
叢集資料表簡介
BigQuery 中的叢集資料表是使用者以叢集資料欄定義欄位排序順序的資料表。叢集資料表可提升查詢效能並降低查詢費用。
在 BigQuery 中,分群資料欄是使用者定義的資料表屬性,可根據分群資料欄中的值排序儲存區塊。儲存區塊大小會根據資料表大小調整。共置發生在儲存空間區塊層級,而非個別資料列層級;如要進一步瞭解這個情境中的共置,請參閱「叢集」。
在每個修改資料表的作業中,叢集資料表都會保留其排序屬性。如果查詢依叢集化資料欄進行篩選或匯總,系統只會根據叢集化資料欄掃描相關區塊,而不是整個資料表或資料表分區。因此,BigQuery 可能無法準確預估查詢將處理的位元組數或查詢費用,但會盡量減少執行時的總位元組數。
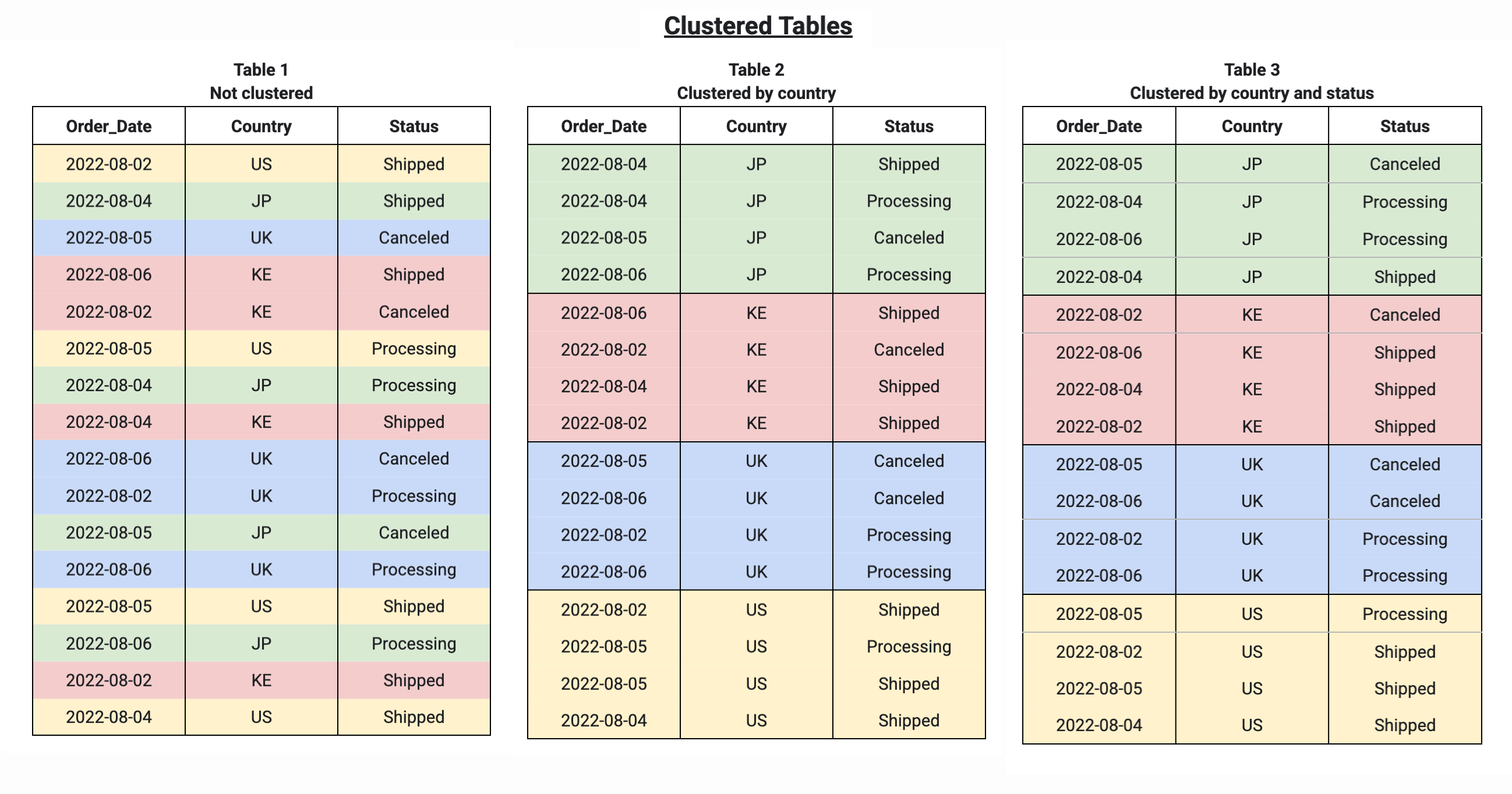
使用多個資料欄對資料表進行叢集處理時,資料欄順序會決定 BigQuery 將資料排序並分組到儲存區塊時,哪些資料欄具有優先權,如下例所示。表 1 顯示未叢集化資料表的邏輯儲存區塊配置。相較之下,資料表 2 只會依 Country 資料欄叢集,而資料表 3 則會依多個資料欄 (Country 和 Status) 叢集。
查詢叢集資料表時,系統無法在查詢執行前提供準確的查詢費用預估值,因為查詢執行前無法得知要掃描的儲存區塊數量。查詢執行完畢後,系統會根據掃描的特定儲存區塊,決定最終費用。
叢集無法保證查詢資料表所需的時段會減少。
使用叢集處理的時機
叢集處理會處理資料表的儲存方式,因此通常是改善查詢效能的第一個好選擇。因此,請務必考慮使用叢集,因為叢集具有下列優點:
- 如果未經分割的資料表超過 64 MB,建議使用叢集功能。同樣地,如果資料表分區大於 64 MB,也可能受益於叢集處理。您可以對較小的資料表或分區進行叢集處理,但通常效能提升幅度不大。
- 如果查詢通常會篩選特定資料欄,叢集處理可加快查詢速度,因為查詢只會掃描符合篩選條件的區塊。
- 如果查詢會依據具有許多不重複值 (高基數) 的資料欄進行篩選,叢集功能會提供詳細的中繼資料給 BigQuery,說明要從何處取得輸入資料,藉此加快查詢速度。
- 叢集處理功能可根據資料表大小,自動調整資料表基礎儲存區塊的大小。
除了叢集處理,您也可以考慮分區處理資料表。這種做法是先將資料分區,然後再依叢集資料欄,將各分區中的資料叢集化。在下列情況下,請考慮使用這個方法:
- 您需要在執行查詢前取得嚴格的查詢費用估算值。查詢叢集資料表的費用只能在查詢執行後判斷。分區功能可讓您在執行查詢前,取得精細的查詢費用估算結果。
- 分區後,每個分區的平均大小至少為 10 GB。建立許多小型分區會增加資料表的中繼資料,並可能影響查詢資料表時的中繼資料存取時間。
- 您需要持續更新資料表,但仍想發揮長期儲存價格的效益。分區功能可讓系統分別判斷每個分區是否符合長期價格資格。如果資料表未經過分區,則必須連續 90 天未編輯整個資料表,才能適用長期價格。
詳情請參閱合併叢集和分區資料表。
叢集資料欄類型和排序
本節說明資料欄類型,以及資料欄順序在資料表叢集中的運作方式。
叢集欄類型
叢集資料欄必須是頂層的非重複資料欄,且屬於下列任一類型:
BIGNUMERICBOOLDATEDATETIMEGEOGRAPHYINT64NUMERICRANGESTRINGTIMESTAMP
如要進一步瞭解資料類型,請參閱 GoogleSQL 資料類型。
叢集資料欄排序
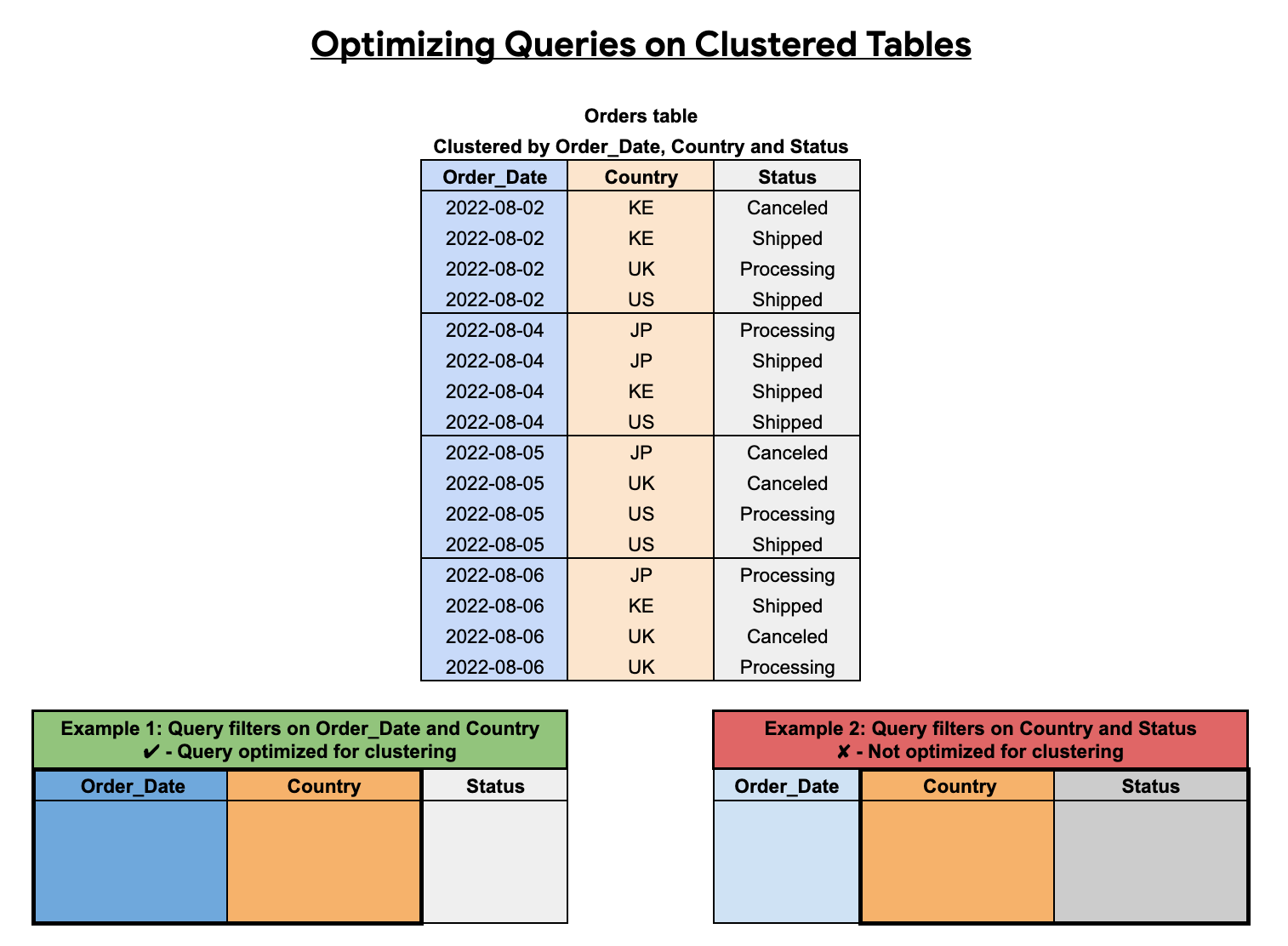
叢集資料欄的順序會影響查詢效能。在下列範例中,Orders 資料表會使用 Order_Date、Country 和 Status 的資料欄排序順序進行分群。在本範例中,第一個叢集資料欄是 Order_Date,因此篩選 Order_Date 和 Country 的查詢會針對叢集進行最佳化,但只篩選 Country 和 Status 的查詢則不會。
區塊修剪
叢集資料表會修剪資料,如此一來,查詢就不會處理修剪掉的資料,查詢成本也會因而降低。這個過程稱為區塊修剪。 BigQuery 根據叢集資料欄的值在叢集資料表中進行資料排序,並將資料組織成區塊。
如果您對叢集資料表執行查詢,且查詢的叢集資料欄含有篩選器,則 BigQuery 會使用篩選器運算式及區塊中繼資料來修剪查詢掃描的區塊。BigQuery 只會掃描相關區塊。
系統不會掃描修剪掉的區塊,只有已掃描的區塊才會計入查詢處理的資料位元組數。查詢在叢集資料表中所處理的位元組數,等同於查詢在已掃描區塊中參照的每一個資料欄所讀取的總位元組數。
如果使用多項篩選器的查詢多次參照某個叢集資料表,則 BigQuery 對各篩選器相應區塊內的資料欄所執行的掃描作業會產生費用。如要瞭解區塊修剪的運作方式,請參閱範例。
合併叢集資料表和分區資料表
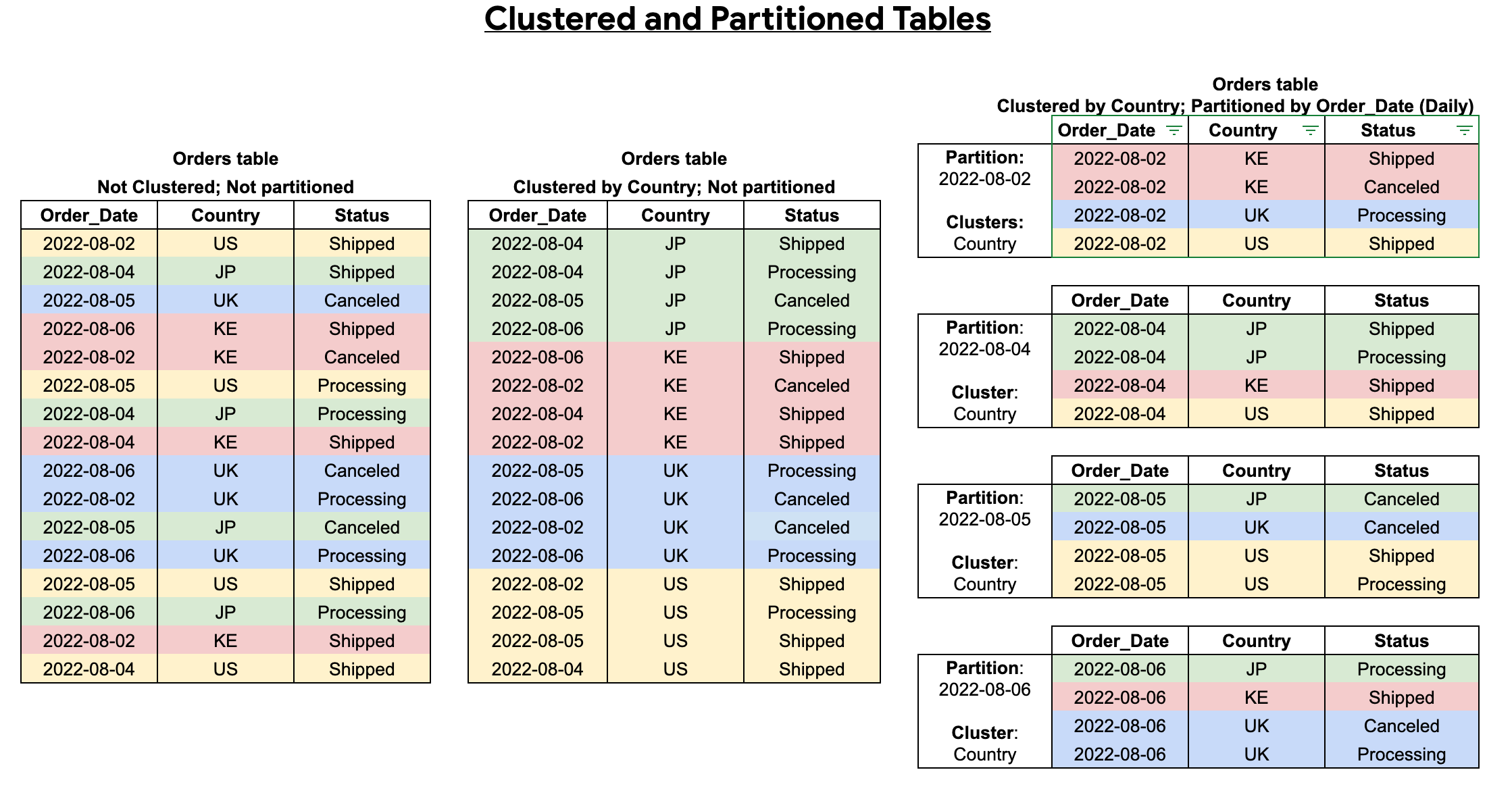
您可以結合資料表叢集處理和資料表分區處理,獲得精細的排序結果,進一步最佳化查詢。
在分區資料表中,資料會儲存在實體區塊中,每個區塊都包含一個資料分區。在每個修改資料表的操作中,分區資料表都會保留其排序屬性的各種中繼資料。有了中繼資料,BigQuery 就能在執行查詢前更準確地估算查詢費用。不過,與未分區資料表相比,分區需要 BigQuery 維護更多中繼資料。隨著分區數量的增加,需要維護的中繼資料量也會增加。
建立經過叢集和分區處理的資料表時,您可以獲得更精細的排序結果,如下圖所示:
範例
您有一個名為 ClusteredSalesData 的叢集資料表。資料表會依 timestamp 資料欄進行分區,並由 customer_id 資料欄建為叢集。資料會按以下這組區塊分類:
| 分區 ID | 區塊 ID | 區塊中 customer_id 的下限 | 區塊中 customer_id 的上限 |
|---|---|---|---|
| 20160501 | B1 | 10000 | 19999 |
| 20160501 | B2 | 20000 | 24999 |
| 20160502 | B3 | 15000 | 17999 |
| 20160501 | B4 | 22000 | 27999 |
您對該資料表進行以下的查詢。查詢包含了 customer_id 資料欄的篩選器。
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id BETWEEN 20000 AND 23000 AND DATE(timestamp) = "2016-05-01"
上述查詢包含下列步驟:
- 掃描 B2 和 B4 區塊中
timestamp、customer_id和totalSale資料欄。 DATE(timestamp) = "2016-05-01"篩選器述語針對timestamp分區資料欄,因此修剪 B3 區塊。customer_id BETWEEN 20000 AND 23000篩選器述語針對customer_id叢集資料欄,因此修剪 B1 區塊。
自動重新分群
資料新增至叢集資料表時,新資料會整理成區塊,這可能會建立新的儲存區塊或更新現有區塊。為達到最佳查詢和儲存效能,您必須進行區塊最佳化,因為新資料可能不會與具有相同叢集值的現有資料分組。
為了維護叢集資料表的效能特性,BigQuery 會在背景中自動重新進行叢集處理。對於分區資料表,系統會以每個分區為範圍維持資料的叢集處理。
限制
- 只能透過 GoogleSQL 語法查詢叢集資料表,以及將查詢結果寫入叢集資料表之中。
- 您最多只能指定四個叢集資料欄。如需其他資料欄,請考慮將叢集與分割區結合使用。
- 使用
STRING類型資料欄建立叢集時,BigQuery 只會使用前 1,024 個字元來建立資料叢集。資料欄中的值本身可以超過 1,024 個字元。 - 如果您將現有的非叢集資料表變更為叢集資料表,現有資料不會自動叢集。只有使用叢集資料欄儲存的新資料,才會自動重新叢集。如要進一步瞭解如何使用
UPDATE陳述式重新叢集現有資料,請參閱「修改叢集規格」。
叢集資料表的配額和限制
BigQuery 會透過配額和限制來限制共用 Google Cloud 資源的使用,包括限制特定資料表作業或一天內執行的工作數。
在分區資料表中使用叢集資料表功能時,須遵守分區資料表的限制。
配額和限制也適用於各種可以在叢集資料表執行的工作。如要瞭解適用於資料表的作業配額,請參閱「配額與限制」中的「作業」。
叢集資料表定價
在 BigQuery 中建立及使用叢集資料表時,系統會依據資料表中儲存的資料量,以及您對資料執行的查詢來計算費用。詳情請參閱儲存空間定價和查詢定價。
與其他 BigQuery 資料表作業一樣,叢集資料表作業也會利用 BigQuery 免費作業,例如批次載入、資料表複製、自動重新叢集和資料匯出。這些作業須遵守 BigQuery 配額與限制。如要瞭解免費作業,請參閱「免費作業」一文。
如需叢集資料表定價的詳細範例,請參閱「估算儲存空間和查詢費用」。
表格安全性
如要控管 BigQuery 資料表的存取權,請參閱「使用 IAM 控管資源存取權」。
後續步驟
- 如要瞭解如何建立及使用叢集資料表,請參閱建立及使用叢集資料表一文。
- 關於如何查詢叢集資料表,請參閱查詢叢集資料表一文。