
שימוש בגיליונות מקושרים
הגיליונות המקושרים מביאים את יכולת ההתאמה לעומס (scaling) של BigQuery לממשק המוכר של Google Sheets. בעזרת הגיליונות המקושרים, אתם יכולים לראות תצוגה מקדימה של הנתונים ב-BigQuery ולהשתמש בהם בטבלאות צירים, בנוסחאות ובתרשימים שנבנו מכל מערך הנתונים.
אפשר גם:
לשתף פעולה עם שותפים, אנליסטים או בעלי עניין אחרים בממשק מוכר של גיליונות אלקטרוניים.
להבטיח שיהיה מקור אחד לניתוח נתוני אמת, ללא ייצוא נוסף של גיליונות אלקטרוניים.
לייעל את תהליכי העבודה של הדיווח ושל מרכז השליטה.
'גיליונות מקושרים' מריצים שאילתות ב-BigQuery בשמכם לפי בקשה או לפי לוח זמנים מוגדר. התוצאות של השאילתות האלה נשמרות בגיליון האלקטרוני לצורך ניתוח ושיתוף.
תרחישים לדוגמה
ריכזנו כאן כמה תרחישי שימוש שממחישים איך 'גיליונות מקושרים' מאפשר לכם לנתח כמויות גדולות של נתונים בגיליון, בלי שתצטרכו לדעת SQL.
תכנון עסקי: בנייה והכנה של מערכי נתונים, ואז מתן אפשרות למשתמשים אחרים להפיק תובנות מהנתונים. לדוגמה, אפשר לנתח נתוני מכירות כדי לקבוע אילו מוצרים נמכרים טוב יותר במיקומים שונים.
שירות לקוחות: אילו חנויות קיבלו הכי הרבה תלונות לכל 10,000 לקוחות.
מכירות: יצירת דוחות פנימיים של כספים ומכירות, ושיתוף דוחות הכנסות עם נציגי מכירות.
בקרת גישה
הגישה הישירה לטבלאות ולמערכי נתונים ב-BigQuery נשלטת בתוך BigQuery. אם רוצים לתת למשתמש גישה רק ל-Google Sheets, משתפים גיליון אלקטרוני ולא מעניקים גישה ל-BigQuery.
משתמש עם גישה ל-Google Sheets בלבד יכול לבצע ניתוח בגיליון ולהשתמש בתכונות אחרות של Google Sheets, אבל הוא לא יוכל לבצע את הפעולות הבאות:
- רענון ידני של נתוני BigQuery בגיליון.
- תזמון הרענון של הנתונים בגיליון.
כשמסננים נתונים בגיליונות מקושרים, השאילתה שנשלחת אל BigQuery מתרעננת בהתאם לפרויקט שבחרתם. אפשר לראות את השאילתה שהופעלה באמצעות מסנן היומן הבא בפרויקט הרלוונטי:
resource.type="bigquery_resource" protoPayload.metadata.firstPartyAppMetadata.sheetsMetadata.docId != NULL_VALUE
VPC Service Controls
אתם יכולים להשתמש ב-VPC Service Controls כדי להגביל את הגישה למשאביGoogle Cloud . מאחר ש-VPC Service Controls לא תומך ב-Sheets, יכול להיות שלא תהיה לכם גישה לנתוני BigQuery שמוגנים באמצעות VPC Service Controls. אם יש לכם את הרשאות הגישה הנדרשות ואתם עומדים בהגבלות הגישה לשימוש ב-VPC Service Controls, אתם יכולים להגדיר את גבולות הגזרה של VPC Service Controls כדי לאפשר שאילתות שהופקו באמצעות גיליונות מקושרים. כדי לעשות את זה, צריך להגדיר את גבולות הגזרה באמצעות:
- רמת גישה או כלל תעבורת נתונים נכנסת (ingress) כדי לאפשר בקשות מכתובות IP מהימנות, מזהויות מהימנות ומכשירי לקוח מהימנים מחוץ לגבולות גזרה.
- כלל יציאה שמאפשר להעתיק את תוצאות השאילתה לגיליונות אלקטרוניים של משתמשים.
מידע נוסף על הגדרת מדיניות של תעבורת נתונים נכנסת (ingress) ויוצאת (egress) ועל הגדרת רמות גישה כדי להגדיר את הכללים בצורה נכונה. כדי להגדיר גבולות גזרה שיאפשרו את העתקת הנתונים הנדרשת, משתמשים בקובץ ה-YAML הבא:
# Allows egress to Sheets through the Connected Sheets feature
- egressTo:
operations:
- serviceName: 'bigquery.googleapis.com'
methodSelectors:
- permission: 'bigquery.vpcsc.importData'
resources:
- projects/628550087766 # Sheets-owned Google Cloud project
egressFrom:
identityType: ANY_USER_ACCOUNT
לפני שמתחילים
קודם כל, צריך לוודא שאתם עומדים בדרישות לגישה לנתוני BigQuery ב-Sheets, כמו שמתואר בקטע 'מה צריך' בנושא Google Workspace איך מתחילים לעבוד עם נתוני BigQuery ב-Google Sheets.
אם אין לכם פרויקט שהוגדר לחיוב, אתם צריכים לפעול לפי השלבים הבאים: Google Cloud
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery מופעל באופן אוטומטי בפרויקטים חדשים.
כדי להפעיל את BigQuery בפרויקט קיים, עוברים אל
מפעילים את BigQuery API.
תפקידים שנדרשים להפעלת ממשקי API
כדי להפעיל ממשקי API, צריך את תפקיד ה-IAM 'אדמין של Service Usage' (
roles/serviceusage.serviceUsageAdmin), שכולל את ההרשאהserviceusage.services.enable. איך מקצים תפקידים
כדי להימנע מחיובים נוספים, תוכלו למחוק את המשאבים שיצרתם. פרטים נוספים מופיעים במאמר בנושא הסרת המשאבים.
פתיחת מערכי נתונים של BigQuery מגיליונות מקושרים
בדוגמה הבאה נעשה שימוש במערך נתונים ציבורי כדי להראות לכם איך להתחבר ל-BigQuery מ-Google Sheets:
יוצרים גיליון אלקטרוני ב-Google Sheets או פותחים גיליון קיים.
לוחצים על נתונים, על מחברים של מקורות נתונים חיצוניים ואז על התחברות ל-BigQuery.
בוחרים Google Cloud פרויקט שמופעל בו חיוב.
לוחצים על קבוצות נתונים ציבוריות.
בתיבת החיפוש, מקלידים chicago ואז בוחרים את מערך הנתונים chicago_taxi_trips.
בוחרים את הטבלה taxi_trips ולוחצים על Connect (חיבור).
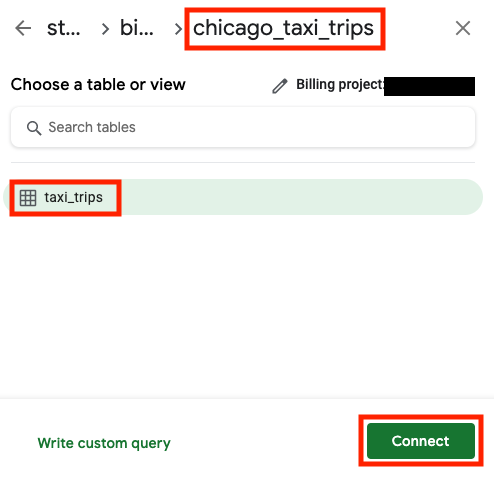
הגיליון האלקטרוני צריך להיראות כך:
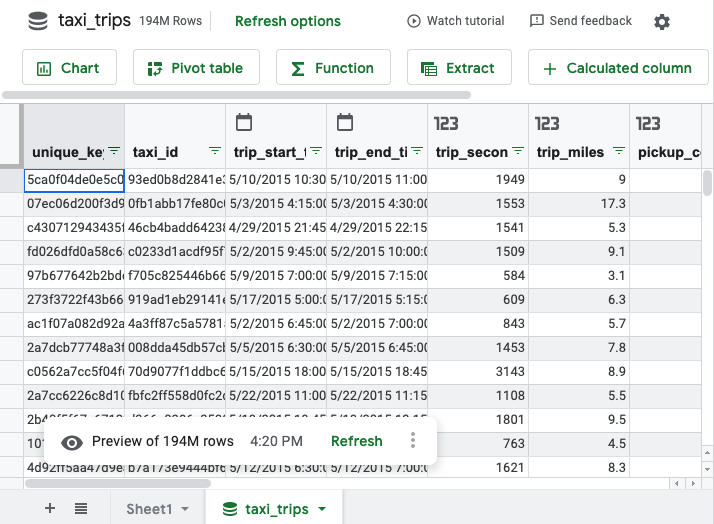
מתחילים להשתמש בגיליון האלקטרוני. אתם יכולים ליצור טבלאות צירים, נוסחאות, תרשימים, עמודות מחושבות ושאילתות מתוזמנות באמצעות טכניקות מוכרות של Google Sheets. מידע נוסף זמין במדריך לגיליונות מקושרים.
למרות שבגיליון האלקטרוני מוצגת תצוגה מקדימה של 500 שורות בלבד, כל טבלאות הצירים, הנוסחאות והתרשימים משתמשים בכל קבוצת הנתונים. מספר השורות המקסימלי של תוצאות שמוחזרות לטבלאות צירים הוא 200,000.
אפשר גם לחלץ את הנתונים ל-Google Sheets. מספר השורות והתאים המקסימלי של תוצאות שמוחזרות לחילוצי נתונים תלוי בתנאים הבאים:
- אם מספר השורות קטן מ-50,000 או שווה לו, לא תהיה מגבלת תאים.
- אם מספר השורות גדול מ-50,000 אבל קטן מ-500,000 או שווה לו, מספר התאים חייב להיות קטן מ-5 מיליון או שווה לו.
- אם מספר השורות גדול מ-500,000, לא תהיה תמיכה בשליפת הנתונים.
כשמשתמשים בגיליונות מקושרים כדי ליצור תרשים, טבלת צירים, נוסחה או תא מחושב אחר מהנתונים, הגיליונות המקושרים מריצים שאילתה ב-BigQuery בשמכם. כדי לראות את השאילתה הזו:
- בוחרים את התא או התרשים שיצרתם.
- מציבים את הסמן מעל רענון.
- אופציונלי: כדי לרענן את תוצאות השאילתה בגיליונות מקושרים, לוחצים על רענון.
כדי לראות את השאילתה ב-BigQuery, לוחצים על פרטי השאילתה ב-BigQuery.
השאילתה תיפתח במסוף Google Cloud .
פתיחת טבלאות בגיליונות מקושרים
כדי לפתוח טבלה ב-Connected Sheets, פועלים לפי השלבים הבאים:
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer, מרחיבים את הפרויקט, לוחצים על Datasets ואז לוחצים על מערך הנתונים שמכיל את הטבלה שרוצים לפתוח ב-Google Sheets.
לוחצים על סקירה כללית > טבלאות, ולצד שם הטבלה לוחצים על הצגת פעולות, ואז בוחרים באפשרות פתיחה ב-> Connected Sheets.
פתיחת שאילתות שמורות בגיליונות מקושרים
ודאו שיש לכם שאילתה שמורה. מידע נוסף זמין במאמר בנושא יצירת שאילתות שמורות.
כדי לפתוח שאילתה שנשמרה בגיליונות מקושרים:
במסוף Google Cloud , עוברים לדף BigQuery.
בחלונית הימנית, לוחצים על כלי הניתוחים:
בחלונית Explorer מרחיבים את הפרויקט ולוחצים על Queries. מחפשים את השאילתה השמורה שרוצים לפתוח בגיליונות מקושרים.
לצד השאילתה השמורה, לוחצים על פתיחת פעולות ואז על פתיחה ב-> Connected Sheets.
לחלופין, לוחצים על שם השאילתה השמורה כדי לפתוח אותה בחלונית הפרטים, ואז לוחצים על פתיחה ב-> Connected Sheets.
מעקב אחרי השימוש ב-BigQuery מתוך גיליונות מקושרים
אדמינים ב-BigQuery יכולים לעקוב אחרי צריכת המשאבים מגיליונות מקושרים ולבדוק אותה כדי להבין את דפוסי השימוש, לנהל את העלויות ולזהות דוחות שנמצאים בשימוש לעיתים קרובות. בקטעים הבאים מופיעות דוגמאות לשאילתות SQL שיעזרו לכם לעקוב אחרי השימוש הזה ברמת הארגון וברמת הפרויקט. מידע נוסף זמין במאמר בנושא JOBS.
לכל השאילתות שמקורן בגיליונות מקושרים מוקצית תחילית ייחודית של מזהה עבודה: sheets_dataconnector. אפשר להשתמש בקידומת הזו כדי לסנן משרות בתצוגות INFORMATION_SCHEMA.JOBS.
נתוני שימוש מצטברים בגיליונות מקושרים לפי משתמש ברמת הארגון
השאילתה הבאה מספקת סיכום של המשתמשים המובילים ב-Connected Sheets בארגון שלכם ב-30 הימים האחרונים, מדורגים לפי סך הנתונים שחויבו. השאילתה צוברת את המספר הכולל של שאילתות, את מספר הבייטים הכולל שחויבו ואת מספר אלפיות השנייה הכולל של משבצות לכל משתמש. המידע הזה שימושי להבנת רמת האימוץ ולזיהוי הצרכנים העיקריים של המשאבים.
SELECT
user_email,
COUNT(*) AS total_queries,
SUM(total_bytes_billed) AS total_bytes_billed,
SUM(total_slot_ms) AS total_slot_ms
FROM
`region-REGION_NAME.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION`
WHERE
-- Filter for jobs created in the last 30 days
creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
-- Filter for jobs originating from Connected Sheets
AND job_id LIKE 'sheets_dataconnector%'
-- Filter for completed jobs
AND state = 'DONE'
AND (statement_type IS NULL OR statement_type <> 'SCRIPT')
GROUP BY
1
ORDER BY
total_bytes_billed DESC;
מחליפים את REGION_NAME באזור של הפרויקט.
לדוגמה, region-us.
התוצאה אמורה להיראות כך:
+---------------------+---------------+--------------------+-----------------+ | user_email | total_queries | total_bytes_billed | total_slot_ms | +---------------------+---------------+--------------------+-----------------+ | alice@example.com | 152 | 12000000000 | 3500000 | | bob@example.com | 45 | 8500000000 | 2100000 | | charles@example.com | 210 | 1100000000 | 1800000 | +---------------------+---------------+--------------------+-----------------+
חיפוש יומני משרות של שאילתות בגיליונות מקושרים ברמת הארגון
השאילתה הבאה מספקת יומן מפורט של כל הפעלה של עבודות ב-Connected Sheets. המידע הזה שימושי לביקורת ולזיהוי של שאילתות ספציפיות בעלות גבוהה.
SELECT
job_id,
creation_time,
user_email,
project_id,
total_bytes_billed,
total_slot_ms
FROM
`region-REGION_NAME.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION`
WHERE
creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
AND job_id LIKE 'sheets_dataconnector%'
AND state = 'DONE'
AND (statement_type IS NULL OR statement_type <> 'SCRIPT')
ORDER BY
creation_time DESC;
מחליפים את REGION_NAME באזור של הפרויקט.
לדוגמה, region-us.
התוצאה אמורה להיראות כך:
+---------------------------------+---------------------------------+-----------------+------------+--------------------+---------------+ | job_id | creation_time | user_email | project_id | total_bytes_billed | total_slot_ms | +---------------------------------+---------------------------------+-----------------+------------+--------------------+---------------+ | sheets_dataconnector_bquxjob_1 | 2025-11-06 00:26:53.077000 UTC | abc@example.com | my_project | 12000000000 | 3500000 | | sheets_dataconnector_bquxjob_2 | 2025-11-06 00:24:04.294000 UTC | xyz@example.com | my_project | 8500000000 | 2100000 | | sheets_dataconnector_bquxjob_3 | 2025-11-03 23:17:25.975000 UTC | bob@example.com | my_project | 1100000000 | 1800000 | +---------------------------------+---------------------------------+-----------------+------------+--------------------+---------------+
סיכום השימוש בגיליונות מקושרים לפי משתמש ברמת הפרויקט
אם אין לכם הרשאות ברמת הארגון או שאתם צריכים רק לעקוב אחרי פרויקט ספציפי, אתם יכולים להריץ את השאילתה הבאה כדי לזהות את המשתמשים המובילים ב-Connected Sheets בפרויקט מסוים ב-30 הימים האחרונים. השאילתה מסכמת את המספר הכולל של שאילתות, את מספר הבייטים הכולל שחויבו ואת מספר אלפיות השנייה הכולל של משבצות זמן לכל משתמש. המידע הזה שימושי להבנת רמת האימוץ ולזיהוי הצרכנים המובילים של המשאבים.
SELECT
user_email,
COUNT(*) AS total_queries,
SUM(total_bytes_billed) AS total_bytes_billed,
SUM(total_slot_ms) AS total_slot_ms
FROM
-- This view queries the project you are currently running the query in.
`region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
-- Filter for jobs created in the last 30 days
creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
-- Filter for jobs originating from Connected Sheets
AND job_id LIKE 'sheets_dataconnector%'
-- Filter for completed jobs
AND state = 'DONE'
AND (statement_type IS NULL OR statement_type <> 'SCRIPT')
GROUP BY
user_email
ORDER BY
total_bytes_billed DESC
LIMIT
10;
מחליפים את REGION_NAME באזור של הפרויקט.
לדוגמה, region-us.
התוצאה אמורה להיראות כך:
+---------------------+---------------+--------------------+-----------------+ | user_email | total_queries | total_bytes_billed | total_slot_ms | +---------------------+---------------+--------------------+-----------------+ | alice@example.com | 152 | 12000000000 | 3500000 | | bob@example.com | 45 | 8500000000 | 2100000 | | charles@example.com | 210 | 1100000000 | 1800000 | +---------------------+---------------+--------------------+-----------------+
איך מוצאים יומני עבודות של שאילתות בגיליונות מקושרים ברמת הפרויקט
אם אין לכם הרשאות ברמת הארגון או שאתם צריכים לעקוב רק אחרי פרויקט ספציפי, מריצים את השאילתה הבאה כדי לראות יומן מפורט של כל השאילתות של Connected Sheets בפרויקט הנוכחי:
SELECT
job_id,
creation_time,
user_email,
total_bytes_billed,
total_slot_ms,
query
FROM
-- This view queries the project you are currently running the query in.
`region-REGION_NAME.INFORMATION_SCHEMA.JOBS_BY_PROJECT`
WHERE
creation_time >= TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
AND job_id LIKE 'sheets_dataconnector%'
AND state = 'DONE'
AND (statement_type IS NULL OR statement_type <> 'SCRIPT')
ORDER BY
creation_time DESC;
מחליפים את REGION_NAME באזור של הפרויקט.
לדוגמה, region-us.
התוצאה אמורה להיראות כך:
+---------------------------------+---------------------------------+------------------+--------------------+-----------------+---------------------------------+ | job_id | creation_time | user_email | total_bytes_billed | total_slot_ms | query | +---------------------------------+---------------------------------+------------------+--------------------+-----------------+---------------------------------+ | sheets_dataconnector_bquxjob_1 | 2025-11-06 00:26:53.077000 UTC | abc@example.com | 12000000000 | 3500000 | SELECT ... FROM dataset.table1 | | sheets_dataconnector_bquxjob_2 | 2025-11-06 00:24:04.294000 UTC | xyz@example.com | 8500000000 | 2100000 | SELECT ... FROM dataset.table2 | | sheets_dataconnector_bquxjob_3 | 2025-11-03 23:17:25.975000 UTC | bob@example.com | 1100000000 | 1800000 | SELECT ... FROM dataset.table3 | +---------------------------------+---------------------------------+------------------+--------------------+-----------------+---------------------------------+
סידור וארגון
כדי להימנע מחיובים בחשבון Google Cloud על המשאבים שבהם השתמשתם במדריך הזה:
- במסוף Google Cloud , נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
המאמרים הבאים
מידע נוסף זמין בנושא איך מתחילים לעבוד עם נתוני BigQuery ב-Google Sheets ב-Google Workspace.
אפשר לצפות בסרטונים מתוך הפלייליסט בנושא שימוש בגיליונות מקושרים ב-YouTube.