
Trabaja con funciones definidas por el usuario en Python
Una función definida por el usuario (UDF) de Python te permite implementar una función escalar en Python y usarla en una consulta en SQL. Las UDF de Python son similares a las UDF de SQL y JavaScript, pero con capacidades adicionales. Las UDF de Python te permiten instalar bibliotecas de terceros desde el índice de paquetes de Python (PyPI) y acceder a servicios externos con una conexión de recursos de Cloud.
Las UDF de Python se compilan y ejecutan en recursos administrados de BigQuery.
Limitaciones
python-3.11es el único tiempo de ejecución compatible.- No puedes crear una UDF de Python temporal.
- No puedes usar una UDF de Python con una vista materializada.
- Los resultados de una consulta que llama a una UDF de Python no se almacenan en caché porque siempre se supone que el valor de retorno de una UDF de Python no es determinista.
- No se admiten las cargas de trabajo aseguradas.
- No se admiten los siguientes tipos de datos:
JSON,RANGE,INTERVALyGEOGRAPHY. - Los contenedores que ejecutan UDF de Python solo se pueden configurar con hasta 4 vCPU y 16 GiB.
- No se admite la encriptación del código de las UDF de Python con claves de encriptación administradas por el cliente (CMEK).
- Las UDF de Python admiten los Controles del servicio de VPC, pero no las redes de VPC.
Roles obligatorios
Los roles de IAM requeridos dependen de si eres propietario o usuario de una UDF de Python.
Propietarios de UDF
Por lo general, el propietario de una UDF de Python crea o actualiza una UDF. También se requieren roles adicionales si creas una UDF de Python que hace referencia a una conexión de recursos de Cloud.
Esta conexión solo es necesaria si tu UDF usa la cláusula WITH CONNECTION para acceder a un servicio externo.
Para obtener los permisos que necesitas para crear o actualizar una UDF de Python, pídele a tu administrador que te otorgue los siguientes roles de IAM:
- Editor de datos de BigQuery (
roles/bigquery.dataEditor) en el conjunto de datos - Usuario de trabajo de BigQuery (
roles/bigquery.jobUser) en el proyecto - Administrador de conexión de BigQuery (
roles/bigquery.connectionAdmin) en el proyecto
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Estos roles predefinidos contienen los permisos necesarios para crear o actualizar una UDF de Python. Para ver los permisos exactos que son necesarios, expande la sección Permisos requeridos:
Permisos necesarios
Se requieren los siguientes permisos para crear o actualizar una UDF de Python:
-
Crea una UDF de Python con la instrucción
CREATE FUNCTION:bigquery.routines.createen el conjunto de datos -
Actualiza una UDF de Python con la instrucción
CREATE FUNCTION:bigquery.routines.updateen el conjunto de datos -
Ejecuta un trabajo de consulta de la instrucción
CREATE FUNCTION:bigquery.jobs.createen el proyecto -
Crea una nueva conexión de recurso de Cloud:
bigquery.connections.createen el proyecto. -
Usa una conexión en la instrucción
CREATE FUNCTION:bigquery.connections.delegateen la conexión
También puedes obtener estos permisos con roles personalizados o con otros roles predefinidos.
Para obtener más información sobre los roles en BigQuery, consulta Roles de IAM predefinidos.
Usuarios de UDF
Un usuario de una UDF de Python invoca una UDF creada por otra persona. También se requieren roles adicionales si invocas una UDF de Python que hace referencia a una conexión de recursos de Cloud.
Para obtener los permisos que necesitas para invocar una UDF de Python creada por otra persona, pídele a tu administrador que te otorgue los siguientes roles de IAM:
- Usuario de BigQuery (
roles/bigquery.user) en el proyecto - Visualizador de datos de BigQuery (
roles/bigquery.dataViewer) en el conjunto de datos - Usuario de conexión de BigQuery (
roles/bigquery.connectionUser) en la conexión
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Estos roles predefinidos contienen los permisos necesarios para invocar una UDF de Python creada por otra persona. Para ver los permisos exactos que son necesarios, expande la sección Permisos requeridos:
Permisos necesarios
Se requieren los siguientes permisos para invocar una UDF de Python creada por otra persona:
-
Para ejecutar un trabajo de consulta que haga referencia a una UDF de Python, haz lo siguiente:
bigquery.jobs.createen el proyecto -
Para invocar una UDF de Python creada por otra persona, sigue estos pasos:
bigquery.routines.geten el conjunto de datos -
Para ejecutar una UDF de Python que haga referencia a una conexión de recursos de Cloud, haz lo siguiente:
bigquery.connections.useen la conexión
También puedes obtener estos permisos con roles personalizados o con otros roles predefinidos.
Para obtener más información sobre los roles en BigQuery, consulta Roles de IAM predefinidos.
Crea una UDF de Python persistente
Sigue estas reglas cuando crees una UDF de Python:
El cuerpo de la UDF de Python debe ser un literal de cadena entre comillas que represente el código de Python. Para obtener más información sobre los literales de cadena entre comillas, consulta Formatos para literales entre comillas.
El cuerpo de la UDF de Python debe incluir una función de Python que se use en el argumento
entry_pointde la lista de opciones de la UDF de Python.Se debe especificar una versión del entorno de ejecución de Python en la opción
runtime_version. La única versión del entorno de ejecución de Python compatible espython-3.11. Para obtener una lista completa de las opciones disponibles, consulta la lista de opciones de la función para la instrucciónCREATE FUNCTION.
Para crear una UDF de Python persistente, usa la declaración CREATE FUNCTION sin la palabra clave TEMP o TEMPORARY. Para borrar una UDF de Python persistente, usa la sentencia DROP FUNCTION.
Ejemplo
Para ver un ejemplo de cómo crear una UDF de Python persistente, elige una de las siguientes opciones:
Console
En el siguiente ejemplo, se crea una UDF de Python persistente llamada multiplyInputs y se llama a la UDF desde una sentencia SELECT:
Ve a la página de BigQuery.
En el editor de consultas, ingresa la siguiente declaración
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyInputs(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="multiply") AS r''' def multiply(x, y): return x * y '''; -- Call the Python UDF. WITH numbers AS (SELECT 1 AS x, 5 as y UNION ALL SELECT 2 AS x, 10 as y UNION ALL SELECT 3 as x, 15 as y) SELECT x, y, `PROJECT_ID.DATASET_ID`.multiplyInputs(x, y) AS product FROM numbers;
Reemplaza PROJECT_ID.DATASET_ID con el ID de tu proyecto y el ID del conjunto de datos
Haz clic en Ejecutar.
En este ejemplo, se produce el siguiente resultado:
+-----+-----+--------------+ | x | y | product | +-----+-----+--------------+ | 1 | 5 | 5.0 | | 2 | 10 | 20.0 | | 3 | 15 | 45.0 | +-----+-----+--------------+
Permite trabajar con BigQuery DataFrames.
En el siguiente ejemplo, se usan BigQuery DataFrames para convertir una función personalizada en una UDF de Python:
Estado de compilación del contenedor
Cuando creas una UDF de Python con la instrucción CREATE FUNCTION, BigQuery crea o actualiza una imagen de contenedor basada en una imagen base. El contenedor se compila en la imagen base con tu código y las dependencias de paquetes especificadas.
La creación del contenedor es un proceso de larga duración. La primera consulta después de ejecutar la instrucción CREATE FUNCTION espera a que se complete la compilación de la imagen. Si no hay dependencias externas, la imagen de contenedor suele crearse en menos de un minuto.
El tamaño de todos los contenedores de UDF de Python por proyecto y región se limita a un total de 10 GiB. Para obtener más información, consulta Límites de las funciones definidas por el usuario para las UDF persistentes. La compilación del contenedor fallará si tu proyecto alcanzó la cuota.
Para ver el estado de la compilación de tu contenedor, elige una de las siguientes opciones:
Console
Ve a la página de BigQuery Studio.
En el panel izquierdo, expande tu proyecto y, luego, haz clic en Conjuntos de datos.
Haz clic en el vínculo para abrir el conjunto de datos que contiene tu UDF de Python.
En la página del conjunto de datos, haz clic en la pestaña Rutinas.
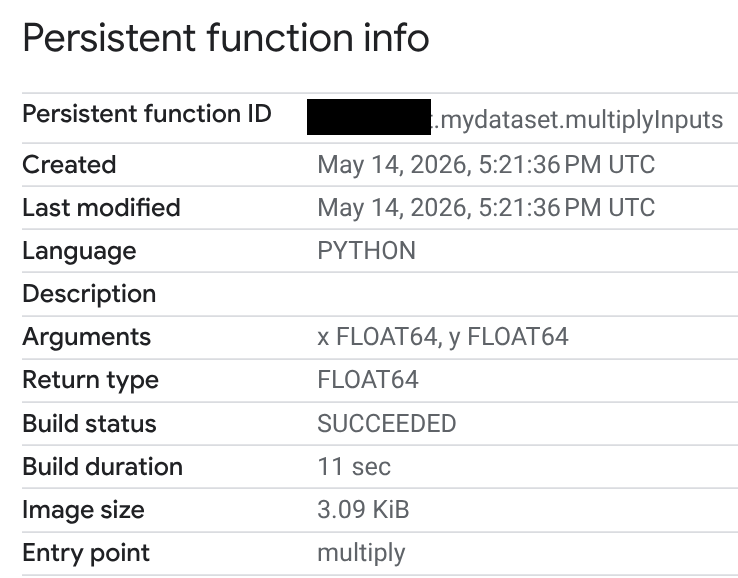
En la columna ID de rutina, haz clic en tu UDF de Python.
En la página Información sobre la función persistente, puedes ver el estado de la compilación, la duración de la compilación y el tamaño de la imagen. El estado de la compilación es uno de los siguientes:
- En curso
- Correcto
- Con errores
Si una compilación falla, la página de información de la función proporciona mensajes de error detallados para que puedas solucionar problemas, como errores de sintaxis o problemas para instalar paquetes externos.
SQL
Para consultar los campos de estado de compilación en la vista INFORMATION_SCHEMA.ROUTINES, sigue estos pasos:
Ve a la página de BigQuery Studio.
Cambia al editor de consultas o haz clic en Consulta en SQL.
Ingresa la siguiente consulta para recuperar los campos
BUILD_STATUSde la vistaINFORMATION_SCHEMA.ROUTINES. La columnaBUILD_STATUSes un tipoSTRUCTen GoogleSQL:SELECT build_status.* FROM `PROJECT_ID.DATASET_ID`.INFORMATION_SCHEMA.ROUTINES;Reemplaza PROJECT_ID.DATASET_ID con el ID de tu proyecto y el ID del conjunto de datos.
El resultado debe tener el siguiente aspecto. Se omiten los campos de error:
+---------------+--------------------------------+------------------------+------------------+ | build_state | build_state_update_time | build_duration_seconds | image_size_bytes | +---------------+--------------------------------+------------------------+------------------+ | SUCCEEDED | 2026-05-14 17:21:49.736000 UTC | 11 | 3167 | +---------------+--------------------------------+------------------------+------------------+
API
Consulta el estado de compilación del contenedor con RoutineBuildStatus en la API.
Crea una UDF de Python vectorizada
Puedes implementar tu UDF de Python para procesar un lote de filas en lugar de una sola fila usando la vectorización. La vectorización puede mejorar el rendimiento de las consultas. Puedes crear una UDF vectorizada con Pandas o Apache Arrow.
Para controlar el comportamiento del procesamiento por lotes, especifica la cantidad máxima de filas en cada lote con la opción max_batching_rows en la lista de opciones de CREATE OR REPLACE FUNCTION. Si especificas max_batching_rows, BigQuery determina la cantidad de filas en un lote, hasta el límite de max_batching_rows.
Si no se especifica max_batching_rows, la cantidad de filas para el procesamiento por lotes se determina automáticamente.
Cómo usar Pandas
Una UDF de Python vectorizada tiene un solo argumento pandas.DataFrame que debe anotarse. El argumento pandas.DataFrame tiene la misma cantidad de columnas que los parámetros de la UDF de Python definidos en la instrucción CREATE FUNCTION. Los nombres de las columnas en el argumento pandas.DataFrame tienen los mismos nombres que los parámetros de la UDF.
Tu función debe devolver un pandas.Series o un pandas.DataFrame de una sola columna con la misma cantidad de filas que la entrada.
En el siguiente ejemplo, se crea una UDF de Python vectorizada llamada multiplyInputs con dos parámetros: x y y:
Ve a la página de BigQuery.
En el editor de consultas, ingresa la siguiente declaración
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorized(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="vectorized_multiply") AS r''' import pandas as pd def vectorized_multiply(df: pd.DataFrame): return df['x'] * df['y'] ''';
Reemplaza PROJECT_ID.DATASET_ID con el ID de tu proyecto y el ID del conjunto de datos.
Llamar a la UDF es igual que en el ejemplo anterior.
Haz clic en Ejecutar.
Usa Apache Arrow
En el siguiente ejemplo, se usa la interfaz RecordBatch de Apache Arrow. Cuando usas la interfaz RecordBatch, la función pasa un lote de filas de columnas de igual longitud al punto de entrada.
En el siguiente ejemplo, se usa Apache Arrow para crear una UDF de Python vectorizada llamada multiplyVectorizedArrow.
Ve a la página de BigQuery.
En el editor de consultas, ingresa la siguiente declaración
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorizedArrow(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS( runtime_version="python-3.11", entry_point="vectorized_multiply_arrow" ) AS r''' import pyarrow as pa import pyarrow.compute as pc def vectorized_multiply_arrow(batch: pa.RecordBatch): # Access columns directly from the Arrow RecordBatch x = batch.column('x') y = batch.column('y') # Use pyarrow.compute for vectorized operations return pc.multiply(x, y) ''';
Reemplaza PROJECT_ID.DATASET_ID con el ID de tu proyecto y el ID del conjunto de datos.
Llamar a la UDF es igual que en los ejemplos anteriores.
Haz clic en Ejecutar.
Llama a una UDF de Python
Si tienes permiso para invocar una UDF de Python, puedes llamarla como cualquier otra función. Para usar una función definida en otro proyecto, usa el nombre completo de la función. Por ejemplo, para llamar a una función de extracción de XML llamada cw_xml_extract en otro proyecto, completa los siguientes pasos.
Console
Ve a la página de BigQuery.
En el editor de consultas, ingresa el siguiente ejemplo:
SELECT `PROJECT_ID.DATASET_ID`.`cw_xml_extract`(xml, '//title/text()') AS `title` FROM UNNEST([ STRUCT('''<book id="1"> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> </book>''' AS xml), STRUCT('''<book id="2"> <title>1984</title> <author>George Orwell</author> </book>''' AS xml), STRUCT('''<book id="3"> <title>Brave New World</title> <author>Aldous Huxley</author> </book>''' AS xml) ])Haz clic en Ejecutar.
En este ejemplo, se produce el siguiente resultado:
+--------------------------+ | title | +--------------------------+ | The Great Gatsby | | 1984 | | Brave New World | +--------------------------+
Permite trabajar con BigQuery DataFrames.
En el siguiente ejemplo, se usan los métodos BigQuery DataFrames
sql_scalar, read_gbq_function y apply para llamar a una UDF de Python:
Tipos de datos de UDF de Python admitidos
En la siguiente tabla, se define la asignación entre los tipos de datos de BigQuery, los tipos de datos de Python y los tipos de datos de Pandas:
| Tipo de datos de BigQuery | Tipo de datos integrado de Python que usa la UDF estándar | Tipo de datos de Pandas que usa la UDF vectorizada | Tipo de datos de PyArrow que se usa para ARRAY y STRUCT en la UDF vectorizada |
|---|---|---|---|
BOOL |
bool |
BooleanDtype |
DataType(bool) |
INT64 |
int |
Int64Dtype |
DataType(int64) |
FLOAT64 |
float |
FloatDtype |
DataType(double) |
STRING |
str |
StringDtype |
DataType(string) |
BYTES |
bytes |
binary[pyarrow] |
DataType(binary) |
TIMESTAMP |
Parámetro de función: Valor que devuelve la función: |
Parámetro de la función: Valor de retorno de la función: |
TimestampType(timestamp[us]), con zona horaria |
DATE |
datetime.date |
date32[pyarrow] |
DataType(date32[day]) |
TIME |
datetime.time |
time64[pyarrow] |
Time64Type(time64[us]) |
DATETIME |
datetime.datetime (sin zona horaria) |
timestamp[us][pyarrow] |
TimestampType(timestamp[us]), sin zona horaria |
ARRAY |
list |
list<...>[pyarrow], en el que el tipo de datos del elemento es pandas.ArrowDtype |
ListType |
STRUCT |
dict |
struct<...>[pyarrow], en el que el tipo de datos del campo es pandas.ArrowDtype |
StructType |
Versiones de entorno de ejecución compatibles
Las UDF de Python de BigQuery admiten el tiempo de ejecución de python-3.11. Esta versión de Python incluye algunos paquetes preinstalados adicionales. En el caso de las bibliotecas del sistema, verifica la imagen base del entorno de ejecución.
| Versión de entorno de ejecución | Versión de Python | Incluye |
|---|---|---|
| python-3.11 | Python 3.11 | numpy 1.26.3 pyarrow 14.0.2 pandas 2.1.4 python-dateutil 2.8.2 absl-py 2.0.0 pytz 2023.3.post1 tzdata 2023.4 six 1.16.0 |
Usa paquetes de terceros
Puedes usar la lista de opciones de CREATE FUNCTION para usar módulos que no sean los que proporciona la biblioteca estándar de Python y los paquetes preinstalados.
Puedes instalar paquetes desde el índice de paquetes de Python (PyPI) o importar archivos de Python desde Cloud Storage.
Instala un paquete desde el índice de paquetes de Python
Cuando instalas un paquete, debes proporcionar su nombre y, de manera opcional, puedes proporcionar su versión con los especificadores de versión de paquetes de Python.
Si el paquete está en el entorno de ejecución, se usa ese paquete, a menos que se especifique una versión en particular en la lista de opciones CREATE FUNCTION. Si no se especifica una versión del paquete y este no está en el tiempo de ejecución, se usa la versión disponible más reciente. Solo se admiten los paquetes con el formato binario de ruedas.
En el siguiente ejemplo, se muestra cómo crear una UDF de Python que instala el paquete scipy con la lista de opciones CREATE OR REPLACE FUNCTION:
Ve a la página de BigQuery.
En el editor de consultas, ingresa la siguiente declaración
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.area(radius FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='area_handler', runtime_version='python-3.11', packages=['scipy==1.15.3']) AS r""" import scipy def area_handler(radius): return scipy.constants.pi*radius*radius """; SELECT `PROJECT_ID.DATASET_ID`.area(4.5);
Reemplaza PROJECT_ID.DATASET_ID con el ID de tu proyecto y el ID del conjunto de datos.
Haz clic en Ejecutar.
Importa archivos de Python adicionales como bibliotecas
Puedes extender tus UDF de Python con la lista de opciones de funciones importando archivos de Python desde Cloud Storage.
En el código Python de tu UDF, puedes importar los archivos Python desde Cloud Storage como módulos con la instrucción import seguida de la ruta de acceso al objeto de Cloud Storage. Por ejemplo, si importas gs://BUCKET_NAME/path/to/lib1.py, tu instrucción de importación sería import
path.to.lib1.
El nombre de archivo de Python debe ser un identificador de Python. Cada nombre de folder en el nombre del objeto (después de /) debe ser un identificador de Python válido. Dentro del rango ASCII (U+0001…U+007F), se pueden usar los siguientes caracteres en los identificadores:
- Letras mayúsculas y minúsculas de la A a la Z
- Guiones bajos
- Los dígitos del cero al nueve, pero un número no puede aparecer como el primer carácter del identificador.
En el siguiente ejemplo, se muestra cómo crear una UDF de Python que importa el paquete de la biblioteca cliente lib1.py desde un bucket de Cloud Storage llamado my_bucket:
Ve a la página de BigQuery.
En el editor de consultas, ingresa la siguiente declaración
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.myFunc(a FLOAT64, b STRING) RETURNS STRING LANGUAGE python OPTIONS ( entry_point='compute', runtime_version='python-3.11', library=['gs://BUCKET_NAME/PATH/lib1.py']) AS r""" import path.to.lib1 as lib1 def compute(a, b): # doInterestingStuff is a function defined in # gs://BUCKET_NAME/PATH/lib1.py return lib1.doInterestingStuff(a, b); """;
Reemplaza lo siguiente:
- PROJECT_ID: el ID de tu proyecto
- DATASET_ID: Es el ID del conjunto de datos.
- BUCKET_NAME: Es el nombre del bucket de Cloud Storage que contiene
lib1.py. - PATH: Es la ruta de acceso al bucket de Cloud Storage.
Haz clic en Ejecutar.
Configura límites de contenedores para las UDF de Python
Puedes usar la lista de opciones de CREATE FUNCTION para especificar los límites de simultaneidad de solicitudes de CPU, memoria y contenedores para los contenedores que ejecutan UDF de Python.
De forma predeterminada, a los contenedores se les asignan los siguientes recursos:
- La memoria asignada es de
512Mi. - La CPU asignada es de
1.0CPU virtuales. - El límite de simultaneidad de solicitudes de contenedores es
80.
En el siguiente ejemplo, se crea una UDF de Python con la lista de opciones CREATE FUNCTION para especificar los límites del contenedor:
Ve a la página de BigQuery.
En el editor de consultas, ingresa la siguiente declaración
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.square_area(length FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='square_area', runtime_version='python-3.11', container_memory='CONTAINER_MEMORY', container_cpu=CONTAINER_CPU, container_request_concurrency=CONTAINER_REQUEST_CONCURRENCY) AS r""" def square_area(length): return length*length """; SELECT `PROJECT_ID.DATASET_ID`.square_area(4.5);
Reemplaza lo siguiente:
- PROJECT_ID.DATASET_ID: Tu ID del proyecto y el ID del conjunto de datos
- CONTAINER_MEMORY: Es el valor de la memoria en el siguiente formato:
<integer_number><unit>. La unidad debe ser uno de los siguientes valores:Mi(MiB),M(MB),Gi(GiB) oG(GB). Por ejemplo,2Gi. - CONTAINER_CPU: Es el valor de la CPU. Las UDF de Python admiten valores de CPU fraccionarios entre
0.33y1.0, y valores de CPU no fraccionarios de1,2y4. - CONTAINER_REQUEST_CONCURRENCY: Es la cantidad máxima de solicitudes simultáneas por instancia de contenedor de UDF de Python. El valor debe ser un número entero entre
1y1000.
Haz clic en Ejecutar.
Valores de CPU admitidos
Las UDF de Python admiten valores de CPU fraccionarios entre 0.33 y 1.0, y valores de CPU no fraccionarios de 1, 2 y 4. Los contenedores que ejecutan UDF de Python se pueden configurar con hasta 4 CPU virtuales. El valor predeterminado es 1.0. Los valores de entrada fraccionarios se redondean a dos decimales antes de aplicarse al contenedor.
Valores de memoria admitidos
Los contenedores de UDF de Python admiten valores de memoria en el siguiente formato:
<integer_number><unit>. La unidad debe ser uno de los siguientes valores: Mi, M, Gi o G. La cantidad mínima de memoria que puedes configurar es 256Mi. La cantidad máxima de memoria que puedes configurar es de 16Gi.
Según el valor de memoria que elijas, también debes especificar una cantidad adecuada de CPU. En la siguiente tabla, se muestran los valores mínimos y máximos de CPU para cada valor de memoria:
| Memoria | CPU mínima | CPU máxima |
|---|---|---|
De 256Mi a 512Mi |
0.33 |
2 |
Mayor que 512Mi y menor o igual que 1Gi |
0.5 |
2 |
Mayor que 1Gi y menor que 2Gi |
1 |
2 |
De 2Gi a 4Gi |
1 |
4 |
Mayor que 4Gi y hasta 8Gi |
2 |
4 |
Mayor que 8Gi y hasta 16Gi |
4 |
4 |
Como alternativa, si ya determinaste la cantidad de CPU que asignarás, puedes usar la siguiente tabla para determinar el rango de memoria adecuado:
| CPU | Memoria mínima | Máximo de memoria |
|---|---|---|
Menos de 0.5 |
256Mi |
512Mi |
0.5 a menos de 1 |
256Mi |
1Gi |
1 |
256Mi |
4Gi |
2 |
256Mi |
8Gi |
4 |
2Gi |
16Gi |
Llama a Google Cloud servicios en línea en código Python
Una UDF de Python accede a un servicio Google Cloud o a un servicio externo con la cuenta de servicio de conexión de recursos de Cloud. Se deben otorgar permisos a la cuenta de servicio de la conexión para acceder al servicio. Los permisos necesarios varían según el servicio al que se accede y las APIs a las que se llama desde tu código de Python.
Si creas una UDF de Python sin usar una conexión de recursos de Cloud, la función se ejecutará en un entorno que bloquea el acceso a la red. Si tu UDF accede a servicios en línea, debes crearla con una conexión de recursos de Cloud. Si no lo haces, la UDF no podrá acceder a la red hasta que se alcance un tiempo de espera de conexión interno. Cuando uses una conexión de Cloud Resource, implementa lo siguiente:
Tiempos de espera Cuando realices llamadas de red dentro de tu UDF de Python, siempre incluye un tiempo de espera razonable. Esto evita que la UDF se detenga indefinidamente si el servicio externo tarda en responder o no se puede acceder a él.
Usa el manejo de errores. Encapsula el código de la llamada de red en un bloque
try...exceptpara controlar correctamente los posibles errores, como los errores de conexión, los tiempos de espera o los códigos de estado de error de HTTP. Esto permite que tu UDF devuelva un error significativo o un valor de resguardo en lugar de provocar que la consulta falle o deje de responder.
En el siguiente ejemplo, se muestra cómo acceder al servicio de Cloud Translation desde una UDF de Python. En este ejemplo, hay dos proyectos: uno llamado my_query_project en el que creas la UDF y la conexión de recursos de Cloud, y otro en el que ejecutas Cloud Translation llamado my_translate_project.
Crea una conexión de recurso de Cloud
Primero, crea una conexión de recursos de Cloud en my_query_project. Para crear la conexión del recurso de Cloud, sigue estos pasos.
Console
Ve a la página de BigQuery.
En el panel de la izquierda, haz clic en Explorar.

Si no ves el panel izquierdo, haz clic en Expandir panel izquierdo para abrirlo.
En el panel Explorador, expande el nombre de tu proyecto y, luego, haz clic en Conexiones.
En la página Connections, haz clic en Create connection.
En Tipo de conexión, elige Modelos remotos de Vertex AI, funciones remotas, BigLake y Spanner (Cloud Resource).
En el campo ID de conexión, ingresa un nombre para tu conexión.
En Tipo de ubicación, selecciona una ubicación para tu conexión. La conexión debe estar ubicada junto con tus otros recursos, como los conjuntos de datos.
Haz clic en Crear conexión.
Haz clic en Ir a la conexión.
En el panel Información de conexión, copia el ID de la cuenta de servicio para usarlo en un paso posterior.
SQL
Usa la sentencia CREATE CONNECTION:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, escribe la siguiente oración:
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
Reemplaza lo siguiente:
-
CONNECTION_NAME: Es el nombre de la conexión en formatoPROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_IDoCONNECTION_ID. Si se omiten el proyecto o la ubicación, se infieren del proyecto y la ubicación en los que se ejecuta la instrucción. -
FRIENDLY_NAME(opcional): Es un nombre descriptivo para la conexión. -
DESCRIPTION(opcional): Es una descripción de la conexión.
-
Haz clic en Ejecutar.
Si deseas obtener información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
bq
En un entorno de línea de comandos, crea una conexión:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
El parámetro
--project_idanula el proyecto predeterminado.Reemplaza lo siguiente:
REGION: tu región de conexiónPROJECT_ID: ID del proyecto de Google CloudCONNECTION_ID: Es un ID para tu conexión.
Cuando creas un recurso de conexión, BigQuery crea una cuenta de servicio del sistema única y la asocia con la conexión.
Solución de problemas: Si recibes el siguiente error de conexión, actualiza el SDK de Google Cloud:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
Recupera y copia el ID de cuenta de servicio para usarlo en un paso posterior:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
El resultado es similar a lo siguiente:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Python
Antes de probar este ejemplo, sigue las instrucciones de configuración para Python incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Python.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Node.js
Antes de probar este ejemplo, sigue las instrucciones de configuración para Node.js incluidas en la guía de inicio rápido de BigQuery sobre cómo usar bibliotecas cliente. Para obtener más información, consulta la documentación de referencia de la API de BigQuery para Node.js.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
Terraform
Usa el recurso google_bigquery_connection.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para bibliotecas cliente.
En el siguiente ejemplo, se crea una conexión de recursos de Cloud llamada my_cloud_resource_connection en la región US:
Para aplicar tu configuración de Terraform en un proyecto de Google Cloud , completa los pasos de las siguientes secciones.
Prepara Cloud Shell
- Inicia Cloud Shell
-
Establece el Google Cloud proyecto predeterminado en el que deseas aplicar tus configuraciones de Terraform.
Solo necesitas ejecutar este comando una vez por proyecto y puedes ejecutarlo en cualquier directorio.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Las variables de entorno se anulan si configuras valores explícitos en el archivo de configuración de Terraform.
Prepara el directorio
Cada archivo de configuración de Terraform debe tener su propio directorio (también llamado módulo raíz).
-
En Cloud Shell, crea un directorio y un archivo nuevo dentro de ese directorio. El nombre del archivo debe tener la extensión
.tf, por ejemplo,main.tf. En este instructivo, el archivo se denominamain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Si sigues un instructivo, puedes copiar el código de muestra en cada sección o paso.
Copia el código de muestra en el
main.tfrecién creado.De manera opcional, copia el código de GitHub. Esto se recomienda cuando el fragmento de Terraform es parte de una solución de extremo a extremo.
- Revisa y modifica los parámetros de muestra que se aplicarán a tu entorno.
- Guarda los cambios.
-
Inicializa Terraform. Solo debes hacerlo una vez por directorio.
terraform init
De manera opcional, incluye la opción
-upgradepara usar la última versión del proveedor de Google:terraform init -upgrade
Aplica los cambios
-
Revisa la configuración y verifica que los recursos que creará o actualizará Terraform coincidan con tus expectativas:
terraform plan
Corrige la configuración según sea necesario.
-
Para aplicar la configuración de Terraform, ejecuta el siguiente comando y, luego, escribe
yescuando se te solicite:terraform apply
Espera hasta que Terraform muestre el mensaje “¡Aplicación completa!”.
- Abre tu proyecto Google Cloud para ver los resultados. En la consola de Google Cloud , navega a tus recursos en la IU para asegurarte de que Terraform los haya creado o actualizado.
Otorga acceso a la cuenta de servicio de la conexión
Necesitas el ID de la cuenta de servicio que copiaste antes cuando configures los permisos para la conexión. Cuando creas un recurso de conexión, BigQuery crea una cuenta de servicio del sistema única y la asocia con la conexión.
Para otorgar a la cuenta de servicio de conexión de recursos de Cloud acceso a tus proyectos, otórgale el rol de consumidor de uso del servicio (roles/serviceusage.serviceUsageConsumer) en my_query_project y el rol de usuario de la API de Cloud Translation (roles/cloudtranslate.user) en my_translate_project.
Console
Ir a la página IAM.
Verifica que
my_query_projectesté seleccionado.Haz clic en Otorgar acceso.
En el campo Principales nuevas, ingresa el ID de la cuenta de servicio de la conexión de recursos en la nube que copiaste antes.
En el campo Selecciona un rol, elige Uso del servicio y, luego, selecciona Consumidor de uso del servicio.
Haz clic en Guardar.
En el selector de proyectos, elige
my_translate_project.Ir a la página IAM.
Haz clic en Otorgar acceso.
En el campo Principales nuevas, ingresa el ID de la cuenta de servicio de la conexión de recursos en la nube que copiaste antes.
En el campo Selecciona un rol, elige Cloud Translation y, luego, selecciona Usuario de la API de Cloud Translation.
Haz clic en Guardar.
SQL
Usa la sentencia GRANT para otorgar el rol de consumidor de Service Usage (roles/serviceusage.serviceUsageConsumer) a la cuenta de servicio en my_query_project:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, escribe la siguiente sentencia:
GRANT `roles/serviceusage.serviceUsageConsumer` ON PROJECT `my_query_project` TO "connection:SERVICE_ACCOUNT_ID";
Reemplaza
SERVICE_ACCOUNT_IDpor el ID de la cuenta de servicio que copiaste antes.Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
Usa la sentencia GRANT para otorgar el rol de usuario de la API de Cloud Translation (roles/cloudtranslate.user) en my_translate_project:
En la consola de Google Cloud , ve a la página BigQuery.
En el editor de consultas, escribe la siguiente sentencia:
GRANT `roles/cloudtranslate.user` ON PROJECT `my_translate_project` TO "connection:SERVICE_ACCOUNT_ID";
Reemplaza
SERVICE_ACCOUNT_IDpor el ID de la cuenta de servicio que copiaste antes.Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
Crea una UDF de Python que llame al servicio de Cloud Translation
En my_query_project, crea una UDF de Python que llame al servicio de Cloud Translation con tu conexión de recursos de Cloud.
En la consola de Google Cloud , ve a la página BigQuery.
Ingresa la siguiente sentencia
CREATE FUNCTIONen el editor de consultas:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.translate_to_es(x STRING) RETURNS STRING LANGUAGE python WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID` OPTIONS (entry_point='do_translate', runtime_version='python-3.11', packages=['google-cloud-translate>=3.11', 'google-api-core']) AS r""" from google.api_core.retry import Retry from google.cloud import translate project = "my_translate_project" translate_client = translate.TranslationServiceClient() def do_translate(x : str) -> str: response = translate_client.translate_text( request={ "parent": f"projects/PROJECT_ID/locations/us-central1", "contents": [x], "target_language_code": "es", "mime_type": "text/plain", }, retry=Retry(), ) return response.translations[0].translated_text """; -- Call the UDF. WITH text_table AS (SELECT "Hello" AS text UNION ALL SELECT "Good morning" AS text UNION ALL SELECT "Goodbye" AS text) SELECT text, `PROJECT_ID.DATASET_ID`.translate_to_es(text) AS translated_text FROM text_table;
Reemplaza lo siguiente:
PROJECT_ID: El ID del proyecto.DATASET_ID: El ID del conjunto de datos.REGION: La región de tu conexión.CONNECTION_ID: Es el ID de la conexión.
Haz clic en Ejecutar.
El resultado debe verse de la siguiente manera:
+--------------------------+-------------------------------+ | text | translated_text | +--------------------------+-------------------------------+ | Hello | Hola | | Good morning | Buen dia | | Goodbye | Adios | +--------------------------+-------------------------------+
Usa los Controles del servicio de VPC
Las UDF de Python heredan el perímetro de los Controles del servicio de VPC del proyecto que ejecuta el trabajo de consulta. Este perímetro protege tus trabajos del robo de datos y garantiza que las interacciones de servicio sean seguras.
Cuando invocas una UDF de Python dentro del perímetro de Controles del servicio de VPC, tiene la siguiente conectividad de red:
- Las UDF de Python que no usan una conexión de recursos de Cloud están completamente aisladas. Se bloquea todo el tráfico saliente.
- Las UDF de Python que usan una conexión de recursos de Cloud están bloqueadas para el acceso a Internet público. Las UDF de Python solo pueden acceder a los Google Cloud servicios que admiten los Controles del servicio de VPC. Se bloquea el tráfico saliente a cualquier destino que no sea
restricted.googleapis.com.
Configura UDFs de Python para acceder a servicios de Google Cloud de forma segura dentro de los Controles del servicio de VPC
Para acceder a los servicios de Google Cloud desde las UDF de Python y, al mismo tiempo, aplicar los Controles del servicio de VPC, sigue estos pasos:
- Crea la UDF de Python con la cláusula
WITH CONNECTIONde la sentencia CREATE FUNCTION. - Incluye el proyecto de BigQuery en el que se ejecuta el trabajo de consulta y el proyecto de servicio de destino en el perímetro de servicio. Como alternativa, configura un puente perimetral.
- Agrega la API del servicio de destino a la configuración del perímetro. Por ejemplo,
translate.googleapis.comsi te conectas a la API de Cloud Translation.
Para obtener más detalles sobre la configuración de un perímetro de Controles del servicio de VPC, consulta los siguientes recursos:
- Controles del servicio de VPC para BigQuery
- Descripción general de los Controles del servicio de VPC
Prácticas recomendadas
Cuando crees UDFs de Python, sigue estas prácticas recomendadas:
- Optimiza la lógica de tus consultas para el procesamiento por lotes. Las estructuras de consultas complejas pueden inhabilitar el procesamiento por lotes. Esto obliga a un procesamiento lento, fila por fila, lo que aumenta significativamente la latencia en conjuntos de datos grandes.
- Optimiza la carga útil de datos. El tamaño de las filas individuales puede afectar la eficiencia de la función de procesamiento por lotes. Mantén cada fila lo más pequeña posible para maximizar la cantidad de filas que se pueden procesar en un solo lote.
- Configura los límites de contenedores de manera eficiente. La escalabilidad es una función de la CPU, la memoria y la simultaneidad de solicitudes. Verifica las métricas de supervisión para ajustar la configuración del contenedor.
Si el uso de CPU es alto, aumenta la asignación de CPU con el límite de
container_cpuo reduce la simultaneidad de solicitudes de contenedores con el límite decontainer_request_concurrency. - Cuando uses el ajuste iterativo, comienza con los valores predeterminados. Si el rendimiento no es óptimo, analiza las métricas de supervisión para identificar cuellos de botella específicos.
- Implementa tiempos de espera de la API. Cuando tu UDF de Python acceda a Internet, establece un tiempo de espera en la llamada a la API para evitar comportamientos inesperados. Un ejemplo de acceso a Internet es la lectura desde un bucket de Cloud Storage.
Consulta las métricas de las UDF de Python
Las UDF de Python exportan métricas a Cloud Monitoring. Estas métricas te ayudan a supervisar varios aspectos del estado operativo y el consumo de recursos de tu UDF, lo que te brinda estadísticas sobre el rendimiento y el comportamiento de tus instancias de UDF.
Tipo de recurso supervisado
Las métricas de las UDF de Python se registran en el siguiente tipo de recurso de Cloud Monitoring:
- Tipo:
bigquery.googleapis.com/ManagedRoutineInvocation - Nombre visible: Invocación de rutina administrada de BigQuery
- Etiquetas:
resource_container: Es el ID del proyecto en el que se ejecutó el trabajo de consulta.location: Es la ubicación en la que se ejecutó el trabajo de consulta.query_job_id: Es el ID del trabajo de consulta que invocó la UDF de Python.routine_project_id: Es el ID del proyecto en el que se almacena la rutina invocada.routine_dataset_id: Es el ID del conjunto de datos en el que se almacena la rutina invocada.routine_id: Es el ID de la rutina invocada.
Métricas
Las siguientes métricas están disponibles para el tipo de recurso bigquery.googleapis.com/ManagedRoutineInvocation:
| Métrica | Descripción | Unidad | Tipo de valor |
|---|---|---|---|
bigquery.googleapis.com/managed_routine/python/cpu_utilizations |
Cuando se invoca una UDF de Python, esta métrica muestra la distribución del uso de CPU en todas las instancias de UDF de Python para el trabajo de la consulta. | Un valor de porcentaje | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/memory_utilizations |
Cuando se invoca una UDF de Python, esta métrica muestra la distribución del uso de memoria en todas las instancias de UDF de Python para el trabajo de la consulta. | Un valor de porcentaje | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/max_request_concurrencies |
Esta métrica muestra la distribución de la cantidad máxima de solicitudes simultáneas que entrega cada instancia de UDF de Python. | Recuento | DISTRIBUTION |
Ver métricas
Para ver las métricas de tus UDF de Python, elige una de las opciones de las siguientes secciones.
Detalles del trabajo
Para ver las métricas de las UDF de Python de un trabajo de consulta específico, sigue estos pasos:
Ve a la página de BigQuery.
Haz clic en Historial de trabajos.
En la columna ID del trabajo, haz clic en el ID del trabajo de la consulta.
En la página Detalles del trabajo de consulta, haz clic en Panel de Cloud Monitoring. Este vínculo muestra un panel filtrado para mostrar las métricas de la UDF de Python para el trabajo.
Explorador de métricas
Para ver las métricas de las UDF de Python en el Explorador de métricas, sigue estos pasos:
Ve a la página Explorador de métricas de Cloud Monitoring.
Haz clic en Seleccionar una métrica y, en el campo Filtro, escribe
BigQuery Managed Routine Invocationobigquery.googleapis.com/ManagedRoutineInvocation.Elige Bigquery Managed Routine > Managed_routine.
Haz clic en cualquiera de las métricas disponibles, como las siguientes:
- Uso de CPU de la instancia
- Uso de memoria de la instancia
- Máx. de solicitudes simultáneas
Haz clic en Aplicar.
De forma predeterminada, las métricas se muestran en un gráfico.
Puedes filtrar y agrupar las métricas con las etiquetas definidas en los tipos de recursos de Monitoring. Para filtrar las métricas, sigue estos pasos:
En el campo Filtro, elige un tipo de recurso, como
query_job_idoroutine_id.En el campo Valor, ingresa el ID del trabajo o de la rutina, o elige uno de la lista.
Paneles de Cloud Monitoring
Para ver las métricas de las UDF de Python con los paneles de supervisión, sigue estos pasos:
Ve a la página Paneles de Cloud Monitoring.
Haz clic en el panel Supervisión de consultas de rutina administrada de BigQuery.
En este panel, se proporciona una descripción general de las métricas clave de todas tus UDF.
Para filtrar este panel, sigue estos pasos:
Haz clic en Filtrar.
En la lista Filtrar por recurso, elige una opción, como ID del proyecto, ubicación, ID de rutina o ID de trabajo.
Ubicaciones admitidas
Las UDF de Python son compatibles con todas las ubicaciones regionales y multirregionales de BigQuery.
Precios
Los cargos por las UDF de Python se facturan con el SKU de los servicios de BigQuery.
Los cargos incluyen lo siguiente:
Compilación o recompilación de la imagen del contenedor de la UDF Este cargo es proporcional a la duración requerida para compilar la imagen correspondiente con el código y las dependencias del cliente.
- Si usas la API de Rutinas, la duración de la compilación más reciente se encuentra en el campo
BuildStatus. También puedes ver la duración de la compilación en la columnaBuildStatusde la vistaINFORMATION_SCHEMA.ROUTINES. - Para ver el costo total de las compilaciones por proyecto, puedes filtrar tu informe de facturación con los siguientes elementos:
- Key:
goog-bq-feature-type - Value:
MANAGED_ROUTINE_BUILD
- Key:
- Si usas la API de Rutinas, la duración de la compilación más reciente se encuentra en el campo
A los clientes de UDF de Python también se les cobra el costo de invocar una UDF de Python. Este cargo es proporcional a la cantidad de procesamiento y memoria que se consumen cuando se invoca la UDF de Python.
- Para ver los costos de las UDF de Python por consulta, puedes consultar el campo
ExternalServiceCostscon la API de Job. También puedes ver los costos por búsqueda en la columnaexternal_service_costsde la vistaINFORMATION_SCHEMA.JOBSy aplicar el siguiente filtro:'external_service_costs.external_service="MANAGED_ROUTINE_EXECUTION"'. - Para ver el costo total de ejecutar UDF de Python por proyecto, puedes filtrar el informe de facturación con los siguientes parámetros:
- Key:
goog-bq-feature-type - Value:
MANAGED_ROUTINE_EXECUTION
- Key:
- Para ver los costos de las UDF de Python por consulta, puedes consultar el campo
Si las UDF de Python generan salida de red externa o de Internet, también verás un cargo de salida de Internet de nivel Premium según los SKU de salida de BigQuery.
Cuotas
Consulta Cuotas y límites de UDF.