
Questo tutorial mostra come eseguire la migrazione di applicazioni stateful in GKE da tipi di macchina di generazioni precedenti, come N2, con volumi Persistent Disk collegati, a tipi di macchina di generazioni più recenti, come N4, con volumi Hyperdisk collegati utilizzando Backup per GKE. Per saperne di più sui tipi di macchine che supportano Hyperdisk, consulta la documentazione di Compute Engine.
Per dimostrare la migrazione, questo tutorial utilizza il database Sakila e il database World per fornire set di dati di esempio. Sakila è un database di esempio fornito da MySQL che rappresenta un negozio di noleggio di DVD fittizio. Il database World contiene dati su paesi e città. Il tutorial utilizza due set di dati diversi in spazi dei nomi separati per simulare un ambiente complesso e multi-tenant.
Questo tutorial è rivolto a specialisti e amministratori dello spazio di archiviazione che creano e allocano lo spazio di archiviazione e gestiscono la sicurezza dei dati e l'accesso ai dati. Per scoprire di più sui ruoli comuni e sulle attività di esempio a cui si fa riferimento nei contenuti di Google Cloud, consulta Ruoli utente e attività comuni di GKE.
Architettura di deployment
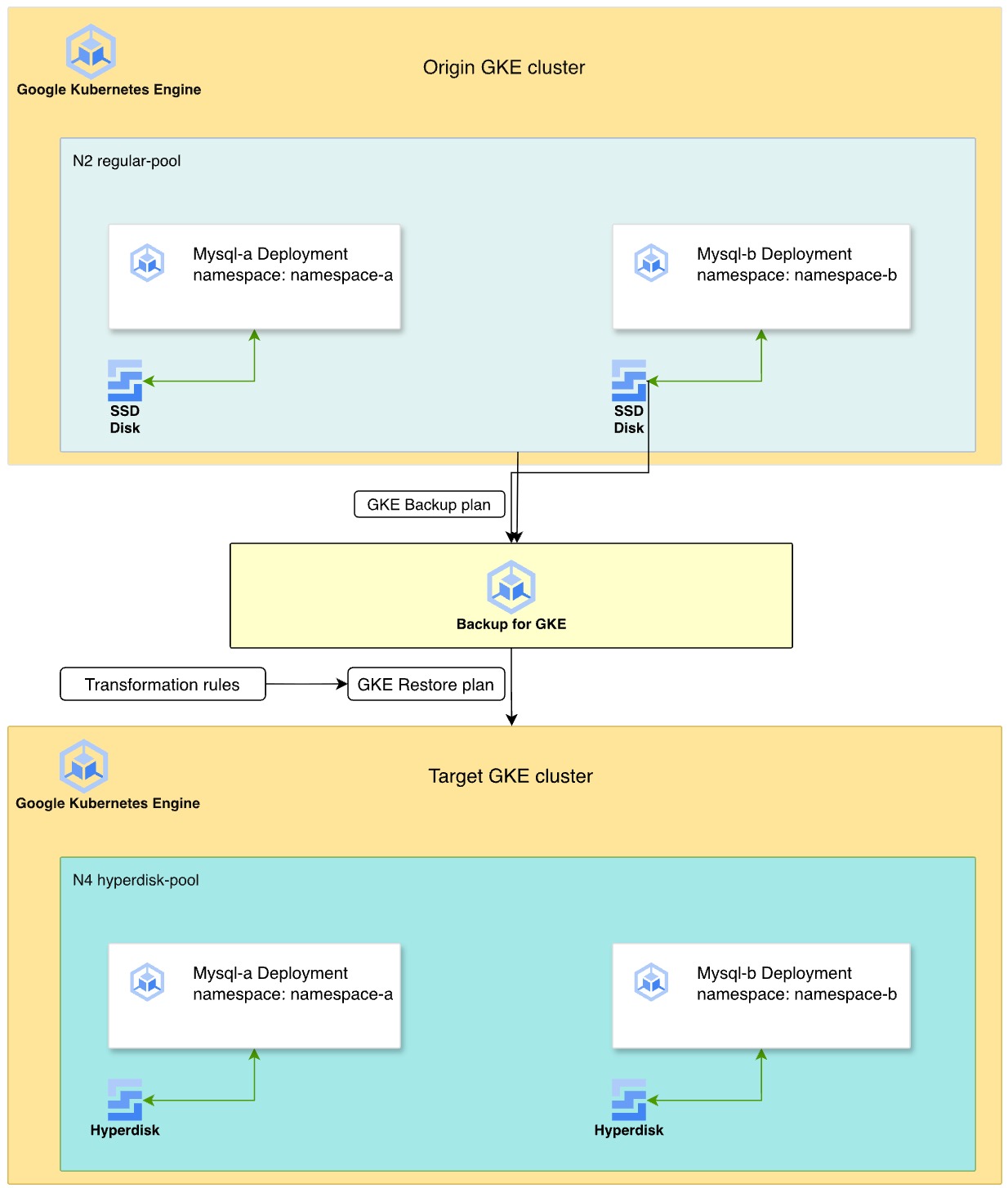
Il seguente diagramma illustra il processo di utilizzo di Backup for GKE per eseguire la migrazione dei carichi di lavoro MySQL stateful da Persistent Disk sui tipi di macchine N2 a Hyperdisk sui tipi di macchine N4.
- Cluster di origine:due deployment MySQL si trovano in spazi dei nomi separati,
namespace-aenamespace-b, in un pool di nodi della serie di macchine N2. Questi deployment utilizzano dischi permanenti SSD per l'archiviazione dei dati. - Strategia di backup:attivi l'agente Backup per GKE sul cluster e crei un piano di backup per acquisire gli spazi dei nomi, i dati dei volumi e i secret. Poi, esegui un backup manuale per creare un punto di ripristino point-in-time.
- Trasformazione e ripristino:definisci un piano di ripristino utilizzando
regole di trasformazione per adattare le risorse all'ambiente di destinazione.
Queste regole eseguono le seguenti operazioni:
- Scambia
StorageClassdapremium-rwo(DP) con una classe di archiviazione Hyperdisk denominatabalanced-storage. - Modifica le regole di affinità dei pod per assicurarti che i carichi di lavoro ripristinati vengano pianificati in un nuovo pool di nodi N4.
- Scambia
- Ambiente di destinazione:esegui il provisioning di un nuovo cluster GKE con tipi di macchine N4. Il processo di ripristino ricrea i dischi come volumi Hyperdisk dal backup e distribuisce le istanze MySQL sui nodi N4 compatibili.
Obiettivi
In questo tutorial imparerai a:
- Prepara le applicazioni stateful GKE per il backup.
- Attiva il componente aggiuntivo Backup per GKE.
- Crea un piano di backup ed esegui il backup del cluster di origine.
- Crea un piano di ripristino che utilizzi regole di trasformazione per eseguire la migrazione dell'archiviazione a Hyperdisk.
- Ripristina il carico di lavoro in un nuovo cluster e verifica i dati.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
- GKE
- Compute Engine (Persistent Disk and Hyperdisk)
- Backup for GKE
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
- Accedi al tuo account Google Cloud . Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine, GKE, Backup for GKE, and IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine, GKE, Backup for GKE, and IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Assicurati di disporre dei seguenti ruoli nel progetto: roles/container.admin, roles/iam.serviceAccountAdmin, roles/compute.admin, roles/gkebackup.admin, roles/monitoring.viewer
Controlla i ruoli
-
Nella console Google Cloud vai alla pagina IAM.
Vai a IAM - Seleziona il progetto.
-
Nella colonna Entità, trova tutte le righe che identificano te o un gruppo di cui fai parte. Per scoprire a quali gruppi appartieni, contatta il tuo amministratore.
- Per tutte le righe che ti specificano o ti includono, controlla la colonna Ruolo per verificare se l'elenco dei ruoli include i ruoli richiesti.
Concedi i ruoli
-
Nella console Google Cloud vai alla pagina IAM.
Vai a IAM - Seleziona il progetto.
- Fai clic su Concedi l'accesso.
-
Nel campo Nuove entità, inserisci il tuo identificatore dell'utente. In genere si tratta dell'indirizzo email di un Account Google.
- Fai clic su Seleziona un ruolo, quindi cerca il ruolo.
- Per concedere altri ruoli, fai clic su Aggiungi un altro ruolo e aggiungi ogni ruolo successivo.
- Fai clic su Salva.
-
Configura Cloud Shell
-
Nella console Google Cloud , attiva Cloud Shell.
Viene avviata una sessione di Cloud Shell e viene visualizzato un prompt della riga di comando. L'inizializzazione della sessione può richiedere alcuni secondi.
- Imposta il progetto predefinito:
gcloud config set project PROJECT_IDSostituisci
PROJECT_IDcon l'ID progetto.
Configura l'ambiente
In questa sezione, preparerai le variabili di ambiente e clonerai il repository di esempio.
Imposta le variabili di ambiente per il progetto, i nomi dei cluster e la zona:
export PROJECT_ID=PROJECT_ID export KUBERNETES_CLUSTER_PREFIX=backup-gke-migration export TARGET_CLUSTER_PREFIX=restore-gke-migration export ZONE=us-central1-aSostituisci
PROJECT_IDcon l'ID progetto Google Cloud.Clona il repository di codice campione e vai alla directory:
git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples cd kubernetes-engine-samples/databases/backup-migration
Crea il cluster GKE di origine
Crea un cluster di zona con un pool di nodi che utilizza i tipi di macchine N2 e volumi Persistent Disk collegati.
Crea il cluster:
gcloud container clusters create ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --location ${ZONE} \ --node-locations ${ZONE} \ --shielded-secure-boot \ --shielded-integrity-monitoring \ --machine-type "e2-micro" \ --num-nodes "1"Crea un pool di nodi con tipi di macchina
n2-standard-4per il carico di lavoro di origine:gcloud container node-pools create regular-pool \ --cluster ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --machine-type n2-standard-4 \ --zone ${ZONE} \ --num-nodes 1Abilita il componente aggiuntivo Backup per GKE sul cluster di origine:
gcloud container clusters update ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --project=${PROJECT_ID} \ --location=${ZONE} \ --update-addons=BackupRestore=ENABLEDRecupera le credenziali per il cluster:
gcloud container clusters get-credentials ${KUBERNETES_CLUSTER_PREFIX}-cluster --zone ${ZONE}Verifica che l'agente Backup per GKE sia abilitato:
gcloud container clusters describe ${KUBERNETES_CLUSTER_PREFIX}-cluster \ --project=${PROJECT_ID} \ --location=${ZONE}L'output è simile al seguente e conferma che l'agente di backup è abilitato:
addonsConfig: gkeBackupAgentConfig: enabled: true
Esegui il deployment di MySQL con dati di esempio
Esegui il deployment di due database MySQL in spazi dei nomi separati per simulare un ambiente di produzione.
Crea gli spazi dei nomi
namespace-aenamespace-b:kubectl create namespace namespace-a kubectl create namespace namespace-bEsegui il deployment dei carichi di lavoro MySQL in
namespace-aenamespace-b:Esegui il deployment del file
mysql-a-deployment.yaml:kubectl apply -f manifests/02-mysql/mysql-a-deployment.yaml -n namespace-aIl seguente manifest crea un pod MySQL in
namespace-acon dischi SSD del disco permanente di cui è stato eseguito il provisioning dinamico sui nodiregular-pool. La password root è impostata sumigration:Esegui il deployment del file
mysql-b-deployment.yaml:kubectl apply -f manifests/02-mysql/mysql-b-deployment.yaml -n namespace-bIl seguente manifest crea un pod MySQL in
namespace-bcon dischi SSD del disco permanente di cui è stato eseguito il provisioning dinamico sui nodiregular-pool. La password root è impostata sumigration:
Esegui il deployment di un pod client MySQL per caricare set di dati di esempio:
kubectl apply -f manifests/02-mysql/mysql-client.yaml kubectl wait pods mysql-client --for condition=Ready --timeout=300sIl seguente manifest esegue il deployment di un pod client MySQL:
Connettiti al pod client:
kubectl exec -it mysql-client -- bashAll'interno del pod, scarica i set di dati di esempio Sakila e World:
curl --output dataset.tgz "https://downloads.mysql.com/docs/sakila-db.tar.gz" tar -xvzf dataset.tgz -C ./ curl --output world-db.tar.gz "https://downloads.mysql.com/docs/world-db.tar.gz" tar xvzf world-db.tar.gz -C ./Importa il set di dati Sakila nel database
mysql-a:mysql -u root -h mysql-a.namespace-a -p # Enter password: migration SOURCE /sakila-db/sakila-schema.sql; SOURCE /sakila-db/sakila-data.sql;Verifica i dati Sakila importati:
USE sakila; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'sakila';Esci da MySQL:
exitImporta il set di dati World nel database
mysql-b:mysql -u root -h mysql-b.namespace-b -p # Enter password: migration SOURCE /world-db/world.sql;Verifica i dati del mondo importati:
USE world; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'world';L'output è simile al seguente:
+-----------------+------------+ | table_name | table_rows | +-----------------+------------+ | city | 4079 | | country | 239 | | countrylanguage | 984 | +-----------------+------------+Esci da MySQL:
exitEsci dalla shell del pod client:
exit
Esegui il backup del cluster GKE
Esegui il backup dell'intero cluster, inclusi secret e volumi.
Crea un piano di backup:
gcloud beta container backup-restore backup-plans create main-plan \ --project=${PROJECT_ID} \ --location=us-central1 \ --cluster=projects/${PROJECT_ID}/locations/${ZONE}/clusters/${KUBERNETES_CLUSTER_PREFIX}-cluster \ --selected-namespaces=namespace-a,namespace-b,default \ --include-secrets \ --include-volume-data \ --target-rpo-minutes=1440 \ --backup-retain-days=7 \ --backup-delete-lock-days=3 \ --locked--selected-namespaces: esegue il backup di spazi dei nomi specifici per evitare conflitti con le risorse di sistema.--include-volume-data: contribuisce a garantire il backup dei dati del Persistent Disk.--target-rpo-minutes: configura la pianificazione del backup in base all'RPO (Recovery Point Objective). L'RPO è il periodo di tempo massimo accettabile durante il quale i dati potrebbero andare persi e determina la frequenza di backup. Con1440minuti (1 giorno), i backup sono programmati per essere eseguiti ogni giorno.
Crea un backup:
gcloud beta container backup-restore backups create first-backup \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan \ --wait-for-completionAttendi che l'output mostri
Backup state: SUCCEEDED.Verifica che il backup sia stato creato:
gcloud beta container backup-restore backups list \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan
Ripristino con la trasformazione Hyperdisk
Ripristina il backup in un nuovo cluster. Il ripristino trasforma lo spazio di archiviazione da Persistent Disk a Hyperdisk e sposta i carichi di lavoro sui nodi N4.
Crea il cluster GKE di destinazione su un nodo N4:
gcloud container clusters create ${TARGET_CLUSTER_PREFIX}-cluster \ --location ${ZONE} \ --node-locations ${ZONE} \ --shielded-secure-boot \ --shielded-integrity-monitoring \ --machine-type "e2-micro" \ --num-nodes "1"Crea un pool di nodi con tipi di macchina
n4-standard-4, necessari per Hyperdisk:gcloud container node-pools create hyperdisk-pool \ --cluster ${TARGET_CLUSTER_PREFIX}-cluster \ --machine-type n4-standard-4 \ --zone ${ZONE} \ --num-nodes 1Recupera le credenziali per il cluster di destinazione:
gcloud container clusters get-credentials ${TARGET_CLUSTER_PREFIX}-cluster --zone ${ZONE}Applica Hyperdisk
StorageClassdenominatobalanced-storage:kubectl apply -f manifests/01-storage-class/storage-class-hdb.yamlIl seguente manifest definisce un Hyperdisk
StorageClass:Esamina le regole di trasformazione nel file
manifests/03-transformation-rule/volume.yaml. Questo file definisce il modo in cui le risorse vengono modificate durante il ripristino:- Trasformazione PVC:modifica
storageClassNameinbalanced-storage(Hyperdisk). - Trasformazione del deployment:aggiorna l'affinità dei nodi per pianificare i pod sui nodi
n4-standard-4.
- Trasformazione PVC:modifica
Crea un piano di ripristino utilizzando queste regole di trasformazione:
gcloud beta container backup-restore restore-plans create main-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=projects/${PROJECT_ID}/locations/us-central1/backupPlans/main-plan \ --cluster=projects/${PROJECT_ID}/locations/${ZONE}/clusters/${TARGET_CLUSTER_PREFIX}-cluster \ --namespaced-resource-restore-mode=merge-replace-on-conflict \ --all-namespaces \ --cluster-resource-conflict-policy=use-existing-version \ --cluster-resource-scope-selected-group-kinds=cluster-resource-scope-all-group-kinds \ --volume-data-restore-policy=restore-volume-data-from-backup \ --transformation-rules-file=manifests/03-transformation-rule/volume.yamlEsegui il ripristino:
gcloud beta container backup-restore restores create first-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --restore-plan=main-restore \ --backup=projects/${PROJECT_ID}/locations/us-central1/backupPlans/main-plan/backups/first-backup
Verificare la migrazione
Verifica che le applicazioni siano in esecuzione sul nuovo cluster e che i dati siano intatti.
Controlla se i pod sono in esecuzione:
kubectl get pods -AConnettiti al pod client MySQL sul nuovo cluster:
# Verify that the client Pod is running kubectl apply -f manifests/02-mysql/mysql-client.yaml kubectl wait pods mysql-client --for condition=Ready --timeout=300s kubectl exec -it mysql-client -- bashVerifica il database Sakila ripristinato in
namespace-a:mysql -u root -h mysql-a.namespace-a -p # Password: migration USE sakila; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'sakila';Verifica il database World ripristinato in
namespace-b:mysql -u root -h mysql-b.namespace-b -p # Password: migration USE world; SELECT table_name, table_rows FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'world';
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina i cluster GKE:
gcloud container clusters delete ${KUBERNETES_CLUSTER_PREFIX}-cluster --location ${ZONE} --quiet gcloud container clusters delete ${TARGET_CLUSTER_PREFIX}-cluster --location ${ZONE} --quietElimina i piani di backup e ripristino:
# Delete the restore plan gcloud beta container backup-restore restore-plans delete main-restore \ --project=${PROJECT_ID} \ --location=us-central1 \ --quiet # Delete the Backup gcloud beta container backup-restore backups delete first-backup \ --project=${PROJECT_ID} \ --location=us-central1 \ --backup-plan=main-plan \ --quiet # Delete the backup plan gcloud beta container backup-restore backup-plans delete main-plan \ --project=${PROJECT_ID} \ --location=us-central1 \ --quiet
Passaggi successivi
- Scopri di più su Backup per GKE.
- Scopri di più sui pool di archiviazione Hyperdisk.