
סקירה כללית על הכנת נתונים ב-BigQuery
אתם יכולים לצמצם באופן משמעותי את הזמן והמאמץ שנדרשים למשימות ידניות של הכנת נתונים באמצעות הכנת נתונים בעזרת AI ב-BigQuery. הכנת הנתונים מתבצעת באמצעות Gemini ב-BigQuery, שמנתח את הנתונים ומספק הצעות חכמות לניקוי, לשינוי ולהרחבה שלהם. Dataform מתזמן את הכנת הנתונים.
יתרונות
- אתם יכולים לצמצם את הזמן שמושקע בפיתוח של צינורות נתונים באמצעות הצעות להמרת נתונים שנוצרות על ידי Gemini בהתאם להקשר.
- אתם יכולים לאמת את התוצאות שנוצרו בתצוגה מקדימה ולקבל הצעות לניקוי נתונים, להעשרת נתונים ולמיפוי סכמות אוטומטי.
- Dataform מאפשר לכם להשתמש בתהליך של אינטגרציה רציפה ופיתוח רציף (CI/CD), ותומך בשיתוף פעולה בין צוותים לצורך בדיקות קוד וניהול גרסאות.
נקודות כניסה להכנת נתונים
אפשר ליצור ולנהל הכנות של נתונים בדף BigQuery Studio (ראו תחילת סשן של הכנת נתונים).
כשפותחים טבלה בהכנת נתונים ב-BigQuery, מופעלת משימה ב-BigQuery באמצעות פרטי הכניסה שלכם. ההרצה יוצרת שורות לדוגמה מהטבלה שנבחרה וכותבת את התוצאות לטבלה זמנית באותו פרויקט. Gemini משתמש בנתונים לדוגמה ובסכימה כדי ליצור הצעות להכנת הנתונים שמוצגות בכלי לעריכת הכנת הנתונים.
תצוגות בעורך של הכנת הנתונים
הכנת הנתונים מופיעה ככרטיסיות בדף BigQuery. בכל כרטיסייה יש סדרה של כרטיסיות משנה, או תצוגות של הכנת נתונים, שבהן אפשר לפתח ולנהל את ההכנות של הנתונים.
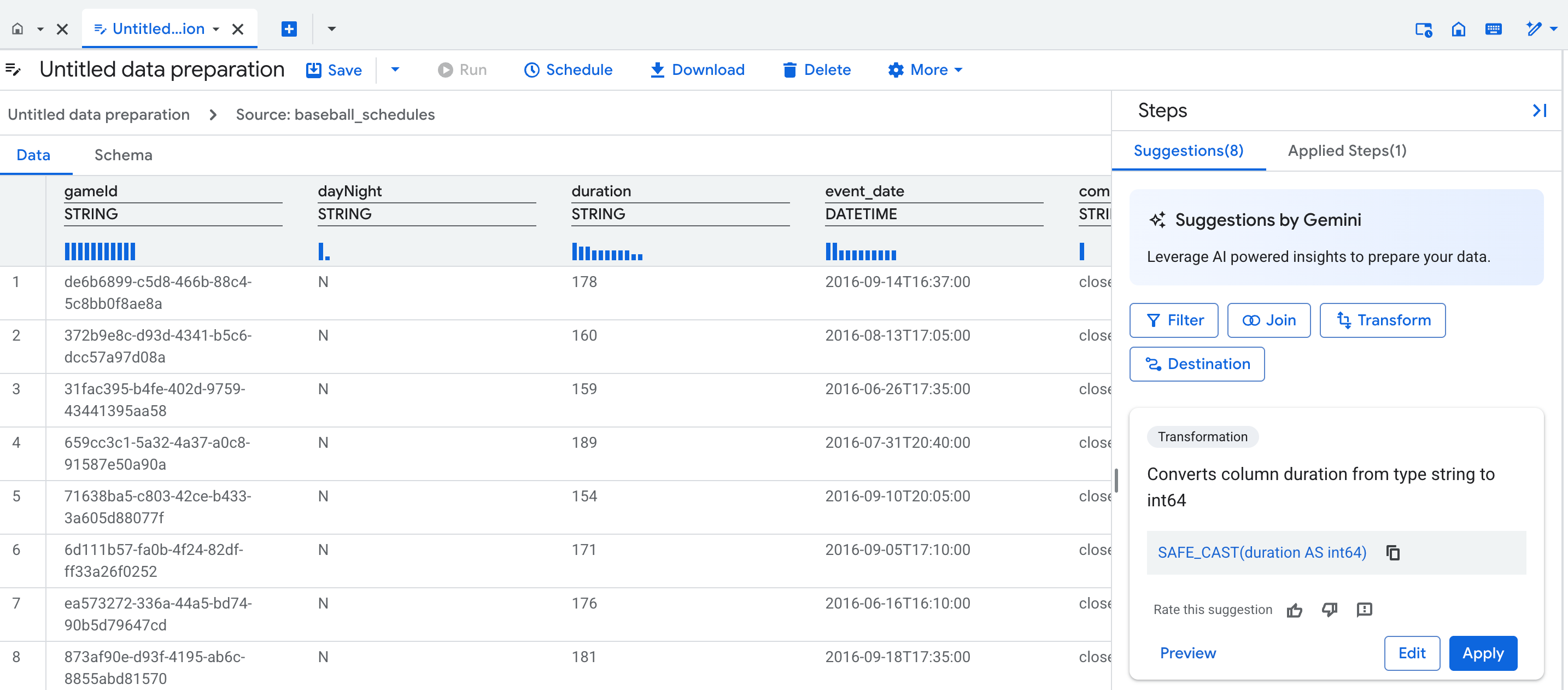
תצוגת נתונים
כשיוצרים הכנת נתונים חדשה, נפתחת כרטיסייה של עורך הכנת הנתונים, שבה מוצג תצוגת הנתונים שמכילה מדגם מייצג של הטבלה. בהכנות נתונים קיימות, אפשר לעבור לתצוגת הנתונים על ידי לחיצה על צומת בתצוגת הגרף של צינור הכנת הנתונים.
בתצוגת הנתונים אפשר:
- כדי ליצור שלבים להכנת הנתונים, צריך ליצור אינטראקציה עם הנתונים.
- יישום ההצעות של Gemini.
- כדי לשפר את איכות ההצעות של Gemini, מזינים ערכים לדוגמה בתאים.
מעל כל עמודה בטבלה מוצג פרופיל סטטיסטי (היסטוגרמה) של מספר הערכים המובילים בכל עמודה בשורות התצוגה המקדימה.
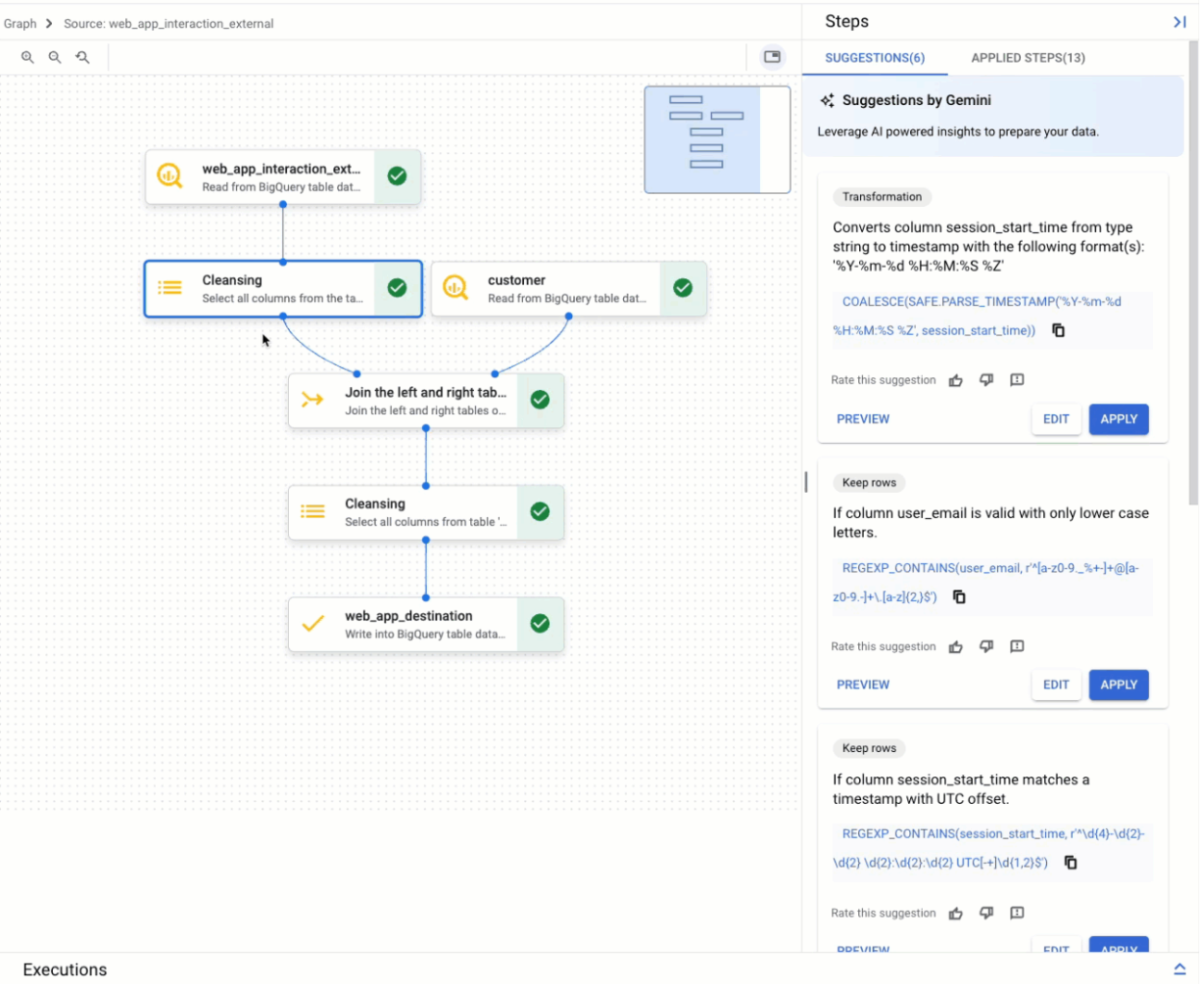
תצוגת תרשים
תצוגת התרשים היא סקירה כללית ויזואלית של הכנת הנתונים. היא מופיעה ככרטיסייה בדף BigQuery במסוף, כשפותחים הכנת נתונים. בתרשים מוצגים צמתים לכל השלבים בצינור להכנת הנתונים. אפשר לבחור צומת בתרשים כדי להגדיר את השלבים של הכנת הנתונים שהוא מייצג.
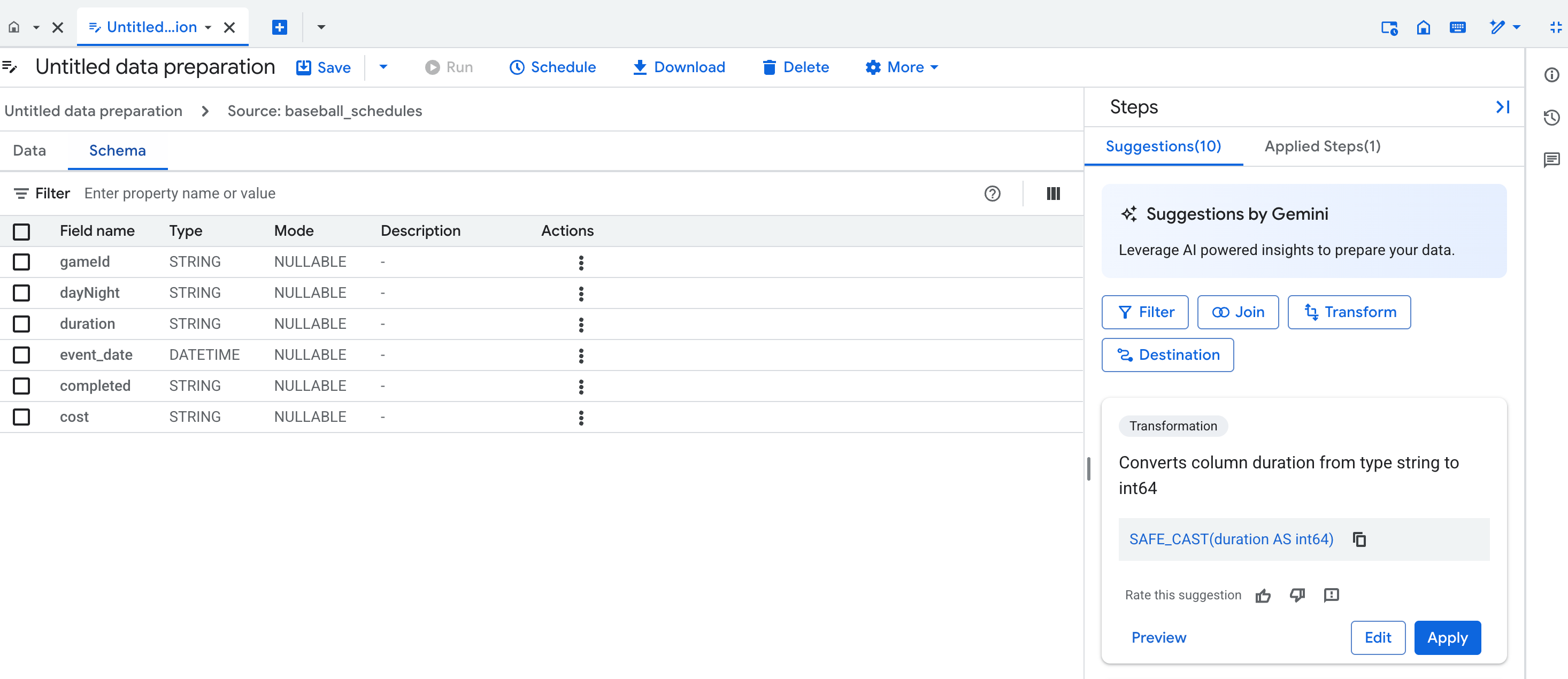
תצוגת סכימה
בתצוגת הסכימה של הכנת הנתונים מוצגת הסכימה הנוכחית של שלב הכנת הנתונים הפעיל. הסכימה שמוצגת תואמת לעמודות בתצוגת הנתונים.
בתצוגת הסכימה אפשר לבצע פעולות ייעודיות בסכימה, כמו הסרת עמודות, שיוצרת גם שלבים ברשימה Applied steps.
הצעות של Gemini
Gemini מספק הצעות בהתאם להקשר כדי לעזור במשימות הבאות של הכנת נתונים:
- החלת טרנספורמציות וכללים לאיכות הנתונים
- סטנדרטיזציה והעשרה של נתונים
- אוטומציה של מיפוי סכימה
כל הצעה מופיעה בכרטיס ברשימת ההצעות של כלי ההכנה של הנתונים. הכרטיס מכיל את הפרטים הבאים:
- הקטגוריה ברמה הגבוהה של השלב, כמו שמירת שורות או טרנספורמציה
- תיאור של השלב, למשל Keep rows if
COLUMN_NAMEis notNULL - ביטוי ה-SQL התואם שמשמש להפעלת השלב
אתם יכולים לראות תצוגה מקדימה של כרטיס ההצעה, לערוך אותו, להחיל אותו או לשפר את ההצעה. אתם יכולים גם להוסיף שלבים באופן ידני. למידע נוסף, ראו הכנת נתונים באמצעות Gemini.
כדי לשפר את ההצעות מ-Gemini, אפשר לתת לו דוגמה לשינוי שרוצים לבצע בעמודה.
דגימת נתונים
BigQuery משתמש בדגימת נתונים כדי לספק תצוגה מקדימה של הכנת הנתונים. אפשר לראות את הדוגמה בתצוגת הנתונים של כל צומת.
כשמוסיפים טבלאות סטנדרטיות של BigQuery כמקור, הנתונים מוכנים באמצעות פונקציית TABLESAMPLE של BigQuery. הפונקציה הזו יוצרת מדגם של 10,000 רשומות.
כשמוסיפים תצוגה מפורטת או טבלה חיצונית כמקור, המערכת קוראת את מיליון הרשומות הראשונות. מתוך הרשומות האלה, המערכת בוחרת מדגם מייצג של 10,000 רשומות.
הנתונים בדוגמה לא מתרעננים באופן אוטומטי. טבלאות לדוגמה נשמרות כתוצאות שאילתות במטמון והן נמחקות אחרי כ-24 שעות. כדי לרענן את הטבלה לדוגמה באופן ידני, אפשר לעיין במאמר בנושא רענון דוגמאות של הכנת נתונים.
מצב כתיבה
כדי לייעל את העלויות ואת זמן העיבוד, אפשר לשנות את הגדרות מצב הכתיבה לעיבוד מצטבר של נתונים חדשים מהמקור. לדוגמה, אם יש לכם טבלה ב-BigQuery שבה מוסיפים רשומות מדי יום, ולוח בקרה ב-Looker שצריך לשקף את הנתונים ששונו, אתם יכולים לתזמן את הכנת הנתונים ב-BigQuery כך שיקראו באופן מצטבר את הרשומות החדשות מטבלת המקור ויעבירו אותן לטבלת היעד.
כדי להגדיר את האופן שבו הכנת הנתונים נכתבת בטבלת היעד, אפשר לעיין במאמר אופטימיזציה של הכנת נתונים באמצעות עיבוד מצטבר של נתונים.
יש תמיכה במצבי הכתיבה הבאים:
| אפשרות מצב כתיבה | תיאור |
|---|---|
| רענון מלא | מבצע את שלבי הכנת הנתונים בכל נתוני המקור, ואז בונה מחדש את טבלת היעד באופן מלא. הטבלה נוצרת מחדש, ולא מתבצעת בה חיתוך. רענון מלא הוא מצב ברירת המחדל כשכותבים לטבלת יעד. |
| הוספה | כל הנתונים מהכנת הנתונים מוכנסים כשורות נוספות בטבלת היעד. |
| מצטבר | הכלי מוסיף לטבלת היעד רק את הנתונים החדשים או את הנתונים שהשתנו, בהתאם לבחירה שלכם בעמודה המצטברת. על סמך העמודה המצטברת שבחרתם, הכנת הנתונים תבחר את המנגנון האופטימלי לזיהוי רשומות שינוי. היא בוחרת ערכים מקסימליים לסוגי נתונים מספריים ולסוגי נתונים של תאריך ושעה וערכים ייחודיים לנתונים קטגוריים. האפשרות 'מקסימום הוספות' מוסיפה רק רשומות שבהן ערך העמודה שצוין גדול מהערך המקסימלי של אותה עמודה בטבלת היעד. האפשרות Unique inserts (הוספות ייחודיות) מוסיפה רק רשומות שבהן ערכי העמודות שצוינו לא מופיעים בערכים הקיימים של אותה עמודה בטבלת היעד. |
| Upsert | ממזגת שורות באמצעות מפתחות המיזוג שצוינו. כששורה קיימת בטבלת היעד תואמת למפתחות המיזוג שצוינו לרשומת קלט, הערכים בשורה הזו מתעדכנים בטבלת היעד. אחרת, שורה חדשה מוכנסת לטבלת היעד. |
שלבים נתמכים בהכנת נתונים
BigQuery תומך בסוגים הבאים של שלבים בהכנת הנתונים:
| סוג השלב | תיאור |
|---|---|
| מקור | הוספת מקור כשבוחרים טבלת BigQuery לקריאה או כשמוסיפים שלב של צירוף. |
| שינוי | מנקה ומבצע טרנספורמציה של נתונים באמצעות ביטוי SQL. אתם מקבלים כרטיסי הצעות לביטויים הבאים:
אפשר גם להשתמש בכל ביטוי SQL תקין של BigQuery בשלבי טרנספורמציה ידניים. לדוגמה:
מידע נוסף זמין במאמר הוספת טרנספורמציה. |
| מסנן | מסיר שורות באמצעות תחביר של פסקה WHERE. כשמוסיפים שלב של סינון, אפשר להפוך אותו לשלב של אימות.מידע נוסף זמין במאמר סינון שורות. |
| ביטול כפילויות | מסיר שורות כפולות מהנתונים על סמך מפתחות וסדר שנבחרו.
מידע נוסף זמין במאמר בנושא הסרת כפילויות מהנתונים. |
| אימות | שולח שורות שלא עומדות בקריטריונים של כלל התיקוף לטבלת שגיאות. אם הנתונים לא עומדים בכלל התיקוף ולא מוגדרת טבלת שגיאות, הכנת הנתונים נכשלת במהלך ההפעלה. מידע נוסף זמין במאמר הגדרת טבלת שגיאות והוספת כלל תיקוף. |
| הצטרפות | מצטרפים ערכים משני מקורות. הטבלאות צריכות להיות באותו מיקום.
העמודות של מפתח הצירוף צריכות להיות מאותו סוג נתונים. הכנת נתונים
תומכת בפעולות הצירוף הבאות:
מידע נוסף זמין במאמר בנושא הוספת פעולת איחוד. |
| יעד | הגדרה של יעד להפקת שלבים בהכנת הנתונים. אם מזינים טבלת יעד שלא קיימת, הכנת הנתונים יוצרת טבלה חדשה באמצעות פרטי הסכימה הנוכחית. מידע נוסף זמין במאמר הוספה או שינוי של טבלת יעד. |
| מחיקת עמודות | מחיקת עמודות מהסכימה. מבצעים את השלב הזה בתצוגת הסכימה.
מידע נוסף זמין במאמר מחיקת עמודה. |
תזמון הרצות של הכנת נתונים
כדי להריץ את שלבי הכנת הנתונים ולטעון את הנתונים המוכנים לטבלת היעד, צריך ליצור תזמון. אפשר לתזמן את הכנת הנתונים מכלי העריכה להכנת נתונים ולנהל אותם בדף תזמון ב-BigQuery. מידע נוסף זמין במאמר תזמון הכנת נתונים.
יצירת צינורות עיבוד נתונים עם משימות להכנת נתונים
אפשר ליצור צינורות נתונים ב-BigQuery שמורכבים ממשימות של הכנת נתונים, שאילתות SQL ומחברות עבודה. לאחר מכן אפשר להריץ את צינורות הנתונים האלה לפי לוח זמנים. מידע נוסף זמין במאמר מבוא לצינורות נתונים ב-BigQuery.
שליטה בגישה
שליטה בגישה להכנת נתונים באמצעות תפקידים בניהול זהויות והרשאות גישה (IAM), הצפנה באמצעות מפתחות Cloud KMS של BigQuery ו-Dataform, ו-VPC Service Controls.
תפקידים והרשאות של IAM
משתמשים שמכינים את הנתונים וחשבונות השירות של Dataform שמריצים את העבודות צריכים הרשאות IAM. מידע נוסף זמין במאמרים בנושא התפקידים הנדרשים והגדרת Gemini for BigQuery.
הצפנה באמצעות מפתחות Cloud KMS
הצפנת נתונים ברמת מערך הנתונים או ברמת הפרויקט באמצעות מפתחות ברירת המחדל של Cloud KMS בניהול הלקוח ב-BigQuery. מידע נוסף זמין במאמרים בנושא הגדרת מפתח ברירת מחדל למערך נתונים והגדרת מפתח ברירת מחדל לפרויקט.
אתם יכולים להצפין את קוד צינור העברת הנתונים ברמת הפרויקט כברירת מחדל באמצעות מפתח Dataform Cloud KMS.
היקפי האבטחה של VPC Service Controls
אם אתם משתמשים ב-VPC Service Controls, אתם צריכים להגדיר את היקף הגזרה כדי להגן על Dataform ועל BigQuery. מידע נוסף זמין במאמרים בנושא מגבלות של VPC Service Controls ב-BigQuery וב-Dataform.
תפקיד שמוענק כשיוצרים תהליך להכנת נתונים
כשיוצרים הכנת נתונים, מערכת BigQuery מעניקה לכם את התפקיד Dataform Admin (roles/dataform.admin) בהכנת הנתונים הזו. לכל המשתמשים שהוקצה להם תפקיד האדמין ב-Dataform בפרויקט Google Cloud יש גישת בעלים לכל ההכנות של הנתונים שנוצרו בפרויקט. כדי לשנות את ההתנהגות הזו, אפשר לקרוא את המאמר הקצאת תפקיד ספציפי בזמן יצירת משאב.
מגבלות
הכנת הנתונים זמינה עם המגבלות הבאות:
- כל מערכי הנתונים של מקור ושל יעד להכנת נתונים צריכים להיות באותו מיקום. למידע נוסף, אפשר לעיין במאמר בנושא מיקומים.
- במהלך עריכת צינורות, נתונים ואינטראקציות נשלחים למרכז נתונים של Gemini לעיבוד. מידע נוסף זמין במאמר בנושא מיקומים.
- Gemini ב-BigQuery לא נתמך על ידי Assured Workloads.
- אי אפשר לראות, להשוות או לשחזר גרסאות של הכנת נתונים ב-BigQuery.
- התשובות של Gemini מבוססות על מדגם של מערך הנתונים שאתם מספקים כשאתם מפתחים את צינור עיבוד הנתונים. למידע נוסף, אפשר לעיין במאמר בנושא איך Gemini for Google Cloud משתמש בנתונים שלכם ובתנאים של תוכנית הבודקים הנאמנים של Gemini for Google Cloud .
- ל-BigQuery Data Preparation אין API משלו. רשימת ממשקי ה-API הנדרשים מופיעה במאמר הגדרת Gemini ב-BigQuery.
מיקומים
עבודות עיבוד הנתונים מבוצעות ומאוחסנות במיקום של מערכי הנתונים של המקור. אם מציינים מיקום של מאגר, הוא חייב להיות זהה למיקום של מערכי נתוני המקור.
האזור שבו מאוחסן קוד הכנת הנתונים יכול להיות שונה מהאזור שבו מופעלת העבודה.
כל נכסי הקוד החדשים בפרויקט Google Cloud משתמשים באזור ברירת מחדל. אחרי שיוצרים את הנכס, אי אפשר לשנות את האזור שלו.
כדי להגדיר את אזור ברירת המחדל לנכסי קוד חדשים:
עוברים לדף BigQuery.
בחלונית הימנית, לוחצים על קבצים כדי לפתוח את דפדפן הקבצים:
לצד שם הפרויקט, לוחצים על View files panel actions (הצגת פעולות בחלונית הקבצים) > Switch code region (החלפת אזור הקוד).
בוחרים את אזור הקוד שרוצים להגדיר כברירת מחדל.
לוחצים על Save.
רשימת האזורים הנתמכים מופיעה במאמר בנושא מיקומים ב-BigQuery Studio.
עיבוד הנתונים ב-BigQuery במהלך הפיתוח וההפעלה מתבצע תמיד במיקום של מערכי הנתונים של המקור. כדי לדעת איפה Gemini ב-BigQuery מעבד את הנתונים שלכם, אפשר לעיין במאמר איפה Gemini ב-BigQuery מעבד את הנתונים שלכם.
תמחור
הכנת נתונים ויצירת דוגמאות לתצוגה מקדימה של נתונים כרוכות בשימוש במשאבי BigQuery, שחלים עליהם חיובים לפי התעריפים שמופיעים בתמחור של BigQuery.
הכנת הנתונים כלולה בתמחור של Gemini ב-BigQuery. אפשר להשתמש בהכנת נתונים ב-BigQuery במהלך תקופת התצוגה המקדימה ללא עלות נוספת. מידע נוסף זמין במאמר בנושא הגדרת Gemini ב-BigQuery.