
Entender a agregação de janelas em consultas contínuas
Para solicitar suporte ou enviar feedback sobre esse recurso, envie um e-mail para bq-continuous-queries-feedback@google.com.
As consultas contínuas do BigQuery oferecem suporte a agregações e janelas como operações com estado. As operações com estado permitem que as consultas contínuas realizem análises complexas que exigem a retenção de informações em várias linhas ou intervalos de tempo. Esse recurso permite calcular métricas ao longo do tempo, como uma média de 30 minutos, armazenando os dados necessários na memória enquanto a consulta é executada.
As funções de janelas atribuem dados a componentes lógicos ou janelas com base no horário do sistema, que indica o horário de confirmação da transação que fez a mudança. No BigQuery, essas funções são funções com valor de tabela (TVFs, na sigla em inglês) que retornam uma tabela que inclui todas as colunas originais e mais duas: window_start e window_end. Essas colunas identificam o intervalo de tempo de cada janela. Para mais
informações sobre operações com estado, consulte
Operações com estado com suporte.
As TVFs de janelas só são compatíveis com consultas contínuas do BigQuery queries.
As TVFs de janelas são diferentes das chamadas de função de janela.
Funções de agregação com suporte
Há suporte para as seguintes funções de agregação:
ANY_VALUEAPPROX_COUNT_DISTINCTAPPROX_QUANTILESAPPROX_TOP_COUNTAPPROX_TOP_SUMARRAY_AGGcom os seguintes requisitos:- Uma cláusula
LIMITé necessária, com um valor máximo de 100. - Uma cláusula
ORDER BYé opcional.
- Uma cláusula
ARRAY_CONCAT_AGGAVGBIT_ANDBIT_ORBIT_XORCORRCOUNTCOUNTIFCOVAR_POPCOVAR_SAMPLOGICAL_ANDLOGICAL_ORMAXMAX_BYMINMIN_BYSTDDEVSTDDEV_POPSTDDEV_SAMPSTRING_AGGcom os seguintes requisitos:- Uma cláusula
LIMITé necessária, com um valor máximo de 100. - Uma cláusula
ORDER BYé opcional.
- Uma cláusula
SUMVAR_POPVAR_SAMPVARIANCE
Funções de agregação sem suporte
As seguintes funções de agregação não têm suporte:
AVG(privacidade diferencial)COUNT(privacidade diferencial)- Funções que contêm expressões
DISTINCT. GROUPINGPERCENTILE_CONT(privacidade diferencial)ST_CENTROID_AGGST_EXTENTST_UNION_AGGSUM(privacidade diferencial)
A função TUMBLE
A função TUMBLE atribui dados a intervalos de tempo não sobrepostos (janelas de rolamento) de tamanho especificado. Por exemplo, uma janela de 5 minutos agrupa eventos em intervalos discretos, como [2026-01-01 12:00:00, 2026-01-01 12:05:00) e [2026-01-01 12:05:00, 2026-01-01 12:10:00). Uma linha com um valor de carimbo de data/hora 2026-01-01 12:03:18 é atribuída à primeira janela. Como essas janelas são disjuntas e não se sobrepõem, cada elemento com um carimbo de data/hora é atribuído a exatamente uma janela.
O diagrama a seguir mostra como a função TUMBLE atribui eventos a intervalos de tempo não sobrepostos:
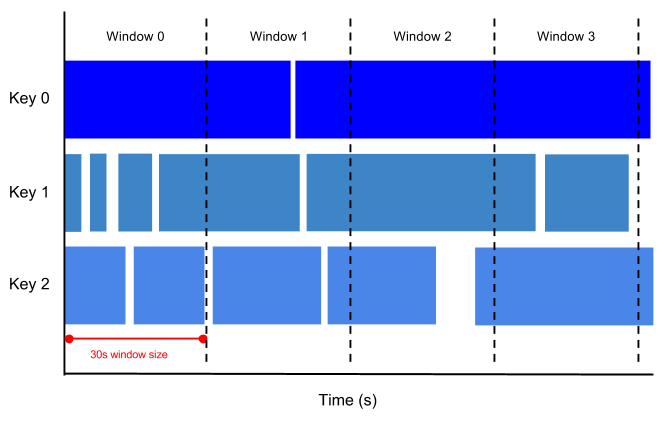
É possível usar essa função no processamento de eventos em tempo real para agrupar eventos por intervalos de tempo antes de realizar agregações.
Sintaxe
TUMBLE(TABLE table, "timestamp_column", window_size)
Definições
table: o nome da tabela do BigQuery. Essa precisa ser uma tabela padrão do BigQuery encapsulada na funçãoAPPENDS. A palavraTABLEprecisa preceder esse argumento.timestamp_column: um literalSTRINGque especifica o nome da coluna na tabela de entrada que contém o horário do evento. Os valores nessa coluna atribuem cada linha a uma janela. A coluna_CHANGE_TIMESTAMP, que define o horário do sistema do BigQuery, é a únicatimestamp_columncom suporte. Colunas definidas pelo usuário não têm suporte.window_size: um valorINTERVALque define a duração de cada janela de rolamento. Os tamanhos de janela podem ser de no máximo 24 horas. Por exemplo:INTERVAL 30 SECOND.
Saída
A função TUMBLE retorna uma saída com as seguintes colunas:
Todas as colunas da tabela de entrada no momento em que a consulta é executada.
window_start: um valorTIMESTAMPque indica o horário de início inclusivo da janela a que o registro pertence.window_end: um valorTIMESTAMPque indica o horário de término exclusivo da janela a que o registro pertence.
Materialização de saída
Em uma consulta contínua do BigQuery, uma agregação em janelas não produz saída para um intervalo de tempo específico até que o BigQuery finalize ou feche essa janela. Esse comportamento garante que o BigQuery emita os resultados agregados somente depois de processar todos os dados relevantes para essa janela.
Por exemplo, se você realizar uma agregação de janela TUMBLE de 5 minutos em uma tabela user_clickstream, os resultados do intervalo [10:15; 10:20) só serão emitidos depois que a consulta processar registros com um _CHANGE_TIMESTAMP de 10:20 ou posterior. Nesse momento, o BigQuery considera a janela fechada.
Além disso, uma janela abre e começa a acumular dados no momento em que o primeiro registro pertencente a esse intervalo de tempo específico aparece.
Enquanto uma janela permanece aberta, o BigQuery precisa preservar os resultados de agregação intermediários. Isso exige o armazenamento do estado, o que significa que o BigQuery precisa preservar os resultados de agregação intermediários. Como esse estado precisa permanecer na memória ativa até que a janela seja fechada, o uso de durações de janela mais longas ou o processamento de fluxos de alto volume leva a uma maior utilização de slots para gerenciar o aumento da quantidade de contexto armazenado. Para mais informações, consulte Considerações de preço.
Limitações
- A função
TUMBLEtem suporte apenas em consultas contínuas do BigQuery. - Ao iniciar uma consulta contínua com a função
TUMBLE, só é possível usar a funçãoAPPENDS. A funçãoCHANGESnão tem suporte. - A coluna de horário do sistema do BigQuery definida por
_CHANGE_TIMESTAMPé a únicatimestamp_columncom suporte. Colunas definidas pelo usuário não têm suporte. - Os tamanhos de janela podem ser de no máximo 24 horas.
- Quando a função de janelas
TUMBLEé executada, ela produz duas colunas de saída adicionais:window_startewindow_end. É necessário incluir pelo menos uma dessas colunas na instruçãoGROUP BYdentro da instruçãoSELECTque realiza a agregação de janelas. - Ao usar a função
TUMBLEcom junções de consultas contínuas, é necessário seguir todas as limitações de junção de consultas contínuas .
Considerações de preço
As consultas contínuas do BigQuery são cobradas com base na capacidade de computação (slots) consumida durante a execução do job. Esse modelo baseado em computação também se aplica a operações com estado, como janelas. Como as janelas exigem que o BigQuery armazene o "estado" enquanto a consulta está ativa, elas consomem recursos de slot adicionais. Em geral, quanto mais contexto ou dados armazenados em uma janela, como ao usar durações de janela mais longas, mais estado o BigQuery precisa preservar. Isso leva a uma maior utilização de slots.
Exemplos
A consulta a seguir mostra como consultar uma tabela de corridas de táxi para receber um número médio de corridas, número de passageiros e tarifa média por táxi a cada 30 minutos e exportar esses dados para uma tabela no BigQuery:
INSERT INTO
`real_time_taxi_streaming.driver_stats`
WITH ride_completions AS (
SELECT
_CHANGE_TIMESTAMP as bq_changed_ts,
CAST(timestamp AS DATE) AS ride_date,
taxi_id,
meter_reading,
passenger_count
FROM
APPENDS(TABLE `real_time_taxi_streaming.taxirides`,
CURRENT_TIMESTAMP() - INTERVAL 10 MINUTE)
WHERE
ride_status = 'dropoff')
SELECT
ride_date,
window_end,
taxi_id,
COUNT(taxi_id) AS total_rides_per_half_hour,
ROUND(AVG(meter_reading),2) AS avg_fare_per_half_hour,
SUM(passenger_count) AS total_passengers_per_half_hour
FROM
tumble(TABLE ride_completions,"bq_changed_ts",INTERVAL 30 MINUTE)
GROUP BY
window_end,
ride_date,
taxi_id
A seguir
- Saiba como realizar JOINs, agregações e janelas.
- Saiba mais sobre as consultas contínuas do BigQuery.
- Saiba como unir dados de vários fluxos.