
Programar uma transferência do Snowflake
Com o conector do Snowflake fornecido pelo serviço de transferência de dados do BigQuery, é possível programar e gerenciar jobs de transferência automatizados para migrar dados do Snowflake para o BigQuery usando listas de permissão de IP público.
Visão geral
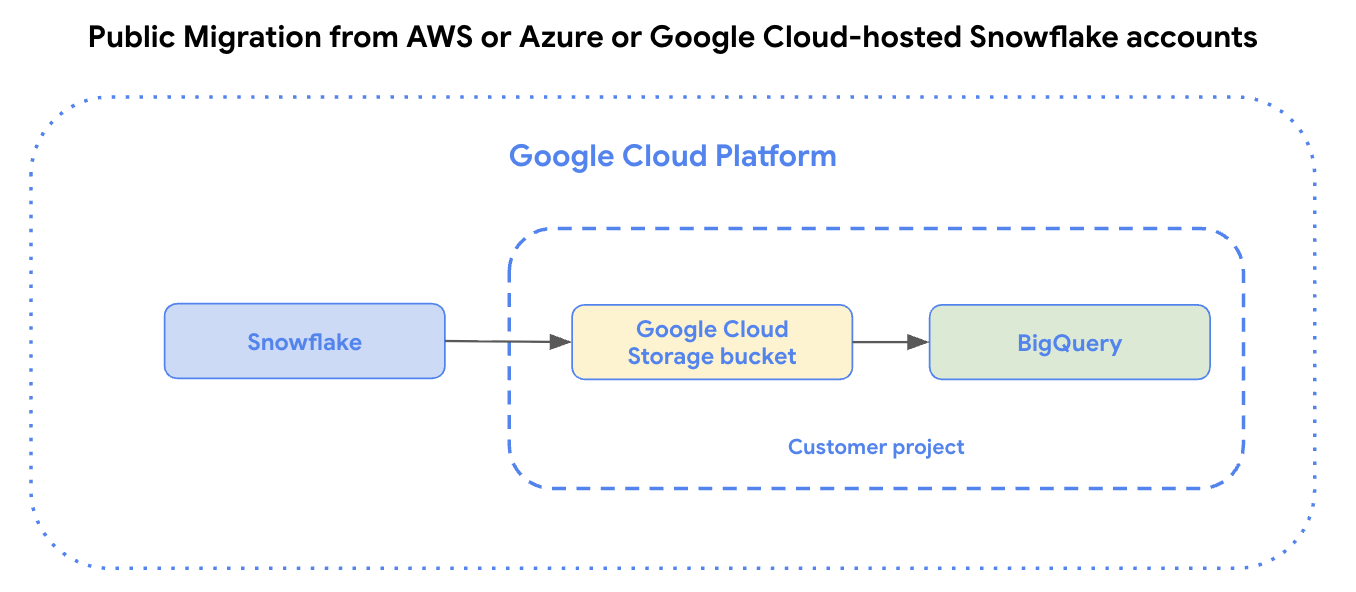
O conector do Snowflake usa agentes de migração no Google Kubernetes Engine e aciona uma operação de carregamento do Snowflake para uma área de preparo no bucket do Cloud Storage.
- Para contas do Amazon Web Services (AWS), do Azure ou do Snowflake hospedadas no Google Cloud, os dados são primeiro armazenados em um bucket do Cloud Storage, que é transferido para o BigQuery com o serviço de transferência de dados do BigQuery.
O diagrama a seguir ilustra transferências de dados públicos de contas do Snowflake hospedadas no Amazon Web Services (AWS), no Azure ou em contas do Snowflake hospedadas no Google Cloud.
Limitações
As transferências de dados feitas com o conector do Snowflake estão sujeitas às seguintes limitações:
- O conector do Snowflake só aceita transferências de tabelas em um único banco de dados e esquema do Snowflake. Para transferir de tabelas com vários bancos de dados ou esquemas do Snowflake, configure cada job de transferência separadamente.
- A velocidade de carregamento de dados do Snowflake para seu bucket do Amazon S3, contêiner do Azure Blob Storage ou bucket do Cloud Storage é limitada pelo warehouse do Snowflake escolhido para essa transferência.
- O BigQuery grava dados do Snowflake no
Cloud Storage como arquivos Parquet. Os arquivos Parquet não são compatíveis com os tipos de dados
TIMESTAMP_TZeTIMESTAMP_LTZ. Se os dados contiverem esses tipos, exporte-os para o Amazon S3 como arquivos CSV e importe-os para o BigQuery. Para mais informações, consulte Visão geral das transferências do Amazon S3.
Antes de começar
Antes de configurar uma transferência do Snowflake, siga todas as etapas listadas nesta seção. Confira a seguir uma lista de todas as etapas necessárias.
- Preparar o projeto do Google Cloud
- Papéis obrigatórios do BigQuery
- Preparar o bucket de preparação
- Criar um usuário do Snowflake com as permissões necessárias
- Adicionar políticas de rede
- Opcional: detecção e mapeamento de esquema
- Avalie o Snowflake para identificar tipos de dados incompatíveis
- Opcional: Ativar transferências incrementais
- Opcional: Ativar a conectividade privada
- Coletar informações de transferência
- Se você planeja especificar uma chave de criptografia gerenciada pelo cliente (CMEK), verifique se a conta de serviço tem permissões para criptografar e descriptografar e que você tem o Cloud KMS ID do recurso da chave necessário para usar a CMEK. Para informações sobre como a CMEK funciona com as transferências, consulte Especificar chave de criptografia com transferências.
Preparar seu projeto do Google Cloud
Crie e configure seu projeto Google Cloud para uma transferência do Snowflake seguindo estas etapas:
Crie um Google Cloud projeto ou selecione um atual.
Verifique se você realizou todas as ações necessárias para ativar o serviço de transferência de dados do BigQuery.
Crie um conjunto de dados do BigQuery para armazenar seus dados. Não é necessário criar tabelas.
Papéis obrigatórios do BigQuery
Para receber as permissões necessárias para criar uma transferência de dados do serviço de transferência de dados do BigQuery,
peça ao administrador para conceder a você o papel do IAM de Administrador do BigQuery (roles/bigquery.admin) no seu projeto.
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Esse papel predefinido contém as permissões necessárias para criar uma transferência de dados do serviço de transferência de dados do BigQuery. Para acessar as permissões exatas necessárias, expanda a seção Permissões necessárias:
Permissões necessárias
As seguintes permissões são necessárias para criar uma transferência de dados do serviço de transferência de dados do BigQuery:
-
Permissões do serviço de transferência de dados do BigQuery:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
Permissões do BigQuery:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
Essas permissões também podem ser concedidas com funções personalizadas ou outros papéis predefinidos.
Para mais informações, consulte Conceder acesso ao bigquery.admin.
Preparar o bucket de staging
Para se preparar para uma transferência de dados do Snowflake, crie um bucket de preparação e configure-o para permitir acesso de gravação do Snowflake. É necessário organizar os dados do Snowflake em um bucket do Cloud Storage antes de carregá-los no BigQuery.
- Crie um bucket do Cloud Storage.
- Crie e configure um objeto de integração de armazenamento do Snowflake para permitir que o Snowflake grave dados no bucket do Cloud Storage como um estágio externo.
- Quando você executa o comando
DESCRIBE INTEGRATION, a conta de serviço do Cloud Storage é listada no campoSTORAGE_GCP_SERVICE_ACCOUNT. Conceda à conta de serviço do Cloud Storage as seguintes permissões no bucket do Cloud Storage:storage.objects.createstorage.objects.deletestorage.objects.getstorage.objects.list
Para permitir o acesso ao bucket de staging, conceda ao agente de serviço do DTS o papel
roles/storage.objectViewercom o seguinte comando:gcloud storage buckets add-iam-policy-binding gs://STAGING_BUCKET_NAME \ --member=serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com \ --role=roles/storage.objectViewer
Para uma transferência de dados particular do Snowflake, crie o bucket de staging e configure-o para conectividade privada.
Criar um usuário do Snowflake com as permissões necessárias
Durante uma transferência do Snowflake, o conector do Snowflake se conecta à sua conta usando uma conexão JDBC. Crie um usuário do Snowflake com uma função personalizada que tenha apenas os privilégios necessários para realizar a transferência de dados:
// Create and configure new role, MIGRATION_ROLE
GRANT USAGE
ON WAREHOUSE WAREHOUSE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON DATABASE DATABASE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON SCHEMA DATABASE_NAME.SCHEMA_NAME
TO ROLE MIGRATION_ROLE;
// You can modify this to give select permissions for all tables in a schema
GRANT SELECT
ON TABLE DATABASE_NAME.SCHEMA_NAME.TABLE_NAME
TO ROLE MIGRATION_ROLE;
GRANT USAGE
ON INTEGRATION STORAGE_INTEGRATION_OBJECT_NAME
TO ROLE MIGRATION_ROLE;
Substitua:
MIGRATION_ROLE: o nome da função personalizada que você está criandoWAREHOUSE_NAME: o nome do seu data warehouseDATABASE_NAME: o nome do banco de dados do Snowflake.SCHEMA_NAME: o nome do seu esquema do Snowflake.TABLE_NAME: o nome do Snowflake incluído nesta transferência de dados.STORAGE_INTEGRATION_OBJECT_NAME: o nome do seu objeto de integração de armazenamento do Snowflake.
Gerar par de chaves para autenticação
Devido à descontinuação dos logins com senha de fator único pelo Snowflake, recomendamos que você use o par de chaves para autenticação.
É possível configurar um par de chaves gerando um par Chave RSA criptografado ou não criptografado e atribuindo a chave pública a um usuário do Snowflake. Para mais informações, consulte Configurar a autenticação de par de chaves.
Permitir o descarregamento para locais externos inline
O conector do Snowflake descarrega dados para locais externos inline durante a transferência. Se a sua conta do Snowflake restringir o descarregamento a locais inline, a transferência vai falhar.
Para permitir o descarregamento em locais inline, execute o seguinte comando SQL na sua conta do Snowflake. É necessário ter o papel ACCOUNTADMIN no Snowflake para executar esse comando.
ALTER ACCOUNT SET PREVENT_UNLOAD_TO_INLINE_URL = false;
Adicionar políticas de rede
Para conectividade pública, a conta do Snowflake permite a conexão pública com credenciais de banco de dados por padrão. No entanto, talvez você tenha configurado regras ou políticas de rede que podem impedir que o conector do Snowflake se conecte à sua conta. Nesse caso, adicione os endereços IP necessários à sua lista de permissões. Para mais informações, consulte Configurar políticas de rede para transferências do Snowflake.
Detecção e mapeamento de esquema
Para definir seu esquema, use o serviço de transferência de dados do BigQuery para detectar automaticamente o esquema e o mapeamento de tipo de dados ao transferir dados do Snowflake para o BigQuery. Se preferir, use o mecanismo de tradução para definir manualmente seu esquema e tipos de dados.
Para mais informações, consulte Detecção e mapeamento de esquema para Snowflake.
Ativar transferências incrementais
Para configurar uma transferência incremental de dados do Snowflake, consulte Configurar transferências incrementais para o Snowflake.
Ativar a conectividade particular
Se você quiser criar uma transferência de dados privada do Snowflake, configure sua rede para conectividade privada.
Coletar informações de transferência
Reúna as informações necessárias para configurar a migração com o serviço de transferência de dados do BigQuery:
- O identificador da sua conta do Snowflake, que é o prefixo no URL da conta. Por exemplo,
ACCOUNT_IDENTIFIER.snowflakecomputing.com - O nome de usuário e a chave privada associada com as permissões adequadas para seu banco de dados do Snowflake. Ele pode ter apenas as permissões necessárias para executar a transferência de dados.
- O URI do bucket de preparo a ser usado para a transferência. Recomendamos que você configure uma política de ciclo de vida para esse bucket, evitando cobranças desnecessárias.
- O URI do bucket do Cloud Storage em que você armazenou os arquivos de mapeamento de esquema obtidos do mecanismo de tradução.
Configurar uma transferência do Snowflake
Selecione uma das seguintes opções:
Console
Acesse a página "Transferências de dados" no console Google Cloud .
Clique em Criar transferência.
Na seção Tipo de origem, selecione Migração do Snowflake na lista Origem.
Na seção Nome da configuração de transferência, insira um nome para a transferência, como
My migration, no campo Nome de exibição. Esse nome pode ter qualquer valor que identifique facilmente a transferência, caso seja necessário modificá-la no futuro.Na seção Configurações de destino, escolha o conjunto de dados criado, na lista Conjunto de dados.
Na seção Credenciais do Snowflake, faça o seguinte:
- Em Identificador da conta, insira um identificador exclusivo para sua conta do Snowflake, que é uma combinação do nome da organização e da conta. O identificador é o prefixo do URL da conta do Snowflake, não o URL completo. Por exemplo,
ACCOUNT_IDENTIFIER.snowflakecomputing.com. - Em Nome de usuário, insira o nome de usuário do usuário do Snowflake cujas credenciais e autorização são usadas para acessar seu banco de dados e transferir as tabelas do Snowflake. Recomendamos usar o usuário que você criou para essa transferência.
- Em Mecanismo de autenticação, selecione um método de autenticação de usuário do Snowflake:
SENHA
- Em Senha, insira a senha do usuário do Snowflake.
KEY_PAIR
- Em Chave privada, insira a chave privada vinculada à chave pública associada ao usuário do Snowflake.
- Em A chave privada está criptografada?, selecione este campo se a chave privada estiver criptografada com uma senha longa.
- Em Senha longa da chave privada, digite a senha longa da chave privada criptografada. Esse campo é obrigatório se você tiver selecionado A chave privada está criptografada. Para mais informações, consulte Gerar um par de chaves para autenticação.
- Em Armazém, insira um armazém usado para a execução dessa transferência de dados.
- Em Banco de dados do Snowflake, insira o nome do banco de dados do Snowflake que contém as tabelas incluídas nesta transferência de dados.
- Em Esquema do Snowflake, insira o nome do esquema do Snowflake que contém as tabelas incluídas nesta transferência de dados.
- Em Identificador da conta, insira um identificador exclusivo para sua conta do Snowflake, que é uma combinação do nome da organização e da conta. O identificador é o prefixo do URL da conta do Snowflake, não o URL completo. Por exemplo,
Na seção Configuração de armazenamento, faça o seguinte:
- Em Nome do objeto de integração de armazenamento, insira o nome do objeto de integração de armazenamento do Snowflake.
- Opcional: em Tamanho máximo do arquivo, especifique o tamanho máximo de cada arquivo descarregado do Snowflake para o local de staging (em MB).
Em Provedor de nuvem, selecione
AWS,AZUREouGCP, dependendo de qual provedor de nuvem está hospedando sua conta do Snowflake.- Em URI do GCS, insira o URI do bucket do Cloud Storage que será usado como um bucket de preparo.
Na seção Conta de serviço, faça o seguinte:
- Em Conta de serviço, insira uma conta de serviço para usar com essa
transferência de dados. A conta de serviço precisa pertencer ao mesmo projeto doGoogle Cloud em que a configuração de transferência e o conjunto de dados de destino foram criados. A conta de serviço precisa ter as permissões necessárias
storage.objects.listestorage.objects.get.
- Em Conta de serviço, insira uma conta de serviço para usar com essa
transferência de dados. A conta de serviço precisa pertencer ao mesmo projeto doGoogle Cloud em que a configuração de transferência e o conjunto de dados de destino foram criados. A conta de serviço precisa ter as permissões necessárias
Na seção Configuração do esquema, faça o seguinte:
- Em Tipo de ingestão, selecione Completa ou Incremental. Para mais informações, consulte Configurar transferências incrementais.
- Em Padrões de nome da tabela, especifique uma tabela para transferir inserindo um nome ou um padrão que corresponda ao nome da tabela no esquema. Você
pode usar expressões regulares para especificar o padrão, por exemplo
table1_regex;table2_regex. Esse padrão precisa seguir a sintaxe da expressão regular do Java. Por exemplo,lineitem;ordertbcorresponde às tabelas chamadaslineitemeordertb..*corresponde a todas as tabelas.
- Opcional: em Usar a saída do BigQuery Translation Engine, selecione este campo se quiser especificar um caminho de saída de tradução personalizado.
- Opcional: em Caminho do GCS de saída da tradução, especifique um caminho para a pasta do Cloud Storage que contém os arquivos de mapeamento de esquema do mecanismo de tradução. Você pode deixar esse campo em branco para que o conector do Snowflake detecte automaticamente seu esquema.
- O caminho precisa seguir o formato
translation_target_base_uri/metadata/config/db/schema/e terminar com/.
- O caminho precisa seguir o formato
- Opcional: em Caminho do arquivo de esquema personalizado, especifique o caminho do Cloud Storage para um arquivo de esquema personalizado.
- Opcional: para Mapear NUMBER de escala zero do Snowflake para INT64 do BigQuery, selecione este campo se quiser que os tipos
NUMBER(p, 0)do Snowflake sejam mapeados paraINT64do BigQuery.
Na seção Conectividade de rede, faça o seguinte:
- Em Usar rede particular, se você estiver criando uma transferência de dados privada, selecione Verdadeiro.
- Em Anexo de serviço do PSC, se você estiver criando uma conexão particular, insira o URI do anexo de serviço. Para mais informações, consulte Criar uma configuração de transferência privada do Snowflake.
- Para o Private Network Service, se você estiver criando uma transferência de dados particular, insira o autolink do diretório de serviços. Para mais informações, consulte Criar uma configuração de transferência privada do Snowflake.
Opcional: na seção Opções de notificação, faça o seguinte:
- Clique no botão para ativar as notificações por e-mail. Quando você ativa essa opção, o administrador de transferência recebe uma notificação por e-mail se uma execução de transferência falhar.
- Em Selecionar um tópico do Pub/Sub, escolha o nome do tópico ou clique em Criar um tópico. Essa opção configura notificações de execução do Pub/Sub da sua transferência.
Se você usa CMEKs, na seção Opções avançadas, selecione Chave gerenciada pelo cliente. Uma lista das CMEKs disponíveis será exibida. Para saber como as CMEKs funcionam com o serviço de transferência de dados do BigQuery, consulte Especificar a chave de criptografia com transferências.
Clique em Salvar.
O console do Google Cloud mostra todos os detalhes da configuração da transferência, incluindo um Nome de recurso para ela.
bq
Digite o comando bq mk e forneça a sinalização de criação da transferência --transfer_config. As sinalizações abaixo também são obrigatórias:
--project_id--data_source--target_dataset--display_name--params
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --target_dataset=dataset \ --display_name=name \ --service_account_name=service_account \ --params='parameters'
Substitua:
- project_id: o ID do projeto Google Cloud . Se
--project_idnão for especificado, o projeto padrão será usado. - data_source: a fonte de dados,
snowflake_migration. - dataset: o conjunto de dados de destino do BigQuery para a configuração de transferência.
- name: o nome de exibição da configuração de transferência. O nome da transferência pode ser qualquer valor que permita identificá-la facilmente, caso precise modificá-la mais tarde.
- service_account: (opcional) o nome da conta de serviço usado para
autenticar a transferência. A conta de serviço precisa pertencer ao mesmo
project_idusado para criar a transferência e ter todas as funções necessárias. - parameters é o parâmetro da configuração de transferência criada no formato JSON. Por exemplo,
--params='{"param":"param_value"}'.
É possível configurar os seguintes parâmetros para sua configuração de transferência do Snowflake:
account_identifier: especifique um identificador exclusivo para sua conta do Snowflake, que é uma combinação do nome da organização e da conta. O identificador é o prefixo do URL da conta do Snowflake, não o URL completo. Por exemplo,account_identifier.snowflakecomputing.com.username: especifique o nome de usuário do usuário do Snowflake cujas credenciais e autorização são usadas para acessar seu banco de dados e transferir as tabelas do Snowflake.auth_mechanism: especifique o método de autenticação do usuário do Snowflake. Os valores aceitos sãoPASSWORDeKEY_PAIR. Para mais informações, consulte Gerar um par de chaves para autenticação.password: especifique a senha do usuário do Snowflake. Esse campo é obrigatório se você tiver especificadoPASSWORDno campoauth_mechanism.private_key: especifique a chave privada vinculada à chave pública associada ao usuário do Snowflake. Esse campo é obrigatório se você tiver especificadoKEY_PAIRno campoauth_mechanism.is_private_key_encrypted: especifiquetruese a chave privada estiver criptografada com uma senha longa.private_key_passphrase: especifique a senha longa da chave privada criptografada. Esse campo é obrigatório se você tiver especificadoKEY_PAIRno campoauth_mechanismetrueno campois_private_key_encrypted.warehouse: especifique um data warehouse usado para a execução dessa transferência de dados.service_account: especifique uma conta de serviço a ser usada com essa transferência de dados. A conta de serviço precisa pertencer ao mesmo projeto do Google Cloud em que a configuração de transferência e o conjunto de dados de destino foram criados. A conta de serviço precisa ter as permissões necessáriasstorage.objects.listestorage.objects.get.database: especifique o nome do banco de dados do Snowflake que contém as tabelas incluídas nesta transferência de dados.schema: especifique o nome do esquema do Snowflake que contém as tabelas incluídas nesta transferência de dados.table_name_patterns: especifique uma tabela para transferir inserindo um nome ou um padrão que corresponda ao nome da tabela no esquema. Você pode usar expressões regulares para especificar o padrão, por exemplo,table1_regex;table2_regex. Esse padrão precisa seguir a sintaxe da expressão regular do Java. Por exemplo,lineitem;ordertbcorresponde às tabelas chamadaslineitemeordertb..*corresponde a todas as tabelas.Também é possível deixar esse campo em branco para migrar todas as tabelas do esquema especificado.
ingestion_mode: especifique o modo de ingestão da transferência. Os valores aceitos sãoFULLeINCREMENTAL. Para mais informações, consulte Configurar transferências graduais.translation_output_gcs_path: (opcional) especifique um caminho para a pasta do Cloud Storage que contém os arquivos de mapeamento de esquema do mecanismo de tradução. Você pode deixar esse campo em branco para que o conector do Snowflake detecte automaticamente seu esquema.- O caminho precisa seguir o formato
gs://translation_target_base_uri/metadata/config/db/schema/e terminar com/.
- O caminho precisa seguir o formato
storage_integration_object_name: especifique o nome do objeto de integração de armazenamento do Snowflake.max_file_size_mb: (opcional) especifique o tamanho máximo de cada arquivo descarregado do Snowflake para o local de staging em MB. O valor precisa estar entre16e5120. O valor padrão é512.staging_gcs_uri: insira o URI do bucket do Cloud Storage que será usado para organizar seus dados.use_private_network: se você estiver criando uma transferência de dados privados, defina comoTRUE.service_attachment: se você estiver criando uma transferência de dados particular, especifique o URI do anexo de serviço. Para mais informações, consulte Criar uma configuração de transferência privada do Snowflake.private_network_service: se você estiver criando uma transferência de dados particular, especifique o autolink do serviço NLB. Para mais informações, consulte Criar uma configuração de transferência privada do Snowflake.
Por exemplo, para uma conta do Snowflake hospedada na AWS, o comando a seguir cria uma transferência do Snowflake chamada Snowflake transfer config com um conjunto de dados de destino chamado your_bq_dataset e um projeto com o ID your_project_id.
PARAMS='{ "account_identifier": "your_account_identifier", "auth_mechanism": "KEY_PAIR", "aws_access_key_id": "your_access_key_id", "aws_secret_access_key": "your_aws_secret_access_key", "cloud_provider": "AWS", "database": "your_sf_database", "ingestion_mode": "INCREMENTAL", "private_key": "-----BEGIN PRIVATE KEY----- privatekey\nseparatedwith\nnewlinecharacters=-----END PRIVATE KEY-----", "schema": "your_snowflake_schema", "service_account": "your_service_account", "storage_integration_object_name": "your_storage_integration_object", "max_file_size_mb": "512", "staging_s3_uri": "s3://your/s3/bucket/uri", "table_name_patterns": ".*", "translation_output_gcs_path": "gs://sf_test_translation/output/metadata/config/database_name/schema_name/", "username": "your_sf_username", "warehouse": "your_warehouse" }' bq mk --transfer_config \ --project_id=your_project_id \ --target_dataset=your_bq_dataset \ --display_name='snowflake transfer config' \ --params="$PARAMS" \ --data_source=snowflake_migration
API
Use o método projects.locations.transferConfigs.create e forneça uma instância do recurso TransferConfig.
Especificar a chave de criptografia com transferências
É possível especificar chaves de criptografia gerenciadas pelo cliente (CMEKs, na sigla em inglês) para criptografar dados de uma execução de transferência. É possível usar uma CMEK para dar suporte a transferências do Snowflake.Quando você especifica uma CMEK com uma transferência, o serviço de transferência de dados do BigQuery aplica a CMEK a qualquer cache intermediário no disco de dados ingeridos para que todo o fluxo de trabalho de transferência de dados fique em conformidade com a CMEK.
Não é possível atualizar uma transferência atual para adicionar uma CMEK se a transferência não tiver sido criada originalmente com uma CMEK. Por exemplo, não é possível alterar uma tabela de destino que, originalmente, estava criptografada por padrão, para ser criptografada com CMEKs. Por outro lado, também não é possível alterar uma tabela de destino criptografada por CMEK para ter um tipo diferente de criptografia.
É possível atualizar uma CMEK para uma transferência se a configuração de transferência tiver sido criada originalmente com uma criptografia CMEK. Quando você atualiza uma CMEK para uma configuração de transferência, o serviço de transferência de dados do BigQuery propaga a CMEK para as tabelas de destino na próxima execução da transferência, em que o serviço de transferência de dados do BigQuery substitui todas as CMEKs desatualizadas pela nova CMEK durante a execução da transferência. Para saber mais, consulte Atualizar uma transferência.
Também é possível usar as chaves padrão do projeto. Quando você especifica uma chave padrão do projeto com uma transferência, o serviço de transferência de dados do BigQuery a usa como padrão para qualquer nova configuração de transferência.
Cotas e limites
O BigQuery tem uma cota de carregamento de 15 TB para cada job de carregamento de cada tabela por padrão. Internamente, o Snowflake compacta os dados da tabela. Portanto, o tamanho da tabela exportada é maior do que o informado pelo Snowflake.
Para melhorar os tempos de carregamento de tabelas maiores e remover o limite de carregamento de 15 TB do BigQuery, especifique o tipo de serviço PIPELINE para sua atribuição de reserva.
Devido ao modelo de consistência do Amazon S3, é possível que alguns arquivos não sejam incluídos na transferência para o BigQuery.
Otimizar o desempenho da transferência de dados
Para monitorar a performance das suas transferências de dados, consulte os registros da transferência de dados. Para melhorar a performance das suas transferências de dados, recomendamos que você siga estas etapas de otimização:
- Mantenha a instância do Snowflake, o bucket de staging e o conjunto de dados do BigQuery na mesma região.
- Para melhorar a velocidade de descarregamento da tabela, faça o seguinte:
- Aumente o tamanho do seu data warehouse virtual do Snowflake, principalmente ao transferir tabelas grandes do Snowflake (1 TiB ou mais).
- Ajuste a opção
MAX_FILE_SIZEna configuração de transferência.- Tamanhos de arquivo menores podem melhorar as velocidades de transferência, mas torná-los muito pequenos pode levar a um número excessivo de arquivos.
- Para melhorar a velocidade de carregamento das tabelas, aumente o número de reservas Slot do BigQuery para os tipos de job
PIPELINEeQUERY. - Ao fazer uma transferência completa, evite o clustering e o particionamento na tabela de destino do BigQuery.
- Ao fazer uma transferência incremental no modo "Upsert", considere o clustering e o particionamento nas colunas de chave primária para melhorar a performance da transferência.
- No entanto, evite clustering e particionamento em colunas que não são de chave primária para evitar operações de mesclagem mais lentas.
Preços
Para informações sobre os preços do serviço de transferência de dados do BigQuery, consulte a página Preços.
- Se o data warehouse do Snowflake e o bucket do Amazon S3 estiverem em regiões diferentes, o Snowflake vai aplicar cobranças de saída ao executar uma transferência de dados do Snowflake. Não há cobranças de saída para transferências de dados do Snowflake se o data warehouse do Snowflake e o bucket do Amazon S3 estiverem na mesma região.
- Quando os dados são transferidos da AWS para Google Cloud, são aplicadas cobranças de saída entre nuvens.
A seguir
- Saiba mais sobre o serviço de transferência de dados do BigQuery.
- Migrar o código SQL com a translação de SQL em lote.