
Optimiser les coûts des fonctions d'IA avec la distillation de modèle
Ce document explique comment utiliser le mode optimisé pour les fonctions d'IA gérées dans BigQuery. Vous pouvez utiliser le mode optimisé pour traiter des ensembles de données à grande échelle contenant des milliers, voire des milliards de lignes, avec une consommation de jetons de grand modèle de langage (LLM) et une latence de requête considérablement réduites par rapport à l'inférence LLM standard par ligne. Cette optimisation ne s'applique qu'aux fonctions AI.IF et AI.CLASSIFY.
Pour mieux comprendre votre consommation de jetons, vous pouvez afficher le nombre de jetons
utilisés par une requête dans la
Google Cloud console. Pour estimer cette utilisation avant d'exécuter une requête, utilisez la
AI.COUNT_TOKENS fonction.
L'exemple suivant montre comment utiliser la fonction AI.IF
avec le mode optimisé pour identifier les articles d'actualité sur les catastrophes naturelles, en utilisant text-embedding-005
comme modèle d'embedding :
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
L'argument optimization_mode => 'MINIMIZE_COST' active le mode optimisé. Il s'agit du paramètre par défaut lorsque des embeddings sont fournis. Vous pouvez donc omettre cet argument.
Dans cet exemple, les embeddings sont générés à la volée. En pratique, nous vous recommandons de matérialiser les embeddings afin de pouvoir les réutiliser.
Fonctionnement du mode optimisé
Les fonctions d'IA gérées, AI.IF et AI.CLASSIFY, appellent généralement un
LLM distant pour chaque ligne de votre ensemble de données. Lorsque vous utilisez le mode optimisé, BigQuery entraîne automatiquement un modèle léger et distillé lors de l'exécution de la requête.
La procédure est la suivante :
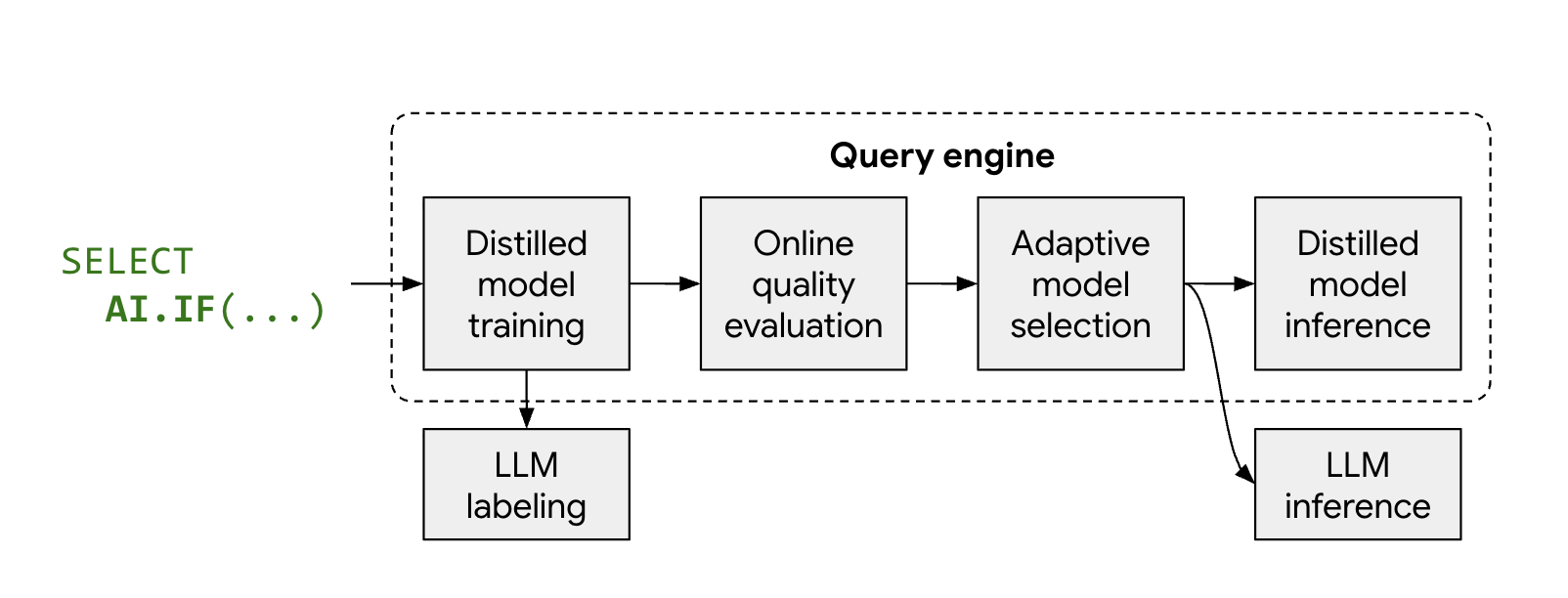
- Échantillonnage et étiquetage : BigQuery sélectionne un petit échantillon représentatif de vos données et appelle Gemini pour fournir des étiquettes.
- Entraînement de modèle distillé : un modèle distillé local est entraîné juste à temps à l'aide des étiquettes LLM et des embeddings de données comme caractéristiques.
- Contrôle qualité : BigQuery évalue la précision du modèle distillé par rapport aux résultats du LLM. Par défaut, si le modèle distillé ne répond pas au seuil de qualité requis, la requête échoue avec une erreur expliquant pourquoi le modèle a été supprimé. Si le modèle est d'une qualité acceptable, BigQuery peut toujours revenir au LLM distant pour des lignes spécifiques afin de maintenir une qualité cohérente ou pour les lignes ne comportant pas d'embeddings valides.
- Inférence : le modèle distillé traite la majorité des lignes, ce qui réduit considérablement le nombre d'appels Gemini.
Limites
Le mode optimisé présente les limites suivantes :
- Nombre minimal de lignes : l'entrée de la fonction AI doit contenir environ 3 000 lignes pour garantir suffisamment de données pour l'entraînement de modèle.
- Types de données : pour les invites qui font référence à plusieurs colonnes, seules les colonnes de chaînes sont compatibles avec l'optimisation.
- Classification multi-étiquettes :
AI.CLASSIFYavecoutput_mode => 'multi'n'est pas compatible avec le mode optimisé. - Compatibilité des fonctions : seuls les fonctions
AI.IFetAI.CLASSIFYsont compatibles avec le mode optimisé. Toutefois, lorsque vous utilisez le mode optimisé avecAI.CLASSIFY, les requêtes peuvent échouer si la qualité du modèle distillé est insuffisante. - Taux d'erreur : l'argument
max_error_ration'est pas compatible avec le mode optimisé.
Avant de commencer
Pour obtenir les autorisations nécessaires pour exécuter des fonctions d'IA gérées dans BigQuery, consultez Définir les autorisations pour les fonctions d'IA générative qui appellent les LLM de la plate-forme d'agent Gemini Enterprise.
Choisir un modèle d'embedding
Pour utiliser le mode optimisé, vous devez calculer les embeddings de vos données et les fournir à la fonction AI. Pour que les colonnes d'entrée aient des embeddings associés, toutes les lignes doivent avoir des dimensions d'embedding cohérentes et être générées par le même modèle d'embedding.
Pour obtenir le meilleur rapport coût/qualité et la meilleure évolutivité, nous vous recommandons de calculer les embeddings de
vos données à l'aide d'un modèle d'embedding, tel que
text-embedding-005 ou les embeddings Gemini
pour les tâches en anglais ou multilingues. Pour les données multimodales (texte et images), utilisez un
modèle d'embedding multimodal tel que
multimodalembedding@001.
Générer des embeddings
Vous pouvez calculer les embeddings de vos données à l'aide de la génération autonome gérée par BigQuery ou en créant manuellement les colonnes d'embedding.
Les sections suivantes décrivent comment utiliser les deux approches avec les fonctions AI.CLASSIFY et AI.IF.
Génération autonome d'embeddings
Si vous utilisez la génération autonome d'embeddings,
BigQuery utilise automatiquement les embeddings lorsque AI.IF ou
AI.CLASSIFY sont appelés. Il s'agit de l'approche recommandée, mais elle est limitée à une colonne d'embedding par table.
L'exemple suivant crée une table avec une colonne d'embedding générée de manière autonome, en utilisant text-embedding-005 comme modèle d'embedding, puis utilise la fonction AI.CLASSIFY pour catégoriser les données :
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
Spécification manuelle des colonnes
Si vous disposez d'une colonne d'embedding existante, spécifiez-la dans l'argument embeddings de AI.IF ou AI.CLASSIFY. Vous pouvez générer cet argument à l'aide de la
AI.EMBED fonction.
L'exemple suivant montre comment créer une table avec une colonne d'embedding, en utilisant text-embedding-005 comme modèle d'embedding, puis comment utiliser cette colonne dans une requête AI.CLASSIFY :
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
Si votre invite fait référence à plusieurs colonnes, fournissez une liste de noms de colonnes et de leurs embeddings correspondants dans l'argument embeddings. Exemple :
embeddings => [('body', body_embedding), ('title', title_embedding)].
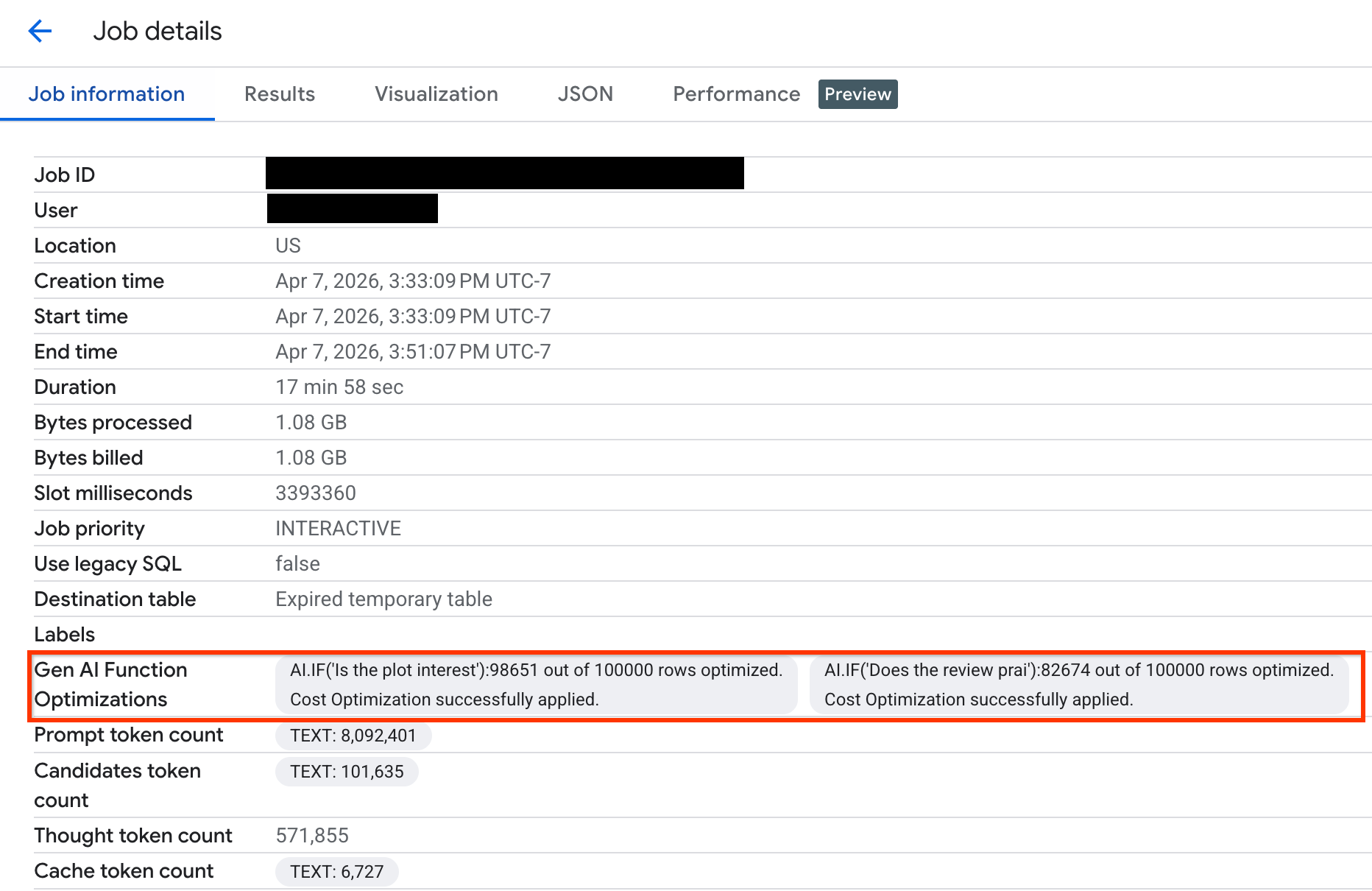
Surveiller l'optimisation des requêtes
Pour vérifier le nombre de lignes optimisées lors de l'exécution de votre requête, vous pouvez afficher les statistiques d'exécution dans la Google Cloud console ou via l'API :
Console
Pour afficher le nombre de lignes optimisées et les messages système concernant l'état de l'optimisation, procédez comme suit :
Dans la Google Cloud console, accédez à la page BigQuery.
Dans le menu de navigation, cliquez sur Explorateur de tâches.
Cliquez sur l'ID de la tâche pour afficher le volet Détails de la tâche.
Cliquez sur l'onglet Informations sur la tâche , puis affichez les métriques et l'état dans le champ Optimisations des fonctions d'IA générative.
API
Consultez FunctionGenAiCostOptimizationStats dans l'objet GenAIFunctionStats des métadonnées de la tâche. Cet objet inclut le nombre de lignes déduites via le workflow optimisé et les messages générés par le système fournissant des informations sur l'état de l'optimisation.
Résoudre les problèmes
Les sections suivantes expliquent comment diagnostiquer et résoudre les problèmes courants liés à l'utilisation du mode optimisé.
La taille des données est trop petite
Problème : données insuffisantes pour l'entraînement du modèle. Le message d'erreur suivant peut s'afficher
: Fail to apply cost optimization because the data size is too
small.
Solution : augmentez la taille de votre entrée à environ 3 000 lignes et vérifiez que des embeddings valides ont été correctement générés pour toutes les lignes.
Peu ou pas d'échantillons dans certaines classes
Problème : nombre insuffisant d'échantillons pour certaines catégories lors de la
phase d'échantillonnage, ce qui empêche l'entraînement du modèle. Le message d'erreur suivant peut s'afficher
: Fail to apply cost optimization because some classes have
few or no samples.
Solution:
- Supprimez les catégories rares ou vides de l'appel de fonction
AI.CLASSIFY. - Regroupez les catégories rares dans une catégorie plus large pour augmenter la taille de l'échantillon. Vous pouvez utiliser une catégorie
OTHERpour regrouper les éléments qui ne sont pas couverts par des catégories plus spécifiques. Toutefois, n'ajoutez pasOTHERsi votre liste de catégories est déjà complète, car ce terme est ambigu et peut entraîner une confusion.
Les embeddings ont des dimensions incohérentes
Problème : incohérences entre les dimensions d'embedding sur les lignes. Le message d'erreur suivant peut s'afficher : Fail to apply cost optimization
because the embeddings have inconsistent dimensions.
Solution : vérifiez que les embeddings sont générés par le même modèle et qu'ils ont la même longueur de vecteur d'embedding. Vous pouvez utiliser une requête SQL semblable à la suivante pour vérifier que les embeddings d'une colonne ont la même longueur :
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
La complexité de l'invite est trop élevée
Problème : le modèle distillé ne peut pas atteindre un seuil de précision élevé. Le message d'erreur suivant peut s'afficher : Fail to apply cost optimization
because the prompt complexity is too high.
Solution:
Utilisez un ensemble de catégories qui forment une partition. Assurez-vous que les catégories se chevauchent le moins possible et couvrent toutes les entrées possibles.
- Évitez les catégories qui se chevauchent, où une entrée peut appartenir à plusieurs catégories simultanément. Par exemple, évitez les catégories telles que
['terrible', 'bad', 'okay', 'good', 'excellent']. - Évitez les lacunes où aucune catégorie ne s'applique. Par exemple, la liste de
catégories
['bad', 'average']ne couvre pas un avis exprimant des éloges. Fournissez des descriptions de catégories pour aider le LLM à résoudre l'ambiguïté entre les catégories. Exemple :
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- Évitez les catégories qui se chevauchent, où une entrée peut appartenir à plusieurs catégories simultanément. Par exemple, évitez les catégories telles que
Essayez des modèles d'embedding plus avancés tels que
text-embedding-005oumultimodalembedding.Contactez bqml-feedback@google.com pour obtenir de l'aide supplémentaire sur le débogage.
Nombre inattendu de lignes traitées par le LLM
Problème : les statistiques d'exécution des requêtes montrent qu'un nombre de lignes étonnamment élevé a été traité par le LLM distant au lieu du modèle distillé. Cela peut être dû aux raisons suivantes :
- Le modèle distillé a été entraîné correctement, mais certaines lignes ne comportaient pas d'embeddings. Ces lignes sont traitées par le LLM distant.
- Le modèle distillé n'a pas pu être appliqué à chaque ligne et a dû revenir au LLM distant pour maintenir une qualité cohérente.
Solution : vérifiez que les embeddings sont correctement générés et valides pour toutes les lignes de vos données. Si le problème persiste, contactez bqml-feedback@google.com pour le débogage.
Colonne d'embedding autonome non détectée
Problème : BigQuery ne parvient pas à détecter une colonne d'embedding autonome. Cela peut se produire si votre script utilise une table temporaire et que la référence à la table d'origine est perdue.
Solution : utilisez le paramètre embeddings pour transmettre explicitement une colonne d'embedding autonome, par exemple embeddings => content_embedding.result, ce qui déclenche l'optimisation des coûts.
Étape suivante
- En savoir plus sur l'IA générative dans BigQuery.
- Consultez la
AI.IFfonction documentation. - Consultez la
AI.CLASSIFYfonction documentation.