
Informazioni sull'aggregazione a finestra nelle query continue
Per richiedere assistenza o fornire un feedback su questa funzionalità, invia un'email all'indirizzo bq-continuous-queries-feedback@google.com.
Le query continue di BigQuery supportano aggregazioni e finestre come operazioni con stato. Le operazioni con stato consentono alle query continue di eseguire analisi complesse che richiedono la conservazione delle informazioni in più righe o intervalli di tempo. Questa funzionalità consente di calcolare le metriche nel tempo, ad esempio una media di 30 minuti, memorizzando i dati necessari in memoria durante l'esecuzione della query.
Le funzioni di windowing assegnano i dati a componenti logici, o finestre, in base all'ora di sistema, che indica l'ora di commit della transazione che ha apportato la modifica. In BigQuery, queste funzioni sono funzioni con valori di tabella (TVF) che restituiscono una tabella che include tutte le colonne originali e due colonne aggiuntive: window_start e window_end. Queste colonne identificano l'intervallo
di tempo per ogni finestra. Per saperne di più sulle operazioni con stato, consulta Operazioni con stato supportate.
Le TVF di finestre sono supportate solo con le query continue di BigQuery.
Le TVF di windowing sono diverse dalle chiamate delle funzioni finestra.
Funzioni di aggregazione supportate
Sono supportate le seguenti funzioni di aggregazione:
ANY_VALUEAPPROX_COUNT_DISTINCTAPPROX_QUANTILESAPPROX_TOP_COUNTAPPROX_TOP_SUMARRAY_AGGcon i seguenti requisiti:- È necessaria una clausola
LIMIT, con un valore massimo di 100. - Una clausola
ORDER BYè facoltativa.
- È necessaria una clausola
ARRAY_CONCAT_AGGAVGBIT_ANDBIT_ORBIT_XORCORRCOUNTCOUNTIFCOVAR_POPCOVAR_SAMPLOGICAL_ANDLOGICAL_ORMAXMAX_BYMINMIN_BYSTDDEVSTDDEV_POPSTDDEV_SAMPSTRING_AGGcon i seguenti requisiti:- È necessaria una clausola
LIMIT, con un valore massimo di 100. - Una clausola
ORDER BYè facoltativa.
- È necessaria una clausola
SUMVAR_POPVAR_SAMPVARIANCE
Funzioni di aggregazione non supportate
Le seguenti funzioni di aggregazione non sono supportate:
AVG(Differential Privacy)COUNT(Differential Privacy)- Funzioni contenenti espressioni
DISTINCT. GROUPINGPERCENTILE_CONT(Differential Privacy)ST_CENTROID_AGGST_EXTENTST_UNION_AGGSUM(Differential Privacy)
Funzione TUMBLE
La funzione TUMBLE assegna i dati a intervalli di tempo non sovrapposti (finestre
temporali) di dimensioni specificate. Ad esempio, una finestra di 5 minuti raggruppa gli eventi in intervalli discreti come [2026-01-01 12:00:00, 2026-01-01 12:05:00) e [2026-01-01 12:05:00, 2026-01-01 12:10:00). Una riga con un valore timestamp
2026-01-01 12:03:18 viene assegnata alla prima finestra. Poiché queste finestre sono
disgiunte e non si sovrappongono, ogni elemento con un timestamp viene assegnato a
esattamente una finestra.
Il seguente diagramma mostra come la funzione TUMBLE assegna gli eventi a intervalli di tempo non sovrapposti:
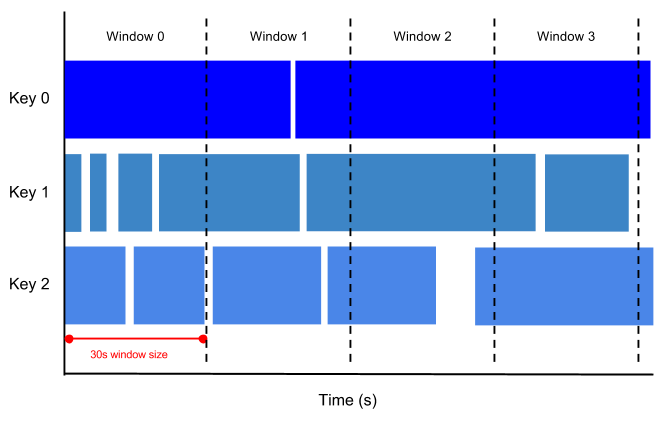
Puoi utilizzare questa funzione nell'elaborazione degli eventi in tempo reale per raggruppare gli eventi in intervalli di tempo prima di eseguire qualsiasi aggregazione.
Sintassi
TUMBLE(TABLE table, "timestamp_column", window_size)
Definizioni
table: il nome della tabella BigQuery. Deve essere una tabella BigQuery standard racchiusa nella funzioneAPPENDS. La parolaTABLEdeve precedere questo argomento.timestamp_column: un valore letteraleSTRINGche specifica il nome della colonna nella tabella di input che contiene l'ora dell'evento. I valori in questa colonna assegnano ogni riga a una finestra. La colonna_CHANGE_TIMESTAMP, che definisce l'ora di sistema BigQuery, è l'unicatimestamp_columnsupportata. Le colonne definite dall'utente non sono supportate.window_size: un valoreINTERVALche definisce la durata di ogni finestra a cascata. Le finestre possono durare al massimo 24 ore. Ad esempio:INTERVAL 30 SECOND.
Output
La funzione TUMBLE restituisce un output con le seguenti colonne:
Tutte le colonne della tabella di input al momento dell'esecuzione della query.
window_start: un valoreTIMESTAMPche indica l'ora di inizio inclusiva della finestra a cui appartiene il record.window_end: un valoreTIMESTAMPche indica l'ora di fine esclusiva della finestra a cui appartiene il record.
Materializzazione dell'output
In una query continua BigQuery, un'aggregazione in finestra non produce output per un intervallo di tempo specifico finché BigQuery non finalizza o chiude la finestra. Questo comportamento garantisce che BigQuery emetta i risultati aggregati solo dopo aver elaborato tutti i dati pertinenti per quella finestra.
Ad esempio, se esegui un'aggregazione della finestra TUMBLE di 5 minuti su una
tabella user_clickstream, i risultati per l'intervallo [10:15; 10:20) vengono emessi solo
dopo che la query elabora i record con un _CHANGE_TIMESTAMP di 10:20 o
successivo. In quel momento, BigQuery considera la finestra chiusa.
Inoltre, si apre una finestra e inizia ad accumulare dati nel momento in cui viene visualizzato il primo record appartenente a quell'intervallo di tempo specifico.
Mentre una finestra rimane aperta, BigQuery deve conservare i risultati dell'aggregazione intermedia. Ciò richiede l'archiviazione dello stato, il che significa che BigQuery deve conservare i risultati dell'aggregazione intermedia. Poiché questo stato deve rimanere nella memoria attiva fino alla chiusura della finestra, l'utilizzo di durate della finestra più lunghe o l'elaborazione di stream ad alto volume comporta un maggiore utilizzo degli slot per gestire la maggiore quantità di contesto archiviato. Per ulteriori informazioni, consulta Considerazioni sui prezzi.
Limitazioni
- La funzione
TUMBLEè supportata solo nelle query continue BigQuery. - Quando avvii una query continua con la funzione
TUMBLE, puoi utilizzare solo la funzioneAPPENDS. La funzioneCHANGESnon è supportata. - La colonna dell'ora di sistema BigQuery definita da
_CHANGE_TIMESTAMPè l'unicotimestamp_columnsupportato. Le colonne definite dall'utente non sono supportate. - Le finestre possono durare al massimo 24 ore.
- Quando viene eseguita la funzione finestra
TUMBLE, vengono prodotte due colonne di output aggiuntive:window_startewindow_end. Devi includere almeno una di queste colonne nell'istruzioneGROUP BYall'interno dell'istruzioneSELECTche esegue l'aggregazione della finestra. - Quando utilizzi la funzione
TUMBLEcon i join di query continui, devi rispettare tutte le limitazioni dei join di query continui.
Considerazioni sui prezzi
Le query continue di BigQuery vengono fatturate in base alla capacità di calcolo (slot) consumata durante l'esecuzione del job. Questo modello basato sul calcolo si applica anche alle operazioni stateful come il raggruppamento in finestre. Poiché il raggruppamento in finestre richiede a BigQuery di archiviare lo "stato" mentre la query è attiva, consuma risorse slot aggiuntive. In generale, più contesto o dati vengono archiviati all'interno di una finestra, ad esempio quando si utilizzano durate della finestra più lunghe, maggiore è lo stato che BigQuery deve conservare. Ciò porta a un maggiore utilizzo degli slot.
Esempi
La seguente query mostra come eseguire query su una tabella delle corse in taxi per ottenere una media streaming di corse, numero di passeggeri e tariffa media per taxi ogni 30 minuti ed esportare questi dati in una tabella in BigQuery:
INSERT INTO
`real_time_taxi_streaming.driver_stats`
WITH ride_completions AS (
SELECT
_CHANGE_TIMESTAMP as bq_changed_ts,
CAST(timestamp AS DATE) AS ride_date,
taxi_id,
meter_reading,
passenger_count
FROM
APPENDS(TABLE `real_time_taxi_streaming.taxirides`,
CURRENT_TIMESTAMP() - INTERVAL 10 MINUTE)
WHERE
ride_status = 'dropoff')
SELECT
ride_date,
window_end,
taxi_id,
COUNT(taxi_id) AS total_rides_per_half_hour,
ROUND(AVG(meter_reading),2) AS avg_fare_per_half_hour,
SUM(passenger_count) AS total_passengers_per_half_hour
FROM
tumble(TABLE ride_completions,"bq_changed_ts",INTERVAL 30 MINUTE)
GROUP BY
window_end,
ride_date,
taxi_id
Passaggi successivi
- Scopri come eseguire JOIN, aggregazioni e finestre.
- Scopri di più sulle query continue di BigQuery.
- Scopri come unire i dati di più stream.