
Mengoptimalkan biaya fungsi AI dengan distilasi model
Dokumen ini menjelaskan cara menggunakan mode yang dioptimalkan untuk fungsi AI terkelola di BigQuery. Anda dapat menggunakan mode yang dioptimalkan untuk memproses set data skala besar yang berisi ribuan, atau bahkan miliaran baris dengan konsumsi token model bahasa besar (LLM) dan latensi kueri yang berkurang secara signifikan dibandingkan dengan inferensi LLM per baris standar. Pengoptimalan ini hanya berlaku untuk fungsi AI.IF dan AI.CLASSIFY.
Untuk lebih memahami penggunaan token, Anda dapat melihat jumlah token yang digunakan oleh kueri di konsolGoogle Cloud . Untuk memperkirakan penggunaan ini sebelum menjalankan kueri, gunakan fungsi AI.COUNT_TOKENS.
Contoh berikut menunjukkan cara menggunakan fungsi AI.IF dengan mode yang dioptimalkan untuk mengidentifikasi artikel berita tentang bencana alam, menggunakan text-embedding-005 sebagai model sematan:
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
Argumen optimization_mode => 'MINIMIZE_COST' mengaktifkan mode
yang dioptimalkan. Ini adalah setelan default saat sematan disediakan, sehingga Anda dapat menghilangkan
argumen ini.
Untuk contoh ini, embedding dibuat secara langsung. Dalam praktiknya, sebaiknya Anda mematerialisasi embedding agar dapat digunakan kembali.
Cara kerja mode yang dioptimalkan
Fungsi AI terkelola, AI.IF dan AI.CLASSIFY, biasanya memanggil LLM jarak jauh untuk setiap baris dalam set data Anda. Saat Anda menggunakan mode yang dioptimalkan,
BigQuery secara otomatis melatih model ringan yang disuling
selama eksekusi kueri.
Prosesnya berjalan sebagai berikut:
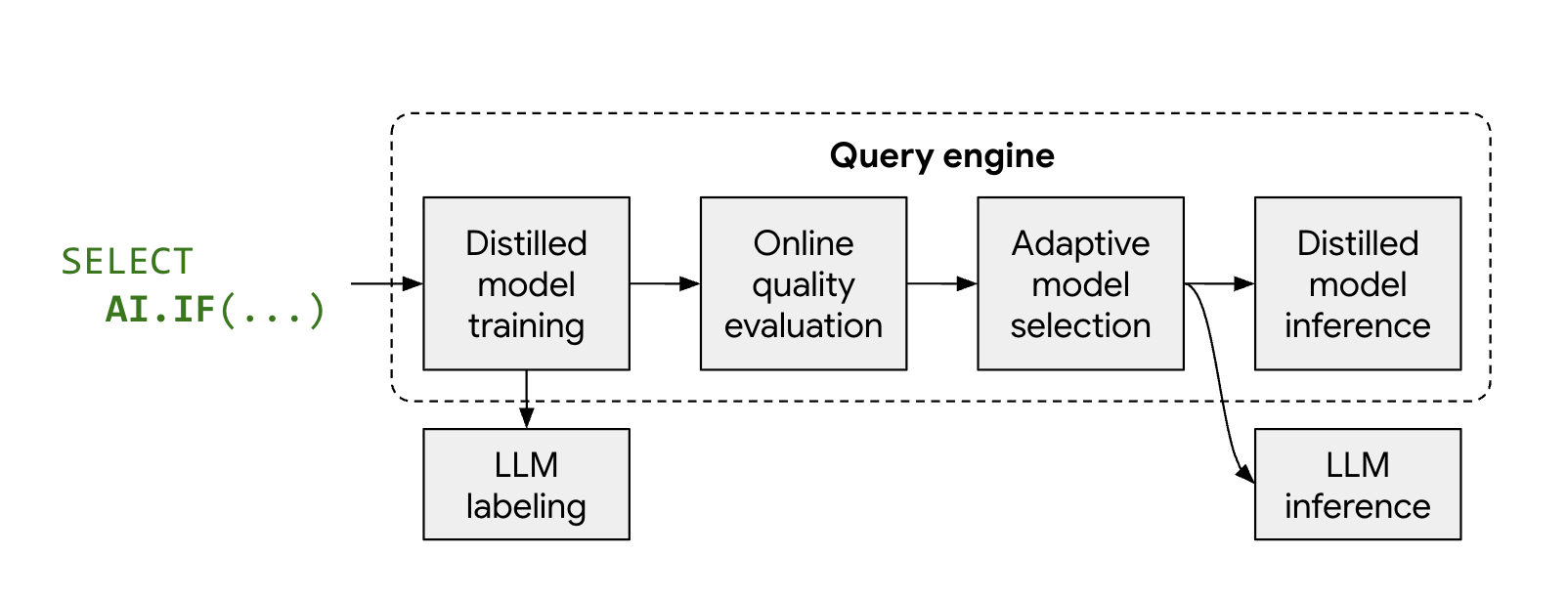
- Sampling dan pemberian label: BigQuery memilih sampel kecil yang representatif dari data Anda dan memanggil Gemini untuk memberikan label.
- Pelatihan model yang disuling: model yang disuling lokal dilatih tepat waktu menggunakan label LLM dan penyematan data sebagai fitur.
- Pemeriksaan kualitas: BigQuery mengevaluasi akurasi model yang disederhanakan terhadap hasil LLM. Secara default, jika model yang disuling gagal memenuhi nilai minimum kualitas yang diperlukan, kueri akan gagal dengan error yang menjelaskan alasan model tersebut dibatalkan. Jika kualitas model dapat diterima, BigQuery mungkin masih melakukan penggantian ke LLM jarak jauh untuk baris tertentu guna mempertahankan kualitas yang konsisten, atau untuk baris yang tidak memiliki sematan yang valid.
- Inferensi: model yang didistilasi memproses sebagian besar baris, sehingga mengurangi jumlah panggilan Gemini secara signifikan.
Batasan
Mode yang dioptimalkan memiliki batasan berikut:
- Jumlah baris minimum: input ke fungsi AI harus berisi sekitar 3.000 baris untuk memastikan data yang cukup untuk pelatihan model.
- Jenis data: untuk perintah yang mereferensikan beberapa kolom, hanya kolom string yang didukung untuk pengoptimalan.
- Klasifikasi multi-label:
AI.CLASSIFYdenganoutput_mode => 'multi'tidak didukung dalam mode yang dioptimalkan. - Dukungan fungsi: hanya fungsi
AI.IFdanAI.CLASSIFYyang mendukung mode yang dioptimalkan; namun, saat menggunakan mode yang dioptimalkan denganAI.CLASSIFY, kueri dapat gagal jika kualitas model yang disuling tidak memadai. - Rasio error: Argumen
max_error_ratiotidak didukung dalam mode yang dioptimalkan.
Sebelum memulai
Untuk mendapatkan izin yang diperlukan untuk menjalankan fungsi AI terkelola di BigQuery, lihat Menetapkan izin untuk fungsi AI generatif yang memanggil LLM Gemini Enterprise Agent Platform.
Memilih model penyematan
Untuk menggunakan mode yang dioptimalkan, Anda harus menghitung embedding untuk data Anda dan memberikannya ke fungsi AI. Agar kolom input memiliki embedding terkait, semua baris harus memiliki dimensi embedding yang konsisten dan dibuat oleh model embedding yang sama.
Untuk kualitas dan skalabilitas biaya terbaik, sebaiknya hitung sematan untuk data Anda menggunakan model sematan, seperti text-embedding-005 atau sematan Gemini untuk tugas berbahasa Inggris atau multibahasa. Untuk data multimodal (teks dan gambar), gunakan model embedding multimodal seperti multimodalembedding@001.
Membuat embedding
Anda dapat menghitung embedding untuk data menggunakan pembuatan otonom yang dikelola oleh BigQuery, atau dengan membuat kolom embedding secara manual. Bagian berikut menjelaskan cara menggunakan kedua pendekatan dengan fungsi AI.CLASSIFY dan AI.IF.
Pembuatan embedding mandiri
Jika Anda menggunakan pembuatan embedding otonom,
BigQuery akan otomatis menggunakan embedding saat AI.IF atau
AI.CLASSIFY dipanggil. Ini adalah pendekatan yang direkomendasikan, tetapi terbatas pada
satu kolom sematan per tabel.
Contoh berikut membuat tabel dengan kolom embedding yang dibuat secara mandiri, menggunakan text-embedding-005 sebagai model embedding, lalu menggunakan fungsi AI.CLASSIFY untuk mengategorikan data:
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
Spesifikasi kolom manual
Jika Anda memiliki kolom penyematan yang sudah ada, tentukan di argumen embeddings
dari AI.IF atau AI.CLASSIFY. Anda dapat membuatnya menggunakan
fungsi AI.EMBED.
Contoh berikut menunjukkan cara membuat tabel dengan kolom embedding, menggunakan text-embedding-005 sebagai model embedding, lalu menggunakan kolom tersebut dalam kueri AI.CLASSIFY:
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
Jika perintah Anda mereferensikan beberapa kolom, berikan daftar nama kolom dan
embedding yang sesuai di argumen embeddings. Contoh: embeddings => [('body', body_embedding), ('title', title_embedding)].
Memantau pengoptimalan kueri
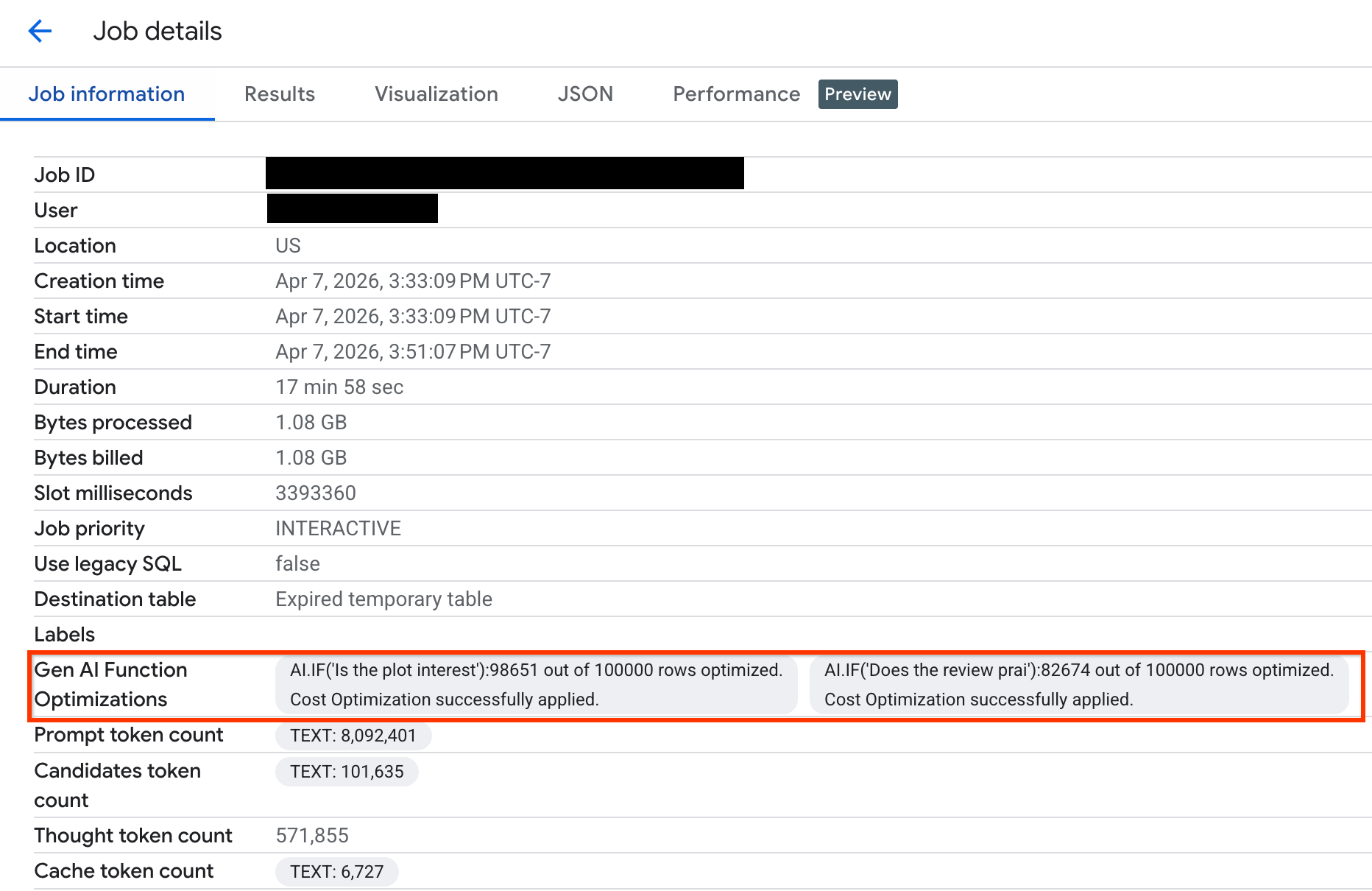
Untuk memverifikasi jumlah baris yang dioptimalkan selama eksekusi kueri, Anda dapat melihat statistik eksekusi di konsol Google Cloud atau melalui API:
Konsol
Untuk melihat jumlah baris yang dioptimalkan dan melihat pesan sistem tentang status pengoptimalan, lakukan hal berikut:
Di konsol Google Cloud , buka halaman BigQuery.
Di menu navigasi, klik Penjelajah tugas.
Klik ID tugas untuk melihat panel Detail tugas.
Klik tab Job information dan lihat metrik serta status di kolom Pengoptimalan fungsi AI generatif.
API
Periksa FunctionGenAiCostOptimizationStats di objek GenAIFunctionStats
metadata tugas. Objek ini mencakup jumlah baris yang disimpulkan
melalui alur kerja yang dioptimalkan dan pesan yang dibuat sistem yang memberikan
insight tentang status pengoptimalan.
Memecahkan masalah
Bagian berikut menjelaskan cara mendiagnosis dan menyelesaikan masalah umum terkait penggunaan mode yang dioptimalkan.
Ukuran data terlalu kecil
Masalah: Data tidak mencukupi untuk pelatihan model. Anda mungkin melihat pesan error berikut: Fail to apply cost optimization because the data size is too
small.
Solusi: Tingkatkan ukuran input Anda menjadi sekitar 3.000 baris dan pastikan sematan yang valid telah dibuat dengan benar untuk semua baris.
Sedikit atau tidak ada sampel di beberapa kelas
Masalah: Jumlah sampel yang tidak mencukupi untuk kategori tertentu selama fase pengambilan sampel, yang mencegah pelatihan model. Anda mungkin melihat pesan error berikut: Fail to apply cost optimization because some classes have
few or no samples.
Solusi:
- Hapus kategori langka atau kosong dari panggilan fungsi
AI.CLASSIFY. - Kelompokkan kategori langka ke dalam kategori yang lebih luas untuk meningkatkan ukuran sampel. Anda
dapat menggunakan kategori
OTHERuntuk mengelompokkan item yang tidak tercakup dalam kategori yang lebih spesifik. Namun, jangan tambahkanOTHERjika daftar kategori Anda sudah lengkap, karena istilah ini ambigu dan dapat menyebabkan kebingungan.
Embedding memiliki dimensi yang tidak konsisten
Masalah: Inkonsistensi antara dimensi penyematan di seluruh baris. Anda
mungkin melihat pesan error berikut: Fail to apply cost optimization
because the embeddings have inconsistent dimensions.
Solusi: Verifikasi bahwa embedding dibuat oleh model yang sama dan memiliki panjang vektor embedding yang sama. Anda dapat menggunakan kueri SQL yang mirip dengan berikut untuk memeriksa apakah embedding dalam kolom memiliki panjang yang sama:
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
Kompleksitas perintah terlalu tinggi
Masalah: Model yang disuling tidak dapat mencapai batas akurasi yang tinggi. Anda
mungkin melihat pesan error berikut: Fail to apply cost optimization
because the prompt complexity is too high.
Solusi:
Gunakan sekumpulan kategori yang membentuk partisi. Pastikan kategori memiliki tumpang-tindih minimal dan mencakup semua kemungkinan input.
- Hindari kategori yang tumpang-tindih jika input dapat termasuk dalam beberapa kategori secara bersamaan. Misalnya, hindari kategori seperti
['terrible', 'bad', 'okay', 'good', 'excellent']. - Hindari kesenjangan saat tidak ada kategori yang berlaku. Misalnya, daftar kategori
['bad', 'average']tidak mencakup ulasan yang memuji. Berikan deskripsi kategori untuk memandu LLM menyelesaikan ambiguitas antar-kategori. Contoh:
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- Hindari kategori yang tumpang-tindih jika input dapat termasuk dalam beberapa kategori secara bersamaan. Misalnya, hindari kategori seperti
Coba model embedding yang lebih canggih seperti
text-embedding-005ataumultimodalembedding.Hubungi bqml-feedback@google.com untuk mendapatkan bantuan tambahan dalam men-debug.
Jumlah baris yang diproses oleh LLM tidak terduga
Masalah: Statistik eksekusi kueri menunjukkan bahwa jumlah baris yang diproses oleh LLM jarak jauh secara tidak terduga tinggi, bukan model yang disuling. Hal ini mungkin disebabkan oleh alasan berikut:
- Model yang disuling berhasil dilatih, tetapi beberapa baris tidak memiliki embedding. Baris ini diproses oleh LLM jarak jauh.
- Model yang disuling tidak dapat diterapkan untuk setiap baris dan harus melakukan fallback ke LLM jarak jauh untuk mempertahankan kualitas yang konsisten.
Solusi: Verifikasi bahwa penyematan dibuat dengan benar dan valid untuk semua baris dalam data Anda. Jika masalah berlanjut, hubungi bqml-feedback@google.com untuk melakukan proses debug.
Kolom penyematan mandiri tidak terdeteksi
Masalah: BigQuery tidak dapat mendeteksi kolom sematan mandiri. Hal ini dapat terjadi jika skrip Anda menggunakan tabel sementara, dan referensi ke tabel asli hilang.
Solusi: Gunakan parameter embeddings untuk meneruskan kolom sematan otonom secara eksplisit—misalnya, embeddings => content_embedding.result—yang memicu pengoptimalan biaya.
Langkah berikutnya
- Pelajari lebih lanjut AI generatif di BigQuery.
- Lihat dokumentasi fungsi
AI.IF. - Lihat dokumentasi fungsi
AI.CLASSIFY.