
Introduzione alle query continue
Questo documento descrive le query continue di BigQuery.
Le query continue di BigQuery sono istruzioni SQL eseguite ininterrottamente. Le query continue ti consentono di analizzare i dati in arrivo in BigQuery in tempo reale. Puoi inserire le righe di output prodotte da una query continua in una tabella BigQuery o esportarle in Pub/Sub, Bigtable o Spanner. Le query continue possono elaborare i dati scritti nelle tabelle BigQuery standard utilizzando uno dei seguenti metodi:
- L'API BigQuery Storage Write
- Il metodo
tabledata.insertAll - Caricamento in batch
- L'istruzione DML
INSERT - Istruzioni Data Manipulation Language (DML) di mutazione
come
DELETE,UPDATEeMERGEdurante l'esportazione dei dati in Pub/Sub. - Scrive i risultati di una query batch in una tabella permanente
- Scrive i risultati di una query continua BigQuery in una tabella permanente.
- Una sottoscrizione Pub/Sub BigQuery
- Scritture da Dataflow a BigQuery
- Scritture da Datastream a BigQuery utilizzando la modalità di scrittura di sola aggiunta
Puoi utilizzare le query continue per eseguire attività sensibili al tempo, ad esempio creare insight e agire immediatamente in base a questi, applicare l'inferenza di machine learning (ML) in tempo reale e replicare i dati in altre piattaforme. In questo modo, puoi utilizzare BigQuery come motore di elaborazione dei dati basato su eventi per la logica decisionale della tua applicazione.
Il seguente diagramma mostra i flussi di lavoro comuni per le query continue:
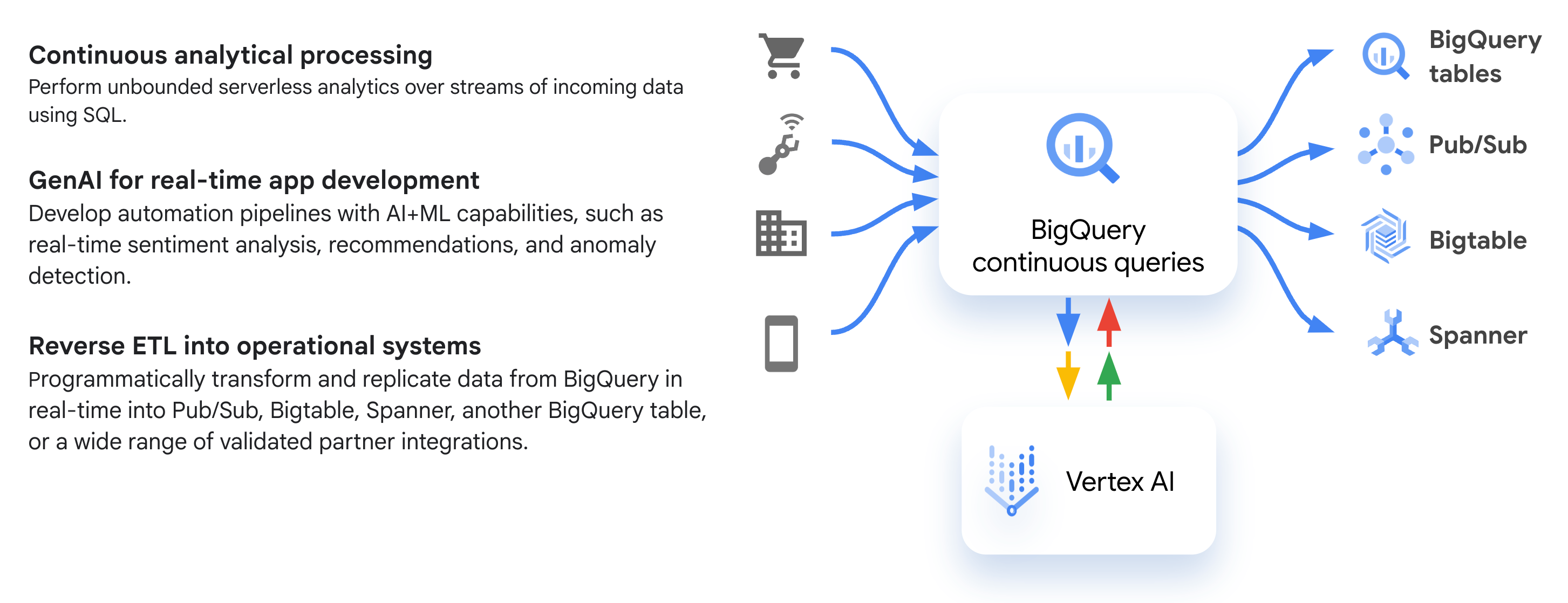
Casi d'uso
Ecco alcuni casi d'uso comuni in cui potresti voler utilizzare le query continue:
- Servizi di interazione con i clienti personalizzati: utilizza l'AI generativa per creare messaggi personalizzati per ogni interazione con i clienti.
- Rilevamento delle anomalie: crea soluzioni che ti consentono di eseguire il rilevamento di anomalie e minacce su dati complessi in tempo reale, in modo da poter reagire più rapidamente ai problemi.
- Pipeline basate su eventi personalizzabili: utilizza l'integrazione di query continua con Pub/Sub per attivare applicazioni downstream in base ai dati in entrata.
- Arricchimento dei dati ed estrazione delle entità: utilizza query continue per eseguire l'arricchimento e la trasformazione dei dati in tempo reale utilizzando funzioni SQL e modelli di machine learning.
- Estrazione, trasformazione e caricamento (ETL) inverso: esegui l'ETL inverso in tempo reale in altri sistemi di archiviazione più adatti per il servizio di applicazioni a bassa latenza. Ad esempio, analizza o migliora i dati degli eventi scritti in BigQuery e poi trasmettili in streaming a Bigtable o Spanner per il servizio di applicazioni.
- Attivazione autonoma degli agenti: attiva pipeline di dati agentiche in tempo reale in base a eventi complessi rilevati nei flussi di dati live. Per un esempio, consulta il codelab Crea un agente di dati basato su eventi con BigQuery e Agent Development Kit (ADK).
- Monitoraggio autonomo degli agenti: sviluppa il monitoraggio e gli avvisi automatizzati in tempo reale per le interazioni agentiche in tempo reale utilizzando il plug-in di analisi degli agenti BigQuery, che trasmette in streaming tutti i dati di traccia degli agenti, l'utilizzo degli strumenti e i log operativi direttamente in BigQuery per una visibilità approfondita della tua forza lavoro AI.
Funzionalità supportata
Le seguenti operazioni sono supportate nelle query continue:
- Esecuzione di istruzioni
INSERTper scrivere i dati di una query continua in una tabella BigQuery. Esecuzione di istruzioni
EXPORT DATAper pubblicare l'output della query continua negli argomenti Pub/Sub. Per maggiori informazioni, consulta Esporta dati in Pub/Sub.Da un argomento Pub/Sub, puoi utilizzare i dati con altri servizi, ad esempio eseguire l'analisi dei flussi di dati utilizzando Dataflow o utilizzare i dati in un flusso di lavoro di integrazione delle applicazioni.
Esecuzione di istruzioni
EXPORT DATAper esportare i dati da BigQuery alle tabelle Bigtable. Per saperne di più, consulta Esportare dati in Bigtable.Esecuzione di istruzioni
EXPORT DATAper esportare i dati da BigQuery alle tabelle Spanner. Per saperne di più, consulta Esportare i dati in Spanner (ETL inversa).Chiamata delle seguenti funzioni di AI generativa:
AI.GENERATE-
- Questa funzione richiede un modello remoto BigQuery ML su un modello Gemini Enterprise Agent Platform.
Chiamata delle seguenti funzioni di AI:
Queste funzioni richiedono un modello remoto BigQuery ML tramite un'API Cloud AI.
Normalizzare i dati numerici utilizzando la funzione
ML.NORMALIZER.Analisi ed elaborazione dei dati
JSON, incluso il supporto per le funzioni JSON e l'annidamento JSON.Utilizzo di funzioni GoogleSQL stateless, ad esempio funzioni di conversione. Nelle funzioni stateless, ogni riga viene elaborata indipendentemente dalle altre righe della tabella.
Utilizzo di operazioni con stato, ad esempio
JOIN, aggregazioni e aggregazioni di finestre. Nelle operazioni con stato, lo stato dei dati importati viene mantenuto in più righe o intervalli di tempo per calcolare un risultato accurato.Utilizzando la funzione
APPENDSdella cronologia delle modifiche per elaborare i dati aggiunti da un momento specifico.Utilizzo della
CHANGESfunzione della cronologia delle modifiche per elaborare i dati modificati, inclusi gli accodamenti e le mutazioni, da un momento specifico quando esporti i dati in Pub/Sub. Tuttavia,CHANGESnon è supportato quando si utilizza un'operazione con stato.
Operazioni stateful supportate
Per richiedere assistenza o fornire un feedback su questa funzionalità, invia un'email all'indirizzo bq-continuous-queries-feedback@google.com.
Le operazioni con stato consentono alle query continue di eseguire analisi complesse che
richiedono la conservazione delle informazioni in più righe o intervalli di tempo. Mentre
le funzioni stateless elaborano ogni riga in modo indipendente, le operazioni stateful mantengono
lo stato dei dati inseriti per supportare funzioni come JOIN, aggregazioni e
aggregazioni di finestre. Questa
funzionalità ti consente di correlare eventi di stream diversi o calcolare metriche
nel tempo, ad esempio una media di 30 minuti, memorizzando i dati necessari nella memoria
durante l'esecuzione della query.
Le query continue supportano le seguenti operazioni con stato:
Autorizzazione
I token di accesso utilizzati durante l'esecuzione dei job di query continua hanno una durata (TTL) di due giorni quando vengono generati da un account utente.Google Cloud Pertanto, questi job smettono di essere eseguiti dopo due giorni. I token di accesso generati dagli account di servizio possono essere eseguiti più a lungo, ma devono comunque rispettare il runtime massimo delle query. Per saperne di più, consulta Eseguire una query continua utilizzando un service account.
Località
Per un elenco delle regioni supportate, vedi Località delle query continue di BigQuery.
Limitazioni
Le query continue sono soggette alle seguenti limitazioni:
- Lo stato dei dati importati viene mantenuto solo per le operazioni con stato specifico in anteprima. Anche se le query continue ora supportano alcuni tipi di
JOIN, aggregazioni e aggregazioni finestra, questi sono limitati a operazioni con stato specifiche. Non tutti i tipi di operazioni con stato sono supportati. Non puoi utilizzare le seguenti funzionalità SQL in una query continua, a meno che non siano elencate come operazione stateful supportata:
I seguenti operatori di query:
Operatori set delle query
Funzioni BigQuery ML diverse da quelle elencate in Funzionalità supportate
Istruzioni DML (Data Manipulation Language) ad eccezione di
INSERT.Istruzioni
EXPORT DATAche non hanno come target Bigtable, Pub/Sub o Spanner.
Le query continue non supportano le seguenti origini dati:
- Tabelle esterne.
- Viste dello schema delle informazioni.
- Tabelle gestite Apache Iceberg.
- Tabelle con caratteri jolly.
- Upsert Change Data Capture (CDC) dati.
- Viste materializzate.
- Viste definite da altre limitazioni delle query continue, ad esempio operazioni
JOIN, funzioni di aggregazione, funzioni definite dall'utente o tabelle abilitate all'acquisizione delle modifiche ai dati.
Le query continue non supportano le funzionalità di sicurezza column- e a livello di riga.
L'output di una query continua è soggetto alle quote e ai limiti intrinseci del servizio di destinazione in cui viene esportato.
Quando esporti i dati in Bigtable, Spanner o endpoint Pub/Sub puoi scegliere come target solo le risorse Bigtable, Spanner o Pub/Sub che rientrano nello stesso confine regionale di Google Cloud del set di dati BigQuery che contiene la tabella su cui stai eseguendo la query. Questa limitazione non si applica quando esporti i dati negli endpoint globali Pub/Sub. Per saperne di più sull'esportazione in un criterio di routing del profilo app Bigtable, consulta Considerazioni sulla località.
Non puoi eseguire una query continua da un data canvas.
Non puoi modificare l'SQL utilizzato in una query continua mentre è in esecuzione il relativo job. Per ulteriori informazioni, consulta Modificare l'SQL di una query continua.
Se un job di query continua è in ritardo nell'elaborazione dei dati in entrata e ha un ritardo della filigrana di output di più di 48 ore, non va a buon fine. Puoi eseguire di nuovo la query e utilizzare la funzione
APPENDSoCHANGESdella cronologia delle modifiche per riprendere l'elaborazione dal momento in cui hai interrotto il job di query continua precedente. Per saperne di più, consulta Avviare una query continua da un momento specifico.Una query continua configurata con un account utente può essere eseguita per un massimo di due giorni. Una query continua configurata con un account di servizio può essere eseguita per un massimo di 150 giorni. Quando viene raggiunto il runtime massimo della query, la query non va a buon fine e l'elaborazione dei dati in arrivo si interrompe.
Sebbene le query continue siano create utilizzando le funzionalità di affidabilità di BigQuery, possono verificarsi problemi temporanei occasionali. I problemi potrebbero comportare una certa quantità di rielaborazione automatica della query continua, il che potrebbe comportare la duplicazione dei dati nell'output della query continua. Progetta i sistemi downstream per gestire questi scenari.
Limitazioni delle prenotazioni
- Per eseguire query continue, devi creare prenotazioni per la versione Enterprise o Enterprise Plus. Le query continue non supportano il modello di fatturazione di calcolo on demand.
- Quando crei un
CONTINUOUSassegnazione di prenotazione, la prenotazione associata è limitata a un massimo di 500 slot. Puoi richiedere un aumento di questo limite contattando bq-continuous-queries-feedback@google.com. - Non puoi creare un'assegnazione di prenotazione che utilizzi un tipo di prestazione diverso nella stessa prenotazione di un'assegnazione di prenotazione di query continua.
- Non puoi configurare la concorrenza delle query continue. BigQuery determina automaticamente il numero di query continue che possono essere eseguite contemporaneamente in base alle assegnazioni di prenotazione disponibili che utilizzano il tipo di prestazione
CONTINUOUS. - Quando esegui più query continue utilizzando la stessa prenotazione, i singoli job potrebbero non dividere equamente le risorse disponibili, come definito da BigQuery fairness.
Scalabilità automatica degli slot
Le query continue possono utilizzare la scalabilità automatica degli slot per scalare dinamicamente la capacità allocata in base al workload. Man mano che il carico di lavoro delle query continue aumenta o diminuisce, BigQuery regola dinamicamente gli slot.
Una volta avviata l'esecuzione, una query continua ascolta attivamente i dati in arrivo, che consumano risorse slot. Mentre una prenotazione con una query continua in esecuzione non viene fare lo scale down a zero slot, una query continua inattiva che ascolta principalmente i dati in arrivo dovrebbe consumare una quantità minima di slot, in genere circa 1 slot.
Condivisione di slot inattivi
Le query continue possono utilizzare la condivisione degli slot inattivi per condividere le risorse degli slot inutilizzati con altre prenotazioni e tipi di job.
- Per eseguire una query continua è comunque necessario un
CONTINUOUSassegnazione di prenotazione e non è possibile fare affidamento esclusivamente sugli slot inattivi di altre prenotazioni. Pertanto, un'assegnazione di prenotazioneCONTINUOUSrichiede una base di riferimento di slot diversa da zero o una configurazione di scalabilità automatica di slot diversa da zero. - Sono condivisibili solo gli slot di riferimento inattivi o gli slot impegnati di un'assegnazione di prenotazione
CONTINUOUS. Gli slot scalati automaticamente non sono condivisibili come slot inattivi per altre prenotazioni.
Prezzi
Le query continue possono utilizzare lo scaling fluido di BigQuery.
Le query continue utilizzano i
prezzi di calcolo della capacità di BigQuery,
che vengono misurati in slot.
Per eseguire query continue, devi disporre di una
prenotazione che utilizzi
Enterprise o Enterprise Plus
e di un assegnazione di prenotazione
che utilizzi il tipo di prestazione CONTINUOUS.
L'utilizzo di altre risorse BigQuery, come l'importazione e l'archiviazione dei dati, viene addebitato alle tariffe indicate nei prezzi di BigQuery.
L'utilizzo di altri servizi che ricevono risultati di query continui o che vengono chiamati durante l'elaborazione di query continue viene addebitato alle tariffe pubblicate per questi servizi. Per i prezzi di altri servizi Google Cloud utilizzati dalle query continue, consulta i seguenti argomenti:
Passaggi successivi
Prova a creare una query continua.