
Kosten für KI-Funktionen mit Modelldistillation optimieren
In diesem Dokument wird beschrieben, wie Sie den optimierten Modus für verwaltete KI
Funktionen in BigQuery verwenden. Im optimierten Modus können Sie umfangreiche Datasets mit Tausenden oder sogar Milliarden von Zeilen verarbeiten. Dabei wird der Tokenverbrauch des Large Language Model (LLM) und die Abfragelatenz im Vergleich zur standardmäßigen LLM-Inferenz pro Zeile erheblich reduziert. Diese Optimierung gilt nur für die Funktionen AI.IF und AI.CLASSIFY.
Um Ihren Tokenverbrauch besser zu verstehen, können Sie die Anzahl der Token ansehen
die von einer Abfrage verwendet werden in der
Google Cloud Konsole. Wenn Sie diese Nutzung schätzen möchten, bevor Sie eine Abfrage ausführen, verwenden Sie die
AI.COUNT_TOKENS Funktion.
Im folgenden Beispiel wird gezeigt, wie Sie die AI.IF Funktion
im optimierten Modus verwenden, um Nachrichtenartikel zu Naturkatastrophen zu identifizieren. Dabei wird text-embedding-005
als Einbettungsmodell verwendet:
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
Das optimization_mode => 'MINIMIZE_COST' Argument aktiviert den optimierten
Modus. Dies ist die Standardeinstellung, wenn Einbettungen bereitgestellt werden. Sie können dieses Argument also weglassen.
In diesem Beispiel werden Einbettungen spontan generiert. In der Praxis empfehlen wir, Einbettungen zu materialisieren, damit sie wiederverwendet werden können.
Funktionsweise des optimierten Modus
Die verwalteten KI-Funktionen AI.IF und AI.CLASSIFY rufen in der Regel für jede Zeile in Ihrem Dataset ein
Remote-LLM auf. Wenn Sie den optimierten Modus verwenden, trainiert BigQuery während der Abfrageausführung automatisch ein leichtgewichtiges, destilliertes Modell.
Der Prozess funktioniert so:
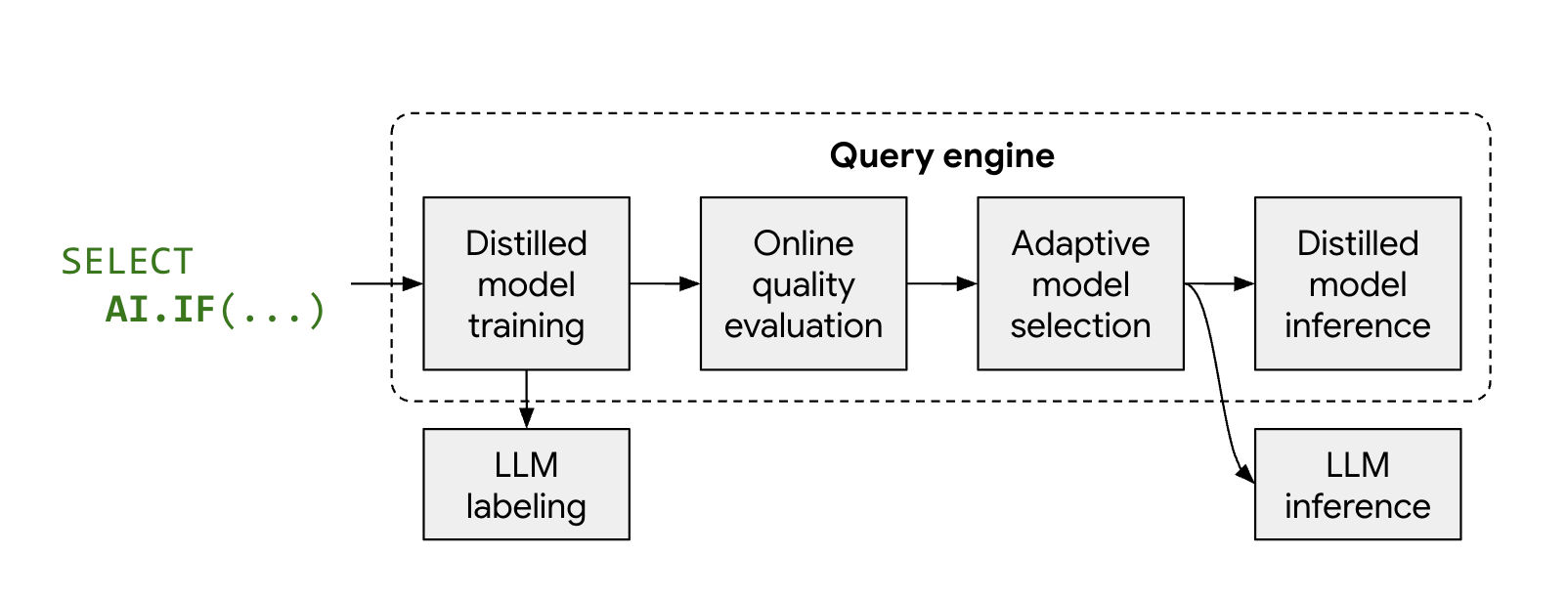
- Sampling und Labeling: BigQuery wählt eine kleine repräsentative Stichprobe Ihrer Daten aus und ruft Gemini auf, um Labels bereitzustellen.
- Training des destillierten Modells: Ein lokales destilliertes Modell wird just-in-time mit den LLM-Labels und Dateneinbettungen als Features trainiert.
- Qualitätsprüfung: BigQuery vergleicht die Genauigkeit des destillierten Modells mit den Ergebnissen des LLM. Wenn das destillierte Modell den erforderlichen Qualitätsschwellenwert nicht erreicht, schlägt die Abfrage standardmäßig mit einem Fehler fehl, in dem erklärt wird, warum das Modell verworfen wurde. Wenn das Modell eine akzeptable Qualität hat, greift BigQuery möglicherweise für bestimmte Zeilen auf das Remote-LLM zurück, um eine gleichbleibende Qualität zu gewährleisten oder für Zeilen, denen gültige Einbettungen fehlen.
- Inferenz: Das destillierte Modell verarbeitet die meisten Zeilen, wodurch die Anzahl der Gemini-Aufrufe erheblich reduziert wird.
Beschränkungen
Der optimierte Modus hat die folgenden Einschränkungen:
- Mindestanzahl von Zeilen: Die Eingabe für die KI-Funktion muss ungefähr 3.000 Zeilen enthalten,damit genügend Daten für das Modelltraining vorhanden sind.
- Datentypen: Bei Prompts, die auf mehrere Spalten verweisen, werden für die Optimierung nur String spalten unterstützt.
- Multilabel-Klassifizierung:
AI.CLASSIFYmitoutput_mode => 'multi'wird im optimierten Modus nicht unterstützt. - Funktionsunterstützung: Nur die Funktionen
AI.IFundAI.CLASSIFYunterstützen den optimierten Modus. Wenn Sie den optimierten Modus mitAI.CLASSIFYverwenden, können Abfragen jedoch fehlschlagen, wenn die Qualität des destillierten Modells nicht ausreicht. - Fehlerverhältnis: Das
max_error_ratioArgument wird im optimierten Modus nicht unterstützt.
Hinweis
Informationen zu den Berechtigungen, die Sie zum Ausführen verwalteter KI-Funktionen in BigQuery benötigen, finden Sie unter Berechtigungen für generative KI-Funktionen festlegen, die LLMs der Gemini Enterprise Agent Platform aufrufen.
Einbettungsmodell auswählen
Wenn Sie den optimierten Modus verwenden möchten, müssen Sie Einbettungen für Ihre Daten berechnen und sie der KI-Funktion zur Verfügung stellen. Damit Eingabespalten zugeordnete Einbettungen haben, müssen alle Zeilen einheitliche Einbettungsdimensionen haben und vom selben Einbettungsmodell generiert werden.
Für die beste Kosten-Qualitäts-Balance und Skalierbarkeit empfehlen wir, Einbettungen für
Ihre Daten mit einem Einbettungsmodell wie
text-embedding-005 oder den Gemini-Einbettungen
für englische oder mehrsprachige Aufgaben zu berechnen. Verwenden Sie für multimodale Daten (Text und Bilder) ein
multimodales Einbettungsmodell wie
multimodalembedding@001.
Einbettungen generieren
Sie können Einbettungen für Ihre Daten mit der autonomen Generierung, die von BigQuery verwaltet wird, oder durch manuelles Erstellen der Einbettungsspalten berechnen.
In den folgenden Abschnitten wird beschrieben, wie Sie beide Ansätze mit den Funktionen AI.CLASSIFY und AI.IF verwenden.
Autonome Einbettungsgenerierung
Wenn Sie die autonome Einbettungsgenerierung verwenden,
verwendet BigQuery die Einbettungen automatisch, wenn AI.IF oder
AI.CLASSIFY aufgerufen werden. Dies ist der empfohlene Ansatz, ist aber auf eine Einbettungsspalte pro Tabelle beschränkt.
Im folgenden Beispiel wird eine Tabelle mit einer autonom generierten Einbettungsspalte erstellt. Dabei wird text-embedding-005 als Einbettungsmodell verwendet. Anschließend werden die Daten mit der Funktion AI.CLASSIFY kategorisiert:
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
Manuelle Spaltenspezifikation
Wenn Sie eine vorhandene Einbettungsspalte haben, geben Sie sie im Argument embeddings von AI.IF oder AI.CLASSIFY an. Sie können sie mit der
AI.EMBED Funktion generieren.
Im folgenden Beispiel wird gezeigt, wie Sie eine Tabelle mit einer Einbettungsspalte erstellen. Dabei wird text-embedding-005 als Einbettungsmodell verwendet. Anschließend wird diese Spalte in einer AI.CLASSIFY-Abfrage verwendet:
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
Wenn Ihr Prompt auf mehrere Spalten verweist, geben Sie im Argument embeddings eine Liste der Spaltennamen und der entsprechenden Einbettungen an. Beispiel:
embeddings => [('body', body_embedding), ('title', title_embedding)].
Abfrageoptimierung überwachen
Wenn Sie prüfen möchten, wie viele Zeilen während der Abfrageausführung optimiert wurden, können Sie die Ausführungsstatistiken in der Google Cloud Konsole oder über die API aufrufen:
Console
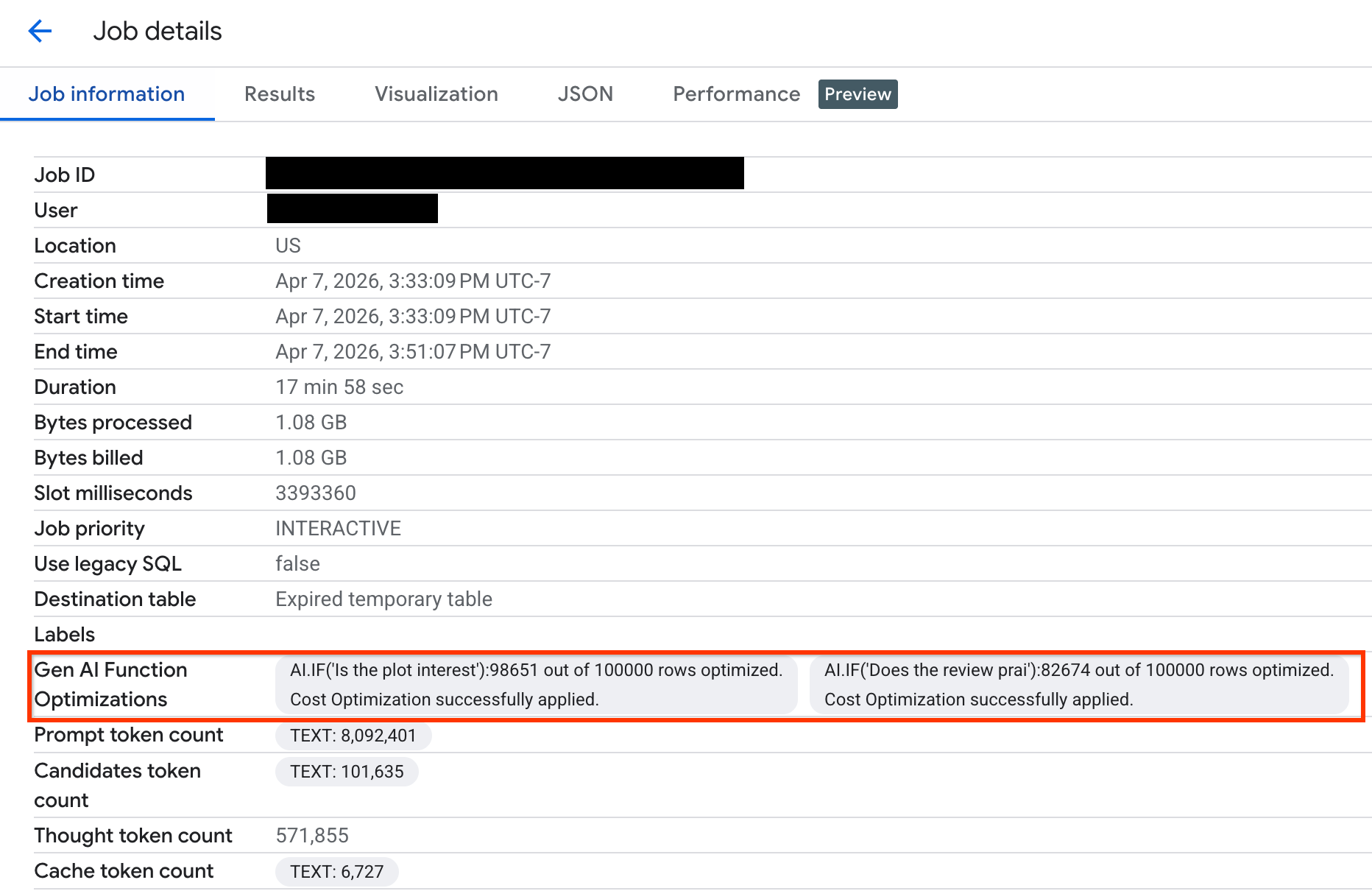
So sehen Sie, wie viele Zeilen optimiert wurden, und rufen Systemmeldungen zum Optimierungsstatus auf:
Rufen Sie in der Google Cloud Konsole die Seite BigQuery auf.
Klicken Sie im Navigationsmenü auf Job Explorer.
Klicken Sie auf die Job-ID, um den Bereich Jobdetails aufzurufen.
Klicken Sie auf den Tab Jobinformationen und sehen Sie sich die Messwerte und den Status im Feld Optimierungen für KI-Funktionen an.
API
Prüfen Sie FunctionGenAiCostOptimizationStats im Objekt GenAIFunctionStats der Jobmetadaten. Dieses Objekt enthält die Anzahl der Zeilen, die mit dem optimierten Workflow abgeleitet wurden, und systemgenerierte Meldungen, die Einblicke in den Optimierungsstatus geben.
Fehlerbehebung
In den folgenden Abschnitten wird beschrieben, wie Sie häufige Probleme bei der Verwendung des optimierten Modus diagnostizieren und beheben.
Datengröße ist zu klein
Problem: Nicht genügend Daten für das Modelltraining. Möglicherweise wird die folgende
Fehlermeldung angezeigt: Fail to apply cost optimization because the data size is too
small.
Lösung: Erhöhen Sie die Größe der Eingabe auf ungefähr 3.000 Zeilen und prüfen Sie,ob für alle Zeilen gültige Einbettungen generiert wurden.
Wenige oder keine Stichproben in einigen Klassen
Problem: Während der
Sampling-Phase ist die Anzahl der Stichproben für bestimmte Kategorien nicht ausreichend, was das Modelltraining verhindert. Möglicherweise wird die folgende
Fehlermeldung angezeigt: Fail to apply cost optimization because some classes have
few or no samples.
Lösung:
- Entfernen Sie seltene oder leere Kategorien aus dem
AI.CLASSIFY-Funktionsaufruf. - Gruppieren Sie seltene Kategorien in einer umfassenderen Kategorie, um die Stichprobengröße zu erhöhen. Sie können eine Kategorie
OTHERverwenden, um Elemente zu gruppieren, die nicht von spezifischeren Kategorien abgedeckt werden. Fügen SieOTHERjedoch nicht hinzu, wenn Ihre Liste der Kategorien bereits vollständig ist, da dieser Begriff mehrdeutig ist und zu Verwirrung führen kann.
Einbettungen haben inkonsistente Dimensionen
Problem: Inkonsistenzen zwischen den Einbettungsdimensionen in den Zeilen. Möglicherweise wird die folgende Fehlermeldung angezeigt: Fail to apply cost optimization
because the embeddings have inconsistent dimensions.
Lösung: Prüfen Sie, ob die Einbettungen vom selben Modell generiert wurden und dieselben Einbettungsvektorlänge haben. Mit einer SQL-Abfrage wie der folgenden können Sie prüfen, ob die Einbettungen in einer Spalte dieselbe Länge haben:
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
Promptkomplexität ist zu hoch
Problem: Das destillierte Modell kann keinen hohen Genauigkeitsschwellenwert erreichen. Möglicherweise wird die folgende Fehlermeldung angezeigt: Fail to apply cost optimization
because the prompt complexity is too high.
Lösung:
Verwenden Sie eine Reihe von Kategorien, die eine Partition bilden. Achten Sie darauf, dass sich die Kategorien nur minimal überschneiden und alle möglichen Eingaben abdecken.
- Vermeiden Sie sich überschneidende Kategorien, bei denen eine Eingabe gleichzeitig zu mehreren Kategorien gehören kann. Vermeiden Sie beispielsweise Kategorien wie
['terrible', 'bad', 'okay', 'good', 'excellent']. - Vermeiden Sie Lücken, in denen keine Kategorien zutreffen. Beispielsweise deckt die Liste der
Kategorien
['bad', 'average']keine Rezension ab, in der Lob ausgedrückt wird. Geben Sie Kategoriebeschreibungen an, damit das LLM Mehrdeutigkeiten zwischen Kategorien auflösen kann. Beispiel:
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- Vermeiden Sie sich überschneidende Kategorien, bei denen eine Eingabe gleichzeitig zu mehreren Kategorien gehören kann. Vermeiden Sie beispielsweise Kategorien wie
Verwenden Sie komplexere Einbettungsmodelle wie
text-embedding-005odermultimodalembedding.Wenn Sie weitere Unterstützung bei der Fehlerbehebung benötigen, wenden Sie sich an bqml-feedback@google.com für zusätzliche Unterstützung.
Unerwartete Anzahl von Zeilen, die vom LLM verarbeitet wurden
Problem: Die Statistiken zur Abfrageausführung zeigen, dass eine unerwartet hohe Anzahl von Zeilen vom Remote-LLM anstelle des destillierten Modells verarbeitet wurde. Das kann folgende Gründe haben:
- Das destillierte Modell wurde erfolgreich trainiert, aber für einige Zeilen fehlen Einbettungen. Diese Zeilen werden vom Remote-LLM verarbeitet.
- Das destillierte Modell konnte nicht für jede Zeile angewendet werden und musste auf das Remote-LLM zurückgreifen, um eine gleichbleibende Qualität zu gewährleisten.
Lösung: Prüfen Sie, ob Einbettungen für alle Zeilen in Ihren Daten ordnungsgemäß generiert wurden und gültig sind. Wenn das Problem weiterhin besteht, wenden Sie sich zur Fehlerbehebung an bqml-feedback@google.com.
Autonome Einbettungsspalte nicht erkannt
Problem: BigQuery kann keine autonome Einbettungs spalte erkennen. Das kann passieren, wenn Ihr Skript eine temporäre Tabelle verwendet und der Verweis auf die ursprüngliche Tabelle verloren geht.
Lösung: Verwenden Sie den embeddings Parameter, um explizit eine autonome
Einbettungsspalte zu übergeben, z. B. embeddings => content_embedding.result. Dadurch wird die Kostenoptimierung ausgelöst.
Nächste Schritte
- Weitere Informationen zu generativer KI in BigQuery.
- Dokumentation zur Funktion
AI.IF - Dokumentation zur Funktion
AI.CLASSIFY