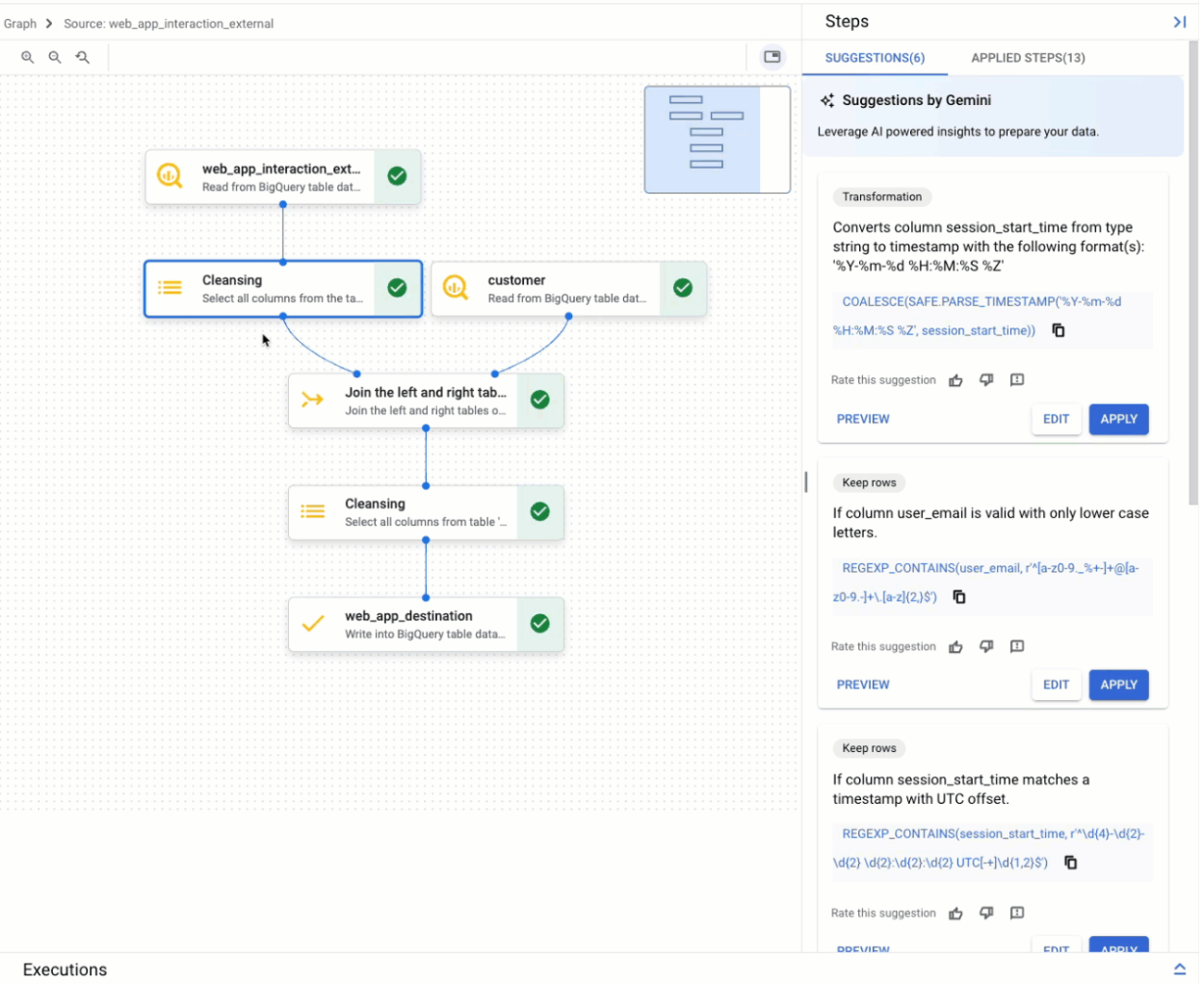
Visualizzazione grafico
La visualizzazione del grafico è una panoramica visiva della preparazione dei dati. Viene visualizzata come scheda nella pagina BigQuery della console quando apri una preparazione dei dati. Il grafico mostra i nodi per tutti i passaggi della pipeline di preparazione dei dati. Puoi selezionare un nodo nel grafico per configurare i passaggi di preparazione dei dati che rappresenta.
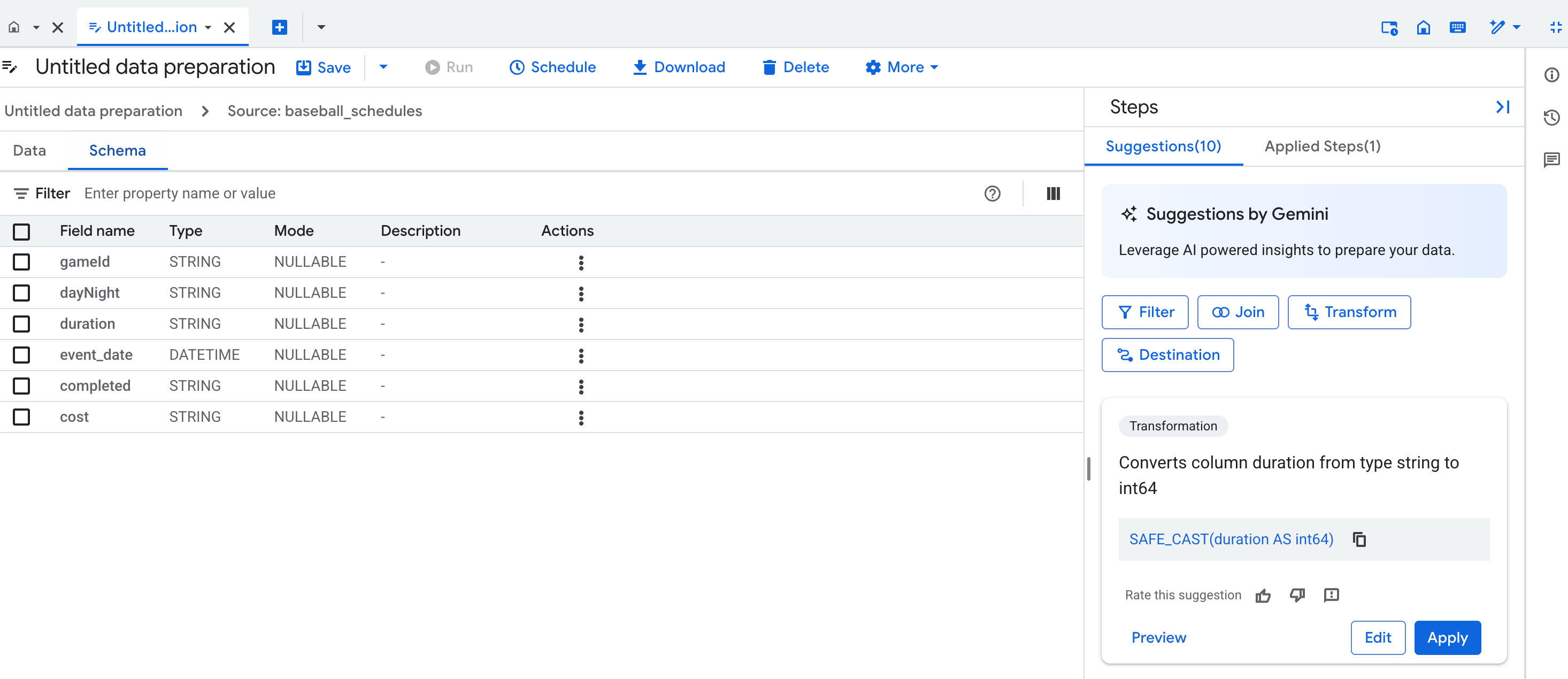
Visualizzazione schema
La visualizzazione dello schema di preparazione dei dati mostra lo schema attuale del passaggio di preparazione dei dati attivo. Lo schema mostrato corrisponde alle colonne nella visualizzazione dei dati.
Nella visualizzazione dello schema, puoi eseguire operazioni di schema dedicate, ad esempio la rimozione delle colonne, che crea anche passaggi nell'elenco Passaggi applicati.
Suggerimenti di Gemini
Gemini fornisce suggerimenti sensibili al contesto per aiutarti con le seguenti attività di preparazione dei dati:
- Applicazione di trasformazioni e regole sulla qualità dei dati
- Standardizzazione e arricchimento dei dati
- Automazione della mappatura dello schema
Ogni suggerimento viene visualizzato in una scheda nell'elenco dei suggerimenti dell'editor di preparazione dei dati. La scheda contiene le seguenti informazioni:
- La categoria di alto livello del passaggio, ad esempio Mantieni righe o Trasformazione
- Una descrizione del passaggio, ad esempio Mantieni righe se
COLUMN_NAMEnon èNULL - L'espressione SQL corrispondente utilizzata per eseguire il passaggio
Puoi visualizzare l'anteprima, modificare o applicare la scheda dei suggerimenti oppure perfezionare il suggerimento. Puoi anche aggiungere passaggi manualmente. Per saperne di più, consulta Preparare i dati con Gemini.
Per perfezionare i suggerimenti di Gemini, fornisci un esempio di cosa modificare in una colonna.
Campionamento dei dati
BigQuery utilizza il campionamento dei dati per fornire un'anteprima della preparazione dei dati. Puoi visualizzare il campione nella visualizzazione dei dati per ogni nodo.
Quando aggiungi tabelle standard di BigQuery come origine, i dati sono
preparati utilizzando una funzione
TABLESAMPLE di BigQuery. Questa funzione crea un campione di 10.000 record.
Quando aggiungi una visualizzazione o una tabella esterna come origine, il sistema legge i primi 1 milione di record. Da questi record, il sistema seleziona un campione rappresentativo di 10.000 record.
I dati nel campione non vengono aggiornati automaticamente. Le tabelle di esempio vengono archiviate come risultati di query memorizzati nella cache e scadono dopo circa 24 ore. Per aggiornare manualmente la tabella di esempio, consulta Aggiornare gli esempi di preparazione dei dati campioni.
Modalità di scrittura
Per ottimizzare i costi e il tempo di elaborazione, puoi modificare le impostazioni della modalità di scrittura per elaborare in modo incrementale i nuovi dati dall'origine. Ad esempio, se hai una tabella in BigQuery in cui i record vengono inseriti quotidianamente e una dashboard di Looker che deve riflettere i dati modificati, puoi pianificare la preparazione dei dati di BigQuery per leggere in modo incrementale i nuovi record dalla tabella di origine e propagarli alla tabella di destinazione.
Per configurare la modalità di scrittura della preparazione dei dati in una tabella di destinazione, consulta Ottimizzare la preparazione dei dati elaborando i dati in modo incrementale.
Sono supportate le seguenti modalità di scrittura:
| Opzione della modalità di scrittura | Descrizione |
|---|---|
| Aggiornamento completo | Esegue i passaggi di preparazione dei dati su tutti i dati di origine e poi ricostruisce completamente la tabella di destinazione. La tabella viene ricreata, non troncata. L'aggiornamento completo è la modalità predefinita quando si scrive in una tabella di destinazione |
| Aggiungi | Inserisce tutti i dati dalla preparazione dei dati come righe aggiuntive nella tabella di destinazione. |
| Incrementale | Inserisce solo i dati nuovi o, a seconda della scelta della colonna incrementale, modificati nella tabella di destinazione. In base alla scelta della colonna incrementale la preparazione dei dati selezionerà il meccanismo di rilevamento dei record di modifica ottimale. Seleziona i valori massimi per i tipi di dati numerici e di data/ora e i valori univoci per i dati categorici. L'opzione Valore massimo inserisce solo i record in cui il valore della colonna specificata è maggiore del valore massimo per la stessa colonna nella tabella di destinazione. L'opzione Univoco inserisce solo i record in cui i valori della colonna specificata non sono presenti nei valori esistenti per la stessa colonna nella tabella di destinazione. |
| Esegui upsert | Unisce le righe utilizzando le chiavi di unione specificate. Quando una riga esistente nella tabella di destinazione corrisponde alle chiavi di unione specificate per un record di input, i valori in questa riga vengono aggiornati nella tabella di destinazione. In caso contrario, viene inserita una nuova riga nella tabella di destinazione. |
Passaggi di preparazione dei dati supportati
BigQuery supporta i seguenti tipi di passaggi di preparazione dei dati:
| Tipo di passaggio | Descrizione |
|---|---|
| Origine | Aggiunge un'origine quando selezioni una tabella BigQuery da cui leggere da o quando aggiungi un passaggio di join. |
| Trasformazione | Pulisce e trasforma i dati utilizzando un'espressione SQL. Ricevi
schede di suggerimenti per le seguenti espressioni:
Puoi anche utilizzare qualsiasi espressione SQL BigQuery valida nei passaggi di trasformazione manuale. Ad esempio:
Per saperne di più, consulta Aggiungere una trasformazione. |
| Filtro | Rimuove le righe tramite la sintassi della clausola WHERE. Quando aggiungi un passaggio di filtro, puoi scegliere di trasformarlo in un passaggio di convalida.
Per saperne di più, consulta Filtrare le righe. |
| Deduplicate | Rimuove le righe duplicate dai dati in base alle chiavi e
all'ordinamento selezionati.
Per saperne di più, consulta Deduplicare i dati. |
| Convalida | Invia le righe che non soddisfano i criteri della regola di convalida a una tabella degli errori
Se i dati non superano la regola di convalida e non è configurata alcuna tabella degli errori, la preparazione dei dati non riesce durante l'esecuzione.
Per saperne di più, consulta Configurare la tabella degli errori e aggiungere una regola di convalida. |
| Partecipa | Unisce i valori di due origini. Le tabelle devono trovarsi nella stessa località.
Le colonne delle chiavi di join devono essere dello stesso tipo di dati. Le preparazioni dei dati
supportano le seguenti operazioni di join:
Per saperne di più, consulta Aggiungere un'operazione di join. |
| Destinazione | Definisce una destinazione per l'output dei passaggi di preparazione dei dati. Se inserisci una tabella di destinazione inesistente, la preparazione dei dati ne crea una nuova utilizzando le informazioni dello schema attuale. Per saperne di più, consulta Aggiungere o modificare una tabella di destinazione. |
| Elimina colonne | Elimina le colonne dallo schema. Esegui
questo passaggio dalla visualizzazione dello schema.
Per saperne di più, consulta Eliminare una colonna. |
Pianificare le esecuzioni di preparazione dei dati
Per eseguire i passaggi di preparazione dei dati e caricare i dati preparati nella tabella di destinazione, crea una pianificazione. Puoi pianificare le preparazioni dei dati dall'editor di preparazione dei dati e gestirle dalla pagina Pianificazione di BigQuery. Per saperne di più, consulta Pianificare le preparazioni dei dati.
Creare pipeline con attività di preparazione dei dati
Puoi creare pipeline di BigQuery composte da attività di preparazione dei dati, query SQL e notebook. Puoi quindi eseguire queste pipeline in base a una pianificazione. Per saperne di più, consulta Introduzione alle pipeline di BigQuery.
Controllo dell'accesso
Controlla l'accesso alle preparazioni dei dati utilizzando i ruoli Identity and Access Management (IAM), la crittografia con le chiavi Cloud KMS di BigQuery e Dataform e i Controlli di servizio VPC.
Ruoli e autorizzazioni IAM
Gli utenti che preparano i dati e i service account Dataform che eseguono i job richiedono le autorizzazioni IAM. Per saperne di più, consulta Ruoli richiesti e Configurare Gemini per BigQuery.
Crittografia con chiavi Cloud KMS
Cripta i dati a livello di set di dati o di progetto utilizzando le chiavi Cloud KMS gestite dal cliente predefinite in BigQuery. Per saperne di più, consulta Impostare una chiave predefinita del set di dati e Impostare una chiave predefinita del progetto.
Per impostazione predefinita, puoi criptare il codice della pipeline a livello di progetto utilizzando una chiave Cloud KMS di Dataform.
Perimetri dei Controlli di servizio VPC
Se utilizzi i Controlli di servizio VPC, devi configurare il perimetro per proteggere Dataform e BigQuery. Per saperne di più, consulta le limitazioni dei Controlli di servizio VPC per BigQuery e Dataform.
Ruolo concesso durante la creazione di una preparazione dei dati
Quando crei una preparazione dei dati, BigQuery ti concede il
ruolo di amministratore Dataform
(roles/dataform.admin) per quella preparazione dei dati. Tutti gli utenti con il
ruolo di amministratore Dataform concesso nel Google Cloud progetto hanno accesso di proprietario a tutte
le preparazioni dei dati create nel progetto. Per ignorare questo comportamento, consulta
Concedere un ruolo specifico al momento della creazione della risorsa.
Limitazioni
La preparazione dei dati è disponibile con le seguenti limitazioni:
- Tutti i set di dati di origine e di destinazione della preparazione dei dati di BigQuery di una determinata preparazione dei dati devono trovarsi nella stessa località. Per saperne di più, consulta Località.
- Durante la modifica della pipeline, i dati e le interazioni vengono inviati a un data center Gemini per l'elaborazione. Per saperne di più, consulta Località.
- Gemini in BigQuery non è supportato da Assured Workloads.
- Le preparazioni dei dati di BigQuery non supportano la visualizzazione, il confronto o il ripristino delle versioni di preparazione dei dati.
- Le risposte di Gemini si basano su un campione del set di dati che fornisci quando sviluppi la pipeline di preparazione dei dati. Per saperne di più, consulta la sezione su come Gemini for Google Cloud utilizza i tuoi dati e i termini del programma Gemini for Google Cloud Trusted Tester.
- La preparazione dei dati di BigQuery non ha una propria API. Per le API necessarie, consulta Configurare Gemini in BigQuery.
Località
I job di trattamento dati vengono eseguiti e archiviati nella località dei set di dati di origine. Se viene specificata una località del repository, deve essere la stessa dei set di dati di origine.
La regione di archiviazione del codice di preparazione dei dati può essere diversa dalla regione di esecuzione del job.
Tutti i nuovi asset di codice nel tuo Google Cloud progetto utilizzano una regione predefinita. Una volta creato l'asset, non puoi modificarne la regione.
Per impostare la regione predefinita per i nuovi asset di codice:
Vai alla pagina BigQuery.
Nel riquadro a sinistra, fai clic su File per aprire il browser dei file:
Accanto al nome del progetto, fai clic su Visualizza azioni del riquadro File > Cambia regione del codice.
Seleziona la regione del codice che vuoi utilizzare come predefinita.
Fai clic su Salva.
Per un elenco delle regioni supportate, consulta Località di BigQuery Studio.
Il trattamento dati di BigQuery durante il tempo di sviluppo e di esecuzione viene sempre eseguito nella località dei set di dati di origine. Per scoprire dove Gemini in BigQuery tratta i tuoi dati, consulta Dove Gemini in BigQuery tratta i tuoi dati.
Prezzi
L'esecuzione delle preparazioni dei dati e la creazione di campioni di anteprima dei dati utilizzano le risorse di BigQuery, che vengono addebitate alle tariffe indicate nei prezzi di BigQuery.
La preparazione dei dati è inclusa nei prezzi di Gemini in BigQuery. Puoi utilizzare la preparazione dei dati di BigQuery durante l'anteprima senza costi aggiuntivi. Per saperne di più, consulta Configurare Gemini in BigQuery.
Passaggi successivi
- Scopri come preparare i dati con Gemini in BigQuery.
- Scopri come eseguire le preparazioni dei dati manualmente o con una pianificazione.