
Otimizar os custos da função de IA com a destilação de modelos
Este documento descreve como usar o modo otimizado para funções de IA gerenciadas no BigQuery. É possível usar o modo otimizado para processar conjuntos de dados em grande escala que contêm milhares ou até bilhões de linhas com consumo de tokens de modelos de linguagem grandes (LLMs) e latência de consulta significativamente reduzidos em comparação com a inferência de LLM padrão por linha. Essa otimização se aplica apenas às funções AI.IF e AI.CLASSIFY.
Para entender melhor o consumo de tokens, você pode ver o número de tokens
usados por uma consulta no
Google Cloud console. Para estimar esse uso antes de executar uma consulta, use a
AI.COUNT_TOKENS função.
O exemplo a seguir demonstra como usar a AI.IF função
com o modo otimizado para identificar artigos de notícias sobre desastres naturais, usando text-embedding-005
como o modelo de embedding:
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
O argumento optimization_mode => 'MINIMIZE_COST' ativa o modo otimizado. Essa é a configuração padrão quando os embeddings são fornecidos. Portanto, é possível omitir esse argumento.
Neste exemplo, os embeddings são gerados em tempo real. Na prática, recomendamos materializar embeddings para que eles possam ser reutilizados.
Como o modo otimizado funciona
As funções de IA gerenciadas, AI.IF e AI.CLASSIFY, normalmente chamam um
LLM remoto para cada linha do conjunto de dados. Ao usar o modo otimizado, o BigQuery treina automaticamente um modelo destilado leve durante a execução da consulta.
O processo funciona da seguinte maneira:
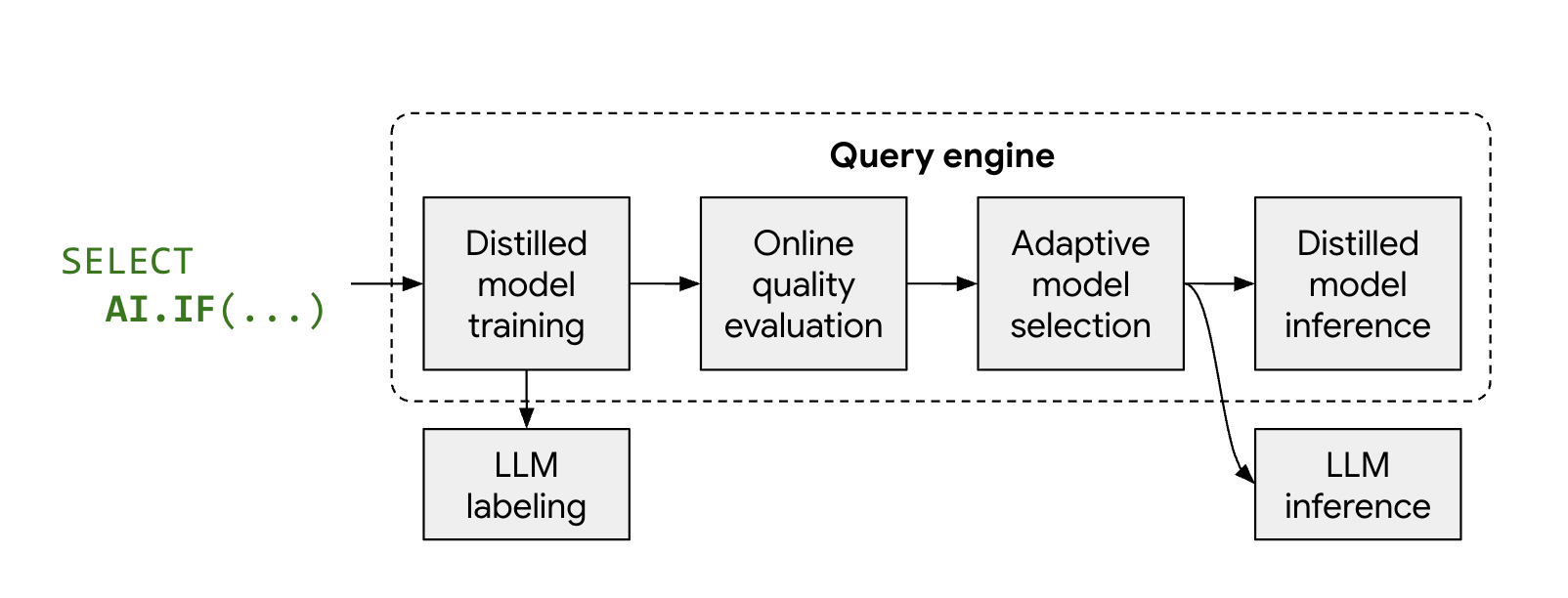
- Amostragem e rotulagem: o BigQuery seleciona uma pequena amostra representativa dos dados e chama o Gemini para fornecer rótulos.
- Treinamento de modelo destilado: um modelo destilado local é treinado no momento certo usando os rótulos de LLM e os embeddings de dados como recursos.
- Verificação de qualidade: o BigQuery avalia a acurácia do modelo destilado em relação aos resultados do LLM. Por padrão, se o modelo destilado não atender ao limite de qualidade necessário, a consulta falhará com um erro explicando por que o modelo foi descartado. Se o modelo for de qualidade aceitável, o BigQuery ainda poderá retornar ao LLM remoto para linhas específicas para manter a qualidade consistente ou para linhas sem embeddings válidos.
- Inferência: o modelo destilado processa a maioria das linhas, reduzindo significativamente o número de chamadas do Gemini.
Limitações
O modo otimizado tem as seguintes limitações:
- Contagem mínima de linhas: a entrada da função de IA precisa conter aproximadamente 3.000 linhas para garantir dados suficientes para o treinamento de modelo.
- Tipos de dados: para comandos que referenciam várias colunas, apenas colunas de string são compatíveis com a otimização.
- Classificação de vários rótulos:
AI.CLASSIFYcomoutput_mode => 'multi'não é compatível com o modo otimizado. - Suporte a funções: apenas as funções
AI.IFeAI.CLASSIFYoferecem suporte ao modo otimizado. No entanto, ao usar o modo otimizado comAI.CLASSIFY, as consultas podem falhar se a qualidade do modelo destilado for insuficiente. - Taxa de erros: o argumento
max_error_rationão é compatível com o modo otimizado.
Antes de começar
Para receber as permissões necessárias para executar funções de IA gerenciadas no BigQuery, consulte Definir permissões para funções de IA generativa que chamam LLMs da plataforma de agentes do Gemini Enterprise.
Escolher um modelo de embedding
Para usar o modo otimizado, é necessário calcular embeddings para os dados e fornecê-los à função de IA. Para que as colunas de entrada tenham embeddings associados, todas as linhas precisam ter dimensões de embedding consistentes e ser geradas pelo mesmo modelo de embedding.
Para melhor custo-qualidade e escalonabilidade, recomendamos calcular embeddings para
seus dados usando um modelo de embedding, como
text-embedding-005 ou os embeddings do Gemini
para tarefas em inglês ou multilíngues. Para dados multimodais (texto e imagens), use um
modelo de embedding multimodal, como
multimodalembedding@001.
Gerar embeddings
É possível calcular embeddings para seus dados usando a geração autônoma gerenciada pelo BigQuery ou criando manualmente as colunas de embedding.
As seções a seguir descrevem como usar as duas abordagens com as funções AI.CLASSIFY e AI.IF.
Geração de embedding autônoma
Se você usar a geração de embedding autônoma,
o BigQuery usará automaticamente os embeddings quando AI.IF ou
AI.CLASSIFY forem chamados. Essa é a abordagem recomendada, mas é limitada a uma coluna de embedding por tabela.
O exemplo a seguir cria uma tabela com uma coluna de embedding gerada de forma autônoma, usando text-embedding-005 como o modelo de embedding e, em seguida, usa a função AI.CLASSIFY para categorizar os dados:
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
Especificação manual da coluna
Se você tiver uma coluna de embedding, especifique-a no argumento embeddings de AI.IF ou AI.CLASSIFY. É possível gerar isso usando a
AI.EMBED função.
O exemplo a seguir demonstra como criar uma tabela com uma coluna de embedding, usando text-embedding-005 como o modelo de embedding e, em seguida, usar essa coluna em uma consulta AI.CLASSIFY:
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
Se o comando referenciar várias colunas, forneça uma lista de nomes de colunas e os embeddings correspondentes no argumento embeddings. Por exemplo:
embeddings => [('body', body_embedding), ('title', title_embedding)].
Monitorar a otimização de consultas
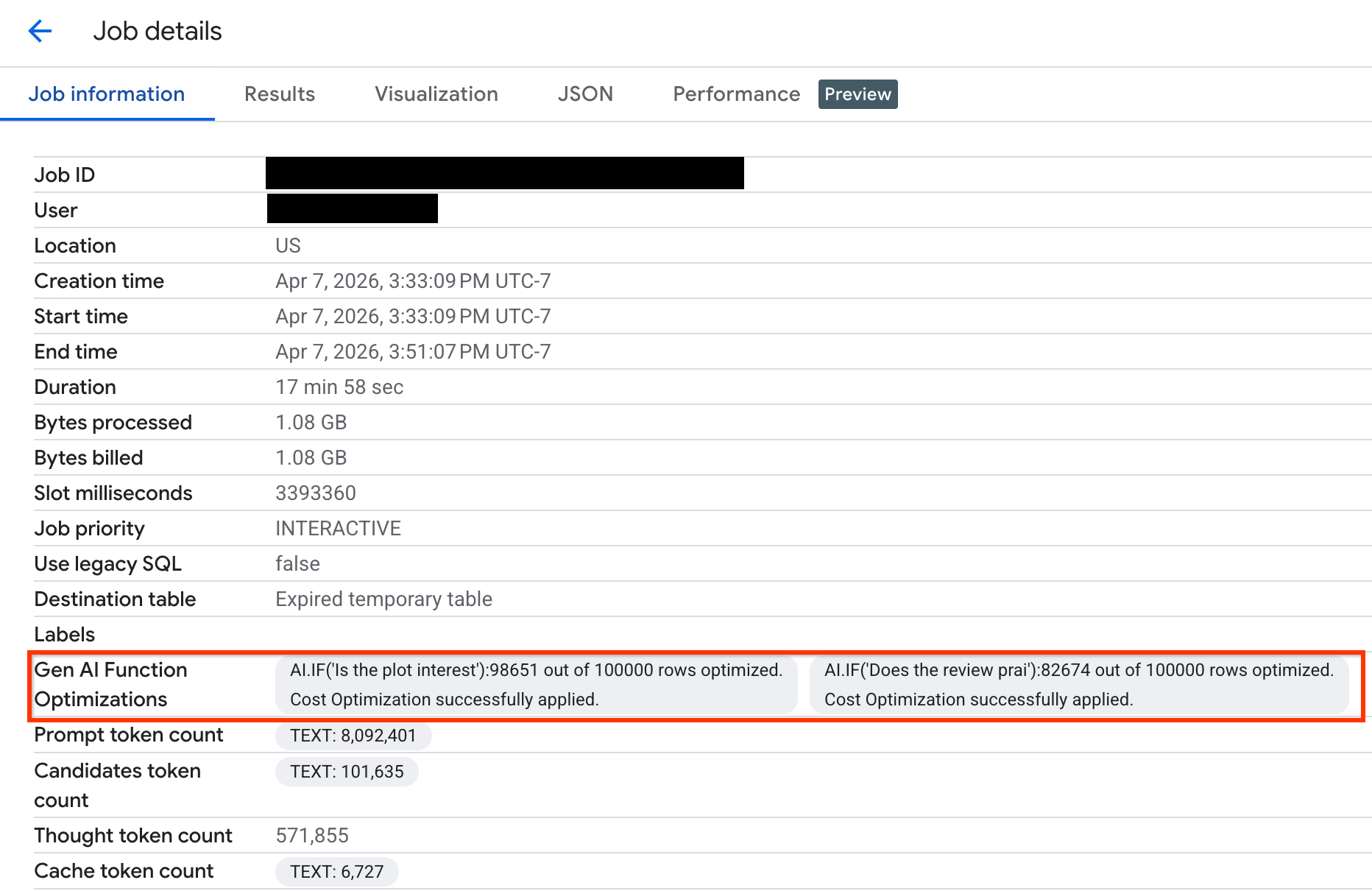
Para verificar quantas linhas foram otimizadas durante a execução da consulta, consulte as estatísticas de execução no Google Cloud console ou na API:
Console
Para conferir quantas linhas foram otimizadas e ver mensagens do sistema sobre o status da otimização, faça o seguinte:
No Google Cloud console, acesse a página BigQuery.
No menu de navegação, clique em Explorador de jobs.
Clique no ID do job para conferir o painel Detalhes do job.
Clique na guia Informações do job e confira as métricas e o status no campo Otimizações de funções de IA generativa.
API
Verifique o FunctionGenAiCostOptimizationStats no objeto GenAIFunctionStats dos metadados do job. Esse objeto inclui o número de linhas inferidas pelo fluxo de trabalho otimizado e mensagens geradas pelo sistema que fornecem insights sobre o estado de otimização.
Resolver problemas
As seções a seguir explicam como diagnosticar e resolver problemas comuns ao usar o modo otimizado.
O tamanho dos dados é muito pequeno
Problema: dados insuficientes para o treinamento de modelo. Você pode receber a seguinte
mensagem de erro: Fail to apply cost optimization because the data size is too
small.
Solução: aumente o tamanho da entrada para aproximadamente 3.000 linhas e verifique se embeddings válidos foram gerados corretamente para todas as linhas.
Poucas ou nenhuma amostra em algumas classes
Problema: número insuficiente de amostras para determinadas categorias durante a fase de amostragem, o que impede treinamento de modelo. Você pode receber a seguinte
mensagem de erro: Fail to apply cost optimization because some classes have
few or no samples.
Solução:
- Remova categorias raras ou vazias da chamada de função
AI.CLASSIFY. - Agrupe categorias raras em uma mais ampla para aumentar o tamanho da amostra. É possível usar uma categoria
OTHERpara agrupar itens não cobertos por categorias mais específicas. No entanto, não adicioneOTHERse a lista de categorias já estiver completa, porque esse termo é ambíguo e pode causar confusão.
Os embeddings têm dimensões inconsistentes
Problema: inconsistências entre as dimensões de embedding nas linhas. Você
pode receber a seguinte mensagem de erro: Fail to apply cost optimization
because the embeddings have inconsistent dimensions.
Solução: verifique se os embeddings são gerados pelo mesmo modelo e têm o mesmo comprimento do vetor de embedding. É possível usar uma consulta SQL semelhante à seguinte para verificar se os embeddings em uma coluna têm o mesmo comprimento:
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
A complexidade do comando é muito alta
Problema: o modelo destilado não consegue atingir um limite de alta precisão. Você
pode receber a seguinte mensagem de erro: Fail to apply cost optimization
because the prompt complexity is too high.
Solução:
Use um conjunto de categorias que formam uma partição. Verifique se as categorias têm sobreposição mínima e cobrem todas as entradas possíveis.
- Evite categorias sobrepostas em que uma entrada possa pertencer a várias categorias simultaneamente. Por exemplo, evite categorias como
['terrible', 'bad', 'okay', 'good', 'excellent']. - Evite lacunas em que nenhuma categoria se aplica. Por exemplo, a lista de
categorias
['bad', 'average']não cobre uma avaliação que expressa elogios. Forneça descrições de categorias para orientar o LLM a resolver a ambiguidade entre categorias. Por exemplo:
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- Evite categorias sobrepostas em que uma entrada possa pertencer a várias categorias simultaneamente. Por exemplo, evite categorias como
Teste modelos de embedding mais avançados, como
text-embedding-005oumultimodalembedding.Entre em contato com bqml-feedback@google.com para receber mais assistência na depuração.
Número inesperado de linhas processadas pelo LLM
Problema: as estatísticas de execução de consultas mostram que um número inesperadamente alto de linhas foi processado pelo LLM remoto em vez do modelo destilado. Isso pode ocorrer pelos seguintes motivos:
- O modelo destilado foi treinado com sucesso, mas algumas linhas tinham embeddings ausentes. Essas linhas são processadas pelo LLM remoto.
- O modelo destilado não pôde ser aplicado a cada linha e precisou retornar ao LLM remoto para manter a qualidade consistente.
Solução: verifique se os embeddings são gerados corretamente e válidos para todas as linhas dos dados. Se o problema persistir, entre em contato com bqml-feedback@google.com para depuração.
Coluna de embedding autônoma não detectada
Problema: o BigQuery não consegue detectar uma coluna de embedding autônoma. Isso pode ocorrer se o script usar uma tabela temporária e a referência à tabela original for perdida.
Solução: use o parâmetro embeddings para transmitir explicitamente uma coluna de embedding autônoma, por exemplo, embeddings => content_embedding.result, que aciona a otimização de custos.
A seguir
- Saiba mais sobre a IA generativa no BigQuery.
- Consulte a
AI.IFfunção documentação. - Consulte a documentação da função
AI.CLASSIFY.