
Présentation des requêtes continues
Ce document décrit les requêtes continues BigQuery.
Les requêtes continues BigQuery sont des instructions SQL qui s'exécutent en continu. Elles vous permettent d'analyser les données entrantes dans BigQuery en temps réel. Vous pouvez insérer les lignes de sortie générées par une requête continue dans une table BigQuery ou les exporter vers Pub/Sub, Bigtable ou Spanner. Les requêtes continues peuvent traiter les données écrites dans les tables BigQuery standards à l'aide de l'une des méthodes suivantes :
- API BigQuery Storage Write
- La méthode
tabledata.insertAll - Chargement par lot
- Instruction LMD
INSERT - Instructions de langage de manipulation de données (LMD)
telles que
DELETE,UPDATE, etMERGElors de l'exportation de données vers Pub/Sub. - Écritures à partir des résultats d'une requête par lot dans une table permanente
- Écritures à partir des résultats d'une requête continue BigQuery dans une table permanente
- Un abonnement BigQuery Pub/Sub
- Écritures depuis Dataflow vers BigQuery
- Écritures depuis Datastream vers BigQuery à l'aide de le mode d'écriture en ajout uniquement
Vous pouvez utiliser des requêtes continues pour effectuer des tâches urgentes, telles que la création et l'action immédiate sur des insights, l'application de l'inférence de machine learning (ML) en temps réel et la réplication des données vers d'autres plates-formes. Cela vous permet d'utiliser BigQuery comme moteur de traitement de données basé sur des événements pour la logique de décision de votre application.
Le schéma suivant illustre des workflows de requêtes continues courants :
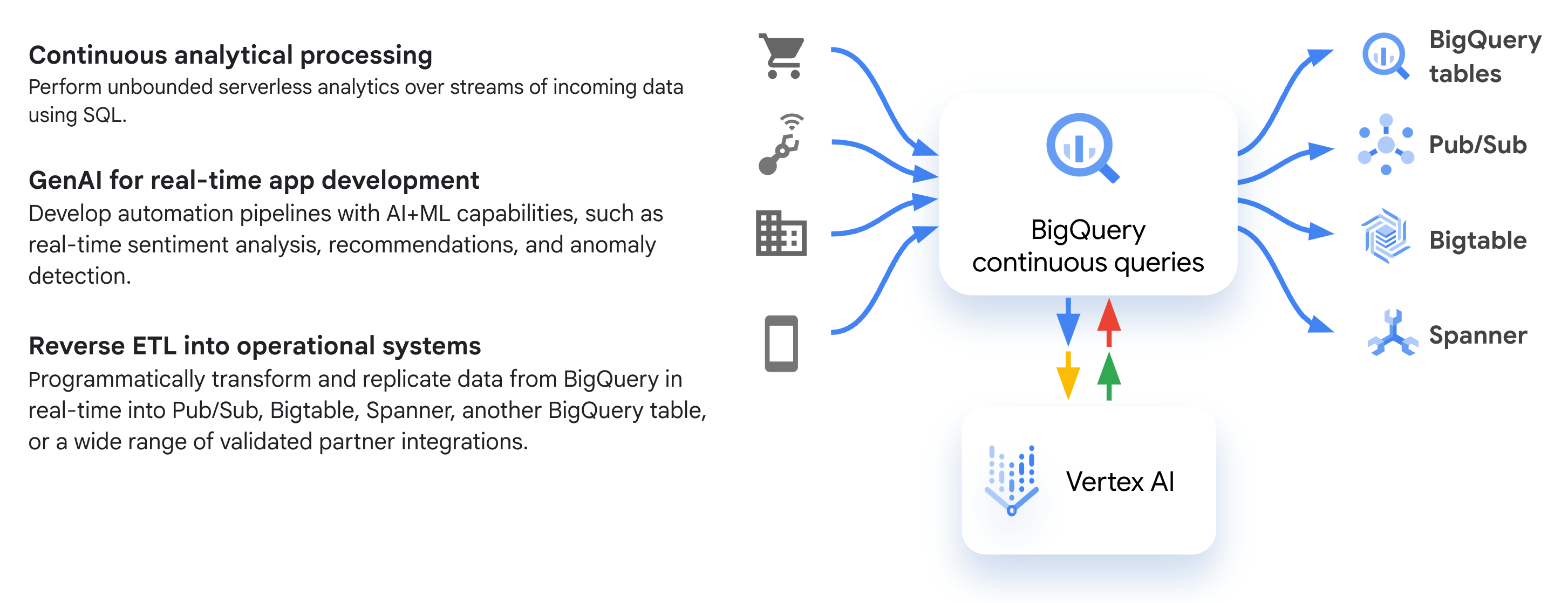
Cas d'utilisation
Voici quelques cas d'utilisation courants de requêtes continues :
- Services d'interaction personnalisés avec les clients : utilisez l'IA générative pour créer des messages sur mesure adaptés à chaque interaction client.
- Détection d'anomalies : créez des solutions vous permettant de détecter les anomalies et les menaces sur des données complexes en temps réel, afin de pouvoir réagir plus rapidement aux problèmes.
- Pipelines personnalisables basés sur des événements : utilisez l'intégration de requêtes continues avec Pub/Sub pour déclencher des applications en aval en fonction des données entrantes.
- Enrichissement des données et extraction d'entités : utilisez des requêtes continues pour effectuer l'enrichissement et la transformation des données en temps réel à l'aide de fonctions SQL et de modèles de ML.
- Opérations d'extraction, de transformation et de chargement (ETL, Extract-Transform-Load) inverses : effectuez un ETL inversé en temps réel dans d'autres systèmes de stockage plus adaptés à la diffusion d'applications à faible latence. Par exemple, analysez ou améliorez les données d'événements écrites dans BigQuery, puis importez-les par flux dans Bigtable ou Spanner pour la diffusion de l'application.
- Déclenchement autonome d'agents : déclenchez des pipelines de données agentifs en temps réel en fonction d'événements complexes détectés dans des flux de données en direct. Pour obtenir un exemple, consultez l' atelier de programmation Créer un agent de données basé sur des événements avec BigQuery et le framework Agent Development Kit (ADK).
- Surveillance autonome des agents : développez une surveillance et des alertes automatisées en temps réel pour les interactions agentives en temps réel à l'aide du plug-in BigQuery Agent Analytics, qui diffuse toutes les données de trace des agents, l'utilisation des outils et les journaux opérationnels directement dans BigQuery pour une observabilité approfondie de votre personnel d'IA.
Fonctionnalités compatibles
Les opérations suivantes sont acceptées dans les requêtes continues :
- L'exécution d'instructions
INSERTpour écrire des données issues d'une requête continue dans une table BigQuery. L'exécution d'instructions
EXPORT DATApour publier le résultat de la requête continue dans des sujets Pub/Sub. Pour en savoir plus, consultez la section Exporter les données vers Pub/Sub.À partir d'un sujet Pub/Sub, vous pouvez utiliser les données avec d'autres services, par exemple pour effectuer des analyses de flux à l'aide de Dataflow ou pour les utiliser dans un workflow d'intégration d'applications.
L'exécution d'instructions
EXPORT DATApour exporter des données depuis BigQuery vers des tables Bigtable Pour en savoir plus, consultez la section Exporter des données vers Bigtable.L'exécution d'instructions
EXPORT DATApour exporter des données depuis BigQuery vers des tables Spanner. Pour en savoir plus, consultez la section Exporter des données vers Spanner (ETL inversé).Appel des fonctions d'IA générative suivantes :
AI.GENERATE-
- Cette fonction nécessite un modèle distant BigQuery ML sur un modèle Gemini Enterprise Agent Platform.
Appel des fonctions d'IA suivantes :
Ces fonctions nécessitent un modèle distant BigQuery ML sur une API d'IA Cloud.
La normalisation des données numériques à l'aide de la
ML.NORMALIZERfonction.L'analyse et le traitement des données
JSON, y compris la prise en charge des fonctions JSON et de la suppression de l'imbrication JSON.L'utilisation de fonctions GoogleSQL sans état, telles que les fonctions de conversion. Dans les fonctions sans état, chaque ligne est traitée indépendamment des autres lignes de la table.
L'utilisation d'opérations avec état—par exemple les
JOINs, les agrégations et les agrégations de fenêtrage. Dans les opérations avec état, l'état des données ingérées est conservé sur plusieurs lignes ou intervalles de temps afin de calculer un résultat précis.L'utilisation de la
APPENDSfonction d'historique des modifications pour traiter les données ajoutées à partir d'un moment précis.L'utilisation de la
CHANGESfonction d'historique des modifications pour traiter les données modifiées, y compris les ajouts et les mutations, à partir d'un moment précis lors de l' exportation de données vers Pub/Sub. Toutefois,CHANGESn'est pas compatible avec les opérations avec état.
Opérations avec état compatibles
Pour demander de l'aide ou envoyer des commentaires concernant cette fonctionnalité, envoyez un e-mail à l'adresse bq-continuous-queries-feedback@google.com.
Les opérations avec état permettent aux requêtes continues d'effectuer des analyses complexes qui nécessitent de conserver des informations sur plusieurs lignes ou intervalles de temps. Alors que
les fonctions sans état traitent chaque ligne indépendamment, les opérations avec état conservent
l'état des données ingérées pour prendre en charge des fonctions telles que les JOINs, les agrégations et
les agrégations de fenêtrage. Cette fonctionnalité vous permet de corréler des événements provenant de différents flux ou de calculer des métriques au fil du temps (par exemple, une moyenne sur 30 minutes) en stockant les données nécessaires en mémoire pendant l'exécution de la requête.
Les requêtes continues sont compatibles avec les opérations avec état suivantes :
Autorisation
Les Google Cloud jetons d'accès utilisés lors de l'exécution de jobs de requête continue ont une valeur TTL (Time To Live) de deux jours lorsqu'ils sont générés par un compte utilisateur. Par conséquent, ces jobs cessent de s'exécuter après deux jours. Les jetons d'accès générés par les comptes de service peuvent s'exécuter plus longtemps, mais doivent toujours respecter la durée d'exécution maximale des requêtes. Pour en savoir plus, consultez la section Exécuter une requête continue à l'aide d'un compte de service.
Emplacements
Pour obtenir la liste des régions compatibles, consultez la section Emplacements des requêtes continues BigQuery.
Limites
Les requêtes continues sont soumises aux limites suivantes :
- L'état des données ingérées n'est conservé que pour les opérations avec état spécifiques
en aperçu.
Bien que les requêtes continues soient désormais compatibles avec certains types de
JOIN, d'agrégations et d'agrégations de fenêtrage, elles sont limitées à des opérations avec état spécifiques. Tous les types d'opérations avec état ne sont pas compatibles. Vous ne pouvez pas utiliser les fonctionnalités SQL suivantes dans une requête continue, sauf si elles sont répertoriées comme une opération avec état compatible :
Les opérateurs de requête suivants :
Fonctions BigQuery ML autres que celles regroupées dans la section Fonctionnalités compatibles
Instructions du langage de manipulation de données (LMD) à l'exception de
INSERT.Instructions
EXPORT DATAqui ne ciblent pas Bigtable, Pub/Sub ni Spanner.
Les requêtes continues ne sont pas compatibles avec les sources de données suivantes :
- Tables externes.
- Vues de schéma d'informations.
- Tables gérées Apache Iceberg.
- Tables génériques.
- Upsert de la capture des données modifiées (CDC)
- Vues matérialisées.
- Vues définies par d'autres limites de requêtes continues, telles que les opérations
JOIN, les fonctions d'agrégation, les fonctions définies par l'utilisateur ou les tables compatibles avec la capture des données modifiées.
Les requêtes continues ne sont pas compatibles avec les fonctionnalités de sécurité au niveau des column- et des lignes.
La sortie d'une requête continue est soumise aux quotas et limites inhérents au service de destination vers lequel elle est exportée.
Lorsque vous exportez des données vers des points de terminaison géolocalisés Bigtable, Spanner ou Pub/Sub , vous ne pouvez cibler que les ressources Bigtable, Spanner ou Pub/Sub qui se trouvent dans la même Google Cloud limite régionale que l'ensemble de données BigQuery contenant la table que vous interrogez. Cette restriction ne s'applique pas lorsque vous exportez des données vers des points de terminaison globaux Pub/Sub. Pour en savoir plus sur l'exportation vers une stratégie de routage de profil d'application Bigtable, consultez la section Considérations sur l'emplacement.
Vous ne pouvez pas exécuter de requête continue à partir d'un canevas de données.
Vous ne pouvez pas modifier le code SQL utilisé dans une requête continue pendant l'exécution du job de requête continue. Pour en savoir plus, consultez la section Modifier le code SQL d'une requête continue.
Si un job de requête continue est en retard dans le traitement des données entrantes et que le décalage du filigrane de sortie est supérieur à 48 heures, il échoue. Vous pouvez exécuter à nouveau la requête et utiliser la fonction d'historique des modifications
APPENDSouCHANGESpour reprendre le traitement à partir du moment où vous avez arrêté le job de requête continue précédent. Pour en savoir plus, consultez la section Démarrer une requête continue à partir d'un moment précis.Une requête continue configurée avec un compte utilisateur peut s'exécuter jusqu'à deux jours. Une requête continue configurée avec un compte de service peut s'exécuter jusqu'à 150 jours. Lorsque la durée d'exécution maximale de la requête est atteinte, la requête échoue et arrête le traitement des données entrantes.
Bien que les requêtes continues soient créées à l'aide des fonctionnalités de fiabilité de BigQuery, des problèmes temporaires peuvent survenir de temps en temps. Ces problèmes peuvent entraîner un certain retraitement automatique de votre requête continue, ce qui peut générer des données en double dans le résultat de la requête continue. Concevez vos systèmes en aval pour gérer de tels scénarios.
Limites de réservation
- Vous devez créer des réservations d'édition Enterprise ou Enterprise Plus pour exécuter des requêtes continues. Les requêtes continues ne sont pas compatibles avec le modèle de facturation des calculs à la demande.
- Lorsque vous créez une
CONTINUOUSattribution de réservation, la réservation associée est limitée à 500 emplacements au maximum. Vous pouvez demander une augmentation de cette limite en contactant bq-continuous-queries-feedback@google.com. - Vous ne pouvez pas créer une attribution de réservation qui utilise un type de mission différent dans la même réservation qu'une attribution de réservation de requête continue.
- Vous ne pouvez pas configurer la simultanéité des requêtes continues. BigQuery détermine automatiquement le nombre de requêtes continues pouvant être exécutées simultanément, en fonction des attributions de réservation disponibles qui utilisent le type de job
CONTINUOUS. - Lorsque vous exécutez plusieurs requêtes continues à l'aide de la même réservation, les jobs individuels peuvent ne pas répartir les ressources disponibles de manière équitable, comme défini par l'équité BigQuery.
Autoscaling des emplacements
Les requêtes continues peuvent utiliser l'autoscaling des emplacements pour adapter dynamiquement la capacité allouée à votre charge de travail. À mesure que la charge de travail de vos requêtes continues augmente ou diminue, BigQuery ajuste dynamiquement vos emplacements.
Une fois qu'une requête continue a commencé à s'exécuter, elle écoute activement les données entrantes, ce qui consomme des ressources d'emplacements. Bien qu'une réservation avec une requête continue en cours d'exécution ne soit pas réduite à zéro emplacement, une requête continue inactive qui écoute principalement les données entrantes devrait consommer une quantité minimale d'emplacements, généralement environ un emplacement.
Partage des emplacements inactifs
Les requêtes continues peuvent utiliser le partage des emplacements inactifs pour partager les ressources d'emplacements inutilisées avec d'autres réservations et types de jobs.
- Une
CONTINUOUSattribution de réservation est toujours requise pour exécuter une requête continue et ne peut pas uniquement s'appuyer sur les emplacements inactifs d'autres réservations. Par conséquent, une attribution de réservationCONTINUOUSnécessite une valeur de référence d'emplacement non nulle ou une configuration d'autoscaling d'emplacement non nulle. - Seuls les emplacements de référence inactifs ou les emplacements sur engagement d'une attribution de réservation
CONTINUOUSpeuvent être partagés. Les emplacements à autoscaling ne peuvent pas être partagés en tant qu'emplacements inactifs pour d'autres réservations.
Tarifs
Les requêtes continues peuvent utiliser le scaling fluide de BigQuery.
Les requêtes continues utilisent
les tarifs des calculs de capacité BigQuery,
exprimée en emplacements.
Pour exécuter des requêtes continues, vous devez disposer d'une réservation qui utilise l'édition Enterprise ou Enterprise Plus et d'une attribution de réservation qui utilise le type de job CONTINUOUS.
L'utilisation d'autres ressources BigQuery, comme l'ingestion et le stockage de données, est facturée selon les tarifs indiqués sur la page Tarifs de BigQuery.
L'utilisation d'autres services qui reçoivent des résultats de requêtes continues ou qui sont appelés pendant le traitement des requêtes continues est facturée selon les tarifs publiés pour ces services. Pour connaître la tarification des autres Google Cloud services utilisés par les requêtes continues, consultez les sections suivantes :
Étape suivante
Essayez de créer une requête continue.