
Introdução às consultas contínuas
Neste documento, descreveremos as consultas contínuas do BigQuery.
As consultas contínuas do BigQuery são instruções SQL executadas continuamente. As consultas contínuas permitem analisar dados recebidos no BigQuery em tempo real. É possível inserir as linhas de saída produzidas por uma consulta contínua em uma tabela do BigQuery ou exportá-las para o Pub/Sub, o Bigtable ou o Spanner. As consultas contínuas podem processar dados que foram escritos em tabelas padrão do BigQuery usando um dos seguintes métodos:
- A API BigQuery Storage Write
- O método
tabledata.insertAll - Carregamento em lote
- A instrução DML
INSERT - Como modificar instruções de linguagem de manipulação de dados (DML)
como
DELETE,UPDATEeMERGEao exportar dados para o Pub/Sub. - Gravações dos resultados de uma consulta em lote em uma tabela permanente
- Gravações dos resultados de uma consulta contínua do BigQuery em uma tabela permanente
- Uma assinatura do Pub/Sub BigQuery
- Gravações do Dataflow para o BigQuery
- Gravações do Datastream para o BigQuery usando o modo de gravação somente anexar
Você pode usar consultas contínuas para realizar tarefas urgentes, como criar insights e agir imediatamente com base neles aplicando a inferência de machine learning (ML) em tempo real e a replicação de dados em outras plataformas. Dessa forma, você pode usar o BigQuery como um dispositivo de tratamento de dados orientado a eventos para a lógica de decisão do aplicativo.
O diagrama a seguir mostra fluxos de trabalho comuns de consulta contínua:
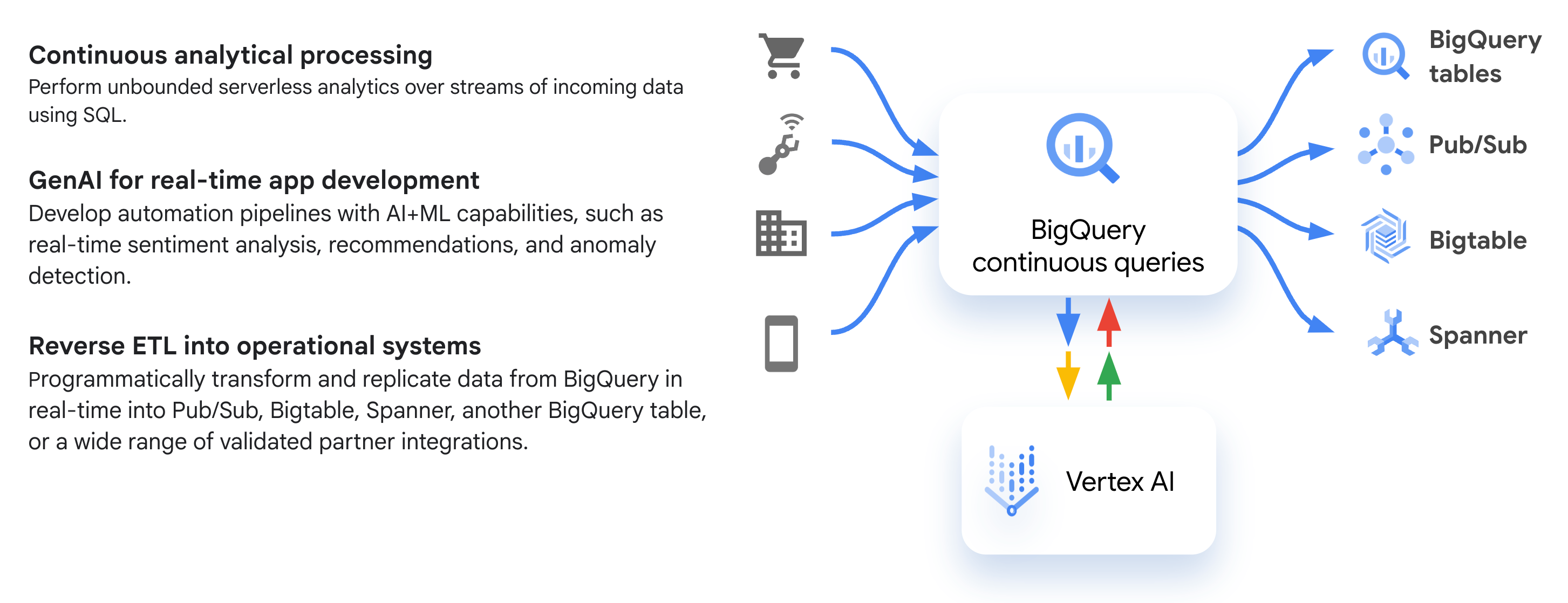
Casos de uso
Veja alguns casos de uso comuns em que convém usar consultas contínuas:
- Serviços personalizados de interação com o cliente: use a IA generativa para criar mensagens personalizadas para cada interação com o cliente.
- Detecção de anomalias: crie soluções que permitam realizar detecção de anomalias e ameaças em dados complexos em tempo real, para que você possa reagir a problemas mais rapidamente.
- Pipelines personalizáveis baseados em eventos: use a integração de consulta contínua com o Pub/Sub para acionar aplicativos downstream com base nos dados recebidos.
- Aprimoramento de dados e extração de entidades: use consultas contínuas para realizar aprimoramento e transformação de dados em tempo real usando funções SQL e modelos de ML.
- ETL (extrair, transformar e carregar) reverso: execute ETL reverso em tempo real em outros sistemas de armazenamento mais adequados para veiculação de aplicativos de baixa latência. Por exemplo: analisar ou aprimorar dados de eventos gravados no BigQuery; e, em seguida, fazer streaming para o Bigtable ou o Spanner para veiculação do aplicativo.
- Acionamento autônomo de agentes: acione pipelines de dados agênticos em tempo real com base em eventos complexos detectados em fluxos de dados ativos. Para conferir um exemplo, consulte o codelab Criar um agente de dados orientado por eventos com o BigQuery e o Kit de Desenvolvimento de Agente (ADK, na sigla em inglês).
- Monitoramento autônomo de agentes: desenvolva monitoramento e alertas automatizados em tempo real para interações agênticas em tempo real usando o plug-in de análise de agentes do BigQuery, que transmite todos os dados de rastreamento de agentes, uso de ferramentas e registros operacionais diretamente para o BigQuery para observabilidade detalhada da sua força de trabalho de IA.
Funcionalidade compatível
As seguintes operações são aceitas em consultas contínuas:
- Execução de
instruções
INSERTpara gravar dados a partir de uma consulta contínua em uma tabela do BigQuery. Execução de instruções
EXPORT DATApara publicar a saída de consultas contínuas em tópicos do Pub/Sub. Para mais informações, consulte Exportar dados para o Pub/Sub.A partir de um tópico do Pub/Sub, é possível usar os dados com outros serviços, como análise de streaming usando o Dataflow, ou usando os dados em um fluxo de trabalho de integração de aplicativos.
Execução de instruções
EXPORT DATApara exportar dados do BigQuery para tabelas Bigtable. Para mais informações, consulte Exportar dados para o Bigtable.Execução de instruções
EXPORT DATApara exportar dados do BigQuery para tabelas do Spanner. Para mais informações, consulte Exportar dados para o Spanner (ETL reverso).Chamando as seguintes funções de IA generativa:
AI.GENERATE-
- Essa função exige que você tenha um modelo remoto de ML do BigQuery em um modelo da plataforma de agentes do Gemini Enterprise.
Chamar as seguintes funções de IA:
Essas funções exigem que você tenha um modelo remoto de ML do BigQuery em uma API Cloud AI.
Normalizar dados numéricos usando a
ML.NORMALIZERfunção.Analisar e processar
JSONdados, incluindo suporte para funções JSON e desaninhamento JSON.Usar funções do GoogleSQL sem estado, por exemplo, funções de conversão. Em funções sem estado, cada linha é processada independentemente de outras linhas na tabela.
Usar operações com estado, por exemplo,
JOINs, agregações e agregações de janelas. Em operações com estado, o estado dos dados ingeridos é mantido em várias linhas ou intervalos de tempo para calcular um resultado preciso.Usar a
APPENDSfunção do histórico de alterações para processar dados anexados de um momento específico.Usar a
CHANGESfunção do histórico de alterações para processar dados alterados, incluindo anexos e mutações, de um momento específico ao exportar dados para o Pub/Sub. No entanto,CHANGESnão é compatível ao usar uma operação com estado.
Operações com estado compatíveis
Para solicitar suporte ou enviar feedback sobre esse recurso, envie um e-mail para bq-continuous-queries-feedback@google.com.
As operações com estado permitem que consultas contínuas realizem análises complexas que exigem a retenção de informações em várias linhas ou intervalos de tempo. Enquanto
as funções sem estado processam cada linha de forma independente, as operações com estado mantêm
o estado dos dados ingeridos para oferecer suporte a funções como JOINs, agregações e
agregações de janelas. Esse recurso permite correlacionar eventos de diferentes streams ou calcular métricas ao longo do tempo, como uma média de 30 minutos, armazenando os dados necessários na memória enquanto a consulta é executada.
As consultas contínuas oferecem suporte às seguintes operações com estado:
Autorização
Os Google Cloud tokens de acesso usados ao executar jobs de consulta contínua têm um time to live (TTL) de dois dias quando são gerados por uma conta de usuário. Portanto, esses jobs param de ser executados após dois dias. Os tokens de acesso gerados por contas de serviço podem ser executados por mais tempo, mas ainda precisam obedecer ao tempo máximo de execução da consulta. Para mais informações, consulte Executar uma consulta contínua usando uma conta de serviço.
Locais
Para conferir uma lista de regiões com suporte, consulte Locais de consultas contínuas do BigQuery.
Limitações
As consultas contínuas estão sujeitas às seguintes limitações:
- O estado dos dados ingeridos é mantido apenas para as operações com estado específicas na visualização.
Embora as consultas contínuas agora ofereçam suporte a alguns tipos de
JOINs, agregações e agregações de janelas, elas são restritas a operações com estado específicas. Nem todos os tipos de operações com estado são compatíveis. Não é possível usar os seguintes recursos do SQL em uma consulta contínua, a menos que eles sejam listados como uma operação com estado compatível:
Os seguintes operadores de consulta:
Operadores de conjunto de consulta
Funções do BigQuery ML que não sejam as listadas em Funcionalidade compatível
Instruções de linguagem de definição de dados (DDL, na sigla em inglês)
Instruções de linguagem de manipulação de dados (DML, na sigla em inglês) exceto
INSERT.Instruções de linguagem de controle de dados (DCL, na sigla em inglês)
Instruções
EXPORT DATAque não segmentam o Bigtable, o Pub/Sub ou o Spanner.
As consultas contínuas não oferecem suporte às seguintes fontes de dados:
- Tabelas externas.
- Visualizações de esquema de informações.
- Tabelas gerenciadas do Apache Iceberg.
- Tabelas curinga.
- Dados de upsert de captura de dados alterados (CDC)
- Visualizações materializadas.
- Visualizações definidas por outras limitações de consulta contínua, como operações
JOIN, funções agregadas, funções definidas pelo usuário ou tabelas ativadas para captura de dados de mudança.
As consultas contínuas não oferecem suporte aos recursos de segurança no nível da column- e da linha.
A saída de uma consulta contínua está sujeita às cotas e limites inerentes do serviço de destino para o qual a saída está sendo exportada.
Ao exportar dados para endpoints de localização do Bigtable, do Spanner ou do Pub/Sub , só é possível segmentar recursos do Bigtable, do Spanner ou do Pub/Sub que se enquadram no mesmo Google Cloud limite regional do conjunto de dados do BigQuery que contém a tabela que você está consultando. Essa restrição não se aplica ao exportar dados para endpoints globais do Pub/Sub. Para mais informações sobre como exportar para uma política de roteamento de perfil de aplicativo do Bigtable, consulte Considerações sobre o local.
Não é possível executar uma consulta contínua em uma tela de dados.
Não é possível modificar o SQL usado em uma consulta contínua enquanto o job da consulta contínua está em execução. Para mais informações, consulte Modificar o SQL de uma consulta contínua.
Se um job de consulta contínua ficar atrasado no processamento de dados recebidos e tiver um atraso de marca d'água de saída de mais de 48 horas, ele falhará. É possível executar a consulta novamente e usar a função do histórico de alterações
APPENDSouCHANGESpara retomar o processamento a partir do momento em que você interrompeu o job de consulta contínua anterior. Para mais informações, consulte Iniciar uma consulta contínua de um momento específico.Uma consulta contínua configurada com uma conta de usuário pode ser executada por até dois dias. Uma consulta contínua configurada com uma conta de serviço pode ser executada por até 150 dias. Quando o tempo máximo de execução da consulta é atingido, a consulta falha e interrompe o processamento de dados recebidos.
Embora as consultas contínuas sejam criadas usando BigQuery recursos de confiabilidade, problemas temporários ocasionais podem ocorrer. Os problemas podem levar a algum tipo de reprocessamento automático da consulta contínua, o que pode resultar em dados duplicados na saída da consulta contínua. Projete seus sistemas downstream para lidar com esses cenários.
Limitações de reserva
- Você precisa criar reservas da edição Enterprise ou da edição Enterprise Plus para executar consultas contínuas. As consultas contínuas não aceitam o modelo de faturamento de computação on demand.
- Quando você cria uma
CONTINUOUSatribuição de reserva, a reserva associada é limitada a no máximo 500 slots. Você pode solicitar um aumento desse limite entrando em contato com bq-continuous-queries-feedback@google.com. - Não é possível criar uma atribuição de reserva que usa um tipo de trabalho diferente na mesma reserva como uma atribuição de reserva de consulta contínua.
- Não é possível configurar a simultaneidade de consultas contínuas. O BigQuery
determina automaticamente o número de consultas contínuas que podem ser executadas
simultaneamente, com base nas atribuições de reserva disponíveis que usam o tipo de job
CONTINUOUS. - Ao executar várias consultas contínuas usando a mesma reserva, jobs individuais podem não dividir os recursos disponíveis de maneira justa, já que são definidos pela imparcialidade do BigQuery.
Escalonamento automático de slots
As consultas contínuas podem usar o escalonamento automático de slots para escalonar dinamicamente a capacidade alocada para acomodar sua carga de trabalho. À medida que a carga de trabalho de consultas contínuas aumenta ou diminui, o BigQuery ajusta dinamicamente os slots.
Depois que uma consulta contínua começa a ser executada, ela detecta ativamente os dados recebidos, o que consome recursos de slot. Embora uma reserva com uma consulta contínua em execução não seja reduzir escala vertical para zero slots, espera-se que uma consulta contínua inativa que esteja principalmente detectando dados recebidos consuma uma quantidade mínima de slots, normalmente cerca de 1 slot.
Compartilhamento de slots inativos
As consultas contínuas podem usar o compartilhamento de slots inativos para compartilhar recursos de slot não utilizados com outras reservas e tipos de job.
- Uma
CONTINUOUSatribuição de reserva ainda é necessária para executar uma consulta contínua e não pode depender apenas de slots inativos de outras reservas. Portanto, uma atribuição de reservaCONTINUOUSexige uma linha de base de slot diferente de zero ou uma configuração de escalonamento automático de slot diferente de zero. - Somente slots de linha de base inativos ou slots confirmados de uma atribuição de reserva
CONTINUOUSpodem ser compartilhados. Os slots com escalonamento automático não podem ser compartilhados como slots inativos para outras reservas.
Preços
As consultas contínuas podem usar o escalonamento fluido do BigQuery.
As consultas contínuas usam
Preços de computação de capacidade do BigQuery,
que são medidos em slots.
Para executar consultas contínuas, é preciso ter uma
reserva que use a
edição Enterprise ou Enterprise Plus
e uma atribuição de reserva
que usa o tipo de job CONTINUOUS.
O uso de outros recursos do BigQuery, como ingestão de dados e armazenamento, é cobrado conforme as taxas mostradas nos Preços do BigQuery.
O uso de outros serviços que recebem resultados de consulta contínua ou que são chamados durante o processamento de consultas é cobrado de acordo com as taxas publicadas para esses serviços. Para os preços de outros Google Cloud serviços usados pelas consultas contínuas, consulte os seguintes tópicos:
A seguir
Tente criar uma consulta contínua.