
Mendapatkan insight performa kueri
Grafik eksekusi untuk kueri adalah representasi visual dari langkah-langkah yang dilakukan BigQuery untuk menjalankan kueri. Dokumen ini menjelaskan cara menggunakan grafik eksekusi kueri untuk mendiagnosis masalah performa kueri dan melihat insight performa kueri.
BigQuery menawarkan performa kueri yang kuat, tetapi juga merupakan sistem terdistribusi yang kompleks dengan banyak faktor internal dan eksternal yang dapat memengaruhi kecepatan kueri. Sifat deklaratif SQL juga dapat menyembunyikan kompleksitas eksekusi kueri. Artinya, saat kueri Anda berjalan lebih lambat dari yang diperkirakan, atau lebih lambat dari yang sebelumnya, memahami apa yang terjadi bisa menjadi tantangan.
Grafik eksekusi kueri menyediakan antarmuka grafis dinamis untuk memeriksa paket kueri dan detail performa kueri. Anda dapat meninjau grafik eksekusi kueri untuk kueri yang sedang berjalan atau telah selesai.
Anda juga dapat menggunakan grafik eksekusi kueri untuk mendapatkan insight performa kueri. Insight performa memberikan saran terbaik untuk membantu Anda meningkatkan performa kueri. Karena performa kueri memiliki banyak aspek, insight performa mungkin hanya memberikan gambaran sebagian dari performa kueri secara keseluruhan.
Izin yang diperlukan
Untuk menggunakan grafik eksekusi kueri, Anda harus memiliki izin berikut:
bigquery.jobs.getbigquery.jobs.listAll
Izin ini tersedia melalui peran Identity and Access Management (IAM) bawaan BigQuery berikut:
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
Struktur grafik eksekusi
Grafik eksekusi kueri memberikan tampilan grafis dari paket kueri di konsol. Setiap kotak mewakili tahap dalam rencana kueri seperti berikut:
- Input: Membaca data dari tabel atau memilih kolom tertentu
- Gabung: Menggabungkan data dari dua tabel berdasarkan kondisi
JOIN - Agregasi: Melakukan penghitungan seperti
SUM - Urutkan: Mengurutkan hasil
Tahap terdiri dari
langkah-langkah
yang menjelaskan operasi individual yang dijalankan oleh setiap pekerja dalam satu tahap. Anda dapat mengklik tahap untuk membukanya dan melihat langkah-langkahnya. Tahapan juga mencakup
informasi pengaturan waktu relatif dan absolut.
Nama tahap merangkum langkah-langkah yang dilakukan. Misalnya, tahap dengan
join dalam namanya berarti bahwa langkah utama dalam tahap tersebut adalah operasi JOIN. Nama tahapan yang memiliki + di akhir berarti tahapan tersebut melakukan langkah-langkah penting tambahan. Misalnya, tahap dengan JOIN+ dalam namanya berarti tahap tersebut melakukan operasi gabungan dan langkah-langkah penting lainnya.
Garis yang menghubungkan tahap mewakili pertukaran data perantara antar-tahap. BigQuery menyimpan data perantara dalam memori pengacakan saat tahap sedang dieksekusi. Angka di tepi menunjukkan perkiraan jumlah baris yang dipertukarkan antar-tahapan. Kuota memori pengacakan berkorelasi dengan jumlah slot yang dialokasikan ke akun. Jika kuota shuffle terlampaui, memori shuffle dapat meluap ke disk dan menyebabkan performa kueri menurun secara drastis.
Melihat insight performa kueri
Konsol
Ikuti langkah-langkah berikut untuk melihat insight performa kueri:
Buka halaman BigQuery di konsol Google Cloud .
Di panel kiri, klik Explorer:

Jika Anda tidak melihat panel kiri, klik Luaskan panel kiri untuk membuka panel.
Di panel Explorer, klik Histori tugas.
Klik Personal History atau Project History.
Dalam daftar tugas, identifikasi tugas kueri yang Anda minati. Klik Tindakan, lalu pilih Lihat tugas di editor.
Pilih tab Execution graph untuk melihat representasi grafis setiap tahap kueri:
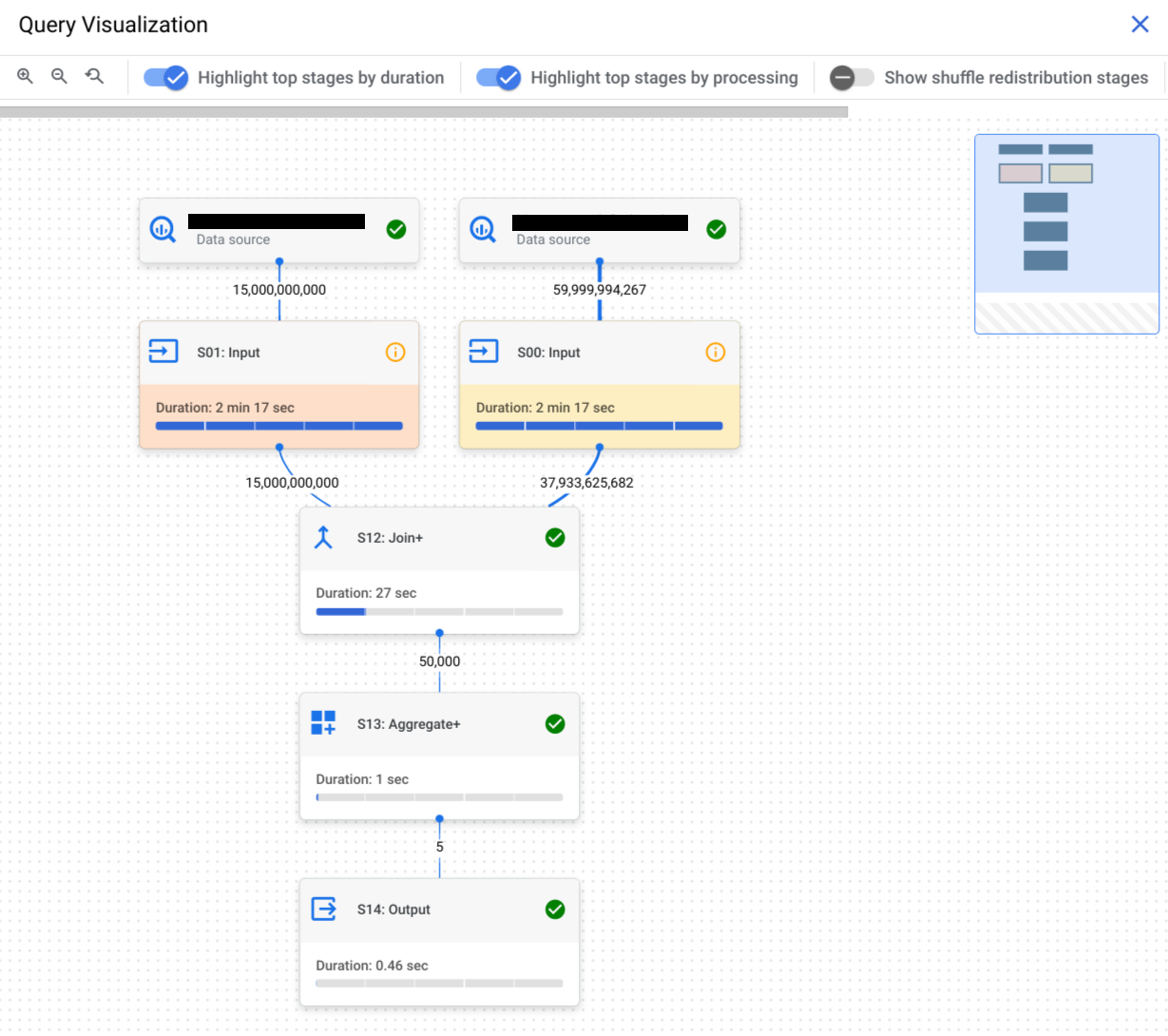
Untuk menentukan apakah tahap kueri memiliki insight performa, lihat ikon yang ditampilkan. Tahapan yang memiliki ikon informasi memiliki insight performa. Tahapan yang memiliki ikon centang tidak.
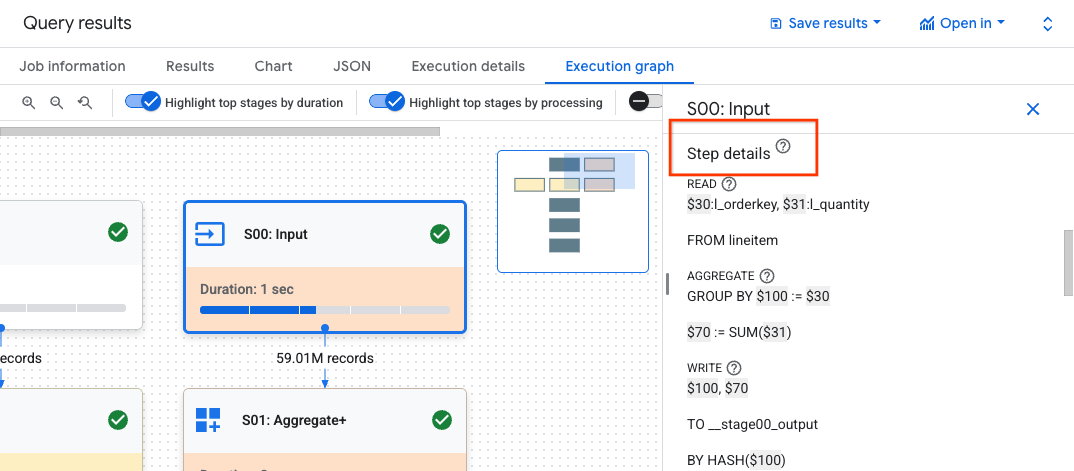
Klik tahap untuk membuka panel detail tahap, tempat Anda dapat melihat informasi berikut:
- Informasi paket kueri untuk tahap.
- Langkah-langkah yang dieksekusi dalam stage.
- Insight performa yang berlaku.
Opsional: Jika Anda sedang memeriksa kueri yang sedang berjalan, klik Sinkronkan untuk memperbarui grafik eksekusi sehingga mencerminkan status kueri saat ini.

Opsional: Untuk menandai tahap teratas berdasarkan durasi tahap pada grafik, klik Tandai tahap teratas berdasarkan durasi.

Opsional: Untuk menandai tahap teratas berdasarkan waktu slot yang digunakan pada grafik, klik Tandai tahap teratas berdasarkan pemrosesan.

Opsional: Untuk menyertakan tahap redistribusi pengacakan pada grafik, klik Tampilkan tahap redistribusi pengacakan.

Gunakan opsi ini untuk menampilkan tahap repartisi dan penggabungan yang disembunyikan dalam grafik eksekusi default.
Tahapan partisi ulang dan penggabungan diperkenalkan saat kueri berjalan, dan digunakan untuk meningkatkan distribusi data di seluruh pekerja yang memproses kueri. Karena tahap ini tidak terkait dengan teks kueri Anda, tahap ini disembunyikan untuk menyederhanakan paket kueri yang ditampilkan.
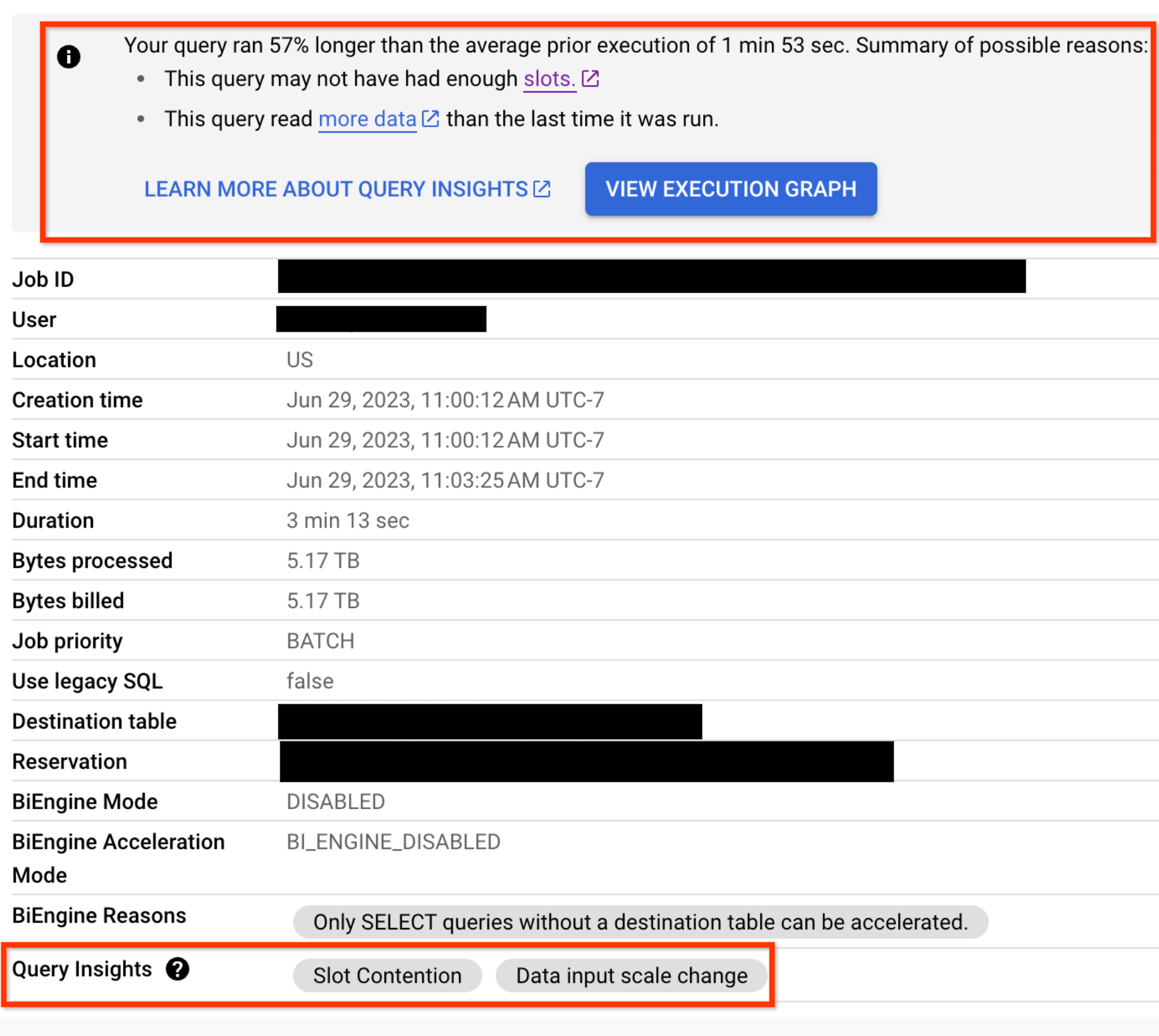
Untuk kueri apa pun yang memiliki masalah regresi performa, insight performa juga ditampilkan di tab Informasi Tugas untuk kueri tersebut:
SQL
Di konsol Google Cloud , buka halaman BigQuery.
Di editor kueri, masukkan pernyataan berikut:
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota OR bi_engine_reasons IS NOT NULL OR high_cardinality_joins IS NOT NULL OR partition_skew IS NOT NULL UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
Klik Run.
Untuk mengetahui informasi selengkapnya tentang cara menjalankan kueri, lihat artikel Menjalankan kueri interaktif.
API
Anda bisa mendapatkan insight performa kueri dalam format non-grafis dengan
memanggil metode API jobs.list
dan memeriksa informasi
JobStatistics2
yang ditampilkan.
Menafsirkan insight performa kueri
Gunakan bagian ini untuk mempelajari lebih lanjut arti insight performa dan cara menindaklanjutinya.
Insight performa ditujukan untuk dua audiens:
Analis: Anda menjalankan kueri dalam project. Anda tertarik untuk mengetahui alasan kueri yang pernah Anda jalankan berjalan lebih lambat secara tidak terduga, dan untuk mendapatkan tips tentang cara meningkatkan performa kueri. Anda memiliki izin yang dijelaskan dalam Izin yang diperlukan.
Administrator data lake atau data warehouse: Anda mengelola resource dan reservasi BigQuery organisasi Anda. Anda memiliki izin yang terkait dengan peran BigQuery Admin.
Setiap bagian berikut memberikan panduan tentang tindakan yang dapat Anda lakukan untuk mengatasi insight performa yang Anda terima, berdasarkan peran yang Anda miliki.
Persaingan slot
Saat Anda menjalankan kueri, BigQuery akan mencoba membagi pekerjaan yang diperlukan oleh kueri Anda menjadi tugas. Tugas adalah satu irisan data yang dimasukkan ke dan dikeluarkan dari tahap. Satu slot mengambil tugas dan mengeksekusi slice data tersebut untuk tahap. Idealnya, slot BigQuery menjalankan tugas ini secara paralel untuk mencapai performa tinggi. Persaingan slot terjadi saat kueri Anda memiliki banyak tugas yang siap untuk mulai dieksekusi, tetapi BigQuery tidak dapat memperoleh slot yang tersedia dalam jumlah yang cukup untuk mengeksekusinya.
Yang harus dilakukan jika Anda seorang analis
Kurangi data yang Anda proses dalam kueri dengan mengikuti panduan di Mengurangi data yang diproses dalam kueri.
Yang harus dilakukan jika Anda adalah administrator
Tingkatkan ketersediaan slot atau kurangi penggunaan slot dengan melakukan tindakan berikut:
- Jika Anda menggunakan harga sesuai permintaan BigQuery, kueri Anda akan menggunakan kumpulan slot bersama. Pertimbangkan untuk beralih ke harga analisis berbasis kapasitas dengan membeli reservasi. Reservasi memungkinkan Anda memesan slot khusus untuk kueri organisasi Anda.
Jika Anda menggunakan reservasi BigQuery, pastikan ada cukup banyak slot dalam reservasi yang ditetapkan ke project yang menjalankan kueri. Reservasi mungkin tidak memiliki cukup slot dalam skenario berikut:
- Ada tugas lain yang menggunakan slot reservasi. Anda dapat menggunakan Diagram Resource Admin untuk melihat cara organisasi Anda menggunakan reservasi.
- Reservasi tidak memiliki slot yang ditetapkan yang cukup untuk menjalankan kueri dengan cukup cepat. Anda dapat menggunakan estimator slot untuk mendapatkan perkiraan ukuran reservasi yang harus Anda buat agar dapat memproses tugas kueri secara efisien.
Untuk mengatasinya, Anda dapat mencoba salah satu solusi berikut:
- Tambahkan lebih banyak slot (baik slot dasar pengukuran atau slot reservasi maksimum) ke reservasi tersebut.
- Buat pemesanan tambahan dan tetapkan ke project yang menjalankan kueri.
- Sebarkan kueri yang menggunakan banyak resource, baik dari waktu ke waktu dalam reservasi atau di berbagai reservasi.
Pastikan tabel yang Anda kueri dikelompokkan. Pengelompokan membantu memastikan BigQuery dapat membaca kolom dengan data yang berkorelasi dengan cepat.
Pastikan tabel yang Anda kueri dipartisi. Untuk tabel yang tidak dipartisi, BigQuery membaca seluruh tabel. Mempartisi tabel membantu memastikan bahwa Anda hanya membuat kueri pada subset tabel yang Anda minati.
Kuota pengacakan tidak mencukupi
Sebelum menjalankan kueri, BigQuery akan membagi logika kueri Anda menjadi beberapa tahapan. Slot BigQuery akan menjalankan tugas untuk setiap tahap. Saat slot menyelesaikan eksekusi tugas tahap, slot akan menyimpan hasil sementara di shuffle. Tahap berikutnya dalam kueri Anda membaca data dari pengacakan untuk melanjutkan eksekusi kueri Anda. Kuota pengacakan tidak mencukupi terjadi saat Anda memiliki lebih banyak data yang perlu ditulis ke pengacakan daripada kapasitas pengacakan yang Anda miliki.
Yang harus dilakukan jika Anda seorang analis
Mirip dengan persaingan slot, mengurangi jumlah data yang diproses kueri Anda dapat mengurangi penggunaan shuffle. Untuk melakukannya, ikuti panduan di Mengurangi data yang diproses dalam kueri.
Operasi tertentu di SQL cenderung menggunakan pengacakan secara lebih ekstensif, terutama operasi JOIN dan klausa GROUP BY.
Jika memungkinkan, mengurangi jumlah data dalam operasi ini dapat mengurangi penggunaan pengacakan.
Yang harus dilakukan jika Anda adalah administrator
Kurangi pertentangan kuota pengacakan dengan melakukan tindakan berikut:
- Mirip dengan persaingan slot, jika Anda menggunakan harga sesuai permintaan BigQuery, kueri Anda akan menggunakan kumpulan slot bersama. Pertimbangkan untuk beralih ke harga analisis berbasis kapasitas dengan membeli reservasi. Dengan reservasi, Anda mendapatkan slot khusus dan kapasitas pengacakan untuk kueri project Anda.
Jika Anda menggunakan reservasi BigQuery, slot dilengkapi dengan kapasitas shuffle khusus. Jika reservasi Anda menjalankan beberapa kueri yang menggunakan shuffle secara ekstensif, hal ini dapat menyebabkan kueri lain yang berjalan secara paralel tidak mendapatkan kapasitas shuffle yang cukup. Anda dapat mengidentifikasi tugas mana yang menggunakan kapasitas pengacakan secara ekstensif dengan membuat kueri pada kolom
period_shuffle_ram_usage_ratiodi tampilanINFORMATION_SCHEMA.JOBS_TIMELINE.Untuk mengatasinya, Anda dapat mencoba satu atau beberapa solusi berikut:
- Tambahkan lebih banyak slot ke reservasi tersebut.
- Buat pemesanan tambahan dan tetapkan ke project yang menjalankan kueri.
- Sebarkan kueri yang memerlukan pengacakan intensif, baik dari waktu ke waktu dalam pemesanan atau di berbagai pemesanan.
Untuk informasi pemecahan masalah tambahan, lihat Error batas ukuran pengacakan di halaman Pemecahan masalah BigQuery.
Perubahan skala input data
Mendapatkan insight performa ini menunjukkan bahwa kueri Anda membaca setidaknya 50% lebih banyak data untuk tabel input tertentu daripada saat terakhir kali Anda menjalankan kueri. Anda dapat menggunakan histori perubahan tabel untuk melihat apakah ukuran tabel yang digunakan dalam kueri baru-baru ini bertambah.
Yang harus dilakukan jika Anda seorang analis
Kurangi data yang Anda proses dalam kueri dengan mengikuti panduan di Mengurangi data yang diproses dalam kueri.
Penggabungan kardinalitas tinggi
Jika kueri berisi gabungan dengan kunci non-unik di kedua sisi gabungan, ukuran tabel output dapat jauh lebih besar daripada ukuran salah satu tabel input. Insight ini menunjukkan bahwa rasio baris output terhadap baris input tinggi dan menawarkan informasi tentang jumlah baris ini.
Yang harus dilakukan jika Anda seorang analis
Periksa kondisi gabungan Anda untuk mengonfirmasi bahwa peningkatan ukuran tabel output sudah sesuai dengan yang diharapkan. Hindari penggunaan
cross join.
Jika Anda harus menggunakan cross join, coba gunakan klausa GROUP BY untuk melakukan pra-agregasi hasil, atau gunakan fungsi jendela. Untuk mengetahui informasi selengkapnya, lihat
Mengurangi data sebelum menggunakan JOIN.
Kecondongan partisi
Untuk memberikan masukan atau meminta dukungan terkait fitur ini, kirim email ke
bq-query-inspector-feedback@google.com.
Distribusi data yang miring dapat menyebabkan kueri berjalan lambat. Saat kueri sedang dijalankan, BigQuery membagi data menjadi partisi kecil untuk pemrosesan paralel. Kemiringan terjadi saat data didistribusikan secara tidak merata di seluruh partisi ini, sering kali karena nilai yang sering muncul dalam kunci penggabungan atau pengelompokan, sehingga beberapa partisi menjadi jauh lebih besar daripada yang lain. Karena satu slot memproses seluruh partisi dan tidak dapat membagi tugas, partisi yang terlalu besar dapat memperlambat pemrosesan, menyebabkan error "sumber daya terlampaui", dan dalam kasus ekstrem dapat menyebabkan slot mengalami error.
Saat Anda menjalankan operasi JOIN, BigQuery akan mempartisi data
di sisi kiri dan kanan gabungan berdasarkan kunci gabungan. Jika partisi terlalu besar, BigQuery akan mencoba menyeimbangkan kembali data. Jika kemiringan terlalu parah untuk diseimbangkan kembali sepenuhnya, insight kemiringan partisi akan ditambahkan ke tahap JOIN dalam grafik eksekusi.
Mengidentifikasi ketidakseimbangan partisi
Gunakan tab Grafik eksekusi di BigQuery Studio untuk menemukan tahap kueri yang mengalami kemiringan partisi. Insight ditandai di tahap. Dari detail tahap, Anda dapat menentukan bagian yang relevan dari teks kueri dan tabel yang sedang diproses. Untuk mengetahui informasi selengkapnya, lihat Memahami langkah-langkah dengan teks kueri.
Contoh
Kueri berikut menggabungkan informasi repositori dengan informasi file. Ketidakseimbangan dapat terjadi jika beberapa repositori memiliki jumlah file yang jauh lebih banyak daripada repositori lainnya.
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
Kunci gabungannya adalah repo_name. Di tabel sample_repos, repo_name diharapkan unik. Namun, dalam tabel sample_files, repo_name dapat muncul berkali-kali. Jika beberapa nilai repo_name muncul secara tidak proporsional
lebih sering di sample_files, hal ini akan menyebabkan kemiringan data.
Untuk mengonfirmasi apakah ada kemiringan data, analisis distribusi kunci gabungan dalam tabel yang lebih besar (sample_files dalam hal ini). Jalankan kueri berikut untuk menilai distribusi repo_name:
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
Untuk tabel yang sangat besar, gunakan fungsi APPROX_TOP_COUNT
untuk memperkirakan nilai yang paling sering muncul secara efisien.
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
Jika jumlah untuk nilai teratas jauh lebih besar daripada yang lain, terjadi kemiringan data.
Mengurangi ketidakseimbangan partisi
Anda dapat menggunakan strategi berikut untuk mengatasi skew partisi:
- Filter data Anda lebih awal. Kurangi jumlah data yang diproses dengan menerapkan filter sedini mungkin dalam kueri Anda. Hal ini dapat mengurangi jumlah baris yang terkait dengan kunci miring sebelum mencapai operasi seperti
JOINatauGROUP BY. Pisahkan kueri untuk mengisolasi tombol yang miring. Jika kemiringan disebabkan oleh beberapa nilai kunci tertentu, mirip dengan kolom
repo_namedalam contoh sebelumnya, pertimbangkan untuk membagi kueri. Proses data untuk kunci miring secara terpisah dari data lainnya, lalu gabungkan hasilnya menggunakanUNION ALL.Contoh: Mengisolasi kunci yang sering digunakan.
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_nameMenangani
NULLdan nilai default: Penyebab umum skew adalah sejumlah besar baris dengan nilaiNULLatau string kosong di kolom utama. Jika Anda tidak memerlukan baris ini untuk analisis, filter baris tersebut menggunakan klausaWHEREsebelumJOINatauGROUP BY.Mengurutkan ulang operasi: Dalam kueri dengan beberapa gabungan, urutan dapat menjadi penting. Jika memungkinkan, lakukan penggabungan yang secara signifikan mengurangi jumlah baris lebih awal dalam kueri.
Gunakan fungsi perkiraan: Untuk agregasi pada data condong, pertimbangkan apakah hasil perkiraan dapat diterima. Fungsi seperti
APPROX_COUNT_DISTINCTlebih toleran terhadap kemiringan data daripada fungsi eksak sepertiCOUNT(DISTINCT).
Menafsirkan informasi tahap kueri
Selain menggunakan insight performa kueri, Anda juga dapat menggunakan panduan berikut saat meninjau detail tahap kueri untuk membantu menentukan apakah ada masalah dengan kueri:
- Jika nilai Wait ms untuk satu atau beberapa tahap tinggi dibandingkan dengan
eksekusi kueri sebelumnya:
- Periksa apakah Anda memiliki cukup slot yang tersedia untuk mengakomodasi beban kerja Anda. Jika tidak, lakukan load balancing saat Anda menjalankan kueri yang menggunakan banyak resource agar kueri tersebut tidak bersaing satu sama lain.
- Jika nilai Wait ms lebih tinggi daripada hanya untuk satu tahap, lihat tahap sebelumnya untuk melihat apakah ada hambatan yang terjadi di sana. Hal-hal seperti perubahan besar pada data atau skema tabel yang terlibat dalam kueri dapat memengaruhi performa kueri.
- Jika nilai Shuffle output bytes untuk suatu tahap tinggi dibandingkan dengan
proses kueri sebelumnya, atau dibandingkan dengan tahap sebelumnya, evaluasi
langkah-langkah yang diproses dalam tahap tersebut untuk melihat apakah ada yang membuat
jumlah data yang sangat besar secara tidak terduga. Salah satu penyebab umumnya adalah saat langkah memproses
INNER JOINdengan kunci duplikat di kedua sisi gabungan. Hal ini dapat menampilkan data dalam jumlah besar yang tidak terduga. - Gunakan grafik eksekusi untuk melihat tahap teratas berdasarkan durasi dan pemrosesan. Pertimbangkan jumlah data yang dihasilkan dan apakah data tersebut sebanding dengan ukuran tabel yang dirujuk dalam kueri. Jika tidak, tinjau langkah-langkah di tahap tersebut untuk melihat apakah ada yang dapat menghasilkan jumlah data sementara yang tidak terduga.
Langkah berikutnya
- Tinjau pedoman pengoptimalan kueri untuk mendapatkan tips tentang cara meningkatkan performa kueri.