
Descripción general de la preparación de datos de BigQuery
En este documento, se describe la preparación de datos mejorada por IA en BigQuery. Las preparaciones de BigQuery son recursos de BigQuery que usan Gemini en BigQuery para analizar tus datos y proporcionar sugerencias inteligentes para limpiarlos, transformarlos y enriquecerlos. Puedes reducir significativamente el tiempo y el esfuerzo necesarios para las tareas manuales de preparación de datos. La programación de las preparaciones de datos se realiza con Dataform.
Beneficios
- Puedes reducir el tiempo dedicado al desarrollo de canalizaciones de datos con sugerencias de transformación contextuales generadas por Gemini.
- Puedes validar los resultados generados en una vista previa y recibir sugerencias de limpieza y enriquecimiento de la calidad de los datos con la asignación de esquemas automatizada.
- Dataform te permite usar un proceso de integración continua y desarrollo continuo (CI/CD), que admite la colaboración entre equipos para las revisiones de código y el control de origen.
Puntos de entrada de la preparación de datos
Puedes crear y administrar preparaciones de datos en la página BigQuery Studio (consulta Inicia una sesión de preparación de datos).
Cuando abres una tabla en la preparación de datos de BigQuery, se ejecuta un trabajo de BigQuery con tus credenciales. La ejecución crea filas de muestra de la tabla elegida y escribe los resultados en una tabla temporal en el mismo proyecto. Gemini usa los datos de muestra y el esquema para generar sugerencias de preparación de datos que se muestran en el editor de preparación de datos.
Vistas en el editor de preparación de datos
Las preparaciones de datos aparecen como pestañas en la página BigQuery. Cada pestaña tiene una serie de subpestañas o vistas de preparación de datos, en las que desarrollas y administras tus preparaciones de datos.
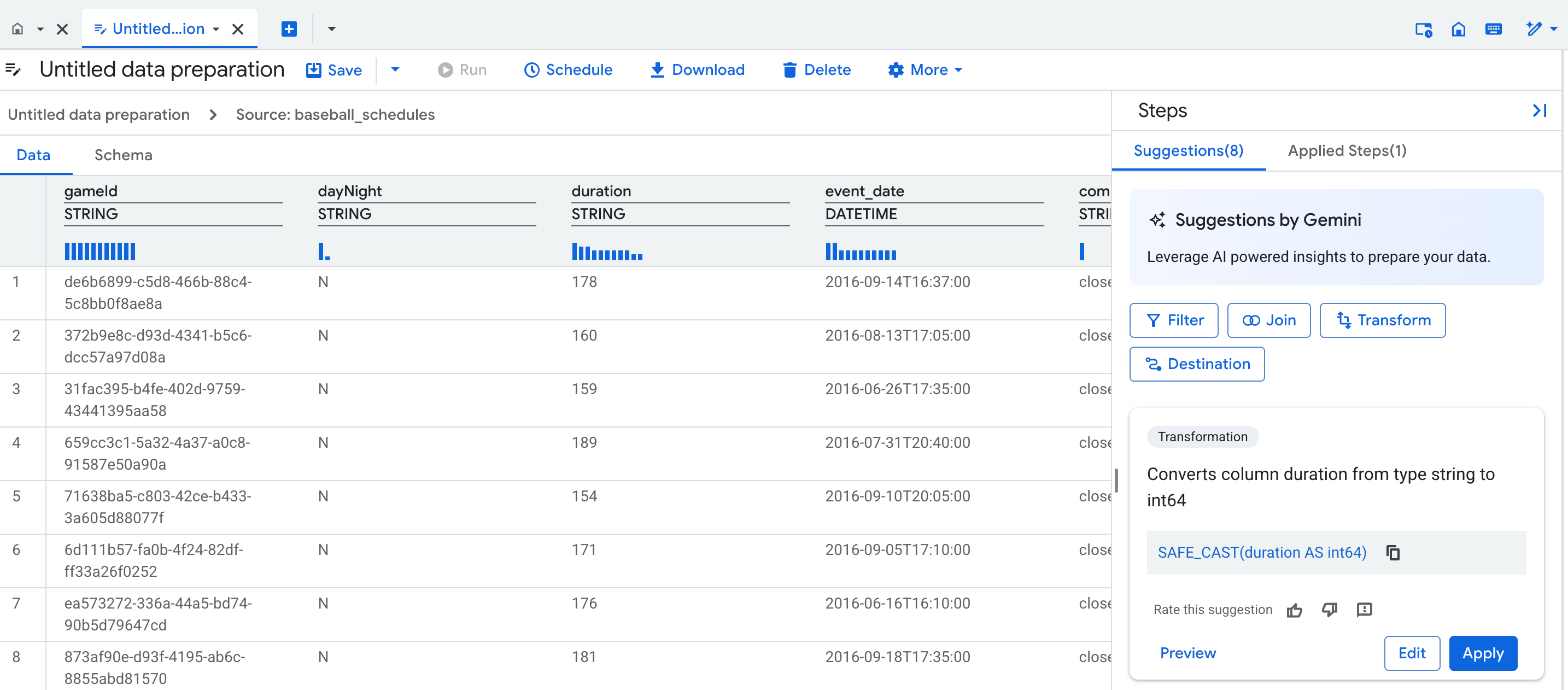
Vista de datos
Cuando creas una preparación de datos nueva, se abre una pestaña del editor de preparación de datos, que muestra la vista de datos, que contiene una muestra representativa de la tabla. Para las preparaciones de datos existentes, puedes navegar a la vista de datos haciendo clic en un nodo en la vista de gráfico de tu canalización de preparación de datos.
La vista de datos te permite hacer lo siguiente:
- Interactúa con tus datos para formar pasos de preparación de datos.
- Aplica sugerencias de Gemini.
- Mejora la calidad de las sugerencias de Gemini ingresando valores de ejemplo en las celdas.
Sobre cada columna de tu tabla, un perfil estadístico (un histograma) muestra el recuento de los valores principales de cada columna en las filas de vista previa.
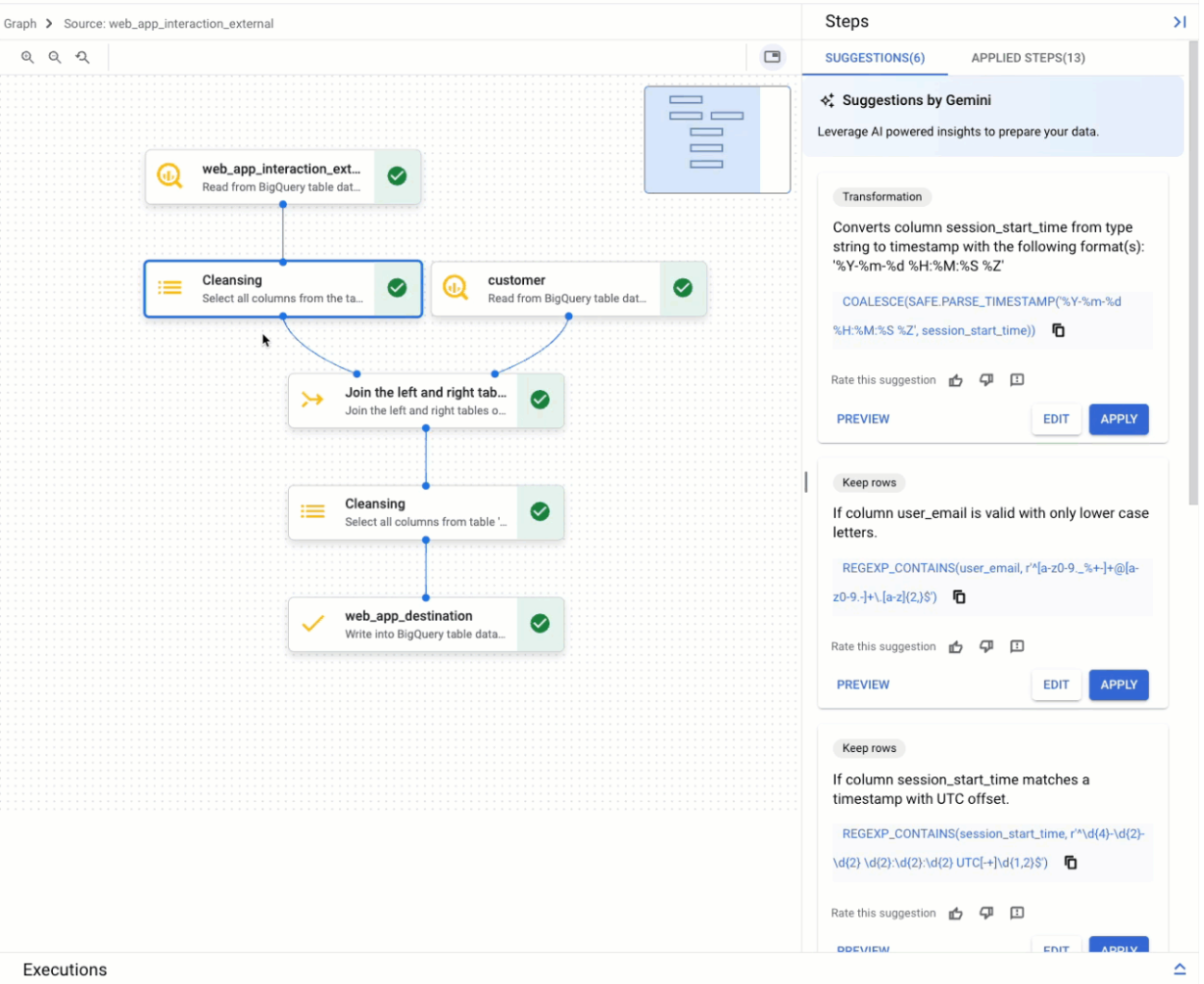
Vista de gráfico
La vista de gráfico es una descripción general visual de la preparación de datos. Aparece como una pestaña en la página BigQuery de la consola cuando abres una preparación de datos. El gráfico muestra nodos para todos los pasos de tu canalización de preparación de datos. Puedes seleccionar un nodo en el gráfico para configurar los pasos de preparación de datos que representa.
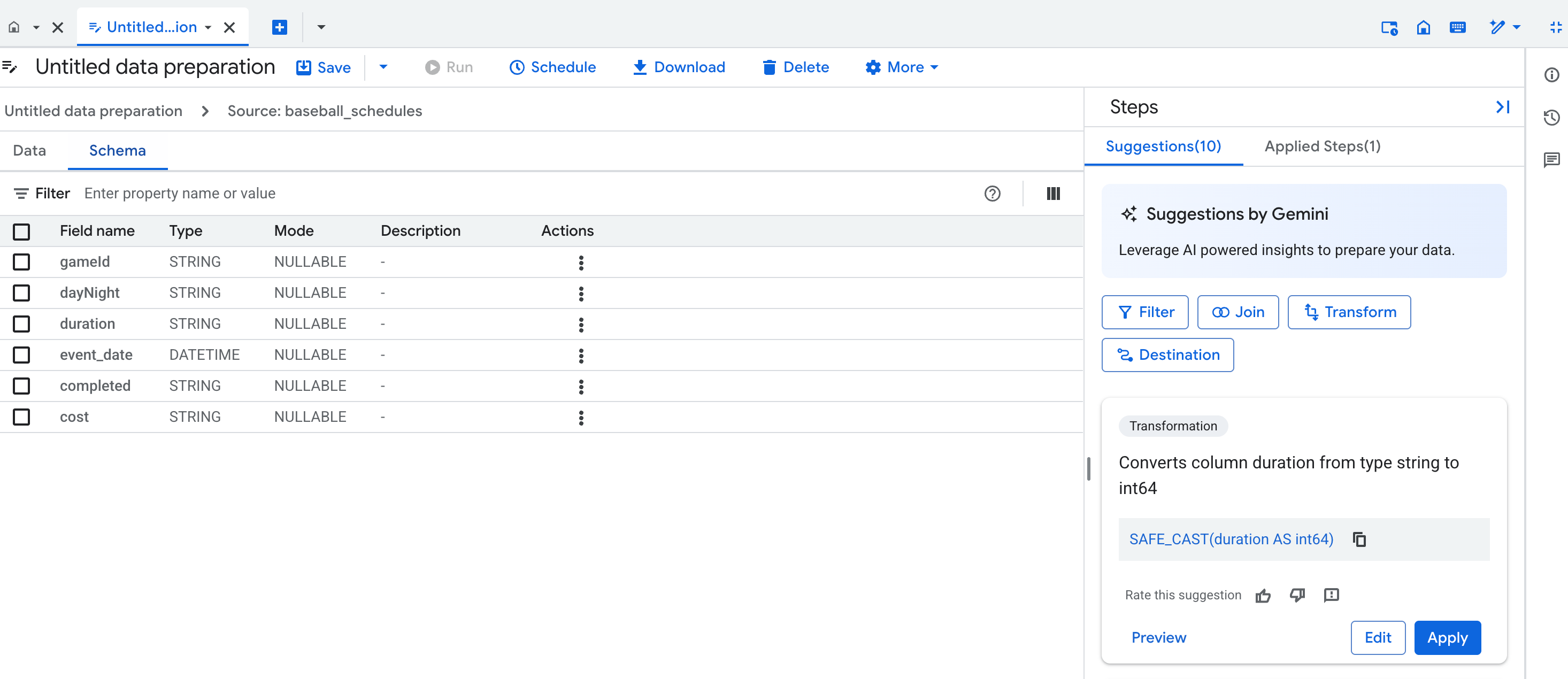
Vista de esquema
La vista de esquema de preparación de datos muestra el esquema actual del paso de preparación de datos activo. El esquema que se muestra coincide con las columnas de la vista de datos.
En la vista de esquema, puedes realizar operaciones de esquema dedicadas, como quitar columnas, lo que también crea pasos en la lista Pasos aplicados.
Sugerencias de Gemini
Gemini proporciona sugerencias contextuales para ayudar con las siguientes tareas de preparación de datos:
- Aplicar transformaciones y reglas de calidad de los datos
- Estandarizar y enriquecer datos
- Automatizar la asignación de esquemas
Cada sugerencia aparece en una tarjeta en la lista de sugerencias del editor de preparación de datos. La tarjeta contiene la siguiente información:
- La categoría de alto nivel del paso, como Conservar filas o Transformación
- Una descripción del paso, como Conservar filas si
COLUMN_NAMEno esNULL - La expresión SQL correspondiente que se usa para ejecutar el paso
Puedes obtener una vista previa, editar o aplicar la tarjeta de sugerencia, o bien ajustar la sugerencia. También puedes agregar pasos de forma manual. Para obtener más información, consulta Prepara datos con Gemini.
Para ajustar las sugerencias de Gemini, dale un ejemplo de lo que se debe cambiar en una columna.
Muestreo de datos
BigQuery usa el muestreo de datos para proporcionar una vista previa de la preparación de datos. Puedes ver la muestra en la vista de datos de cada nodo.
Cuando agregas tablas estándar de BigQuery como fuente, los datos se
preparan con una función de BigQuery
TABLESAMPLE. Esta función crea una muestra de 10,000 registros.
Cuando agregas una vista o una tabla externa como fuente, el sistema lee los primeros 1 millón de registros. A partir de estos registros, el sistema selecciona una muestra representativa de 10,000 registros.
Los datos de la muestra no se actualizan automáticamente. Las tablas de muestra se almacenan como resultados de consultas en caché y vencen en aproximadamente 24 horas. Para actualizar manualmente la tabla de muestra, consulta Actualiza las muestras de preparación de datos
Modo de escritura
Para optimizar los costos y el tiempo de procesamiento, puedes cambiar la configuración del modo de escritura para procesar de forma incremental los datos nuevos de la fuente. Por ejemplo, si tienes una tabla en BigQuery en la que se insertan registros a diario y un panel de Looker que debe reflejar los datos modificados, puedes programar la preparación de datos de BigQuery para que lea de forma incremental los registros nuevos de la tabla de origen y los propague a la tabla de destino.
Para configurar la forma en que se escribe la preparación de datos en una tabla de destino, consulta Optimiza la preparación de datos procesando datos de forma incremental.
Se admiten los siguientes modos de escritura:
| Opción de modo de escritura | Descripción |
|---|---|
| Actualización completa | Realiza los pasos de preparación de datos en todos los datos de origen y, luego, vuelve a compilar la tabla de destino por completo. La tabla se vuelve a crear, no se trunca. La actualización completa es el modo predeterminado cuando se escribe en una tabla de destino. |
| Adjunto | Inserta todos los datos de la preparación de datos como filas adicionales en la tabla de destino. |
| Incremental | Inserta solo los datos nuevos o, según la elección de la columna incremental, datos modificados en la tabla de destino. Según la elección de la columna incremental, la preparación de datos seleccionará el mecanismo óptimo de detección de registros de cambios. Elige valores máximos para los tipos de datos numéricos y de fecha y hora y valores únicos para los datos categóricos. El valor máximo inserta solo registros en los que el valor de columna especificado es mayor que el valor máximo de esta misma columna en la tabla de destino. El valor único inserta solo registros en los que los valores de columna especificados no están presentes en los valores existentes de la misma columna en la tabla de destino. |
| Actualizar o insertar | Combina filas con las claves de combinación especificadas. Cuando una fila existente en la tabla de destino coincide con las claves de combinación especificadas para un registro de entrada los valores de esta fila se actualizan en la tabla de destino. De lo contrario, se inserta una fila nueva en la tabla de destino. |
Pasos de preparación de datos admitidos
BigQuery admite los siguientes tipos de pasos de preparación de datos:
| Tipo de paso | Descripción |
|---|---|
| Fuente | Agrega una fuente cuando seleccionas una tabla de BigQuery para leer de o cuando agregas un paso de unión. |
| Transformación | Limpia y transforma datos con una expresión SQL. Recibirás
tarjetas de sugerencias para las siguientes expresiones:
También puedes usar cualquier expresión SQL de BigQuery válida en los pasos de transformación manual. Por ejemplo:
Para obtener más información, consulta Agrega una transformación. |
| Filtro | Quita filas a través de la sintaxis de la cláusula WHERE. Cuando agregas un paso de filtro, puedes elegir convertirlo en un paso de validación.
Para obtener más información, consulta Filtra filas. |
| Anulación de duplicación | Quita las filas duplicadas de los datos según las claves y el
orden seleccionados.
Para obtener más información, consulta Anula la duplicación de datos. |
| Validación | Envía las filas que no cumplen con los criterios de la regla de validación a una tabla de errores. Si los datos no cumplen con la regla de validación y no se configura ninguna tabla de errores, la preparación de datos falla durante la ejecución.
Para obtener más información, consulta Configura la tabla de errores y agrega una regla de validación. |
| Unirse | Une valores de dos fuentes. Las tablas deben estar en la misma ubicación.
Las columnas de claves de unión deben ser del mismo tipo de datos. Las preparaciones de datos
admiten las siguientes operaciones de unión:
Para obtener más información, consulta Agrega una operación de unión. |
| Destino | Define un destino para generar los pasos de preparación de datos. Si ingresas una tabla de destino que no existe, la preparación de datos crea una tabla nueva con la información del esquema actual. Para obtener más información, consulta Agrega o cambia una tabla de destino. |
| Borrar columnas | Borra columnas del esquema. Realiza
este paso desde la vista de esquema.
Para obtener más información, consulta Borra una columna. |
Programa ejecuciones de preparación de datos
Para ejecutar los pasos de preparación de datos y cargar los datos preparados en la tabla de destino, crea un programa. Puedes programar preparaciones de datos desde el editor de preparación de datos y administrarlas desde la página Programación de BigQuery. Para obtener más información, consulta Programa preparaciones de datos.
Compila canalizaciones con tareas de preparación de datos
Puedes compilar canalizaciones de BigQuery compuestas por tareas de preparación de datos, consulta en SQL y notebooks. Luego, puedes ejecutar estas canalizaciones según un programa. Para obtener más información, consulta Introducción a las canalizaciones de BigQuery.
Controle el acceso
Controla el acceso a las preparaciones de datos con los roles de Identity and Access Management (IAM), la encriptación con las claves de Cloud KMS de BigQuery y Dataform, y los Controles del servicio de VPC.
Permisos y funciones de IAM
Los usuarios que preparan los datos y las cuentas de servicio de Dataform que ejecutan los trabajos requieren permisos de IAM. Para obtener más información, consulta Roles obligatorios y Configura Gemini para BigQuery.
Encriptación con las claves de Cloud KMS
Encripta los datos a nivel del conjunto de datos o del proyecto con las claves de Cloud KMS administradas por el cliente predeterminadas en BigQuery. Para obtener más información, consulta Establece una clave predeterminada del conjunto de datos y Establece una clave predeterminada del proyecto.
Puedes encriptar el código de canalización a nivel del proyecto de forma predeterminada con una clave de Cloud KMS de Dataform.
Perímetros de los Controles del servicio de VPC
Si usas los Controles del servicio de VPC, debes configurar el perímetro para proteger Dataform y BigQuery. Para obtener más información, consulta las limitaciones de los Controles del servicio de VPC para BigQuery y Dataform.
Rol otorgado cuando se crea una preparación de datos
Cuando creas una preparación de datos, BigQuery te otorga el
rol de administrador de Dataform
(roles/dataform.admin) en esa preparación de datos. Todos los usuarios con el
rol de administrador de Dataform otorgado en el Google Cloud proyecto tienen acceso de propietario a todas
las preparaciones de datos creadas en el proyecto. Para anular este comportamiento, consulta
Otorga un rol específico cuando se crea un recurso.
Limitaciones
La preparación de datos está disponible con las siguientes limitaciones:
- Todos los conjuntos de datos de origen y destino de BigQuery de una preparación de datos determinada deben estar en la misma ubicación. Para obtener más información, consulta Ubicaciones.
- Durante la edición de la canalización, los datos y las interacciones se envían a un centro de datos de Gemini para su procesamiento. Para obtener más información, consulta Ubicaciones.
- Gemini en BigQuery no es compatible con Assured Workloads.
- Las preparaciones de datos de BigQuery no admiten la visualización, la comparación ni el restablecimiento de versiones de preparación de datos.
- Las respuestas de Gemini se basan en una muestra del conjunto de datos que proporcionas cuando desarrollas tu canalización de preparación de datos. Para obtener más información, consulta cómo Gemini para Google Cloud usa tus datos y las condiciones del programa de Verificadores de confianza de Gemini para Google Cloud .
- La preparación de datos de BigQuery no tiene su propia API. Para obtener las APIs necesarias, consulta Configura Gemini en BigQuery.
Ubicaciones
Tus trabajos de procesamiento de datos se ejecutan y almacenan en la ubicación de tus conjuntos de datos de origen. Si se especifica una ubicación del repositorio, debe ser la misma que la ubicación de los conjuntos de datos de origen.
La región de almacenamiento de código de preparación de datos puede ser diferente de la región de ejecución del trabajo.
Todos los elementos de código nuevos de tu Google Cloud proyecto usan una región predeterminada. Después de crear el elemento, no puedes cambiar su región.
Para configurar la región predeterminada de los elementos de código nuevos, haz lo siguiente:
Ve a la página de BigQuery.
En el panel izquierdo, haz clic en Archivos para abrir el navegador de archivos:
Junto al nombre del proyecto, haz clic en Ver acciones del panel de archivos > Cambiar región de código.
Selecciona la región de código que deseas usar como predeterminada.
Haz clic en Guardar.
Para obtener una lista de las regiones admitidas, consulta Ubicaciones de BigQuery Studio.
El procesamiento de datos de BigQuery durante el desarrollo y el tiempo de ejecución siempre se realiza en la ubicación de tus conjuntos de datos de origen. Para obtener información sobre dónde Gemini en BigQuery procesa tus datos, consulta Dónde Gemini en BigQuery procesa tus datos.
Precios
La ejecución de preparaciones de datos y la creación de muestras de vista previa de datos usan recursos de BigQuery, que se cobran según las tarifas que se muestran en los precios de BigQuery.
La preparación de datos se incluye en los precios de Gemini en BigQuery. Puedes usar la preparación de datos de BigQuery durante la versión preliminar sin costo adicional. Para obtener más información, consulta Configura Gemini en BigQuery.
¿Qué sigue?
- Aprende a preparar datos con Gemini en BigQuery.
- Aprende a ejecutar preparaciones de datos de forma manual o con un programa.