
Fensteraggregation in kontinuierlichen Abfragen
Wenn Sie Support für dieses Feature anfordern oder Feedback dazu geben möchten, senden Sie eine E-Mail an bq-continuous-queries-feedback@google.com.
Kontinuierliche BigQuery-Abfragen unterstützen Aggregationen und Fensterfunktionen als zustandsbehaftete Vorgänge. Mit zustandsorientierten Vorgängen können kontinuierliche Abfragen komplexe Analysen durchführen, für die Informationen über mehrere Zeilen oder Zeitintervalle hinweg beibehalten werden müssen. Mit dieser Funktion können Sie Messwerte im Zeitverlauf berechnen, z. B. einen 30‑Minuten-Durchschnitt, indem Sie die erforderlichen Daten während der Ausführung der Abfrage im Arbeitsspeicher speichern.
Fensterfunktionen weisen Daten basierend auf der Systemzeit, die die Commit-Zeit der Transaktion angibt, mit der die Änderung vorgenommen wurde, logischen Komponenten oder Fenstern zu. In BigQuery sind diese Funktionen Tabellenwertfunktionen (Table-valued functions, TVFs), die eine Tabelle mit allen Originalspalten und zwei zusätzlichen Spalten zurückgeben: window_start und window_end. In diesen Spalten wird das Zeitintervall für jedes Fenster angegeben. Weitere Informationen zu zustandsbehafteten Vorgängen finden Sie unter Unterstützte zustandsbehaftete Vorgänge.
Fensterfunktionen werden nur für kontinuierliche BigQuery-Abfragen unterstützt.
TVFs für Fensterfunktionen unterscheiden sich von Fensterfunktionsaufrufen.
Unterstützte Aggregatfunktionen
Die folgenden Aggregatfunktionen werden unterstützt:
ANY_VALUEAPPROX_COUNT_DISTINCTAPPROX_QUANTILESAPPROX_TOP_COUNTAPPROX_TOP_SUMARRAY_AGGmit den folgenden Anforderungen:- Eine
LIMIT-Klausel ist erforderlich. Der Höchstwert ist 100. - Eine
ORDER BY-Klausel ist optional.
- Eine
ARRAY_CONCAT_AGGAVGBIT_ANDBIT_ORBIT_XORCORRCOUNTCOUNTIFCOVAR_POPCOVAR_SAMPLOGICAL_ANDLOGICAL_ORMAXMAX_BYMINMIN_BYSTDDEVSTDDEV_POPSTDDEV_SAMPSTRING_AGGmit den folgenden Anforderungen:- Eine
LIMIT-Klausel ist erforderlich. Der Höchstwert ist 100. - Eine
ORDER BY-Klausel ist optional.
- Eine
SUMVAR_POPVAR_SAMPVARIANCE
Nicht unterstützte Aggregatfunktionen
Die folgenden Aggregatfunktionen werden nicht unterstützt:
AVG(Differential Privacy)COUNT(Differential Privacy)- Funktionen mit
DISTINCT-Ausdrücken. GROUPINGPERCENTILE_CONT(Differential Privacy)ST_CENTROID_AGGST_EXTENTST_UNION_AGGSUM(Differential Privacy)
Die Funktion TUMBLE
Mit der Funktion TUMBLE werden Daten in nicht überlappende Zeitintervalle (rollierende Fenster) der angegebenen Größe aufgeteilt. Bei einem 5‑Minuten-Zeitfenster werden Ereignisse beispielsweise in diskrete Intervalle wie [2026-01-01 12:00:00, 2026-01-01 12:05:00) und [2026-01-01 12:05:00, 2026-01-01 12:10:00) gruppiert. Eine Zeile mit dem Zeitstempelwert 2026-01-01 12:03:18 wird dem ersten Fenster zugewiesen. Da diese Fenster disjunkt sind und sich nicht überschneiden, wird jedes Element mit einem Zeitstempel genau einem Fenster zugewiesen.
Das folgende Diagramm zeigt, wie die Funktion TUMBLE Ereignisse nicht überlappenden Zeitintervallen zuweist:
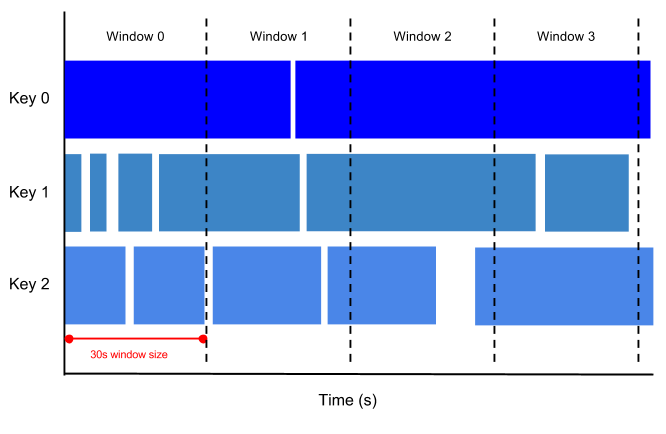
Sie können diese Funktion bei der Echtzeit-Ereignisverarbeitung verwenden, um Ereignisse nach Zeiträumen zu gruppieren, bevor Sie Aggregationen ausführen.
Syntax
TUMBLE(TABLE table, "timestamp_column", window_size)
Definitionen
table: Der Name der BigQuery-Tabelle. Dies muss eine BigQuery-Standardtabelle sein, die in die FunktionAPPENDSeingeschlossen ist. Diesem Argument muss das WortTABLEvorangestellt werden.timestamp_column: EinSTRING-Literal, das den Namen der Spalte in der Eingabetabelle angibt, die die Ereigniszeit enthält. Mit den Werten in dieser Spalte wird jeder Zeile ein Fenster zugewiesen. Die Spalte_CHANGE_TIMESTAMP, die die BigQuery-Systemzeit definiert, ist die einzige unterstütztetimestamp_column. Benutzerdefinierte Spalten werden nicht unterstützt.window_size: EinINTERVAL-Wert, der die Dauer jedes rollierenden Fensters definiert. Die Fenstergröße darf maximal 24 Stunden betragen. Beispiel:INTERVAL 30 SECOND.
Ausgabe
Die Funktion TUMBLE gibt eine Ausgabe mit den folgenden Spalten zurück:
Alle Spalten der Eingabetabelle zum Zeitpunkt der Ausführung der Abfrage.
window_start: EinTIMESTAMP-Wert, der die inklusive Startzeit des Zeitraums angibt, zu dem der Datensatz gehört.window_end: EinTIMESTAMP-Wert, der die ausschließliche Endzeit des Zeitraums angibt, zu dem der Datensatz gehört.
Ausgabematerialisierung
Bei einer kontinuierlichen BigQuery-Abfrage wird für ein bestimmtes Zeitintervall erst dann eine Ausgabe für eine aggregierte Fensterfunktion generiert, wenn BigQuery das Fenster fertiggestellt oder geschlossen hat. So wird sichergestellt, dass BigQuery die aggregierten Ergebnisse erst ausgibt, nachdem alle relevanten Daten für das Fenster verarbeitet wurden.
Wenn Sie beispielsweise eine 5‑Minuten-Fensteraggregation für eine user_clickstream-Tabelle ausführen, werden die Ergebnisse für das Intervall [10:15; 10:20) erst ausgegeben, nachdem in der Abfrage Datensätze mit einem _CHANGE_TIMESTAMP von 10:20 oder später verarbeitet wurden.TUMBLE Ab diesem Zeitpunkt betrachtet BigQuery das Zeitfenster als geschlossen.
Außerdem wird ein Fenster geöffnet, in dem Daten ab dem Zeitpunkt erfasst werden, an dem der erste Datensatz für diesen Zeitraum angezeigt wird.
Solange ein Fenster geöffnet bleibt, muss BigQuery die Zwischenergebnisse der Aggregation beibehalten. Dazu muss der Status gespeichert werden. Das bedeutet, dass BigQuery die Zwischenergebnisse der Aggregation beibehalten muss. Da dieser Status bis zum Schließen des Fensters im aktiven Speicher verbleiben muss, führt die Verwendung längerer Fensterzeiträume oder die Verarbeitung von Streams mit hohem Volumen zu einer höheren Slot-Auslastung, um die größere Menge an gespeichertem Kontext zu verwalten. Weitere Informationen finden Sie unter Preise.
Beschränkungen
- Die Funktion
TUMBLEwird nur in kontinuierlichen BigQuery-Abfragen unterstützt. - Wenn Sie eine kontinuierliche Abfrage mit der Funktion
TUMBLEstarten, können Sie nur die FunktionAPPENDSverwenden. Die FunktionCHANGESwird nicht unterstützt. - Die BigQuery-Systemzeitspalte, die durch
_CHANGE_TIMESTAMPdefiniert wird, ist die einzige unterstütztetimestamp_column. Benutzerdefinierte Spalten werden nicht unterstützt. - Die Fenstergröße darf maximal 24 Stunden betragen.
- Wenn die
TUMBLE-Fensterfunktion ausgeführt wird, werden zwei zusätzliche Ausgabespalten erstellt:window_startundwindow_end. Sie müssen mindestens eine dieser Spalten in dieGROUP BY-Anweisung innerhalb derSELECT-Anweisung einfügen, mit der die Fensteraggregation ausgeführt wird. - Wenn Sie die Funktion
TUMBLEmit kontinuierlichen Join-Abfragen verwenden, müssen Sie alle Einschränkungen für kontinuierliche Join-Abfragen beachten.
Kosten
Kontinuierliche BigQuery-Abfragen werden auf Grundlage der verbrauchten Rechenkapazität (Slots) während der Ausführung des Jobs abgerechnet. Dieses rechenbasierte Modell gilt auch für zustandsbehaftete Vorgänge wie Windowing. Da für die Fensterung in BigQuery der „Status“ gespeichert werden muss, während die Abfrage aktiv ist, werden zusätzliche Slot-Ressourcen benötigt. Je mehr Kontext oder Daten in einem Fenster gespeichert sind, z. B. bei Verwendung längerer Fensterzeiträume, desto mehr Status muss BigQuery beibehalten. Das führt zu einer höheren Auslastung der Slots.
Beispiele
Mit der folgenden Abfrage können Sie eine Tabelle mit Taxifahrten abfragen, um alle 30 Minuten einen Streamingdurchschnitt der Anzahl der Fahrten, der Anzahl der Fahrgäste und des durchschnittlichen Fahrpreises pro Taxi zu erhalten und diese Daten in eine Tabelle in BigQuery zu exportieren:
INSERT INTO
`real_time_taxi_streaming.driver_stats`
WITH ride_completions AS (
SELECT
_CHANGE_TIMESTAMP as bq_changed_ts,
CAST(timestamp AS DATE) AS ride_date,
taxi_id,
meter_reading,
passenger_count
FROM
APPENDS(TABLE `real_time_taxi_streaming.taxirides`,
CURRENT_TIMESTAMP() - INTERVAL 10 MINUTE)
WHERE
ride_status = 'dropoff')
SELECT
ride_date,
window_end,
taxi_id,
COUNT(taxi_id) AS total_rides_per_half_hour,
ROUND(AVG(meter_reading),2) AS avg_fare_per_half_hour,
SUM(passenger_count) AS total_passengers_per_half_hour
FROM
tumble(TABLE ride_completions,"bq_changed_ts",INTERVAL 30 MINUTE)
GROUP BY
window_end,
ride_date,
taxi_id
Nächste Schritte
- Weitere Informationen zum Ausführen von JOINs, Aggregationen und Windowing
- Weitere Informationen zu Continuous Queries in BigQuery
- Weitere Informationen zum Zusammenführen von Daten aus mehreren Streams