
Trabaja con datos de trama usando Earth Engine en BigQuery
En este documento,
se explica cómo combinar datos de trama y vectoriales con la
ST_REGIONSTATS función,
que usa Google Earth Engine para obtener acceso a datos de imágenes y de trama
en BigQuery.
Descripción general
Una trama es una cuadrícula bidimensional de píxeles, a cada uno de los cuales se le asigna uno o más valores llamados bandas. Por ejemplo, cada píxel podría corresponder a un kilómetro cuadrado en particular en la superficie de la Tierra y tener bandas para la temperatura promedio y la precipitación promedio. Los datos de trama incluyen imágenes satelitales y otros datos continuos basados en cuadrículas, como pronósticos meteorológicos y cobertura terrestre. Muchos formatos de imagen comunes, como los archivos PNG o JPEG, se formatean como datos de trama.
Los datos de trama suelen contrastarse con los datos vectoriales, en los que los datos se describen mediante líneas o curvas en lugar de una cuadrícula rectangular fija. Por ejemplo, puedes usar el tipo de datos GEOGRAPHY en BigQuery para describir los límites de países, ciudades o regiones.
Los datos geoespaciales de trama y vectoriales suelen combinarse con una operación de estadísticas zonales, que calcula un agregado de todos los valores de trama dentro de una región vectorial determinada. Por ejemplo, es posible que desees calcular lo siguiente:
- Calidad del aire promedio en una colección de ciudades
- Potencial solar para una colección de polígonos de edificios
- Riesgo de incendio resumido a lo largo de los corredores de líneas eléctricas en áreas boscosas
BigQuery se destaca en el procesamiento de datos vectoriales, y Google Earth Engine se destaca en el procesamiento de datos de trama. Puedes usar la
ST_REGIONSTATS función de geografía
para combinar datos de trama con Earth Engine con tus datos vectoriales almacenados
en BigQuery.
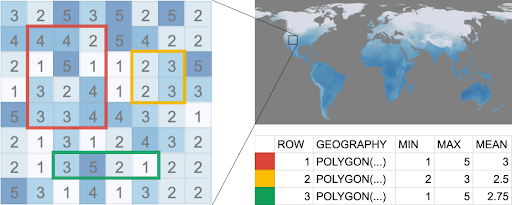
Antes de comenzar
Para usar la función
ST_REGIONSTATSen tus consultas, habilita la API de Earth Engine.Opcional: Para suscribirte y usar los datos publicados en BigQuery sharing (anteriormente Analytics Hub) con la función
ST_REGIONSTATS, habilita la API de Analytics Hub.
Permisos necesarios
Para obtener los permisos que
necesitas para llamar a la ST_REGIONSTATS función,
pídele a tu administrador que te otorgue los
siguientes roles de IAM en tu proyecto:
- Visualizador de recursos de Earth Engine (
roles/earthengine.viewer) - Consumidor de Service Usage (
roles/serviceusage.serviceUsageConsumer) -
Suscríbete a conjuntos de datos en BigQuery sharing:
Editor de datos de BigQuery (
roles/bigquery.dataEditor)
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Estos roles predefinidos contienen
los permisos necesarios para llamar a la función ST_REGIONSTATS. Para ver los permisos exactos que son
necesarios, expande la sección Permisos requeridos:
Permisos requeridos
Se requieren los siguientes permisos para llamar a la función ST_REGIONSTATS:
-
earthengine.computations.create -
serviceusage.services.use -
bigquery.datasets.create
También puedes obtener estos permisos con roles personalizados o otros roles predefinidos.
Busca datos de trama
El parámetro raster_id en la función ST_REGIONSTATS es una cadena que especifica la fuente de tus datos de trama. En las siguientes secciones, se explica cómo encontrar y dar formato al ID de trama.
Tablas de imágenes de BigQuery
Puedes usar BigQuery sharing (anteriormente Analytics Hub) para descubrir y acceder a conjuntos de datos de trama en BigQuery. Para usar BigQuery sharing, debes habilitar la API de Analytics Hub y asegurarte de tener los permisos necesarios para ver y suscribirte a las fichas y los intercambios de datos.
Google Earth Engine publica conjuntos de datos disponibles públicamente que contienen datos de trama en las multirregiones US y EU. Para
suscribirte
a un conjunto de datos de Earth Engine con datos de trama, sigue estos pasos:
Ve a la página Sharing (Analytics Hub).
Haz clic en Search listings.
En el campo Search for listings, ingresa
"Google Earth Engine".Haz clic en un conjunto de datos al que quieras suscribirte.
Haz clic en Suscribirse.
Opcional: Actualiza los campos Project o Linked dataset name.
Haz clic en Guardar. El conjunto de datos vinculado se agrega a tu proyecto.
El conjunto de datos contiene una tabla de imágenes que
almacena metadatos para una colección de imágenes de trama que sigue
la especificación de elementos STAC. Una tabla de imágenes es
análoga a una colección de imágenes de Earth Engine
(ImageCollection).
Cada fila de la tabla corresponde a una sola imagen de trama, con columnas que contienen propiedades y metadatos de la imagen. El ID de trama de cada imagen se almacena en la columna assets.image.href. Haz referencia a las imágenes en tus consultas con este ID como el valor del parámetro raster_id.
Filtra la tabla con columnas de propiedades para seleccionar imágenes o subconjuntos de imágenes específicos que cumplan con tus criterios. Para obtener más información sobre las bandas disponibles, el tamaño de los píxeles y las definiciones de propiedades, abre la tabla y haz clic en la pestaña Image details.
Cada tabla de imágenes incluye una tabla *_metadata correspondiente que proporciona información de respaldo para la tabla de imágenes.
Por ejemplo, el conjunto de datos ERA5-Land proporciona estadísticas diarias de variables climáticas y está disponible públicamente. La tabla climate contiene varios IDs de trama. La siguiente consulta filtra la tabla de imágenes con la columna start_datetime para obtener el ID de trama de la imagen correspondiente al 1 de enero de 2025 y calcula la temperatura promedio de cada país con la banda temperature_2m:
SQL
WITH SimplifiedCountries AS (
SELECT
ST_SIMPLIFY(geometry, 10000) AS simplified_geometry,
names.primary AS name
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
subtype = 'country'
)
SELECT
sc.simplified_geometry AS geometry,
sc.name,
ST_REGIONSTATS(
sc.simplified_geometry,
(SELECT assets.image.href
FROM `LINKED_DATASET_NAME.climate`
WHERE start_datetime = '2025-01-01 00:00:00'),
'temperature_2m'
).mean - 273.15 AS mean_temperature
FROM
SimplifiedCountries AS sc
ORDER BY
mean_temperature DESC;
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configura las ADC para un entorno de desarrollo local.
GeoTIFF de Cloud Storage
GeoTIFF es un formato de archivo común para almacenar datos geoespaciales de trama. La función
ST_REGIONSTATS admite datos de trama almacenados en el
formato GeoTIFF optimizado para la nube
(COG) en buckets de
Cloud Storage que se encuentran en las siguientes regiones:
- Multirregión de
US us-central1- Multirregión de
EU europe-west1
Proporciona el URI de Cloud Storage como el ID de trama, como gs://bucket/folder/raster.tif.
Recursos de imágenes de Earth Engine
La función ST_REGIONSTATS admite el paso de una ruta de acceso de recursos de imágenes de Earth Engine para el argumento raster_id. Los datos de trama de Earth Engine están disponibles como imágenes individuales o colecciones de imágenes. Estos datos existen en la región US y solo son compatibles con las consultas que se ejecutan en la región US. Para encontrar el ID de trama de una imagen, sigue estos pasos:
- Busca en el catálogo de datos de Earth Engine el conjunto de datos que te interesa.
Para abrir la página de descripción de esa entrada, haz clic en el nombre del conjunto de datos. El fragmento de Earth Engine describe una sola imagen o una colección de imágenes.
Si el fragmento de Earth Engine tiene el formato
ee.Image('IMAGE_PATH'), el ID de trama es'ee://IMAGE_PATH'.Si el fragmento de Earth Engine tiene el formato
ee.ImageCollection('IMAGE_COLLECTION_PATH'), puedes usar el editor de código de Earth Engine para filtrar ImageCollection a una sola imagen. Usa el métodoee.Image.get('system:id')para imprimir elIMAGE_PATHvalor de esa imagen en la consola. El ID de trama es'ee://IMAGE_PATH'.
Pesos de píxeles
Puedes especificar un peso, a veces denominado valor de máscara,
para el parámetro include en la ST_REGIONSTATS
función que determina cuánto
ponderar cada píxel en los cálculos. Los valores de peso deben estar entre 0 y 1.
Los pesos fuera de este rango se establecen en el límite más cercano, ya sea 0 o 1.
Un píxel se considera válido si tiene un peso superior a 0. Un peso de 0 indica un píxel no válido. Los píxeles no válidos suelen representar datos faltantes o no confiables, como áreas oscurecidas por nubes, anomalías del sensor, errores de procesamiento o ubicaciones fuera de un límite definido.
Si no especificas un peso, cada píxel se pondera automáticamente según la proporción del píxel que se encuentra dentro de la geometría, lo que permite la inclusión proporcional en las estadísticas zonales. Si la geometría es inferior a 1/256 del tamaño del píxel, el peso del píxel es 0. En estos casos, se muestra null para todas las estadísticas, excepto count y area, que son 0.
Si un píxel que se interseca parcialmente tiene un peso del argumento include a ST_REGIONSTATS, BigQuery usa el mínimo de ese peso y la fracción del píxel que se interseca con la región.
Los valores de peso no tienen la misma precisión que los valores FLOAT64. En la práctica, su valor real puede diferir del valor usado en los cálculos hasta en 1/256 (aproximadamente el 0.4%).
Puedes proporcionar una expresión con la sintaxis de expresión de imágenes de Earth Engine
en tu include argumento para ponderar píxeles de forma dinámica según criterios específicos dentro de las bandas de trama. Por ejemplo, la siguiente expresión restringe los cálculos a los píxeles en los que la banda probability supera el 70%:
include => 'probability > 0.7'
Si el conjunto de datos incluye una banda de factor de peso, puedes usarla con la siguiente sintaxis:
include => 'weight_factor_band_name'
Tamaño de píxeles y escala de análisis
Una imagen geoespacial de trama es una cuadrícula de píxeles que corresponde a alguna ubicación en la superficie de la Tierra. El tamaño de píxeles de una trama, a veces llamado la escala, es el tamaño nominal de un borde de un píxel en el sistema de referencia de coordenadas de la cuadrícula. Por ejemplo, una trama con una resolución de 10 metros tiene píxeles de 10 metros por 10 metros. El tamaño de píxeles informado original puede variar mucho entre los conjuntos de datos, desde menos de 1 metro hasta más de 20 kilómetros.
Cuando se usa la función ST_REGIONSTATS para calcular estadísticas zonales, el tamaño de píxeles de los datos de trama es una consideración fundamental. Por ejemplo, agregar datos de trama de alta resolución en la región de un país puede ser intensivo en términos de procesamiento y, además, innecesariamente detallado. Por el contrario, agregar datos de baja resolución en la región, como parcelas de la ciudad, podría no proporcionar suficientes detalles.
Para obtener resultados significativos y eficientes de tu análisis, te recomendamos que elijas un tamaño de píxeles adecuado para el tamaño de tus polígonos y el objetivo de tu análisis. Puedes encontrar el tamaño de píxeles de cada conjunto de datos de trama en la sección de descripción de las tablas de imágenes en BigQuery sharing.
Si cambias el tamaño de los píxeles, se modifica la cantidad de píxeles que se intersecan con una geografía determinada, lo que afecta los resultados y su interpretación. No recomendamos cambiar el tamaño de los píxeles para los análisis de producción. Sin embargo, si estás creando un prototipo de consulta, aumentar el tamaño de los píxeles puede reducir el tiempo de ejecución y el costo de la consulta, en especial para los datos de alta resolución.
Para cambiar el tamaño de los píxeles, establece la scale en el argumento options de la función ST_REGIONSTATS. Por ejemplo,
para calcular estadísticas sobre píxeles de 1,000 metros, usa
options => JSON '{"scale":1000}'
El cálculo de estadísticas para polígonos que son mucho más pequeños que los píxeles de la trama puede producir resultados inexactos o nulos. En ese caso,
una alternativa es reemplazar el polígono por su punto centroide con
ST_CENTROID.
Facturación
Cuando ejecutas una consulta, el uso de la función ST_REGIONSTATS se factura por separado del resto de la consulta porque Earth Engine calcula los resultados de la llamada a función. Se te factura este uso en horas de ranura en la SKU de servicios de BigQuery, independientemente de si usas la facturación a pedido o las reservas. Para ver el
importe facturado por las llamadas de BigQuery a Earth Engine,
consulta tu informe de facturación
y usa etiquetas para filtrar por
la clave de etiqueta goog-bq-feature-type, con el valor EARTH_ENGINE. Si falla la función ST_REGIONSTATS, no se te facturará ningún cálculo de Earth Engine que se haya usado.
Para cada consulta, puedes usar el
jobs.get método
en la API de BigQuery para ver la siguiente información:
- El
slotMscampo, que muestra la cantidad de milisegundos de ranura que consumió Earth Engine cuando elexternalServicecampo esEARTH_ENGINEy elbillingMethodcampo esSERVICES_SKU. - El campo
totalServicesSkuSlotMs, que muestra la cantidad total de milisegundos de ranura que usan todos los servicios externos de BigQuery que se facturan en la SKU de servicios de BigQuery.
También puedes consultar el campo total_services_sku_slot_ms en la
INFORMATION_SCHEMA.JOBS vista
para encontrar los milisegundos de ranura totales que consumen los servicios externos facturados en la
SKU de servicios de BigQuery.
Factores de costo
Los siguientes factores afectan el uso de procesamiento cuando ejecutas la función ST_REGIONSTATS:
- La cantidad de filas de entrada
- La imagen de trama que usas Algunas tramas son composiciones creadas a partir de colecciones de imágenes de origen en el catálogo de datos de Earth Engine, y los recursos de procesamiento para producir el resultado compuesto varían.
- La resolución de la imagen
- El tamaño y la complejidad de la geografía de entrada, la cantidad de píxeles que se intersecan con la geografía y la cantidad de mosaicos de imágenes y bytes que lee Earth Engine
La ubicación de la geografía de entrada en la Tierra en relación con las imágenes de origen, la proyección y la resolución de la imagen
- Las proyecciones de imágenes pueden deformar los píxeles, en especial los píxeles en latitudes altas o muy fuera del área de cobertura prevista de la imagen.
- Para las tramas compuestas, la cantidad de imágenes de origen que se intersecan con la geografía de entrada puede variar regionalmente y con el tiempo. Por ejemplo, algunos satélites producen más imágenes en latitudes bajas o altas, según su órbita y los parámetros de recopilación de datos, o pueden omitir imágenes según las condiciones atmosféricas cambiantes.
El uso de fórmulas en los argumentos
includeoband_name, y la cantidad de bandas que implicanEl almacenamiento en caché de los resultados anteriores
Controla los costos
Para controlar los costos asociados con la función ST_REGIONSTATS, puedes ajustar la cuota que controla la cantidad de tiempo de ranura que la función puede consumir. El valor predeterminado es de 350 horas de ranura por día.
Cuando veas tus cuotas,
filtra la lista Métrica a
earthengine.googleapis.com/bigquery_slot_usage_time
para ver la cuota de Earth Engine asociada con las llamadas de
BigQuery. Para obtener más información, consulta las cuotas de funciones de trama de
BigQuery
en la documentación de Google Earth Engine.
Regiones admitidas
Las consultas que llaman a la función ST_REGIONSTATS deben ejecutarse en una de las siguientes regiones:
- Multirregión de
US us-central1us-central2- Multirregión de
EU europe-west1
¿Qué sigue?
- Prueba el instructivo que te muestra cómo usar datos de trama para analizar la temperatura.
- Obtén más información sobre las funciones de geografía en BigQuery.
- Obtén más información para trabajar con datos geoespaciales.